Há pouco tempo, deparei-me com uma tarefa bastante simples e ao mesmo tempo interessante: implementar terminal somente leitura em um aplicativo da web. O interesse na tarefa foi dado por três aspectos importantes:
- suporte para seqüências básicas de escape ANSI
- suporte para pelo menos 50.000 linhas de dados
- exibir dados assim que estiverem disponíveis.
Neste artigo, falarei sobre como foi implementado e como otimizou tudo.
Isenção de responsabilidade: não sou desenvolvedor web experiente, portanto algumas coisas podem parecer óbvias para você e as conclusões ou decisões estão erradas. Por correções e esclarecimentos, serei grato.
Por que isso
A tarefa toda é a seguinte: um script está sendo executado no servidor (bash, python etc.) e escreve algo no stdout. E essa conclusão deve ser exibida na página da Web à medida que ela chega. Ao mesmo tempo, deve ser semelhante ao terminal (com formatação, transferência de cursor etc.)
Eu não controlo o próprio script e sua saída de forma alguma e o mostro de forma pura.
Obviamente, entre a interface da web e o script, deve haver um intermediário - um servidor da web. E se não dissimular - eu já tenho um aplicativo da web e um servidor, e de alguma forma funcionar. O esquema é mais ou menos assim:

Mas antes, o servidor era responsável pelo processamento e formatação. E eu queria melhorá-lo por um grande número de razões:
- processamento de dados duplo - primeiro analisando no servidor e depois transformando em componentes html no cliente
- algoritmo não ideal devido à preparação de dados para o cliente
- carga pesada no servidor - o processamento da saída de um único script pode carregar completamente um único encadeamento no servidor
- suporte incompleto para seqüências de escape ANSI
- erros sutis
- o cliente se saiu muito mal ao exibir até 10k linhas formatadas
Portanto, foi decidido transferir toda a lógica de análise para o aplicativo Web e deixar apenas o fluxo de dados brutos para o servidor
Declaração do problema
Partes do texto chegam ao cliente. O cliente deve analisá-los em componentes: texto sem formatação, avanço de linha, retorno de carro e comandos ANSI especiais. Não há garantias na integridade das partes - um comando ou uma palavra pode vir em pacotes diferentes.
Os comandos ANSI podem afetar o formato do texto (cor, plano de fundo, estilo), a posição do cursor (de onde o texto subsequente deve ser exibido) ou para limpar parte da tela.
Um exemplo de como é:

Além disso, pode haver URLs no texto que também precisam ser reconhecidos e destacados.
Tomamos a biblioteca acabada e ...
Entendi que o processamento correto e rápido de todos os comandos não é uma tarefa fácil. Por isso, decidi procurar uma biblioteca pronta. E eis que eu imediatamente me deparei com o xterm.js . Um componente pronto do terminal, que já é usado em muitos lugares e, além disso, "é realmente rápido, inclui até um renderizador acelerado por GPU" . O último foi o mais importante para mim, porque Eu finalmente queria ter um cliente muito rápido.
Apesar de gostar de escrever minhas próprias bicicletas, fiquei extremamente feliz por não apenas economizar tempo, mas também obter várias funcionalidades úteis gratuitamente.
Levei duas horas para tentar conectar o terminal e não consegui lidar com isso. Absolutamente.
Diferentes alturas de linha, seleção distorcida, tamanho adaptativo do terminal, uma API muito estranha, falta de documentação sã ...
Mas eu ainda tinha um pouco de inspiração e acreditava que poderia lidar com esses problemas.
Até eu alimentar meu teste de 10k linhas no terminal ... Ele morreu. E enterrou comigo os restos de minhas esperanças.
Descrição do algoritmo final
Primeiro, copiei o algoritmo atual implementado em python e o adaptei para javascript (apenas removendo chaves e outro para sintaxe).
Eu conhecia todos os principais prós e contras do antigo algoritmo, então só precisava melhorar os lugares ineficazes nele.
Após deliberação, tentativa e erro, decidi pela seguinte opção: dividimos o algoritmo em 2 componentes:
- modelo para analisar texto e armazenar o estado atual do "terminal"
- mapeamento que traduz o modelo em HTML
Modelo (estrutura e algoritmo)
- Todas as linhas são armazenadas em uma matriz (número da linha = índice na matriz)
- Os estilos de texto são armazenados em uma matriz separada.
- A posição atual do cursor é armazenada e pode ser alterada por comandos
- O próprio algoritmo verifica os dados de entrada caractere por caractere:
- Se for apenas texto, adicione à linha atual
- Se houver quebra de linha, aumente o índice da linha atual
- Se esse é um dos caracteres de comando, colocamos no buffer de comando e aguardamos o próximo caractere
- Se o buffer do comando estiver correto, execute este comando, caso contrário, escrevemos esse buffer como texto
- O modelo notifica os ouvintes sobre quais linhas foram alteradas após o processamento de texto recebido
Na minha implementação, a complexidade do algoritmo é O ( n log n ), em que log n é a preparação de linhas alteradas para notificação (exclusividade e classificação). No momento da redação deste artigo, percebi que, em um caso especial, você pode se livrar do log n , já que as linhas são adicionadas com mais freqüência ao final.
Exibição
- Exibe texto como elementos HTML
- Se a sequência foi alterada, substitui completamente todos os elementos da sequência
- Quebra cada linha com base em estilos: cada segmento estilizado tem seu próprio elemento
Com essa estrutura, testar é uma tarefa bastante simples - transferimos o texto para o modelo (em um único pacote ou em partes) e apenas verificamos o estado atual de todas as linhas e estilos nele. E para exibir apenas alguns testes, porque sempre redesenha as linhas alteradas.
Uma vantagem importante é também uma certa preguiça da tela. Se em um pedaço de texto sobrescrevermos a mesma linha (por exemplo, barra de progresso), depois que o modelo funcionar, para exibição, ele parecerá com uma linha alterada.
DOM vs Canvas
Eu gostaria de pensar um pouco sobre por que escolhi o DOM, embora o objetivo fosse desempenho. A resposta é simples - preguiça. Para mim, renderizar tudo no Canvas sozinho parece uma tarefa bastante assustadora. Mantendo a usabilidade: realçar, copiar, redimensionar a tela, parecer elegante, etc. O exemplo do xterm.js me mostrou claramente que isso não é nada fácil. Sua renderização em tela estava longe de ser ideal.
Além disso, a depuração da árvore DOM no navegador e a capacidade de cobrir testes de unidade são uma vantagem importante.
No final, meu objetivo era 50 mil linhas e eu sabia que o DOM tinha que lidar com isso, com base no trabalho do antigo algoritmo.
Otimizações
O algoritmo estava pronto, depurado e lenta mas seguramente funcionou. Estava na hora de abrir o criador de perfil e otimizar. Olhando para o futuro, direi que a maioria das otimizações foi uma surpresa para mim (como geralmente acontece).
A criação de perfil foi realizada em 10 mil linhas, cada uma contendo elementos estilizados. O número total de elementos DOM é de cerca de 100k.
Nenhuma abordagem e ferramentas especiais foram usadas. Somente o Chrome Dev Tools e algumas ativações para cada medição. Na prática, apenas os valores absolutos de medição (quantos segundos para concluir) diferiam nos lançamentos, mas não uma proporção percentual entre os métodos. Portanto, considero essa técnica condicionalmente suficiente.
Abaixo, gostaria de abordar com mais detalhes as melhorias mais interessantes. E, para começar, um gráfico do que era:

Todos os gráficos de criação de perfil foram criados após a implementação, otimizando o código da memória.
string.trim
Primeiro de tudo, me deparei com uma string.trim incompreensível que consumia uma quantidade muito perceptível de CPU (parece-me que isso era de 10 a 20%)

trim () é a função básica do idioma. Por que está usando algum tipo de biblioteca? E mesmo que seja algum tipo de polyfill, por que ativou a versão mais recente do chrome?
Um pouco de pesquisa e a resposta é encontrada: https://babeljs.io/docs/en/babel-preset-env . Por padrão, ele habilita o polyfill para um número bastante grande de navegadores e faz isso no estágio de compilação. A solução para mim foi especificar 'targets': '> 0.25%, not dead'
Mas, no final, excluí a chamada de corte completamente, como desnecessária.
Vue.js
No ano passado, transferi o componente terminal para o Vue.js. Agora eu tive que transferi-lo de volta para baunilha, o motivo está na captura de tela abaixo (veja o número de linhas envolvendo o Vue.js):
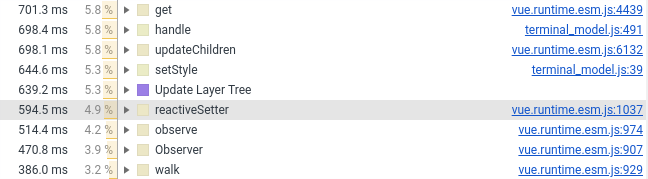
Deixei apenas wrapper, estilos e processamento de mouse no componente Vue. Tudo o que se refere à criação de elementos DOM foi para JS puro, que é conectado ao componente Vue como um campo normal (que não é monitorado pela estrutura).
created() { this.terminalModel = new TerminalModel(); this.terminal = new Terminal(this.terminalModel); },
Eu não considero isso um sinal de menos ou uma falha no Vue.js. Só que estruturas e desempenho em si não se misturam bem. Bem, quando você coloca dezenas e centenas de milhares de objetos em uma estrutura reativa, é muito difícil esperar o processamento dentro de alguns milissegundos. E, para ser sincero, fico surpreso que o Vue.js tenha se saído muito bem.
Adicionando novos itens
Tudo é simples aqui - se você possui vários milhares de novos elementos e deseja adicioná-los ao componente pai, fazer appendChild não é uma boa ideia. O navegador precisa fazer o processamento um pouco mais frequentemente e gastar mais tempo na renderização. Um dos efeitos colaterais no meu caso foi uma desaceleração na rolagem automática, pois força uma recontagem de todos os componentes adicionados.

Para resolver o problema, existe um DocumentFragment. Primeiro, adicionamos todos os elementos a ele e depois ao componente pai. O navegador cuidará da linha dos componentes recebidos.
Essa abordagem reduz a quantidade de tempo que o navegador gasta na renderização e organização dos elementos.
Eu também tentei outras maneiras de acelerar a adição de itens. Nenhum deles poderia adicionar nada sobre o DocumentFragment.
span vs div
De fato, isso poderia ser chamado de display:inline (span) vs display:block (div).
Inicialmente, eu tinha todas as linhas no intervalo e terminei com um caractere de quebra de linha. No entanto, em termos de desempenho, isso não é muito eficaz: o navegador precisa descobrir onde o elemento começa e termina. Com display: block, esses cálculos são muito mais simples.
A substituição por uma renderização acelerada por div quase duas vezes.
Infelizmente, no caso de display:block destacar várias linhas de texto parece pior:

Durante muito tempo, não pude decidir qual é o melhor - mais 2 segundos de renderização ou seleção humana. Como resultado, a praticidade derrotou a beleza.
Assistente CSS de nível 10
Outros ~ 10% do tempo de renderização foram cortados pela "otimização" do CSS, que eu uso para formatar o texto.
Inexperiência no desenvolvimento web e compreensão do básico jogado contra mim. Eu pensei que quanto mais precisos os seletores, melhor, mas especificamente no meu caso, não era assim.
Para formatar o texto no terminal, usei os seguintes seletores:
#script-panel-container .log-content > div > span.text_color_green,
Mas (no chrome), a seguinte opção é um pouco mais rápida:
span.text_color_green
Eu realmente não gosto desse seletor, porque global demais, mas o desempenho é mais caro.
string.split
Se você tem um déjà vu devido a um dos pontos anteriores, é falso. Desta vez, não se trata de polyfill, mas da implementação padrão no chrome:

(Embrulhei string.split em defSplit para que a função apareça no criador de perfil)
1% são triviais. Mas o ciclista idealista em mim foi assombrado. No meu caso, a divisão é sempre feita um caractere de cada vez e sem regulares. Portanto, implementei uma opção simples. Aqui está o resultado:

fastSplit function fastSplit(str, separatorChar) { if (str === '') { return ['']; } let result = []; let lastIndex = 0; for (let i = 0; i < str.length; i++) { const char = str[i]; if (char === separatorChar) { const chunk = str.substr(lastIndex, i - lastIndex); lastIndex = i + 1; result.push(chunk); } } if (lastIndex < str.length) { const lastChunk = str.substr(lastIndex, str.length - lastIndex); result.push(lastChunk); } return result; }
Acredito que, depois disso, eles sejam obrigados a me levar à equipe do Google Chrome sem uma entrevista.
Otimização, posfácio
A otimização é um processo sem fim e algo pode ser melhorado indefinidamente. Especialmente considerando que diferentes casos de uso requerem otimizações diferentes (e conflitantes).
No meu caso, escolhi o caso de uso principal e otimizei o tempo de operação de 15 segundos para 5 segundos. Por isso, decidi parar.

Ainda pretendo melhorar alguns lugares, mas isso se deve à experiência adquirida.
Bônus Teste de mutação.
Aconteceu que, nos últimos meses, encontrei frequentemente o termo "teste mutacional". E eu decidi que esta tarefa é uma ótima maneira de experimentar esta fera. Especialmente depois que não recebi cobertura de código no Webstorm, para testes de carma.
Como a técnica e a biblioteca são novas para mim, decidi me dar bem com um pouco de sangue: testar apenas um componente - o modelo. Nesse caso, você pode indicar claramente qual arquivo estamos testando e qual suíte de teste se destina a ele.
Mas o que quer que se possa dizer, eu tive que mexer muito para conseguir a integração com o karma e o webpack.
No final, tudo começou e depois de meia hora eu vi resultados tristes: cerca de metade dos mutantes sobreviveram. Eu matei parte imediatamente, parte deixada para o futuro (quando implementei os comandos ANSI ausentes).
Depois disso, a preguiça venceu e, no momento, os resultados são os seguintes (para 128 testes):
Ran 79.04 tests per mutant on average. ------------------|---------|----------|-----------|------------|---------| File | % score | # killed | # timeout | # survived | # error | ------------------|---------|----------|-----------|------------|---------| terminal_model.js | 73.10 | 312 | 25 | 124 | 1 | ------------------|---------|----------|-----------|------------|---------| 23:01:08 (18212) INFO Stryker Done in 26 minutes 32 seconds.
Em geral, essa abordagem me pareceu muito útil (obviamente melhor que a cobertura de código) e engraçada. O único aspecto negativo é um tempo terrivelmente longo - 30 minutos por aula é demais.
E o mais importante, essa abordagem me fez pensar novamente em 100% de cobertura e se vale a pena cobrir tudo com testes: agora minha opinião está ainda mais próxima de "sim" ao responder a essa pergunta.
Conclusão
A otimização de desempenho, na minha opinião, é uma boa maneira de aprender algo mais profundo. Também é um bom treino para o cérebro. E é uma pena que isso raramente seja realmente necessário (pelo menos nos meus projetos).
E, como sempre, a abordagem de “primeiro perfil e depois otimização” funciona muito melhor do que a intuição.
Referências
Implementação antiga:
Nova implementação:
Infelizmente, não há demonstração de componentes da web, então você não poderá cutucá-la. Então peço desculpas antecipadamente
Obrigado pelo seu tempo, terei prazer em comentários, sugestões e críticas razoáveis!