Hoje, a maioria dos produtos de software é desenvolvida em equipes. As condições de sucesso para o desenvolvimento da equipe podem ser apresentadas na forma de um esquema simples.
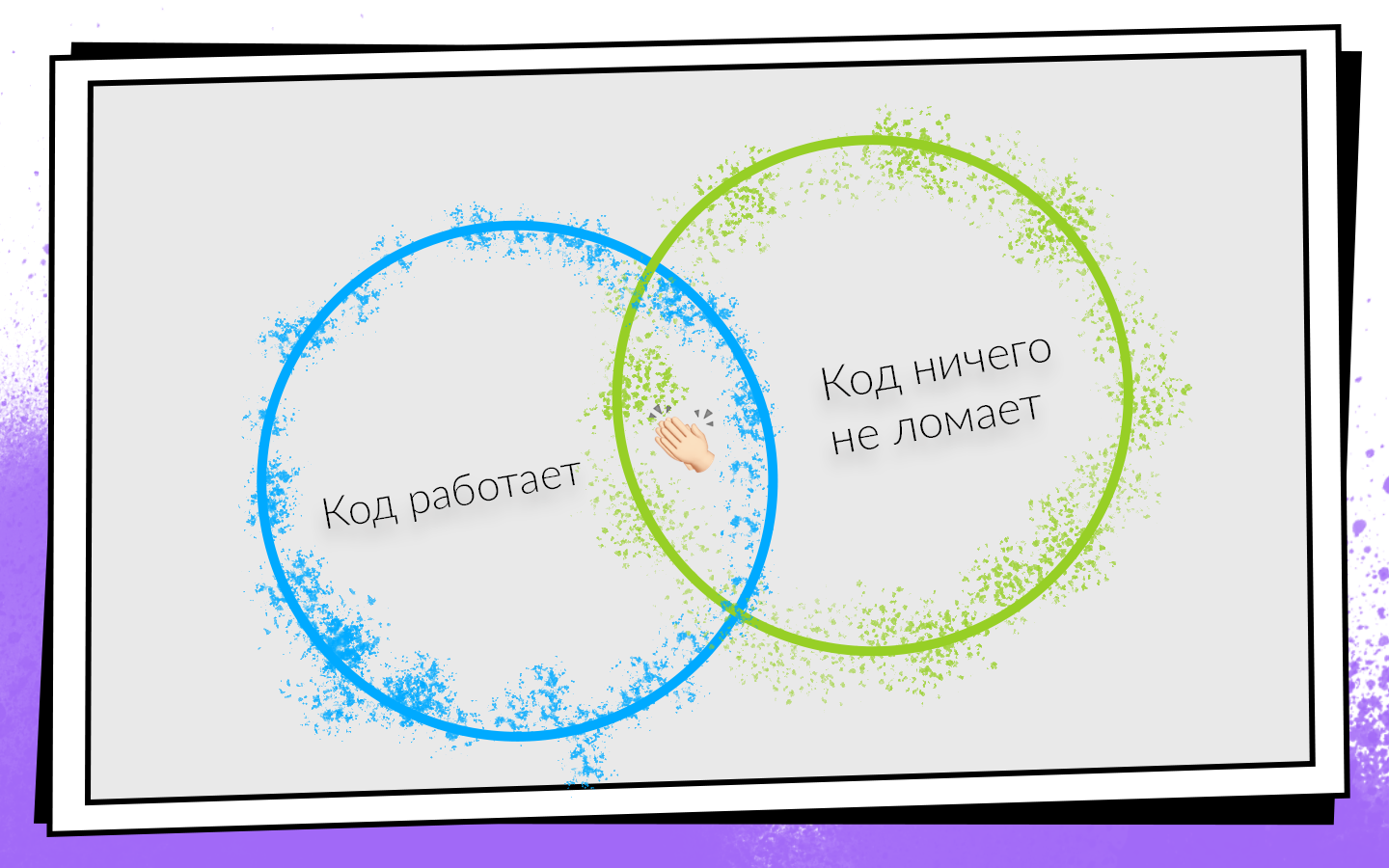
Depois de escrever o código, você deve se certificar de que:
- Isso funciona.
- Não quebra nada, incluindo o código que seus colegas escreveram.
Se as duas condições forem atendidas, você estará no caminho do sucesso. Para verificar facilmente essas condições e não desativar um caminho lucrativo, eles criaram a Integração Contínua.
O IC é um fluxo de trabalho no qual você integra seu código ao código geral do produto o mais rápido possível. E não apenas integrar, mas também verificar constantemente se tudo funciona. Como você precisa verificar muitas e muitas vezes, pense na automação. Você pode verificar tudo na tração manual, mas não vale a pena, e é por isso.
- As pessoas são caras . Uma hora de trabalho de qualquer programador é mais cara que uma hora de trabalho de qualquer servidor.
- As pessoas estão erradas . Portanto, podem surgir situações quando eles executam testes na ramificação errada ou coletam a confirmação incorreta para testadores.
- As pessoas são preguiçosas . Periodicamente, quando eu termino uma tarefa, penso: “Mas o que há para verificar? Eu escrevi duas linhas - stopudovo tudo funciona! ” Penso que para alguns de vocês, esses pensamentos às vezes vêm à mente. Mas você sempre precisa verificar.
Como a Integração Contínua foi introduzida e desenvolvida na equipe de desenvolvimento móvel Avito, como eles atingiram de 0 a 450 montagens por dia e que constroem máquinas coletam 200 horas por dia, diz Nikolay Nesterov (
nnesterov ) - participante de todas as mudanças evolutivas do aplicativo CI / CD Android .
A história é baseada no exemplo da equipe do Android, mas a maioria das abordagens também se aplica ao iOS.
Era uma vez uma pessoa que trabalhava na equipe Avito Android. Por definição, ele não precisava de nada da Integração Contínua: não havia ninguém com quem se integrar.
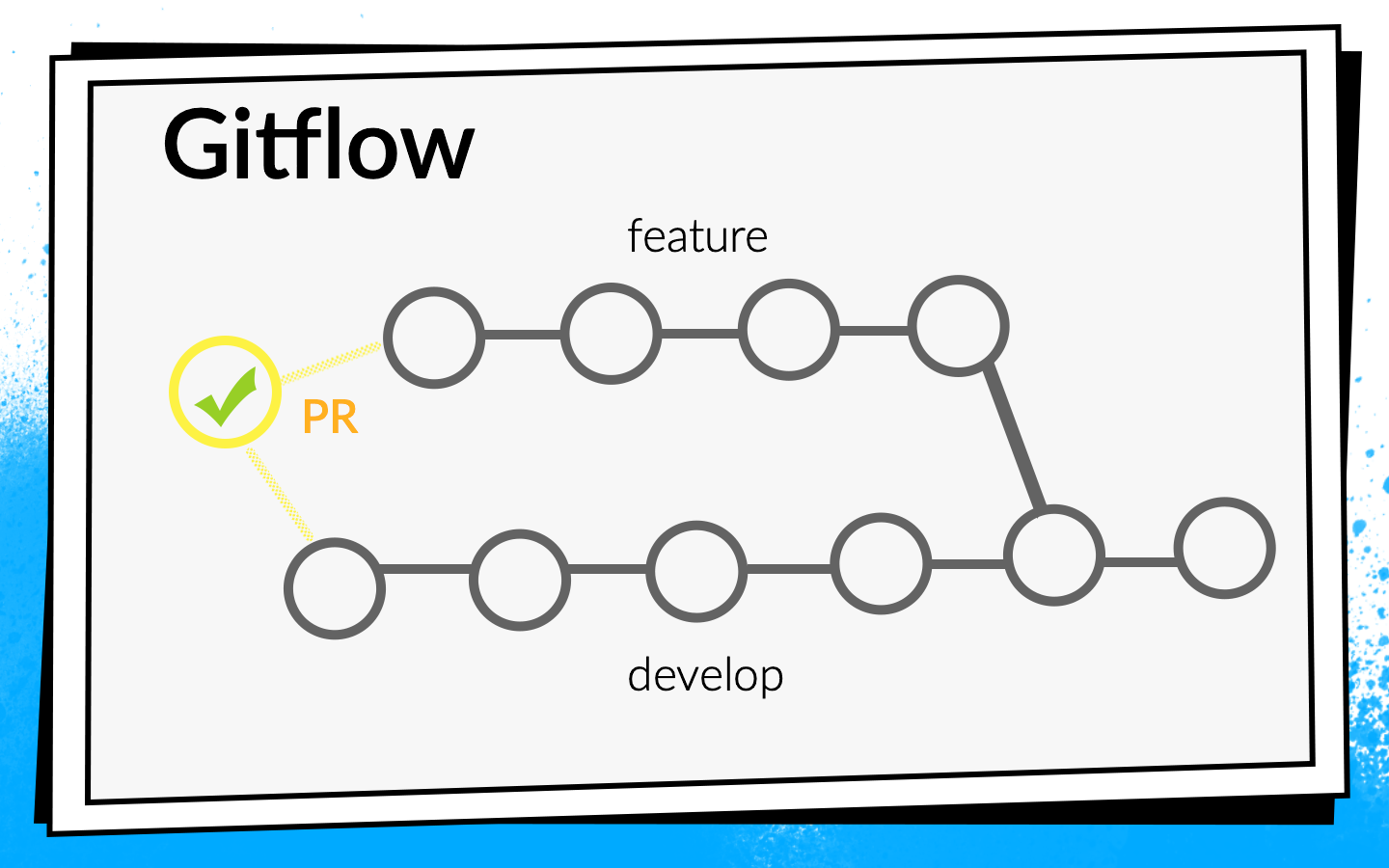
Mas o aplicativo cresceu, mais e mais novas tarefas apareceram, respectivamente, a equipe cresceu. Em algum momento, estava na hora de estabelecer formalmente o processo de integração de código. Foi decidido usar o fluxo Git.

O conceito de fluxo Git é conhecido: existe uma ramificação de desenvolvimento comum no projeto e, para cada novo recurso, os desenvolvedores cortam uma ramificação separada, confirmam, enviam por push e, quando desejam injetar seu código na ramificação de desenvolvimento, solicitam pull aberto. Para compartilhar conhecimento e discutir abordagens, introduzimos uma revisão de código, ou seja, os colegas devem verificar e confirmar o código um do outro.
Cheques
Observar o código com seus olhos é legal, mas não o suficiente. Portanto, as verificações automáticas são introduzidas.
- Antes de tudo, verificamos a montagem do ARC .
- Muitos testes Junit .
- Consideramos a cobertura do código , pois executamos os testes.
Para entender como essas verificações devem ser executadas, vejamos o processo de desenvolvimento no Avito.
Esquematicamente, pode ser representado da seguinte maneira:
- O desenvolvedor escreve o código em seu laptop. Você pode executar verificações de integração aqui - com um gancho de confirmação ou apenas executar verificações em segundo plano.
- Depois que o desenvolvedor executa o código, ele abre a solicitação de recebimento. Para que o código dele entre na ramificação de desenvolvimento, você deve passar por uma revisão de código e coletar o número necessário de confirmações. Você pode ativar verificações e compilações aqui: até que todas as compilações sejam bem-sucedidas, a solicitação pull não pode ser mesclada.
- Depois que a solicitação de recebimento é mesclada e o código está em desenvolvimento, você pode escolher um horário conveniente: por exemplo, à noite, quando todos os servidores estão livres, e as verificações de unidade, como você quiser.
Ninguém gostou de executar testes em seu laptop. Quando o desenvolvedor terminar o recurso, ele deseja iniciá-lo rapidamente e abrir a solicitação de recebimento. Se nesse momento algumas verificações longas forem iniciadas, isso não é apenas muito agradável, mas também atrasa o desenvolvimento: enquanto o laptop está verificando alguma coisa, é impossível trabalhar normalmente nela.
Nós realmente gostamos de executar verificações à noite, porque há muito tempo e servidores, você pode dar um passeio. Infelizmente, quando o código do recurso foi desenvolvido, o desenvolvedor já tem muito menos motivação para reparar os erros encontrados pela CI. Periodicamente, me pego pensando, quando olhava no relatório da manhã, todos os erros encontrados para corrigi-los algum tempo depois, porque agora em Jira existe uma nova e interessante tarefa que só quero começar a fazer.
Se as verificações bloquearem a solicitação de recebimento, a motivação será suficiente, porque até que as construções fiquem verdes, o código não entrará em desenvolvimento, o que significa que a tarefa não será concluída.
Como resultado, escolhemos esta estratégia: à noite, conduzimos o conjunto máximo possível de verificações, a mais crítica delas e, o mais importante, rapidamente, executamos uma solicitação de recebimento. Mas não paramos por aí - estamos otimizando simultaneamente a velocidade de aprovação nas verificações, para que elas mudem do modo noturno para as verificações na solicitação de recebimento.
Naquele momento, todos os nossos assemblies foram rápidos o suficiente, então incluímos o conjunto ARC, os testes Junit e o cálculo da cobertura de código com o bloqueador de solicitação de recebimento. Eles o ativaram, refletiram sobre o assunto e abandonaram a cobertura de código porque achavam que não precisávamos disso.
Levamos dois dias para concluir a configuração básica do IC (a seguir, uma estimativa temporária é aproximada, necessária para a escala).Depois disso, eles começaram a pensar mais - estamos verificando corretamente? Estamos lançando builds sob solicitação pull corretamente?
Iniciamos a construção no último commit da ramificação com a qual a solicitação pull está aberta. Mas as verificações desse commit apenas mostram que o código que o desenvolvedor escreveu funciona. Mas eles não provam que ele não quebrou nada. De fato, você precisa verificar o status da ramificação de revelação depois que o recurso foi injetado nela.
Para fazer isso, escrevemos um script bash simples
premerge.sh:
Aqui, todas as alterações mais recentes do desenvolvimento são simplesmente puxadas e mescladas na ramificação atual. Adicionamos o script premerge.sh como a primeira etapa de todas as compilações e começamos a verificar exatamente o que queremos, ou seja, a
integração .
Demorou três dias para localizar o problema, encontrar uma solução e escrever este script.O aplicativo desenvolvido, cada vez mais tarefas apareciam, a equipe crescia e premerge.sh às vezes começava a nos decepcionar. Desenvolver mudanças conflitantes e penetrantes que interromperam a assembléia.
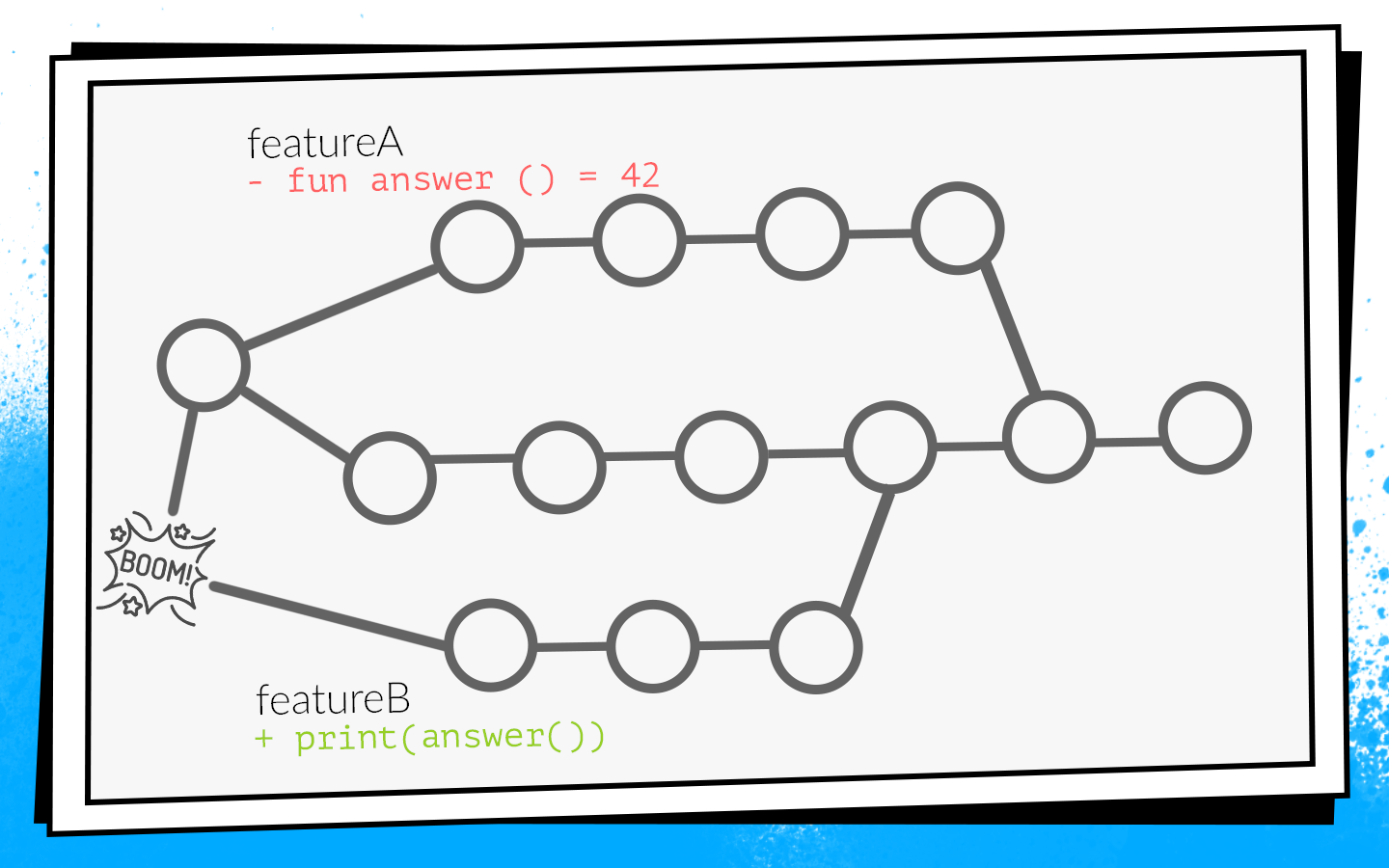
Um exemplo de como isso acontece:

Dois desenvolvedores começam a visualizar simultaneamente os recursos A e B. O desenvolvedor do recurso A descobre a função
answer() não utilizada no projeto e, como um bom olheiro, a remove. Ao mesmo tempo, o desenvolvedor do recurso B adiciona uma nova chamada a essa função em sua ramificação.
Os desenvolvedores concluem o trabalho e, ao mesmo tempo, solicitam pull aberto. As construções iniciam, premerge.sh verifica a solicitação de recebimento de um novo estado de desenvolvimento - todas as verificações são verdes. Depois que os recursos de solicitação de recebimento A forem mesclados, os recursos de solicitação de recebimento B serão mesclados ... Lança! Desenvolver quebras porque no código de desenvolvimento há uma chamada para uma função inexistente.
Quando não vai se desenvolver, isso é um
desastre local . Toda a equipe não pode coletar e dar nada para o teste.
Aconteceu que eu estava frequentemente envolvido em tarefas de infraestrutura: análise, rede, bancos de dados. Ou seja, escrevi as funções e classes que outros desenvolvedores usam. Por causa disso, muitas vezes entrei em tais situações. Eu até tive essa foto de uma vez.

Como isso não nos convinha, começamos a elaborar opções sobre como evitar isso.
Como não quebrar desenvolver
Primeira opção:
reconstrua todas as solicitações pull quando a atualização for desenvolvida. Se, no nosso exemplo, uma solicitação pull com o recurso A primeiro entrar em desenvolvimento, a solicitação pull do recurso B será reconstruída e, consequentemente, as verificações falharão devido a um erro de compilação.
Para entender quanto tempo levará, considere um exemplo com dois PRs. Abrimos dois PRs: duas compilações, dois lançamentos de teste. Depois que o primeiro PR é despejado no desenvolvimento, o segundo deve ser reconstruído. No total, dois lançamentos de cheques de RP levam três PRs: 2 + 1 = 3.
Em princípio, é normal. Mas analisamos as estatísticas e uma situação típica em nossa equipe era de 10 PRs abertos e, em seguida, o número de verificações é a soma da progressão: 10 + 9 + ... + 1 = 55. Ou seja, para aceitar 10 PRs, é necessário reconstruir 55 vezes. E isso está em uma situação ideal, quando todas as verificações passam pela primeira vez, quando ninguém abre uma solicitação de recebimento adicional enquanto essas dez estão sendo processadas.
Imagine-se um desenvolvedor que precisa ter tempo para pressionar o botão "mesclar" primeiro, porque se isso for feito por um vizinho, você terá que esperar até que todas as montagens sejam executadas novamente ... Não, isso não funcionará, isso atrasará seriamente o desenvolvimento.
A segunda maneira possível:
coletar solicitação de recebimento após revisão de código. Ou seja, abra a solicitação de recebimento, colete o número necessário de atualizações de colegas, corrija o que você precisa e execute as compilações. Se tiverem êxito, a solicitação pull será mesclada com o develop. Nesse caso, não há reinicializações adicionais, mas o feedback diminui bastante. Como desenvolvedor, quando abro uma solicitação de recebimento, quero imediatamente ver se ele vai. Por exemplo, se um teste falhar, você precisará corrigi-lo rapidamente. No caso de uma compilação atrasada, o feedback fica mais lento, o que significa todo o desenvolvimento. Isso também não nos convinha.
Como resultado, apenas a terceira opção permaneceu - dar um
ciclo . Todo o nosso código, todas as nossas fontes são armazenadas no repositório no servidor Bitbucket. Assim, tivemos que desenvolver um plugin para o Bitbucket.

Este plug-in substitui o mecanismo de mesclagem de solicitação de recebimento. O início é padrão: o PR é aberto, todos os conjuntos são iniciados, a revisão do código é aprovada. Porém, após a revisão do código ser aprovada e o desenvolvedor decidir clicar em "mesclar", o plug-in verifica se o estado em que as verificações de desenvolvimento foram executadas. Se, após as compilações, o develop conseguiu atualizar, o plug-in não permitirá a mesclagem de uma solicitação pull na ramificação principal. Simplesmente reiniciará as compilações em relação ao novo desenvolvimento.

Em nosso exemplo com alterações conflitantes, essas compilações falharão devido a um erro de compilação. Dessa forma, o desenvolvedor do recurso B precisará corrigir o código, reiniciar as verificações e o plug-in aplicará automaticamente a solicitação de recebimento.
Antes de implementar este plug-in, tivemos uma média de 2,7 execuções de teste por solicitação pull. Com o plugin, houve 3,6 lançamentos. Isso nos convinha.
Vale a pena notar que este plugin tem uma desvantagem: ele reinicia a compilação apenas uma vez. Ou seja, permanece uma pequena janela através da qual mudanças conflitantes podem se desenvolver. Mas a probabilidade disso não é alta e fizemos esse compromisso entre o número de partidas e a probabilidade de falha. Por dois anos, ele disparou apenas uma vez, portanto, provavelmente não em vão.
Demoramos duas semanas para escrever a primeira versão do plugin para Bitbucket.Novos cheques
Enquanto isso, nossa equipe continuou a crescer. Novas verificações foram adicionadas.
Pensamos: por que reparar erros se eles podem ser evitados? E então eles introduziram a
análise de código estático . Começamos com o lint, que está incluído no Android SDK. Mas naquela época ele não sabia trabalhar com o código Kotlin, e já possuímos 75% do aplicativo escrito em Kotlin. Portanto, as
verificações internas do Android Studio foram adicionadas ao fiapo
.Para fazer isso, tive que ser muito pervertido: pegue o Android Studio, empacote-o no Docker e execute-o no CI com um monitor virtual para que ele pensasse que estava sendo executado em um laptop real. Mas funcionou.
Também nesse momento, começamos a escrever muitos
testes de
instrumentação e implementamos o
teste de captura de tela . É quando uma captura de tela de referência é gerada para uma visualização pequena separada, e o teste é que uma captura de tela é tirada da visualização e comparada diretamente com a referência pixel por pixel. Se houver uma discrepância, significa que um layout foi para algum lugar ou algo está errado nos estilos.
Porém, testes de instrumentação e de captura de tela precisam ser executados em dispositivos: emuladores ou em dispositivos reais. Dado que existem muitos testes e eles geralmente perseguem, você precisa de um farm inteiro. Para iniciar sua própria fazenda é muito trabalhoso, por isso encontramos uma opção pronta - o Firebase Test Lab.
Laboratório de teste do Firebase
Foi escolhido porque o Firebase é um produto do Google, ou seja, deve ser confiável e dificilmente morrerá. Os preços são acessíveis: US $ 5 por hora para um dispositivo real e US $ 1 por hora para um emulador.
Demorou cerca de três semanas para implementar o Firebase Test Lab em nosso IC.Mas a equipe continuou a crescer, e o Firebase, infelizmente, começou a nos decepcionar. Naquela época, ele não tinha SLA. Às vezes, o Firebase nos fazia esperar até que o número necessário de dispositivos para testes se tornasse gratuito e não os executasse imediatamente, como queríamos. A espera na fila demorou meia hora, e esse é um tempo muito longo. Os testes de instrumentação eram executados em todas as relações públicas, os atrasos atrasavam muito o desenvolvimento e, em seguida, uma conta mensal vinha com uma soma redonda. Em geral, foi decidido abandonar o Firebase e serrar em casa, já que a equipe cresceu o suficiente.
Docker + python + bash
Pegamos o docker, inserimos emuladores nele, escrevemos um programa simples em Python que, no momento certo, aumenta o número certo de emuladores na versão correta e os interrompe quando necessário. E, é claro, alguns scripts bash - onde sem eles?
Foram necessárias cinco semanas para criar nosso próprio ambiente de teste.Como resultado, cada solicitação de recebimento tinha uma extensa lista de mesclagem de verificações de bloqueio:
- Assembléia do ARC;
- Testes Junit
- Fiapos;
- Verificações do Android Studio;
- Testes de instrumentação;
- Testes de captura de tela.
Isso impediu muitas possíveis falhas. Tecnicamente, tudo funcionou, mas os desenvolvedores reclamaram que a espera pelos resultados era muito longa.
Quanto tempo é quanto? Carregamos os dados do Bitbucket e TeamCity no sistema de análise e percebemos que o
tempo médio de espera é de 45 minutos . Ou seja, um desenvolvedor, que abre uma solicitação de recebimento, espera, em média, resultados de compilação de 45 minutos. Na minha opinião, isso é muito, e você não pode trabalhar assim.
Obviamente, decidimos acelerar todas as nossas compilações.
Acelerar
Vendo que muitas vezes as construções estão alinhadas, a primeira coisa que
compramos é o ferro - o desenvolvimento extensivo é o mais simples. As construções pararam de ficar na fila, mas o tempo de espera diminuiu apenas um pouco, porque algumas verificações estavam sendo realizadas por um período muito longo.
Removemos verificações muito longas
Nossa integração contínua pode detectar esses tipos de erros e problemas.
- Não vou . O IC pode detectar um erro de compilação quando, devido a alterações conflitantes, algo não está ocorrendo. Como eu disse, ninguém pode coletar nada, o desenvolvimento aumenta e todos ficam nervosos.
- Um erro no comportamento . Por exemplo, quando o aplicativo é criado, mas quando você clica no botão, ele trava ou o botão não é pressionado. Isso é ruim porque esse bug pode alcançar o usuário.
- Bug no layout . Por exemplo, um botão é pressionado, mas movido 10 pixels para a esquerda.
- Aumento da dívida técnica .
Observando esta lista, percebemos que apenas os dois primeiros pontos são críticos. Queremos pegar esses problemas antes de tudo. Os erros no layout são detectados no estágio de revisão do projeto e são facilmente corrigidos. Trabalhar com dívida técnica requer um processo e planejamento separados, por isso decidimos não verificar a solicitação de recebimento.
Com base nessa classificação, sacudimos toda a lista de verificações.
Riscou o Lint e adiou o lançamento para a noite: apenas para fornecer um relatório de quantos problemas existem no projeto. Concordamos em trabalhar separadamente com a dívida técnica, mas
recusamos completamente os cheques do Android Studio . O Android Studio do Docker para lançar inspeções parece interessante, mas traz muitos problemas no suporte. Qualquer atualização para as versões do Android Studio é uma luta contra bugs obscuros. Também foi difícil manter testes de captura de tela, porque a biblioteca não funcionava de maneira muito estável, havia falsos positivos.
Os testes de captura de tela foram removidos da lista de verificações .
Como resultado, nos resta:
- Assembléia do ARC;
- Testes Junit
- Testes de instrumentação.
Cache remoto Gradle
Sem verificações pesadas, as coisas melhoraram. Mas não há limite para a perfeição!
Nossa aplicação já foi dividida em aproximadamente 150 módulos gradle. Normalmente, nesse caso, o cache remoto Gradle funciona bem e decidimos experimentá-lo.
O cache remoto Gradle é um serviço que pode criar artefatos de cache para tarefas individuais em módulos separados. Gradle, em vez de realmente compilar o código, bate no cache remoto via HTTP e pergunta se alguém já executou essa tarefa. Nesse caso, basta baixar o resultado.
Iniciar o cache remoto do Gradle é fácil porque o Gradle fornece uma imagem do Docker. Conseguimos fazer isso em três horas.Tudo o que era necessário era iniciar o Docker e registrar uma linha no projeto. Mas, embora você possa iniciá-lo rapidamente para que tudo funcione bem, isso levará muito tempo.
Abaixo está um gráfico de erros de cache.

No início, a porcentagem de falhas após o cache era de cerca de 65. Três semanas depois, conseguimos aumentar esse valor para 20%. Acontece que as tarefas que o aplicativo Android coleta possuem dependências transitivas estranhas, devido às quais Gradle perdeu o cache.
Ao conectar o cache, aceleramos bastante a montagem. Mas, além da montagem, os testes de instrumentação ainda estão perseguindo, e estão perseguindo por um longo tempo. Talvez nem todos os testes precisem ser perseguidos para cada solicitação de recebimento. Para descobrir, usamos a análise de impacto.
Análise de impacto
Na solicitação pull, criamos o git diff e encontramos os módulos Gradle modificados.

Faz sentido executar apenas os testes de instrumentação que testam os módulos modificados e todos os módulos que dependem deles. Não faz sentido executar testes para módulos vizinhos: o código não foi alterado lá e nada pode ser interrompido.
Os testes de instrumentação não são tão simples, porque devem estar localizados no módulo Aplicativo de nível superior. Aplicamos uma heurística de análise de bytecode para entender a qual módulo cada teste pertence.
Demorou cerca de oito semanas para atualizar os testes de instrumentação para testar apenas os módulos envolvidos.As medidas de aceleração de verificação funcionaram com sucesso. Após 45 minutos, chegamos a aproximadamente 15. Um quarto de hora para aguardar a compilação já é normal.
Mas agora os desenvolvedores começaram a reclamar que não está claro para eles quais builds estão sendo lançadas, onde o log ficará, por que o build está vermelho, qual teste caiu etc.
Os problemas de feedback retardam o desenvolvimento, por isso tentamos fornecer as informações mais compreensíveis e detalhadas sobre cada PR e compilação. Começamos com comentários no Bitbucket for PR, indicando qual compilação caiu e por que, escrevemos mensagens direcionadas no Slack. No final, eles criaram um painel para a página de Relações Públicas com uma lista de todas as compilações em execução no momento e seu status: na linha, inicia, trava ou termina. Você pode clicar na compilação e acessar seu log.
 Seis semanas foram gastas em feedback detalhado.
Seis semanas foram gastas em feedback detalhado.Planos
Passamos para a história mais recente. Tendo resolvido a questão do feedback, fomos para um novo nível - decidimos construir nossa própria fazenda de emuladores. Quando existem muitos testes e emuladores, eles são difíceis de gerenciar. Como resultado, todos os nossos emuladores foram movidos para um cluster k8s com gerenciamento flexível de recursos.
Além disso, existem outros planos.
- Return Lint (e outras análises estáticas). Já estamos trabalhando nessa direção.
- Execute todos os testes de ponta a ponta no bloqueador PR em todas as versões do SDK.
Assim, traçamos a história do desenvolvimento da Integração Contínua no Avito. Agora, quero dar alguns conselhos do ponto de vista dos experientes.
Dicas
Se eu pudesse dar apenas um conselho, seria o seguinte:
Por favor, tenha cuidado com os scripts de shell!
O Bash é uma ferramenta muito flexível e poderosa, é muito conveniente e rápido para escrever scripts nele. Mas com ele você pode cair na armadilha e, infelizmente, caímos nela.
Tudo começou com scripts simples executados em nossas máquinas de construção:
Mas, como você sabe, tudo se desenvolve e se complica com o tempo - vamos executar um script a partir de outro, vamos passar alguns parâmetros para lá - no final, tive que escrever uma função que determina qual nível de bash de aninhamento estamos no momento para substituir as aspas necessárias, para que tudo comece.

Você pode imaginar o trabalho envolvido no desenvolvimento desses scripts. Eu aconselho você a não cair nessa armadilha.
O que pode ser substituído?
- Qualquer linguagem de script. Escrever em Python ou Kotlin Script é mais conveniente porque é programação, não scripts.
- Ou descreva toda a lógica de construção na forma de tarefas de classificação personalizada para seu projeto.
Decidimos escolher a segunda opção e agora estamos excluindo sistematicamente todos os scripts do bash e escrevendo muitos shuffles personalizados do gradle.
Dica 2: mantenha sua infraestrutura em código.É conveniente quando a configuração de Integração Contínua não é armazenada na interface de interface do usuário Jenkins ou TeamCity, etc., mas como arquivos de texto diretamente no repositório do projeto. Isso fornece capacidade de versão. Não será difícil reverter ou coletar código em outra ramificação.
Os scripts podem ser armazenados no projeto. E o que fazer com o meio ambiente?
Dica 3: o Docker pode ajudar com o meio ambiente.Definitivamente ajudará os desenvolvedores do Android, ainda não iOS, infelizmente.
Este é um exemplo de um arquivo docker simples que contém jdk e android-sdk:
FROM openjdk:8 ENV SDK_URL="https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip" \ ANDROID_HOME="/usr/local/android-sdk" \ ANDROID_VERSION=26 \ ANDROID_BUILD_TOOLS_VERSION=26.0.2 # Download Android SDK RUN mkdir "$ANDROID_HOME" .android \ && cd "$ANDROID_HOME" \ && curl -o sdk.zip $SDK_URL \ && unzip sdk.zip \ && rm sdk.zip \ && yes | $ANDROID_HOME/tools/bin/sdkmanager --licenses # Install Android Build Tool and Libraries RUN $ANDROID_HOME/tools/bin/sdkmanager --update RUN $ANDROID_HOME/tools/bin/sdkmanager "build-tools;${ANDROID_BUILD_TOOLS_VERSION}" \ "platforms;android-${ANDROID_VERSION}" \ "platform-tools" RUN mkdir /application WORKDIR /application
Depois de escrever esse arquivo de encaixe (vou lhe contar um segredo, você não pode escrevê-lo, mas retirá-lo do GitHub) e coletar a imagem, você obtém uma máquina virtual na qual é possível criar o aplicativo e executar os testes do Junit.
Os dois principais argumentos pelos quais isso faz sentido são escalabilidade e repetibilidade. Usando a janela de encaixe, você pode aumentar rapidamente uma dúzia de agentes de construção que terão exatamente o mesmo ambiente que o antigo. Isso facilita a vida dos engenheiros de CI. Colocar o android-sdk no docker é bastante simples, com os emuladores um pouco mais complicados: você precisa trabalhar um pouco (bem, ou fazer o download do finalizado novamente no GitHub).
Dica número 4: não esqueça que as verificações não são feitas apenas para verificação, mas para as pessoas.O feedback rápido e, o mais importante, claro é muito importante para os desenvolvedores: o que eles quebraram, que teste caiu, onde o log de criação.
Dica 5: seja pragmático com a integração contínua.Entenda claramente que tipos de erros você deseja evitar, quanto você está disposto a gastar recursos, tempo, tempo no computador. As verificações muito longas podem, por exemplo, ser reagendadas da noite para o dia. E aqueles que pegam erros não muito importantes devem ser completamente abandonados.
Dica número 6: use ferramentas prontas.Agora, existem muitas empresas que fornecem CI de nuvem.

Para equipes pequenas, essa é uma boa saída. Você não precisa manter nada, apenas pague algum dinheiro, colete seu aplicativo e até realize testes de instrumentação.
Dica 7: em uma equipe grande, as soluções internas são mais lucrativas.Porém, mais cedo ou mais tarde, com o crescimento da equipe, as soluções internas serão mais lucrativas. Há um ponto nessas decisões. Em economia, existe uma lei de retornos decrescentes: em qualquer projeto, cada melhoria subsequente é cada vez mais difícil, requer cada vez mais investimento.
A economia descreve toda a nossa vida, incluindo a integração contínua. Criei um cronograma de trabalho para cada estágio do desenvolvimento da Integração Contínua.

Pode-se ver que qualquer melhoria é cada vez mais difícil. Observando este gráfico, podemos entender que o desenvolvimento da Integração Contínua deve ser consistente com o crescimento do tamanho da equipe. Para uma equipe de duas pessoas, gastar 50 dias desenvolvendo um farm de emuladores internos é uma idéia mais ou menos. Mas, ao mesmo tempo, para uma grande equipe não fazer a Integração Contínua também é uma má idéia, devido a problemas de integração, correção de comunicações etc. vai demorar ainda mais tempo.
Começamos com o fato de que a automação é necessária porque as pessoas são caras, enganadas e preguiçosas. Mas as pessoas também automatizam. Portanto, todos esses mesmos problemas se aplicam à automação.
- Automatizar é caro. Lembre-se do horário de trabalho.
- Na automação, as pessoas cometem erros.
- Às vezes, a automação é muito preguiçosa, porque tudo funciona assim. Por que mais melhorar, por que toda essa integração contínua?
: 20% . , . , , , - , develop, . , , - .
Continuous Integration. ., , AppsConf . . 22-23 .