Continuando a considerar as tecnologias para acelerar as operações de E / S aplicadas aos sistemas de armazenamento, iniciadas no artigo anterior , não se pode deixar de se debruçar sobre uma opção tão popular como a classificação automática de níveis. Embora a ideologia dessa função seja muito próxima da de vários fabricantes de sistemas de armazenamento, consideraremos os recursos de implementação rasgável usando o exemplo de armazenamento Qsan .
Apesar da variedade de dados armazenados no sistema de armazenamento, esses mesmos dados podem ser divididos em vários grupos com base em sua relevância (frequência de uso). Os dados mais populares ("quentes") são extremamente importantes para organizar o acesso mais rápido, enquanto o processamento de dados menos populares ("frios") pode ser realizado com uma prioridade mais baixa.
Para organizar esse esquema, é utilizada a funcionalidade de rasgo. A matriz de dados nesse caso não consiste no mesmo tipo de discos, mas em vários grupos de unidades que formam diferentes níveis de armazenamento em camadas. Usando um algoritmo especial, os dados são movidos automaticamente entre os níveis para garantir o máximo desempenho final.
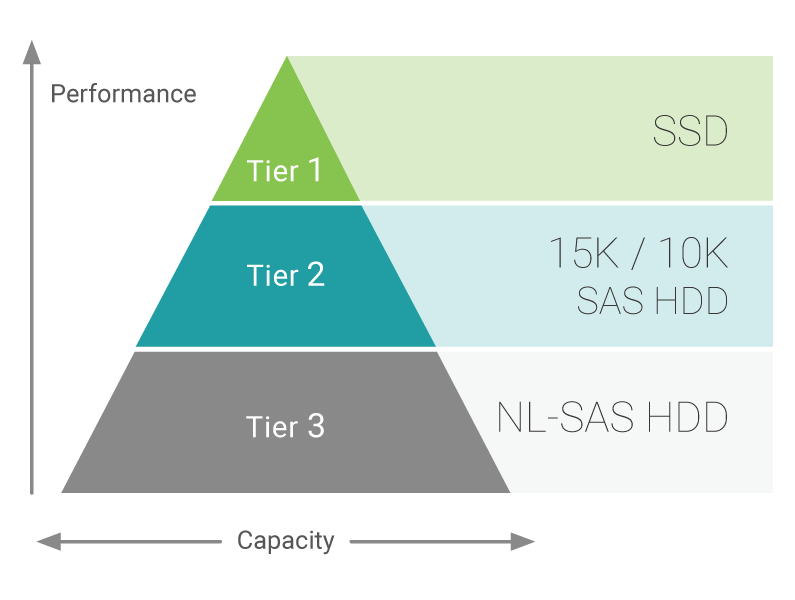
Os sistemas de armazenamento Qsan suportam até três camadas de armazenamento:
- Nível 1: desempenho máximo do SSD
- Nível 2: HDD SAS 10K / 15K, alto desempenho
- Nível 3: HDD NL-SAS 7.2K, capacidade máxima
O pool de classificação automática por níveis pode conter os três níveis e apenas dois em qualquer combinação. Dentro de cada camada, as unidades são combinadas em grupos RAID familiares. Para máxima flexibilidade, o nível RAID em cada camada pode ser diferente. Ou seja, por exemplo, nada impede que você organize uma estrutura como 4x SSD RAID10 + 6x HDD 10K RAID5 + 12 HDD 7.2K RAID6
Depois de criar volumes (discos virtuais) no pool de Camadas automáticas , a coleção de estatísticas em segundo plano em todas as operações de E / S é iniciada. Para fazer isso, o espaço é "cortado" em blocos de 1 GB (o chamado sub LUN). Cada vez que você acessa esse bloco, recebe um coeficiente 1. Em seguida, com o tempo, esse coeficiente diminui. Após 24 horas, na ausência de solicitações de entrada / saída para esta unidade, ela já será igual a 0,5 e continuará a cair após cada hora subsequente.
Em um determinado momento (por padrão, todos os dias à meia-noite), os resultados coletados são classificados por atividade de sub LUN com base em seus coeficientes. Com base nisso, é tomada uma decisão sobre quais blocos se mover e em qual direção. Após o qual, de fato, há uma realocação de dados entre os níveis.
O sistema de armazenamento Qsan implementa perfeitamente o controle do processo de rompimento usando uma variedade de parâmetros, o que permitirá que você configure com muita flexibilidade o desempenho final da matriz.
Para determinar a localização inicial dos dados e a direção prioritária de seus movimentos, são usadas políticas definidas separadamente para cada volume:
- Classificação automática por níveis - a política padrão, o posicionamento inicial e a direção dos movimentos são determinados automaticamente, ou seja, Os dados "quentes" tendem ao nível mais alto e os dados "frios" diminuem. O posicionamento inicial é selecionado com base no espaço disponível em cada nível. Mas você precisa entender que o sistema visa principalmente maximizar o uso das unidades mais rápidas. Portanto, se houver espaço livre, os dados serão colocados nos níveis superiores. Essa política é adequada para a maioria dos cenários em que a demanda de dados não pode ser prevista com antecedência.
- Comece alto e depois em níveis automáticos - a diferença em relação ao anterior é apenas no local dos dados originais (no nível mais rápido)
- O nível mais alto - os dados sempre se esforçam para ocupar o nível mais rápido. Se no processo eles forem movidos para baixo, o mais rápido possível eles serão movidos de volta. Esta política é adequada para dados que requerem o acesso mais rápido.
- Nível mínimo - os dados sempre se esforçam para ocupar o nível mais baixo. Essa política é perfeita para dados raramente usados (por exemplo, arquivos).
- Sem movimento - o sistema determina automaticamente a localização inicial dos dados e não os move. No entanto, as estatísticas continuam sendo coletadas caso sua realocação seja necessária posteriormente.
Vale ressaltar que, apesar de as políticas serem definidas ao criar cada volume, elas podem ser alteradas repetidamente durante o ciclo de vida do sistema.
Além das políticas para o mecanismo de lacrimejamento, a frequência e o ritmo da movimentação de dados entre níveis também são configurados. Você pode definir um horário específico de movimentação: diariamente ou em determinados dias da semana, além de reduzir o intervalo de coleta de estatísticas para várias horas (a frequência mínima é de 2 horas). Se for necessário limitar o tempo de execução da operação de movimentação de dados, você pode definir o período (janela para movimentação). Além disso, a velocidade de realocação também é indicada - 3 modos: rápido, médio e lento.
No caso de necessidade de realocação imediata de dados, é possível executá-lo no modo manual a qualquer momento, sob o comando do administrador.
É claro que quanto mais rápido e mais rápido os dados forem movidos entre os níveis, mais flexível o sistema de armazenamento se adaptará às condições operacionais atuais. Mas, ao mesmo tempo, vale lembrar que a movimentação é uma carga adicional (principalmente em discos), portanto, não há necessidade de "conduzir" os dados sem extrema necessidade. É melhor planejar o movimento para momentos de carga mínima. Se o trabalho de armazenamento exigir constantemente alto desempenho 24/7, vale a pena reduzir ao mínimo a taxa de realocação.
A abundância de configurações de rasgo sem dúvida agradará aos usuários avançados. No entanto, para aqueles que se deparam com essa tecnologia pela primeira vez, não há nada com que se preocupar. É bem possível confiar nas configurações padrão (política de classificação automática de níveis, movendo-se na velocidade máxima uma vez por dia à noite) e, conforme as estatísticas se acumulam, ajustar certos parâmetros para alcançar o resultado desejado.
Comparando o peering com uma tecnologia não menos popular para aumentar o desempenho como o cache de SSD , deve-se ter em mente os diferentes princípios de seus algoritmos.
| Armazenamento em cache SSD | Classificação automática por níveis |
|---|
| Taxa de início do efeito | Quase instantaneamente. Mas um efeito perceptível somente depois que o cache "aquece" (minutos-horas) | Depois de coletar estatísticas (de 2 horas, idealmente por dia), mais o tempo para mover os dados |
| Duração do efeito | Até que os dados sejam substituídos por uma nova parte (minutos-horas) | Embora a demanda por dados seja relevante (dia ou mais) |
| Indicações de uso | Aumente instantaneamente a produtividade por um curto período de tempo (bancos de dados, ambientes de virtualização) | Maior produtividade por um longo período (arquivos, web, servidores de correio) |
Também um dos recursos do rasgamento é a capacidade de usá-lo não apenas em cenários como "SSD + HDD", mas também "HDD rápido + HDD lento" ou todos os três níveis em geral, o que é impossível em princípio ao usar o cache do SSD.
Teste
Para testar a operação de algoritmos de rasgo, realizamos um teste simples. Um conjunto de dois níveis de SSD (RAID 1) + HDD 7.2K (RAID1) foi criado, no qual o volume com a diretiva "nível mínimo" foi colocado. I.e. os dados sempre devem estar localizados em discos lentos.
A interface de controle mostra claramente a localização dos dados entre os níveis
Depois de preencher o volume com dados, alteramos a política de posicionamento para Camadas automáticas e executamos o teste do IOmeter.
Após várias horas de teste, quando o sistema conseguiu acumular estatísticas, o processo de realocação começou.
No final da movimentação de dados, nosso volume de teste foi totalmente rastreado para o nível superior (SSD).
O veredicto
A classificação automática de níveis é uma tecnologia maravilhosa que permite aumentar a produtividade do sistema de armazenamento com o mínimo de custos de material e tempo, devido ao uso mais intensivo de unidades de alta velocidade. No que diz respeito à Qsan, o único investimento é uma licença, adquirida de uma vez por todas, sem limitação no volume / número de discos / prateleiras / etc. Essa funcionalidade é equipada com configurações tão avançadas que podem satisfazer quase todas as tarefas de negócios. E a visualização de processos na interface permitirá gerenciar efetivamente o dispositivo.