
Olá Habr! Continuo publicando o ciclo sobre o interior da plataforma de pagamento RBK.money, iniciada neste post . Hoje falaremos sobre o esquema de processamento lógico, microsserviços específicos e seu relacionamento um com o outro, como os serviços que processam cada parte da lógica de negócios são separados logicamente, por que o núcleo de processamento não sabe nada sobre os números de seus cartões de pagamento e como os pagamentos são executados dentro da plataforma. Além disso, um pouco mais detalhadamente, revelarei o tópico de como fornecemos alta disponibilidade e dimensionamento para lidar com altas cargas.
Lógica geral e abordagens gerais
Em geral, o esquema dos elementos básicos da parte do processamento responsável pelos pagamentos é semelhante a esse.
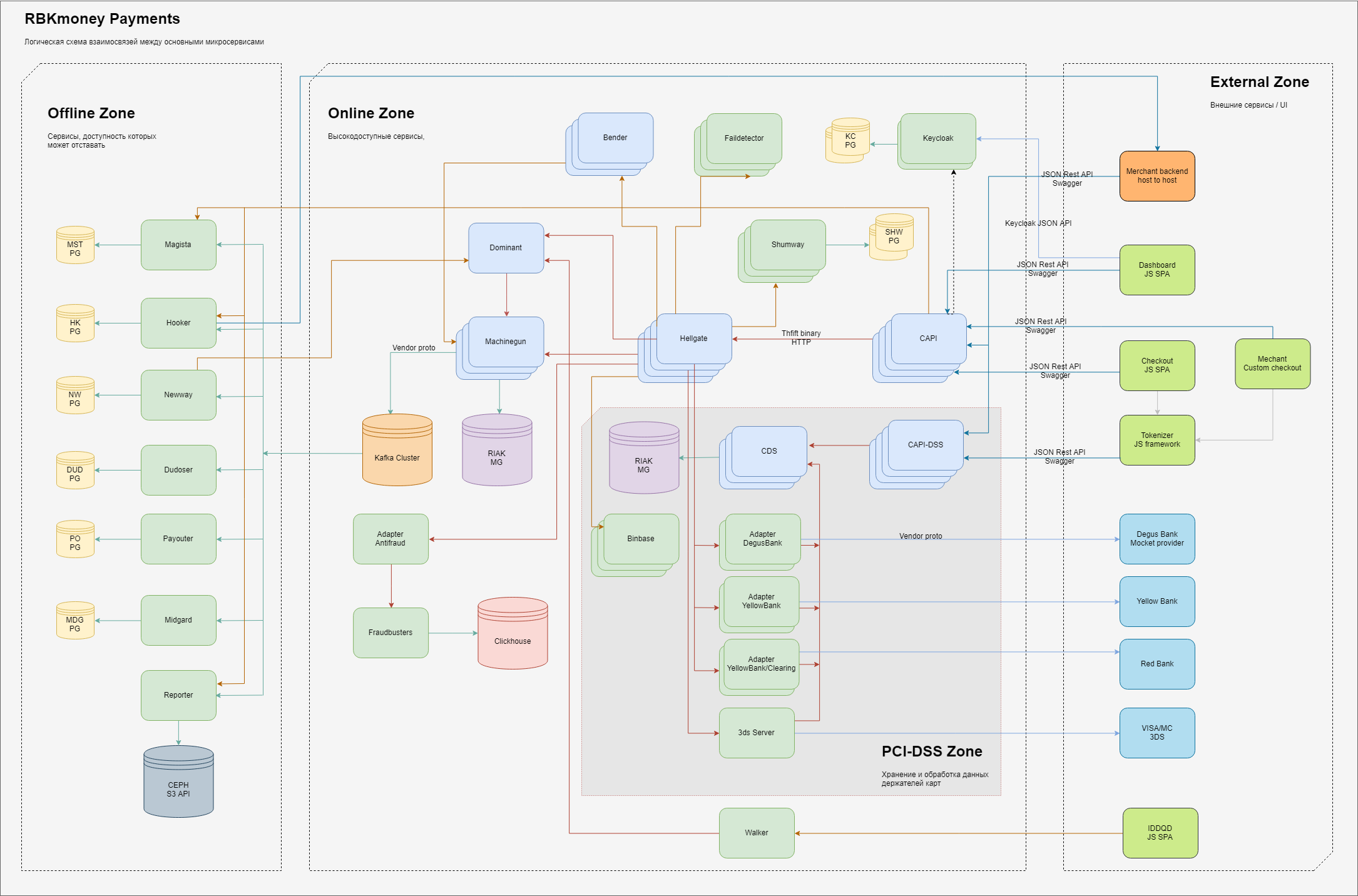
Logicamente, dentro de nós mesmos, dividimos as áreas de responsabilidade em três domínios:
- zona externa, entidades que estão na Internet, como aplicativos JS do nosso formulário de pagamento (você digita os detalhes do seu cartão), back-end de nossos clientes comerciais, além de gateways de processamento de nossos bancos parceiros e fornecedores de outros métodos de pagamento;
- uma zona interna altamente acessível, os microsserviços vivem lá, que fornecem diretamente o trabalho do gateway de pagamento e gerenciam o débito de dinheiro, levando-os em consideração em nosso sistema e outros serviços on-line, caracterizados pelo requisito "sempre deve estar disponível, apesar de qualquer falha em nossos CDs";
- existe uma área separada de serviços que trabalha diretamente com os dados completos dos titulares de cartão, e esses serviços têm requisitos separados apresentados pelo Ministério das Ferrovias e sujeitos a certificação obrigatória sob os padrões PCI-DSS. Explicaremos mais detalhadamente por que essa separação abaixo;
- a zona interna, onde existem requisitos menores para a disponibilidade dos serviços prestados ou o tempo de resposta, no sentido clássico - esse é um back office. Embora, é claro, aqui também tentemos garantir o princípio de “sempre disponível”, apenas gastamos menos esforço nisso;
Dentro de cada zona, existem microsserviços que executam suas partes do processamento da lógica de negócios. Eles recebem chamadas RPC na entrada e na saída, geram dados processados usando algoritmos incorporados, que também são executados como chamadas de outros microsserviços ao longo da cadeia.
Para garantir escalabilidade, tentamos armazenar estados no menor número de lugares possível. Os serviços sem estado no diagrama não têm conexões com armazenamentos persistentes, com estado, respectivamente, estão conectados a eles. Em geral, usamos vários serviços limitados para armazenamento de estado persistente - para a parte principal do processamento, esses são clusters Riak KV, para serviços relacionados - PostgreSQL, para processamento de fila assíncrona que usamos Kafka.
Para garantir alta disponibilidade, implantamos serviços em várias instâncias, geralmente de 3 a 5.
É fácil dimensionar serviços sem estado, simplesmente aumentamos o número de instâncias que precisamos em diferentes máquinas virtuais, elas estão registradas no Consul, estão disponíveis para resolução através do DNS do console e começam a receber chamadas de outros serviços, processando os dados recebidos e enviando-os ainda mais.
Os serviços com estado, ou melhor, é o principal e mostrado no diagrama como metralhadora, implementam uma interface altamente acessível (a arquitetura distribuída é baseada na distribuição Erlang) e a sincronização via Consul KV é usada para garantir o enfileiramento e o bloqueio distribuído. Esta é uma descrição curta e detalhada estará em um post separado.
Pronto para uso, o Riak fornece um armazenamento masterless persistente altamente acessível, não o preparamos de forma alguma, a configuração está quase no padrão. Com o perfil de carregamento atual, temos 5 nós no cluster implantados em hosts separados. Uma observação importante - praticamente não usamos índices e grandes amostras de dados, trabalhamos com chaves específicas.
Onde é muito caro implementar o esquema KV, usamos os bancos de dados PostgeSQL com replicação ou até soluções monomodo, pois sempre podemos fazer o upload dos eventos necessários no caso de uma falha da parte online via Machinegun.
A separação de cores dos microsserviços no diagrama indica os idiomas em que são gravados - verde claro - esses são aplicativos Java, azul claro - Erlang.
Todos os serviços funcionam em contêineres Docker, que são artefatos de construção de IC e estão localizados no Docker Registry local. Implanta serviços na produção SaltStack, cuja configuração está no repositório privado do Github.
Os desenvolvedores solicitam mudanças de forma independente neste repositório, onde descrevem os requisitos para o serviço - indicam a versão e os parâmetros desejados, como o tamanho da memória alocada para o contêiner, transferidos para variáveis de ambiente e outras coisas. Além disso, após a confirmação manual da solicitação de alteração por funcionários autorizados (temos DevOps, suporte e segurança da informação), o CD lança automaticamente as instâncias do contêiner com as novas versões para os hosts do ambiente do produto.
Além disso, cada serviço grava logs em um formato compreensível para o Elasticsearch. Os arquivos de log são selecionados pelo Filebeat, que os grava no cluster Elasticsearch. Portanto, apesar de os desenvolvedores não terem acesso ao ambiente do produto, eles sempre têm a oportunidade de depurar e ver o que acontece com seus serviços.
Interação com o mundo exterior

Qualquer alteração no estado da plataforma conosco ocorre exclusivamente através de chamadas para os métodos correspondentes de APIs públicas. Na verdade, não usamos aplicativos da Web clássicos e geração de conteúdo no servidor; tudo o que você vê como interface do usuário são visualizações JS em nossas APIs públicas. Em princípio, qualquer ação na plataforma pode ser executada com uma cadeia de chamadas curl do console, que usamos. Em particular, para escrever testes de integração (nós os escrevemos em JS como uma biblioteca), que no CI, durante cada montagem, verifica todos os métodos públicos.
Além disso, essa abordagem resolve todos os problemas de integração externa com nossa plataforma, permitindo que você obtenha um único protocolo para o usuário final na forma de uma bela forma de inserir dados de pagamento e host-to-host para integração direta com processamento de terceiros usando exclusivamente a interação entre servidores.
Além da cobertura completa dos testes de integração, usamos as abordagens de atualização temporária; em uma arquitetura distribuída, é bastante fácil fazer isso, por exemplo, lançando apenas um serviço de cada grupo em uma passagem, seguido de uma pausa e análise de logs e gráficos.
Isso nos permite implantar quase o tempo todo, incluindo as noites de sexta-feira, lançar algo inoperante sem muito medo ou retroceder rapidamente, fazendo com que uma reversão simples seja confirmada com uma alteração, até que ninguém perceba.

Antes de qualquer chamada ao método público, precisamos autorizar e autenticar o cliente. Para que um cliente apareça na plataforma, você precisa de um serviço que cuide de toda a interação com o usuário final, forneça interfaces para registrar, inserir e redefinir senhas, controle de segurança e outras ligações.
Aqui, não inventamos uma bicicleta, apenas integramos a solução de código aberto da Redhat - Keycloak . Antes de iniciar qualquer interação conosco, você precisará se registrar na plataforma, o que, de fato, acontece através do Keycloak.
Após a autenticação bem-sucedida no serviço, o cliente recebe um JWT. Nós o usaremos posteriormente para autorização - no lado Keycloak, você pode especificar campos arbitrários que descrevem funções que serão incorporadas como uma estrutura json simples no JWT e assinadas com a chave privada do serviço.
Uma das características do JWT é que essa estrutura é assinada pela chave privada do servidor; portanto, para autorizar a lista de funções e seus outros objetos, não precisamos acessar o serviço de autorização, o processo é completamente dissociado. Os serviços CAPI na inicialização leem a chave pública Keycloak e a utilizam para autorizar chamadas para métodos de API pública.
Como criamos o principal esquema de revogação, a história é separada e digna de seu próprio post.
Assim, recebemos o JWT, podemos usá-lo para autenticação. Aqui o grupo de APIs comuns de microsserviços entra em cena, no diagrama indicado como CAPI e CAPI-DSS, implementando as seguintes funções:
- autorização de mensagens recebidas. Cada chamada pública da API é precedida por um cabeçalho HTTP Authorizaion: Bearer {JWT}. Os serviços do grupo API Comum o utilizam para verificar os dados assinados com a chave pública existente do serviço de autorização;
- validação dos dados recebidos. Como o esquema é descrito como uma especificação OpenAPI, também conhecida como Swagger, a validação de dados pode ser muito fácil e com poucas chances de receber comandos de controle no fluxo de dados. Isso tem um efeito positivo na segurança do serviço como um todo;
- tradução de formatos de dados de JSON REST público para Thrift binário interno;
- enquadrando a ligação de transporte com dados como um trace_id exclusivo e passando o evento ainda mais dentro da plataforma para um serviço que gerencia a lógica de negócios e sabe o que é, por exemplo, o pagamento.
Temos muitos desses serviços, eles são bastante simples e o carvalho, não armazena nenhum estado; portanto, para o dimensionamento linear do desempenho, simplesmente os implantamos em capacidades livres nas quantidades necessárias.
PCI-DSS e dados abertos do cartão

Como você pode ver no diagrama, temos dois desses grupos de serviços - o principal, a API comum, é responsável pelo processamento de todos os fluxos de dados que não possuem dados abertos do titular do cartão e o segundo, a API comum do PCI-DSS, que trabalha diretamente com esses cartões. No interior, eles são exatamente iguais, mas nós os separamos fisicamente e os organizamos em diferentes pedaços de ferro.
Isso é feito para minimizar o número de locais para armazenamento e processamento de dados do cartão, reduzir os riscos de vazamento desses dados e da área de certificação PCI-DSS. E isso, acredite, é um processo bastante demorado e caro - como empresa de pagamento, somos obrigados a receber uma certificação paga para conformidade com os padrões MPS a cada ano, e quanto menos servidores e serviços envolvidos nele, mais rápido e fácil é concluir esse processo. Bem, na segurança, isso se reflete da maneira mais positiva.
Faturamento e tokenização
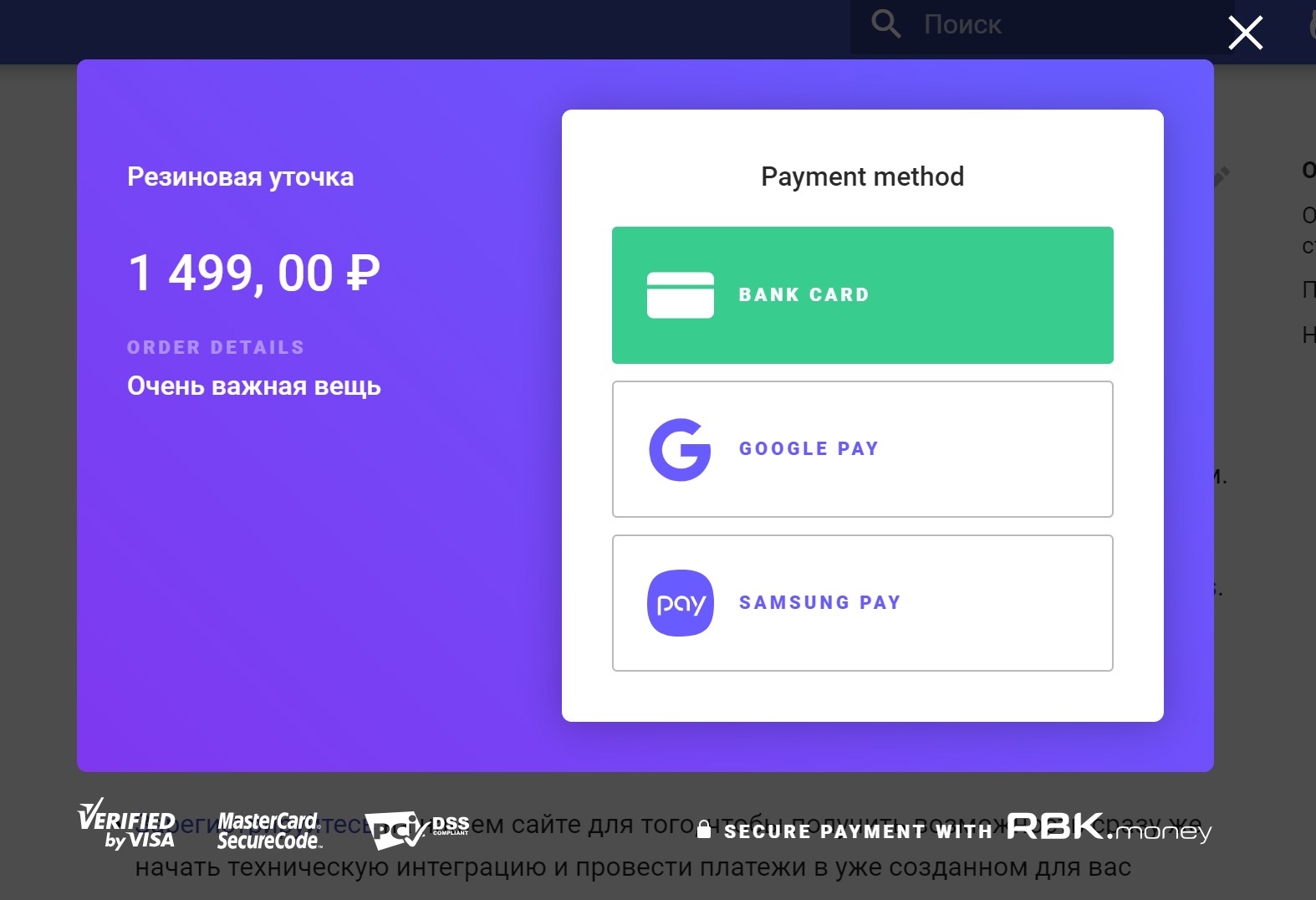
Portanto, queremos iniciar o pagamento e cancelar o dinheiro do cartão do pagador.
Imagine que a solicitação para isso veio na forma de uma cadeia de chamadas para os métodos de nossa API pública, que foi iniciada por você como pagador depois de acessar a loja on-line, coletar uma cesta de mercadorias, clicar em "Comprar", inserir os detalhes do cartão em nosso pagamento e clique no botão "Pagar".
Fornecemos vários processos de negócios para baixa de dinheiro, mas o mais interessante é o processo usando contas a pagar. Em nossa plataforma, você pode criar uma fatura para pagamento ou uma fatura que será um contêiner para pagamentos.
Em uma fatura, você pode tentar pagá-la uma a uma, ou seja, criar pagamentos até o próximo pagamento ser bem-sucedido. Por exemplo, você pode tentar pagar uma fatura de diferentes cartões, carteiras e outros métodos de pagamento. Se não houver dinheiro em um dos cartões, você pode tentar outro e assim por diante.
Isso tem um efeito positivo na conversão e na experiência do usuário.
Máquina do estado da fatura

Dentro da plataforma, essa cadeia se transforma em interações ao longo da seguinte rota:
- Antes de entregar o conteúdo ao seu navegador, nosso cliente-comerciante se integrou à nossa plataforma, registrou-se conosco e recebeu um JWT para autorização;
- a partir de seu back-end, o comerciante chamou o método createInvoice () , ou seja, ele criou uma fatura para pagamento em nossa plataforma. De fato, o back-end do comerciante enviou uma solicitação HTTP POST do seguinte conteúdo ao nosso endpoint:
curl -X POST \ https://api.rbk.money/v2/processing/invoices \ -H 'Authorization: Bearer {JWT}' \ -H 'Content-Type: application/json; charset=utf-8' \ -H 'X-Request-ID: 1554417367' \ -H 'cache-control: no-cache' \ -d '{ "shopID": "TEST", "dueDate": "2019-03-28T17:41:32.569Z", "amount": 6000, "currency": "RUB", "product": "Order num 12345", "description": "Delicious meals", "cart": [ { "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "metadata": { "order_id": "Internal order num 13123298761" } }'
A solicitação foi equilibrada em um dos aplicativos erlang do grupo Common API, que verificou sua validade, foi para o serviço Bender, onde recebeu a chave de idempotência, transferiu-a para a plataforma e enviou uma solicitação ao grupo de serviços Hellgate. A instância do Hellgate realizou verificações comerciais, por exemplo, para garantir que o proprietário desse JWT não seja bloqueado em princípio, possa criar faturas e geralmente interagir com a plataforma e começar a criar uma fatura.
Podemos dizer que o Hellgate é o núcleo do nosso processamento, já que é ele quem opera com entidades comerciais, sabe como lançar um pagamento, quem precisa ser chutado para que esse pagamento se transforme em uma cobrança em dinheiro real, como calcular a rota desse pagamento, quem deve ser instruído a cancelar o pagamento refletidos nos balanços, calcule as comissões e outras obrigações.
Normalmente, ele também não armazena nenhum estado e também é facilmente escalável. Mas não queremos perder a fatura ou receber uma cobrança dupla em dinheiro no cartão no caso de uma divisão da rede ou falha do Hellgate por qualquer motivo. É necessário salvar persistentemente esses dados.
Aí vem o terceiro microsserviço, a metralhadora. O Hellgate envia à Machinegun uma chamada para "criar um autômato" com uma carga útil na forma de parâmetros de consulta. Metralhadora organiza solicitações simultâneas e, usando o Hellgate, cria o primeiro evento a partir dos parâmetros - InvoiceCreated. Que então ele mesmo e escreve em Riak e filas. Depois disso, uma resposta bem-sucedida é retornada na ordem inversa à solicitação inicial na cadeia.
Em resumo, o Machinegun é um DBMS com timers sobre qualquer outro DBMS, na versão atual da plataforma - sobre o Riak. Ele fornece uma interface que permite controlar máquinas independentes e fornece garantias de idempotência e ordem de gravação. É MG que não permitirá que o evento seja gravado automaticamente da fila se vários HGs chegarem a ele de repente com essa solicitação.
Um autômato é uma entidade exclusiva dentro da plataforma, composta por um identificador, um conjunto de dados na forma de uma lista de eventos e um cronômetro. O estado final do autômato é calculado a partir do processamento de todos os seus eventos que iniciam sua transição para o estado correspondente. Usamos essa abordagem para trabalhar com entidades comerciais, descrevendo-as como máquinas de estados finitos. De fato, todas as faturas criadas por nossos comerciantes, bem como os pagamentos nelas, são máquinas de estados finitos com sua própria lógica de transição entre estados.
A interface para trabalhar com temporizadores no Machinegun permite que você receba uma solicitação do formulário "Desejo continuar processando esta máquina em 15 anos" de outro serviço, juntamente com eventos para gravação. Essas tarefas pendentes são implementadas em timers internos. Na prática, eles são usados com muita frequência - chamadas periódicas ao banco, ações automáticas com pagamentos devido à inatividade prolongada, etc.
A propósito, os códigos-fonte de metralhadora estão abertos sob a licença Apache 2.0 em nosso repositório público . Esperamos que este serviço possa ser útil à comunidade.
Uma descrição detalhada do trabalho da Metralhadora e, em geral, como preparamos o sistema de distribuição, é puxada para um grande poste separado, para que eu não pare aqui com mais detalhes.
As nuances da autorização de clientes externos

Após um salvamento bem-sucedido, o Hellgate retorna os dados para o CAPI, ele converte a estrutura de desvio binário em um JSON lindamente projetado, pronto para ser enviado ao backend do comerciante:
{ "invoice": { "amount": 6000, "cart": [ { "cost": 5000, "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "cost": 1000, "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "createdAt": "2019-04-04T23:00:31.565518Z", "currency": "RUB", "description": "Delicious meals", "dueDate": "2019-04-05T00:00:30.889000Z", "id": "18xtygvzFaa", "metadata": { "order_id": "Internal order num 13123298761" }, "product": "Order num 12345", "shopID": "TEST", "status": "unpaid" }, "invoiceAccessToken": { "payload": "{JWT}" } }
Parece que você pode enviar conteúdo ao pagador no navegador e iniciar o processo de pagamento, mas aqui pensamos que nem todos os comerciantes estariam prontos para implementar de forma independente a autorização no lado do cliente, por isso nós mesmos o implementamos. A abordagem é que o CAPI gera outro JWT que permite iniciar os processos de tokenização do cartão, gerenciar uma fatura específica e adicioná-la à estrutura da fatura retornada.
Um exemplo das funções descritas em um JWT semelhante:
"resource_access": { "common-api": { "roles": [ "invoices.18xtygvzFaa.payments:read", "invoices.18xtygvzFaa.payments:write", "invoices.18xtygvzFaa:read", "payment_resources:write" ] } }
Esse JWT tem um número limitado de tentativas de uso e a vida útil que configuramos, o que permite a publicação no navegador do pagador. Mesmo se for interceptado, o máximo que um invasor pode fazer é pagar pela fatura de outra pessoa ou ler seus dados. Além disso, como a máquina de pagamento não opera com dados abertos do cartão, o máximo que um invasor pode ver é um número de cartão mascarado do tipo 4242 42** **** 4242 , o valor do pagamento e, opcionalmente, uma cesta de mercadorias.
A fatura criada e a chave de acesso permitem iniciar o processo de negócios de pagamento. Fornecemos o ID da fatura e seu JWT ao navegador pagador e transferimos o controle para nossos aplicativos JS.
Nosso aplicativo Checkout JS implementa uma interface para interagir com você como pagador - desenha um formulário de entrada de dados de pagamento, inicia um pagamento, recebe seu status final, mostra um ponto engraçado ou triste.
Tokenização e dados do cartão

Mas o Google Checkout não funciona com dados do cartão. Como mencionado acima, queremos armazenar dados confidenciais na forma de dados do titular do cartão no menor número possível de lugares. Para fazer isso, implementamos a tokenização.
É aqui que a biblioteca JS do Tokenizer entra em cena. Quando você insere seu cartão nos campos de entrada e clica em "Pagar", ele intercepta esses dados e os envia de forma assíncrona para processamento, chamando o método createPaymentResource () .
Essa solicitação é equilibrada para aplicativos CAPI-DSS individuais, que também autorizam a solicitação, apenas verificando a JWT da fatura, validando os dados e enviando-os por tront ao serviço de armazenamento de dados do cartão. No diagrama, é indicado como CDS - Cartão de armazenamento de dados.
Os principais objetivos deste serviço:
- receber dados confidenciais em uma entrada, no nosso caso - dados do seu cartão;
- criptografar esses dados com uma chave de criptografia de dados;
- gerar algum valor aleatório usado como chave;
- salve os dados criptografados nessa chave no seu cluster Riak;
- retorne a chave na forma de um token de dados de pagamento para o serviço CAPI-DSS.
Ao longo do caminho, o serviço resolve várias tarefas importantes, como gerar chaves para criptografar chaves, inserir essas chaves com segurança, criptografar dados, controlar o apagamento do CVV após o pagamento e assim por diante, mas isso está além do escopo desta publicação.
Não foi sem proteção contra a possibilidade de dar um tiro no próprio pé. Há uma probabilidade diferente de zero de que uma JWT privada, projetada para autorizar solicitações do back-end, seja publicada na Web no navegador do cliente. Para evitar que isso aconteça, criamos uma proteção - você pode chamar o método createPaymentResource () apenas com a chave de autorização da fatura. Ao tentar usar uma plataforma JWT privada, retornará um erro HTTP / 401.
Depois de concluir a solicitação de tokenização, o Tokenizer retorna o token recebido ao Checkout e termina seu trabalho.
Processo de negócios da máquina de pagamento

O checkout inicia o processo de pagamento, ou seja, chama o método createPayment () , passando o token do cartão recebido anteriormente como argumento e inicia o processo de pesquisa de eventos, na verdade, chamando o método da API getInvoiceEvents () uma vez por segundo.
Essas solicitações por meio do CAPI se enquadram no Hellgate, que começa a implementar um processo comercial de pagamento, sem usar dados do cartão:
- Em primeiro lugar, o Hellgate vai para o serviço de gerenciamento de configuração - Dominante e recebe a revisão atual da configuração do domínio. Ele contém todas as regras pelas quais esse pagamento será efetuado, em qual banco ele será autorizado, quais taxas de transação serão registradas etc.
- do serviço de gerenciamento de membros, agora faz parte da HG, aprende dados sobre os números internos das contas do comerciante em favor dos quais o pagamento é feito, aplica o valor das taxas, prepara o plano de postagem e o coloca no serviço Shumway. Este serviço é responsável por gerenciar informações sobre a movimentação de dinheiro nas contas dos participantes de uma transação ao efetuar um pagamento. O plano de lançamento contém a instrução "para congelar a possível movimentação de fundos nas contas dos participantes na transação especificada no plano";
- enriquece os dados de pagamento consultando serviços adicionais, por exemplo, na Binbase, a fim de descobrir o país do banco emissor que emitiu o cartão e seu tipo, por exemplo, “ouro, crédito”;
- chama o serviço do inspetor, como regra, é o Antifraud para receber a pontuação do pagamento e decidir sobre a escolha de um terminal que cubra o nível de risco emitido pela pontuação. Por exemplo, um terminal sem 3D-Secure pode ser usado para pagamentos de baixo risco, e um pagamento que recebeu um nível de risco fatal encerrará sua vida;
- chama o serviço de detecção de erros, o Detector de falhas e, com base nos dados recebidos, seleciona a rota de pagamento - o adaptador de protocolo do banco, que atualmente possui o menor número de erros e a maior probabilidade de pagamento bem-sucedido;
- envia uma solicitação ao adaptador de protocolo bancário selecionado, seja o adaptador YellowBank ", autorize a quantidade especificada desse token" nesse caso.
O adaptador de protocolo para o token recebido vai para o CDS, recebe os dados do cartão descriptografado, transfere-os para um protocolo específico do banco e, em geral, recebe autorização - confirmação do banco adquirente de que o montante indicado foi congelado na conta do pagador.
É nesse momento que você recebe um SMS com uma mensagem sobre o débito de fundos do seu cartão no seu banco, embora, na verdade, os fundos tenham sido congelados na sua conta.
O adaptador notifica HG da autorização bem-sucedida, seu código CVV é removido do serviço CDS e este é o fim do estágio de interação. A gerência retorna à HG.

Dependendo da chamada createPayment () especificada pelo comerciante do processo de negócios de pagamento, a HG espera chamadas da API externa para o método de captura de autorização, ou seja, confirmação da retirada de dinheiro do seu cartão ou imediatamente por conta própria, se o comerciante escolheu o esquema pagamento de estágio único.
Como regra, a maioria dos comerciantes usa um pagamento em uma etapa; no entanto, existem categorias de negócios que, no momento da autorização, ainda não sabem o valor total debitado. Isso geralmente acontece no setor de turismo quando você reserva uma excursão por um valor e, após confirmar a reserva, o valor é especificado e pode diferir daquele que foi autorizado no início.
Apesar do fato de que a quantidade de confirmação pode ser exclusivamente igual ou menor que a quantidade de autorização, existem armadilhas aqui. Imagine que você paga por um produto ou serviço de um cartão em uma moeda diferente da moeda da sua conta bancária à qual o cartão está vinculado.
No momento da autorização, o valor bloqueado na sua conta com base na taxa de câmbio no dia da autorização. Como o pagamento pode estar no status de "autorizado" (apesar de o Ministério das Ferrovias ter recomendações por um período máximo de 3 dias) por alguns dias, a captura da autorização será realizada na taxa do dia em que foi feita.
Assim, você assume riscos cambiais, que podem ser a seu favor e contra você, especialmente em uma situação de alta volatilidade no mercado de moedas.
Para capturar a autorização, o mesmo processo de comunicação com o adaptador de protocolo ocorre como para o recebimento e, se for bem-sucedido, o HG aplica o plano de lançamento da conta no Shumway e transfere o pagamento para o status "Pago". É neste momento que nós, como sistema de pagamento, temos obrigações financeiras com os participantes da transação.
Também é importante notar que quaisquer alterações no estado da máquina da fatura, que incluem o processo de pagamento, são registradas pelo Hellgate em Machinegun, garantindo a persistência dos dados e enriquecendo a fatura com novos eventos.
Sincronização de estado de uma máquina de pagamento e interface do usuário
Enquanto o processo de pagamento em segundo plano está ocorrendo dentro da plataforma, o Checkout realiza o processamento solicitando eventos. Após o recebimento de determinados eventos, ele desenha o estado atual do pagamento de uma maneira que seja compreensível para uma pessoa - desenha um pré-carregador, exibe a tela "Seu pagamento foi processado com sucesso" ou "O pagamento não foi recebido" ou redireciona o navegador para a página do seu banco emissor para inserir a senha 3D-Secure;
Se falhar, o Google Checkout oferecerá a você uma outra forma de pagamento ou tente novamente, iniciando um novo pagamento como parte da fatura.
Esse esquema com pesquisa de eventos torna possível restaurar o estado mesmo após o fechamento da guia do navegador - em caso de inicialização repetida, o Checkout receberá a lista atual de eventos e desenhará o cenário atual de interação do usuário, por exemplo, oferecerá a digitação do código 3D-Secure ou mostrará que o pagamento já foi concluído com êxito.
Replicação de eventos na zona offline
Juntamente com as interfaces de controle da máquina, a Machinegun implementa um serviço responsável pelo transbordamento do fluxo de eventos para serviços responsáveis por outras tarefas menos on-line da plataforma.
Como intermediário de filas nas finais, decidimos pelo Kafka, embora já tivéssemos implementado essa funcionalidade usando o próprio Machinegun. No caso geral, esse serviço é a preservação de um fluxo de eventos ordenado garantido ou a emissão de uma lista específica de eventos mediante solicitação a outros consumidores.
Também implementamos inicialmente um esquema de deduplicação de eventos, fornecendo garantias de que o mesmo evento não seria replicado duas vezes; no entanto, a carga no Riak, gerada por uma similar, nos fez recusá-lo - afinal, pesquisar por índices não é a melhor coisa Capacidade de armazenamento KV. Agora, cada consumidor de serviço é responsável pela deduplicação de eventos independentemente.
Em geral, a replicação de eventos pelo Machinegun termina com a confirmação do armazenamento de dados em Kafka, e os consumidores já estão conectados aos tópicos do Kafka e baixam as listas de eventos que lhes interessam.
Modelo de aplicativo típico da zona offline
Por exemplo, o serviço Dudoser é responsável por enviar uma notificação por email de um pagamento bem-sucedido. Na inicialização, ele elabora uma lista de eventos de pagamentos bem-sucedidos, pega informações sobre o endereço e o valor de lá, salva em uma instância local do PostgreSQL e a utiliza para processamento adicional da lógica de negócios.
Todos os outros serviços semelhantes operam de acordo com a mesma lógica, por exemplo, o serviço Magista, responsável pela pesquisa de faturas e pagamentos na conta pessoal do comerciante ou no serviço Hooker, que envia retornos de chamada assíncronos ao back-end para comerciantes que, por um motivo ou outro, não podem organizar eventos de pesquisa entrando em contato diretamente para a API de processamento.
Essa abordagem nos permite liberar a carga no processamento, alocando o máximo de recursos e fornecendo alta velocidade e disponibilidade do processamento de pagamentos, proporcionando alta conversão. Consultas pesadas como "clientes comerciais desejam ver as estatísticas de pagamentos do ano passado" são processadas por serviços que não afetam a carga atual da parte de processamento on-line e, portanto, não afetam você, como pagadores e comerciantes, como nossos clientes.
Talvez paremos nisso para não tornar o post muito longo. Em artigos futuros, definitivamente vou falar sobre as nuances de garantir a atomicidade de alterações, garantias e pedidos em um sistema distribuído carregado usando metralhadora, Bender, CAPI e Hellgate como exemplos.
Bem, sobre Salt Stack da próxima vez ¯\_(ツ)_/¯