
Em 28 de fevereiro, fiz uma apresentação no SphinxSearch-meetup , realizado em nosso escritório. Ele falou sobre como viemos da reconstrução regular de índices para pesquisa de texto completo e do envio de atualizações no código "no local" para índices de tempo de trilho e sincronização automática do estado do índice e do banco de dados MariaDB. Uma gravação de vídeo do meu relatório está disponível no link e, para quem prefere ler a assistir ao vídeo, escrevi este artigo.
Começarei com a organização de nossa pesquisa e por que começamos tudo isso.
Nossa busca foi organizada de acordo com um esquema completamente padrão.
Do front end, as solicitações do usuário chegam ao servidor de aplicativos escrito em PHP e ele, por sua vez, se comunica com o banco de dados (temos o MariaDB). Se precisarmos fazer uma pesquisa, o servidor de aplicativos se volta para o balanceador (temos haproxy), que o conecta a um dos servidores em que o searchd está em execução, e esse servidor já realiza uma pesquisa e retorna o resultado.
Os dados do banco de dados entram no índice de uma maneira bastante tradicional: de acordo com a programação, reconstruímos o índice a cada poucos minutos com os documentos atualizados recentemente, e reconstruímos o índice com os chamados documentos "arquivados" (ou seja, aqueles com os quais Durante muito tempo, nada aconteceu). Existem algumas máquinas alocadas para indexação, um script é executado em uma programação, que primeiro cria o índice, renomeia os arquivos de índice de uma maneira especial e, em seguida, coloca-os em uma pasta separada. E em cada um dos servidores com searchd, o rsync é iniciado uma vez por minuto, que copia arquivos dessa pasta para a pasta searchd indexes e, se algo tiver sido copiado, ele executa a solicitação RELOAD INDEX.
No entanto, para algumas alterações nos currículos e nas vagas, era necessário que eles "alcançassem" o índice o mais rápido possível. Por exemplo, se uma vaga publicada em domínio público for removida da publicação, é razoável esperar, do ponto de vista do usuário, que ela desapareça do problema em alguns segundos, não mais. Portanto, esses tipos de alterações são enviadas diretamente via searchd usando consultas UPDATE. E, para que essas alterações sejam aplicadas a todas as cópias de índices em todos os nossos servidores, um índice distribuído é configurado em cada pesquisa, que envia atualizações de atributos para todas as instâncias da pesquisa. O servidor de aplicativos ainda se conecta ao balanceador e envia uma solicitação para atualizar o índice distribuído; portanto, ele não precisa conhecer antecipadamente a lista de servidores com searchd, nem chegará exatamente a qual servidor com searchd.
Tudo isso funcionou muito bem, mas houve problemas.
- O atraso médio entre a criação do documento (temos este currículo ou vaga) e sua entrada no índice foi diretamente proporcional ao seu número em nosso banco de dados.
- Como usamos o índice distribuído para distribuir atualizações de atributos, não tínhamos garantia de que essas atualizações fossem aplicadas a todas as cópias do índice.
- As alterações "urgentes" que ocorreram durante a reconstrução do índice foram perdidas quando o comando
RELOAD INDEX foi executado (simplesmente porque ainda não estavam no índice recém-construído) e só entraram no índice após a próxima reindexação. 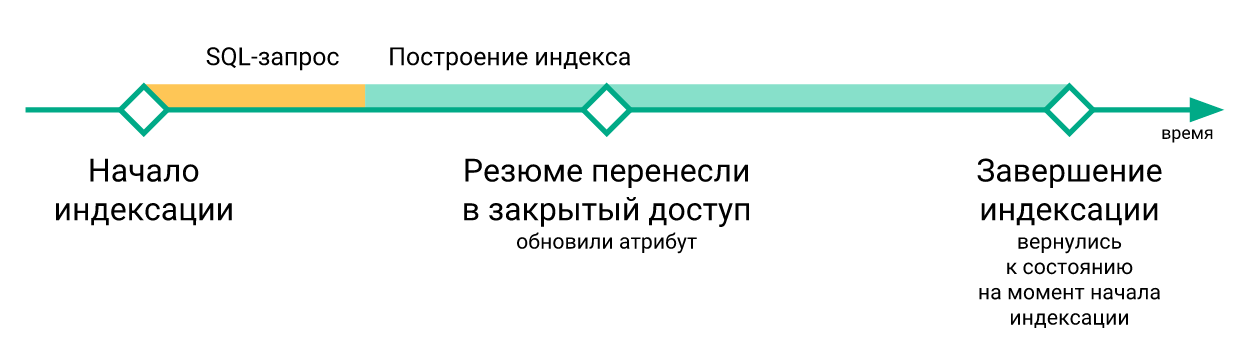
- Os scripts para atualização de índices nos servidores com searchd foram executados independentemente um do outro, não houve sincronização entre eles. Por esse motivo, o atraso entre a atualização do índice em diferentes servidores pode chegar a vários minutos.
- Se fosse necessário testar algo relacionado à pesquisa, era necessário recriar o índice após cada alteração.
Cada um desses problemas separadamente não valia a pena retrabalhar a infra-estrutura de busca, mas, juntos, eles estragavam a vida de maneira bastante tangível.
Decidimos lidar com os problemas acima usando os índices em tempo real do Sphinx. Além disso, a transição para os índices de RT não foi suficiente para nós. Para finalmente se livrar de qualquer corrida de dados, era necessário garantir que todas as atualizações do aplicativo no índice passassem pelo mesmo canal. Além disso, era necessário salvar em algum lugar as alterações feitas no banco de dados enquanto o índice estava sendo reconstruído (porque, afinal, às vezes é necessário reconstruí-lo, mas o procedimento não é instantâneo).
Decidimos fazer a conexão usando o protocolo de replicação do MySQL como um canal de transferência de dados, e o binlog do MySQL é o local para salvar as alterações durante a reconstrução do índice. Essa solução nos permitiu livrar da escrita no Sphinx a partir do código do aplicativo. E como já tínhamos usado a replicação baseada em linha com um ID de transação global naquele momento, a alternância entre réplicas de banco de dados poderia ser feita de maneira bastante simples.
A ideia de conectar-se diretamente ao banco de dados para obter alterações de lá para enviar para o índice, é claro, não é nova: em 2016, colegas da Avito fizeram uma apresentação onde descreveram detalhadamente como resolveram o problema de sincronizar dados no Sphinx com o banco de dados principal. Decidimos usar a experiência deles e criar um sistema semelhante para nós mesmos, com a diferença de que não possuímos o PostgreSQL, mas o MariaDB e o antigo ramo do Sphinx (versão 2.3.2).
Fizemos um serviço que assina as alterações no MariaDB e atualiza o índice no Sphinx. Suas responsabilidades são as seguintes:
- conexão com o servidor MariaDB via protocolo de replicação e recebimento de eventos do binlog;
- rastreando a posição atual do binlog e o número da última transação concluída;
- filtrando eventos de binlog;
- descobrir quais documentos precisam ser adicionados, excluídos ou atualizados no índice e para documentos atualizados - quais campos precisam ser atualizados;
- solicitação de dados ausentes do MariaDB;
- geração e execução de solicitações de atualização de índice;
- reconstruindo o índice, se necessário.
Fizemos uma conexão usando o protocolo de replicação usando a biblioteca go-mysql . Ela é responsável por estabelecer uma conexão com o MariaDB, ler eventos de replicação e passá-los para um manipulador. Esse manipulador começa na goroutine, que é controlada pela biblioteca, mas nós mesmos escrevemos o código do manipulador. No código do manipulador, os eventos são verificados com uma lista de tabelas que nos interessam e as alterações nessas tabelas são enviadas para processamento. Nosso manipulador também armazena o status da transação. Isso ocorre porque os eventos no protocolo de replicação estão em ordem: GTID (início da transação) -> ROW (alteração de dados) -> XID (fim da transação), e apenas o primeiro deles contém informações sobre o número da transação. É mais conveniente transferir o número da transação juntamente com sua conclusão, a fim de salvar informações sobre em que posição no binlog as alterações foram aplicadas e, para isso, precisamos lembrar o número da transação atual entre o início e a conclusão.
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+
Nós salvamos o número da última transação concluída em um índice especial de um documento em cada servidor com searchd. No início do serviço, verificamos que os índices foram inicializados e possuem a estrutura esperada, além de que a posição salva em todos os servidores esteja presente e a mesma em todos os servidores. Então, se essas verificações foram bem-sucedidas e conseguimos iniciar a leitura do binlog a partir da posição salva, iniciamos o procedimento de sincronização. Se as verificações falharem ou não foi possível começar a ler o binlog da posição salva, redefinimos a posição salva para a posição atual do servidor MariaDB e reconstruímos o índice.
O processamento de eventos de replicação começa determinando quais documentos são afetados por uma alteração específica no banco de dados. Para fazer isso, na configuração do nosso serviço, fizemos algo como rotear para eventos de alteração de linha nas tabelas de nosso interesse, ou seja, um conjunto de regras para determinar como as alterações no banco de dados devem ser indexadas.
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"]
Por exemplo, com este conjunto de regras, as alterações vacancy_metro_station vacancy , vacancy_language e vacancy_metro_station devem estar no índice de vacancy . O número do documento pode ser obtido no campo de id da tabela de vacancy e no campo vacancy_id das outras duas tabelas. O campo column_map é uma tabela da dependência dos campos de índice nos campos de diferentes tabelas de banco de dados.
Além disso, quando recebemos a lista de documentos afetados pelas alterações, precisamos atualizá-los no índice, mas não o fazemos imediatamente. Primeiro, acumulamos alterações para cada documento e enviamos as alterações para o índice assim que um curto período de tempo (temos 100 milissegundos) desde a última alteração deste documento.
Decidimos fazer isso para evitar muitas atualizações desnecessárias de índice, porque em muitos casos ocorre uma única alteração lógica em um documento com a ajuda de várias consultas SQL que afetam tabelas diferentes e, às vezes, são executadas em transações completamente diferentes.
Vou dar um exemplo simples. Suponha que um usuário tenha editado uma vaga. O código responsável por salvar as alterações geralmente é escrito para simplificar aproximadamente desta maneira:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT;
Em outras palavras, primeiro todos os registros antigos são excluídos das tabelas vinculadas e, em seguida, novos são inseridos. Ao mesmo tempo, ainda haverá entradas no binlog sobre essas exclusões e inserções, mesmo que nada tenha sido alterado no documento.
Para atualizar apenas o necessário, fizemos o seguinte: classifique as linhas alteradas para que, para cada par de documentos de índice, todas as alterações possam ser recuperadas em ordem cronológica. Em seguida, podemos aplicá-los, por sua vez, para determinar quais campos em que tabelas foram alteradas e quais não são. Depois disso, podemos usar a tabela column_map obter uma lista de campos e atributos de índice que precisam ser atualizados para cada documento afetado. Além disso, os eventos relacionados a um documento podem não chegar um após o outro, mas como se fossem “diferentes” se forem executados em transações diferentes. Mas, em nossa capacidade de determinar quais documentos foram alterados, isso não afetará.
Ao mesmo tempo, essa abordagem nos permitiu atualizar apenas os atributos do índice, se não houvesse alterações nos campos de texto, além de combinar o envio de alterações ao Sphinx.
Portanto, agora podemos descobrir quais documentos precisam ser atualizados no índice.
Em muitos casos, os dados do binlog não são suficientes para criar uma solicitação para atualizar o índice; portanto, obtemos os dados ausentes no mesmo servidor onde lemos o binlog. Para isso, existe um modelo de solicitação para recebimento de dados na configuração do nosso serviço.
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
Neste modelo, todos os campos são marcados com aliases especiais: [___]:___ .
É usado na formação de uma solicitação para receber os dados ausentes e na construção do índice (mais sobre isso posteriormente).
Nós formamos uma solicitação deste tipo:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id
Em seguida, para cada documento, verificamos se é o resultado dessa solicitação. Caso contrário, significa que foi excluído da tabela principal e, portanto, também pode ser excluído do índice (executamos a consulta DELETE para este documento). Se for, verifique se precisamos atualizar os campos de texto para este documento. Se os campos de texto não precisarem ser atualizados, faremos uma consulta UPDATE para este documento, caso contrário, REPLACE .
Vale a pena observar aqui que a lógica de manter a posição a partir da qual você pode começar a ler o binlog em caso de falhas tinha que ser complicada, porque agora é possível uma situação em que não aplicamos todas as alterações lidas no binlog.
Para retomar a leitura do binlog funcionando corretamente, fizemos o seguinte: para cada evento de alteração de linha no banco de dados, lembre-se do ID da última transação concluída no momento em que esse evento ocorreu. Depois de enviar as alterações para o Sphinx, atualizamos o número da transação a partir do qual você pode começar a ler com segurança, como a seguir. Se não processamos todas as alterações acumuladas (porque alguns documentos não foram "rastreados" na fila), obteremos o número da transação mais antiga das relacionadas às alterações que ainda não conseguimos aplicar. E se aplicamos todas as alterações acumuladas, pegamos o número da última transação concluída.
O que aconteceu como resultado foi bom para nós, mas havia um ponto mais importante: para que o desempenho do índice em tempo real permanecesse em um nível aceitável ao longo do tempo, era necessário que o tamanho e o número de "pedaços" desse índice permanecessem pequenos. Para fazer isso, o Sphinx possui uma solicitação FLUSH RAMCHUNK , que FLUSH RAMCHUNK um novo bloco de disco, e uma solicitação OPTIMIZE INDEX , que mescla todos os blocos de disco em um. Inicialmente, pensávamos que o executaríamos periodicamente e isso é tudo. Infelizmente, porém, verificou-se que na versão 2.3.2 OPTIMIZE INDEX não funciona (ou seja, com uma probabilidade bastante alta leva a uma queda na pesquisad). Portanto, decidimos apenas uma vez por dia recriar completamente o índice, especialmente porque de tempos em tempos ainda precisamos fazê-lo (por exemplo, se o esquema do índice ou as configurações do tokenizer mudarem).
O procedimento para reconstruir o índice ocorre em várias etapas.
Geramos uma configuração para indexador
Como mencionado acima, há um modelo de consulta SQL na configuração do serviço. Também é usado para formar a configuração do indexador.
Também na configuração, existem outras configurações necessárias para criar o índice (configurações do tokenizer, dicionários, várias restrições ao consumo de recursos).
Salve a posição atual do MariaDB
A partir dessa posição, começaremos a ler o binlog, depois que o novo índice estiver disponível em todos os servidores com searchd.
Começamos o indexador
indexer --config tmp.vacancy.indexer.0.conf --all comandos do indexer --config tmp.vacancy.indexer.0.conf --all formulários indexer --config tmp.vacancy.indexer.0.conf --all e aguardamos sua conclusão. Além disso, se o índice for dividido em partes, iniciaremos a construção de todas as partes em paralelo.
Carregamos arquivos de índice em servidores
O download para cada servidor também ocorre em paralelo, mas naturalmente esperamos até que todos os arquivos sejam carregados em todos os servidores. Para baixar arquivos na configuração do serviço, há uma seção com um modelo de comando para baixar arquivos.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
Para cada servidor, simplesmente substituímos seu nome na variável Host e executamos o comando resultante. Usamos o rsync para download, mas, em princípio, qualquer programa ou script que aceite uma lista de arquivos no stdin e faça o download desses arquivos para a pasta em que o searchd espera ver os arquivos de índice o fará.
Paramos a sincronização
Paramos de ler o binlog, paramos a goroutine responsável pelo acúmulo de alterações.
Substitua o índice antigo por um novo
Para cada servidor com searchd, fazemos consultas seqüenciais RELOAD INDEX vacancy_plain , TRUNCATE INDEX vacancy_plain , ATTACH INDEX vacancy_plain TO vacancy . Se o índice for dividido em partes, executamos essas consultas para cada parte sequencialmente. Ao mesmo tempo, se estivermos em um ambiente de produção, antes de executar essas consultas em qualquer servidor, removeremos a carga dele através do balanceador (para que ninguém faça consultas SELECT aos índices entre TRUNCATE e ATTACH ), e assim que Quando a última solicitação ATTACH for concluída, retornamos a carga para este servidor.
Reiniciando a sincronização a partir de uma posição salva
Assim que substituímos todos os índices em tempo real pelos recém-construídos, retomamos a leitura do binlog e sincronizamos eventos do binlog, começando pela posição que salvamos antes do início da indexação.
Aqui está um exemplo de um gráfico do atraso do índice do servidor MariaDB.

Aqui você pode ver que, embora o estado do índice após a reconstrução volte no tempo, isso acontece muito brevemente.
Agora que tudo está mais ou menos pronto, é hora de lançar. Fizemos isso gradualmente. Primeiro, lançamos um índice em tempo real em alguns servidores e o restante na época funcionou da mesma maneira. Ao mesmo tempo, a estrutura dos índices nos servidores "novos" não diferia dos antigos, portanto, nosso aplicativo PHP ainda podia se conectar ao balanceador sem se preocupar se a solicitação seria processada em um índice em tempo real ou em um índice simples.
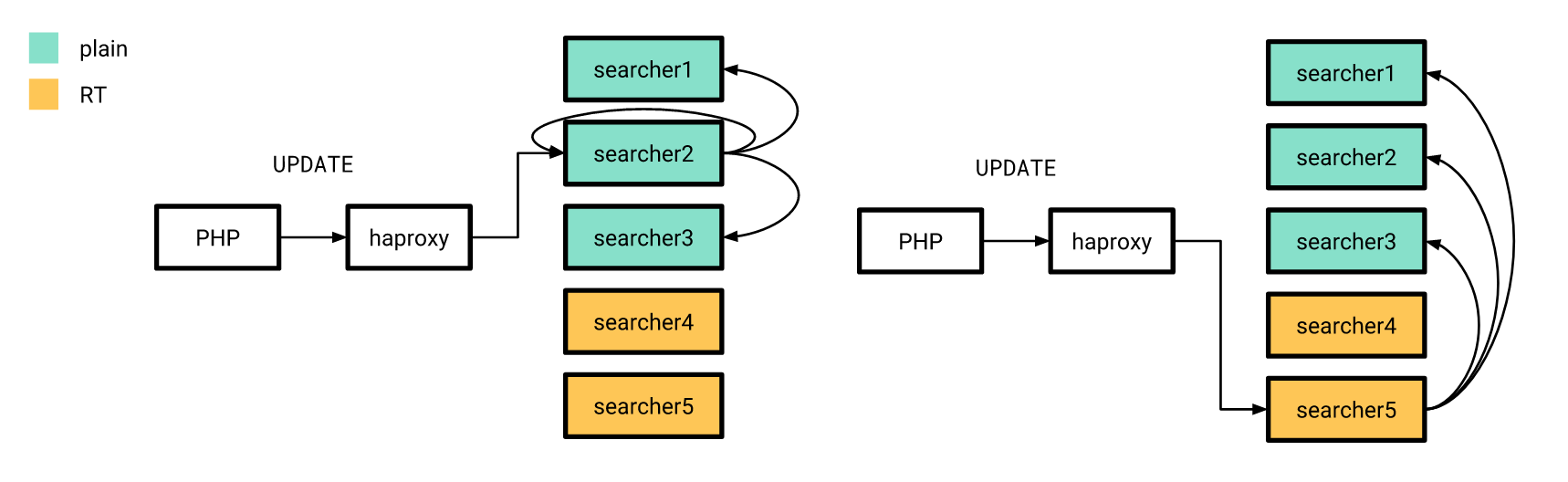
As atualizações de atributos, sobre as quais falei anteriormente, também foram enviadas de acordo com o esquema antigo, com a diferença de que o índice distribuído em todos os servidores estava configurado para enviar consultas UPDATE apenas para servidores com índices simples. Além disso, se a solicitação UPDATE do aplicativo atingir o servidor com índices em tempo real, ela não executará essa solicitação em casa, mas a enviará para os servidores configurados da maneira antiga.
Após o lançamento, como esperávamos, ele reduziu significativamente o atraso entre a forma como um resumo ou vaga é alterada no banco de dados e como as alterações correspondentes entram no índice.
Depois de mudar para um índice em tempo real, não havia necessidade de reconstruir o índice após cada alteração nos servidores de teste. E, assim, tornou-se possível escrever autotestes de ponta a ponta com a participação da pesquisa de forma relativamente barata. No entanto, como processamos as alterações do binlog de maneira assíncrona (do ponto de vista dos clientes que gravam no banco de dados), tivemos que esperar até que as alterações relativas ao documento participante do autoteste fossem processadas pelo nosso serviço e enviadas para a pesquisa. .
Para fazer isso, criamos um terminal em nosso serviço, o que faz exatamente isso, isto é, aguarda até que todas as alterações sejam aplicadas ao número de transação especificado. Para fazer isso, imediatamente após fazer as alterações necessárias no banco de dados, solicitamos a MariaDB @@gtid_current_pos e o transferimos para o terminal do nosso serviço. Se já aplicamos todas as transações a essa posição nesse momento, o serviço responde imediatamente que podemos continuar. Caso contrário, na goroutine responsável pela aplicação das alterações, criamos uma assinatura para este GTID e, assim que ele (ou qualquer um que esteja seguindo) é aplicado, também permitimos que o cliente continue o autoteste.
No código PHP, ele se parece com isso:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } }
Resultados
Como resultado, conseguimos reduzir significativamente o atraso entre a atualização do MariaDB e o Sphinx.


Também ficamos muito mais confiantes de que todas as atualizações chegam a todos os nossos servidores Sphinx a tempo.
Além disso, o teste de pesquisa (manual e automático) tornou-se muito mais agradável.
Infelizmente, isso não nos foi dado de graça: o desempenho do índice em tempo real comparado ao índice simples acabou sendo um pouco pior.
A distribuição do tempo de processamento das consultas de pesquisa, dependendo do tempo para um índice simples, é mostrada abaixo.

E aqui está o mesmo gráfico para o índice em tempo real.

Você pode ver que o compartilhamento de solicitações "rápidas" diminuiu um pouco, enquanto o compartilhamento de solicitações "lentas" aumentou.
Em vez de uma conclusão
Resta dizer que o código do serviço descrito neste artigo foi publicado em domínio público . Infelizmente, ainda não existe documentação detalhada, mas se desejar, você pode executar um exemplo de uso desse serviço através do docker-compose .
Referências
- Slides de vídeo e relatório
- Reportagem de vídeo de Andrey Smirnov e Vyacheslav Kryukov em Highload ++
- Biblioteca Go-mysql
- Código de serviço com exemplo de uso