Neste artigo, gostaria de falar sobre os recursos das matrizes All Flash AccelStor que trabalham com uma das plataformas de virtualização mais populares - o VMware vSphere. Em particular, focar nos parâmetros que ajudarão a obter o máximo efeito ao usar uma ferramenta tão poderosa como o All Flash.
Todas as matrizes do Flash AccelStor NeoSapphire ™ são dispositivos de um ou dois nós baseados em SSDs com uma abordagem fundamentalmente diferente para implementar o conceito de armazenamento de dados e organizar o acesso a eles usando sua própria tecnologia FlexiRemap® , em vez dos algoritmos RAID muito populares. As matrizes fornecem acesso de bloco para hosts por meio de interfaces Fibre Channel ou iSCSI. Para ser sincero, observamos que os modelos com a interface ISCSI também têm acesso a arquivos como um bom bônus. Mas neste artigo, focaremos no uso de protocolos de bloco como o mais produtivo para o All Flash.
Todo o processo de implantação e configuração da colaboração entre a matriz AccelStor e o sistema de virtualização VMware vSphere pode ser dividido em vários estágios:
- Implementação da topologia de conexão e configuração da rede SAN;
- Configurando toda a matriz Flash;
- Configurar hosts ESXi;
- Configure máquinas virtuais.
Matrizes AccelStor NeoSapphire ™ com Fibre Channel e iSCSI foram usadas como equipamento de exemplo. O software base é o VMware vSphere 6.7U1.
Antes de implantar os sistemas descritos neste artigo, é altamente recomendável que você se familiarize com a documentação da VMware sobre problemas de desempenho ( Melhores Práticas de Desempenho para VMware vSphere 6.7 ) e configurações de iSCSI ( Melhores Práticas para Executar o VMware vSphere On iSCSI )
Topologia de conexão e configuração de SAN
Os principais componentes de uma rede SAN são HBAs em hosts ESXi, comutadores SAN e nós de matriz. Uma topologia típica dessa rede ficaria assim:
O termo Switch aqui refere-se a um único switch físico ou a um conjunto de switches (Fabric) ou a um dispositivo compartilhado entre diferentes serviços (VSAN no caso do Fibre Channel e VLAN no caso do iSCSI). O uso de dois comutadores independentes / Fabric elimina um possível ponto de falha.
A conexão direta de hosts à matriz, apesar de suportada, é altamente desencorajada. O desempenho de matrizes All Flash é bastante alto. E para obter a velocidade máxima, você precisa usar todas as portas da matriz. Portanto, é necessário pelo menos um comutador entre hosts e NeoSapphire ™.
Ter duas portas no host HBA também é um pré-requisito para desempenho máximo e tolerância a falhas.
Se você usar a interface Fibre Channel, precisará configurar o zoneamento para evitar possíveis conflitos entre iniciadores e destinos. As zonas são construídas com base no princípio de "uma porta do iniciador - uma ou mais portas do array".
Se você estiver usando a conexão iSCSI, se estiver usando um switch compartilhado com outros serviços, deverá isolar o tráfego iSCSI dentro de uma VLAN separada. Também é altamente recomendável que você ative o suporte a Jumbo Frames (MTU = 9000) para aumentar o tamanho dos pacotes na rede e, assim, reduzir a quantidade de sobrecarga durante a transmissão. No entanto, vale lembrar que, para a operação correta, é necessário alterar o parâmetro MTU em todos os componentes de rede ao longo da cadeia iniciador-switch-alvo.
Configurando todas as matrizes Flash
A matriz é entregue aos clientes com grupos FlexiRemap® já formados. Portanto, nenhuma ação é necessária para integrar as unidades em uma única estrutura. É suficiente criar volumes com o tamanho e a quantidade necessários.
Por conveniência, existe uma funcionalidade para criação em lote de vários volumes de um determinado volume de uma só vez. Os volumes "thin" são criados por padrão, pois isso permite um uso mais racional do espaço de armazenamento disponível (inclusive graças ao suporte da Space Reclamation). Em termos de desempenho, a diferença entre volumes finos e grossos não excede 1%. No entanto, se você quiser "espremer todos os sucos" da matriz, sempre poderá converter qualquer volume "fino" em "grosso". Mas deve-se lembrar que tal operação é irreversível.
Resta então "publicar" os volumes criados e definir direitos de acesso a eles a partir dos hosts usando a ACL (endereços IP para iSCSI e WWPN para FC) e a separação física das portas na matriz. Para modelos iSCSI, isso é feito através da criação do Target.
Para modelos FC, a publicação ocorre através da criação de um LUN para cada porta na matriz.
Para acelerar o processo de configuração, os hosts podem ser agrupados. Além disso, se o host usar o FC HBA de várias portas (o que geralmente ocorre na prática), o sistema determinará automaticamente que as portas desse HBA pertencem ao mesmo host devido ao WWPN, que diferem por um. Além disso, a criação em lote do Target / LUN é suportada para ambas as interfaces.
Um ponto importante ao usar a interface iSCSI é criar vários destinos para volumes de uma só vez para aumentar o desempenho, pois a fila de destino não pode ser alterada e, na verdade, será um gargalo.
Configurar hosts ESXi
No lado ESXi, a configuração básica é feita de acordo com o cenário bastante esperado. Procedimento para conexão iSCSI:
- Adicionar adaptador iSCSI de software (não é necessário se já tiver sido adicionado ou se estiver usando o adaptador iSCSI de hardware);
- Criando vSwitch, através do qual o tráfego iSCSI passará, e adicionando uplink físico e VMkernal a ele;
- Adicionando endereços de matriz à descoberta dinâmica;
- Criando armazenamento de dados
Algumas notas importantes:
- No caso geral, é claro, você pode usar o vSwitch existente, mas no caso de um vSwitch separado, o gerenciamento das configurações do host será muito mais simples.
- É necessário separar o tráfego de gerenciamento e o iSCSI em links físicos e / ou VLANs separados para evitar problemas de desempenho.
- Os endereços IP do VMkernal e as portas correspondentes da matriz All Flash devem estar na mesma sub-rede, novamente devido a problemas de desempenho.
- Para garantir a tolerância a falhas do VMware, o vSwitch deve ter pelo menos dois links físicos
- Se estiver usando Jumbo Frames, você deve alterar o MTU do vSwitch e do VMkernal
- Não será errado lembrar que, de acordo com as recomendações da VMware para adaptadores físicos que serão usadas para trabalhar com tráfego iSCSI, é necessário configurar o Teaming e Failover. Em particular, cada VMkernal deve funcionar apenas através de um uplink, o segundo uplink deve ser alternado para o modo não utilizado. Para tolerância a falhas, você precisa adicionar dois VMkernal, cada um dos quais funcionará através de seu uplink.
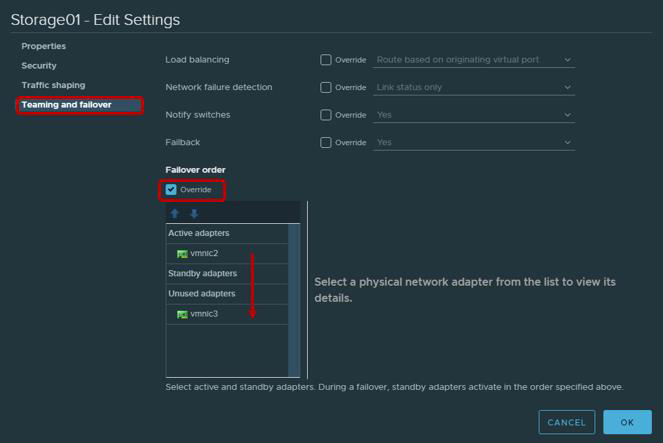
| Adaptador VMkernel (vmk #) | Adaptador de rede física (vmnic #) |
|---|
| vmk1 (Storage01) | Adaptadores ativos
vmnic2
Adaptadores não utilizados
vmnic3
|
| vmk2 (Storage02) | Adaptadores ativos
vmnic3
Adaptadores não utilizados
vmnic2
|
Nenhuma conexão Fibre Channel necessária. Você pode criar imediatamente um armazenamento de dados.
Depois de criar o armazenamento de dados, é necessário garantir que a política Round Robin seja usada para os caminhos do Target / LUN como os mais produtivos.
Por padrão, as configurações do VMware fornecem o uso dessa política de acordo com o esquema: 1000 solicitações pelo primeiro caminho, próximas 1000 solicitações pelo segundo caminho, etc. Essa interação do host com uma matriz de controlador duplo será desequilibrada. Portanto, recomendamos configurar o parâmetro Round Robin policy = 1 através do Esxcli / PowerCLI.
ParâmetrosPara Esxcli:
- Imprimir LUNs disponíveis
lista de dispositivos nmp de armazenamento esxcli
- Copiar nome do dispositivo
- Alterar política de round robin
esxcli armazenamento nmp psp roundrobin deviceconfig set --type = iops --iops = 1 --device = "Device_ID"
A maioria dos aplicativos modernos é projetada para trocar pacotes de dados grandes, a fim de maximizar a utilização da largura de banda e reduzir a carga da CPU. Portanto, o ESXi, por padrão, transfere solicitações de E / S para o dispositivo de armazenamento em lotes de até 32767 KB. No entanto, para vários cenários, a troca de porções menores será mais produtiva. Para matrizes AccelStor, estes são os seguintes cenários:
- A máquina virtual usa UEFI em vez do BIOS herdado
- Usado pelo vSphere Replication
Para esses cenários, é recomendável alterar o valor do parâmetro Disk.DiskMaxIOSize para 4096.
Para conexões iSCSI, é recomendável alterar o parâmetro Login Timeout para 30 (padrão 5) para aumentar a estabilidade da conexão e desativar o atraso do reconhecimento de pacotes DelayedAck encaminhados. As duas opções estão no vSphere Client: Host → Configurar → Armazenamento → Adaptadores de armazenamento → Opções avançadas para o adaptador iSCSI
Um ponto bastante sutil é o número de volumes usados para o armazenamento de dados. É claro que, para facilitar o gerenciamento, existe o desejo de criar um grande volume para todo o volume da matriz. No entanto, a presença de vários volumes e, consequentemente, o armazenamento de dados tem um efeito benéfico no desempenho geral (mais sobre as filas um pouco mais adiante no texto). Portanto, recomendamos a criação de pelo menos dois volumes.
Mais recentemente, a VMware aconselhou limitar o número de máquinas virtuais em um único armazenamento de dados, novamente para obter o melhor desempenho possível. No entanto, agora, especialmente com a disseminação da VDI, esse problema não é mais tão agudo. Mas isso não cancela a regra de longa data - distribuir máquinas virtuais que exigem E / S intensivas em diferentes armazenamentos de dados. Não há nada melhor para determinar o número ideal de máquinas virtuais por volume do que carregar o array All Flash do AccelStor em sua infraestrutura.
Configurar máquinas virtuais
Não há requisitos especiais ao configurar máquinas virtuais, ou melhor, eles são bastante comuns:
- Usando a versão mais alta possível da VM (compatibilidade)
- É mais preciso definir o tamanho da RAM quando as máquinas virtuais são densamente colocadas, por exemplo, em VDI (já que, por padrão, na inicialização, é criado um arquivo de paginação que é comparável ao tamanho da RAM, que consome capacidade útil e afeta o desempenho final)
- Use as versões de E / S mais eficientes dos adaptadores: tipo de rede VMXNET 3 e tipo SCSI PVSCSI
- Use o tipo de unidade Thick Provision Eager Zeroed para desempenho máximo e Thin Provisioning para utilização máxima de armazenamento
- Se possível, limite o trabalho de máquinas de E / S não críticas usando o Limite de disco virtual
- Certifique-se de instalar o VMware Tools
Notas da fila
Uma fila (ou E / S pendentes) é o número de solicitações de E / S (comandos SCSI) que aguardam o processamento a qualquer momento de um dispositivo / aplicativo específico. No caso de um estouro de fila, erros QFULL são gerados, o que resulta em um aumento no parâmetro de latência. Ao usar sistemas de armazenamento em disco (eixo), teoricamente, quanto maior a fila, maior o desempenho. No entanto, você não deve abusar, porque é fácil encontrar o QFULL. No caso dos sistemas All Flash, por um lado, tudo é um pouco mais simples: a matriz atrasa várias ordens de magnitude mais baixas e, portanto, na maioria das vezes não é necessário ajustar separadamente o tamanho das filas. Mas, por outro lado, em alguns cenários de uso (um forte viés nos requisitos de E / S para máquinas virtuais específicas, testes para desempenho máximo etc.), se você não alterar os parâmetros da fila, pelo menos entenda quais indicadores podem ser alcançados e, mais importante, de que maneira.
O próprio All Flash Array do AccelStor não possui limites de volumes ou portas de E / S. Se necessário, mesmo um único volume pode obter todos os recursos da matriz. A única restrição de fila é com destinos iSCSI. É por esse motivo que a necessidade de criar vários destinos (idealmente até 8 peças) para cada volume para superar esse limite foi indicada acima. Além disso, as matrizes AccelStor são soluções altamente produtivas. Portanto, você deve usar todas as portas de interface do sistema para atingir a velocidade máxima.
No lado ESXi do host, a situação é completamente diferente. O próprio host aplica a prática de acesso igual aos recursos para todos os participantes. Portanto, existem filas de E / S separadas para o SO convidado e o HBA. As filas para o sistema operacional convidado são combinadas de filas para o adaptador SCSI virtual e o disco virtual:
A fila para HBA depende do tipo / fornecedor específico:
O desempenho final da máquina virtual será determinado pelo limite mais baixo de profundidade da fila entre os componentes do host.
Graças a esses valores, você pode avaliar os indicadores de desempenho que podemos obter em uma ou outra configuração. Por exemplo, queremos saber o desempenho teórico de uma máquina virtual (sem ligação a um bloco) com latência de 0,5 ms. Então, suas IOPS = (1.000 / latência) * E / S pendentes (limite de profundidade da fila)
ExemplosExemplo 1
- Adaptador FC Emulex HBA
- Uma VM no armazenamento de dados
- Adaptador SCSI para VMware Paravirtual
Aqui, o limite de profundidade da fila é determinado pelo Emulex HBA. Portanto, IOPS = (1000 / 0,5) * 32 = 64K
Exemplo 2
- Adaptador de software iSCSI da VMware
- Uma VM no armazenamento de dados
- Adaptador SCSI para VMware Paravirtual
Aqui, o limite de profundidade da fila já está definido pelo adaptador SCSI Paravirtual. Portanto, IOPS = (1000 / 0,5) * 64 = 128K
As principais matrizes All AccelStor All Flash (como a P710 ) são capazes de oferecer um desempenho de 700K IOPS para gravação em bloco 4K. Com esse tamanho de bloco, é óbvio que uma única máquina virtual não é capaz de carregar essa matriz. Para fazer isso, você precisará de 11 (por exemplo 1) ou 6 (por exemplo 2) máquinas virtuais.
Como resultado, com a configuração correta de todos os componentes descritos do data center virtual, você pode obter resultados impressionantes em termos de desempenho.
Aleatório em 4K, 70% de leitura / 30% de gravação
De fato, o mundo real é muito mais difícil de descrever com uma fórmula simples. Um único host sempre tem muitas máquinas virtuais com diferentes configurações e requisitos de E / S. Sim, e o processador host está envolvido no processamento de entrada / saída, cuja potência não é infinita. Portanto, para liberar todo o potencial do mesmo modelo, o P710 na realidade precisará de três hosts. Além disso, os aplicativos executados dentro de máquinas virtuais fazem ajustes. Portanto, para um dimensionamento preciso, sugerimos o uso de um teste no caso de modelos de teste de matrizes do All Flash AccelStor dentro da infraestrutura do cliente para tarefas atuais da vida real.