Na
primeira parte do artigo, usando Ghidra, analisamos automaticamente um programa simples de crack (que baixamos do crackmes.one). Descobrimos como renomear funções "incompreensíveis" diretamente na listagem do descompilador e também entendemos o algoritmo do programa "de nível superior", ou seja, o que é feito por
main () .
Nesta parte, como prometi, faremos a análise da função
_construct_key () , que, como descobrimos, é responsável por ler o arquivo binário transferido para o programa e verificar os dados lidos.
Etapa 5 - Visão geral da função _construct_key ()
Vejamos a lista completa desta função imediatamente:
Listagem _construct_key ()char ** __cdecl _construct_key(FILE *param_1) { int iVar1; size_t sVar2; uint uVar3; uint local_3c; byte local_36; char local_35; int local_34; char *local_30 [4]; char *local_20; undefined4 local_19; undefined local_15; char **local_14; int local_10; local_14 = (char **)__prepare_key(); if (local_14 == (char **)0x0) { local_14 = (char **)0x0; } else { local_19 = 0; local_15 = 0; _text(&local_19,1,4,param_1); iVar1 = _text((char *)&local_19,*(char **)local_14[1],4); if (iVar1 == 0) { _text(local_14[1] + 4,2,1,param_1); _text(local_14[1] + 6,2,1,param_1); if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) { local_30[0] = *local_14; local_30[1] = *local_14 + 0x10c; local_30[2] = *local_14 + 0x218; local_30[3] = *local_14 + 0x324; local_20 = *local_14 + 0x430; local_10 = 0; while (local_10 < 5) { local_35 = 0; _text(&local_35,1,1,param_1); if (*local_30[local_10] != local_35) { _free_key(local_14); return (char **)0x0; } local_36 = 0; _text(&local_36,1,1,param_1); if (local_36 == 0) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x104) = (uint)local_36; _text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1); sVar2 = _text(local_30[local_10] + 1); if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) { _free_key(local_14); return (char **)0x0; } local_3c = 0; _text(&local_3c,1,1,param_1); local_3c = local_3c + 7; uVar3 = _text(param_1); if (local_3c < uVar3) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x108) = local_3c; _text(param_1,local_3c,0); local_10 = local_10 + 1; } local_34 = 0; _text(&local_34,4,1,param_1); if (*(int *)(*local_14 + 0x53c) == local_34) { _text("Markers seem to still exist"); } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } return local_14; }
Com esta função, faremos o mesmo que antes com
main () - para começar, revisaremos as chamadas de função "veladas". Como esperado, todas essas funções são das bibliotecas padrão C. Não descreverei o procedimento para renomear funções novamente - retorne à primeira parte do artigo, se necessário. Como resultado da renomeação, as seguintes funções padrão foram "encontradas":
- fread ()
- strncmp ()
- strlen ()
- ftell ()
- fseek ()
- puts ()
Renomeamos as funções de wrapper correspondentes em nosso código (aquelas que o descompilador escondeu por trás da palavra
_text ) adicionando o índice 2 (para que não houvesse confusão com as funções C originais). Quase todas essas funções são para trabalhar com fluxos de arquivos. Não é surpreendente - uma rápida olhada no código é suficiente para entender que ele lê sequencialmente dados de um arquivo (cujo descritor é passado para a função como o único parâmetro) e compara os dados lidos com uma certa matriz bidimensional de bytes
locais_14 .
Vamos supor que essa matriz contenha dados para verificação de chave. Chame, diga
key_array . Como o Hydra permite renomear não apenas funções, mas também variáveis, usaremos isso e renomearemos o incompreensível
local_14 em um
array de chaves mais compreensível. Isso é feito da mesma maneira que nas funções: através do menu do botão direito do mouse (
Renomear local ) ou pela tecla
L do teclado.
Portanto, imediatamente após a declaração das variáveis locais, uma certa função
_prepare_key () é
chamada :
key_array = (char **)__prepare_key(); if (key_array == (char **)0x0) { key_array = (char **)0x0; }
Voltaremos a
_prepare_key () , este é o terceiro nível de aninhamento em nossa hierarquia de chamadas:
main () -> _construct_key () -> _prepare_key () . Enquanto isso, aceitamos que ele crie e, de alguma forma, inicialize essa matriz bidimensional de "teste". E somente se esse array não estiver vazio, a função continuará seu trabalho, conforme evidenciado pelo bloco
else imediatamente após a condição acima.
Em seguida, o programa lê os 4 primeiros bytes do arquivo e o compara com a seção correspondente da matriz
key_array . (O código abaixo é após renomear, incluindo a variável
local_19, renomei first_4bytes .)
first_4bytes = 0; fread2(&first_4bytes,1,4,param_1); iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4); if (iVar1 == 0) { ... }
Assim, uma execução adicional ocorre apenas se os primeiros 4 bytes coincidirem (lembre-se disso). Em seguida, lemos 2 blocos de 2 bytes do arquivo (e a mesma
matriz_chave é usada como um buffer para gravar dados):
fread2(key_array[1] + 4,2,1,param_1); fread2(key_array[1] + 6,2,1,param_1);
E novamente - além disso, a função só funciona se a próxima condição for verdadeira:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
É fácil ver que o primeiro dos blocos de 2 bytes lidos acima deve ser o número 5 e o segundo o número 4 (o tipo de dados
curto ocupa apenas 2 bytes em plataformas de 32 bits).
Em seguida é o seguinte:
local_30[0] = *key_array;
Aqui vemos que a matriz
local_30 (declarada como char * local_30 [4]) contém os deslocamentos do ponteiro
key_array . Ou seja,
local_30 é uma matriz de linhas de marcador nas quais os dados do arquivo provavelmente serão lidos. Sob essa suposição,
renomei local_30 para
marcadores . Nesta seção do código, apenas a última linha parece um pouco suspeita, onde a atribuição do último deslocamento (no índice 0x430, ou seja, 1072) é executada não pelo próximo elemento de
marcadores , mas por uma variável
local_20 separada (
char * ). Mas vamos descobrir ainda, mas por enquanto - vamos seguir em frente!
Em seguida, aguardamos um ciclo:
i = 0;
I.e. Apenas 5 iterações de 0 a 4 inclusive. No loop, a leitura do arquivo e a verificação da conformidade com nossa matriz de
marcadores começam imediatamente:
char c_marker = 0;
Ou seja, o próximo byte do arquivo é lido na variável
c_marker (no código descompilado original -
local_35 ) e verificado quanto à conformidade com o primeiro caractere do i-ésimo elemento de
marcadores . No caso de uma incompatibilidade, a matriz
key_array é anulada e um ponteiro duplo vazio é retornado. Mais adiante, vemos que isso é feito sempre que os dados lidos não coincidem com os dados de verificação.
Mas aqui, como se costuma dizer, "o cachorro está enterrado". Vamos dar uma olhada neste ciclo. Possui 5 iterações, como descobrimos. Você pode verificar isso se quiser, olhando para o código do assembler:


De fato, o comando CMP compara o valor da variável
local_10 (já temos
i ) com o número 4 e se o valor for
menor ou igual a 4 (o comando JLE),
é feita a transição para o rótulo
LAB_004017eb , ou seja, início do corpo do ciclo. I.e. a condição será atendida para
i = 0, 1, 2, 3 e 4 - apenas 5 iterações! Tudo ficaria bem, mas os
marcadores também
são indexados por essa variável em um loop e, afinal, essa matriz é declarada com apenas 4 elementos:
char *markers [4];
Então, alguém está claramente tentando enganar alguém :) Lembra, eu disse que essa linha é duvidosa?
local_20 = *key_array + 0x430;
Assim mesmo! Basta olhar para toda a lista da função e tentar encontrar pelo menos mais uma referência à variável
local_20 . Ela não está lá! Concluímos a partir disso: esse deslocamento também deve ser armazenado na matriz de
marcadores , e a própria matriz deve conter 5 elementos. Vamos consertar. Vá para a declaração da variável,
pressione Ctrl + L (Redigitar variável) e altere com ousadia o tamanho da matriz para 5:
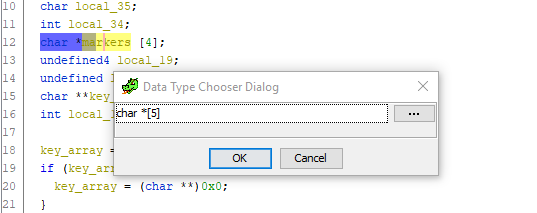
Feito. Role para baixo até o código para atribuir deslocamentos do ponteiro aos
marcadores e - e eis! - uma variável extra incompreensível desaparece e tudo se encaixa:
markers[0] = *key_array; markers[1] = *key_array + 0x10c; markers[2] = *key_array + 0x218; markers[3] = *key_array + 0x324; markers[4] = *key_array + 0x430;
Retornamos ao nosso
loop while (no código-fonte, provavelmente será, mas não nos importamos). Em seguida, o byte do arquivo é lido novamente e seu valor é verificado:
byte n_strlen1 = 0;
OK, este
n_strlen1 deve ser diferente de zero. Porque Você verá agora, mas ao mesmo tempo entenderá por que dei a essa variável o seguinte nome:
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1; fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1); n_strlen2 = strlen2(markers[i] + 1);
Eu adicionei comentários sobre os quais tudo deve ficar claro.
N_strlen1 bytes são lidos a partir do arquivo e salvos como uma sequência de caracteres (isto é, uma string) na matriz de
marcadores [i] - ou seja, após o correspondente "símbolo de parada", que já está escrito a partir de
key_array . Salvar o valor
n_strlen1 nos
marcadores [i] no deslocamento 0x104 (260) não desempenha nenhum papel aqui (consulte a primeira linha no código acima). De fato, esse código pode ser otimizado da seguinte maneira (e certamente este é o caso no código fonte):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1); n_strlen2 = strlen2(markers[i] + 1); if (n_strlen2 != (size_t) n_strlen1) { ... }
Ele também verifica se o comprimento da linha de leitura é
n_strlen1 . Isso pode parecer desnecessário, pois esse parâmetro foi passado para a função
fread , mas o
fread lê
não mais do que muitos bytes especificados e pode ler menos do que o indicado, por exemplo, no caso de atender ao marcador de fim de arquivo (EOF). Ou seja, tudo é rigoroso: o comprimento da linha (em bytes) é indicado no arquivo e, em seguida, a própria linha segue - e exatamente 5 vezes. Mas estamos nos adiantando.
Águas adicionais este código (que eu também comentei imediatamente):
uint n_pos = 0;
Ainda é mais simples aqui: pegamos o próximo byte do arquivo, adicionamos 7 e comparamos o valor resultante com a posição atual do cursor no fluxo de arquivos obtido pela função
ftell () . O valor de
n_pos não deve ser menor que a posição do cursor (ou seja, deslocamento em bytes desde o início do arquivo).
A linha final do loop:
fseek2(param_1,n_pos,0);
I.e. reorganize o cursor do arquivo (desde o início) para a posição indicada por
n_pos pela função
fseek () . OK, fazemos todas essas operações no loop 5 vezes. A função
_construct_key () termina com o seguinte código:
int i_lastmarker = 0;
Portanto, o último bloco de dados no arquivo deve ser um valor inteiro de 4 bytes e deve ser igual ao valor na
matriz_chave [0] [1340] . Nesse caso, receberemos uma mensagem de felicitações no console. Caso contrário, a matriz vazia ainda retorna sem elogios :)
Etapa 6 - Visão geral da função __prepare_key ()
Só temos uma função desmontada -
__prepare_key () . Já imaginamos que é nele que os dados de verificação são gerados no formato da matriz
key_array , que é usada na função
_construct_key () para verificar os dados do arquivo. Resta descobrir que tipo de dados lá!
Não analisarei essa função em detalhes e imediatamente darei uma lista completa com comentários depois de toda a renomeação necessária de variáveis:
Lista de funções __Prepare_key () void ** __prepare_key(void) { void **key_array; void *pvVar1; key_array = (void **)calloc2(1,8); if (key_array == (void **)0x0) { key_array = (void **)0x0; } else { pvVar1 = calloc2(1,0x540); *key_array = pvVar1; pvVar1 = calloc2(1,8); key_array[1] = pvVar1; *(undefined4 *)key_array[1] = 0x404024; *(undefined2 *)((int)key_array[1] + 4) = 5; *(undefined2 *)((int)key_array[1] + 6) = 4; *(undefined *)*key_array = 0x62; *(undefined4 *)((int)*key_array + 0x104) = 3; *(undefined *)((int)*key_array + 0x218) = 0x57; *(undefined *)((int)*key_array + 0x324) = 0x70; *(undefined *)((int)*key_array + 0x10c) = 0x6c; *(undefined *)((int)*key_array + 0x430) = 0x98; *(undefined4 *)((int)*key_array + 0x53c) = 0x462; } return key_array; }
O único lugar que vale a pena considerar é esta linha:
*(undefined4 *)key_array[1] = 0x404024;
Como eu entendo que aqui está a linha "VOID"? O fato é que 0x404024 é o endereço no espaço de endereço do programa que leva à seção
.rdata . Clicar duas vezes nesse valor nos permite ver claramente o que existe:

A propósito, o mesmo pode ser entendido no código do assembler para esta linha:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
Os dados correspondentes à linha VOID estão no início da seção
.rdata (no deslocamento zero do endereço correspondente).
Portanto, na saída dessa função, uma matriz bidimensional deve ser formada com os seguintes dados:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Etapa 7 - Prepare o binário para o crack
Agora podemos começar a síntese do arquivo binário. Todos os dados iniciais em nossas mãos:
1) dados de verificação (“símbolos de parada”) e suas posições na matriz de verificação;
2) a sequência de dados no arquivo
Vamos restaurar a estrutura do arquivo que estamos procurando, de acordo com o algoritmo da função
_construct_key () . Portanto, a sequência de dados no arquivo será a seguinte:
Estrutura de arquivo- 4 bytes == matriz_chave [1] [0 ... 3] == "VOID"
- 2 bytes == matriz_chave [1] [4] == 5
- 2 bytes == matriz_chave [1] [6] == 4
- 1 byte == matriz_chave [0] [0] == 'b' (token)
- 1 byte == (comprimento da próxima linha) == n_strlen1
- n_strlen1 bytes == (qualquer sequência) == n_strlen1
- 1 byte == (+7 == próximo token) == n_pos
- 1 byte == matriz_chave [0] [0] == 'l' (token)
- 1 byte == (comprimento da próxima linha) == n_strlen1
- n_strlen1 bytes == (qualquer sequência) == n_strlen1
- 1 byte == (+7 == próximo token) == n_pos
- 1 byte == matriz_chave [0] [0] == 'W' (token)
- 1 byte == (comprimento da próxima linha) == n_strlen1
- n_strlen1 bytes == (qualquer sequência) == n_strlen1
- 1 byte == (+7 == próximo token) == n_pos
- 1 byte == matriz_chave [0] [0] == 'p' (token)
- 1 byte == (comprimento da próxima linha) == n_strlen1
- n_strlen1 bytes == (qualquer sequência) == n_strlen1
- 1 byte == (+7 == próximo token) == n_pos
- 1 byte == matriz_chave [0] [0] == 152 (token)
- 1 byte == (comprimento da próxima linha) == n_strlen1
- n_strlen1 bytes == (qualquer sequência) == n_strlen1
- 1 byte == (+7 == próximo token) == n_pos
- 4 bytes == (matriz_chave [1340]) == 1122
Para maior clareza, criei no Excel um tablet com os dados do arquivo desejado:

Aqui na 7ª linha - os próprios dados na forma de caracteres e números, na 6ª linha - suas representações hexadecimais, na 8ª linha - o tamanho de cada elemento (em bytes), na 9ª linha - o deslocamento relativo ao início do arquivo. Essa visão é muito conveniente porque permite que você insira qualquer linha no arquivo futuro (marcado com um preenchimento amarelo), enquanto os valores dos comprimentos dessas linhas, bem como os desvios de posição do próximo símbolo de parada, são calculados automaticamente por fórmulas, conforme o algoritmo do programa. Acima (nas linhas 1 a 4), a estrutura da matriz de verificação
key_array é
mostrada .
O excel em si e outros materiais de origem do artigo podem ser baixados
aqui .
Geração e validação de arquivos binários
A única coisa que resta é gerar o arquivo desejado em formato binário e alimentá-lo com o nosso crack. Para gerar o arquivo, escrevi um script Python simples:
Script para gerar o arquivo import sys, os import struct import subprocess out_str = ['!', 'I', ' solved', ' this', ' crackme!'] def write_file(file_path): try: with open(file_path, 'wb') as outfile: outfile.write('VOID'.encode('ascii')) outfile.write(struct.pack('2h', 5, 4)) outfile.write('b'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[0]))) outfile.write(out_str[0].encode('ascii')) pos = 10 + len(out_str[0]) outfile.write(struct.pack('B', pos - 6)) outfile.write('l'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[1]))) outfile.write(out_str[1].encode('ascii')) pos += 3 + len(out_str[1]) outfile.write(struct.pack('B', pos - 6)) outfile.write('W'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[2]))) outfile.write(out_str[2].encode('ascii')) pos += 3 + len(out_str[2]) outfile.write(struct.pack('B', pos - 6)) outfile.write('p'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[3]))) outfile.write(out_str[3].encode('ascii')) pos += 3 + len(out_str[3]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('B', 152)) outfile.write(struct.pack('B', len(out_str[4]))) outfile.write(out_str[4].encode('ascii')) pos += 3 + len(out_str[4]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('i', 1122)) except Exception as err: print(err) raise def main(): if len(sys.argv) != 2: print('USAGE: {this_script.py} path_to_crackme[.exe]') return if not os.path.isfile(sys.argv[1]): print('File "{}" unavailable!'.format(sys.argv[1])) return file_path = os.path.splitext(sys.argv[1])[0] + '.dat' try: write_file(file_path) except: return try: outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT) print(outputstr.decode('utf-8')) except Exception as err: print(err) if __name__ == '__main__': main()
O script leva o caminho para as rachaduras como um único parâmetro, depois gera um arquivo binário com a chave no mesmo diretório e chama as rachaduras com o parâmetro correspondente, traduzindo a saída do programa para o console.
Para converter dados de texto em binários, use o pacote
struct . O método
pack () permite gravar dados binários em um formato que indica o tipo de dados ("B" = "byte", "i" = int etc.) e também é possível especificar a sequência (">" = "Big -endian "," <"=" Little-endian "). O pedido padrão é Little-endian. Porque como já determinamos no primeiro artigo que esse é exatamente o nosso caso, indicamos apenas o tipo.
Todo o código como um todo reproduz o algoritmo do programa que encontramos. Como a linha a ser impressa se for bem-sucedida, especifiquei "Solucionei esse crackme!" (você pode modificar esse script para que seja possível especificar qualquer linha).
Verifique a saída:

Viva, tudo funciona! Assim, suando um pouco e resolvendo algumas funções, fomos capazes de restaurar completamente o algoritmo do programa e "decifrá-lo". Obviamente, isso é apenas uma simples rachadura, um programa de teste e até o segundo nível de dificuldade (dos 5 oferecidos nesse site). Na realidade, lidaremos com uma hierarquia complexa de chamadas e dezenas - centenas de funções e, em alguns casos - seções criptografadas de dados, código de lixo e outras técnicas de ofuscação, até o uso de máquinas virtuais internas e código P ... Mas isso, como dizem, já está uma história completamente diferente.
Materiais para o artigo.