 Há pouco tempo, o Google lançou o Cloud Firestore. O Cloud Firestore é um banco de dados NoSQL baseado em nuvem que o Google posicionou como um substituto para o Realtime Database. Neste artigo, quero dizer como começar a usá-lo.
Há pouco tempo, o Google lançou o Cloud Firestore. O Cloud Firestore é um banco de dados NoSQL baseado em nuvem que o Google posicionou como um substituto para o Realtime Database. Neste artigo, quero dizer como começar a usá-lo.
As possibilidades
O Cloud Firestore permite armazenar dados em um servidor remoto, acessá-los facilmente e monitorar alterações em tempo real. A documentação possui uma excelente comparação do Cloud Firestore e do Realtime Database.
Criando e se conectando a um projeto
No console do Firebase, selecione Banco de Dados e clique em Criar banco de dados. Em seguida, selecione as configurações de acesso. Para a familiarização, um modo de teste será suficiente para nós, mas, no estímulo, é melhor abordar esse problema com mais seriedade. Leia mais sobre os modos de acesso aqui .
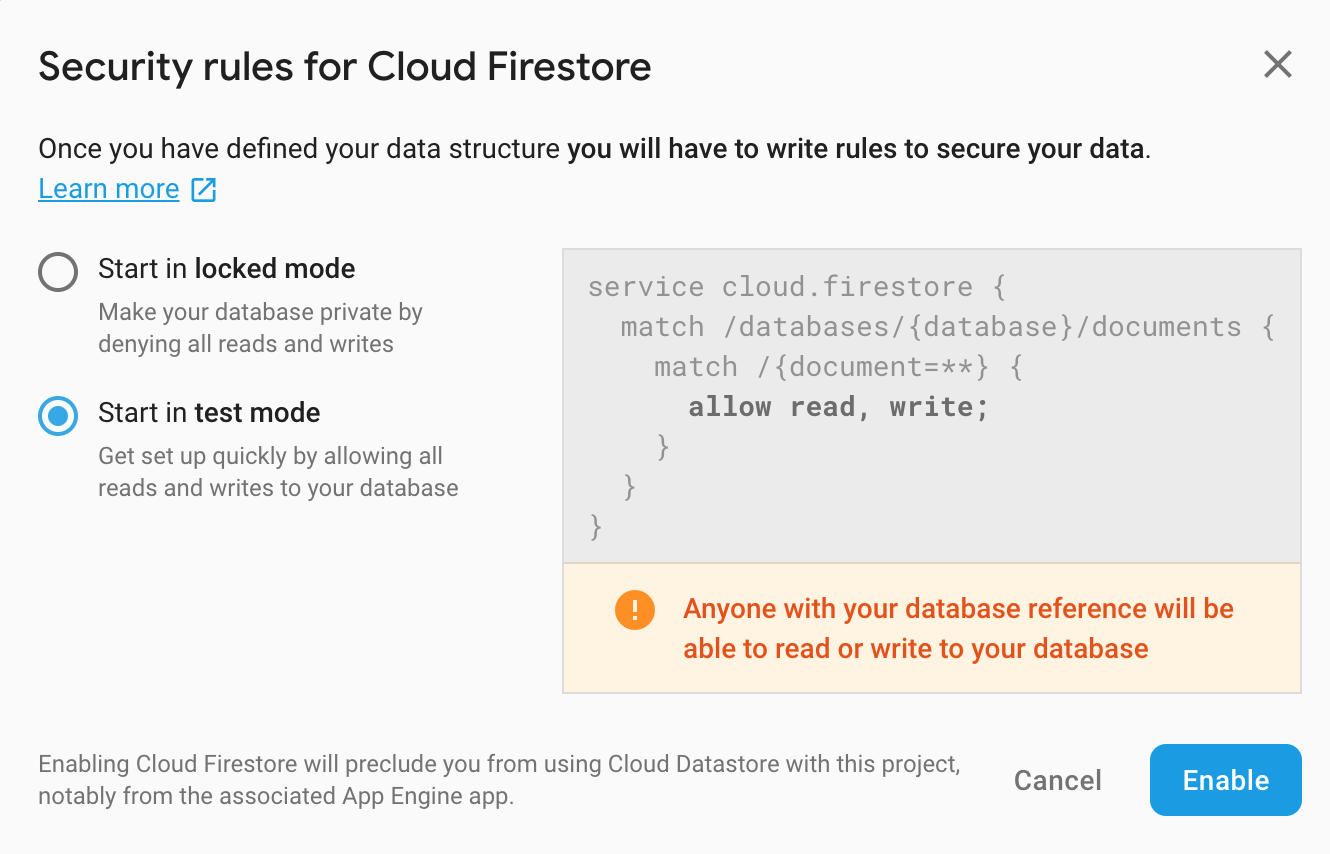
Para configurar o projeto, execute as seguintes etapas:
- Adicione o Firebase ao projeto de acordo com as instruções aqui.
- Adicione dependência ao app / build.gradle
implementation 'com.google.firebase:firebase-firestore:18.1.0'
Agora está tudo pronto.
Para me familiarizar com as técnicas básicas de trabalho com o Cloud Firestore, escrevi um aplicativo simples. Para funcionar, você precisa criar um projeto no console do Firebase e adicionar o arquivo google-services.json ao projeto no Android Studio.
Estrutura de armazenamento de dados
O Firestore usa coleções e documentos para armazenar dados. Um documento é um registro que contém quaisquer campos. Os documentos são combinados em coleções. Um documento também pode conter coleções aninhadas, mas isso não é suportado no Android. Se traçarmos uma analogia com o banco de dados SQL, a coleção é uma tabela e o documento é uma entrada nesta tabela. Uma coleção pode conter documentos com um conjunto diferente de campos.
Recebendo e gravando dados
Para obter todos os documentos de uma coleção, o código a seguir é suficiente
remoteDB.collection(“Tasks”) .get() .addOnSuccessListener { querySnapshot ->
Aqui solicitamos todos os documentos da coleção Tarefas .
A biblioteca permite gerar consultas com parâmetros. O código a seguir mostra como obter documentos da coleção por condição
remoteDB.collection(“Tasks”) .whereEqualTo("title", "Task1") .get() .addOnSuccessListener { querySnapshot ->
Aqui, solicitamos todos os documentos da coleção Tarefas para os quais o campo de título corresponde ao valor da Tarefa1 .
Após o recebimento dos documentos, eles podem ser imediatamente convertidos em nossas classes de dados
remoteDB.collection(“Tasks”) .get() .addOnSuccessListener { querySnapshot ->
Para escrever, você precisa criar um Hashmap com dados (em que o nome do campo atua como chave e o valor desse campo como valor) e transferi-lo para a biblioteca. O código a seguir demonstra isso
val taskData = HashMap<String, Any>() taskData["title"] = task.title taskData["created"] = Timestamp(task.created.time / 1000, 0) remoteDB.collection("Tasks") .add(taskData) .addOnSuccessListener {
Neste exemplo, um novo documento será criado e o Firestore gerará um ID para ele. Para definir seu próprio ID, faça o seguinte
val taskData = HashMap<String, Any>() taskData["title"] = task.title taskData["created"] = Timestamp(task.created.time / 1000, 0) remoteDB.collection("Tasks") .document("New task") .set(taskData) .addOnSuccessListener {
Nesse caso, se não houver documento com o ID igual a Nova tarefa , ele será criado e, se houver, os campos especificados serão atualizados.
Outra opção para criar / atualizar um documento
remoteDB.collection("Tasks") .document("New task") .set(mapToRemoteTask(task)) .addOnSuccessListener {
Inscrever-se nas alterações
O Firestore permite que você assine alterações de dados. Você pode assinar alterações na coleção e alterações em um documento específico
remoteDB.collection("Tasks") .addSnapshotListener { querySnapshot, error ->
querySnapshot.documents - contém uma lista atualizada de todos os documentos
querySnapshot.documentChanges - contém uma lista de alterações. Cada objeto contém um documento modificado e o tipo de alteração. São possíveis 3 tipos de alterações
ADICIONADO - documento adicionado,
MODIFICADO - o documento foi alterado,
REMOVIDO - documento excluído
Carregando grandes quantidades de dados
O Banco de dados em tempo real fornece um mecanismo menos conveniente para baixar grandes quantidades de dados, que consiste na edição manual do arquivo json e no download. Pronto para uso, o Firestore não fornece nada disso. Foi muito inconveniente adicionar novos documentos até encontrar uma maneira de carregar facilmente uma grande quantidade de informações. Para que você não tenha problemas como o meu, abaixo anexarei instruções sobre como baixar rápida e facilmente uma grande quantidade de dados. A instrução foi encontrada na Internet.
- Instale o Node.js e o npm
- Instale o pacote firebase-admin executando o comando
npm install firebase-admin --save - Gere o arquivo json com dados da coleção. Um exemplo pode ser encontrado no arquivo Tasks.json.
- Para fazer o download, precisamos de uma chave de acesso. Como obtê-lo está bem descrito neste artigo.
- No arquivo export.js, coloque seus dados
require ('./ firestore_key.json') - arquivo com chave de acesso. Eu estava em uma pasta com um script
<YOU_DATABASE> - o nome da sua base de firestore
"./json/Tasks.json" - o caminho para o arquivo no qual os dados
['created'] - lista de nomes de campos com o tipo Timestamp - Executar script
node export.js
O script usa os desenvolvimentos de dalenguyen
Conclusão
Usei o Cloud Firestore em um dos meus projetos e não tive problemas sérios. Uma de minhas coleções contém cerca de 15.000 documentos e as consultas são bastante rápidas, sem o uso de índices. Usando o Cloud Firestore em conjunto com a Configuração remota e de sala, você pode reduzir significativamente o número de chamadas ao banco de dados e não ultrapassar os limites livres. Com uma tarifa gratuita por dia, você pode ler 50.000 documentos, gravar 20.000 e excluir 20.000.