Olá pessoal. Menos e menos tempo resta até o lançamento do curso
"Segurança dos Sistemas de Informação" , então hoje continuamos compartilhando publicações dedicadas ao lançamento deste curso. A propósito, esta publicação é uma continuação desses dois artigos:
“Fundamentos dos mecanismos JavaScript: formulários gerais e cache Inline. Parte 1 " ,
" Noções básicas de mecanismos JavaScript: formulários gerais e cache Inline. Parte 2 " .
O artigo descreve os principais conceitos básicos. Eles são comuns a todos os mecanismos JavaScript, e não apenas ao
V8 em que os autores estão trabalhando (
Benedict e
Matthias ). Como desenvolvedor de JavaScript, posso dizer que uma compreensão mais profunda de como funciona o mecanismo JavaScript ajudará você a descobrir como escrever código eficiente.

Em um
artigo anterior, discutimos como os mecanismos JavaScript otimizam o acesso a objetos e matrizes usando formulários e caches embutidos. Neste artigo, examinaremos a otimização dos compromissos do pipeline e a aceleração do acesso às propriedades do protótipo.
Nota: se você preferir assistir a apresentações do que ler artigos, assista a este vídeo . Caso contrário, pule e continue lendo.
Níveis de otimização e trade-offsNa última vez , descobrimos que todos os mecanismos JavaScript modernos têm o mesmo pipeline:
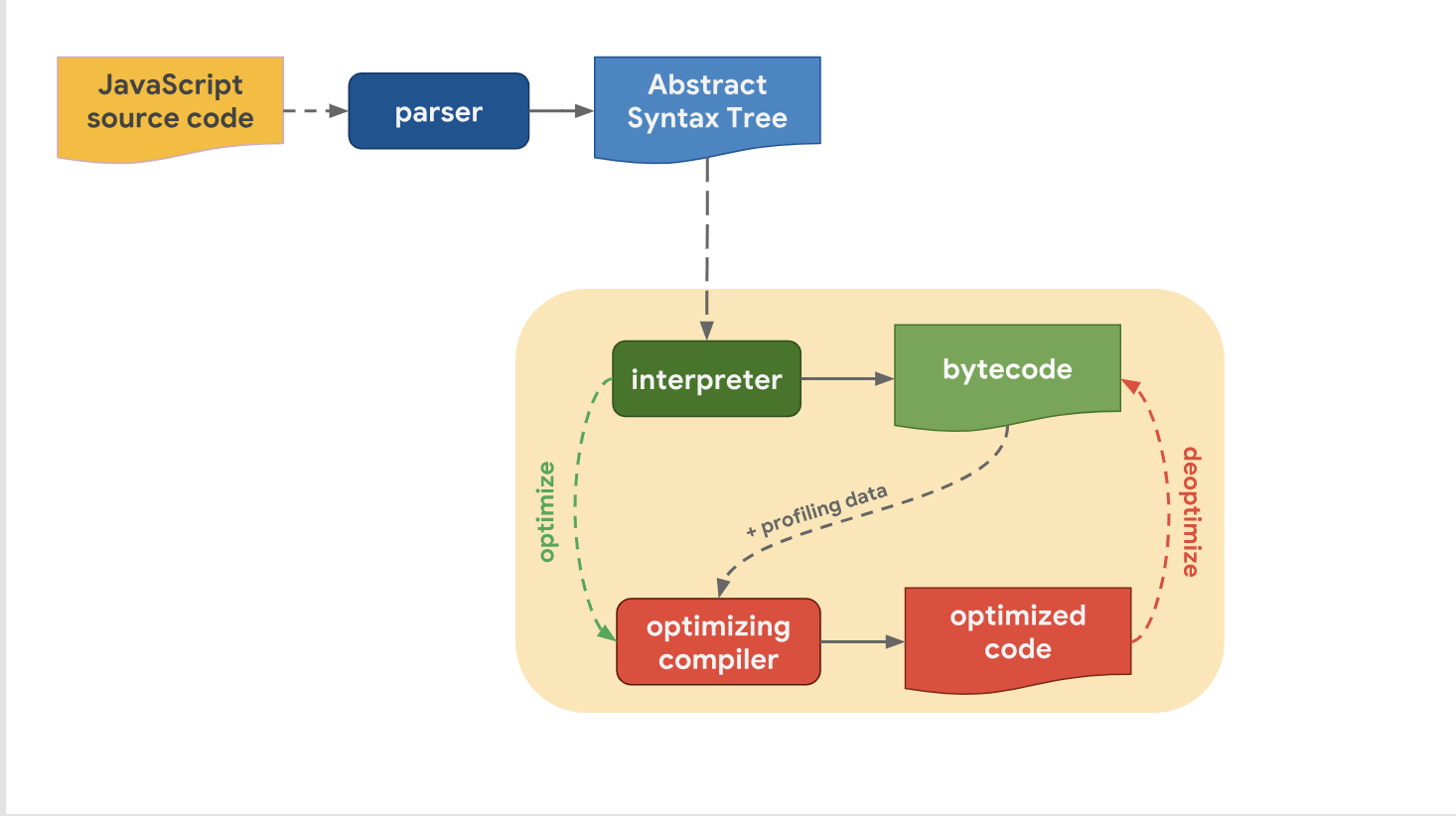
Também percebemos que, apesar de os oleodutos de alto nível de mecanismo para mecanismo serem similares em estrutura, há uma diferença no oleoduto de otimização. Por que isso é assim? Por que alguns mecanismos têm mais níveis de otimização do que outros? A questão é fazer um compromisso entre uma transição rápida para o estágio de execução do código ou gastar um pouco mais de tempo para executar o código com desempenho ideal.

O intérprete pode gerar rapidamente bytecode, mas somente o bytecode não é eficiente o suficiente em termos de velocidade. Envolver um compilador otimizador nesse processo gasta uma certa quantidade de tempo, mas permite um código de máquina mais eficiente.
Vamos dar uma olhada em como o V8 lida com isso. Lembre-se de que na V8 o intérprete é chamado Ignição e é considerado o intérprete mais rápido entre os mecanismos existentes (em questões de velocidade de execução bruta do código de bytecode). O compilador de otimização na V8 é chamado TurboFan, e é ele quem gera o código da máquina altamente otimizado.

A troca entre atraso de inicialização e velocidade de execução é a razão pela qual alguns mecanismos JavaScript preferem adicionar níveis de otimização adicionais entre as etapas. Por exemplo, o SpiderMonkey adiciona uma camada de linha de base entre seu intérprete e o compilador IonMonkey de otimização total:
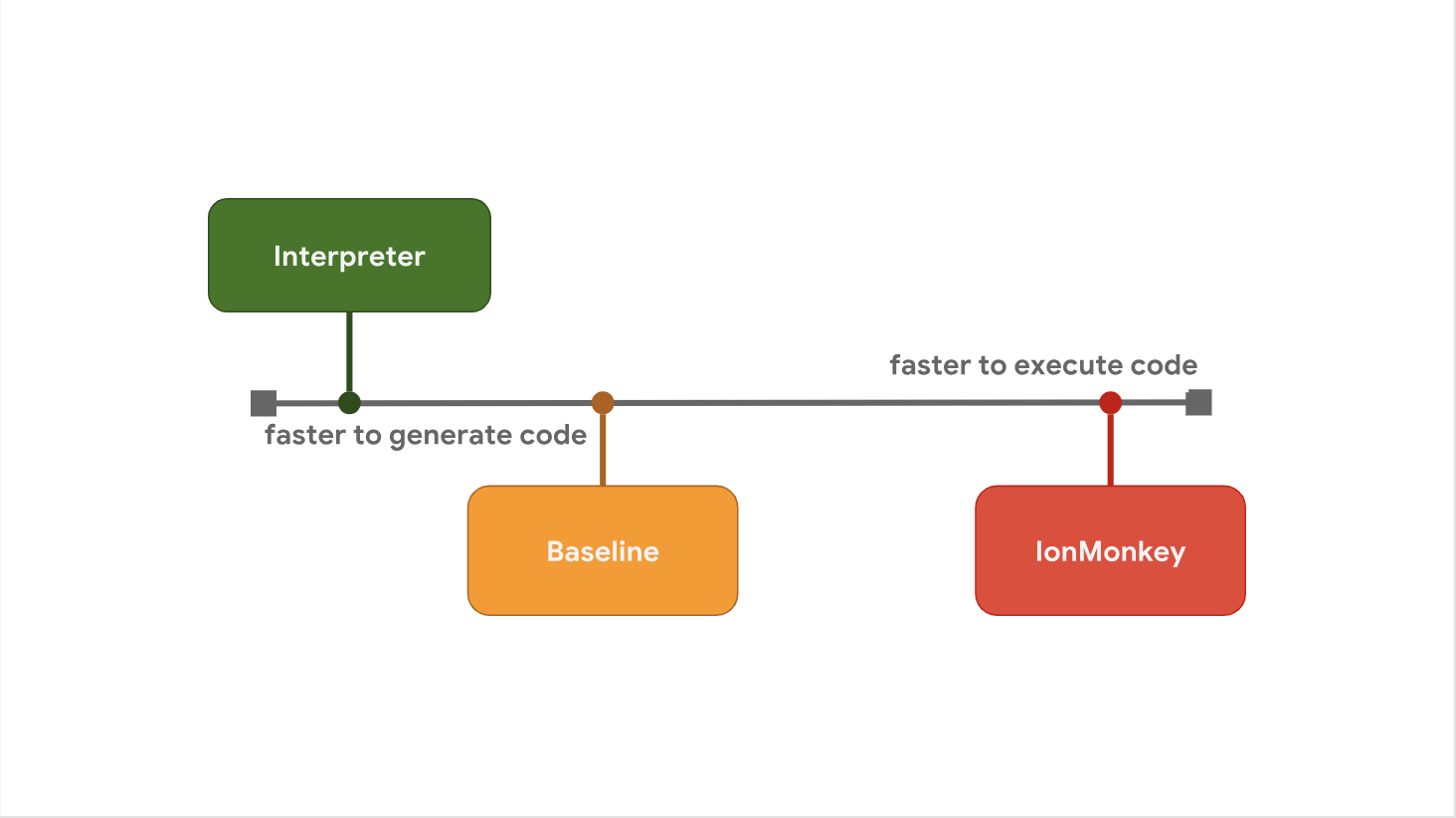
O intérprete gera rapidamente o bytecode, mas o próprio bytecode é relativamente lento. A linha de base gera código um pouco mais, mas fornece desempenho aprimorado no tempo de execução. Finalmente, o compilador otimizador IonMonkey gasta mais tempo gerando código de máquina, mas esse código é extremamente eficiente.
Vamos dar uma olhada em um exemplo específico e ver como os pipelines de vários motores lidam com esse problema. Aqui no hot loop, o mesmo código é frequentemente repetido.
let result = 0; for (let i = 0; i < 4242424242; ++i) { result += i; } console.log(result);
A V8 inicia iniciando o bytecode no intérprete do Ignition. Em algum momento, o mecanismo determina que o código está quente e inicia a interface TurboFan, que integra dados de criação de perfil e cria uma representação básica da máquina do código. Em seguida, ele é enviado para o otimizador TurboFan em outro thread para aprimoramentos adicionais.

Enquanto a otimização estiver em andamento, o V8 continua executando o código no Ignition. Em algum momento, quando o otimizador termina e recebemos o código da máquina executável, ele imediatamente segue para o estágio de execução.
O SpyderMonkey também inicia a execução do bytecode no intérprete. Mas ele tem um nível adicional de linha de base, o que significa que o código de acesso rápido é enviado para lá primeiro. O compilador da linha de base gera código de linha de base no encadeamento principal e continua a execução no final de sua geração.

Se o código da linha de base estiver em execução há algum tempo, o SpiderMonkey finalmente inicia a interface IonMonkey (interface do IonMonkey) e executa o otimizador, o processo é muito semelhante ao V8. Tudo isso continua funcionando ao mesmo tempo na linha de base, enquanto o IonMonkey está envolvido na otimização. Por fim, quando o otimizador termina seu trabalho, o código otimizado é executado em vez do código de linha de base.
A arquitetura do Chakra é muito semelhante ao SpiderMonkey, mas o Chakra está tentando executar mais processos ao mesmo tempo para evitar o bloqueio do thread principal. Em vez de executar qualquer parte do compilador no encadeamento principal, o Chakra copia os dados de bytecode e de criação de perfil que o compilador precisa e os envia para o processo do compilador dedicado.

Quando o código gerado está pronto, o mecanismo executa esse código SimpleJIT em vez do bytecode. O mesmo acontece com o FullJIT. A vantagem dessa abordagem é que a pausa que ocorre durante a cópia geralmente é muito menor do que iniciar um compilador completo (front-end). Por outro lado, essa abordagem tem uma desvantagem. Está no fato de que a heurística da cópia pode ignorar algumas informações necessárias para a otimização, para que possamos dizer que, em certa medida, a qualidade do código é sacrificada para acelerar o trabalho.
No JavaScriptCore, todos os compiladores de otimização funcionam completamente em paralelo com a execução básica do JavaScript. Não há fase de cópia. Em vez disso, o thread principal simplesmente começa a compilar em outro thread. Os compiladores, em seguida, usam um esquema de bloqueio complexo para acessar dados de criação de perfil do thread principal.

A vantagem dessa abordagem é que ela reduz a quantidade de lixo que aparece após a otimização no encadeamento principal. A desvantagem dessa abordagem é que ela requer a solução de problemas complexos de multithreading e alguns custos de bloqueio para várias operações.
Conversamos sobre as vantagens e desvantagens entre a geração rápida de código enquanto o interpretador está em execução e a geração rápida de código usando o compilador de otimização. Mas há mais um compromisso e diz respeito ao uso da memória. Para ilustrar, escrevi um programa JavaScript simples que adiciona dois números.
function add(x, y) { return x + y; } add(1, 2);
Observe o bytecode que é gerado para a função add pelo intérprete do Ignition na V8.
StackCheck Ldar a1 Add a0, [0] Return
Não se preocupe com o bytecode, você não precisa lê-lo. Aqui é necessário prestar atenção ao fato de que ele contém
apenas 4 instruções .
Quando o código esquenta, o TurboFan gera um código de máquina altamente otimizado, que é apresentado abaixo:
leaq rcx,[rip+0x0] movq rcx,[rcx-0x37] testb [rcx+0xf],0x1 jnz CompileLazyDeoptimizedCode push rbp movq rbp,rsp push rsi push rdi cmpq rsp,[r13+0xe88] jna StackOverflow movq rax,[rbp+0x18] test al,0x1 jnz Deoptimize movq rbx,[rbp+0x10] testb rbx,0x1 jnz Deoptimize movq rdx,rbx shrq rdx, 32 movq rcx,rax shrq rcx, 32 addl rdx,rcx jo Deoptimize shlq rdx, 32 movq rax,rdx movq rsp,rbp pop rbp ret 0x18
Realmente existem muitas equipes aqui, especialmente em comparação com as quatro que vimos no bytecode. Em geral, o bytecode é muito mais amplo que o código de máquina, e em particular o código de máquina otimizado. O bytecode, por outro lado, é executado pelo intérprete, enquanto o código otimizado pode ser executado diretamente pelo processador.
Essa é uma das razões pelas quais os mecanismos JavaScript não apenas "otimizam tudo". Como vimos anteriormente, a geração de código de máquina otimizado leva muito tempo e, portanto, requer mais memória.
 Para resumir:
Para resumir: A razão pela qual os mecanismos JavaScript têm níveis diferentes de otimização é encontrar um compromisso entre a geração rápida de código usando o interpretador e a geração rápida de código usando o compilador de otimização. A adição de mais níveis de otimização permite que você tome decisões mais informadas, com base no custo de complexidade adicional e sobrecarga durante a execução. Além disso, há uma troca entre o nível de otimização e o uso de memória. É por isso que os mecanismos JavaScript tentam otimizar apenas funções importantes.
Otimize o acesso às propriedades do protótipoNa última vez , falamos sobre como os mecanismos JavaScript otimizam o carregamento das propriedades do objeto usando formulários e caches inline. Lembre-se de que os mecanismos armazenam as formas dos objetos separadamente dos valores do objeto.
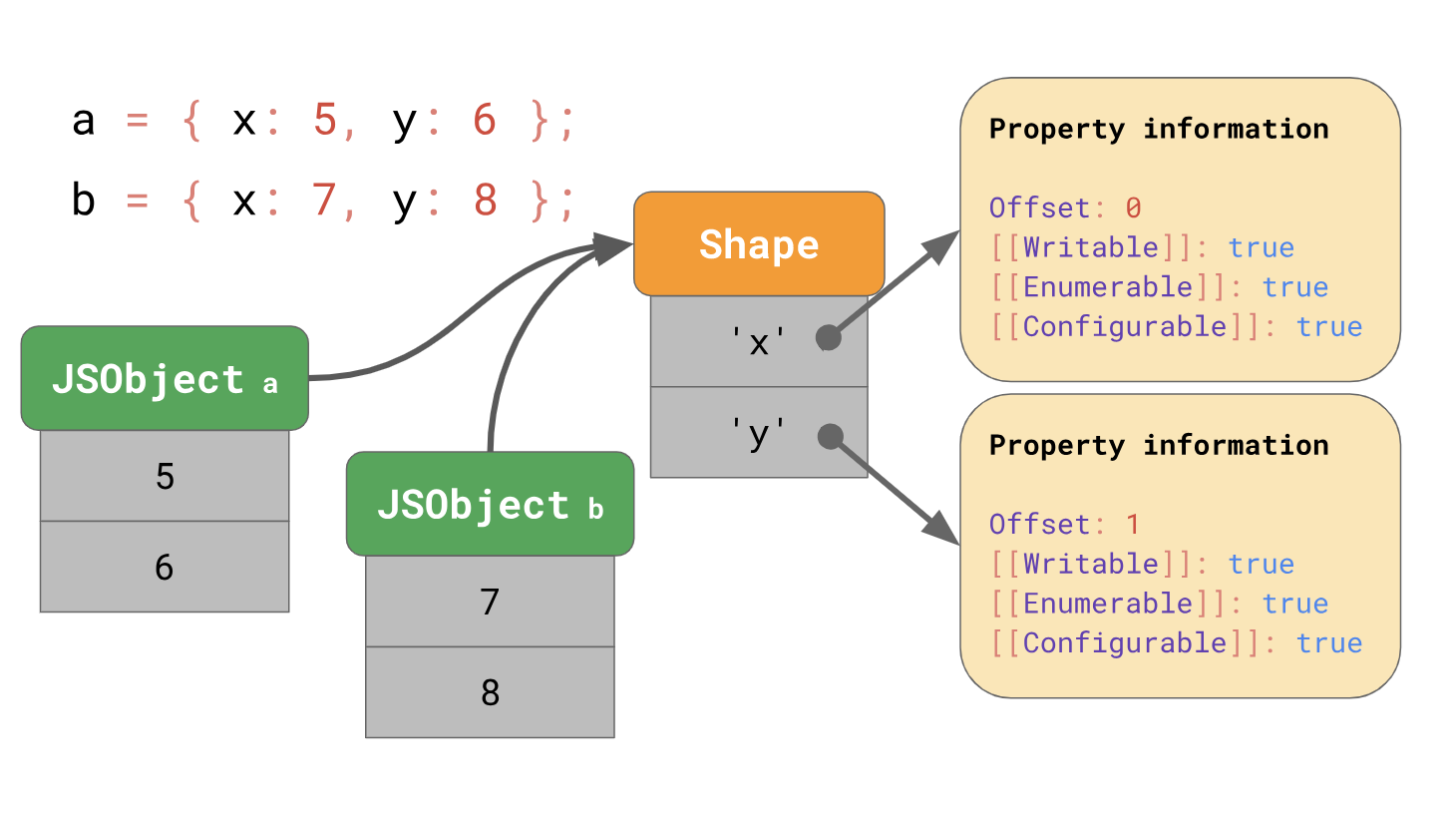
Os formulários permitem usar a otimização usando caches embutidos ou ICs abreviados. Ao trabalhar juntos, formulários e ICs podem acelerar o acesso repetido a propriedades do mesmo local no seu código.
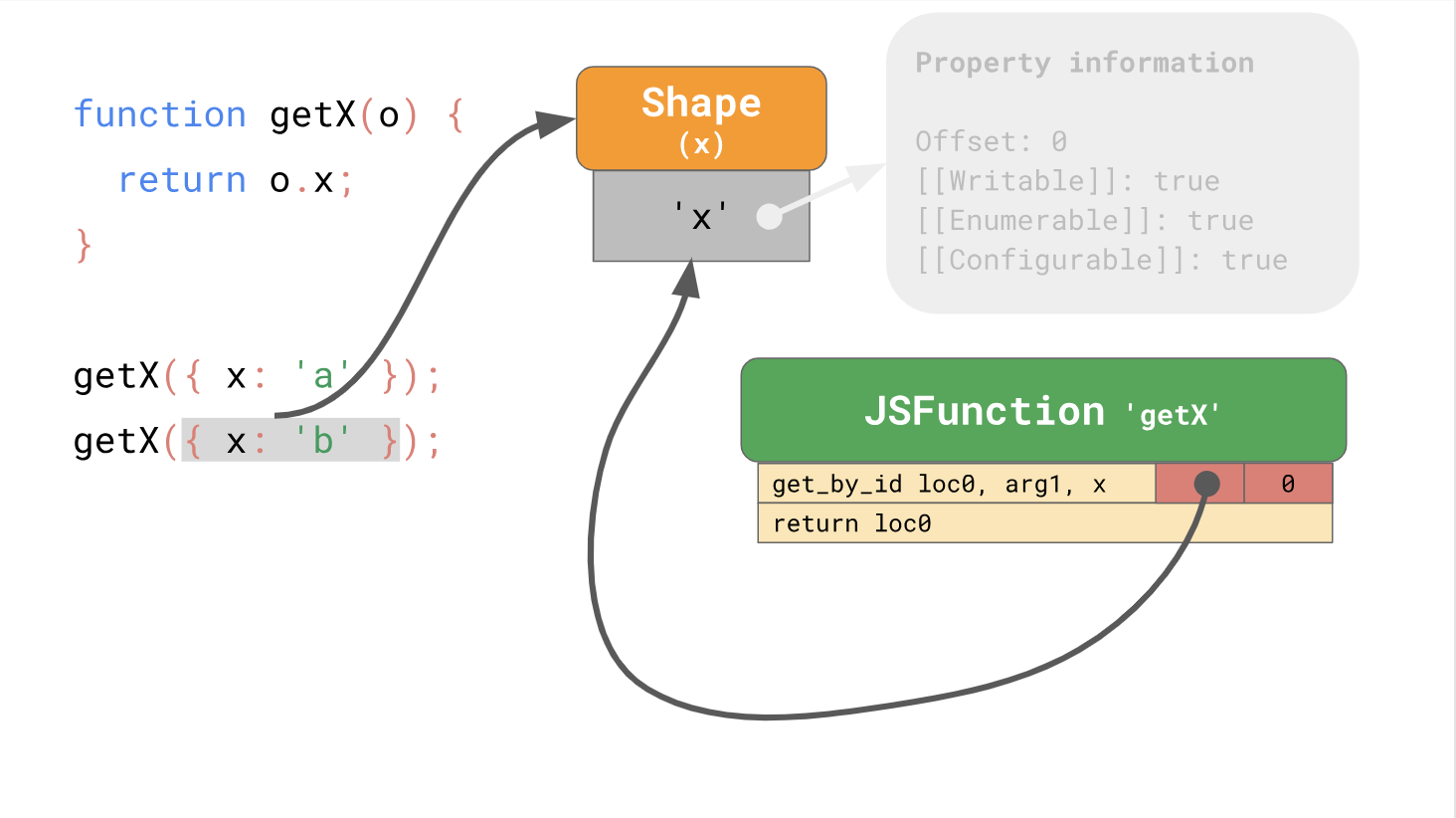
Portanto, a primeira parte da publicação chegou ao fim e sobre classes e programação de protótipos pode ser encontrada na
segunda parte . Tradicionalmente, aguardamos seus comentários e discussões tempestuosas, assim como convidamos você a um
dia aberto no curso "Segurança dos sistemas de informação".