O progresso no campo das redes neurais em geral e o reconhecimento de padrões em particular levou ao fato de que pode parecer que criar um aplicativo de rede neural para trabalhar com imagens seja uma tarefa rotineira. De certa forma, é - se você teve uma idéia relacionada ao reconhecimento de padrões, não duvide que alguém já tenha escrito algo assim. Tudo o que você precisa é encontrar o trecho de código correspondente no Google e "compilá-lo" do autor.
No entanto, ainda existem inúmeros detalhes que tornam a tarefa não tão insolúvel quanto ... chata, eu diria. Leva muito tempo, especialmente se você é iniciante e precisa de liderança, passo a passo, um projeto realizado diante de seus olhos e concluído do início ao fim. Sem o habitual nesses casos, “pule esta parte óbvia” desculpas.
Neste artigo, consideraremos a tarefa de criar um identificador de raças de cães: criaremos e treinaremos uma rede neural, depois a portaremos para Java para Android e a publicaremos no Google Play.
Se você quiser ver o resultado final, aqui está:
NeuroDog App no Google Play.
Site com minha robótica (em andamento):
robotics.snowcron.com .
Site com o próprio programa, incluindo um guia:
Guia do usuário do NeuroDog .
E aqui está uma captura de tela do programa:
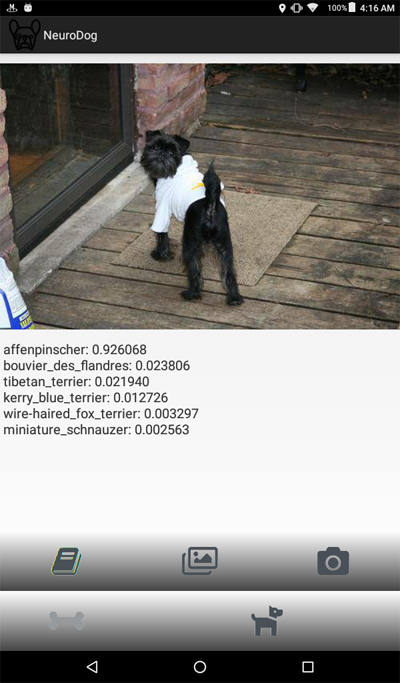
Declaração do problema
Usaremos Keras: uma biblioteca do Google para trabalhar com redes neurais. Esta é uma biblioteca de alto nível, o que significa que é mais fácil de usar em comparação com as alternativas que eu conheço. Se alguma coisa - existem muitos livros sobre Keras na rede, de alta qualidade.
Usaremos a CNN - Redes Neurais Convolucionais. A CNN (e configurações mais avançadas baseadas nelas) são o padrão de fato no reconhecimento de imagens. Ao mesmo tempo, o treinamento de uma rede nem sempre é fácil: você precisa escolher a estrutura de rede correta, os parâmetros de treinamento (todas essas taxas de aprendizado, momento, L1 e L2, etc.). A tarefa requer recursos computacionais significativos e, portanto, resolvê-la simplesmente passando por TODOS os parâmetros falhará.
Essa é uma das várias razões pelas quais, na maioria dos casos, eles usam o chamado "conhecimento de transferência", em vez da abordagem chamada "baunilha". O Transfer Knowlege usa uma rede neural treinada por alguém antes de nós (por exemplo, Google) e geralmente para uma tarefa semelhante, mas ainda diferente. Pegamos as camadas iniciais, substituímos as camadas finais por nosso próprio classificador - e funciona, e funciona muito bem.
A princípio, esse resultado pode ser surpreendente: como é que adotamos uma rede do Google treinada para distinguir gatos de cadeiras e reconhece as raças de cães para nós? Para entender como isso acontece, você precisa entender os princípios básicos do trabalho das Redes Neurais Profundas, incluindo os usados para o reconhecimento de padrões.
Nós “alimentamos” a rede com uma imagem (uma matriz de números, isto é) como entrada. A primeira camada analisa a imagem em busca de padrões simples, como "linha horizontal", "arco" etc. A próxima camada recebe esses padrões como entrada e produz padrões de segunda ordem, como "pêlo", "canto do olho" ... Por fim, obtemos um quebra-cabeça do qual podemos reconstruir o cão: lã, dois olhos e uma mão humana nos dentes.
Tudo isso foi feito com a ajuda de camadas pré-treinadas obtidas por nós (por exemplo, do Google). Em seguida, adicionamos nossas camadas e as ensinamos a extrair informações sobre raças desses padrões. Parece lógico.
Para resumir, neste artigo, criaremos a CNN "vanilla" e várias variantes de "transfer learning" de diferentes tipos de redes. Quanto ao "baunilha": eu o crio, mas não pretendo configurá-lo selecionando parâmetros, pois é muito mais fácil treinar e configurar redes "pré-treinadas".
Como planejamos ensinar nossa rede neural a reconhecer raças de cães, devemos "mostrar" amostras de várias raças. Felizmente, há um conjunto de fotografias criadas
aqui para uma tarefa semelhante (o
original está aqui ).
Então, planejo portar as melhores redes recebidas para o Android. Portar redes Kerasov para o Android é relativamente simples, bem formalizado e faremos todas as etapas necessárias, para que não seja difícil reproduzir esta parte.
Depois publicaremos tudo isso no Google Play. Naturalmente, o Google resistirá, portanto, truques adicionais serão usados. Por exemplo, o tamanho do nosso aplicativo (devido a uma rede neural volumosa) será maior que o tamanho permitido do APK do Android aceito pelo Google Play: teremos que usar pacotes. Além disso, o Google não mostrará nosso aplicativo nos resultados da pesquisa. Isso pode ser corrigido registrando as tags de pesquisa no aplicativo ou apenas aguardando ... uma semana ou duas.
Como resultado, obtemos um aplicativo "comercial" totalmente funcional (entre aspas, como é definido de graça) para Android e usando redes neurais.
Ambiente de desenvolvimento
Você pode programar o Keras de maneiras diferentes, dependendo do sistema operacional em uso (recomendado pelo Ubuntu), da presença ou ausência de uma placa de vídeo e assim por diante. Não há nada de ruim no desenvolvimento no computador local (e, consequentemente, na sua configuração), exceto que essa não é a maneira mais fácil.
Primeiro, a instalação e configuração de um grande número de ferramentas e bibliotecas leva tempo e, quando novas versões são lançadas, você terá que gastar tempo novamente. Em segundo lugar, as redes neurais exigem grande poder computacional para treinamento. Você pode acelerar (10 ou mais vezes) esse processo se usar uma GPU ... no momento da redação deste artigo, as principais GPUs mais adequadas para este trabalho custam entre US $ 2.000 e US $ 7.000. E sim, eles também precisam ser configurados.
Então, vamos para o outro lado. O fato é que o Google permite que ouriços pobres como nós usem GPUs de seu cluster - gratuitamente, para cálculos relacionados a redes neurais, ele também fornece um ambiente totalmente configurado, todos juntos, isso é chamado de Google Colab. O serviço fornece acesso ao Jupiter Notebook com python, Keras e um grande número de outras bibliotecas já configuradas. Tudo o que você precisa fazer é obter uma conta do Google (obter uma conta do Gmail e isso lhe dará acesso a todo o resto).
No momento, a Colab pode ser contratada
aqui , mas, conhecendo o Google, isso pode mudar a qualquer momento. Basta pesquisar no Google Colab.
O problema óbvio com o uso do Colab é que é um serviço WEB. Como acessamos nossos dados? Salvar a rede neural após o treinamento, por exemplo, baixar dados específicos da nossa tarefa e assim por diante?
Existem várias (no momento em que escrevemos este artigo - três) maneiras diferentes, usamos a que acho mais conveniente - usamos o Google Drive.
O Google Drive é um armazenamento de dados baseado em nuvem que funciona como um disco rígido comum e pode ser mapeado no Google Colab (veja o código abaixo). Depois disso, você pode trabalhar com ele como faria com os arquivos em um disco local. Ou seja, por exemplo, para acessar as fotos de cães para treinar nossa rede neural, precisamos carregá-las no Google Drive, só isso.
Criando e treinando uma rede neural
Abaixo, dou o código em Python, bloco por bloco (do Jupiter Notebook). Você pode copiar esse código no seu Jupiter Notebook e executá-lo, bloco por bloco, também, pois os blocos podem ser executados independentemente (é claro, as variáveis definidas no bloco anterior podem ser necessárias no final, mas essa é uma dependência óbvia).
Inicialização
Primeiro de tudo, vamos montar o Google Drive. Apenas duas linhas. Esse código deve ser executado apenas uma vez em uma sessão Colab (digamos, uma vez a cada 6 horas). Se você chamar pela segunda vez enquanto a sessão ainda estiver "viva", ela será ignorada, pois a unidade já está montada.
from google.colab import drive drive.mount('/content/drive/')
No primeiro começo, você será solicitado a confirmar suas intenções, não há nada complicado. Aqui está o que parece:
>>> Go to this URL in a browser: ... >>> Enter your authorization code: >>> ·········· >>> Mounted at /content/drive/
Uma seção de
inclusão completamente padrão; é possível que alguns dos arquivos incluídos não sejam necessários, bem ... desculpe. Além disso, como vou testar redes neurais diferentes, será necessário comentar / descomentar alguns dos módulos incluídos para tipos específicos de redes neurais: por exemplo, para usar o InceptionV3 NN, descomentar a inclusão do InceptionV3 e comentar, por exemplo, o ResNet50. Ou não: tudo o que muda com isso é o tamanho da memória usada e isso não é muito forte.
import datetime as dt import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from tqdm import tqdm import cv2 import numpy as np import os import sys import random import warnings from sklearn.model_selection import train_test_split import keras from keras import backend as K from keras import regularizers from keras.models import Sequential from keras.models import Model from keras.layers import Dense, Dropout, Activation from keras.layers import Flatten, Conv2D from keras.layers import MaxPooling2D from keras.layers import BatchNormalization, Input from keras.layers import Dropout, GlobalAveragePooling2D from keras.callbacks import Callback, EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras.callbacks import ModelCheckpoint import shutil from keras.applications.vgg16 import preprocess_input from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from keras.models import load_model from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions from keras.applications import inception_v3 from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input as inception_v3_preprocessor from keras.applications.mobilenetv2 import MobileNetV2 from keras.applications.nasnet import NASNetMobile
No Google Drive, criamos uma pasta para nossos arquivos. A segunda linha exibe seu conteúdo:
working_path = "/content/drive/My Drive/DeepDogBreed/data/" !ls "/content/drive/My Drive/DeepDogBreed/data" >>> all_images labels.csv models test train valid
Como você pode ver, as fotos dos cães (copiadas do conjunto de dados de Stanford (veja acima) no Google Drive) são salvas primeiro na pasta
all_images . Mais tarde, iremos copiá-los nos diretórios
train, valid e
test . Salvaremos modelos treinados na pasta de
modelos . Quanto ao arquivo labels.csv, isso faz parte do conjunto de dados com fotos, contém uma tabela de correspondência dos nomes das fotos e raças de cães.
Existem muitos testes que você pode executar para entender exatamente o que recebemos para uso temporário do Google. Por exemplo:
Como você pode ver, a GPU está realmente conectada e, caso contrário, você precisa encontrar e ativar essa opção nas configurações do Notebook Jupiter.
Em seguida, precisamos declarar algumas constantes, como o tamanho das imagens, etc. Usaremos imagens com um tamanho de 256x256 pixels; essa é uma imagem grande o suficiente para não perder detalhes e pequena o suficiente para que tudo caiba na memória. Observe, no entanto, que alguns tipos de redes neurais que usaremos esperam imagens de 224x224 pixels. Nesses casos, comentamos 256 e descomentamos 224.
A mesma abordagem (comentário um - descomente) será aplicada aos nomes dos modelos que salvamos, simplesmente porque não queremos sobrescrever arquivos que ainda podem ser úteis.
warnings.filterwarnings("ignore") os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' np.random.seed(7) start = dt.datetime.now() BATCH_SIZE = 16 EPOCHS = 15 TESTING_SPLIT=0.3
Carregamento de dados
Primeiro, vamos
fazer o upload do arquivo
labels.csv e dividi-lo nas partes de treinamento e validação. Observe que ainda não há uma parte de teste, pois vou trapacear para obter mais dados de treinamento.
labels = pd.read_csv(working_path + 'labels.csv') print(labels.head()) train_ids, valid_ids = train_test_split(labels, test_size = TESTING_SPLIT) print(len(train_ids), 'train ids', len(valid_ids), 'validation ids') print('Total', len(labels), 'testing images') >>> id breed >>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull >>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo >>> 2 001cdf01b096e06d78e9e5112d419397 pekinese >>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick >>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever >>> 7155 train ids 3067 validation ids >>> Total 10222 testing images
Em seguida, copie os arquivos de imagem para as pastas de treinamento / validação / teste, de acordo com os nomes dos arquivos. A função a seguir copia os arquivos cujos nomes transferimos para a pasta especificada.
def copyFileSet(strDirFrom, strDirTo, arrFileNames): arrBreeds = np.asarray(arrFileNames['breed']) arrFileNames = np.asarray(arrFileNames['id']) if not os.path.exists(strDirTo): os.makedirs(strDirTo) for i in tqdm(range(len(arrFileNames))): strFileNameFrom = strDirFrom + arrFileNames[i] + ".jpg" strFileNameTo = strDirTo + arrBreeds[i] + "/" + arrFileNames[i] + ".jpg" if not os.path.exists(strDirTo + arrBreeds[i] + "/"): os.makedirs(strDirTo + arrBreeds[i] + "/")
Como você pode ver, apenas copiamos um arquivo para cada raça de cão como
teste . Além disso, ao copiar, criamos subpastas, uma para cada raça. Consequentemente, as fotografias são copiadas para subpastas por raça.
Isso é feito porque o Keras pode trabalhar com um diretório de estrutura semelhante, carregando arquivos de imagem conforme necessário e não todos de uma vez, o que economiza memória. Carregar todas as 15.000 imagens de uma só vez é uma má idéia.
Teremos que chamar essa função apenas uma vez, pois ela copia imagens - e não é mais necessária. Assim, para uso futuro, devemos comentar:
Obtenha uma lista de raças de cães:
breeds = np.unique(labels['breed']) map_characters = {}
Processamento de imagem
Vamos usar o recurso da biblioteca Keras chamado ImageDataGenerators. ImageDataGenerator pode processar a imagem, dimensionar, girar e assim por diante. Também pode aceitar uma função de
processamento que pode processar imagens adicionalmente.
def preprocess(img): img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation = cv2.INTER_AREA)
Preste atenção ao seguinte código:
Podemos normalizar (sub-dados sob o intervalo 0-1 em vez do original 0-255) no próprio ImageDataGenerator. Por que, então, precisamos de um pré-processador? Como exemplo, considere a chamada borrada (comentada, não a uso): esta é a mesma manipulação de imagem personalizada que pode ser arbitrária. Qualquer coisa do contraste ao HDR.
Usaremos dois ImageDataGenerators diferentes, um para treinamento e outro para validação. A diferença é que, para o treinamento, precisamos de curvas e redimensionamentos para aumentar a "variedade" de dados, mas para validação, não precisamos deles, pelo menos não nesta tarefa.
train_datagen = ImageDataGenerator( preprocessing_function=preprocess,
Criando uma rede neural
Como já mencionado, vamos criar vários tipos de redes neurais. Cada vez que chamaremos outra função para criar, inclua outros arquivos e, às vezes, determine um tamanho de imagem diferente. Portanto, para alternar entre diferentes tipos de redes neurais, devemos comentar / descomentar o código apropriado.
Primeiro de tudo, crie uma CNN “baunilha”. Não funciona bem, porque decidi não perder tempo depurando-o, mas pelo menos fornece uma base que pode ser desenvolvida se houver um desejo (geralmente essa é uma má ideia, pois as redes pré-treinadas fornecem o melhor resultado).
def createModelVanilla(): model = Sequential()
Quando criamos redes usando
transferência de aprendizado , o procedimento muda:
def createModelMobileNetV2():
A criação de outros tipos de redes segue o mesmo padrão:
def createModelResNet50(): base_model = ResNet50(weights='imagenet', include_top=False, pooling='avg', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)) x = base_model.output x = Dense(512)(x) x = Activation('relu')(x) x = Dropout(0.5)(x) predictions = Dense(NUM_CLASSES, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions)
Atenção: vencedor! Este NN mostrou o melhor resultado:
def createModelInceptionV3():
Outro:
def createModelNASNetMobile():
Diferentes tipos de redes neurais podem ser usados para diferentes tarefas. Portanto, além dos requisitos de precisão da previsão, o tamanho pode ter importância (o NN móvel é 5 vezes menor que o Inception) e a velocidade (se precisarmos de processamento em tempo real de um fluxo de vídeo, a precisão terá que ser sacrificada).
Treinamento em redes neurais
Antes de tudo, estamos
experimentando , portanto devemos poder remover as redes neurais que salvamos, mas que não usamos mais. A seguinte função remove NN, se existir:
A maneira como criamos e excluímos redes neurais é bastante simples e direta. Primeiro exclua. Ao chamar
delete (somente), lembre-se de que o Notebook Jupiter possui uma função de "seleção de execução", selecione apenas o que deseja usar e execute-o.
Em seguida, criamos uma rede neural se o arquivo não existir, ou chamaremos o
carregamento, se existir: é claro, não podemos chamar “delete” e esperar que o NN exista; portanto, para usar uma rede neural salva, não chame
delete .
Em outras palavras, podemos criar um novo NN ou usar o existente, dependendo da situação e do que estamos experimentando atualmente. Um cenário simples: treinamos uma rede neural e depois saímos de férias. Eles retornaram e o Google acertou a sessão. Por isso, precisamos carregar a que foi salva anteriormente: comente “delete” e descomente “load”.
deleteSavedNet(working_path + strModelFileName)
Os pontos de verificação são um elemento muito importante do nosso programa. Podemos criar uma série de funções que devem ser chamadas no final de cada era do treinamento e passá-las ao ponto de verificação. Por exemplo, você pode salvar uma rede neural
se ela mostrar resultados melhores do que os que já foram salvos.
checkpoint = ModelCheckpoint(working_path + strModelFileName, monitor='val_acc', verbose=1, save_best_only=True, mode='auto', save_weights_only=False) callbacks_list = [ checkpoint ]
Por fim, ensinamos a rede neural no conjunto de treinamento:
Os gráficos de precisão e perda para a melhor das configurações são os seguintes:
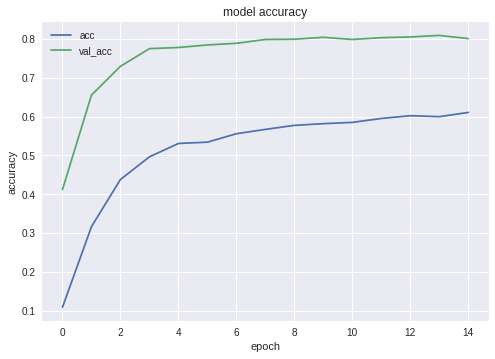

Como você pode ver, a rede neural está aprendendo e não é ruim.
Teste de rede neural
Após a conclusão do treinamento, devemos testar o resultado; por isso, NN apresenta fotos que ela nunca tinha visto antes - aquelas que copiamos na pasta de testes - uma para cada raça de cão.
Exportar uma rede neural para um aplicativo Java
Primeiro de tudo, precisamos organizar o carregamento da rede neural a partir do disco. O motivo é claro: a exportação ocorre em outro bloco de código; portanto, provavelmente iniciaremos a exportação separadamente - quando a rede neural for levada ao seu estado ideal. Ou seja, imediatamente antes da exportação, na mesma execução do programa, não treinaremos a rede. Se você usar o código mostrado aqui, não haverá diferença; a rede ideal foi selecionada para você. Mas se você aprender algo próprio, treinar tudo de novo antes de economizar é uma perda de tempo, se antes você salvava tudo.
Pelo mesmo motivo - para não pular o código - eu incluo os arquivos necessários para a exportação aqui. Ninguém o incomoda de movê-los para o início do programa, se o seu senso de beleza exigir:
from keras.models import Model from keras.models import load_model from keras.layers import * import os import sys import tensorflow as tf
Um pequeno teste após o carregamento de uma rede neural, apenas para garantir que tudo esteja carregado - funciona:
img = image.load_img(working_path + "test/affenpinscher.jpg")

Em seguida, precisamos obter os nomes das camadas de entrada e saída da rede (esta ou a função de criação, devemos "nomear" explicitamente as camadas, o que não fizemos).
model.summary() >>> Layer (type) >>> ====================== >>> input_7 (InputLayer) >>> ______________________ >>> conv2d_283 (Conv2D) >>> ______________________ >>> ... >>> dense_14 (Dense) >>> ====================== >>> Total params: 22,913,432 >>> Trainable params: 1,110,648 >>> Non-trainable params: 21,802,784
Usaremos os nomes das camadas de entrada e saída posteriormente quando importarmos a rede neural para um aplicativo Java.
Outro código que circula na rede para obter esses dados:
def print_graph_nodes(filename): g = tf.GraphDef() g.ParseFromString(open(filename, 'rb').read()) print() print(filename) print("=======================INPUT===================") print([n for n in g.node if n.name.find('input') != -1]) print("=======================OUTPUT==================") print([n for n in g.node if n.name.find('output') != -1]) print("===================KERAS_LEARNING==============") print([n for n in g.node if n.name.find('keras_learning_phase') != -1]) print("===============================================") print()
Mas eu não gosto dele e não o recomendo.O código a seguir exportará a Rede Neural Keras para o formato pb , que capturaremos do Android. def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True): if os.path.exists(output_dir) == False: os.mkdir(output_dir) out_nodes = [] for i in range(len(keras_model.outputs)): out_nodes.append(out_prefix + str(i + 1)) tf.identity(keras_model.output[i], out_prefix + str(i + 1)) sess = K.get_session() from tensorflow.python.framework import graph_util from tensorflow.python.framework graph_io init_graph = sess.graph.as_graph_def() main_graph = graph_util.convert_variables_to_constants( sess, init_graph, out_nodes) graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False) if log_tensorboard: from tensorflow.python.tools import import_pb_to_tensorboard import_pb_to_tensorboard.import_to_tensorboard( os.path.join(output_dir, model_name), output_dir)
Chamando estas funções para exportar uma rede neural:
model = load_model(working_path + strModelFileName) keras_to_tensorflow(model, output_dir=working_path + strModelFileName, model_name=working_path + "models/dogs.pb") print_graph_nodes(working_path + "models/dogs.pb")
A última linha imprime a estrutura da rede neural resultante.Criando um aplicativo Android usando uma rede neural
A exportação de redes neurais no Android é bem formalizada e não deve causar dificuldades. Como sempre, existem várias maneiras pelas quais usamos o mais popular (no momento da redação).Primeiro, usamos o Android Studio para criar um novo projeto. Vamos "cortar custos" porque nossa tarefa não é um tutorial para Android. Portanto, o aplicativo conterá apenas uma atividade. Como você pode ver, adicionamos a pasta “assets” e copiamos nossa rede neural (a que exportamos anteriormente).
Como você pode ver, adicionamos a pasta “assets” e copiamos nossa rede neural (a que exportamos anteriormente).Arquivo Gradle
Neste arquivo, você precisa fazer várias alterações. Primeiro de tudo, precisamos importar a biblioteca tensorflow-android . É usado para trabalhar com o Tensorflow (e, consequentemente, o Keras) do Java: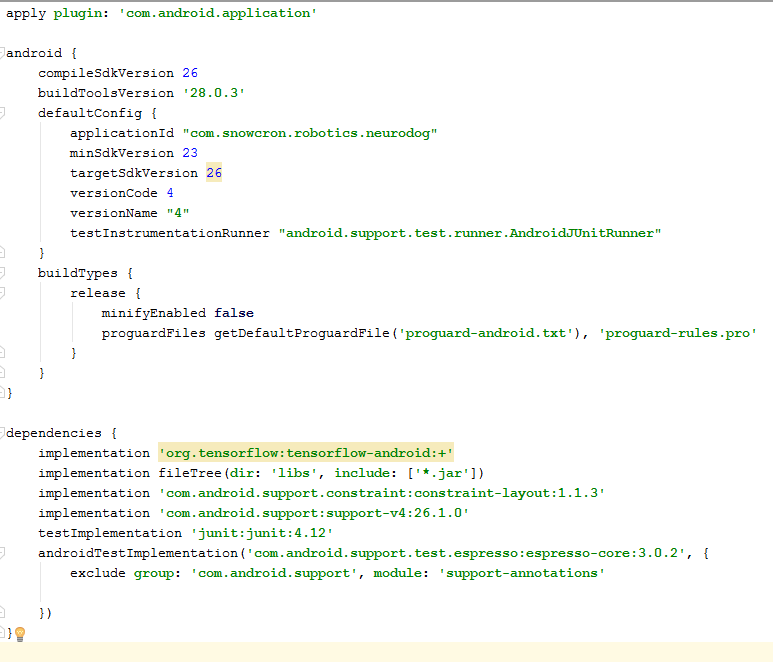 Outro obstáculo não óbvio: versionCode e versionName . Quando o aplicativo é alterado, você precisa fazer o upload de novas versões no Google Play. Sem alterar as versões no gdadle (por exemplo, 1 -> 2 -> 3 ...), você não pode fazer isso, o Google emitirá um erro "esta versão já existe".
Outro obstáculo não óbvio: versionCode e versionName . Quando o aplicativo é alterado, você precisa fazer o upload de novas versões no Google Play. Sem alterar as versões no gdadle (por exemplo, 1 -> 2 -> 3 ...), você não pode fazer isso, o Google emitirá um erro "esta versão já existe".Manifesto
Antes de tudo, nosso aplicativo será "pesado" - a Rede Neural de 100 Mb caberá facilmente na memória dos celulares modernos, mas abrir uma instância separada para cada foto "compartilhada" do Facebook é definitivamente uma má idéia.Por isso, proibimos a criação de mais de uma instância do nosso aplicativo: <activity android:name=".MainActivity" android:launchMode="singleTask">
Ao adicionar android: launchMode = "singleTask" a MainActivity, pedimos ao Android para abrir (ativar) uma cópia existente do aplicativo, em vez de criar outra instância.Em seguida, precisamos incluir nosso aplicativo na lista, que o sistema mostra quando alguém "compartilha" a imagem: <intent-filter> <action android:name="android.intent.action.SEND" /> <category android:name="android.intent.category.DEFAULT" /> <data android:mimeType="image/*" /> </intent-filter>
Por fim, precisamos solicitar recursos e permissões que nosso aplicativo usará: <uses-feature android:name="android.hardware.camera" android:required="true" /> <uses-permission android:name= "android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.READ_PHONE_STATE" tools:node="remove" />
Se você está familiarizado com a programação para Android, esta parte não deve causar perguntas.Aplicativo de layout.
Criaremos dois layouts, um para retrato e outro para paisagem. É assim que o layout do Portrait se parece .O que adicionaremos: um campo grande (exibição) para mostrar a foto, uma lista irritante de anúncios (mostrada quando o botão com um osso é pressionado), o botão Ajuda, botões para baixar uma foto do Arquivo / Galeria e capturar da câmera e, finalmente, (inicialmente oculto) botão "Processar" para processamento de imagem.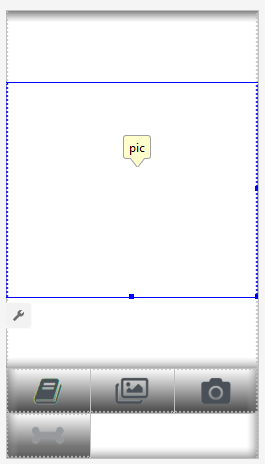 A atividade em si contém toda a lógica de mostrar e ocultar, além de ativar / desativar os botões, dependendo do estado do aplicativo.
A atividade em si contém toda a lógica de mostrar e ocultar, além de ativar / desativar os botões, dependendo do estado do aplicativo.Mainatividade
Esta atividade herda (estende) a atividade padrão do Android: public class MainActivity extends Activity
Considere o código responsável pela operação da rede neural.Primeiro de tudo, a rede neural aceita Bitmap. Inicialmente, este é um Bitmap grande (de tamanho arbitrário) da câmera ou de um arquivo (m_bitmap), depois o transformamos, levando aos pixels padrão de 256x256 (m_bitmapForNn). Também armazenamos o tamanho do bitmap (256) em uma constante: static Bitmap m_bitmap = null; static Bitmap m_bitmapForNn = null; private int m_nImageSize = 256;
Devemos dizer à rede neural os nomes das camadas de entrada e saída; nós os recebemos anteriormente (veja a listagem), mas lembre-se de que, no seu caso, eles podem ser diferentes: private String INPUT_NAME = "input_7_1"; private String OUTPUT_NAME = "output_1";
Em seguida, declaramos uma variável para armazenar o objeto TensofFlow. Além disso, armazenamos o caminho para o arquivo de rede neural (que se encontra nos ativos):private TensorFlowInferenceInterface tf;
string privada MODEL_PATH =
"arquivo: ///android_asset/dogs.pb";
Armazenamos as raças de cães na lista, para que mais tarde elas sejam mostradas ao usuário, e não os índices da matriz: private String[] m_arrBreedsArray;
Inicialmente, baixamos o Bitmap. No entanto, a rede neural espera uma matriz de valores RGB, e sua saída é uma matriz de probabilidades de que essa raça seja o que é mostrado na figura. Portanto, precisamos adicionar mais duas matrizes (observe que 120 é o número de raças de cães presentes em nossos dados de treinamento): private float[] m_arrPrediction = new float[120]; private float[] m_arrInput = null;
Download da biblioteca de inferência tensorflow: static { System.loadLibrary("tensorflow_inference"); }
Como as operações da rede neural levam tempo, precisamos executá-las em um encadeamento separado; caso contrário, existe a chance de recebermos uma mensagem do sistema "o aplicativo não responde", sem mencionar um usuário insatisfeito. class PredictionTask extends AsyncTask<Void, Void, Void> { @Override protected void onPreExecute() { super.onPreExecute(); }
No onCreate () do MainActivity, precisamos adicionar o onClickListener para o botão "Process": m_btn_process.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { processImage(); } });
Aqui processImage () chama apenas o segmento que descrevemos acima: private void processImage() { try { enableControls(false);
Notas adicionais
Não planejamos discutir os detalhes da programação da interface do usuário para Android, pois isso certamente não se aplica à tarefa de portar redes neurais. No entanto, uma coisa ainda vale a pena mencionar.Quando impedimos a criação de instâncias adicionais de nosso aplicativo, também quebramos a ordem normal de criação e exclusão de atividade (fluxo de controle): se você "compartilha" uma imagem do Facebook e depois compartilha outra, o aplicativo não será reiniciado. Isso significa que a maneira “tradicional” de capturar dados transferidos no onCreate não será suficiente, pois o onCreate não será chamado.Veja como resolver esse problema:1. No onCreate em MainActivity, chame a função onSharedIntent: protected void onCreate( Bundle savedInstanceState) { super.onCreate(savedInstanceState); .... onSharedIntent(); ....
Também adicionamos um manipulador para onNewIntent: @Override protected void onNewIntent(Intent intent) { super.onNewIntent(intent); setIntent(intent); onSharedIntent(); }
Aqui está a própria função onSharedIntent: private void onSharedIntent() { Intent receivedIntent = getIntent(); String receivedAction = receivedIntent.getAction(); String receivedType = receivedIntent.getType(); if (receivedAction.equals(Intent.ACTION_SEND)) {
Agora, processamos os dados transferidos no onCreate (se o aplicativo não estava na memória) ou no onNewIntent (se ele foi iniciado anteriormente).Boa sorte Se você gostou do artigo, "gostei" de todas as formas possíveis, também existem botões "sociais" no site .