
Em 1 de abril, terminou a final do SNA Hackathon 2019 , cujos participantes competiram na classificação do feed da rede social usando modernas tecnologias de aprendizado de máquina, visão computacional, processamento de testes e sistemas de recomendação. Seleção on-line difícil e dois dias de trabalho duro em 160 gigabytes de dados não foram em vão :). Falamos sobre o que ajudou os participantes a obter sucesso e sobre outras observações interessantes.
Sobre dados e tarefa
A competição apresentou dados dos mecanismos de preparação do feed para os usuários da rede social OK , que consiste em três partes:
- a exibição de conteúdo registra nos feeds do usuário com um grande número de atributos que descrevem o usuário, o conteúdo, o autor e outras propriedades;
- textos relacionados ao conteúdo exibido;
- corpos de imagens utilizados no conteúdo.
A quantidade total de dados excede 160 gigabytes, dos quais mais de 3 são responsáveis por logs, mais 3 por textos e o restante por imagens. A grande quantidade de dados não assustou os participantes: de acordo com as estatísticas do ML Bootcamp , quase 200 pessoas participaram da competição, que enviou mais de 3.000 inscrições, e as mais ativas conseguiram quebrar a fasquia das 100 soluções enviadas. Talvez eles tenham sido motivados pelo prêmio total de 700.000 rublos + 3 placas gráficas GTX 2080 Ti.

Os participantes da competição precisavam resolver o problema de classificar a fita: para cada usuário individual, classifique os objetos exibidos de forma que aqueles que obtiveram a marca "Classe!" Fiquem mais próximos do início da lista.
ROC-AUC foi usado como uma métrica de avaliação da qualidade. Ao mesmo tempo, a métrica não foi considerada para todos os dados como um todo, mas separadamente para cada usuário e, em seguida, calculada a média. Essa opção de cálculo é digna de nota, pois os algoritmos que aprenderam a distinguir usuários que colocam muitas classes não recebem vantagens. Por outro lado, não existe essa opção nos pacotes Python padrão, que revelaram alguns pontos interessantes, que são discutidos abaixo.
Sobre a tecnologia
Tradicionalmente, o SNA Hackathon não é apenas algoritmos, mas também tecnologias - o volume de dados enviados excede 160 gigabytes, o que coloca os participantes na frente de tarefas técnicas interessantes.
Parquet vs. CSV
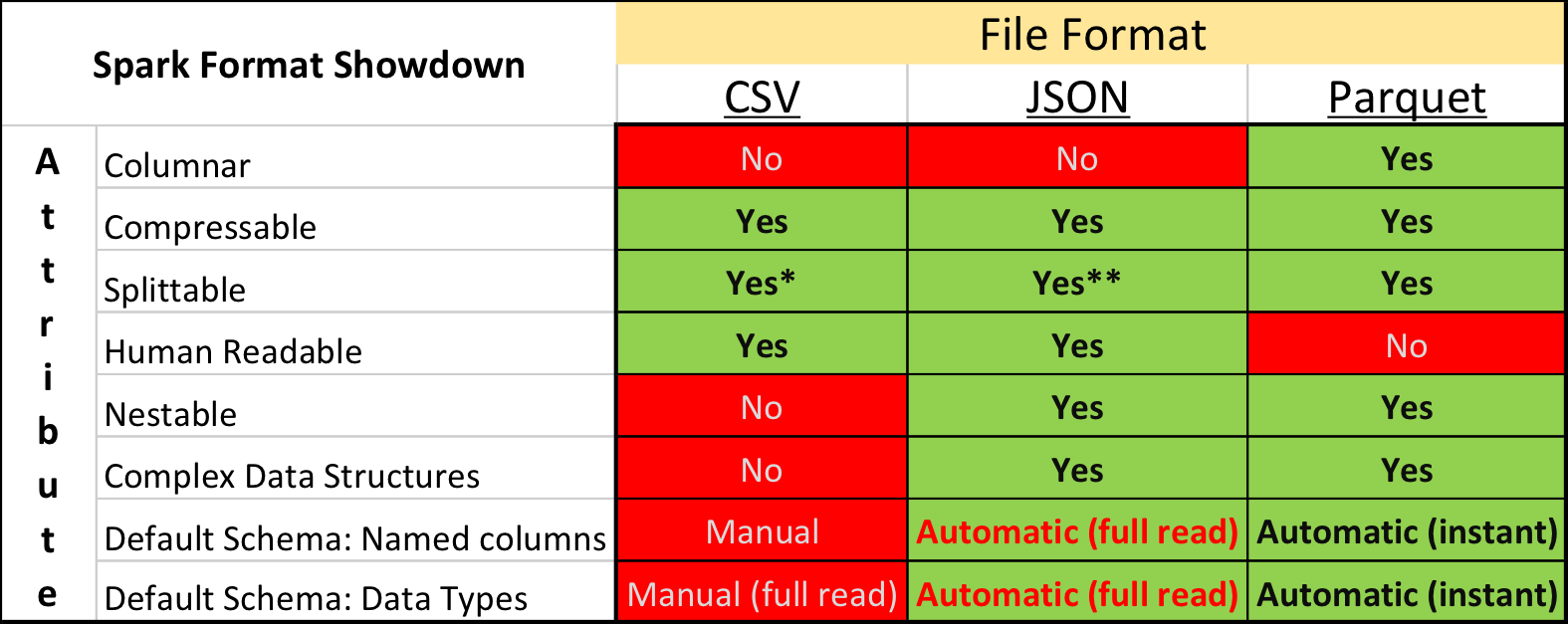
Na pesquisa acadêmica e no Kaggle, o formato de dados dominante é o CSV , assim como outros formatos de texto sem formatação. No entanto, a situação na indústria é um pouco diferente - velocidades significativamente mais compactas e de processamento podem ser obtidas usando formatos de armazenamento "binários".
Em particular, no ecossistema construído com base no Apache Spark , o Apache Parquet é o mais popular - um formato de armazenamento de dados em coluna com suporte para muitos recursos operacionais importantes:
- um circuito explicitamente especificado com suporte à evolução;
- lendo apenas as colunas necessárias do disco;
- suporte básico para índices e filtros ao ler;
- compressão de string.
Mas, apesar das vantagens óbvias, o envio de dados para a competição no formato Apache Parquet recebeu críticas severas de alguns participantes. Além do conservadorismo e da falta de vontade de gastar tempo desenvolvendo algo novo, houve vários momentos realmente desagradáveis.
Primeiro, o suporte ao formato na biblioteca Apache Arrow , a principal ferramenta para trabalhar com o Parquet do Python, está longe de ser perfeito. Ao preparar os dados, todos os campos estruturais tiveram que ser expandidos para o plano e, ainda assim, ao ler textos, muitos participantes encontraram um erro e foram forçados a instalar a biblioteca da versão 0.11.1 antiga em vez da versão 0.12 atual. Em segundo lugar, você não verá o arquivo Parquet usando simples utilitários de console: cat, less, etc. No entanto, essa desvantagem é relativamente fácil de compensar o uso do pacote de ferramentas para parquet .
No entanto, aqueles que inicialmente tentaram converter todos os dados em CSV, depois trabalhar no ambiente familiar, finalmente abandonaram essa idéia - afinal, o Parquet funciona significativamente mais rápido.
Boosting e GPU

Na conferência SmartData em São Petersburgo, “amplamente conhecida em círculos estreitos”, Alexey Natekin comparou o desempenho de várias ferramentas populares de reforço enquanto trabalhava na CPU / GPU e chegou à conclusão de que a GPU não oferece um ganho tangível. Mas, mesmo assim, essa conclusão levou a uma polêmica ativa, principalmente com os desenvolvedores da ferramenta CatBoost doméstica.
Nos últimos dois anos, o progresso no desenvolvimento de GPUs e a adaptação de algoritmos não parou e a final do SNA Hackathon pode ser considerada um triunfo do par CatBoost + GPU - todos os vencedores o usaram e puxaram a métrica principalmente devido à capacidade de cultivar mais árvores por unidade de tempo.
A implementação integrada da codificação de destino médio também contribuiu para o alto resultado de soluções baseadas no CatBoost, mas o número e a profundidade das árvores deram um aumento mais significativo.
Outras ferramentas de impulso estão se movendo em uma direção semelhante, adicionando e melhorando o suporte à GPU. Então cresça mais árvores!
Spark vs. Pyspark

A ferramenta Apache Spark é uma forte líder em Data Science industrial, graças em parte à API Python. No entanto, o uso do Python vem com sobrecarga adicional para integração entre diferentes tempos de execução e trabalho do interpretador.
Isso por si só não é um problema se o usuário estiver ciente da extensão em que a quantidade de custos adicionais leva a uma ação específica. Entretanto, muitos não percebem a magnitude do problema - apesar de os participantes não usarem o Apache Spark, discussões sobre Python vs. Scala apareceu regularmente no chat do hackathon, o que levou ao aparecimento do correspondente post analisado .
Em resumo, a desaceleração do uso do Spark através do Python em comparação ao uso do Spark via Scala / Java pode ser dividida nos seguintes níveis:
- somente a API Spark SQL é usada sem UDF (User Defined Functions) - nesse caso, praticamente não há sobrecarga, pois todo o plano de execução da consulta é calculado na estrutura da JVM;
- O UDF é usado no Python sem chamar pacotes com código C ++ - nesse caso, o desempenho do estágio em que o UDF é calculado cai de 7 a 10 vezes ;
- O UDF é usado no Python com acesso ao pacote C ++ (numpy, sklearn etc.) - nesse caso, o desempenho cai de 10 a 50 vezes .
Em parte, o efeito negativo pode ser compensado pelo uso de PyDp (JIT para Python) e UDFs vetorizados ; no entanto, nesses casos, a diferença de desempenho é múltipla e a complexidade da implementação e implantação vem com um "bônus" adicional.
Sobre Algoritmos
Mas a coisa mais interessante sobre os hackathons da Data Science não é, obviamente, as tecnologias, mas os novos algoritmos da moda e antigos. O CatBoost dominou o SNA Hackathon este ano, mas havia várias abordagens alternativas. Vamos falar sobre eles :).
Gráficos diferenciáveis

Uma das primeiras publicações de decisões baseadas nos resultados da rodada de qualificação foi dedicada não a árvores, mas a gráficos diferenciáveis (também chamados de redes neurais artificiais). O autor é um funcionário da OK, então ele não pode se dar ao luxo de buscar prêmios, mas gosta de construir uma solução promissora com base em uma base matemática sólida.
A principal idéia da solução proposta foi criar um único gráfico diferenciável computacional que traduza os recursos disponíveis em uma previsão que leve em consideração vários aspectos dos dados de entrada:
- as uniões de objeto e usuário permitem adicionar um elemento de recomendações clássicas de colaboração;
- a transição da incorporação escalar para a agregação por meio do MLP permite adicionar características arbitrárias;
- a atenção ao valor da chave de consulta permitiu que o modelo se adaptasse dinamicamente ao comportamento de até mesmo um usuário anteriormente desconhecido, olhando para seu histórico recente.
Esse modelo provou ser muito bom na seleção on-line para resolver o problema de recomendar conteúdo de texto; portanto, várias equipes tentaram jogá-lo na final de uma só vez; no entanto, não tiveram sucesso. Isso se deve em parte ao fato de que isso requer tempo e experiência, e em parte ao fato de que o número de atributos na final era muito maior e os métodos baseados em árvores receberam uma vantagem significativa devido a eles.
Dominante colaborativo

Obviamente, ao organizar o concurso, sabíamos que havia um sinal bastante forte nos logs, porque os sinais coletados refletiam uma parte significativa do trabalho realizado em OK para classificar o feed. No entanto, até o fim, eles esperavam que os participantes conseguissem lidar com a “maldição do terceiro personagem” - situações em que enormes recursos humanos e de máquinas investiam no desenvolvimento de um modelo para extrair atributos do conteúdo (textos e fotos) resultando em ganhos extremamente modestos em qualidade em comparação aos já traços preparados, principalmente colaborativos.
Conhecendo esse problema, inicialmente dividimos a tarefa em três faixas na fase de qualificação e formamos um conjunto de dados combinado apenas na final, mas no formato hackathon com uma métrica fixa, as equipes que investiram no desenvolvimento de modelos de conteúdo se viram em uma situação de perda deliberada em comparação com as equipes que desenvolvem colaboração. parte.
O prêmio do júri ajudou a compensar essa injustiça ...
Cluster profundo

Que foi quase unanimemente premiado pelo trabalho de reprodução e teste do algoritmo Deep Cluster no facebook. O método de marcação inicial simples e não obrigatório para a criação de clusters e incorporação de imagens impressionou com idéias de novidades e resultados promissores.
A essência do método é extremamente simples:
- calcular vetores de incorporação de imagens com qualquer rede neural significativa;
- agrupar os vetores no espaço resultante com médias k;
- treinar um classificador de rede neural para prever um conjunto de imagens;
- repita as etapas 2-3 até a convergência (se você tiver 800 GPUs) ou enquanto houver tempo suficiente.
Com um mínimo de esforços, conseguimos obter um agrupamento de imagens OK de alta qualidade, boas incorporações e um aumento métrico no terceiro dígito.
Olhe para o futuro

Em qualquer dado, você pode encontrar "brechas" para melhorar a previsão. Por si só, isso não é tão ruim, é muito pior se as brechas forem encontradas e, por um longo tempo, aparecerem apenas na forma de discrepâncias incompreensíveis entre os resultados da validação em dados históricos e testes A / B.
Uma das brechas mais comuns desse tipo é o uso de informações do futuro. Essa informação geralmente é um sinal muito forte e o algoritmo de aprendizado de máquina, se ativado, começará a usá-lo com confiança. Quando você cria um modelo para o seu produto, está tentando de todas as maneiras possíveis evitar o vazamento de informações no futuro, mas no hackathon essa é uma boa chance de aumentar a métrica usada pelos participantes.
A brecha mais óbvia foi a presença de numLikes e numDislikes nesses campos, com contagens de reação no objeto no momento do show. Ao comparar os dois eventos mais próximos no tempo relacionados ao mesmo objeto, foi possível determinar com alta precisão qual foi a reação ao objeto no primeiro deles. Havia vários contadores semelhantes nos dados e seu uso deu uma vantagem notável. Naturalmente, no uso real, essas informações não estarão disponíveis.
Na vida, um problema semelhante pode ser encontrado sem perceber, geralmente com resultados negativos. Por exemplo, contando estatísticas sobre o número de marcas "Classe!" para o objeto de acordo com todos os dados e tomando-o como um atributo separado. Ou, como fizeram em uma das equipes participantes, adicionando um identificador de objeto ao modelo como um atributo categórico. Em um conjunto de treinamento, um modelo com esse recurso funciona bem, mas não pode generalizar para um conjunto de testes.
Em vez de uma conclusão

Todos os materiais do concurso, incluindo dados e apresentações de decisões dos participantes, estão disponíveis no Mail.ru Cloud . Os dados estão disponíveis para uso em projetos de pesquisa sem restrições, exceto pela disponibilidade de links. Para a história, vamos deixar a mesa final aqui com as métricas das equipes finais:
- Crouching Scala, ocultando Python - 0.7422, analisando a solução está disponível aqui , e o código está aqui e aqui .
- Cidade Mágica - 0,7256
- Kefir - 0.7226
- Equipe 6 - 0,7205
- Três em um barco - 0,7188
- Sala 14 - 0,7167 e prêmio do júri
- BezSNA - 0.7147
- PONGA - 0.7117
- Equipe 5 - 0,7112
O SNA Hackathon 2019, como os eventos anteriores da série, foi um sucesso em todos os sentidos. Conseguimos reunir profissionais legais em diferentes campos sob o mesmo teto e passamos um tempo frutífero, pelo qual muito agradecemos aos próprios participantes e a todos aqueles que ajudaram na organização.
Algo poderia ter sido feito ainda melhor? Claro que sim! Cada competição realizada nos enriquece com uma nova experiência, que levamos em consideração na preparação da próxima e não vamos parar por aí. Então, até breve no SNA Hackathon!