Olá pessoal

Não sei você, mas sempre quis reverter os jogos antigos de console, tendo também um descompilador em estoque. E agora, esse momento alegre da minha vida chegou - GHIDRA saiu. Não vou escrever sobre o que é, você pode facilmente pesquisar no Google. E as revisões são tão diferentes (especialmente as retrógradas) que será difícil para um novato decidir lançar esse milagre ... Aqui está um exemplo para você: " Eu trabalhei por idéias por 20 anos e olho sua Hydra com grande desconfiança, porque a NSA. Mas quando- Vou executá-lo e verificá-lo na prática ".
Em poucas palavras, rodar Hydra não é assustador. E o que obtemos após o lançamento bloqueará todo o seu medo de marcadores e backdoors da onipresente NSA.
Então, do que estou falando ... Existe um prefixo: Sony Playstation 1 ( PS1 , PSX , Curling iron ). Muitos jogos divertidos foram criados para ele, surgiram várias franquias que ainda são populares. E um dia eu queria descobrir como eles funcionam: quais formatos de dados existem, se a compactação de recursos é usada, tente traduzir algo para o russo (direi imediatamente que ainda não traduzi nenhum jogo).
Comecei escrevendo um utilitário interessante para trabalhar com o formato TIM com um amigo no Delphi (isso é algo como o BMP do mundo Playstation): Tim2View . Ao mesmo tempo, teve sucesso (e talvez agora tenha). Então eu queria aprofundar a compressão.
E então os problemas começaram. Eu não estava familiarizado com o MIPS época. Tomou a estudar. Também não conhecia o IDA Pro (vim para reverter jogos no Sega Mega Drive depois do Playstation ). Mas, graças à Internet, descobri que o IDA Pro suporta o download e a análise de arquivos executáveis PS1 : PS-X EXE . Tentei fazer upload de um arquivo do jogo (parece que eles eram Lemmings ) com um nome e extensão estranhos, como SLUS_123.45 em Ida, eu tenho SLUS_123.45 linhas de código assembler (felizmente, eu já tinha uma ideia do que era, graças aos drivers de exe do Windows em x86) e começou a entender.
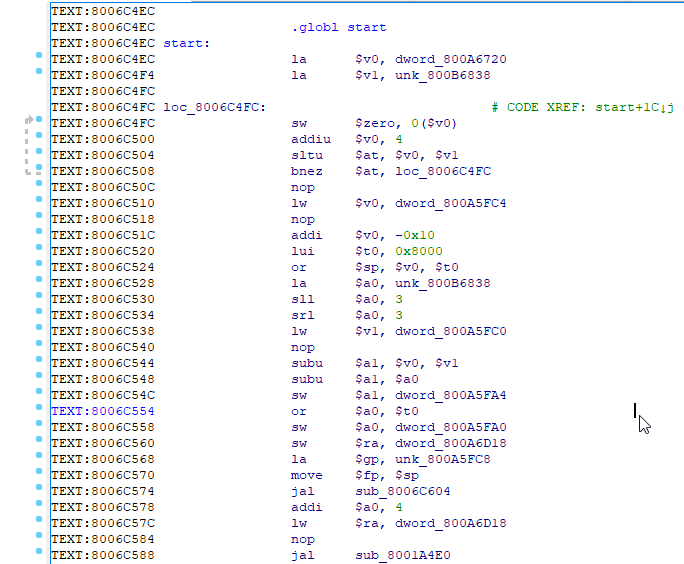
O primeiro lugar difícil de entender foi a linha de montagem. Por exemplo, você vê uma chamada para alguma função e, imediatamente após o carregamento no registro, o parâmetro que deve ser usado nessa função. Em resumo, antes de qualquer salto e chamada de função, a instrução após o salto / chamada é executada primeiro e somente então a chamada ou salto em si.
Depois de todas as dificuldades que passei, consegui escrever vários empacotadores / desempacotadores de recursos do jogo. Mas nunca estudei código de verdade. Porque Bem, tudo é comum: havia muito código, acesso ao BIOS e funções que eram praticamente impossíveis de entender (eram biblioteca, e eu não tinha um SDK para curling), instruções para trabalhar com três registradores ao mesmo tempo, falta de um descompilador.
E assim, depois de muitos e muitos anos, GHIDRA sai. Entre as plataformas suportadas pelo descompilador está o MIPS . Oh alegria! Vamos tentar descompilar algo em breve! Mas ... eu estava esperando por uma chatice. PS-X EXE não PS-X EXE suportados pelo Hydra. Não tem problema, escreva o seu!
Realmente código
Chega de digressão lírica, vamos escrever código. Como criar meus próprios downloaders para o Ghidra , eu já tinha uma ideia do que escrevi anteriormente . Portanto, resta apenas encontrar o Mapa de Memória do primeiro ferro de frisar, os endereços dos registradores e, você pode coletar e carregar binários. Mal disse o que fez.
O código estava pronto, registradores e regiões foram adicionados e reconhecidos, mas ainda havia um grande espaço em branco nos locais em que as funções de biblioteca e BIOS eram chamadas. E, infelizmente, a Hydra não teve o suporte da FLIRT . Caso contrário, vamos adicionar.
O formato das assinaturas do FLIRT é conhecido e descrito no arquivo pat.txt , que pode ser encontrado no Ida SDK. Ida também tem um utilitário para criar essas assinaturas especificamente a partir dos arquivos da biblioteca Playstation , e é chamado: ppsx . Eu baixei o SDK para o PsyQ Playstation Development Kit chamado PsyQ Playstation Development Kit , encontrei arquivos lib lá e tentei criar pelo menos algumas assinaturas deles - com êxito. Acontece um pequeno texto no qual cada linha tem um formato específico. Resta escrever o código que irá analisar essas linhas e aplicá-las ao código.
Patparser
Como cada linha tem um formato específico, seria lógico escrever uma expressão regular. Aconteceu assim:
private static final Pattern linePat = Pattern.compile("^((?:[0-9A-F\\.]{2})+) ([0-9A-F]{2}) ([0-9A-F]{4}) ([0-9A-F]{4}) ((?:[:\\^][0-9A-F]{4}@? [\\.\\w]+ )+)((?:[0-9A-F\\.]{2})+)?$");
Bem, para destacar na lista de módulos separadamente o deslocamento, o tipo e o nome da função, escrevemos um regexp separado:
private static final Pattern modulePat = Pattern.compile("([:\\^][0-9A-F]{4}@?) ([\\.\\w]+) ");
Agora vamos analisar os componentes de cada assinatura separadamente:
- Primeiro, vem a sequência hexadecimal de bytes ( 0-9A-F ), onde alguns deles podem ser qualquer um (caractere de ponto "."). Portanto, criamos uma classe que armazenará essa sequência. Eu chamei de
MaskedBytes :
MaskedBytes.java package pat; public class MaskedBytes { private final byte[] bytes, masks; public final byte[] getBytes() { return bytes; } public final byte[] getMasks() { return masks; } public final int getLength() { return bytes.length; } public MaskedBytes(byte[] bytes, byte[] masks) { this.bytes = bytes; this.masks = masks; } public static MaskedBytes extend(MaskedBytes src, MaskedBytes add) { return extend(src, add.getBytes(), add.getMasks()); } public static MaskedBytes extend(MaskedBytes src, byte[] addBytes, byte[] addMasks) { int length = src.getBytes().length; byte[] tmpBytes = new byte[length + addBytes.length]; byte[] tmpMasks = new byte[length + addMasks.length]; System.arraycopy(src.getBytes(), 0, tmpBytes, 0, length); System.arraycopy(addBytes, 0, tmpBytes, length, addBytes.length); System.arraycopy(src.getMasks(), 0, tmpMasks, 0, length); System.arraycopy(addMasks, 0, tmpMasks, length, addMasks.length); return new MaskedBytes(tmpBytes, tmpMasks); } }
- O comprimento do bloco a partir do qual o
CRC16 é calculado. CRC16 , que usa seu próprio polinômio ( 0x8408 ):
Código de contagem CRC16 public static boolean checkCrc16(byte[] bytes, short resCrc) { if ( bytes.length == 0 ) return true; int crc = 0xFFFF; for (int i = 0; i < bytes.length; ++i) { int a = bytes[i]; for (int x = 0; x < 8; ++x) { if (((crc ^ a) & 1) != 0) { crc = (crc >> 1) ^ 0x8408; } else { crc >>= 1; } a >>= 1; } } crc = ~crc; int x = crc; crc = (crc << 8) | ((x >> 8) & 0xFF); crc &= 0xFFFF; return (short)crc == resCrc; }
- O comprimento total do "módulo" em bytes.
- Lista de nomes globais (o que precisamos).
- Lista de links para outros nomes (também necessário).
- Bytes finais.
Cada nome no módulo possui um tipo específico e deslocamento em relação ao início. Um tipo pode ser indicado por um dos caracteres ::, ^, @, dependendo do tipo:
- " : NAME ": nome global. Foi por causa de tais nomes que eu comecei tudo;
- " : NAME @ ": nome / etiqueta local. Pode não ser indicado, mas deixe estar;
- " ^ NAME ": link para o nome.
Por um lado, tudo é simples, mas um link pode facilmente não ser uma referência a uma função (e, consequentemente, o salto será relativo), mas a uma variável global. Qual é o seu problema? E é que no PSX você não pode inserir um DWORD inteiro no registro com uma instrução. Para fazer isso, faça o download na forma de metades. O fato é que, no MIPS o tamanho da instrução é limitado a quatro bytes. E, ao que parece, você só precisa primeiro extrair metade de uma instrução e depois desmontar a próxima - e obter a segunda metade. Mas não é tão simples. A primeira metade pode ser carregada com as instruções 5 de volta e o link no módulo será fornecido somente após o carregamento da segunda metade. Eu tive que escrever um analisador sofisticado (provavelmente pode ser modificado).
Como resultado, criamos enum para três tipos de nomes:
ModuleType.java package pat; public enum ModuleType { GLOBAL_NAME, LOCAL_NAME, REF_NAME; public boolean isGlobal() { return this == GLOBAL_NAME; } public boolean isLocal() { return this == LOCAL_NAME; } public boolean isReference() { return this == REF_NAME; } @Override public String toString() { if (isGlobal()) { return "Global"; } else if (isLocal()) { return "Local"; } else { return "Reference"; } } }
Vamos escrever um código que converta seqüências e pontos hexadecimais de texto no tipo MaskedBytes :
hexStringToMaskedBytesArray () private MaskedBytes hexStringToMaskedBytesArray(String s) { MaskedBytes res = null; if (s != null) { int len = s.length(); byte[] bytes = new byte[len / 2]; byte[] masks = new byte[len / 2]; for (int i = 0; i < len; i += 2) { char c1 = s.charAt(i); char c2 = s.charAt(i + 1); masks[i / 2] = (byte) ( (((c1 == '.') ? 0x0 : 0xF) << 4) | (((c2 == '.') ? 0x0 : 0xF) << 0) ); bytes[i / 2] = (byte) ( (((c1 == '.') ? 0x0 : Character.digit(c1, 16)) << 4) | (((c2 == '.') ? 0x0 : Character.digit(c2, 16)) << 0) ); } res = new MaskedBytes(bytes, masks); } return res; }
Você já pode pensar em uma classe que armazenará informações sobre cada função individual: o nome da função, o deslocamento no módulo e o tipo:
ModuleData.java package pat; public class ModuleData { private final long offset; private final String name; private final ModuleType type; public ModuleData(long offset, String name, ModuleType type) { this.offset = offset; this.name = name; this.type = type; } public final long getOffset() { return offset; } public final String getName() { return name; } public final ModuleType getType() { return type; } }
E, finalmente: uma classe que armazenará tudo o que é indicado em cada linha do arquivo pat , ou seja: bytes, crc, uma lista de nomes com deslocamentos:
SignatureData.java package pat; import java.util.Arrays; import java.util.List; public class SignatureData { private final MaskedBytes templateBytes, tailBytes; private MaskedBytes fullBytes; private final int crc16Length; private final short crc16; private final int moduleLength; private final List<ModuleData> modules; public SignatureData(MaskedBytes templateBytes, int crc16Length, short crc16, int moduleLength, List<ModuleData> modules, MaskedBytes tailBytes) { this.templateBytes = this.fullBytes = templateBytes; this.crc16Length = crc16Length; this.crc16 = crc16; this.moduleLength = moduleLength; this.modules = modules; this.tailBytes = tailBytes; if (this.tailBytes != null) { int addLength = moduleLength - templateBytes.getLength() - tailBytes.getLength(); byte[] addBytes = new byte[addLength]; byte[] addMasks = new byte[addLength]; Arrays.fill(addBytes, (byte)0x00); Arrays.fill(addMasks, (byte)0x00); this.fullBytes = MaskedBytes.extend(this.templateBytes, addBytes, addMasks); this.fullBytes = MaskedBytes.extend(this.fullBytes, tailBytes); } } public MaskedBytes getTemplateBytes() { return templateBytes; } public MaskedBytes getTailBytes() { return tailBytes; } public MaskedBytes getFullBytes() { return fullBytes; } public int getCrc16Length() { return crc16Length; } public short getCrc16() { return crc16; } public int getModuleLength() { return moduleLength; } public List<ModuleData> getModules() { return modules; } }
Agora, o principal: escrevemos código para criar todas essas classes:
Analisando uma linha obtida de um arquivo pat private List<ModuleData> parseModuleData(String s) { List<ModuleData> res = new ArrayList<ModuleData>(); if (s != null) { Matcher m = modulePat.matcher(s); while (m.find()) { String __offset = m.group(1); ModuleType type = __offset.startsWith(":") ? ModuleType.GLOBAL_NAME : ModuleType.REF_NAME; type = (type == ModuleType.GLOBAL_NAME && __offset.endsWith("@")) ? ModuleType.LOCAL_NAME : type; String _offset = __offset.replaceAll("[:^@]", ""); long offset = Integer.parseInt(_offset, 16); String name = m.group(2); res.add(new ModuleData(offset, name, type)); } } return res; }
Analisando todas as linhas do arquivo pat private void parse(List<String> lines) { modulesCount = 0L; signatures = new ArrayList<SignatureData>(); int linesCount = lines.size(); monitor.initialize(linesCount); monitor.setMessage("Reading signatures..."); for (int i = 0; i < linesCount; ++i) { String line = lines.get(i); Matcher m = linePat.matcher(line); if (m.matches()) { MaskedBytes pp = hexStringToMaskedBytesArray(m.group(1)); int ll = Integer.parseInt(m.group(2), 16); short ssss = (short)Integer.parseInt(m.group(3), 16); int llll = Integer.parseInt(m.group(4), 16); List<ModuleData> modules = parseModuleData(m.group(5)); MaskedBytes tail = null; if (m.group(6) != null) { tail = hexStringToMaskedBytesArray(m.group(6)); } signatures.add(new SignatureData(pp, ll, ssss, llll, modules, tail)); modulesCount += modules.size(); } monitor.incrementProgress(1); } }
O código para criar a função em que uma das assinaturas foi reconhecida:
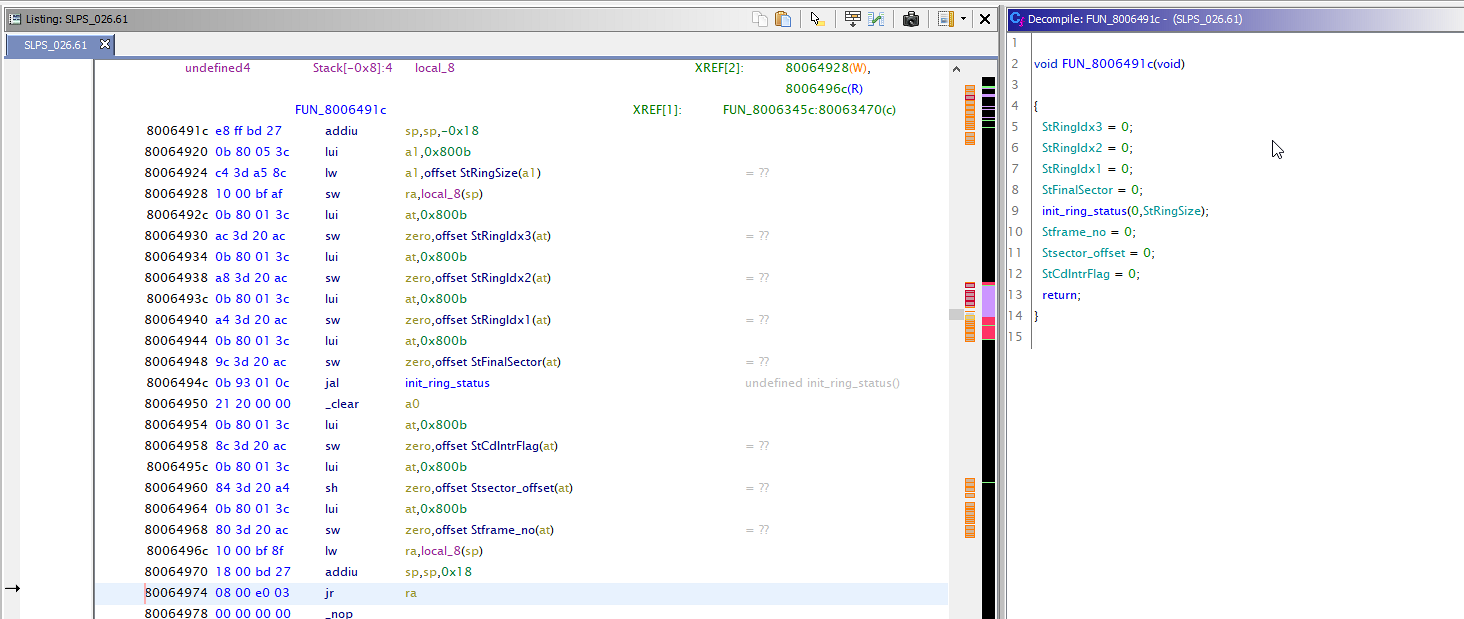
Criação de Função private static void disasmInstruction(Program program, Address address) { DisassembleCommand cmd = new DisassembleCommand(address, null, true); cmd.applyTo(program, TaskMonitor.DUMMY); } public static void setFunction(Program program, FlatProgramAPI fpa, Address address, String name, boolean isFunction, boolean isEntryPoint, MessageLog log) { try { if (fpa.getInstructionAt(address) == null) disasmInstruction(program, address); if (isFunction) { fpa.createFunction(address, name); } if (isEntryPoint) { fpa.addEntryPoint(address); } if (isFunction && program.getSymbolTable().hasSymbol(address)) { return; } program.getSymbolTable().createLabel(address, name, SourceType.IMPORTED); } catch (InvalidInputException e) { log.appendException(e); } }
O lugar mais difícil, como mencionado anteriormente, é contar um link para outro nome / variável (talvez o código precise ser aprimorado):
Contagem de Links public static void setInstrRefName(Program program, FlatProgramAPI fpa, PseudoDisassembler ps, Address address, String name, MessageLog log) { ReferenceManager refsMgr = program.getReferenceManager(); Reference[] refs = refsMgr.getReferencesFrom(address); if (refs.length == 0) { disasmInstruction(program, address); refs = refsMgr.getReferencesFrom(address); if (refs.length == 0) { refs = refsMgr.getReferencesFrom(address.add(4)); if (refs.length == 0) { refs = refsMgr.getFlowReferencesFrom(address.add(4)); Instruction instr = program.getListing().getInstructionAt(address.add(4)); if (instr == null) { disasmInstruction(program, address.add(4)); instr = program.getListing().getInstructionAt(address.add(4)); if (instr == null) { return; } } FlowType flowType = instr.getFlowType(); if (refs.length == 0 && !(flowType.isJump() || flowType.isCall() || flowType.isTerminal())) { return; } refs = refsMgr.getReferencesFrom(address.add(8)); if (refs.length == 0) { return; } } } } try { program.getSymbolTable().createLabel(refs[0].getToAddress(), name, SourceType.IMPORTED); } catch (InvalidInputException e) { log.appendException(e); } }
E, o toque final - aplique as assinaturas:
applySignatures () public void applySignatures(ByteProvider provider, Program program, Address imageBase, Address startAddr, Address endAddr, MessageLog log) throws IOException { BinaryReader reader = new BinaryReader(provider, false); PseudoDisassembler ps = new PseudoDisassembler(program); FlatProgramAPI fpa = new FlatProgramAPI(program); monitor.initialize(getAllModulesCount()); monitor.setMessage("Applying signatures..."); for (SignatureData sig : signatures) { MaskedBytes fullBytes = sig.getFullBytes(); MaskedBytes tmpl = sig.getTemplateBytes(); Address addr = program.getMemory().findBytes(startAddr, endAddr, fullBytes.getBytes(), fullBytes.getMasks(), true, TaskMonitor.DUMMY); if (addr == null) { monitor.incrementProgress(sig.getModules().size()); continue; } addr = addr.subtract(imageBase.getOffset()); byte[] nextBytes = reader.readByteArray(addr.getOffset() + tmpl.getLength(), sig.getCrc16Length()); if (!PatParser.checkCrc16(nextBytes, sig.getCrc16())) { monitor.incrementProgress(sig.getModules().size()); continue; } addr = addr.add(imageBase.getOffset()); List<ModuleData> modules = sig.getModules(); for (ModuleData data : modules) { Address _addr = addr.add(data.getOffset()); if (data.getType().isGlobal()) { setFunction(program, fpa, _addr, data.getName(), data.getType().isGlobal(), false, log); } monitor.setMessage(String.format("%s function %s at 0x%08X", data.getType(), data.getName(), _addr.getOffset())); monitor.incrementProgress(1); } for (ModuleData data : modules) { Address _addr = addr.add(data.getOffset()); if (data.getType().isReference()) { setInstrRefName(program, fpa, ps, _addr, data.getName(), log); } monitor.setMessage(String.format("%s function %s at 0x%08X", data.getType(), data.getName(), _addr.getOffset())); monitor.incrementProgress(1); } } }
Aqui você pode falar sobre uma função interessante: findBytes() . Com ele, é possível procurar sequências específicas de bytes, com as máscaras de bits especificadas para cada byte. O método é chamado assim:
Address addr = program.getMemory().findBytes(startAddr, endAddr, bytes, masks, forward, TaskMonitor.DUMMY);
Como resultado, o endereço do qual os bytes começam é retornado ou null .
Escrevendo um analisador
Vamos fazer isso lindamente, e não usaremos assinaturas se não quisermos, mas deixe o usuário escolher esta etapa. Para fazer isso, você precisará escrever seu próprio analisador de código (você pode ver os desta lista - é tudo o que são, sim):
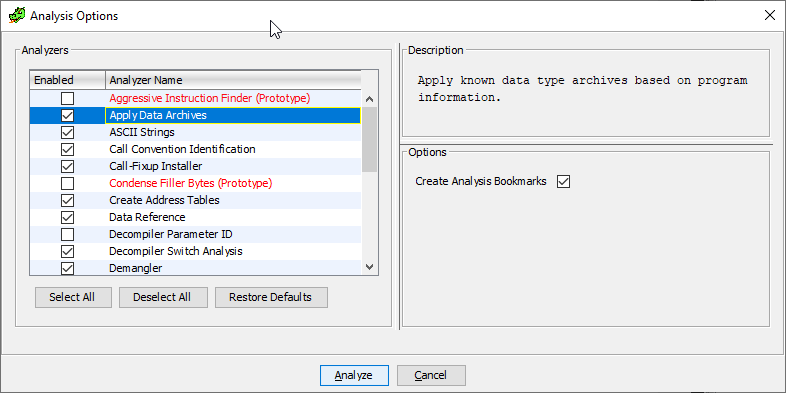
Portanto, para entrar nessa lista, você precisará herdar da classe AbstractAnalyzer e substituir alguns métodos:
- Construtor. Ele precisará chamar o construtor da classe base com o nome, a descrição do analisador e seu tipo (mais sobre isso mais adiante). Parece algo assim para mim:
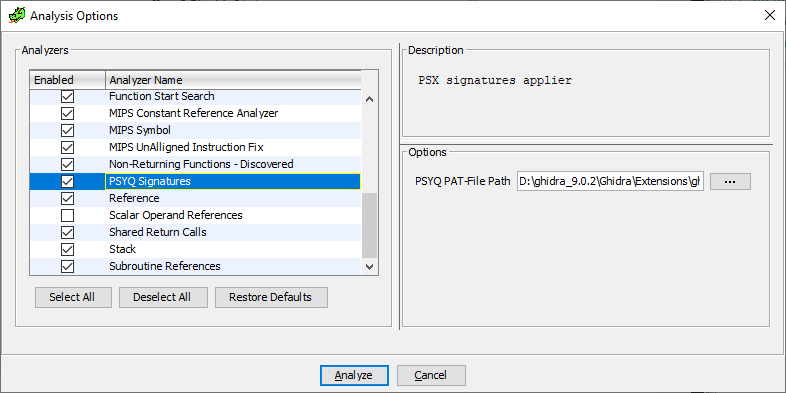
public PsxAnalyzer() { super("PSYQ Signatures", "PSX signatures applier", AnalyzerType.INSTRUCTION_ANALYZER); }
getDefaultEnablement() . Determina se nosso analisador está sempre disponível ou apenas se determinadas condições forem atendidas (por exemplo, se nosso carregador for usado).canAnalyze() . É possível usar esse analisador em um arquivo binário para download?
Os parágrafos 2 e 3 podem, em princípio, ser verificados por uma única função:
public static boolean isPsxLoader(Program program) { return program.getExecutableFormat().equalsIgnoreCase(PsxLoader.PSX_LOADER); }
Onde PsxLoader.PSX_LOADER armazena o nome do carregador de inicialização e é definido anteriormente.
Total, temos:
@Override public boolean getDefaultEnablement(Program program) { return isPsxLoader(program); } @Override public boolean canAnalyze(Program program) { return isPsxLoader(program); }
registerOptions() . Não é necessário redefinir esse método, mas se precisarmos perguntar algo ao usuário, por exemplo, o caminho para o arquivo pat antes da análise, é melhor fazer isso neste método. Temos:
private static final String OPTION_NAME = "PSYQ PAT-File Path"; private File file = null; @Override public void registerOptions(Options options, Program program) { try { file = Application.getModuleDataFile("psyq4_7.pat").getFile(false); } catch (FileNotFoundException e) { } options.registerOption(OPTION_NAME, OptionType.FILE_TYPE, file, null, "PAT-File (FLAIR) created from PSYQ library files"); }
Aqui é necessário esclarecer. O método estático getModuleDataFile() da classe Application retorna o caminho completo para o arquivo no diretório de data , que fica na árvore do nosso módulo, e pode armazenar os arquivos necessários aos quais queremos nos referir posteriormente.
Bem, o método registerOption() uma opção com o nome especificado em OPTION_NAME , o tipo File (ou seja, o usuário poderá selecionar o arquivo através de uma caixa de diálogo regular), o valor padrão e a descrição.
Próximo. Porque não teremos uma oportunidade normal de consultar a opção registrada posteriormente; precisaremos redefinir o método optionsChanged() :
@Override public void optionsChanged(Options options, Program program) { super.optionsChanged(options, program); file = options.getFile(OPTION_NAME, file); }
Aqui, simplesmente atualizamos a variável global de acordo com o novo valor.
O método added() . Agora, o principal: o método que será chamado quando o analisador iniciar. Nele, receberemos uma lista de endereços disponíveis para análise, mas precisamos apenas daqueles que contêm código. Portanto, você precisa filtrar. Código final:
Método Added () @Override public boolean added(Program program, AddressSetView set, TaskMonitor monitor, MessageLog log) throws CancelledException { if (file == null) { return true; } Memory memory = program.getMemory(); AddressRangeIterator it = memory.getLoadedAndInitializedAddressSet().getAddressRanges(); while (!monitor.isCancelled() && it.hasNext()) { AddressRange range = it.next(); try { MemoryBlock block = program.getMemory().getBlock(range.getMinAddress()); if (block.isInitialized() && block.isExecute() && block.isLoaded()) { PatParser pat = new PatParser(file, monitor); RandomAccessByteProvider provider = new RandomAccessByteProvider(new File(program.getExecutablePath())); pat.applySignatures(provider, program, block.getStart(), block.getStart(), block.getEnd(), log); } } catch (IOException e) { log.appendException(e); return false; } } return true; }
Aqui, examinamos a lista de endereços que são executáveis e tentamos aplicar assinaturas lá.
Conclusões e final
Como tudo. De fato, não há nada super complicado aqui. Existem exemplos, a comunidade é animada, você pode perguntar com segurança sobre o que não está claro ao escrever o código. Conclusão: um carregador de inicialização e analisador de trabalho para arquivos executáveis do Playstation 1 .
Todos os códigos-fonte estão disponíveis aqui: ghidra_psx_ldr
Lançamentos aqui: Lançamentos