Olá pessoal, estamos compartilhando com você a segunda parte da publicação “Sistemas de arquivos virtuais no Linux: por que eles são necessários e como funcionam?” A primeira parte pode ser lida
aqui . Lembre-se de que esta série de publicações é dedicada ao lançamento de um novo thread no curso
Linux Administrator , que começará muito em breve.
Como assistir ao VFS com ferramentas eBPF e ccoA maneira mais fácil de entender como o kernel opera nos arquivos
sysfs é observá-lo na prática, e a maneira mais fácil de observar o ARM64 é usar o eBPF. O eBPF (abreviação de Berkeley Packet Filter) consiste em uma máquina virtual em execução no
kernel que usuários privilegiados podem
query na linha de comando. As fontes do kernel dizem ao leitor o que o kernel pode fazer; A execução de ferramentas eBPF em um sistema ocupado mostra o que o kernel realmente faz.

Felizmente, começar a usar o eBPF é bastante fácil com as ferramentas
bcc , que estão disponíveis como pacotes na
distribuição geral do Linux e são documentadas em detalhes por
Bernard Gregg .
bcc ferramentas
bcc são scripts Python com pequenas inserções de código C, o que significa que qualquer pessoa familiarizada com os dois idiomas pode modificá-los facilmente. Existem 80 scripts Python em
bcc/tools , o que significa que provavelmente o desenvolvedor ou administrador do sistema poderá escolher algo adequado para resolver o problema.
Para ter uma idéia superficial do que o VFS faz em um sistema em execução, tente
vfscount ou
vfsstat . Isso mostrará, por exemplo, que dezenas de chamadas para
vfs_open() e "seus amigos" ocorrem literalmente a cada segundo.
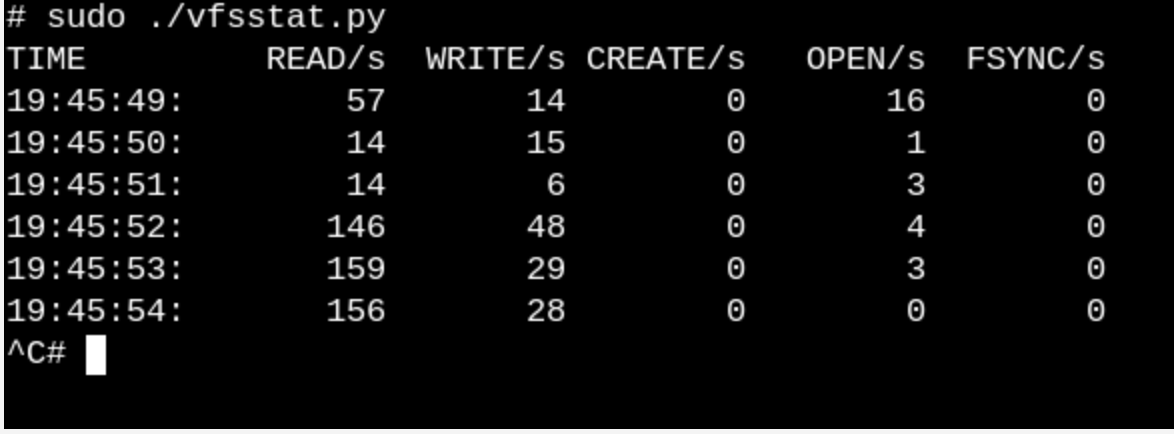
vfsstat.py é um script Python com inserções de código C que simplesmente conta as chamadas de função do VFS.
Damos um exemplo mais trivial e vemos o que acontece quando inserimos uma unidade flash USB em um computador e o sistema a detecta.
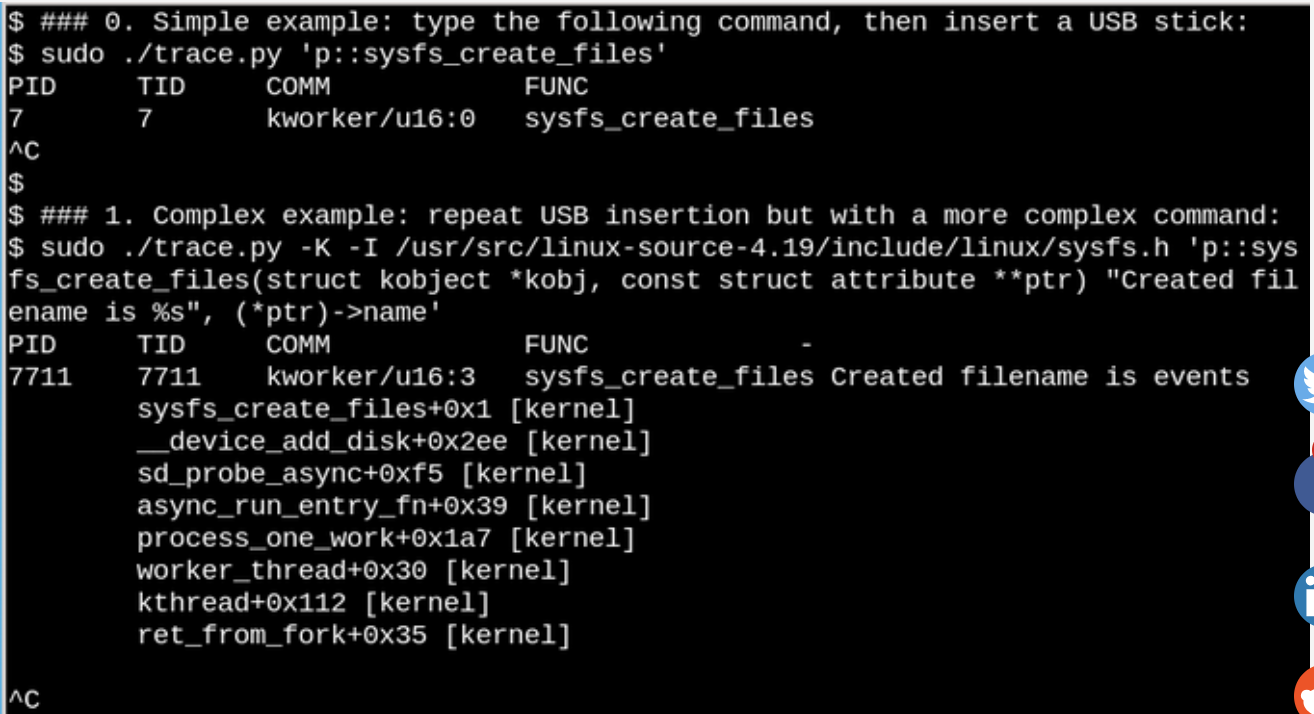
Usando o eBPF, você pode ver o que acontece em /sys quando uma unidade flash USB é inserida. Um exemplo simples e complexo é mostrado aqui.
No exemplo acima, a ferramenta
bcc trace.py exibe uma mensagem quando o comando
sysfs_create_files() é
sysfs_create_files() . Vimos que
sysfs_create_files() foi iniciado usando o fluxo do
kworker em resposta à unidade flash sendo inserida, mas qual arquivo foi criado? O segundo exemplo mostra todo o poder do eBPF. Aqui
trace.py exibe o backtrace do kernel (opção -K) e o nome do arquivo criado por
sysfs_create_files() . A inserção de instrução única é um código C que inclui uma sequência de formatos facilmente reconhecível fornecida por um script Python que executa o compilador
just-in-time do LLVM. Ele compila e executa essa linha em uma máquina virtual dentro do kernel. A assinatura completa da função
sysfs_create_files () deve ser reproduzida no segundo comando para que a cadeia de formato possa se referir a um dos parâmetros. Erros neste fragmento de código C resultam em erros reconhecíveis do compilador C. Por exemplo, se você omitir a opção -l, verá "Falha ao compilar o texto BPF". Os desenvolvedores familiarizados com C e Python acharão as ferramentas
bcc fáceis de expandir e modificar.
Quando uma unidade USB é inserida, um
kworker kernel mostrará que o PID 7711 é o fluxo do
kworker que criou o arquivo
«events» no
sysfs . Assim, uma chamada com
sysfs_remove_files() mostrará que a remoção da unidade excluiu o arquivo de
events , o que está alinhado com o conceito geral de contagem de referência. Ao mesmo tempo, visualizar
sysfs_create_link () com o eBPF ao inserir uma unidade USB mostrará que pelo menos 48 links simbólicos foram criados.
Então, qual é o significado do arquivo de eventos? O uso do
cscope para procurar
__device_add_disk () mostra que ele chama
disk_add_events () , e
"media_change" ou
"eject_request" podem ser gravados no arquivo de evento. Aqui, a camada de bloco do kernel informa o espaço do usuário da aparência e extração do "disco". Observe o quão informativo esse método de pesquisa é pelo exemplo de inserção de uma unidade USB em comparação com a tentativa de descobrir como tudo funciona, exclusivamente a partir da fonte.
Os sistemas de arquivos raiz somente leitura permitem dispositivos incorporadosObviamente, ninguém desliga o servidor ou o computador, puxando o plugue da tomada. Mas porque? E tudo porque os sistemas de arquivos montados em dispositivos de armazenamento físico podem ter registros pendentes e as estruturas de dados que registram seu estado podem não ser sincronizadas com os registros no armazenamento. Quando isso acontece, os proprietários do sistema precisam aguardar a próxima inicialização para executar o
fsck filesystem-recovery e, na pior das hipóteses, perder dados.
No entanto, todos sabemos que muitos dispositivos de IoT, além de roteadores, termostatos e carros, agora estão executando o Linux. Muitos desses dispositivos praticamente não têm interface com o usuário e não há como desativá-los "de maneira limpa". Imagine iniciar um carro com uma bateria descarregada, quando a energia do dispositivo de controle no
Linux constantemente sobe e desce. Como é que o sistema é inicializado sem um longo
fsck quando o mecanismo finalmente começa a funcionar? E a resposta é simples. Os dispositivos incorporados contam com um sistema de arquivos raiz somente leitura (abreviado como
ro-rootfs (sistema de arquivos raiz somente leitura)).
ro-rootfs oferece muitos benefícios menos óbvios do que genuínos. Uma vantagem é que o malware não pode gravar em
/usr ou
/lib se nenhum processo Linux puder escrever nele. Outra é que um sistema de arquivos amplamente imutável é essencial para o suporte de campo a dispositivos remotos, pois a equipe de suporte usa sistemas locais que são nominalmente idênticos aos sistemas locais. Talvez a vantagem mais importante (mas também a mais insidiosa) seja que o ro-rootfs força os desenvolvedores a decidir quais objetos do sistema serão alterados, mesmo no estágio de design do sistema. Trabalhar com ro-rootfs pode ser desconfortável e doloroso, como geralmente ocorre com variáveis const em linguagens de programação, mas seus benefícios podem facilmente cobrir a sobrecarga extra.
Criar
rootfs somente
rootfs requer um esforço extra para desenvolvedores incorporados, e é aí que o VFS entra em cena. O Linux exige que os arquivos em
/var sejam graváveis e, além disso, muitos aplicativos populares que executam sistemas embarcados tentarão criar
dot-files configuração em
$HOME . Uma das soluções para arquivos de configuração no diretório inicial é geralmente a geração e montagem preliminares no
rootfs . Para
/var uma das abordagens possíveis é montá-lo em uma seção separada gravável, enquanto o
/ mount em si é somente leitura. Outra alternativa popular é usar montagens de ligação ou sobreposição.
Suportes vinculáveis e sobrepostos, seu uso em contêineresA execução do comando
man mount é a melhor maneira de aprender sobre montagens mapeadas e sobrepostas que dão aos desenvolvedores e administradores de sistema a capacidade de criar um sistema de arquivos de uma maneira e depois fornecê-los para aplicativos de outra. Para sistemas embarcados, isso significa a capacidade de armazenar arquivos em
/var em uma unidade flash somente leitura, mas a sobreposição ou vinculação do caminho de
tmpfs para
/var na inicialização permitirá que os aplicativos escrevam notas lá (rabisco). Na próxima vez que você ativá-lo, as alterações em
/var serão perdidas. Uma montagem de sobreposição cria uma união entre
tmpfs e o sistema de arquivos subjacente e permite que você supostamente faça alterações nos arquivos existentes no
ro-tootf enquanto uma montagem vinculada pode tornar novas pastas vazias do
tmpfs visíveis como graváveis nos caminhos
ro-rootfs . Enquanto
overlayfs é o tipo
proper de sistema de arquivos, montagens de ligação são implementadas no
espaço para nome do
VFS .
Com base na descrição de montagens sobrepostas e vinculadas, ninguém fica surpreso que os
contêineres do Linux as usem ativamente. Vamos observar o que acontece quando usamos
systemd-nspawn para iniciar o contêiner usando a ferramenta
bcc mountsnoop .

Uma chamada para
system-nspawn inicia o contêiner enquanto
mountsnoop.py .
Vamos ver o que aconteceu:
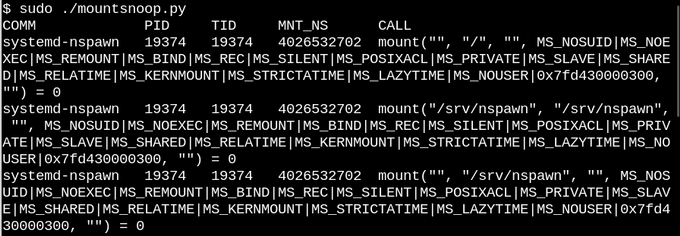
A execução do
mountsnoop durante a “inicialização” do contêiner indica que o tempo de execução do contêiner depende muito da montagem que está sendo conectada (apenas o início da saída longa é exibido).
Aqui,
systemd-nspawn fornece os arquivos selecionados nos
procfs e
sysfs host para o contêiner como caminhos para seus
rootfs . Além do sinalizador
MS_BIND , que define a montagem de ligação, alguns outros sinalizadores no sistema montado determinam o relacionamento entre as alterações no espaço para nome do host e o contêiner. Por exemplo, uma montagem de ligação pode pular alterações em
/proc e
/sys para um contêiner ou ocultá-las, dependendo da chamada.
ConclusãoCompreender a estrutura interna do Linux pode parecer uma tarefa impossível, pois o próprio kernel contém uma enorme quantidade de código, deixando os aplicativos de espaço para usuário do Linux e as interfaces de chamada do sistema nas bibliotecas C, como a
glibc . Uma maneira de progredir é ler o código-fonte de um subsistema do kernel, com ênfase na compreensão de chamadas e cabeçalhos do sistema voltados para o espaço do usuário, bem como as principais interfaces principais do kernel, por exemplo, a tabela
file_operations . As operações de arquivo fornecem o princípio de "tudo é um arquivo", portanto, gerenciá-las é especialmente bom. Os arquivos do kernel de origem C no diretório de nível superior
fs/ representam a implementação de sistemas de arquivos virtuais, que são uma camada de shell que fornece ampla e relativamente simples compatibilidade de sistemas de arquivos e dispositivos de armazenamento populares. Montar com ligação e sobreposição nos namespaces do Linux é uma mágica do VFS que possibilita a criação de contêineres somente leitura e sistemas de arquivos raiz. Combinado com o aprendizado do código fonte, a ferramenta principal do eBPF e sua interface cco
torne a pesquisa do kernel mais fácil do que nunca.
Amigos, escrever este artigo foi útil para você? Talvez você tenha algum comentário ou comentário? E aqueles que estão interessados no curso Linux Administrator, nós convidamos você a
abrir o dia da casa , que ocorrerá em 18 de abril.
A primeira parte