Gostaria de dizer um mecanismo interessante para trabalhar com uma configuração de sistema distribuído. A configuração é apresentada diretamente em uma linguagem compilada (Scala) usando tipos seguros. Neste post, um exemplo dessa configuração é analisado e vários aspectos da introdução de uma configuração compilada no processo geral de desenvolvimento são considerados.
( inglês )
1. Introdução
Construir um sistema distribuído confiável implica que todos os nós usem a configuração correta, sincronizada com outros nós. Normalmente, as tecnologias DevOps (terraform, ansible ou algo parecido) são usadas para gerar automaticamente arquivos de configuração (geralmente exclusivos para cada nó). Também gostaríamos de ter certeza de que todos os nós em interação usam protocolos idênticos (incluindo a mesma versão). Caso contrário, a incompatibilidade será incorporada ao nosso sistema distribuído. No mundo da JVM, uma conseqüência desse requisito é a necessidade de usar a mesma versão de uma biblioteca contendo mensagens de protocolo em todos os lugares.
E o teste do sistema distribuído? Obviamente, assumimos que os testes de unidade são fornecidos para todos os componentes antes de passarmos para o teste de integração. (Para extrapolar os resultados do teste para o tempo de execução, também devemos fornecer um conjunto idêntico de bibliotecas no estágio de teste e no tempo de execução.)
Ao trabalhar com testes de integração, geralmente é mais fácil em qualquer lugar usar um único caminho de classe em todos os nós. Nós apenas teremos que garantir que o mesmo caminho de classe esteja envolvido no tempo de execução. (Apesar de ser possível executar nós diferentes com caminhos de classe diferentes, isso leva a complicações de toda a configuração e dificuldades nos testes de implantação e integração.) Como parte desta postagem, assumimos que o mesmo caminho de classe será usado em todos os nós.
A configuração evolui com o aplicativo. Para identificar os vários estágios da evolução dos programas, usamos versões. Parece lógico também identificar versões diferentes das configurações. E a própria configuração deve ser colocada no sistema de controle de versão. Se houver apenas uma configuração em produção, podemos usar apenas o número da versão. Se muitas instâncias de produção são usadas, precisamos de várias
ramificações de configuração e um rótulo adicional além da versão (por exemplo, o nome da ramificação). Assim, podemos identificar exclusivamente a configuração exata. Cada identificador de configuração corresponde exclusivamente a uma certa combinação de nós distribuídos, portas, recursos externos e versões da biblioteca. Na estrutura deste post, procederemos do fato de haver apenas um ramo e podemos identificar a configuração da maneira usual usando três números separados por um ponto (1.2.3).
Em ambientes modernos, os arquivos de configuração são criados manualmente muito raramente. Com mais freqüência, eles são gerados durante a implantação e não são mais tocados (para não quebrar nada ). Surge uma pergunta lógica: por que ainda estamos usando um formato de texto para armazenar a configuração? Uma alternativa completamente viável é a capacidade de usar código regular para configuração e obter benefícios das verificações em tempo de compilação.
Neste post, estamos apenas explorando a ideia de representar uma configuração dentro de um artefato compilado.
Configuração compilada
Esta seção descreve um exemplo de uma configuração compilada estática. Dois serviços simples são implementados - o serviço de eco e o serviço de eco do cliente. Com base nesses dois serviços, duas versões do sistema são montadas. Em uma modalidade, ambos os serviços estão localizados no mesmo nó, em outra modalidade, em nós diferentes.
Normalmente, um sistema distribuído contém vários nós. Os nós podem ser identificados usando valores de algum tipo NodeId :
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
ou
case class NodeId(hostName: String)
ou mesmo
object Singleton type NodeId = Singleton.type
Os nós desempenham várias funções, os serviços são iniciados neles e as comunicações TCP / HTTP podem ser estabelecidas entre eles.
Para descrever as comunicações TCP, precisamos de pelo menos um número de porta. Também gostaríamos de refletir o protocolo suportado nessa porta para garantir que o cliente e o servidor usem o mesmo protocolo. Vamos descrever a conexão usando esta classe:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
em que Port é apenas um número inteiro Int com um intervalo de valores válidos:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Tipos refinadosVeja biblioteca refinada e meu relatório . Em resumo, a biblioteca permite adicionar restrições que são verificadas no momento da compilação aos tipos. Nesse caso, os valores válidos do número da porta são números inteiros de 16 bits. Para uma configuração compilada, o uso da biblioteca refinada é opcional, mas pode melhorar a capacidade do compilador de verificar a configuração.
Para protocolos HTTP (REST), além do número da porta, também podemos precisar de um caminho para o serviço:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Tipos fantasmasPara identificar o protocolo no estágio de compilação, usamos um parâmetro de tipo que não é usado dentro da classe. Essa decisão se deve ao fato de que no tempo de execução não usamos uma instância de protocolo, mas gostaríamos que o compilador verifique a compatibilidade do protocolo. Graças ao protocolo, não poderemos transferir o serviço inadequado como uma dependência.
Um protocolo comum é a API REST com serialização Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
onde RequestMessage é o tipo de solicitação, ResponseMessage é o tipo de resposta.
Obviamente, você pode usar outras descrições de protocolo que fornecem a precisão necessária.
Para os fins deste post, usaremos uma versão simplificada do protocolo:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Aqui, a solicitação é uma sequência adicionada ao URL e a resposta é a sequência retornada no corpo da resposta HTTP.
A configuração do serviço é descrita pelo nome, portas e dependências do serviço. Esses elementos podem ser representados no Scala de várias maneiras (por exemplo, HList , tipos de dados algébricos). Para os propósitos deste post, usaremos o Cake Pattern e representamos os módulos usando as trait . (O padrão de bolo não é um elemento necessário da abordagem descrita. É apenas uma das implementações possíveis.)
Dependências entre serviços podem ser representadas como métodos que retornam EndPoint portas EndPoint de outros nós:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Para criar um serviço de eco, apenas um número de porta e uma indicação de que essa porta suporta o protocolo de eco são suficientes. Não foi possível indicar uma porta específica, porque As características permitem declarar métodos sem implementação (métodos abstratos). Nesse caso, ao criar uma configuração específica, o compilador exigiria uma implementação de método abstrato e um número de porta. Como implementamos o método, ao criar uma configuração específica, não podemos especificar outra porta. O valor padrão será usado.
Na configuração do cliente, declaramos uma dependência no serviço de eco:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
A dependência é do mesmo tipo que o serviço exportado echoService . Em particular, no cliente de eco, exigimos o mesmo protocolo. Portanto, ao conectar os dois serviços, podemos ter certeza de que tudo funcionará corretamente.
Implementação de serviçoPara iniciar e parar o serviço, é necessária uma função. (A capacidade de interromper o serviço é essencial para o teste.) Novamente, existem várias opções para implementar essa função (por exemplo, poderíamos usar classes de tipo com base no tipo de configuração). Para os fins deste post, usaremos o Cake Pattern. Representaremos o serviço usando a classe cats.Resource , porque Nesta classe, os meios de liberação segura garantida de recursos em caso de problemas já são fornecidos. Para obter o recurso, precisamos fornecer uma configuração e um contexto de tempo de execução pronto. A função para iniciar o serviço pode ter o seguinte formato:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
onde
Config - tipo de configuração para este serviçoAddressResolver - um objeto de tempo de execução que permite descobrir os endereços de outros nós (veja abaixo)
e outros tipos da biblioteca de cats :
F[_] - tipo de efeito (no caso mais simples, F[A] pode ser apenas uma função () => A Neste post, usaremos cats.IO )Reader[A,B] - mais ou menos sinônimo da função A => Bcats.Resource - um recurso que pode ser obtido e liberadoTimer - temporizador (permite adormecer por um tempo e medir intervalos de tempo)ContextShift - análogo de ExecutionContextApplicative - uma classe de tipo de efeito que permite combinar efeitos individuais (quase uma mônada). Em aplicativos mais complexos, parece melhor usar o Monad / ConcurrentEffect .
Usando esta assinatura de função, podemos implementar vários serviços. Por exemplo, um serviço que não faz nada:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Consulte o código-fonte para outros serviços - serviço de eco , cliente de eco
e controladores vitalícios .)
Um nó é um objeto que pode iniciar vários serviços (o lançamento da cadeia de recursos é garantido pelo Cake Pattern):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Observe que indicamos o tipo exato de configuração necessária para este nó. Se esquecermos de especificar um dos tipos de configuração exigidos por um serviço separado, haverá um erro de compilação. Além disso, não poderemos iniciar o nó se não fornecermos algum objeto do tipo apropriado com todos os dados necessários.
Resolução de nome de hostPara se conectar a um host remoto, precisamos de um endereço IP real. É possível que o endereço seja conhecido depois do restante da configuração. Portanto, precisamos de uma função que mapeie o identificador do nó para o endereço:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Você pode oferecer várias maneiras de implementar essa função:
- Se os endereços forem conhecidos antes da implantação, podemos gerar um código Scala com
endereços e inicie a montagem. Isso irá compilar e executar os testes.
Nesse caso, a função será conhecida estaticamente e pode ser representada no código como uma exibição de mapa Map[NodeId, NodeAddress] . - Em alguns casos, um endereço válido só é conhecido após o início do nó.
Nesse caso, podemos implementar um "serviço de descoberta" (descoberta), que é executado antes que os outros nós e todos os nós se registrem nesse serviço e solicitem os endereços de outros nós. - Se podemos modificar o
/etc/hosts , podemos usar nomes de host predefinidos (como my-project-main-node e echo-backend ) e apenas vincular esses nomes
com endereços IP durante a implantação.
No quadro deste post, não consideraremos esses casos com mais detalhes. Para o nosso
Em um exemplo de brinquedo, todos os nós terão um endereço IP - 127.0.0.1 .
Em seguida, consideramos duas opções para um sistema distribuído:
- Colocação de todos os serviços em um nó.
- E a colocação do serviço de eco e do cliente de eco em diferentes nós.
Configuração para um único nó :
Configuração de nó único object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
O objeto implementa a configuração do cliente e do servidor. A configuração da vida útil também é usada para finalizar o programa após uma lifetime . (Ctrl-C também funciona e libera todos os recursos corretamente.)
O mesmo conjunto de características e implementações de configuração pode ser usado para criar um sistema que consiste em dois nós separados :
Configuração para dois nós object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Importante! Observe como a ligação do serviço é executada. Indicamos o serviço implementado por um nó como a implementação do método de dependência de outro nó. O tipo de dependência é verificado pelo compilador, porque contém o tipo de protocolo. Quando iniciada, a dependência conterá o identificador correto do nó de destino. Graças a esse esquema, indicamos o número da porta exatamente uma vez e sempre garantimos a referência à porta correta.
Implementação de dois nós do sistemaPara esta configuração, usamos a mesma implementação de serviço sem alterações. A única diferença é que agora temos dois objetos que implementam conjuntos diferentes de serviços:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
O primeiro nó implementa o servidor e precisa apenas da configuração do servidor. O segundo nó é implementado pelo cliente e usa outra parte da configuração. Ambos os nós também precisam gerenciar o tempo de vida. O nó do servidor é executado indefinidamente até ser parado pelo SIGTERM e o nó do cliente termina após algum tempo. Veja o aplicativo de inicialização .
Processo geral de desenvolvimento
Vamos ver como essa abordagem de configuração afeta o processo geral de desenvolvimento.
A configuração será compilada junto com o restante do código e um artefato (.jar) será gerado. Aparentemente, faz sentido colocar a configuração em um artefato separado. Isso se deve ao fato de podermos ter muitas configurações baseadas no mesmo código. Novamente, você pode gerar artefatos que correspondem a diferentes ramificações de configuração. Juntamente com a configuração, as dependências de versões específicas das bibliotecas são preservadas e essas versões são preservadas para sempre, sempre que decidirmos implantar essa versão da configuração.
Qualquer alteração na configuração se transforma em uma alteração no código. E, portanto, cada um desses
A mudança será coberta pelo processo usual de garantia de qualidade:
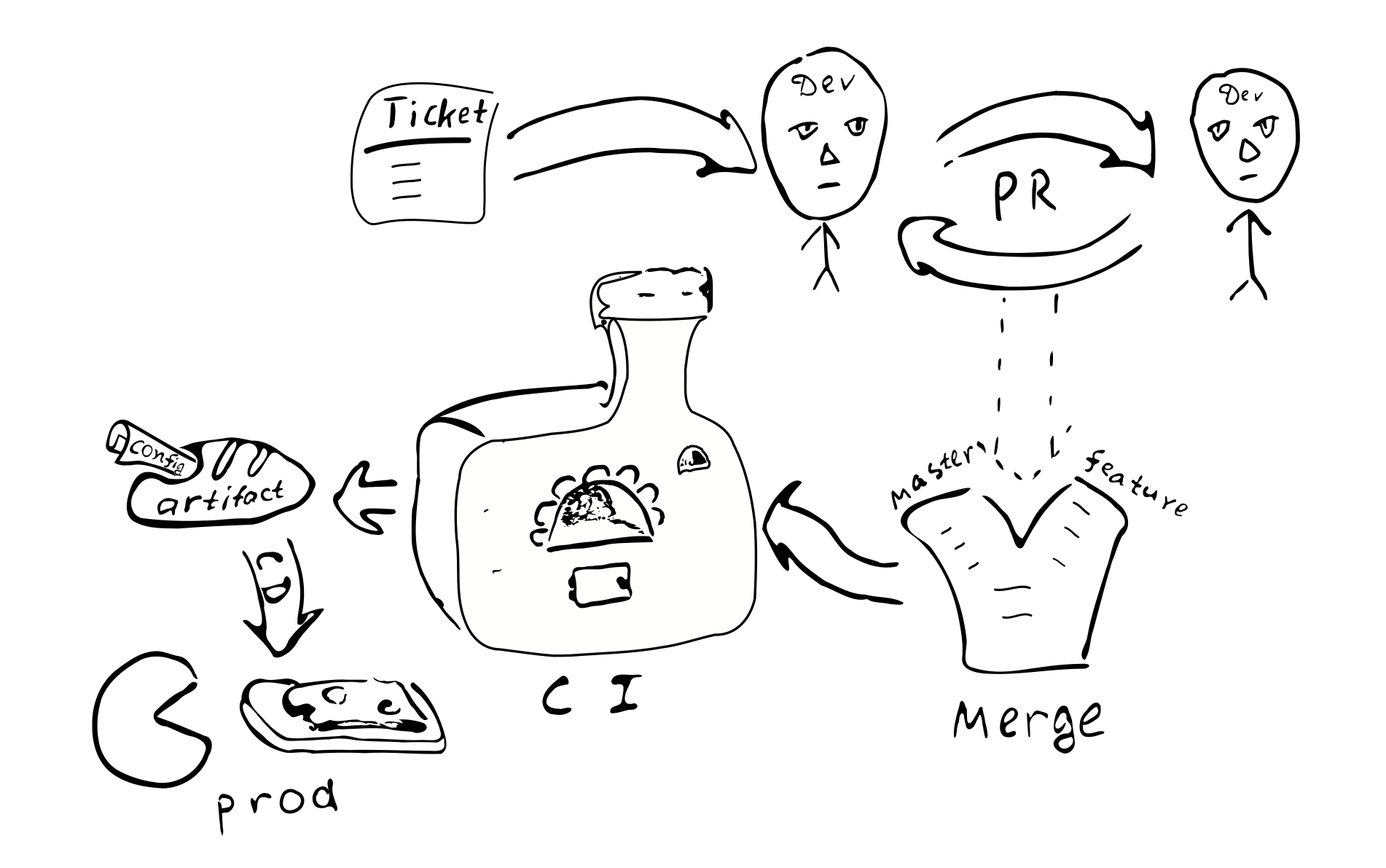
Um ticket no bugtracker -> PR -> review -> mesclar com os ramos correspondentes ->
integração -> implantação
As principais conseqüências da implementação de uma configuração compilada:
A configuração será coordenada em todos os nós do sistema distribuído. Devido ao fato de que todos os nós recebem a mesma configuração de uma única fonte.
É problemático alterar a configuração em apenas um dos nós. Portanto, “desvio de configuração” é improvável.
Torna-se mais difícil fazer pequenas alterações na configuração.
A maioria das alterações na configuração ocorrerá como parte do processo geral de desenvolvimento e será revisada.
Preciso de um repositório separado para armazenar a configuração de produção? Essa configuração pode conter senhas e outras informações secretas, acesso ao qual gostaríamos de restringir. Com base nisso, parece fazer sentido armazenar a configuração final em um repositório separado. Você pode dividir a configuração em duas partes - uma contendo as definições de configuração pública e a outra contendo as configurações de acesso restrito. Isso permitirá que a maioria dos desenvolvedores tenha acesso a parâmetros comuns. É fácil conseguir essa separação usando características intermediárias que contêm valores padrão.
Possíveis variações
Vamos tentar comparar a configuração compilada com algumas alternativas comuns:
- Um arquivo de texto na máquina de destino.
- Armazenamento centralizado de valor-chave (
etcd / zookeeper ). - Componentes do processo que podem ser reconfigurados / reiniciados sem reiniciar o processo.
- Armazenamento da configuração fora do artefato e controle de versão.
Os arquivos de texto fornecem flexibilidade significativa em termos de pequenas alterações. O administrador do sistema pode ir para o nó remoto, fazer alterações nos arquivos correspondentes e reiniciar o serviço. Para sistemas grandes, no entanto, essa flexibilidade pode ser indesejável. Das alterações feitas, não há vestígios em outros sistemas. Ninguém analisa as alterações. É difícil estabelecer quem fez as alterações e por que motivo. As alterações não são testadas. Se o sistema for distribuído, o administrador poderá esquecer de fazer a alteração correspondente em outros nós.
(Observe também que o uso de uma configuração compilada não bloqueia a possibilidade de usar arquivos de texto no futuro. Será suficiente adicionar um analisador e validador que dê o mesmo tipo de Config que uma saída e você poderá usar arquivos de texto. Imediatamente, a complexidade do sistema com a configuração compilada é um pouco menor que a complexidade de um sistema que usa arquivos de texto, porque os arquivos de texto requerem código adicional.)
O armazenamento centralizado de valores-chave é um bom mecanismo para distribuir meta-parâmetros de um aplicativo distribuído. Devemos decidir quais são os parâmetros de configuração e o que são apenas dados. Suponha que tenhamos uma função C => A => B , com os parâmetros C raramente mudando e os dados A frequência. Nesse caso, podemos dizer que C são os parâmetros de configuração e A são os dados. Parece que os parâmetros de configuração diferem dos dados, pois geralmente mudam com menos frequência do que os dados. Além disso, os dados geralmente vêm de uma fonte (do usuário) e os parâmetros de configuração de outra (do administrador do sistema).
Se raramente é necessário atualizar os parâmetros que precisam ser alterados sem reiniciar o programa, isso geralmente pode levar a uma complicação do programa, porque precisaremos fornecer os parâmetros de alguma forma, armazenar, analisar e verificar, processar valores incorretos. Portanto, do ponto de vista da redução da complexidade do programa, faz sentido reduzir o número de parâmetros que podem ser alterados durante o programa (ou não oferecer suporte a esses parâmetros).
Do ponto de vista deste post, distinguiremos entre parâmetros estáticos e dinâmicos. Se a lógica do serviço exigir alteração de parâmetros durante o programa, chamaremos esses parâmetros de dinâmicos. Caso contrário, os parâmetros são estáticos e podem ser configurados usando uma configuração compilada. Para reconfiguração dinâmica, podemos precisar de um mecanismo para reiniciar partes do programa com novos parâmetros, semelhante à maneira como os processos do sistema operacional são reiniciados. (Em nossa opinião, é aconselhável evitar a reconfiguração em tempo real, pois a complexidade do sistema aumenta. Se possível, é melhor usar os recursos padrão do sistema operacional para reiniciar os processos.)
Um aspecto importante do uso de uma configuração estática que força as pessoas a considerar a reconfiguração dinâmica é o tempo que o sistema leva para reiniciar após uma atualização de configuração (tempo de inatividade). De fato, se precisarmos fazer alterações na configuração estática, teremos que reiniciar o sistema para que os novos valores entrem em vigor. O problema do tempo de inatividade tem uma gravidade diferente para diferentes sistemas. Em alguns casos, você pode agendar uma reinicialização no momento em que a carga for mínima. Se você deseja fornecer serviço contínuo, pode implementar as "conexões de drenagem" (drenagem da conexão do AWS ELB) . Ao mesmo tempo, quando precisamos reiniciar o sistema, lançamos uma instância paralela desse sistema, mudamos o balanceador para ele e aguardamos até que as conexões antigas sejam concluídas. Depois que todas as conexões antigas forem concluídas, desativamos a instância antiga do sistema.
Vamos agora considerar a questão de armazenar a configuração dentro ou fora do artefato. Se armazenarmos a configuração dentro do artefato, pelo menos tivemos a oportunidade durante a montagem do artefato para garantir que a configuração esteja correta. Se a configuração estiver fora do artefato controlado, será difícil rastrear quem e por que fez alterações nesse arquivo. Quão importante é isso? Em nossa opinião, para muitos sistemas de produção, é importante ter uma configuração estável e de alta qualidade.
A versão do artefato permite determinar quando ele foi criado, quais valores ele contém, quais funções estão ativadas / desativadas, quem é responsável por qualquer alteração na configuração. Obviamente, armazenar a configuração dentro do artefato requer algum esforço, portanto, é necessário tomar uma decisão informada.
Os prós e contras
Gostaria de me debruçar sobre os prós e contras da tecnologia proposta.
Os benefícios
A seguir, é apresentada uma lista dos principais recursos de uma configuração de sistema distribuído compilado:
- Verificação de configuração estática. Permite que você tenha certeza de que
A configuração está correta. - . . Scala , . ,
trait' , , val', (DRY) . ( Seq , Map , ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- . , . , , — . production- .
- Teste. mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList (case class') . - , : (
package , import , ; override def ' , ). , DSL. , (, XML), . - .
Conclusão
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
, .