No mês passado, na NVIDIA GTC 2019, a NVIDIA introduziu um novo aplicativo que transforma bolas coloridas simples desenhadas pelo usuário em imagens impressionantes e foto-realistas.
O aplicativo é construído sobre a tecnologia de
redes generativas competitivas (GAN), baseada em aprendizado profundo. A própria NVIDIA o chama de GauGAN - um trocadilho destinado a se referir ao artista Paul Gauguin. A funcionalidade GauGAN é baseada no novo algoritmo SPADE.
Neste artigo, explicarei como essa obra-prima de engenharia funciona. E, a fim de atrair o maior número possível de leitores interessados, tentarei dar uma descrição detalhada de como as redes neurais convolucionais funcionam. Como o SPADE é uma rede competitiva e geradora, vou falar mais sobre eles. Mas se você já conhece esse termo, pode ir imediatamente para a seção “Transmissão imagem a imagem”.
Geração de imagem
Vamos começar a entender: na maioria das aplicações modernas de aprendizado profundo, o tipo de discriminante neural (discriminador) é usado e o SPADE é uma rede neural generativa (gerador).
Discriminadores
O discriminador classifica os dados de entrada. Por exemplo, um classificador de imagens é um discriminador que captura uma imagem e seleciona um rótulo de classe adequado, por exemplo, define a imagem como "cachorro", "carro" ou "semáforo", ou seja, seleciona um rótulo que descreve a imagem inteira. A saída obtida pelo classificador é geralmente apresentada como um vetor de números
onde
É um número de 0 a 1, expressando a confiança da rede de que a imagem pertence ao objeto selecionado.
classe.
O discriminador também pode compilar uma lista de classificações. Ele pode classificar cada pixel de uma imagem como pertencendo à classe de "pessoas" ou "máquinas" (a chamada "segmentação semântica").
 O classificador obtém uma imagem com 3 canais (vermelho, verde e azul) e a compara com um vetor de confiança em cada classe possível que a imagem pode representar.
O classificador obtém uma imagem com 3 canais (vermelho, verde e azul) e a compara com um vetor de confiança em cada classe possível que a imagem pode representar.Como a conexão entre a imagem e sua classe é muito complexa, as redes neurais a passam por uma pilha de várias camadas, cada uma das quais a processa "levemente" e transfere sua saída para o próximo nível de interpretação.
Geradores
Uma rede generativa como o SPADE recebe um conjunto de dados e procura criar novos dados originais que parecem pertencer a essa classe de dados. Ao mesmo tempo, os dados podem ser qualquer coisa: sons, idioma ou outra coisa, mas vamos nos concentrar nas imagens. Em geral, a entrada de dados em uma rede desse tipo é simplesmente um vetor de números aleatórios, com cada um dos conjuntos possíveis de dados de entrada criando sua própria imagem.
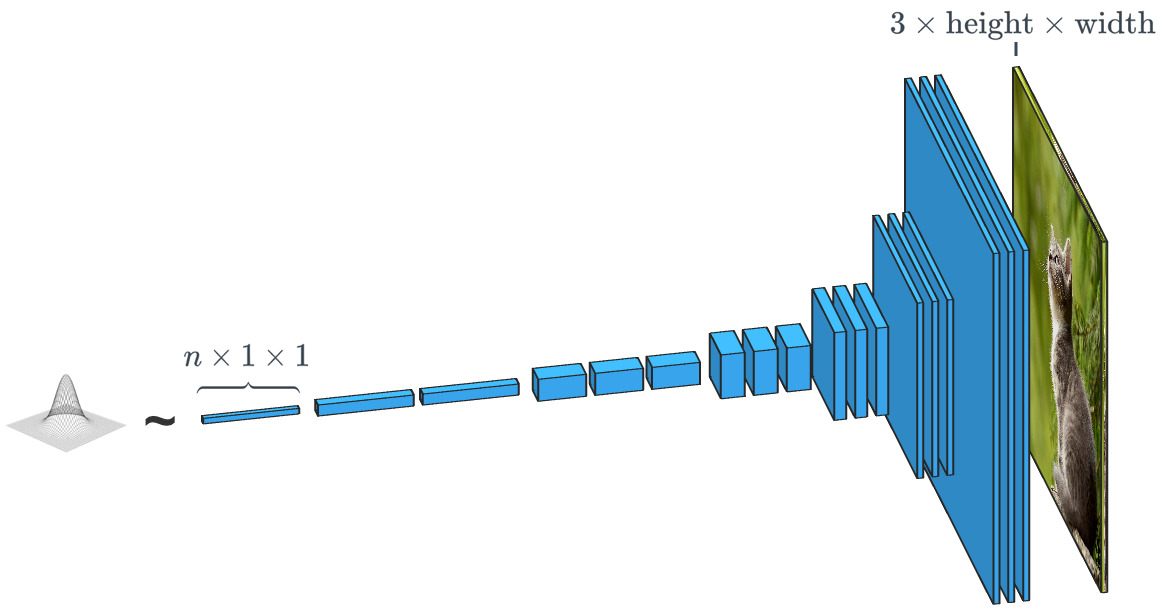 Um gerador baseado em um vetor de entrada aleatória funciona praticamente oposto ao classificador de imagem. Nos geradores de "classe condicional", o vetor de entrada é, de fato, o vetor de uma classe de dados inteira.
Um gerador baseado em um vetor de entrada aleatória funciona praticamente oposto ao classificador de imagem. Nos geradores de "classe condicional", o vetor de entrada é, de fato, o vetor de uma classe de dados inteira.Como já vimos, o SPADE usa muito mais do que apenas um "vetor aleatório". O sistema é guiado por um tipo de desenho chamado "mapa de segmentação". O último indica o que e onde postar. O SPADE conduz o processo oposto à segmentação semântica que mencionamos acima. Em geral, uma tarefa discriminatória que converte um tipo de dados em outro tem uma tarefa semelhante, mas segue um caminho diferente e incomum.
Geradores e discriminadores modernos geralmente usam redes convolucionais para processar seus dados. Para uma introdução mais completa às redes neurais convolucionais (CNNs), consulte o post
Chew on Karna ou o
trabalho de Andrey Karpati .
Há uma diferença importante entre o classificador e o gerador de imagens, e reside em como exatamente eles alteram o tamanho da imagem durante o processamento. O classificador de imagens deve reduzi-lo até que a imagem perca todas as informações espaciais e restem apenas as classes. Isso pode ser alcançado através da combinação de camadas ou do uso de redes convolucionais pelas quais os pixels individuais são transmitidos. O gerador, por outro lado, cria uma imagem usando o processo inverso de "convolução", que é chamado de transposição convolucional. Ele é freqüentemente confundido com "deconvolução" ou
"convolução reversa" .
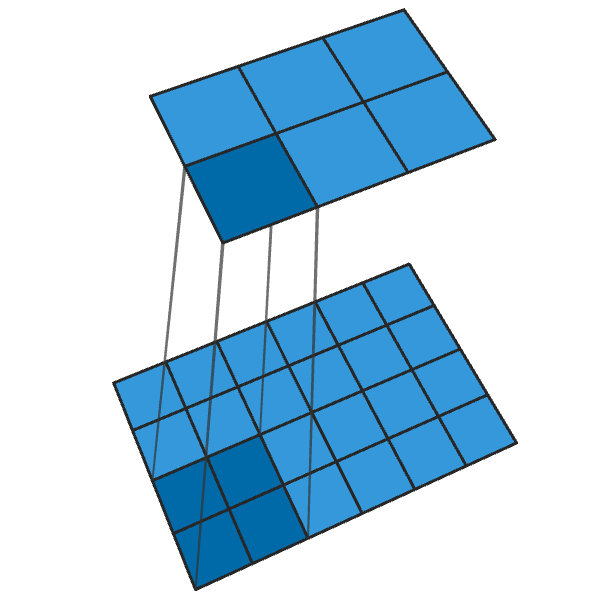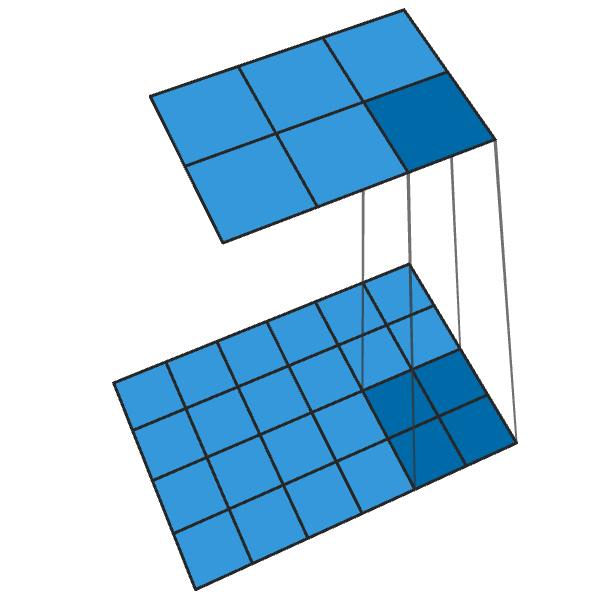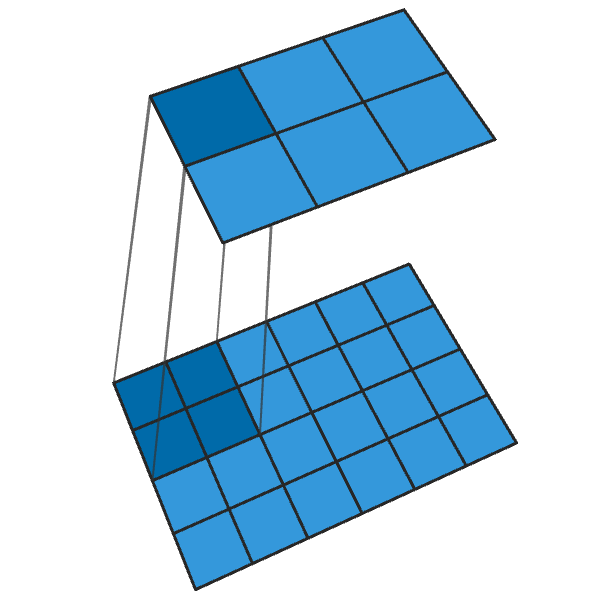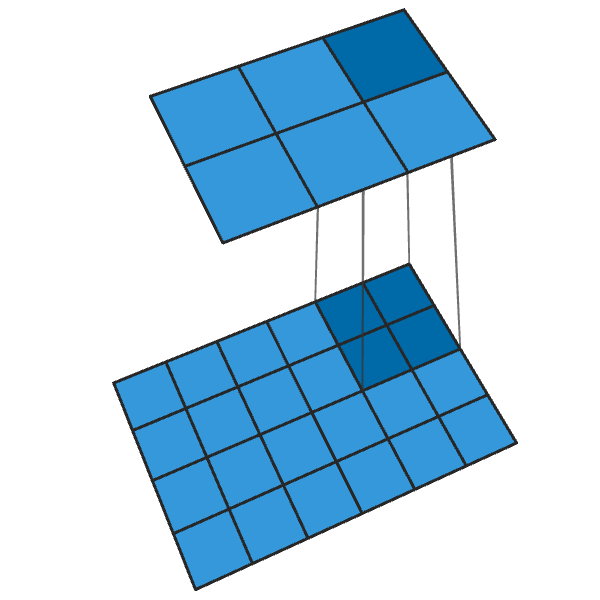
Convolução 2x2 convencional com uma etapa de "2" transforma cada bloco 2x2 em um ponto, reduzindo o tamanho da saída em 1/2.

Uma convolução 2x2 transposta com uma etapa "2" gera um bloco 2x2 de cada ponto, aumentando o tamanho da saída em 2 vezes.
Treinamento do gerador
Teoricamente, uma rede neural convolucional pode gerar imagens como descrito acima. Mas como a treinamos? Ou seja, se levarmos em conta o conjunto de dados da imagem de entrada, como podemos ajustar os parâmetros do gerador (no nosso caso, SPADE) para criar novas imagens que pareçam corresponder ao conjunto de dados proposto?
Para fazer isso, você precisa comparar com os classificadores de imagem, onde cada um deles tem o rótulo de classe correto. Conhecendo o vetor de previsão de rede e a classe correta, podemos usar o algoritmo de retropropagação para determinar os parâmetros de atualização da rede. Isso é necessário para aumentar sua precisão na determinação da classe desejada e reduzir a influência de outras classes.
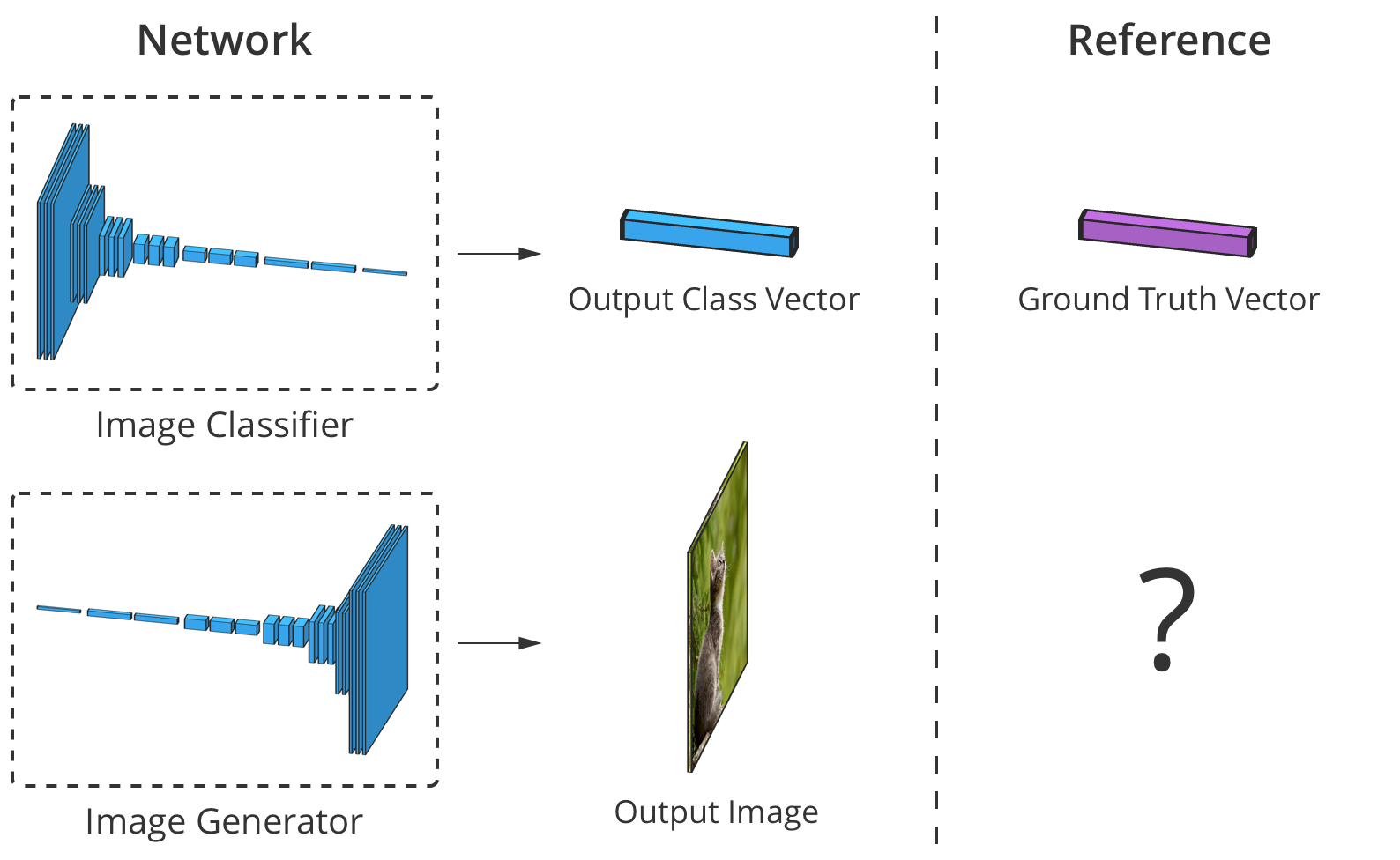 A precisão do classificador de imagem pode ser estimada comparando seu elemento de saída por elemento com o vetor de classe correto. Mas para geradores, não há imagem de saída "certa".
A precisão do classificador de imagem pode ser estimada comparando seu elemento de saída por elemento com o vetor de classe correto. Mas para geradores, não há imagem de saída "certa".O problema é que, quando o gerador cria uma imagem, não há valores "corretos" para cada pixel (não podemos comparar o resultado, como no caso de um classificador baseado em uma base previamente preparada, aprox. Trans.). Teoricamente, qualquer imagem que pareça crível e semelhante aos dados de destino é válida, mesmo que seus valores de pixel sejam muito diferentes das imagens reais.
Então, como podemos dizer ao gerador em quais pixels ele deve mudar sua saída e como criar imagens mais realistas (por exemplo, como emitir um "sinal de erro")? Os pesquisadores refletiram muito sobre essa questão e, de fato, é bastante difícil. A maioria das idéias, como calcular alguma "distância" média de imagens reais, produz imagens borradas e de baixa qualidade.
Idealmente, poderíamos "medir" o quão realista as imagens geradas parecem com o uso de um conceito de "alto nível", como "Quão difícil é distinguir essa imagem da imagem real?" ...
Redes adversárias generativas
Foi exatamente isso que foi implementado como parte de
Goodfellow et al., 2014 . A idéia é gerar imagens usando duas redes neurais em vez de uma: uma rede -
gerador, o segundo é um classificador de imagem (discriminador). A tarefa do discriminador é distinguir as imagens de saída do gerador das imagens reais do conjunto de dados primário (as classes dessas imagens são designadas como "falsas" e "reais"). O trabalho do gerador é enganar o discriminador criando imagens o mais semelhante possível às imagens no conjunto de dados. Podemos dizer que o gerador e o discriminador são oponentes nesse processo. Daí o nome:
rede gerador-adversário .
Como isso nos ajuda? Agora, podemos usar uma mensagem de erro baseada apenas na previsão do discriminador: um valor de 0 ("falso") a 1 ("real"). Como o discriminador é uma rede neural, podemos compartilhar suas conclusões sobre erros com o gerador de imagens. Ou seja, o discriminador pode dizer ao gerador onde e como deve ajustar suas imagens para "enganar" melhor o discriminador (isto é, como aumentar o realismo de suas imagens).
No processo de aprender a encontrar imagens falsas, o discriminador fornece ao gerador um feedback cada vez melhor sobre como este pode melhorar seu trabalho. Assim, o discriminador executa uma função de
"aprender uma perda" para o gerador.
Glorious Small GAN
A GAN considerada por nós em seu trabalho segue a lógica descrita acima. Seu discriminador
analisa a imagem
e obtém o valor
de 0 a 1, o que reflete seu grau de confiança de que a imagem é real ou falsificada pelo gerador. O gerador dele
obtém um vetor aleatório de números normalmente distribuídos
e exibe a imagem
que pode ser enganado pelo discriminador (de fato, esta imagem
)
Um dos problemas que não discutimos é como treinar o GAN e quais desenvolvedores de
funções de perda usam para medir o desempenho da rede. Em geral, a função de perda deve aumentar à medida que o discriminador é treinado e diminuir à medida que o gerador é treinado. A função de perda da fonte GAN usou os dois parâmetros a seguir. O primeiro é
representa o grau em que o discriminador classifica corretamente as imagens reais como reais. O segundo é o quão bem o discriminador detecta imagens falsas:
$ inline $ \ begin {equação *} \ mathcal {L} _ \ text {GAN} (D, G) = \ sub-suporte {E _ {\ vec {x} \ sim p_ \ text {data}} [\ log D ( \ vec {x})]} _ {\ text {precisão nas imagens reais}} + \ underbrace {E _ {\ vec {z} \ sim \ mathcal {N}} [\ log (1 - D (G (\ vec {z}))]} _ {\ text {precisão nas falsificações}} \ end {equation *} $ inline $
Discriminador
deriva sua afirmação de que a imagem é real. Faz sentido desde
aumenta quando o discriminador considera x real. Quando o discriminador detecta melhor imagens falsas, o valor da expressão também aumenta.
(começa a lutar por 1), já que
tenderá a 0.
Na prática, avaliamos a precisão usando lotes inteiros de imagens. Tomamos muitas (mas de nenhuma maneira todas) imagens reais
e muitos vetores aleatórios
para obter as médias de acordo com a fórmula acima. Depois, selecionamos erros comuns e um conjunto de dados.
Com o tempo, isso leva a resultados interessantes:
 Goodfellow GAN simulando conjuntos de dados MNIST, TFD e CIFAR-10. As imagens de contorno são as mais próximas do conjunto de dados às falsificações adjacentes.
Goodfellow GAN simulando conjuntos de dados MNIST, TFD e CIFAR-10. As imagens de contorno são as mais próximas do conjunto de dados às falsificações adjacentes.Tudo isso foi fantástico há apenas 4,5 anos. Felizmente, como mostram o SPADE e outras redes, o aprendizado de máquina continua a progredir rapidamente.
Problemas de treinamento
As redes competitivas entre gerações são notórias por sua complexidade na preparação e instabilidade do trabalho. Um dos problemas é que, se o gerador estiver muito à frente do discriminador no ritmo do treinamento, sua seleção de imagens será reduzida àquelas que o ajudarão a enganar o discriminador. De fato, como resultado, o treinamento do gerador se resume a criar uma imagem única e universal para enganar o discriminador. Esse problema é chamado de "modo de recolhimento".

O modo de recolhimento do GAN é semelhante ao do Goodfellow. Observe que muitas dessas imagens de quartos são muito semelhantes umas às outras.
FonteOutro problema é que, quando o gerador efetivamente engana o discriminador
, opera com um gradiente muito pequeno, portanto
Não é possível obter dados suficientes para encontrar a resposta verdadeira, na qual essa imagem pareceria mais realista.
Os esforços dos pesquisadores para resolver esses problemas visavam principalmente alterar a estrutura da função de perda. Uma das mudanças simples propostas por
Xudong Mao et al., 2016 é a substituição da função de perda
para algumas funções simples
, que são baseados em quadrados de área menor. Isso leva à estabilização do processo de treinamento, obtendo melhores imagens e menos chance de colapso usando gradientes não atenuados.
Outro problema que os pesquisadores encontraram é a dificuldade de obter imagens de alta resolução, em parte porque uma imagem mais detalhada fornece ao discriminador mais informações para detectar imagens falsas. Os GANs modernos começam a treinar a rede com imagens de baixa resolução e gradualmente adicionam mais e mais camadas até que o tamanho de imagem desejado seja alcançado.
 A adição gradual de camadas com maior resolução durante o treinamento GAN aumenta significativamente a estabilidade de todo o processo, bem como a velocidade e a qualidade da imagem resultante.
A adição gradual de camadas com maior resolução durante o treinamento GAN aumenta significativamente a estabilidade de todo o processo, bem como a velocidade e a qualidade da imagem resultante.Transmissão imagem a imagem
Até agora, falamos sobre como gerar imagens a partir de conjuntos aleatórios de dados de entrada. Mas o SPADE não usa apenas dados aleatórios. Essa rede usa uma imagem chamada mapa de segmentação: atribui uma classe de material a cada pixel (por exemplo, grama, madeira, água, pedra, céu). A partir desta imagem, o cartão é SPADE e gera o que parece uma foto. Isso é chamado de "transmissão imagem a imagem".
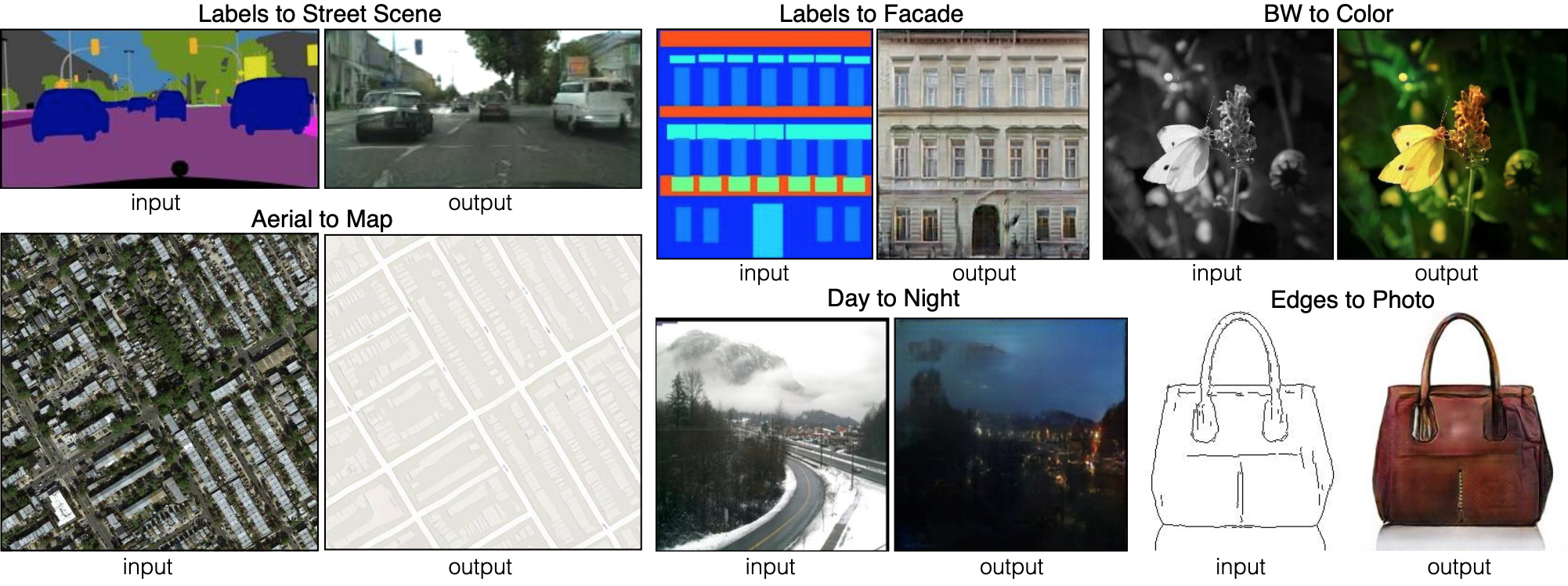 Seis tipos diferentes de transmissões Imagem a Imagem demonstradas pelo pix2pix. O Pix2pix é o antecessor das duas redes, que discutiremos mais adiante: pix2pixHD e SPADE.
Seis tipos diferentes de transmissões Imagem a Imagem demonstradas pelo pix2pix. O Pix2pix é o antecessor das duas redes, que discutiremos mais adiante: pix2pixHD e SPADE.Para que o gerador aprenda essa abordagem, ele precisa de um conjunto de mapas de segmentação e fotos correspondentes. Estamos modificando a arquitetura GAN para que tanto o gerador quanto o discriminador recebam um mapa de segmentação. O gerador, é claro, precisa de um mapa para saber "para que lado desenhar". O discriminador também precisa dele para garantir que o gerador coloque as coisas certas nos lugares certos.
Durante o treinamento, o gerador aprende a não colocar grama onde “céu” é indicado no mapa de segmentação, porque, caso contrário, o discriminador poderá detectar facilmente uma imagem falsa e assim por diante.
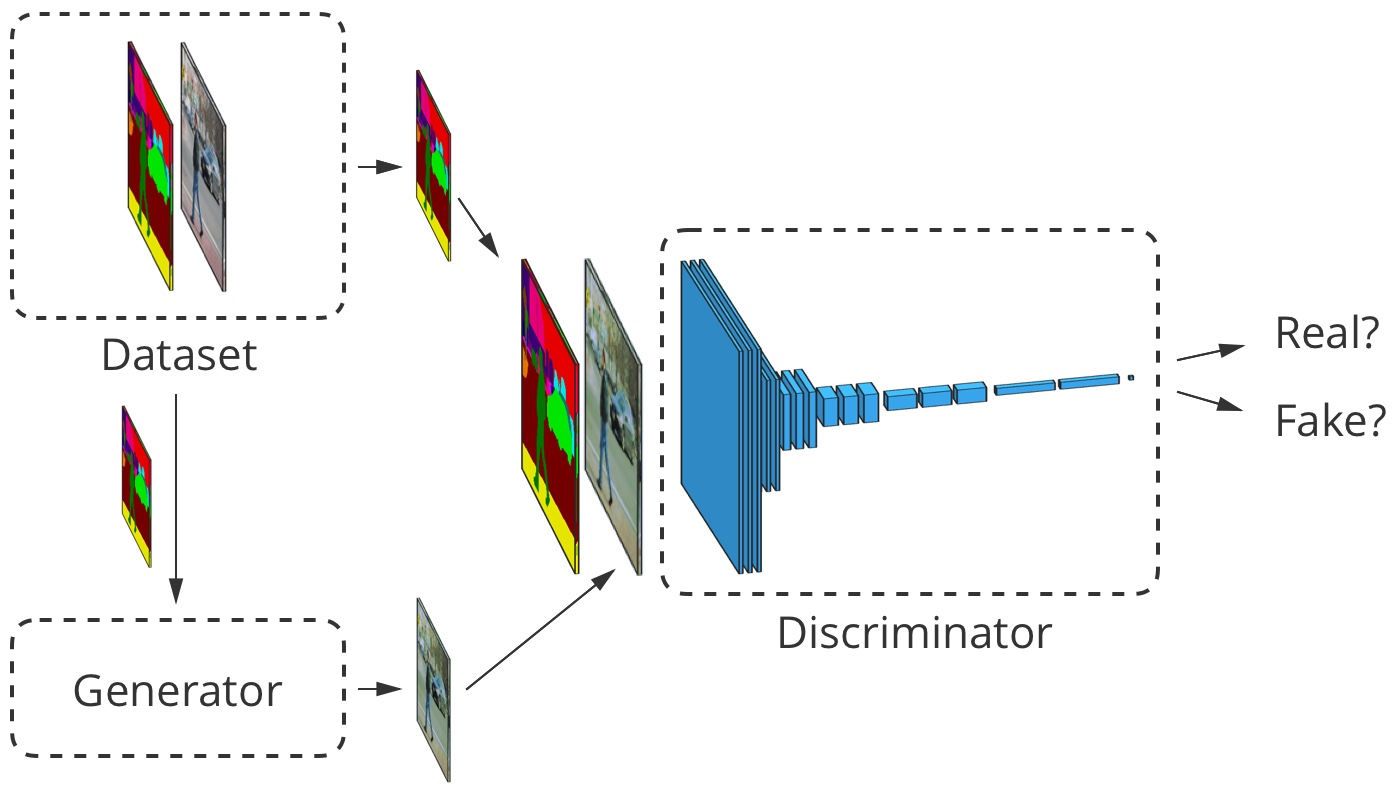 Para tradução imagem a imagem, a imagem de entrada é aceita pelo gerador e pelo discriminador. O discriminador recebe adicionalmente a saída do gerador ou a saída verdadeira do conjunto de dados de treinamento. Exemplo
Para tradução imagem a imagem, a imagem de entrada é aceita pelo gerador e pelo discriminador. O discriminador recebe adicionalmente a saída do gerador ou a saída verdadeira do conjunto de dados de treinamento. ExemploDesenvolvimento de tradutor de imagem para imagem
Vejamos um verdadeiro tradutor de imagem para imagem:
pix2pixHD . A propósito, o SPADE foi projetado para a maior parte da imagem e semelhança do pix2pixHD.
Para um tradutor de imagem para imagem, nosso gerador cria uma imagem e a aceita como entrada. Poderíamos usar apenas um mapa de camadas convolucionais, mas como as camadas convolucionais combinam valores apenas em pequenas áreas, precisamos de muitas camadas para transmitir informações de imagem de alta resolução.
O pix2pixHD resolve esse problema com mais eficiência com a ajuda do "Encoder", que reduz a escala da imagem de entrada, seguido pelo "Decoder", que aumenta a escala para obter a imagem de saída. Como veremos em breve, o SPADE tem uma solução mais elegante que não requer um codificador.
 Diagrama de rede Pix2pixHD em um nível "alto". Os blocos “residuais” e “+ operação” se referem à tecnologia “pular conexões” da rede neural residual . Existem blocos de salto na rede, que são interconectados no codificador e decodificador.
Diagrama de rede Pix2pixHD em um nível "alto". Os blocos “residuais” e “+ operação” se referem à tecnologia “pular conexões” da rede neural residual . Existem blocos de salto na rede, que são interconectados no codificador e decodificador.Normalização de lote é um problema
Quase todas as redes neurais convolucionais modernas usam a normalização de lotes ou um de seus análogos para acelerar e estabilizar o processo de treinamento. A ativação de cada canal muda a média para 0 e o desvio padrão para 1 antes de um par de parâmetros de canal
e
deixe-os desnormalizarem novamente.
Infelizmente, a normalização em lote prejudica os geradores, dificultando a implementação da rede de alguns tipos de processamento de imagem. Em vez de normalizar um lote de imagens, o pix2pixHD usa um
padrão de normalização , que normaliza cada imagem individualmente.
Treinamento Pix2pixHD
GANs modernos, como pix2pixHD e SPADE, medem o realismo de suas imagens de saída um pouco diferente do que foi descrito para o design original de redes de contenção generativas.
Para resolver o problema de gerar imagens de alta resolução, o pix2pixHD usa três discriminadores da mesma estrutura, cada um dos quais recebe a imagem de saída em uma escala diferente (tamanho normal, reduzido em 2 vezes e reduzido em 4 vezes).
Pix2pixHD usa
, e também inclui outro elemento projetado para tornar as conclusões do gerador mais realistas (independentemente de isso ajudar a enganar o discriminador). Este item
chamado “correspondência de recursos” - incentiva o gerador a fazer a distribuição das camadas da mesma maneira ao simular a discriminação entre dados reais e as saídas do gerador, minimizando
entre eles.
Portanto, a otimização se resume ao seguinte:
exibição $$ $$ \ begin {equação *} \ min_G \ bigg (\ lambda \ sum_ {k = 1,2,3} V_ \ text {LSGAN} (G, D_k) + \ big (\ max_ {D_1, D_2 , D_3} \ sum_ {k = 1,2,3} \ mathcal {L} _ \ text {FM} (G, D_k) \ big) \ bigg) \ end {equação *}, $$ display $$
onde as perdas são resumidas por três fatores discriminatórios e coeficiente
, que controla a prioridade de ambos os elementos.
 O pix2pixHD usa um mapa de segmentação composto por um quarto real (à esquerda em cada exemplo) para criar um quarto falso (à direita).
O pix2pixHD usa um mapa de segmentação composto por um quarto real (à esquerda em cada exemplo) para criar um quarto falso (à direita).Embora os discriminadores reduzam a escala da imagem até desmontar a imagem inteira, eles param em "pontos" do tamanho 70 × 70 (em escalas apropriadas). Depois, eles simplesmente resumem todos os valores desses "pontos" para a imagem inteira.
E essa abordagem funciona bem, já que a função
, ,
. , .
 pix2pixHD . CelebA , .
pix2pixHD . CelebA , .pix2pixHD?
, . , pix2pixHD .
, pix2pixHD , , , . , . «» ()
. β- , : , «», «», «» - .
pix2pixHD . , , .— SPADE.
: SPADE
- : - () (SPADE).
SPADE , , γ, β, , . , 2 .
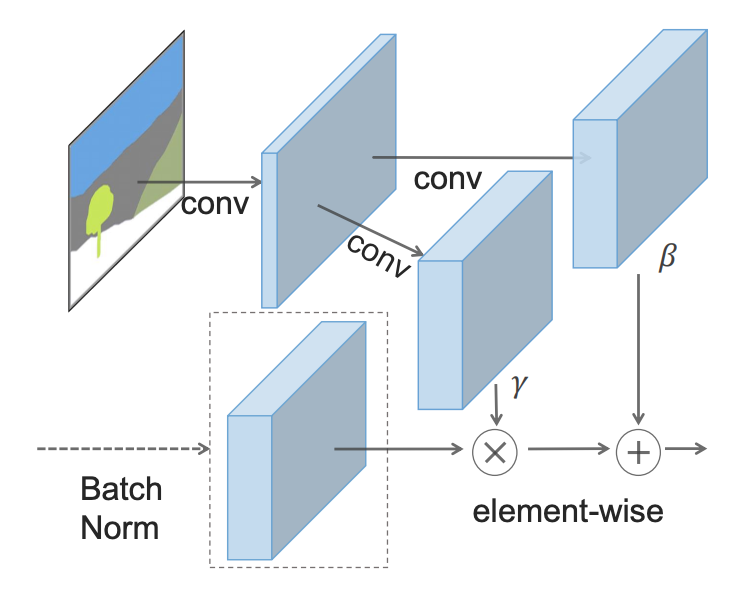 , SPADE .
, SPADE .SPADE « », ( ):
 SPADE pix2pixHD
SPADE pix2pixHD, «» , . GAN, . (« »). «» pix2pixHD, .
SPADE , pix2pixHD, :
hinge loss .
:
 SPADE pix2pixHD
SPADE pix2pixHD, SPADE . . GauGAN «» , . , - SPADE , «» , .
, SPADE , «» .
, , «». SPADE , , ? 55, «».
, , 5x5 . , .
SPADE , , , , pix2pixHD. , .
SPADE — (, , , ).
 SPADE , .
SPADE , .: ,
, . , , SPADE , , .
, . , ,
.
É assim que o SPADE / GaiGAN funciona. Espero que este artigo tenha satisfeito sua curiosidade sobre como o novo sistema NVIDIA funciona. Você pode entrar em contato comigo pelo Twitter @AdamDanielKin ou e-mail adam@AdamDKing.com.