O setor se concentrou em acelerar a multiplicação de matrizes, mas a melhoria do algoritmo de pesquisa pode levar a um aumento mais sério no desempenho

Nos últimos anos, a indústria de computadores tem estado ocupada tentando acelerar os cálculos necessários para redes neurais artificiais - tanto para treinamento quanto para tirar conclusões de seu trabalho. Em particular, foi feito um grande esforço no desenvolvimento de ferro especial, no qual esses cálculos podem ser realizados. O Google desenvolveu a
Tensor Processing Unit , ou TPU,
introduzida pela primeira
vez ao público em 2016. Mais tarde, a Nvidia introduziu a Unidade de processamento gráfico
V100 , descrevendo-a como um chip projetado especificamente para treinamento e uso de IA, bem como para outras necessidades de computação de alto desempenho. Cheio de outras startups, concentrando-se em outros tipos de
aceleradores de
hardware .
Talvez todos cometam um grande erro.
Essa ideia foi expressa no
trabalho , que apareceu em meados de março no site arXiv. Nela, seus autores,
Beidi Chen ,
Tarun Medini e
Anshumali Srivastava, da Rice University, argumentam que talvez o equipamento especial desenvolvido para a operação de redes neurais esteja sendo otimizado para o algoritmo errado.
O fato é que o trabalho das redes neurais geralmente depende da rapidez com que o equipamento pode executar a multiplicação de matrizes usadas para determinar os parâmetros de saída de cada nêutron artificial - sua “ativação” - para um determinado conjunto de valores de entrada. As matrizes são usadas porque cada valor de entrada para um neurônio é multiplicado pelo parâmetro de peso correspondente, e então todos são somados - e essa multiplicação com adição é a operação básica da multiplicação de matrizes.
Pesquisadores da Rice University, como alguns outros cientistas, perceberam que a ativação de muitos neurônios em uma camada específica da rede neural é muito pequena e não afeta o valor de saída calculado pelas camadas subseqüentes. Portanto, se você souber o que são esses neurônios, poderá simplesmente ignorá-los.
Pode parecer que a única maneira de descobrir quais neurônios em uma camada não estão ativados é primeiro executar todas as operações de multiplicação de matrizes para essa camada. Mas os pesquisadores perceberam que você pode realmente decidir dessa maneira mais eficiente se observar o problema de um ângulo diferente. "Abordamos esse problema como uma solução para o problema de pesquisa", diz Srivastava.
Ou seja, em vez de calcular multiplicações de matrizes e observar quais neurônios foram ativados para uma determinada entrada, é possível ver apenas que tipo de neurônios estão no banco de dados. A vantagem dessa abordagem no problema é que você pode usar uma estratégia generalizada que há muito tempo foi aprimorada por cientistas da computação para acelerar a pesquisa de dados no banco de dados: hash.
O hash permite verificar rapidamente se existe um valor na tabela do banco de dados, sem precisar passar por cada linha em uma linha. Você usa um hash, facilmente calculado aplicando uma função de hash ao valor desejado, indicando onde esse valor deve ser armazenado no banco de dados. Depois, você pode verificar apenas um local para descobrir se esse valor está armazenado lá.
Os pesquisadores fizeram algo semelhante para cálculos relacionados a redes neurais. O exemplo a seguir ajudará a ilustrar sua abordagem:
Suponha que tenhamos criado uma rede neural que reconhece a entrada manuscrita de números. Suponha que a entrada seja pixels cinza em uma matriz de 16x16, ou seja, um total de 256 números. Nós alimentamos esses dados em uma camada oculta de 512 neurônios, cujos resultados de ativação são alimentados pela camada de saída de 10 neurônios, um para cada um dos números possíveis.
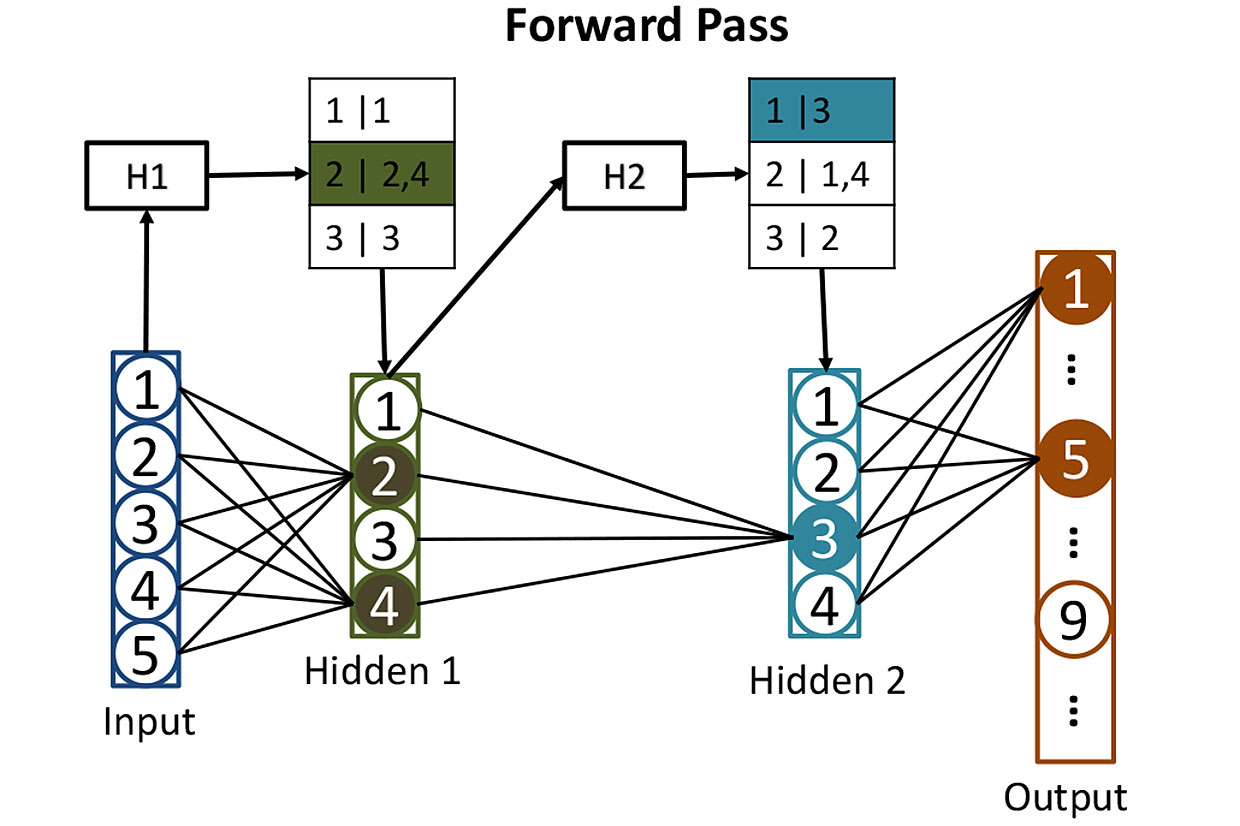 Tabelas de redes: antes de calcular a ativação de neurônios em camadas ocultas, usamos hashes para nos ajudar a determinar quais neurônios serão ativados. Aqui, o hash dos valores de entrada H1 é usado para procurar os neurônios correspondentes na primeira camada oculta - nesse caso, serão os neurônios 2 e 4. O segundo hash H2 mostra quais neurônios da segunda camada oculta contribuirão. Essa estratégia reduz o número de ativações que precisam ser calculadas.
Tabelas de redes: antes de calcular a ativação de neurônios em camadas ocultas, usamos hashes para nos ajudar a determinar quais neurônios serão ativados. Aqui, o hash dos valores de entrada H1 é usado para procurar os neurônios correspondentes na primeira camada oculta - nesse caso, serão os neurônios 2 e 4. O segundo hash H2 mostra quais neurônios da segunda camada oculta contribuirão. Essa estratégia reduz o número de ativações que precisam ser calculadas.É muito difícil treinar essa rede, mas por enquanto vamos omitir esse momento e imaginar que já ajustamos todos os pesos de cada neurônio para que a rede neural reconheça números manuscritos perfeitamente. Quando um número legível escrito chega à sua entrada, a ativação de um dos neurônios de saída (correspondente a esse número) será próxima de 1. A ativação dos outros nove será próxima de 0. Classicamente, a operação dessa rede requer uma multiplicação de matrizes para cada um dos 512 neurônios ocultos, e mais um para cada fim de semana - o que nos dá muitas multiplicações.
Os pesquisadores adotam uma abordagem diferente. O primeiro passo é misturar os pesos de cada um dos 512 neurônios na camada oculta usando o "hash sensível à localidade", uma das propriedades das quais dados de entrada semelhantes fornecem valores de hash semelhantes. Você pode agrupar neurônios com hashes semelhantes, o que significa que esses neurônios têm conjuntos de pesos semelhantes. Cada grupo pode ser armazenado em um banco de dados e determinado pelo hash dos valores de entrada que levarão à ativação desse grupo de neurônios.
Depois de todo esse hash, é fácil determinar quais neurônios ocultos serão ativados por alguma nova entrada. Você precisa executar 256 valores de entrada por meio de funções hash facilmente calculáveis e usar o resultado para pesquisar no banco de dados os neurônios que serão ativados. Dessa forma, você terá que calcular os valores de ativação para apenas alguns neurônios importantes. Não é necessário calcular a ativação de todos os outros neurônios da camada apenas para descobrir que eles não contribuem para o resultado.
A entrada dessa rede neural de dados pode ser representada como a execução de uma consulta de pesquisa em um banco de dados que pede para encontrar todos os neurônios que seriam ativados por contagem direta. Você obtém a resposta rapidamente porque usa hashes para pesquisar. E então você pode simplesmente calcular a ativação de um pequeno número de neurônios que realmente importam.
Os pesquisadores usaram essa técnica, que eles chamaram de SLIDE (Sub-Linear Deep learning Engine), para treinar uma rede neural - para um processo que possui mais solicitações computacionais do que para o objetivo a que se destina. Eles então compararam o desempenho do algoritmo de aprendizado com uma abordagem mais tradicional usando uma GPU poderosa - especificamente, a GPU Nvidia V100. Como resultado, eles obtiveram algo surpreendente: "Nossos resultados mostram que, em média, a tecnologia SLIDE da CPU pode executar ordens de magnitude mais rápidas que a melhor alternativa possível, implementada nos melhores equipamentos e com qualquer precisão".
É muito cedo para tirar conclusões sobre se esses resultados (que os especialistas ainda não avaliaram) resistirão aos testes e se forçarão os fabricantes de chips a dar uma olhada diferente no desenvolvimento de equipamentos especiais para aprendizado profundo. Mas o trabalho enfatiza definitivamente o perigo do arrastamento de um certo tipo de ferro nos casos em que existe a possibilidade de um novo e melhor algoritmo para a operação de redes neurais.