Prefácio
Frequentemente, usuários, desenvolvedores e administradores de DBMSs do MS SQL Server enfrentam problemas de desempenho do banco de dados ou DBMS em geral, portanto, o monitoramento do MS SQL Server é muito relevante.
Este artigo é uma adição ao artigo
Usando o Zabbix para monitorar o banco de dados do MS SQL Server e examinará alguns aspectos do monitoramento do MS SQL Server, em particular: como determinar rapidamente quais recursos estão faltando, bem como recomendações para definir sinalizadores de rastreamento.
Para que os seguintes scripts funcionem, você deve criar o esquema inf no banco de dados desejado da seguinte maneira:
Criando infuse <_>; go create schema inf;
Método para detectar falta de RAM
O primeiro indicador de falta de RAM ocorre quando uma instância do MS SQL Server consome toda a RAM alocada.
Para fazer isso, crie a seguinte exibição inf.vRAM:
Criando uma visualização inf.vRAM CREATE view [inf].[vRAM] as select a.[TotalAvailOSRam_Mb]
Em seguida, você pode determinar que a instância do MS SQL Server consome toda a memória alocada a ela pela seguinte consulta:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb from [inf].[vRAM];
Se o indicador SQL_server_physical_memory_in_use_Mb for constantemente não inferior a SQL_server_committed_target_Mb, será necessário verificar as estatísticas das expectativas.
Para determinar a falta de RAM por meio das estatísticas de expectativa, crie uma visualização inf.vWaits:
Criando uma exibição inf.vWaits CREATE view [inf].[vWaits] as WITH [Waits] AS (SELECT [wait_type],
Nesse caso, você pode determinar a falta de RAM pela seguinte consulta:
SELECT [Percentage] ,[AvgWait_S] FROM [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Aqui você precisa prestar atenção ao desempenho de Porcentagem e AvgWait_S. Se eles são significativos em sua totalidade, há uma probabilidade muito alta de que a RAM não seja suficiente para uma instância do MS SQL Server. Valores essenciais são determinados individualmente para cada sistema. No entanto, você pode começar com a seguinte métrica: Porcentagem> = 1 e AvgWait_S> = 0,005.
Para emitir indicadores para um sistema de monitoramento (por exemplo, Zabbix), você pode criar as duas consultas a seguir:
- quanto em porcentagem os tipos de expectativas para RAM ocupam (a soma de todos esses tipos de expectativas):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
- quantos milissegundos os tipos de expectativas para RAM ocupam (o valor máximo de todos os atrasos médios para todos esses tipos de expectativas):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Com base na dinâmica dos valores obtidos para esses dois indicadores, podemos concluir se há RAM suficiente para a instância do MS SQL Server.
Método de detecção de sobrecarga da CPU
Para identificar a falta de tempo da CPU, basta usar a exibição do sistema sys.dm_os_schedulers. Aqui, se o indicador runnable_tasks_count for constantemente maior que 1, há uma alta probabilidade de que o número de núcleos não seja suficiente para uma instância do MS SQL Server.
Para exibir o indicador em um sistema de monitoramento (por exemplo, Zabbix), você pode criar a seguinte consulta:
select max([runnable_tasks_count]) as [runnable_tasks_count] from sys.dm_os_schedulers where scheduler_id<255;
Com base na dinâmica dos valores obtidos para esse indicador, podemos concluir se há tempo de processador suficiente (o número de núcleos da CPU) para uma instância do MS SQL Server.
No entanto, é importante lembrar que as próprias solicitações podem solicitar vários encadeamentos de uma só vez. E, às vezes, o otimizador não pode avaliar corretamente a complexidade da própria solicitação. Em seguida, a solicitação pode receber muitos encadeamentos que, em um determinado momento, não podem ser processados simultaneamente. E isso também causa um tipo de espera associado à falta de tempo do processador e o crescimento da fila para agendadores que usam núcleos de CPU específicos, ou seja, o indicador runnable_tasks_count aumentará nessas condições.
Nesse caso, antes de aumentar o número de núcleos da CPU, você deve configurar corretamente as propriedades de paralelismo da instância do MS SQL Server e, a partir da versão 2016, configurar corretamente as propriedades de paralelismo dos bancos de dados necessários:

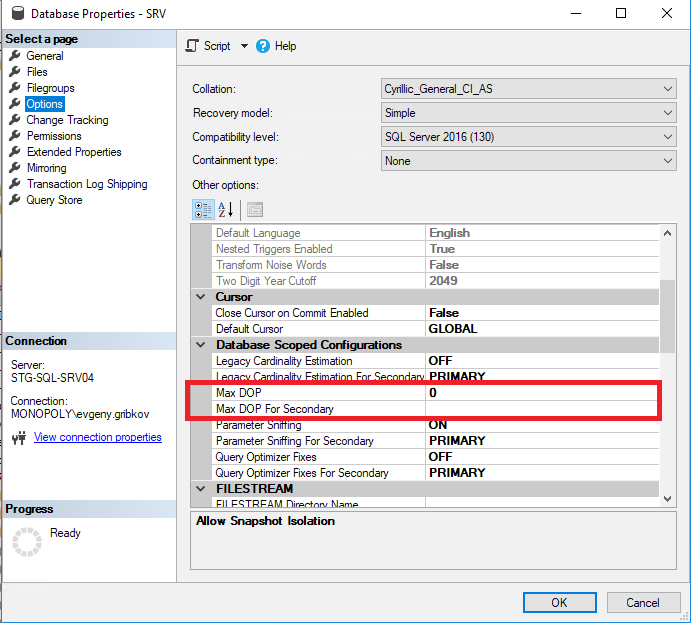
Aqui vale a pena prestar atenção aos seguintes parâmetros:
- Grau máximo de paralelismo - define o número máximo de threads que podem ser alocados para cada solicitação (o padrão é restrição a 0 apenas pelo sistema operacional e pela edição do MS SQL Server)
- Limiar de custo para paralelismo - custo estimado do paralelismo (o padrão é 5)
- DOP máximo define o número máximo de threads que podem ser alocados para cada consulta no nível do banco de dados (mas não mais do que o valor da propriedade "Max Degree of Parallelism") (o padrão é restrição de 0 apenas pelo sistema operacional e pela edição do MS SQL Server, bem como a restrição na propriedade "Max Degree of Parallelism" de toda a instância do MS SQL Server)
É impossível fornecer uma receita igualmente boa para todos os casos, ou seja, você precisa analisar solicitações difíceis.
Por experiência própria, recomendo o seguinte algoritmo de ações para sistemas OLTP para configurar propriedades de paralelismo:
- banir a simultaneidade pela primeira vez, definindo o nível de toda a instância do Max Degree of Parallelism como 1
- analise os pedidos mais difíceis e escolha o número ideal de threads para eles
- configure Max Degree of Parallelism para o número ideal selecionado de threads obtidos no item 2 e, para bancos de dados específicos, defina o valor Max DOP obtido no item 2 para cada banco de dados
- analise os pedidos mais difíceis e identifique o efeito negativo do multithreading. Se for, aumente o Limite de custo para paralelismo.
Para sistemas como 1C, Microsoft CRM e Microsoft NAV, na maioria dos casos, a proibição de multithreading é adequada.
Além disso, se a edição Standard estiver instalada, na maioria dos casos a proibição de multithreading é adequada devido ao fato de que esta edição é limitada pelo número de núcleos da CPU.
Para sistemas OLAP, o algoritmo descrito acima não é adequado.
Por experiência própria, recomendo o seguinte algoritmo de ações para sistemas OLAP para definir propriedades de paralelismo:
- analise os pedidos mais difíceis e escolha o número ideal de threads para eles
- defina o Grau máximo de paralelismo para o número ideal selecionado de encadeamentos obtidos no item 1 e também para bancos de dados específicos defina o valor Max DOP obtido no item 1 para cada banco de dados
- analise as solicitações mais difíceis e identifique o efeito negativo do limite de simultaneidade. Se estiver, abaixe o valor do Limite de custo para paralelismo ou repita as etapas 1-2 deste algoritmo
Ou seja, para sistemas OLTP, passamos de single-threaded para multithreading, e para sistemas OLAP, pelo contrário, passamos de multithreading para single-threaded. Portanto, é possível selecionar as configurações de simultaneidade ideais para um banco de dados específico e para toda a instância do MS SQL Server.
Também é importante entender que as configurações de propriedades de simultaneidade precisam ser alteradas com o tempo, com base nos resultados do monitoramento do desempenho do MS SQL Server.
Recomendações para definir sinalizadores de rastreamento
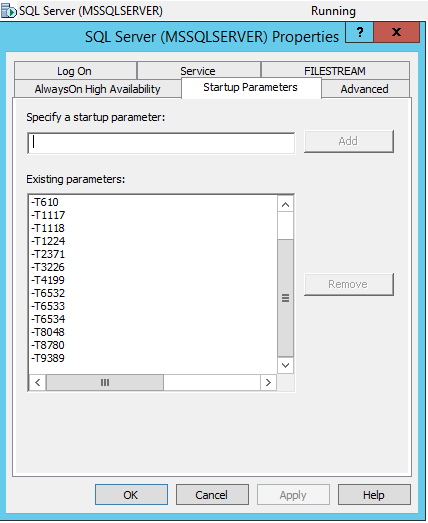
De minha própria experiência e da experiência de meus colegas, recomendo definir os seguintes sinalizadores de rastreamento no nível de inicialização do serviço MS SQL Server para as versões 2008-2016 para obter o desempenho ideal:
- 610 - Reduzindo o registro de inserções em tabelas indexadas. Pode ajudar com inserções em tabelas com um grande número de registros e muitas transações, com expectativas longas e freqüentes do WRITELOG para alterações nos índices
- 1117 - Se um arquivo em um grupo de arquivos atingir o limite de crescimento automático, todos os arquivos no grupo de arquivos serão expandidos
- 1118 - Força todos os objetos a serem localizados em extensões diferentes (proibição de extensões mistas), o que minimiza a necessidade de digitalizar a página SGAM, que é usada para rastrear extensões mistas
- 1224 - Desativa a escalação de bloqueios com base no número de bloqueios. O uso excessivo de memória pode incluir escalação de bloqueio.
- 2371 - Altera o limite de atualizações automáticas fixas de estatísticas para o limite de atualizações dinâmicas automáticas de estatísticas. É importante atualizar planos de consulta para tabelas grandes em que determinar incorretamente o número de registros leva a planos de execução incorretos
- 3226 - Suprime mensagens de backup bem-sucedidas no log de erros
- 4199 - Inclui alterações no otimizador de consulta lançadas nos service packs de atualização cumulativa e SQL Server
- 6532-6534 - Inclui desempenho aprimorado de consulta para tipos de dados espaciais
- 8048 - Converte objetos de memória particionados NUMA em particionados por CPU
- 8780 - Permite alocação de tempo adicional para agendar uma solicitação. Algumas solicitações sem esse sinalizador podem ser rejeitadas porque não possuem um plano de solicitações (erro muito raro)
- 9389 - Inclui um buffer de memória dinâmico adicional fornecido temporariamente para operadores em modo em lote, que permite que o operador em modo em lote solicite memória adicional e evite transferir dados para tempdb se houver memória adicional disponível
Antes da versão de 2016, é útil incluir o sinalizador de rastreamento 2301, que inclui a otimização do suporte estendido à decisão e, assim, ajuda na escolha de planos de consulta mais corretos. No entanto, a partir da versão 2016, costuma ter um efeito negativo em um tempo geral de execução da consulta bastante longo.
Além disso, para sistemas em que há muitos índices (por exemplo, para bancos de dados 1C), recomendo que você ative o sinalizador de rastreamento 2330, que desativa a coleta no uso de índices, o que geralmente afeta positivamente o sistema.
Saiba mais sobre sinalizadores de rastreamento
aqui .
Usando o link acima, também é importante considerar as versões e os assemblies do MS SQL Server, pois para versões mais recentes, alguns sinalizadores de rastreamento são ativados por padrão ou não têm efeito. Por exemplo, na versão 2017, é relevante definir apenas os 5 sinalizadores de rastreamento a seguir: 1224, 3226, 6534, 8780 e 9389.
Você pode ativar ou desativar o sinalizador de rastreamento usando os comandos DBCC TRACEON e DBCC TRACEOFF, respectivamente. Veja
aqui para mais detalhes.
Você pode obter o status de sinalizadores de rastreio usando o comando DBCC TRACESTATUS:
mais .
Para que os sinalizadores de rastreamento sejam incluídos na execução automática do serviço MS SQL Server, você precisa acessar o SQL Server Configuration Manager e adicionar esses sinalizadores de rastreamento nas propriedades do serviço via -T:
Sumário
Neste artigo, foram examinados alguns aspectos do monitoramento do MS SQL Server, com a ajuda da qual você pode identificar rapidamente a falta de RAM e tempo livre da CPU, além de vários outros problemas menos óbvios. Os sinalizadores de rastreamento mais usados foram considerados.
Fontes
»
Estatísticas de espera do SQL Server»
Estatísticas de expectativa do SQL Server ou por favor me diga onde dói»
Exibição do sistema sys.dm_os_schedulers»
Usando o Zabbix para rastrear o banco de dados do MS SQL Server»
Estilo de Vida SQL»
Sinalizadores de rastreamento»
Sql.ru