 Conforme prometido
Conforme prometido , continuamos a falar sobre o desenvolvimento
dos processadores Elbrus . Este artigo é técnico. As informações fornecidas no artigo não são documentação oficial, porque foram obtidas durante o estudo de Elbrus como uma caixa preta. Mas certamente será interessante para uma melhor compreensão da arquitetura Elbrus, porque, embora tivéssemos documentação oficial, muitos detalhes ficaram claros somente após longas experiências, quando a
Embox funcionou.
Lembre-se de que no
artigo anterior falamos sobre a inicialização básica do sistema e o driver da porta serial. A Embox começou, mas para mais avanços precisávamos de interrupções, um cronômetro do sistema e, é claro, eu gostaria de incluir algum conjunto de testes de unidade, e para isso precisamos do setjmp. Este artigo se concentrará em registros, pilhas e outros detalhes técnicos necessários para implementar todas essas coisas.
Vamos começar com uma breve introdução à arquitetura, que é a informação mínima necessária para entender o que será discutido mais adiante. No futuro, vamos nos referir às informações desta seção.
Breve introdução: pilhas
Existem três pilhas em Elbrus:
- Pilha de procedimentos (PS)
- Pilha de cadeia de procedimentos (PCS)
- Pilha de usuários (EUA)
Vamos analisá-los com mais detalhes. Os endereços na figura são condicionais, mostram em que direção os movimentos são direcionados - de um endereço maior para um menor ou vice-versa.

A pilha de procedimentos (PS) destina-se a dados alocados a registros "operacionais".
Por exemplo, podem ser argumentos de função; em arquiteturas "comuns", esse conceito é o mais próximo dos registros de uso geral. Diferentemente das arquiteturas de processador "regulares", no E2K, os registros usados nas funções são empilhados em uma pilha separada.
A pilha de informações de encadernação (PCS) foi projetada para colocar informações sobre o procedimento anterior (de chamada) e usada ao retornar. Os dados no endereço de retorno, assim como no caso dos registros, são colocados em um local separado. Portanto, a promoção de pilha (por exemplo, para sair por exceção em C ++) é um processo mais demorado do que nas arquiteturas "comuns". Por outro lado, isso elimina problemas de estouro de pilha.
Ambas as pilhas (PS e PCS) são caracterizadas por um endereço base, tamanho e deslocamento de corrente. Esses parâmetros são definidos nos registros PSP e PCSP, são de 128 bits e no assembler você precisa se referir a campos específicos (por exemplo, alto ou baixo). Além disso, o funcionamento das pilhas está intimamente relacionado ao conceito de um arquivo de registro, mais sobre isso abaixo. A interação com o arquivo ocorre através do mecanismo de registros de bombeamento / troca. Um papel ativo nesse mecanismo é desempenhado pelo chamado "ponteiro de hardware para o topo da pilha" das informações processuais ou da pilha de informações de ligação, respectivamente. Sobre isso também abaixo. É importante que, a cada momento, os dados dessas pilhas estejam na RAM ou em um arquivo de registro.
Também é importante notar que essas pilhas (a pilha processual e a pilha de informações vinculativas) crescem. Nos deparamos com isso quando implementamos context_switch.
A pilha do usuário também recebe o endereço e o tamanho base. O ponteiro atual está no registro USD.lo. Na sua essência, é uma pilha clássica que cresce. Somente, diferentemente das arquiteturas "comuns", as informações de outras pilhas (registros e endereços de retorno) não se encaixam lá.
Um requisito não padrão, na minha opinião, para os limites e tamanhos das pilhas é o alinhamento de 4Kb, e o endereço base da pilha e seu tamanho devem estar alinhados com 4Kb. Em outras arquiteturas, não atendi a essa restrição. Encontramos esse detalhe novamente quando implementamos context_switch.
Breve introdução: Registros. Registre arquivos. Janelas de registro
Agora que descobrimos um pouco as pilhas, precisamos entender como as informações são apresentadas nelas. Para fazer isso, precisamos introduzir mais alguns conceitos.
Um arquivo de registro (RF) é um conjunto de todos os registros. Existem dois arquivos de registro que precisamos: um arquivo de informações de conexão (arquivo de cadeia - CF), o outro é chamado de arquivo de registro (RF); ele armazena registros “operacionais”, que são armazenados na pilha de procedimentos.
A janela Registro é a área (conjunto de registros) do arquivo de registro atualmente disponível.
Vou explicar com mais detalhes. O que é um conjunto de registros, eu acho, ninguém precisa explicar.
É sabido que um dos gargalos da arquitetura x86 é precisamente um pequeno número de registros. Nas arquiteturas RISC com registros, é mais simples, geralmente em torno de 16 registros, dos quais vários (2-3) são ocupados por necessidades oficiais. Por que não fazer apenas 128 registros, porque parece que isso aumentará o desempenho do sistema? A resposta é bastante simples: uma instrução de processador precisa de um local para armazenar o endereço de registro e, se houver muitas delas, também serão necessários muitos bits para isso. Portanto, eles fazem todo tipo de truque, fazem registros de sombra, registram bancos, janelas e assim por diante. Por registradores-sombra, quero dizer o princípio da organização de registros no ARM. Se ocorrer uma interrupção ou outra situação, um conjunto diferente de registros com os mesmos nomes (números) estará disponível, enquanto as informações armazenadas no conjunto original permanecem lá. Os bancos de registradores, de fato, são muito semelhantes aos registradores-sombra, simplesmente não há troca de hardware dos conjuntos de registradores, e o programador escolhe qual banco (conjunto de registradores) deve entrar em contato agora.
As janelas de registro foram projetadas para otimizar o trabalho com a pilha. Como você provavelmente entende, em uma arquitetura “normal”, você insere um procedimento, salva os registros na pilha (ou o procedimento de chamada salva, depende do contrato) e pode usar os registros, porque as informações já estão armazenadas na pilha. Mas o acesso à memória é lento e, portanto, deve ser evitado. Ao entrar no procedimento, vamos disponibilizar um novo conjunto de registros, os dados do antigo serão salvos, o que significa que você não precisa despejá-los na memória. Além disso, quando você retornar ao procedimento de chamada, a janela de registro anterior também retornará, portanto, todos os dados nos registros serão relevantes. Este é o conceito de uma janela de registro.
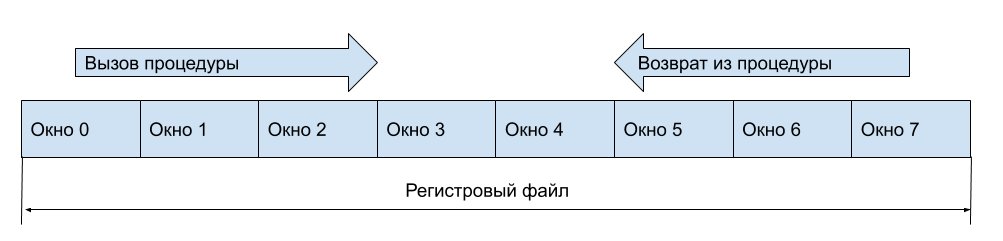
É claro que você ainda precisa salvar os registros na pilha (na memória), mas isso pode ser feito quando as janelas de registro gratuito terminarem.
E o que fazer com os registros de entrada e saída (argumentos ao inserir a função e o resultado retornado)? Deixe a janela conter parte dos registros visíveis na janela anterior, mais precisamente, parte dos registros estará disponível para ambas as janelas. Então, em geral, ao chamar uma função, você não precisa acessar a memória. Suponha que nossos registros sejam assim
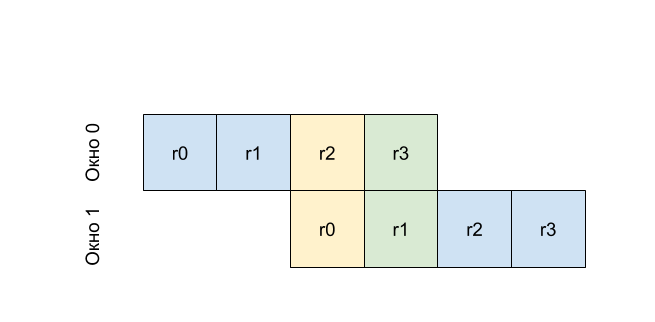
Ou seja, r0 na primeira janela será o mesmo registro que r2 em zero e r1 da primeira janela no mesmo registro que r3. Ou seja, escrevendo em r2 antes de chamar o procedimento (alterando o número da janela) obtemos o valor em r0 no procedimento chamado. Este princípio é chamado de mecanismo de rotação das janelas.
Vamos otimizar um pouco mais, porque os criadores da Elbrus fizeram exatamente isso. Deixe que as janelas que temos não sejam de tamanho fixo, mas variáveis, o tamanho da janela pode ser definido no momento da entrada no procedimento. Faremos o mesmo com o número de registros rotacionados. É claro que isso nos levará a alguns problemas, porque, nas janelas rotativas clássicas, existe um índice de janelas através do qual é determinado que você precisa salvar os dados do arquivo de registro na pilha ou carregá-los. Mas se você não inserir o índice da janela, mas o índice do registro a partir do qual nossa janela atual é iniciada, esse problema não surgirá. No Elbrus, esses índices estão contidos nos registros PSHTP (para a pilha de procedimentos PS) e PCSHTP (para a pilha de informações processuais do PCS). A documentação refere-se a "ponteiros de hardware para o topo da pilha". Agora você pode tentar novamente ler sobre as pilhas, acho que ficará mais claro.
Como você entende, esse mecanismo implica que você tem a capacidade de controlar o que está na memória. Ou seja, sincronize o arquivo de registro e a pilha. Quero dizer um programador de sistemas. Se você é um programador de aplicativos, o equipamento fornecerá entrada e saída transparentes do procedimento. Ou seja, se não houver registros suficientes ao tentar selecionar uma nova janela, a janela de registro será "bombeada" automaticamente. Nesse caso, todos os dados do arquivo de registro serão salvos na pilha apropriada (na memória) e o "ponteiro para o topo da pilha" (índice de deslocamento) será zerado. Da mesma forma, a troca de um arquivo de registro da pilha ocorre automaticamente. Mas se você estiver desenvolvendo, por exemplo, a alternância de contexto, que é exatamente o que fizemos, precisará de um mecanismo para trabalhar com a parte oculta do arquivo de registro. No Elbrus, os comandos FLUSHR e FLUSHC são usados para isso. FLUSHR - limpando o arquivo de registro, todas as janelas, exceto a atual, são liberadas para a pilha de procedimentos, o índice PSHTP é redefinido para zero. FLUSHC - limpa o arquivo de informações de ligação, tudo, exceto a janela atual, é despejado na pilha de informações de ligação, o índice PCSHTP também é redefinido para zero.
Breve introdução: Implementação em Elbrus
Agora que discutimos o trabalho não óbvio com registros e pilhas, falaremos mais especificamente sobre várias situações no Elbrus.
Quando entramos na próxima função, o processador cria duas janelas: uma janela na pilha PS e uma janela na pilha PCS.
Uma janela na pilha PCS contém as informações necessárias para retornar de uma função: por exemplo, IP (Ponteiro de Instrução) da instrução na qual você precisará retornar da função. Com isso, tudo fica mais ou menos claro.
A janela na pilha PS é um pouco mais complicada. O conceito de registros da janela atual é introduzido. Nesta janela, você tem acesso aos registros da janela atual -% dr0,% dr1, ...,% dr15, ... Ou seja, para nós, como usuário, eles sempre são numerados de 0, mas isso é numerado em relação ao endereço base da janela atual. Por meio desses registradores, os argumentos são passados quando a função é chamada e o valor é retornado, e a função é usada como registrador de uso geral dentro da função. Na verdade, isso foi explicado ao considerar o mecanismo de rotação das janelas de registro.
O tamanho da janela de registro no Elbrus pode ser controlado. Isso, como eu disse, é necessário para otimização. Por exemplo, em uma função, precisamos de apenas 4 registros para passar argumentos e alguns cálculos; nesse caso, o programador (ou compilador) decide quantos registros serão alocados para a função e, com base nisso, define o tamanho da janela. O tamanho da janela é definido pela operação setwd:
setwd wsz=0x10
Especifica o tamanho da janela em termos de registradores quádruplos (registradores de 128 bits).

Agora, digamos que você queira chamar uma função a partir de uma função. Para isso, o conceito já descrito de uma janela de registro girado é aplicado. A figura acima mostra um fragmento de um arquivo de registro em que uma função com a janela 1 (verde) chama uma função com a janela 2 (laranja). Em cada uma dessas duas funções, você terá acesso aos seus% dr0,% dr1, ... Mas os argumentos serão passados pelos chamados registros rotativos. Em outras palavras, parte dos registros da janela 1 se tornarão os registros da janela 2 (observe que essas duas janelas se cruzam). Esses registros também são definidos pela janela (veja os registros do Rotary na figura) e têm o endereço% db [0],% db [1], ... Portanto, o registro% dr0 na janela 2 nada mais é do que o registro% db [0] em janela 1.
A janela de registro de rotação é definida pela operação setbn:
setbn rbs = 0x3, rsz = 0x8
rbs define o tamanho da janela girada e rsz define o endereço base, mas em relação à janela de registro atual. I.e. Aqui, alocamos três registros, começando no dia 8.
Com base no exposto, mostramos como é a chamada de função. Para simplificar, supomos que a função use um argumento:
void my_func(uint64_t a) { }
Então, para chamar essa função, você precisa preparar uma janela de registros rotativos (já fizemos isso via setbn). Em seguida, no registro% db0, colocamos o valor que será passado para my_func. Depois disso, você precisa chamar a instrução CALL e não se esqueça de dizer a ela onde a janela dos registros girados começa. Ignoramos a preparação para a chamada (o comando disp) agora, porque não diferencia maiúsculas de minúsculas. Como resultado, no assembler, uma chamada para esta função deve ser assim:
addd 0, %dr9, %db[0] disp %ctpr1, my_func call %ctpr1, wbs = 0x8
Então, com registros um pouco descobri. Agora vamos ver a pilha de informações vinculativas. Ele armazena os chamados registros CR. De fato, dois - CR0, CR1. E eles já contêm as informações necessárias para retornar da função.

Os registradores CR0 e CR1 da janela da função que chamou a função com os registradores marcados em laranja são verdes. Os registradores CR0 contêm o ponteiro de instruções da função de chamada e um determinado arquivo predicado (PF-Predicate File), uma história sobre isso definitivamente está além do escopo deste artigo.
Os registros CR1 contêm dados como PSR (status do processador de texto), número da janela, tamanho da janela e assim por diante. No Elbrus, tudo é tão flexível que todo procedimento armazena informações no CR1, inclusive sobre se a operação de ponto flutuante está incluída no procedimento e um registro contendo informações sobre exceções de software, mas é claro que você precisa pagar para salvar informações adicionais.
É muito importante não esquecer que o arquivo de registro e o arquivo de informações de ligação podem ser extraídos e trocados da memória principal e vice-versa (das pilhas PS e PCS descritas acima). Este ponto é importante ao implementar o setjmp descrito posteriormente.
SETJMP / LONGJMP
E, finalmente, pelo menos de alguma maneira, entendendo como as pilhas e os registros são organizados no Elbrus, você pode começar a fazer algo útil, ou seja, adicionar novas funcionalidades ao Embox.
Na Embox, o sistema de teste de unidade requer setjmp / longjmp, portanto tivemos que implementar essas funções.
Para a implementação, é necessário salvar / restaurar os registros: CR0, CR1, PSP, PCSP, USD, - já familiares para nós a partir de uma breve introdução. De fato, salvar / restaurar é implementado em nossa testa, mas há uma nuance significativa que muitas vezes foi sugerida na descrição de pilhas e registros, a saber: pilhas devem ser sincronizadas, porque estão localizadas não apenas na memória, mas também no arquivo de registro. Essa nuance significa que você precisa cuidar de vários recursos, sem os quais nada funcionará.
O primeiro recurso é desativar as interrupções durante o salvamento e a restauração. Ao restaurar uma interrupção, é obrigatório proibir, caso contrário, pode surgir uma situação em que entramos no manipulador de interrupções com pilhas com meia comutação (referindo-se ao bombeamento da troca de arquivos de registro descrita na “descrição resumida”). E ao salvar, o problema é que, após entrar e sair da interrupção, o processador pode novamente trocar parte do arquivo de registro da RAM (e isso arruinará as condições invariantes PSHTP = 0 e PSCHTP = 0, um pouco mais sobre elas). É por isso que, tanto no setjmp quanto no longjmp, as interrupções devem ser desativadas. Também deve ser observado aqui que especialistas do MCST nos aconselharam a usar colchetes atômicos em vez de desativar interrupções, mas, por enquanto, usamos a implementação mais simples (compreensível para nós).
O segundo recurso está relacionado ao bombeamento / extração de um arquivo de registro da memória. É o seguinte. O arquivo de registro tem um tamanho limitado e, portanto, é frequentemente bombeado para a memória e vice-versa. Portanto, se simplesmente salvarmos os valores dos registros PSP e PSHTP, fixaremos o valor do ponteiro atual na memória e no arquivo de registro. Porém, como o arquivo de registro está mudando, no momento da restauração do contexto, ele indica dados já incorretos (não aqueles que “salvamos”). Para evitar isso, você precisa liberar todo o arquivo de registro na memória. Assim, ao salvar em setjmp, temos os registros PSP.ind na memória e registros PSHTP.ind na janela de registro. Acontece que você precisa salvar todos os registros PCSP.ind + PCSHTP.ind. A seguir está a função que executa esta operação:
.type update_pcsp_ind,@function $update_pcsp_ind: setwd wsz = 0x4, nfx = 0x0 shld %dr1, (64 - 10), %dr1 shrd %dr1, (64 - 10), %dr1 addd %dr1, %dr0, %dr0 E2K_ASM_RETURN
Também é necessário esclarecer um pequeno ponto neste código descrito no comentário, ou seja, é necessário expandir programaticamente o caractere no índice PCSHTP.ind, porque o índice pode ser negativo e armazenado em código adicional. Para fazer isso, primeiro mudamos para (64-10) para a esquerda (registro de 64 bits), para um campo de 10 bits e depois voltamos.
O mesmo vale para o PSP (pilha de procedimentos)
.type update_psp_ind,@function $update_psp_ind: setwd wsz = 0x4, nfx = 0x0 shld %dr1, (64 - 12), %dr1 shrd %dr1, (64 - 12), %dr1 muld %dr1, 2, %dr1 addd %dr1, %dr0, %dr0 E2K_ASM_RETURN
Com uma pequena diferença (o campo é de 12 bits e os registradores são contados em termos de 128 bits, ou seja, o valor deve ser multiplicado por 2).
Código Setjmp em si
C_ENTRY(setjmp): setwd wsz = 0x14, nfx = 0x0 setbn rsz = 0x3, rbs = 0x10, rcur = 0x0 disp %ctpr1, ipl_save ipd 3 call %ctpr1, wbs = 0x10 addd 0, %db[0], %dr9 rrd %cr0.hi, %dr1 rrd %cr1.lo, %dr2 rrd %cr1.hi, %dr3 rrd %usd.lo, %dr4 rrd %usd.hi, %dr5 rrd %psp.hi, %dr6 rrd %pshtp, %dr7 addd 0, %dr6, %db[0] addd 0, %dr7, %db[1] disp %ctpr1, update_psp_ind ipd 3 call %ctpr1, wbs = 0x10 addd 0, %db[0], %dr6 rrd %pcsp.hi, %dr7 rrd %pcshtp, %dr8 addd 0, %dr7, %db[0] addd 0, %dr8, %db[1] disp %ctpr1, update_pcsp_ind ipd 3 call %ctpr1, wbs = 0x10 addd 0, %db[0], %dr7 std %dr1, [%dr0 + E2K_JMBBUFF_CR0_HI] std %dr2, [%dr0 + E2K_JMBBUFF_CR1_LO] std %dr3, [%dr0 + E2K_JMBBUFF_CR1_HI] std %dr4, [%dr0 + E2K_JMBBUFF_USD_LO] std %dr5, [%dr0 + E2K_JMBBUFF_USD_HI] std %dr6, [%dr0 + E2K_JMBBUFF_PSP_HI] std %dr7, [%dr0 + E2K_JMBBUFF_PCSP_HI] addd 0, %dr9, %db[0] disp %ctpr1, ipl_restore ipd 3 call %ctpr1, wbs = 0x10 adds 0, 0, %r0 E2K_ASM_RETURN
Ao implementar o longjmp, é importante não esquecer a sincronização dos dois arquivos de registro; portanto, é necessário liberar não apenas a janela de registro (flushr), mas também o arquivo do fichário (flushc). Vamos descrever a macro:
#define E2K_ASM_FLUSH_CPU \ flushr; \ nop 2; \ flushc; \ nop 3;
Agora que todas as informações estão na memória, podemos registrar com segurança a recuperação no longjmp.
C_ENTRY(longjmp): setwd wsz = 0x14, nfx = 0x0 setbn rsz = 0x3, rbs = 0x10, rcur = 0x0 disp %ctpr1, ipl_save ipd 3 call %ctpr1, wbs = 0x10 addd 0, %db[0], %dr9 E2K_ASM_FLUSH_CPU ldd [%dr0 + E2K_JMBBUFF_CR0_HI], %dr2 ldd [%dr0 + E2K_JMBBUFF_CR1_LO], %dr3 ldd [%dr0 + E2K_JMBBUFF_CR1_HI], %dr4 ldd [%dr0 + E2K_JMBBUFF_USD_LO], %dr5 ldd [%dr0 + E2K_JMBBUFF_USD_HI], %dr6 ldd [%dr0 + E2K_JMBBUFF_PSP_HI], %dr7 ldd [%dr0 + E2K_JMBBUFF_PCSP_HI], %dr8 rwd %dr2, %cr0.hi rwd %dr3, %cr1.lo rwd %dr4, %cr1.hi rwd %dr5, %usd.lo rwd %dr6, %usd.hi rwd %dr7, %psp.hi rwd %dr8, %pcsp.hi addd 0, %dr9, %db[0] disp %ctpr1, ipl_restore ipd 3 call %ctpr1, wbs = 0x10 adds 0, %r1, %r0 E2K_ASM_RETURN
Mudança de contexto
Depois que descobrimos o setjmp / longjmp, a implementação básica do context_switch parecia clara o suficiente para nós. De fato, como no primeiro caso, precisamos salvar / restaurar os registros de informações e pilhas de conexão, além de restaurar corretamente o registro de status do processador (UPSR).
Eu vou explicar Como no caso de setjmp, ao salvar registros, você deve primeiro redefinir o arquivo de registro e o arquivo de informações de ligação para a memória (flushr + flushc). Depois disso, precisamos salvar os valores atuais dos registradores CR0 e CR1 para que, quando retornarmos, pule exatamente para onde o fluxo atual foi alternado. Em seguida, salvamos os descritores das pilhas PS, PCS e US. E, finalmente, você precisa cuidar da restauração correta do modo de interrupção - para esses fins, também salvamos o registro UPSR.
Código do assembler context_switch:
C_ENTRY(context_switch): setwd wsz = 0x10, nfx = 0x0 rrd %upsr, %dr2 std %dr2, [%dr0 + E2K_CTX_UPSR] rrd %upsr, %dr2 andnd %dr2, (UPSR_IE | UPSR_NMIE), %dr2 rwd %dr2, %upsr E2K_ASM_FLUSH_CPU rrd %cr0.lo, %dr2 rrd %cr0.hi, %dr3 rrd %cr1.lo, %dr4 rrd %cr1.hi, %dr5 std %dr2, [%dr0 + E2K_CTX_CR0_LO] std %dr3, [%dr0 + E2K_CTX_CR0_HI] std %dr4, [%dr0 + E2K_CTX_CR1_LO] std %dr5, [%dr0 + E2K_CTX_CR1_HI] rrd %usd.lo, %dr3 rrd %usd.hi, %dr4 rrd %psp.lo, %dr5 rrd %psp.hi, %dr6 rrd %pcsp.lo, %dr7 rrd %pcsp.hi, %dr8 std %dr3, [%dr0 + E2K_CTX_USD_LO] std %dr4, [%dr0 + E2K_CTX_USD_HI] std %dr5, [%dr0 + E2K_CTX_PSP_LO] std %dr6, [%dr0 + E2K_CTX_PSP_HI] std %dr7, [%dr0 + E2K_CTX_PCSP_LO] std %dr8, [%dr0 + E2K_CTX_PCSP_HI] ldd [%dr1 + E2K_CTX_CR0_LO], %dr2 ldd [%dr1 + E2K_CTX_CR0_HI], %dr3 ldd [%dr1 + E2K_CTX_CR1_LO], %dr4 ldd [%dr1 + E2K_CTX_CR1_HI], %dr5 rwd %dr2, %cr0.lo rwd %dr3, %cr0.hi rwd %dr4, %cr1.lo rwd %dr5, %cr1.hi ldd [%dr1 + E2K_CTX_USD_LO], %dr3 ldd [%dr1 + E2K_CTX_USD_HI], %dr4 ldd [%dr1 + E2K_CTX_PSP_LO], %dr5 ldd [%dr1 + E2K_CTX_PSP_HI], %dr6 ldd [%dr1 + E2K_CTX_PCSP_LO], %dr7 ldd [%dr1 + E2K_CTX_PCSP_HI], %dr8 rwd %dr3, %usd.lo rwd %dr4, %usd.hi rwd %dr5, %psp.lo rwd %dr6, %psp.hi rwd %dr7, %pcsp.lo rwd %dr8, %pcsp.hi ldd [%dr1 + E2K_CTX_UPSR], %dr2 rwd %dr2, %upsr E2K_ASM_RETURN
Outro ponto importante é a inicialização do encadeamento do SO. Na Embox, cada thread possui um determinado procedimento primário
void _NORETURN thread_trampoline(void);
em que todo o trabalho adicional do fluxo será executado. Portanto, precisamos de alguma forma preparar as pilhas para chamar essa função, é aqui que nos deparamos com o fato de que existem três pilhas e elas não crescem na mesma direção. Por arquitetura, criamos um fluxo com uma única pilha, ou melhor, ele tem um único lugar abaixo da pilha, no topo temos uma estrutura que descreve o próprio fluxo e assim por diante, aqui tivemos que cuidar de pilhas diferentes, para não esquecer que elas deveriam estar alinhadas 4 kB, não esqueça todos os tipos de direitos de acesso e assim por diante.
Como resultado, no momento decidimos dividir o espaço sob a pilha em três partes, um quarto sob a pilha de informações de ligação, um quarto sob a pilha processual e metade sob a pilha do usuário.
Trago o código para que você possa avaliar o tamanho, é necessário considerar que isso é uma inicialização mínima. #define E2K_STACK_ALIGN (1UL << 12) #define round_down(x, bound) ((x) & ~((bound) - 1)) /* Reserve 1/4 for PSP stack, 1/4 for PCSP stack, and 1/2 for USD stack */ #define PSP_CALC_STACK_BASE(sp, size) binalign_bound(sp - size, E2K_STACK_ALIGN) #define PSP_CALC_STACK_SIZE(sp, size) binalign_bound((size) / 4, E2K_STACK_ALIGN) #define PCSP_CALC_STACK_BASE(sp, size) \ (PSP_CALC_STACK_BASE(sp, size) + PSP_CALC_STACK_SIZE(sp, size)) #define PCSP_CALC_STACK_SIZE(sp, size) binalign_bound((size) / 4, E2K_STACK_ALIGN) #define USD_CALC_STACK_BASE(sp, size) round_down(sp, E2K_STACK_ALIGN) #define USD_CALC_STACK_SIZE(sp, size) \ round_down(USD_CALC_STACK_BASE(sp, size) - PCSP_CALC_STACK_BASE(sp, size),\ E2K_STACK_ALIGN) static void e2k_calculate_stacks(struct context *ctx, uint64_t sp, uint64_t size) { uint64_t psp_size, pcsp_size, usd_size; log_debug("Stacks:\n"); ctx->psp_lo |= PSP_CALC_STACK_BASE(sp, size) << PSP_BASE; ctx->psp_lo |= E2_RWAR_RW_ENABLE << PSP_RW; psp_size = PSP_CALC_STACK_SIZE(sp, size); assert(psp_size); ctx->psp_hi |= psp_size << PSP_SIZE; log_debug(" PSP.base=0x%lx, PSP.size=0x%lx\n", PSP_CALC_STACK_BASE(sp, size), psp_size); ctx->pcsp_lo |= PCSP_CALC_STACK_BASE(sp, size) << PCSP_BASE; ctx->pcsp_lo |= E2_RWAR_RW_ENABLE << PCSP_RW; pcsp_size = PCSP_CALC_STACK_SIZE(sp, size); assert(pcsp_size); ctx->pcsp_hi |= pcsp_size << PCSP_SIZE; log_debug(" PCSP.base=0x%lx, PCSP.size=0x%lx\n", PCSP_CALC_STACK_BASE(sp, size), pcsp_size); ctx->usd_lo |= USD_CALC_STACK_BASE(sp, size) << USD_BASE; usd_size = USD_CALC_STACK_SIZE(sp, size); assert(usd_size); ctx->usd_hi |= usd_size << USD_SIZE; log_debug(" USD.base=0x%lx, USD.size=0x%lx\n", USD_CALC_STACK_BASE(sp, size), usd_size); } static void e2k_calculate_crs(struct context *ctx, uint64_t routine_addr) { uint64_t usd_size = (ctx->usd_hi >> USD_SIZE) & USD_SIZE_MASK; /* Reserve space in hardware stacks for @routine_addr */ /* Remark: We do not update psp.hi to reserve space for arguments, * since routine do not accepts any arguments. */ ctx->pcsp_hi |= SZ_OF_CR0_CR1 << PCSP_IND; ctx->cr0_hi |= (routine_addr >> CR0_IP) << CR0_IP; ctx->cr1_lo |= PSR_ALL_IRQ_ENABLED << CR1_PSR; /* Divide on 16 because it field contains size in terms * of 128 bit values. */ ctx->cr1_hi |= (usd_size >> 4) << CR1_USSZ; } void context_init(struct context *ctx, unsigned int flags, void (*routine_fn)(void), void *sp, unsigned int stack_size) { memset(ctx, 0, sizeof(*ctx)); e2k_calculate_stacks(ctx, sp, stack_size); e2k_calculate_crs(ctx, (uint64_t) routine_fn); if (!(flags & CONTEXT_IRQDISABLE)) { ctx->upsr |= (UPSR_IE | UPSR_NMIE); } }
O artigo também continha trabalhos com interrupções, exceções e temporizadores, mas, como ficou tão grande, decidimos falar sobre isso na
próxima parte .
Por precaução, repito, este material não é uma documentação oficial! Para suporte oficial, documentação e o restante, você precisa entrar em contato diretamente com o ICST. O código na
Embox , é claro, está aberto, mas para compilá-lo, você precisará de um compilador cruzado, que, novamente, pode ser obtido no
MCST .