Normalmente, o Nginx usa produtos comerciais ou alternativas de código aberto, como Prometheus + Grafana, para monitorar e analisar o desempenho do Nginx. Essa é uma boa opção para monitoramento ou análise em tempo real, mas não é muito conveniente para análise histórica. Em qualquer recurso popular, a quantidade de dados dos logs do nginx está crescendo rapidamente e é lógico usar algo mais especializado para analisar uma grande quantidade de dados.
Neste artigo, mostrarei como usar o Athena para analisar logs usando o Nginx como exemplo e mostrarei como compilar um painel analítico a partir desses dados usando a estrutura cube.js de código aberto . Aqui está a arquitetura completa da solução:

TL: DR;
Link para o painel concluído .
Usamos o Fluentd para coletar informações, o AWS Kinesis Data Firehose e o AWS Glue para processamento e o AWS S3 para armazenamento. Usando este pacote, você pode armazenar não apenas logs nginx, mas também outros eventos, bem como logs de outros serviços. É possível substituir algumas peças por outras semelhantes à sua pilha; por exemplo, você pode gravar logs no kinesis diretamente do nginx, ignorando o fluentd ou usar o logstash para fazer isso.
Coletando logs do Nginx
Por padrão, os logs do Nginx são mais ou menos assim:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
Eles podem ser analisados, mas é muito mais fácil corrigir a configuração do Nginx para que ele exiba logs em JSON:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
S3 para armazenamento
Para armazenar os logs, usaremos o S3. Isso permite armazenar e analisar os logs em um único local, já que o Athena pode trabalhar com dados no S3 diretamente. Mais adiante neste artigo, mostrarei como dobrar e processar corretamente os logs, mas primeiro precisamos de um balde limpo no S3, no qual nada mais será armazenado. Vale a pena pensar com antecedência em qual região você criará o bucket, porque o Athena não está disponível em todas as regiões.
Crie um diagrama no console do Athena
Crie uma tabela no Athena para logs. É necessário para a escrita e a leitura, se você planeja usar o Kinesis Firehose. Abra o console do Athena e crie uma tabela:
Criação de tabela SQL CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
Criar fluxo Kinesis Firehose
O Kinesis Firehose gravará os dados recebidos do Nginx no S3 no formato selecionado, divididos em diretórios no formato AAAA / MM / DD / HH. Isso é útil ao ler dados. Obviamente, você pode escrever diretamente no S3 a partir do fluentd, mas nesse caso você deve escrever JSON, o que é ineficiente devido ao grande tamanho do arquivo. Além disso, ao usar o PrestoDB ou Athena, o JSON é o formato de dados mais lento. Portanto, abra o console do Kinesis Firehose, clique em "Criar fluxo de entrega", selecione "PUT direto" no campo "entrega":
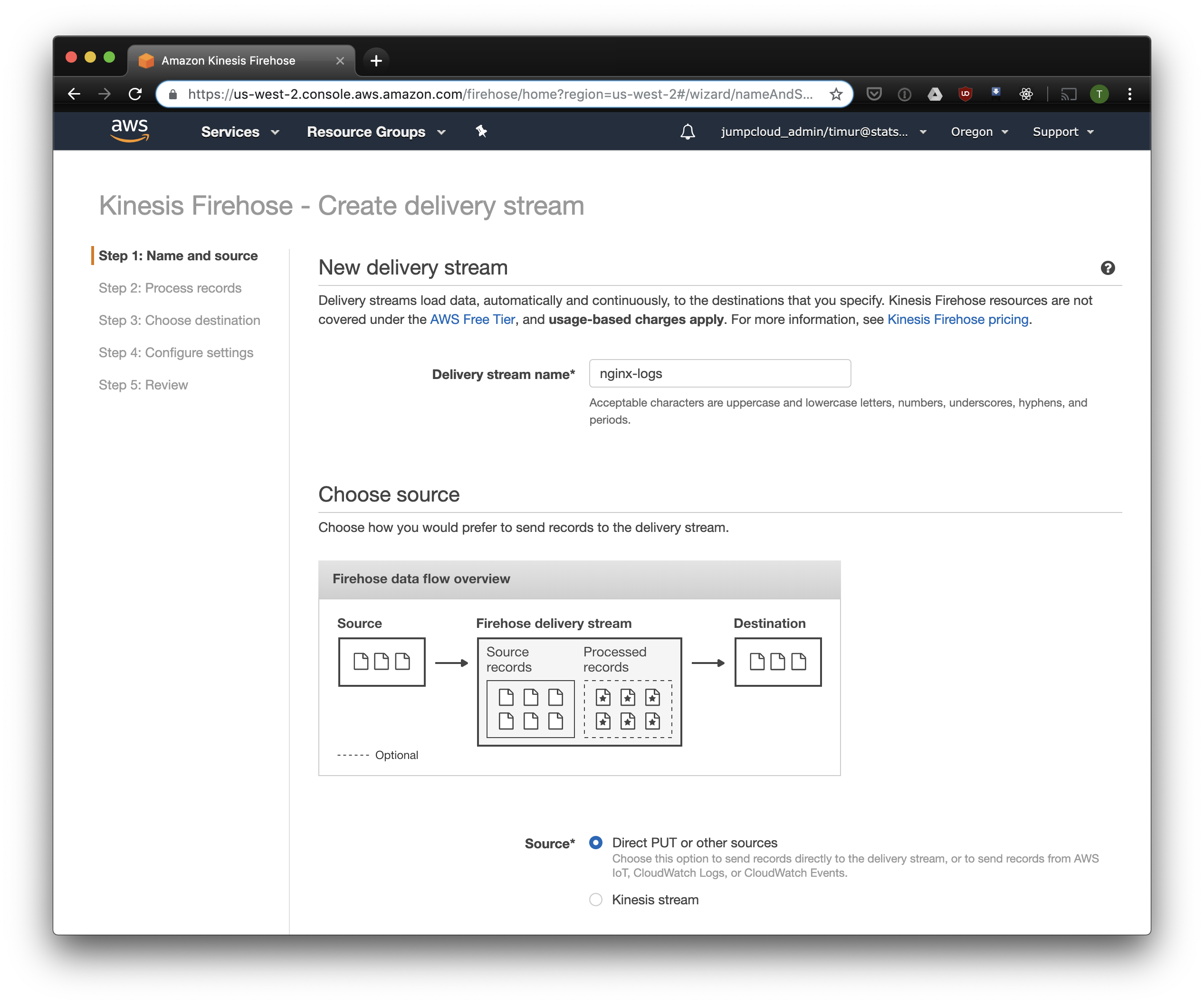
Na próxima guia, selecione "Conversão de formato de gravação" - "Ativado" e selecione "Apache ORC" como o formato para gravação. Segundo Owen O'Malley , esse é o formato ideal para o PrestoDB e Athena. Como um diagrama, indicamos a tabela que criamos acima. Observe que você pode especificar qualquer local S3 em kinesis, apenas o esquema é usado na tabela. Mas se você especificar outro local S3, a leitura desses registros desta tabela não funcionará.
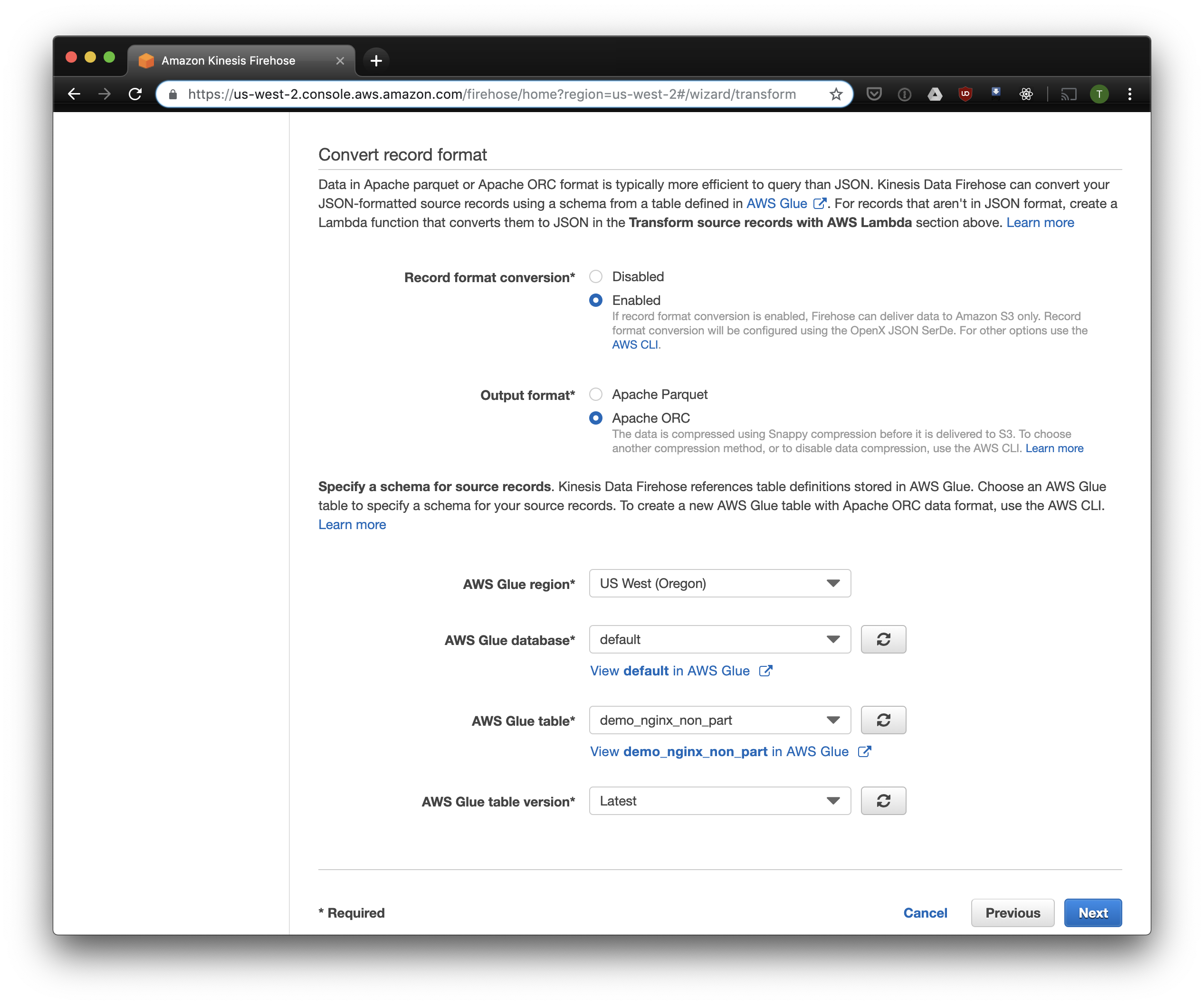
Escolhemos o S3 para armazenamento e o bucket que criamos anteriormente. O Aws Glue Crawler, sobre o qual falarei um pouco mais tarde, não sabe como trabalhar com prefixos no bucket S3, por isso é importante deixá-lo vazio.

As opções restantes podem ser alteradas dependendo da sua carga, geralmente uso as padrão. Observe que a compactação S3 não está disponível, mas o ORC usa a compactação nativa por padrão.
Fluente
Agora que configuramos o armazenamento e o recebimento de logs, você precisa configurar o envio. Usaremos o Fluentd porque eu amo Ruby, mas você pode usar o Logstash ou enviar logs para o kinesis diretamente. Você pode iniciar o servidor Fluentd de várias maneiras, vou falar sobre o docker, porque é simples e conveniente.
Primeiro, precisamos do arquivo de configuração fluent.conf. Crie-o e adicione a fonte:
digite para a frente
porta 24224
bind 0.0.0.0
Agora você pode iniciar o servidor Fluentd. Se você precisar de uma configuração mais avançada, o Docker Hub possui um guia detalhado, incluindo como montar sua imagem.
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
Essa configuração usa o /fluentd/log para armazenar em cache os logs antes do envio. Você pode ficar sem isso, mas, ao reiniciar, pode perder tudo em cache por trabalho excessivo. Qualquer porta também pode ser usada, 24224 é a porta padrão do Fluentd.
Agora que temos o Fluentd em execução, podemos enviar logs do Nginx para lá. Geralmente, executamos o Nginx em um contêiner do Docker. Nesse caso, o Docker possui um driver de log nativo para o Fluentd:
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
Se você executar o Nginx de maneira diferente, poderá usar os arquivos de log, o Fluentd possui um plug-in de cauda de arquivo .
Adicione a análise de log configurada acima à configuração do Fluent:
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
E enviando logs para o Kinesis usando o plug - in kinesis firehose :
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
Athena
Se você configurou tudo corretamente, depois de um tempo (por padrão, o Kinesis grava os dados recebidos a cada 10 minutos), você deve ver os arquivos de log no S3. No menu "monitoramento" do Kinesis Firehose, é possível ver a quantidade de dados gravados no S3, além de erros. Não esqueça de conceder acesso de gravação ao bucket S3 para a função Kinesis. Se Kinesis não conseguiu analisar algo, ele adicionará erros no mesmo bloco.
Agora você pode ver os dados em Athena. Vamos encontrar algumas novas consultas às quais cometemos erros:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
Digitalizar todos os registros para cada solicitação
Agora, nossos logs são processados e empilhados no S3 no ORC, compactados e prontos para análise. O Kinesis Firehose até os coloca em diretórios a cada hora. No entanto, enquanto a tabela não estiver particionada, o Athena carregará dados de todos os tempos para cada consulta, com raras exceções. Este é um grande problema por dois motivos:
- A quantidade de dados está em constante crescimento, diminuindo a velocidade das consultas;
- O Athena é cobrado com base na quantidade de dados verificados, com um mínimo de 10 MB para cada solicitação.
Para corrigir isso, usamos o AWS Glue Crawler, que verificará os dados no S3 e registrará as informações da partição no Glue Metastore. Isso nos permitirá usar partições como um filtro para solicitações no Athena, e ele somente examinará os diretórios especificados na solicitação.
Personalizar o Amazon Glue Crawler
O Amazon Glue Crawler verifica todos os dados no bucket S3 e cria tabelas de partição. Crie um rastreador de cola no console da AWS Glue e adicione o balde no qual você armazena os dados. Você pode usar um rastreador para vários buckets; nesse caso, ele criará tabelas no banco de dados especificado com nomes que correspondem aos nomes dos buckets. Se você planeja usar esses dados o tempo todo, certifique-se de ajustar a programação de inicialização do rastreador para atender às suas necessidades. Usamos um rastreador para todas as tabelas, que é executado a cada hora.
Tabelas Particionadas
Após o primeiro início do rastreador, as tabelas para cada intervalo verificado devem aparecer no banco de dados especificado nas configurações. Abra o console do Athena e encontre a tabela com os logs do Nginx. Vamos tentar ler algo:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
Esta consulta selecionará todos os registros recebidos das 6 às 7 da manhã de 8 de abril de 2019. Mas quanto mais eficaz do que apenas ler de uma tabela não particionada? Vamos descobrir e selecionar os mesmos registros, filtrando-os por carimbo de data / hora:
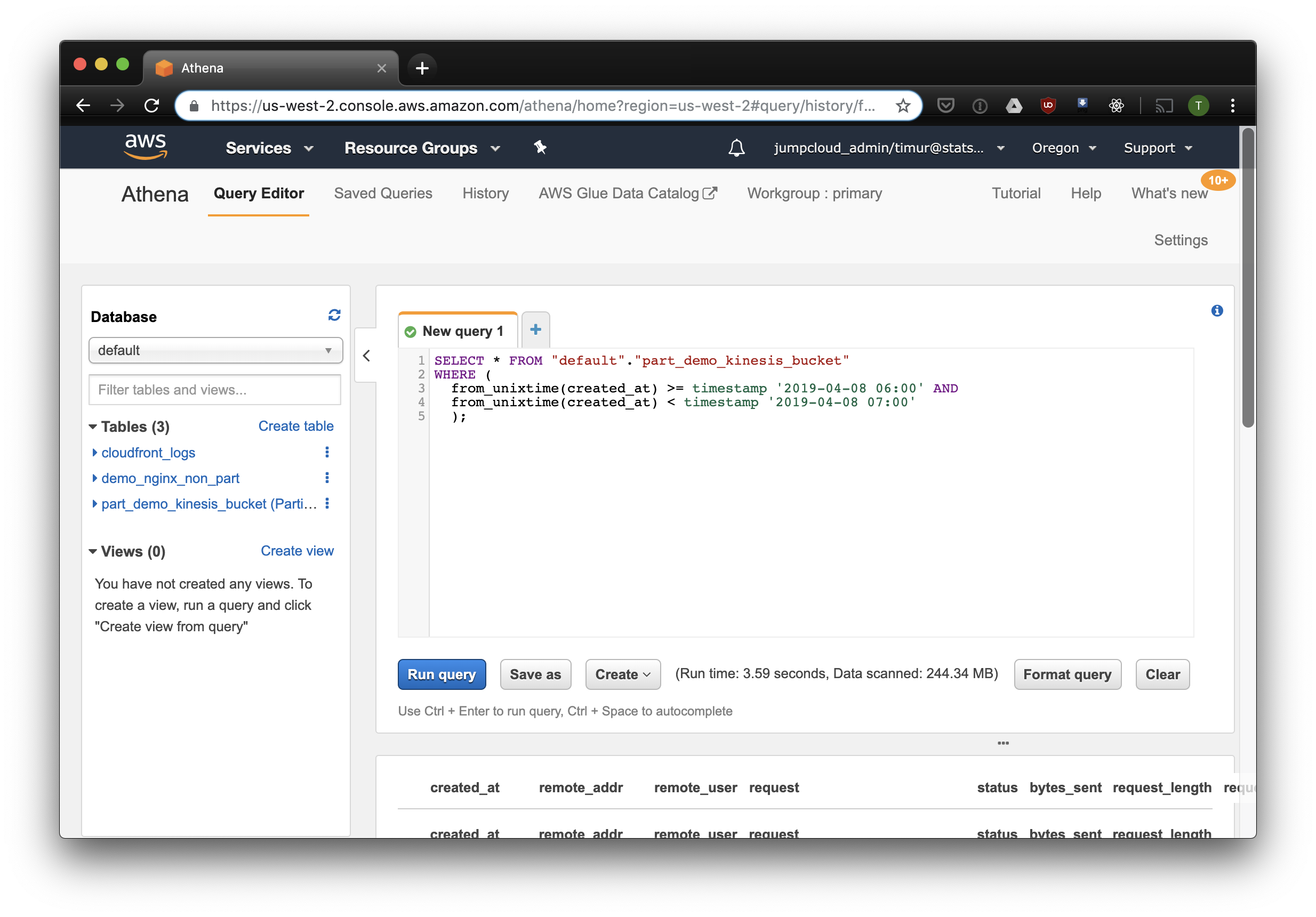
3,59 segundos e 244,34 megabytes de dados no conjunto de dados, nos quais há apenas uma semana de logs. Vamos tentar o filtro por partições:
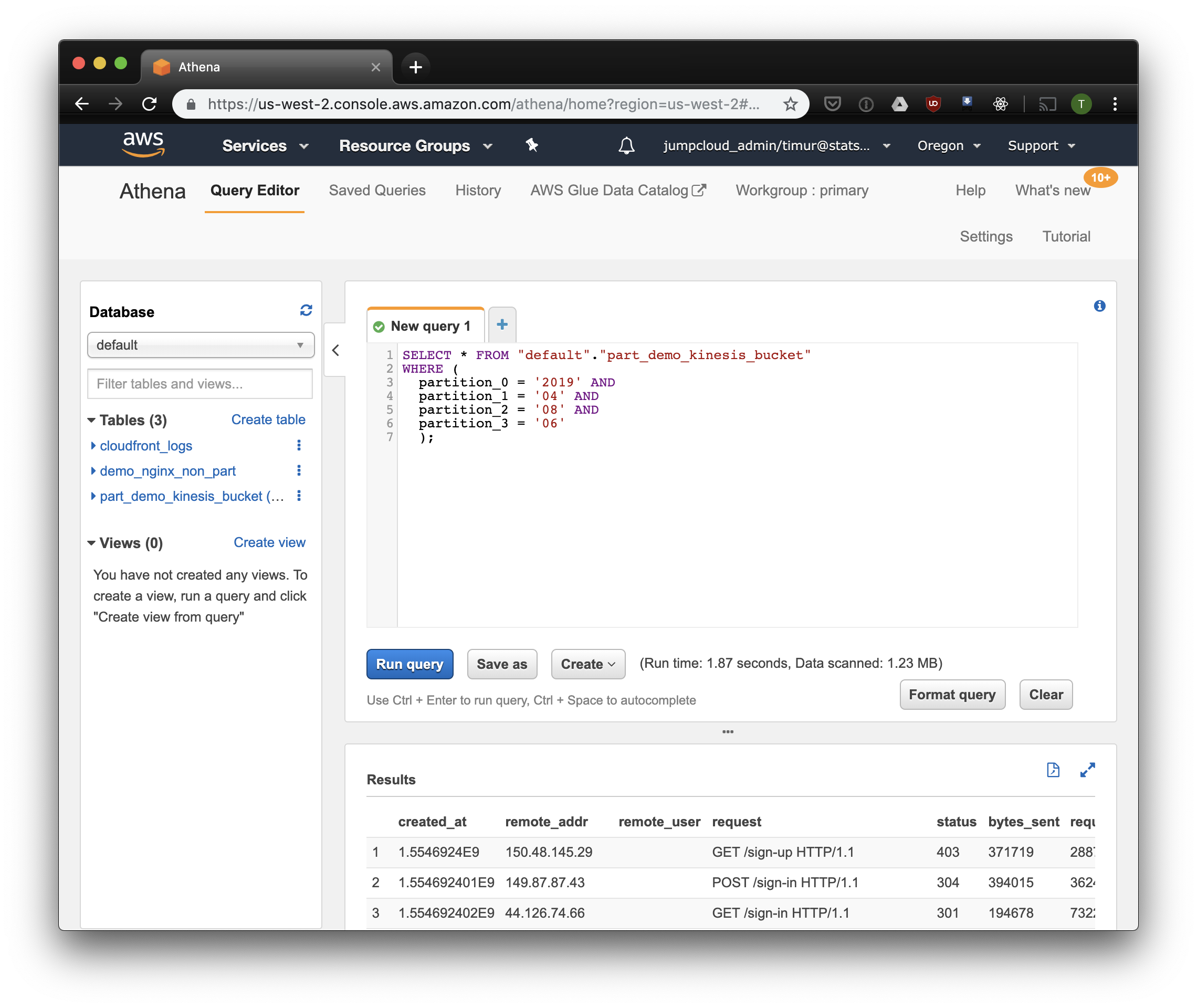
Um pouco mais rápido, mas o mais importante - apenas 1,23 megabytes de dados! Seria muito mais barato se não fosse pelo preço mínimo de 10 megabytes por solicitação. Mas é muito melhor de qualquer maneira, e em grandes conjuntos de dados a diferença será muito mais impressionante.
Crie um painel usando o Cube.js
Para criar um painel, usamos a estrutura analítica Cube.js. Ele tem algumas funções, mas estamos interessados em duas: a capacidade de usar automaticamente filtros em partições e pré-agregação de dados. Ele usa um esquema de dados escrito em Javascript para gerar SQL e executar uma consulta ao banco de dados. Tudo o que é necessário para nós é indicar como usar o filtro de partição no esquema de dados.
Vamos criar um novo aplicativo Cube.js. Como já usamos a pilha da AWS, é lógico usar o Lambda para implantação. Você pode usar o modelo expresso para geração se planeja hospedar o back-end Cube.js no Heroku ou Docker. A documentação descreve outros métodos de hospedagem .
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
Variáveis de ambiente são usadas para configurar o acesso ao banco de dados em cube.js. O gerador criará um arquivo .env no qual você pode especificar suas chaves para o Athena .
Agora precisamos de um esquema de dados no qual indicamos como nossos logs são armazenados. Lá você pode especificar como ler métricas para painéis.
No diretório de schema , crie o arquivo Logs.js Aqui está um exemplo de modelo de dados para nginx:
Código do modelo const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
Aqui usamos a variável FILTER_PARAMS para gerar uma consulta SQL com um filtro de partição.
Também especificamos as métricas e parâmetros que queremos exibir no painel e especificamos as pré-agregações. O Cube.js criará tabelas adicionais com dados pré-agregados e atualizará automaticamente os dados assim que estiverem disponíveis. Isso não apenas acelera as solicitações, mas também reduz o custo do uso do Athena.
Inclua essas informações no arquivo do esquema de dados:
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
Nesse modelo, indicamos que é necessário agregar previamente os dados para todas as métricas usadas e usar o particionamento mensal. O particionamento de pré-agregações pode acelerar significativamente a coleta e atualização de dados.
Agora podemos montar um painel!
O back-end do Cube.js fornece uma API REST e um conjunto de bibliotecas de clientes para estruturas de front-end populares. Usaremos a versão React do cliente para criar o painel. O Cube.js fornece apenas dados, por isso precisamos de uma biblioteca para visualizações - eu gosto de recargas , mas você pode usar qualquer.
O servidor Cube.js aceita a solicitação no formato JSON , que indica as métricas necessárias. Por exemplo, para calcular quantos erros o Nginx deu por dia, você precisa enviar a seguinte solicitação:
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
Instale o cliente Cube.js e a biblioteca de componentes React via NPM:
$ npm i --save @cubejs-client/core @cubejs-client/react
Importamos cubejs e componentes QueryRenderer para descarregar os dados e coletamos o painel:
Código do painel import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
As fontes do painel estão disponíveis no CodeSandbox .