Neste post, gostaríamos de compartilhar uma maneira interessante de lidar com a configuração de um sistema distribuído.
A configuração é representada diretamente no idioma Scala de maneira segura. Um exemplo de implementação é descrito em detalhes. Vários aspectos da proposta são discutidos, incluindo influência no processo geral de desenvolvimento.
( em russo )
1. Introdução
A construção de sistemas distribuídos robustos requer o uso de configuração correta e coerente em todos os nós. Uma solução típica é usar uma descrição de implantação textual (terraform, ansible ou algo semelhante) e arquivos de configuração gerados automaticamente (geralmente - dedicados a cada nó / função). Também gostaríamos de usar os mesmos protocolos das mesmas versões em cada nó de comunicação (caso contrário, teríamos problemas de incompatibilidade). No mundo da JVM, isso significa que pelo menos a biblioteca de mensagens deve ter a mesma versão em todos os nós de comunicação.
Que tal testar o sistema? Obviamente, devemos ter testes de unidade para todos os componentes antes de chegar aos testes de integração. Para poder extrapolar os resultados do teste em tempo de execução, devemos garantir que as versões de todas as bibliotecas sejam mantidas idênticas nos ambientes de tempo de execução e de teste.
Ao executar testes de integração, geralmente é muito mais fácil ter o mesmo caminho de classe em todos os nós. Só precisamos garantir que o mesmo caminho de classe seja usado na implantação. (É possível usar caminhos de classe diferentes em nós diferentes, mas é mais difícil representar essa configuração e implantá-la corretamente.) Portanto, para manter as coisas simples, consideraremos apenas caminhos de classe idênticos em todos os nós.
A configuração tende a evoluir junto com o software. Geralmente usamos versões para identificar vários
estágios da evolução do software. Parece razoável cobrir a configuração no gerenciamento de versões e identificar configurações diferentes com alguns rótulos. Se houver apenas uma configuração em produção, podemos usar a versão única como um identificador. Às vezes, podemos ter vários ambientes de produção. E para cada ambiente, podemos precisar de um ramo de configuração separado. Portanto, as configurações podem ser rotuladas com ramificação e versão para identificar exclusivamente configurações diferentes. Cada rótulo e versão da ramificação corresponde a uma única combinação de nós distribuídos, portas, recursos externos e versões da biblioteca de caminhos de classe em cada nó. Aqui, cobriremos apenas a ramificação única e identificaremos as configurações por uma versão decimal de três componentes (1.2.3), da mesma maneira que outros artefatos.
Nos ambientes modernos, os arquivos de configuração não são mais modificados manualmente. Normalmente geramos
arquivos de configuração no momento da implantação e nunca mais os toque . Então, pode-se perguntar por que ainda usamos o formato de texto para arquivos de configuração? Uma opção viável é colocar a configuração dentro de uma unidade de compilação e se beneficiar da validação da configuração em tempo de compilação.
Nesta postagem, examinaremos a idéia de manter a configuração no artefato compilado.
Configuração compilável
Nesta seção, discutiremos um exemplo de configuração estática. Dois serviços simples - o serviço de eco e o cliente do serviço de eco estão sendo configurados e implementados. Em seguida, dois sistemas distribuídos diferentes com os dois serviços são instanciados. Um é para uma configuração de nó único e outro para configuração de dois nós.
Um sistema distribuído típico consiste em alguns nós. Os nós podem ser identificados usando algum tipo:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
ou apenas
case class NodeId(hostName: String)
ou mesmo
object Singleton type NodeId = Singleton.type
Esses nós executam várias funções, executam alguns serviços e devem poder se comunicar com os outros nós por meio de conexões TCP / HTTP.
Para conexão TCP, é necessário pelo menos um número de porta. Também queremos garantir que cliente e servidor estejam falando o mesmo protocolo. Para modelar uma conexão entre nós, declaremos a seguinte classe:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
onde Port é apenas um Int dentro do intervalo permitido:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Tipos refinadosVeja a biblioteca refinada . Em suma, permite adicionar restrições de tempo de compilação a outros tipos. Nesse caso, Int só pode ter valores de 16 bits que podem representar o número da porta. Não há requisitos para usar esta biblioteca para esta abordagem de configuração. Apenas parece se encaixar muito bem.
Para HTTP (REST), também podemos precisar de um caminho do serviço:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Tipo fantasmaPara identificar o protocolo durante a compilação, estamos usando o recurso Scala de declarar o argumento do tipo Protocol que não é usado na classe. É o chamado tipo fantasma . Em tempo de execução, raramente precisamos de uma instância de identificador de protocolo, por isso não a armazenamos. Durante a compilação, esse tipo de fantasma oferece segurança adicional ao tipo. Não podemos passar a porta com protocolo incorreto.
Um dos protocolos mais usados é a API REST com serialização Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
em que RequestMessage é o tipo básico de mensagens que o cliente pode enviar ao servidor e ResponseMessage é a mensagem de resposta do servidor. Obviamente, podemos criar outras descrições de protocolo que especifiquem o protocolo de comunicação com a precisão desejada.
Para os fins deste post, usaremos uma versão mais simples do protocolo:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Neste protocolo, a mensagem de solicitação é anexada ao URL e a mensagem de resposta é retornada como uma sequência simples.
Uma configuração de serviço pode ser descrita pelo nome do serviço, uma coleção de portas e algumas dependências. Existem algumas maneiras possíveis de como representar todos esses elementos no Scala (por exemplo, HList , tipos de dados algébricos). Para os fins deste post, usaremos o Cake Pattern e representaremos peças combináveis (módulos) como características. (O padrão de bolo não é um requisito para essa abordagem de configuração compilável. É apenas uma possível implementação da ideia.)
Dependências podem ser representadas usando o padrão de bolo como pontos finais de outros nós:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
O serviço de eco precisa apenas de uma porta configurada. E declaramos que esta porta suporta o protocolo de eco. Observe que não precisamos especificar uma porta específica no momento, porque as características permitem declarações de métodos abstratos. Se usarmos métodos abstratos, o compilador exigirá uma implementação em uma instância de configuração. Aqui fornecemos a implementação ( 8081 ) e ela será usada como valor padrão se a ignorarmos em uma configuração concreta.
Podemos declarar uma dependência na configuração do cliente de serviço de eco:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
A dependência tem o mesmo tipo que o echoService . Em particular, exige o mesmo protocolo. Portanto, podemos ter certeza de que, se conectarmos essas duas dependências, elas funcionarão corretamente.
Implementação de serviçosUm serviço precisa de uma função para iniciar e encerrar normalmente. (A capacidade de encerrar um serviço é essencial para o teste.) Novamente, existem algumas opções para especificar essa função para uma determinada configuração (por exemplo, poderíamos usar classes de tipo). Para este post, usaremos novamente o Cake Pattern. Podemos representar um serviço usando cats.Resource que já fornece bracketing e liberação de recursos. Para adquirir um recurso, devemos fornecer uma configuração e algum contexto de tempo de execução. Portanto, a função de inicialização do serviço pode se parecer com:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
onde
Config - tipo de configuração exigida por este iniciador de serviçoAddressResolver - um objeto de tempo de execução que tem a capacidade de obter endereços reais de outros nós (continue lendo para obter detalhes).
os outros tipos são de cats :
F[_] - tipo de efeito (no caso mais simples, F[A] poderia ser apenas () => A Neste post, usaremos cats.IO )Reader[A,B] - é mais ou menos sinônimo de uma função A => Bcats.Resource - tem maneiras de adquirir e liberarTimer - permite dormir / medir o tempoContextShift - análogo de ExecutionContextApplicative - invólucro de funções em vigor (quase uma mônada) (podemos eventualmente substituí-lo por outra coisa)
Usando essa interface, podemos implementar alguns serviços. Por exemplo, um serviço que não faz nada:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Consulte Código fonte para outras implementações de serviços - serviço de eco ,
clientes de eco e controladores vitalícios .)
Um nó é um único objeto que executa alguns serviços (o início de uma cadeia de recursos é ativado pelo Cake Pattern):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Observe que no nó especificamos o tipo exato de configuração que é necessário para esse nó. O compilador não permitirá que construamos o objeto (Cake) com tipo insuficiente, porque cada característica de serviço declara uma restrição no tipo de Config . Também não poderemos iniciar o nó sem fornecer uma configuração completa.
Resolução do endereço do nóPara estabelecer uma conexão, precisamos de um endereço de host real para cada nó. Pode ser conhecido depois de outras partes da configuração. Portanto, precisamos de uma maneira de fornecer um mapeamento entre a identificação do nó e seu endereço real. Esse mapeamento é uma função:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Existem algumas maneiras possíveis de implementar essa função.
- Se conhecermos os endereços reais antes da implantação, durante a instanciação dos hosts do nó, podemos gerar o código Scala com os endereços reais e executar a compilação posteriormente (que executa verificações no tempo de compilação e executa o conjunto de testes de integração). Nesse caso, nossa função de mapeamento é conhecida estaticamente e pode ser simplificada para algo como um
Map[NodeId, NodeAddress] . - Às vezes, obtemos endereços reais apenas posteriormente quando o nó é realmente iniciado ou não temos endereços de nós que ainda não foram iniciados. Nesse caso, podemos ter um serviço de descoberta iniciado antes de todos os outros nós, e cada nó pode anunciar seu endereço nesse serviço e assinar as dependências.
- Se podemos modificar o
/etc/hosts , podemos usar nomes de host predefinidos (como my-project-main-node e echo-backend ) e apenas associar esse nome ao endereço IP no momento da implantação.
Neste post, não abordamos esses casos em mais detalhes. De fato, no nosso exemplo de brinquedo, todos os nós terão o mesmo endereço IP - 127.0.0.1 .
Nesta postagem, consideraremos dois layouts de sistema distribuído:
- Layout de nó único, onde todos os serviços são colocados no nó único.
- Layout de dois nós, em que serviço e cliente estão em nós diferentes.
A configuração para um layout de nó único é a seguinte:
Configuração de nó único object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
Aqui, criamos uma única configuração que estende a configuração do servidor e do cliente. Também configuramos um controlador de ciclo de vida que normalmente encerra o cliente e o servidor após o intervalo da lifetime passar.
O mesmo conjunto de implementações e configurações de serviço pode ser usado para criar o layout de um sistema com dois nós separados. Só precisamos criar duas configurações de nó separadas com os serviços apropriados:
Configuração de dois nós object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Veja como especificamos a dependência. Mencionamos o serviço fornecido pelo outro nó como uma dependência do nó atual. O tipo de dependência é verificado porque contém o tipo fantasma que descreve o protocolo. E em tempo de execução, teremos o ID do nó correto. Este é um dos aspectos importantes da abordagem de configuração proposta. Ele nos permite definir a porta apenas uma vez e garantir que estamos fazendo referência à porta correta.
Implementação de dois nósPara esta configuração, usamos exatamente as mesmas implementações de serviços. Nenhuma alteração. No entanto, criamos duas implementações de nó diferentes que contêm diferentes conjuntos de serviços:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
O primeiro nó implementa o servidor e precisa apenas da configuração do lado do servidor. O segundo nó implementa o cliente e precisa de outra parte da configuração. Ambos os nós requerem alguma especificação vitalícia. Para os propósitos deste nó de pós-serviço, terá uma vida útil infinita que pode ser finalizada usando o SIGTERM , enquanto o cliente de eco será finalizado após a duração finita configurada. Consulte o aplicativo inicial para obter detalhes.
Processo geral de desenvolvimento
Vamos ver como essa abordagem muda a maneira como trabalhamos com a configuração.
A configuração como código será compilada e produzirá um artefato. Parece razoável separar o artefato de configuração de outros artefatos de código. Freqüentemente, podemos ter várias configurações na mesma base de código. E, é claro, podemos ter várias versões de vários ramos de configuração. Em uma configuração, podemos selecionar versões específicas de bibliotecas e isso permanecerá constante sempre que implantarmos essa configuração.
Uma alteração na configuração se torna uma alteração no código. Portanto, deve ser coberto pelo mesmo processo de garantia de qualidade:
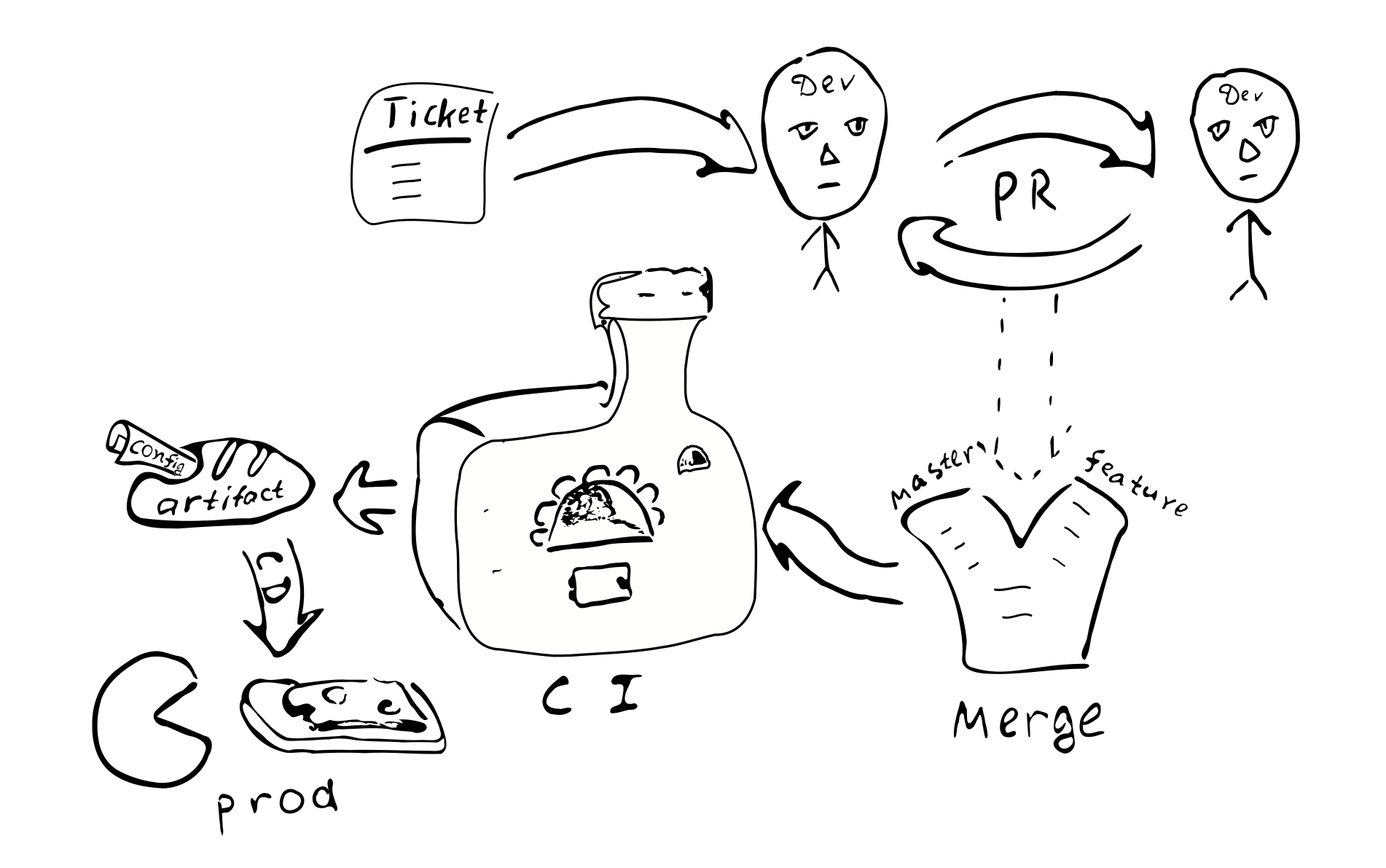
Ticket -> PR -> revisão -> mesclagem -> integração contínua -> implantação contínua
Existem as seguintes consequências da abordagem:
A configuração é coerente para a instância de um sistema específico. Parece que não há como haver conexão incorreta entre os nós.
Não é fácil alterar a configuração apenas em um nó. Não parece razoável fazer login e alterar alguns arquivos de texto. Portanto, o desvio da configuração se torna menos possível.
Pequenas alterações na configuração não são fáceis de fazer.
A maioria das alterações na configuração seguirá o mesmo processo de desenvolvimento e passará por uma revisão.
Precisamos de um repositório separado para configuração da produção? A configuração de produção pode conter informações confidenciais que gostaríamos de manter fora do alcance de muitas pessoas. Portanto, pode valer a pena manter um repositório separado com acesso restrito que conterá a configuração de produção. Podemos dividir a configuração em duas partes - uma que contém os parâmetros mais abertos de produção e outra que contém a parte secreta da configuração. Isso permitiria o acesso à maioria dos desenvolvedores à grande maioria dos parâmetros, restringindo o acesso a coisas realmente sensíveis. É fácil fazer isso usando traços intermediários com valores de parâmetro padrão.
Variações
Vamos ver os prós e os contras da abordagem proposta em comparação com outras técnicas de gerenciamento de configuração.
Primeiro, listaremos algumas alternativas para os diferentes aspectos da maneira proposta de lidar com a configuração:
- Arquivo de texto na máquina de destino.
- Armazenamento centralizado de valores-chave (como
etcd / zookeeper ). - Componentes de subprocesso que podem ser reconfigurados / reiniciados sem reiniciar o processo.
- Configuração fora do artefato e controle de versão.
O arquivo de texto oferece alguma flexibilidade em termos de correções ad-hoc. O administrador de um sistema pode efetuar login no nó de destino, fazer uma alteração e simplesmente reiniciar o serviço. Isso pode não ser tão bom para sistemas maiores. Nenhum vestígio é deixado para trás da alteração. A alteração não é revisada por outro par de olhos. Pode ser difícil descobrir o que causou a mudança. Não foi testado. Da perspectiva do sistema distribuído, um administrador pode simplesmente esquecer de atualizar a configuração em um dos outros nós.
(Porém, se eventualmente houver a necessidade de começar a usar arquivos de configuração de texto, teremos de adicionar apenas analisador + validador que possa produzir o mesmo tipo de Config e que seria suficiente para começar a usar configurações de texto. Isso também mostra que o a complexidade da configuração em tempo de compilação é um pouco menor que a complexidade das configurações baseadas em texto, porque na versão baseada em texto precisamos de algum código adicional.)
O armazenamento centralizado de valores-chave é um bom mecanismo para distribuir meta-parâmetros de aplicativos. Aqui precisamos pensar sobre o que consideramos ser valores de configuração e o que são apenas dados. Dada uma função C => A => B , geralmente chamamos raramente de valores variáveis C "configuração", enquanto os dados frequentemente alterados A - apenas inserem dados. A configuração deve ser fornecida à função antes dos dados A Dada essa idéia, podemos dizer que é a frequência esperada de alterações o que poderia ser usado para distinguir dados de configuração de apenas dados. Além disso, os dados geralmente vêm de uma fonte (usuário) e a configuração vem de uma fonte diferente (administrador). Lidar com parâmetros que podem ser alterados após a inicialização do processo leva a um aumento da complexidade do aplicativo. Para esses parâmetros, teremos que lidar com o mecanismo de entrega, análise e validação, lidando com valores incorretos. Portanto, para reduzir a complexidade do programa, é melhor reduzir o número de parâmetros que podem mudar no tempo de execução (ou mesmo eliminá-los completamente).
Da perspectiva deste post, devemos fazer uma distinção entre parâmetros estáticos e dinâmicos. Se a lógica de serviço exigir uma alteração rara de alguns parâmetros em tempo de execução, podemos chamá-los de parâmetros dinâmicos. Caso contrário, eles são estáticos e podem ser configurados usando a abordagem proposta. Para reconfiguração dinâmica, outras abordagens podem ser necessárias. Por exemplo, partes do sistema podem ser reiniciadas com os novos parâmetros de configuração de maneira semelhante à reinicialização de processos separados de um sistema distribuído.
(Minha humilde opinião é evitar a reconfiguração do tempo de execução, porque aumenta a complexidade do sistema.
Pode ser mais simples confiar apenas no suporte do SO para reiniciar processos. Embora nem sempre seja possível.)
Um aspecto importante do uso da configuração estática que às vezes leva as pessoas a considerar a configuração dinâmica (sem outros motivos) é o tempo de inatividade do serviço durante a atualização da configuração. De fato, se precisarmos fazer alterações na configuração estática, precisaremos reiniciar o sistema para que novos valores se tornem efetivos. Os requisitos para o tempo de inatividade variam para diferentes sistemas, portanto, pode não ser tão crítico. Se for crítico, temos que planejar com antecedência o reinício de qualquer sistema. Por exemplo, podemos implementar a drenagem de conexão do AWS ELB . Nesse cenário, sempre que precisamos reiniciar o sistema, iniciamos uma nova instância do sistema em paralelo e depois mudamos o ELB para ele, deixando o sistema antigo concluir a manutenção das conexões existentes.
Que tal manter a configuração dentro do artefato com versão ou fora? Manter a configuração dentro de um artefato significa que, na maioria dos casos, essa configuração passou no mesmo processo de garantia de qualidade que outros artefatos. Portanto, pode-se ter certeza de que a configuração é de boa qualidade e confiável. Pelo contrário, a configuração em um arquivo separado significa que não há vestígios de quem e por que fez alterações nesse arquivo. Isso é importante? Acreditamos que, para a maioria dos sistemas de produção, é melhor ter uma configuração estável e de alta qualidade.
A versão do artefato permite descobrir quando foi criado, quais valores ele contém, quais recursos são ativados / desativados, quem foi responsável por fazer cada alteração na configuração. Pode ser necessário algum esforço para manter a configuração dentro de um artefato e é uma escolha de design a ser feita.
Prós e contras
Aqui gostaríamos de destacar algumas vantagens e discutir algumas desvantagens da abordagem proposta.
Vantagens
Recursos da configuração compilável de um sistema distribuído completo:
- Verificação estática da configuração. Isso fornece um alto nível de confiança, de que a configuração está correta, dadas as restrições de tipo.
- Linguagem avançada de configuração. Normalmente, outras abordagens de configuração são limitadas a, no máximo, substituição de variáveis.
Usando o Scala, é possível usar uma ampla variedade de recursos de idiomas para melhorar a configuração. Por exemplo, podemos usar características para fornecer valores padrão, objetos para definir escopo diferente, podemos nos referir a valores definidos apenas uma vez no escopo externo (DRY). É possível usar sequências literais ou instâncias de determinadas classes ( Seq , Map etc.). - DSL Scala tem suporte decente para gravadores DSL. É possível usar esses recursos para estabelecer uma linguagem de configuração mais conveniente e amigável ao usuário final, para que a configuração final seja pelo menos legível pelos usuários do domínio.
- Integridade e coerência entre nós. Um dos benefícios de ter a configuração para todo o sistema distribuído em um só lugar é que todos os valores são definidos estritamente uma vez e depois reutilizados em todos os locais onde precisamos deles. Além disso, digite declarações de porta segura para garantir que, em todas as configurações corretas possíveis, os nós do sistema falem o mesmo idioma. Existem dependências explícitas entre os nós, o que dificulta o esquecimento de fornecer alguns serviços.
- Alta qualidade de mudanças. A abordagem geral de passar as alterações de configuração através do processo normal de RP estabelece altos padrões de qualidade também na configuração.
- Alterações simultâneas na configuração. Sempre que fazemos alterações na implantação automática da configuração, assegura que todos os nós estejam sendo atualizados.
- Simplificação de aplicativos. O aplicativo não precisa analisar e validar a configuração e manipular valores de configuração incorretos. Isso simplifica a aplicação geral. (Algum aumento de complexidade está na própria configuração, mas é uma troca consciente em relação à segurança.) É bem simples retornar à configuração comum - basta adicionar as peças que faltam. É mais fácil começar com a configuração compilada e adiar a implementação de peças adicionais para alguns momentos posteriores.
- Configuração com versão. Devido ao fato de que as mudanças na configuração seguem o mesmo processo de desenvolvimento, como resultado, obtemos um artefato com uma versão exclusiva. Isso nos permite alterar a configuração novamente, se necessário. Podemos até implantar uma configuração que foi usada há um ano e funcionará exatamente da mesma maneira. A configuração estável melhora a previsibilidade e a confiabilidade do sistema distribuído. A configuração é fixada em tempo de compilação e não pode ser facilmente violada em um sistema de produção.
- Modularidade A estrutura proposta é modular e os módulos podem ser combinados de várias maneiras para
suporta configurações diferentes (configurações / layouts). Em particular, é possível ter um layout de nó único em pequena escala e uma configuração em vários nós em grande escala. É razoável ter vários layouts de produção. - Teste Para fins de teste, é possível implementar um serviço simulado e usá-lo como uma dependência de uma maneira segura. Alguns layouts de teste diferentes com várias peças substituídas por zombarias podem ser mantidos simultaneamente.
- Teste de integração. Às vezes, em sistemas distribuídos, é difícil executar testes de integração. Usando a abordagem descrita para digitar a configuração segura do sistema distribuído completo, podemos executar todas as partes distribuídas em um único servidor de forma controlável. É fácil imitar a situação
quando um dos serviços ficar indisponível.
Desvantagens
A abordagem de configuração compilada é diferente da configuração "normal" e pode não atender a todas as necessidades. Aqui estão algumas das desvantagens da configuração compilada:
- Configuração estática. Pode não ser adequado para todos os aplicativos. Em alguns casos, é necessário corrigir rapidamente a configuração na produção, ignorando todas as medidas de segurança. Essa abordagem torna mais difícil. A compilação e reimplantação são necessárias após fazer qualquer alteração na configuração. Esse é o recurso e o fardo.
- Geração de configuração. Quando a configuração é gerada por alguma ferramenta de automação, essa abordagem requer compilação subsequente (que por sua vez pode falhar). Pode ser necessário um esforço adicional para integrar esta etapa adicional ao sistema de construção.
- Instrumentos. Atualmente, existem muitas ferramentas em uso que dependem de configurações baseadas em texto. Alguns deles
não será aplicável quando a configuração for compilada. - É necessária uma mudança de mentalidade. Os desenvolvedores e o DevOps estão familiarizados com os arquivos de configuração de texto. A idéia de compilar a configuração pode parecer estranha para eles.
- Antes de introduzir a configuração compilável, é necessário um processo de desenvolvimento de software de alta qualidade.
Existem algumas limitações do exemplo implementado:
- Se fornecermos uma configuração extra que não é exigida pela implementação do nó, o compilador não nos ajudará a detectar a implementação ausente. Isso pode ser resolvido usando
HList ou ADTs (classes de caso) para a configuração do nó, em vez de características e padrão de bolo. - Temos que fornecer algumas informações gerais no arquivo de configuração: (
package , import , declarações de object ;
override def 's para parâmetros que possuem valores padrão). Isso pode ser parcialmente resolvido usando uma DSL. - Neste post, não abordamos a reconfiguração dinâmica de clusters de nós semelhantes.
Conclusão
Neste post, discutimos a idéia de representar a configuração diretamente no código-fonte de uma maneira segura. A abordagem pode ser utilizada em muitos aplicativos como um substituto para xml e outras configurações baseadas em texto. Apesar de nosso exemplo ter sido implementado no Scala, ele também pode ser traduzido para outros idiomas compiláveis (como Kotlin, C #, Swift etc.). Pode-se tentar essa abordagem em um novo projeto e, caso não se encaixe bem, mudar para o modo antiquado.
Obviamente, a configuração compilável requer um processo de desenvolvimento de alta qualidade. Em troca, promete fornecer uma configuração robusta de alta qualidade.
Essa abordagem pode ser estendida de várias maneiras:
- Pode-se usar macros para executar a validação da configuração e falhar no momento da compilação, no caso de falhas de restrições da lógica de negócios.
- Uma DSL pode ser implementada para representar a configuração de uma maneira fácil de usar no domínio.
- Gerenciamento dinâmico de recursos com ajustes de configuração automáticos. Por exemplo, quando ajustamos o número de nós do cluster, podemos desejar (1) que os nós obtenham uma configuração levemente modificada; (2) gerenciador de cluster para receber novas informações de nós.
Obrigado
Gostaria de agradecer a Andrey Saksonov, Pavel Popov e Anton Nehaev, por darem um feedback inspirador sobre o rascunho deste post que me ajudou a esclarecer.