Links rápidos
-
O caminho para a versão 12-
Primeiro, um pouco de matemática-
O cálculo da incerteza-
Matemática Clássica, Elementar e Avançada-
Mais com polígonos-
Computação com Polyhedra-
Geometria estilo Euclides tornada computável-
Tornar-se super-simbólico com teorias axiomáticas-
O problema do n corpo-
Extensões de idioma e conveniências-
Mais funções de aprendizado de máquina-
O mais recente em redes neurais-
Computando com Imagens-
Reconhecimento de fala e muito mais com áudio-
Processamento de linguagem natural-
Química Computacional-
Computação Geográfica Estendida-
Muitas pequenas melhorias de visualização-
Apertando a integração da base de conhecimento-
Integrando Big Data de bancos de dados externos-
RDF, SPARQL e tudo o mais-
Otimização Numérica-
Análise de elementos finitos não lineares-
Novo e sofisticado compilador-
Chamando Python e outros idiomas-
Mais para o Wolfram "Super Shell"-
Fantoches em um navegador da Web-
Microcontroladores autônomos-
Chamando a linguagem Wolfram de Python e outros lugares-
Ligando ao universo da unidade-
Ambientes simulados para aprendizado de máquina-
Computação Blockchain (e CryptoKitty)-
E criptografia comum também-
Conexão a feeds de dados financeiros-
Engenharia de software e atualizações de plataforma-
E muito mais ...
16 de abril de 2019 - Stephen Wolfram
Hoje, estamos lançando a versão 12 do
Wolfram Language (e
Mathematica ) em
plataformas de desktop e na
nuvem Wolfram . Lançamos a
versão 11.0 em agosto de 2016 ,
11.1 em março de 2017 ,
11.2 em setembro de 2017 e
11.3 em março de 2018 . É um grande salto da versão 11.3 para a versão 12.0. No total, existem
278 funções completamente novas , em talvez 103 áreas, juntamente com milhares de atualizações diferentes em todo o sistema:

Em uma "
versão inteira " como 12, nosso objetivo é fornecer novas áreas de funcionalidade totalmente preenchidas. Mas, em cada versão, também queremos fornecer os resultados mais recentes de nossos esforços de pesquisa e desenvolvimento. Na versão 12.0, talvez metade de nossas novas funções possa ser vista como áreas de acabamento iniciadas em versões ".1" anteriores - enquanto metade inicia novas áreas. Discutirei os dois tipos de funções nesta peça, mas enfatizarei particularmente as especificidades do que há de novo na passagem de 11.3 para 12.0.
Devo dizer que agora que o 12.0 está concluído, estou impressionado com o quanto há nele e com o quanto adicionamos desde o 11.3. Em minha palestra na
Conferência de Tecnologia da Wolfram em outubro passado, resumi o que tínhamos até aquele momento - e até isso levou quase quatro horas. Agora há ainda mais.
O que conseguimos fazer é um testemunho da força de nosso esforço de P&D e da eficácia da Wolfram Language como ambiente de desenvolvimento. Naturalmente, essas duas coisas estão se
formando há três décadas . Mas uma novidade da versão 12.0 é que temos permitido que as pessoas assistam ao nosso processo de design nos bastidores -
transmitindo ao vivo mais de 300 horas de minhas reuniões internas de design . Portanto, além de tudo o mais, suspeito que isso faça da Versão 12.0 o primeiro grande lançamento de software na história que foi aberto dessa maneira.
OK, então o que há de novo na 12.0? Há coisas grandes e surpreendentes - principalmente em
química ,
geometria ,
incerteza numérica e
integração de bancos de dados . Mas, no geral, existem muitas coisas em muitas áreas - e, de fato, até o resumo básico delas no
Centro de Documentação já tem 19 páginas:

Embora hoje em dia a grande maioria do que a Wolfram Language (e o Mathematica) faça não seja o que geralmente é considerado matemática, ainda colocamos imenso esforço de P&D em forçar as fronteiras do que pode ser feito em matemática. E como um primeiro exemplo do que adicionamos na
versão 12.0, aqui está o
ComplexPlot3D bastante colorido:
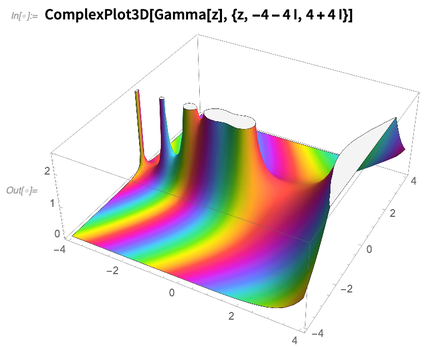
Sempre foi possível escrever o código da Wolfram Language para fazer gráficos no plano complexo. Mas apenas agora resolvemos os problemas de matemática e algoritmos necessários para automatizar o processo de plotagem robusta de funções patológicas no plano complexo.
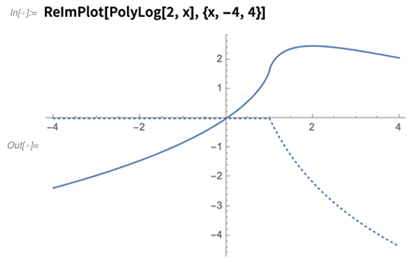
Anos atrás, lembro-me de
traçar meticulosamente a
função dilogaritmo , com suas partes reais e imaginárias. Agora o
ReImPlot apenas faz isso:
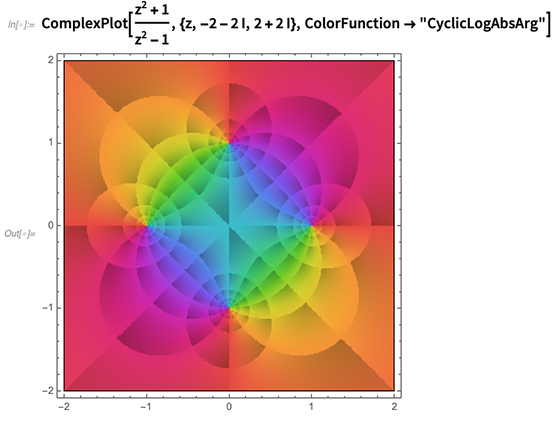
A visualização de funções complexas é (trocadilho à parte) uma história complexa, com detalhes fazendo uma grande diferença no que se nota sobre uma função. Portanto, uma das coisas que fizemos na versão 12.0 é introduzir maneiras padronizadas cuidadosamente selecionadas (como
funções de cores nomeadas) para destacar diferentes recursos:
O cálculo da incerteza
As medições no mundo real geralmente têm incertezas que são representadas como valores com ± erros. Temos pacotes adicionais para lidar com "números com erros" há muito tempo. Mas na versão 12.0, estamos construindo em computação com incerteza, e estamos fazendo certo.
A chave é o objeto simbólico
Around [
x, δ ], que representa um valor “around
x ”, com incerteza
δ :

Você pode fazer aritmética com
Around , e há um cálculo completo de como as incertezas se combinam:

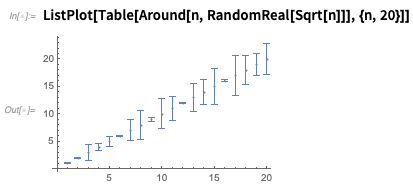
Se você plotar em
torno de números, eles serão mostrados com barras de erro:
Existem muitas opções - como aqui está uma maneira de mostrar incerteza em
xey :
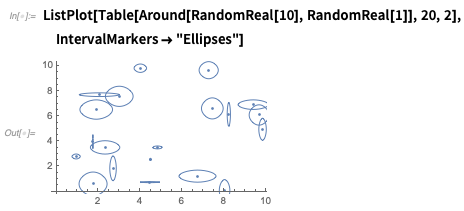
Você pode ter em
torno de quantidades:

E você também pode ter objetos
Around simbólicos:
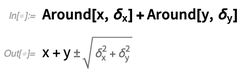
Mas o que realmente é um objeto
Around ? É algo em que existem certas regras para combinar incertezas, baseadas em distribuições normais não correlacionadas. Mas não há nenhuma afirmação sendo feita de que
Around [
x, δ ] represente algo que, em detalhes, segue uma distribuição normal - mais do que isso
Around [
x, δ ] representa um número especificamente no intervalo definido pelo
Intervalo [{
x - δ, x + δ }]. Apenas os objetos
Around propagam seus erros ou incertezas de acordo com regras gerais consistentes que capturam com sucesso o que normalmente é feito na ciência experimental.
OK, digamos que você faça várias medições de algum valor. Você pode obter uma estimativa do valor - junto com sua incerteza - usando
MeanAround (e, sim, se as próprias medições tiverem incertezas, elas serão levadas em consideração na ponderação de suas contribuições):

As funções em todo o sistema - principalmente no
aprendizado de máquina - estão começando a ter a opção
ComputeUn incerto ->
Verdadeiro , o que os faz fornecer objetos ao invés de números puros.
Por aí pode parecer um conceito simples, mas está cheio de sutilezas - que é o principal motivo que levou até agora para entrar no sistema. Muitas das sutilezas giram em torno de correlações entre incertezas. A idéia básica é que a incerteza de todo objeto
Around é assumida como independente. Mas, às vezes, temos valores com incertezas correlacionadas - e, além de
Around , também existe o
VectorAround , que representa um vetor de valores potencialmente correlacionados com uma matriz de covariância especificada.
Há ainda mais sutileza quando se lida com coisas como fórmulas algébricas. Se alguém substituir x aqui por
Around , então, seguindo as regras de
Around , cada instância será considerada não correlacionada:
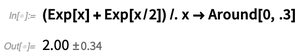
Mas provavelmente se quer assumir aqui que, embora o valor de x possa ser incerto, será o mesmo para cada instância, e é possível fazer isso usando a função
AroundReplace (observe que o resultado é diferente):
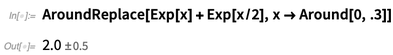
Há muita sutileza em como exibir números incertos. Como quantos 0s à direita você deve colocar:

Ou quanta precisão da incerteza você deve incluir (há um ponto de interrupção convencional quando os dígitos finais são 35):

Em casos raros em que muitos dígitos são conhecidos (pense, por exemplo, em algumas
constantes físicas ), alguém quer ir para uma maneira diferente de especificar incerteza:

E isso continua e continua. Mas gradualmente o
Around começará a aparecer em todo o sistema. A propósito, existem muitas outras maneiras de especificar
Around numbers. Este é um número com 10% de erro relativo:

É o melhor que a
Around pode fazer para representar um intervalo:

Para uma
distribuição ,
Around calcula a variação:
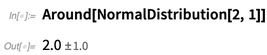
Também pode levar em consideração a assimetria, fornecendo incertezas assimétricas:

Matemática Clássica, Elementar e Avançada
Ao tornar a matemática computacional, é sempre um desafio poder "acertar tudo" e não confundir ou intimidar usuários elementares. A versão 12.0 apresenta várias coisas para ajudar. Primeiro, tente resolver uma
equação quintica irredutível:

No passado, isso mostraria um monte de objetos
raiz explícitos. Mas agora os objetos
Raiz são formatados como caixas mostrando seus valores numéricos aproximados. Os cálculos funcionam exatamente da mesma maneira, mas a tela não confronta imediatamente as pessoas com a necessidade de saber sobre números algébricos.
Quando dizemos
Integrar , queremos dizer "encontrar uma integral", no sentido de uma antiderivada. Porém, no cálculo elementar, as pessoas querem ver constantes explícitas de integração (como sempre no
Wolfram | Alpha ), por isso adicionamos
uma opção para isso (e C [
n ] também possui uma nova e agradável forma de saída):
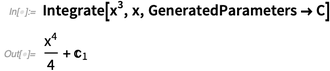
Quando comparamos nossos recursos de integração simbólica, nos saímos muito bem. Mas sempre há mais a ser feito, particularmente em termos de encontrar as formas mais simples de integrais (e, no nível teórico, isso é uma conseqüência inevitável da indecidibilidade da equivalência da expressão simbólica). Na versão 12.0, continuamos escolhendo a fronteira, adicionando casos como:

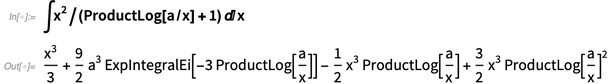
Na Versão 11.3, introduzimos a análise assintótica, podendo encontrar valores assintóticos de integrais e assim por diante. A versão 12.0 adiciona somas assintóticas, recorrências assintóticas e soluções assintóticas às equações:
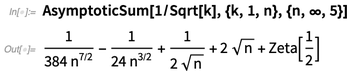
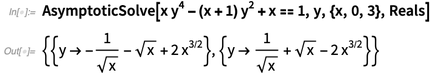
Uma das grandes coisas de tornar a matemática computacional é que ela nos dá novas maneiras de explicar a própria matemática. E algo que estamos fazendo é aprimorar nossa documentação para que ela explique a matemática e as funções. Por exemplo, aqui está o começo da documentação sobre
Limite - com diagramas e exemplos das principais idéias matemáticas:
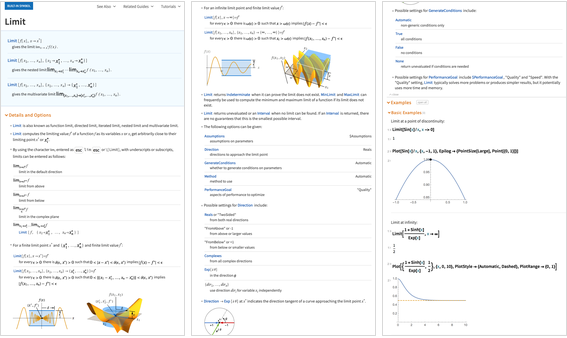
Os polígonos fazem parte da Wolfram Language desde a versão 1. Mas na versão 12.0 eles estão sendo generalizados: agora há uma maneira sistemática de especificar buracos neles. Um caso de uso geográfico clássico é o polígono
da África do Sul - com seu orifício para o país do
Lesoto .
Na versão 12.0, assim como o
Root , o
Polygon obtém um novo formulário de exibição conveniente:
Você pode calcular com ele como antes:
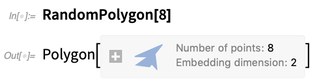
 RandomPolygon também
RandomPolygon também é novo. Você pode pedir, digamos, 5 polígonos convexos aleatórios, cada um com 10 vértices, em 3D:
Existem muitas novas operações em polígonos. Como
PolygonDecomposition , que pode, por exemplo, decompor um polígono em partes convexas:

Polígonos com orifícios também introduzem a necessidade de outros tipos de operações, como
OuterPolygon ,
SimplePolygonQ e
CanonicalizePolygon .
Os polígonos são bem simples de especificar: você apenas fornece os vértices em ordem (e, se tiverem furos, também os vértices). Os poliedros são um pouco mais complicados: além de fornecer os vértices, é preciso dizer como esses vértices formam faces. Porém, na versão 12.0, o
Poliedro permite fazer isso com considerável generalidade, incluindo vazios (o análogo 3D de orifícios), etc.
Mas primeiro, reconhecendo seus mais de
2000 anos de história , a Versão 12.0 introduz funções para os cinco
sólidos platônicos :
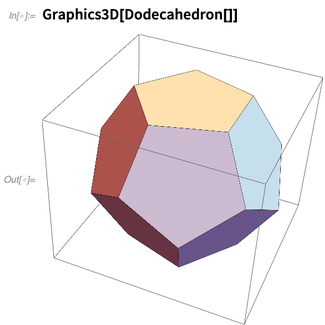
E, considerando os sólidos platônicos, pode-se começar imediatamente a computar com eles:

Aqui está o ângulo sólido subtendido no vértice 1 (já que é platônico, todos os vértices dão o mesmo ângulo):
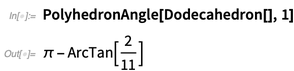
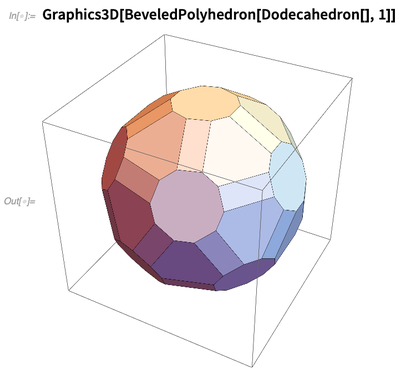
Aqui está uma operação feita no poliedro:

Além dos sólidos platônicos, a Versão 12 também se baseia em todos os "
poliedros uniformes " (
n arestas e
m faces se encontram em cada vértice) - e você também pode obter versões simbólicas de
poliedros dos poliedros nomeados da
Polyhedron .

Você pode fazer qualquer poliedro (incluindo um "aleatório", com o
RandomPolyhedron ) e depois fazer os cálculos que desejar:


O Mathematica e a Wolfram Language são muito poderosos para fazer
geometria computacional explícita e
geometria representada em termos de álgebra . Mas e a geometria da maneira como é feita nos
Elementos de Euclides - em que se faz afirmações geométricas e depois se vê quais são suas consequências?
Bem, na versão 12, com toda a torre de tecnologia que construímos, finalmente conseguimos oferecer um novo estilo de computação matemática - que de fato automatiza o que Euclid estava fazendo há mais de 2000 anos. Uma idéia-chave é introduzir "cenas geométricas" simbólicas que possuam símbolos representando construções como pontos e, em seguida, definir objetos e relações geométricos em termos deles.
Por exemplo, aqui está uma cena geométrica representando um triângulo
a, b, c e um círculo entre
a, b e
c , com
o centro
o , com a restrição de que
o está no ponto médio da linha de
a a
c :

Por si só, isso é apenas uma coisa simbólica. Mas podemos fazer operações nele. Por exemplo, podemos solicitar uma instância aleatória, na qual
a, b, c e
o são específicos:
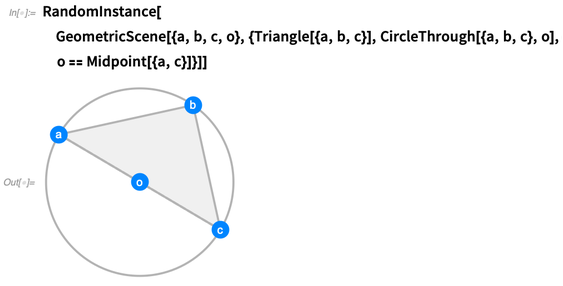
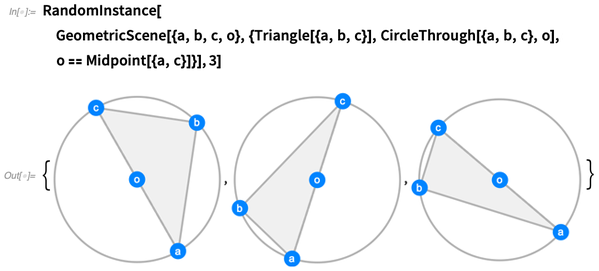
Você pode gerar quantas instâncias aleatórias desejar. Tentamos tornar as instâncias o mais genéricas possível, sem coincidências que não sejam forçadas pelas restrições:
OK, mas agora vamos "tocar Euclides" e encontrar conjecturas geométricas que são consistentes com nossa configuração:

Para uma determinada cena geométrica, pode haver muitas conjecturas possíveis. Tentamos escolher os interessantes. Nesse caso, criamos dois - e o que é ilustrado é o primeiro: que a linha ba é perpendicular à linha cb. Por acaso, esse resultado realmente aparece em Euclides (está no
Livro 3, como parte da Proposição 31 ) - embora seja geralmente chamado
de teorema de Thales .
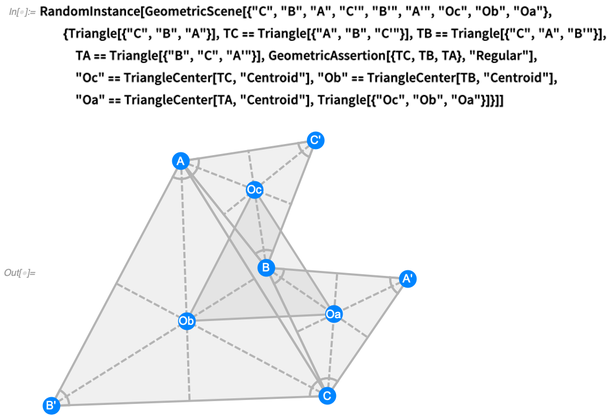
Na versão 12.0, agora temos toda uma linguagem simbólica para representar coisas típicas que aparecem na geometria no estilo Euclides. Aqui está uma situação mais complexa - correspondente ao chamado
teorema de Napoleão :
Na versão 12.0, existem muitas funções geométricas novas e úteis que funcionam em coordenadas explícitas:
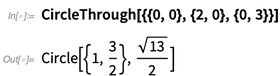
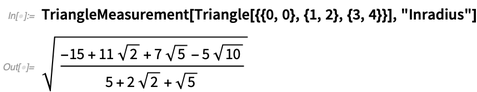
Para triângulos, há 12 tipos de "centros" suportados e, sim, podem haver coordenadas simbólicas:

E para apoiar a configuração de declarações geométricas, também precisamos de "
asserções geométricas ". Na versão 12.0, existem 29 tipos diferentes - como
"Paralelo" ,
"Congruente" ,
"Tangente" ,
"Convexo" etc. Aqui estão três círculos declarados como tangentes aos pares:
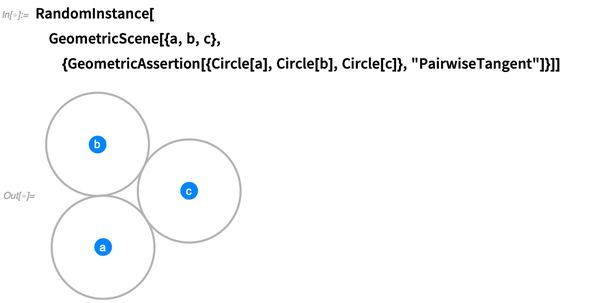
Tornando-se super-simbólico com teorias axiomáticas
A versão 11.3 introduziu o
FindEquationalProof para gerar representações simbólicas de provas. Mas que axiomas devem ser usados para essas provas? A versão 12.0 introduz o
AxiomaticTheory , que fornece axiomas para várias
teorias axiomáticas comuns.
Aqui está o meu
sistema de axioma favorito :

O que isso significa? Em certo sentido, é uma expressão simbólica mais simbólica do que estamos acostumados. Em algo como 1 +
x , não dizemos qual é o valor de
x , mas imaginamos que ele possa ter um valor. Na expressão acima, a, bec são "símbolos formais" puros que cumprem um papel essencialmente estrutural e nunca podem ser pensados como tendo valores concretos.
E o · (ponto central)? Em 1 +
x , sabemos o que + significa. Mas o · pretende ser um operador puramente abstrato. O ponto do axioma está em vigor para
definir uma restrição sobre o que · pode representar. Nesse caso em particular, verifica-se que o axioma é um
axioma da álgebra booleana , de modo que pode representar
Nand e
Nor . Mas podemos derivar formalmente as consequências do axioma, por exemplo, com
FindEquationalProof :
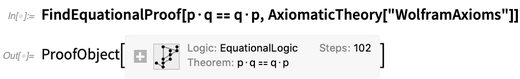
Há um pouco de sutileza nisso tudo. No exemplo acima, é útil ter · como operador, até porque ele é exibido de maneira adequada. Mas não há significado
interno para isso, e o
AxiomaticTheory permite que você dê outra coisa (aqui
f ) como operador:

O que o
"Nand" está fazendo lá? É um nome para o operador (mas não deve ser interpretado como algo a ver com o valor do operador). Nos
axiomas da teoria dos grupos , por exemplo, vários operadores aparecem:
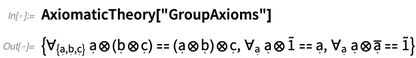
Isso fornece as representações padrão dos vários operadores aqui:
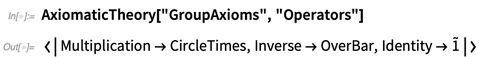 A AxiomaticTheory
A AxiomaticTheory conhece teoremas notáveis para sistemas axiomáticos específicos:
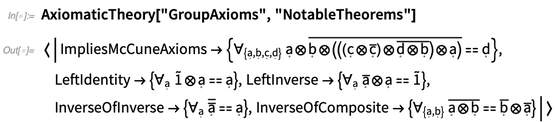
A idéia básica dos símbolos formais foi introduzida na Versão 7, para fazer coisas como representar variáveis fictícias em construções geradas como estas:


Você pode inserir um símbolo formal usando
\ [FormalA] ou Esc, a, Esc, etc. Mas na versão 7,
\ [FormalA] foi renderizado como
a . E isso significava que a expressão acima parecia:

Eu sempre pensei que isso parecia incrivelmente complicado. E para a versão 12, queríamos simplificá-la. Tentamos muitas possibilidades, mas acabamos decidindo por um único ponto fraco cinza - o que acho muito melhor.
No
AxiomaticTheory , as variáveis e os operadores são "puramente simbólicos". Mas uma coisa que é definitiva é a aridade de cada operador, que se pode perguntar ao
AxiomaticTheory :
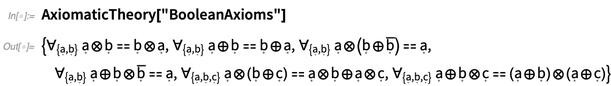

Convenientemente, a representação de operadores e aridades pode ser imediatamente inserida em
agrupamentos , para obter possíveis expressões envolvendo variáveis específicas:

O problema do n corpo
As teorias axiomáticas representam uma área histórica clássica da matemática. Outra área histórica clássica - muito mais no lado aplicado - é o
problema dos corpos n . A versão 12.0 introduz o
NBodySimulation , que fornece simulações do problema do n corpo. Aqui está um problema de três corpos (pense
Terra-Lua-Sol ) com certas condições iniciais (e lei da força do quadrado inverso):

Você pode perguntar sobre vários aspectos da solução; isso representa as posições em função do tempo:
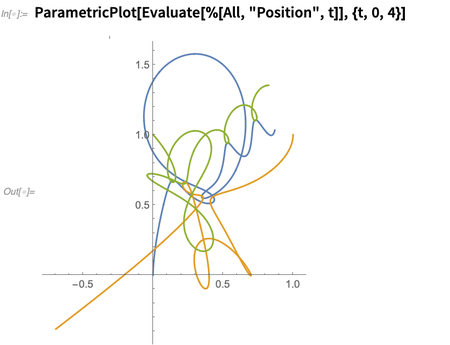
Por baixo, isso está apenas resolvendo equações diferenciais, mas - um pouco como
SystemModel -
NBodySimulation fornece uma maneira conveniente de configurar as equações e lidar com suas soluções. E sim, as leis de força padrão estão embutidas, mas você pode definir suas próprias.
Extensões e Convenções de Idiomas
Estamos aprimorando o núcleo da Wolfram Language há mais de 30 anos e, em cada versão sucessiva, acabamos introduzindo novas extensões e conveniências.
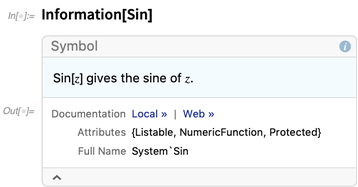
Temos a função
Information desde a versão 1.0, mas na 12.0 a ampliamos bastante. Costumava fornecer apenas informações sobre símbolos (embora isso também tenha sido modernizado):
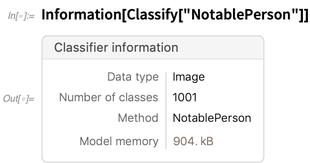
Mas agora também fornece informações sobre vários tipos de objetos. Aqui estão as informações sobre um classificador:
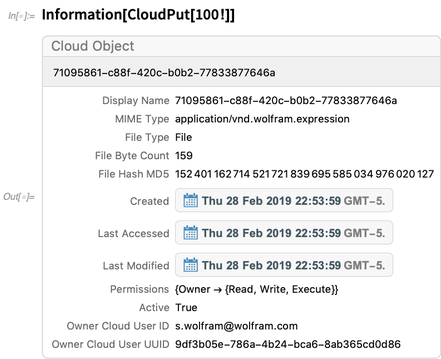
Aqui estão as informações sobre um objeto de nuvem:
Passe o mouse sobre os rótulos na "caixa de informações" e você pode descobrir os nomes das propriedades correspondentes:

Para entidades, o
Information fornece um resumo dos valores conhecidos da propriedade:
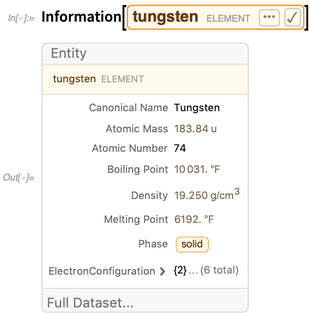
Nas últimas versões, introduzimos muitos novos formulários de exibição de resumo. Na versão 11.3, apresentamos o
Iconize , que é essencialmente uma maneira de criar um formulário de exibição de resumo para qualquer coisa. O Iconize provou ser ainda mais útil do que o inicialmente previsto. É ótimo para ocultar complexidade desnecessária, tanto em notebooks quanto em partes do código da Wolfram Language. Na versão 12.0, reprojetamos a forma como o Iconize é exibido, principalmente para torná-lo "bem lido" nas expressões e códigos.
Você pode explicitamente iconizar algo:

Pressione o + e você verá alguns detalhes:
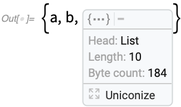
Pressione

e você obterá a expressão original novamente:

Se você tiver muitos dados que deseja referenciar em um cálculo, sempre poderá armazená-los em um arquivo ou na
nuvem (ou mesmo em um
repositório de dados ). Geralmente, é mais conveniente apenas colocá-lo em seu notebook, para que você tenha tudo no mesmo lugar. Uma maneira de evitar que os dados “assumam seu notebook” é
colocar células fechadas . Mas o Iconize fornece uma maneira muito mais flexível e elegante de fazer isso.
Quando você está escrevendo um código, geralmente é conveniente “iconizar no lugar”. O menu do botão direito agora permite fazer isso:

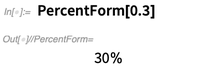
Falando em exibição, aqui está algo pequeno, mas conveniente, que adicionamos na versão 12.0:
E aqui estão algumas outras "conveniências numéricas" que adicionamos:

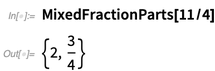
A programação funcional sempre foi uma parte central da Wolfram Language. Mas procuramos continuamente estendê-lo e introduzir novas primitivas geralmente úteis. Um exemplo na versão 12.0 é
SubsetMap :
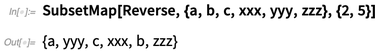

Funções são normalmente coisas que podem receber várias entradas, mas sempre fornecem uma única peça de saída. Em áreas como
a computação quântica , no entanto, a pessoa está interessada em ter
n entradas e
n saídas.
O SubsetMap efetivamente implementa
n-> n funções, captando entradas de
n posições especificadas em uma lista, aplicando alguma operação a elas e, em seguida, retornando os resultados nas mesmas
n posições.
Comecei a formular o que é agora o
SubsetMap cerca de um ano atrás. E rapidamente percebi que, na verdade, eu poderia ter usado essa função em todos os tipos de lugares ao longo dos anos. Mas como deve ser chamado esse "pedaço de trabalho computacional" em particular? Meu nome de trabalho inicial era
ArrayReplaceFunction (que
abreviei para
ARF em minhas anotações). Em uma
sequência de reuniões (transmitidas ao vivo) , fomos e voltamos. Havia idéias como
ApplyAt (mas não é realmente
Apply ) e
MutateAt (mas não está fazendo mutação no sentido lvalue), bem como
RewriteAt ,
ReplaceAt ,
MultipartApply e
ConstructInPlace . Havia idéias sobre os formulários de “decorador de funções” ao curry, como
PartAppliedFunction ,
PartwiseFunction ,
AppliedOnto ,
AppliedAcross e
MultipartCurry .
Mas, de alguma forma, quando explicamos a função, voltamos a falar sobre como ela estava operando em um subconjunto de uma lista e como era realmente como o
Map , exceto que ela estava operando em vários elementos ao mesmo tempo. Então, finalmente, decidimos pelo nome
SubsetMap . E - em mais um reforço da importância do design da linguagem - é notável como, uma vez que se tem um nome para algo assim, se vê imediatamente capaz de raciocinar sobre ele e ver onde ele pode ser usado.
Durante muitos anos, trabalhamos duro para tornar a Wolfram Language o sistema de mais alto nível e mais automatizado para
o aprendizado de máquina de última geração . Introduzimos desde o início as “superfunções”
Classificar e
prever que executam tarefas de
classificação e previsão de uma maneira totalmente automatizada, escolhendo automaticamente a melhor abordagem para a entrada específica fornecida. Ao longo do caminho, introduzimos outras superfunções - como
SequencePredict ,
ActiveClassification e
FeatureExtract .
Na versão 12.0, temos várias novas funções importantes de aprendizado de máquina. Há
FindAnomalies , que encontra "elementos anômalos" nos dados:
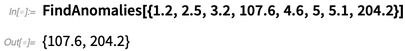
Junto com isso, há
DeleteAnomalies , que exclui elementos que considera anômalos:

Há também
SynthesizeMissingValues , que tenta gerar valores plausíveis para dados ausentes:
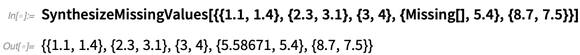
Como essas funções funcionam? Todos eles são baseados em uma nova função chamada
LearnDistribution , que tenta aprender a distribuição subjacente de dados, com um certo conjunto de exemplos. Se os exemplos fossem apenas números, isso seria essencialmente um problema estatístico padrão, para o qual poderíamos usar algo como
EstimatedDistribution . Mas o ponto sobre o
LearnDistribution é que ele funciona com dados de qualquer tipo, não apenas com números. Aqui está aprendendo uma distribuição subjacente para uma coleção de cores:

Depois de termos essa "distribuição aprendida", podemos fazer todo tipo de coisa com ela. Por exemplo, isso gera 20 amostras aleatórias a partir dele:

Mas agora pense em
FindAnomalies . O que é preciso fazer é descobrir quais pontos de dados são anômalos em relação ao esperado. Ou, em outras palavras, dada a distribuição subjacente dos dados, ele encontra quais pontos de dados são discrepantes, no sentido de que eles devem ocorrer apenas com uma probabilidade muito baixa de acordo com a distribuição.
E, assim como em uma distribuição numérica comum, podemos calcular o
PDF para uma determinada parte dos dados. É provável que o roxo tenha em conta a distribuição de cores que aprendemos com nossos exemplos:

Mas o vermelho é realmente muito improvável:

Para distribuições numéricas comuns, existem conceitos como o
CDF que nos dizem probabilidades cumulativas, dizem que obteremos resultados "mais distantes" do que um valor específico. Para espaços de coisas arbitrárias, não existe realmente a noção de "mais longe". Mas criamos uma função que chamamos de
RarerProbability , que nos diz qual é a probabilidade total de gerar um exemplo com um PDF menor do que algo que fornecemos:


Agora, temos uma maneira de descrever anomalias: são apenas pontos de dados que têm uma probabilidade muito menor e mais rara. E, de fato,
FindAnomalies tem uma opção
AcceptanceThreshold (com valor padrão 0,001) que especifica o que deve ser considerado como "muito pequeno".
OK, mas vamos ver esse trabalho em algo mais complicado do que cores. Vamos treinar um detector de anomalias analisando 1000 exemplos de dígitos manuscritos:

Agora,
FindAnomalies pode nos dizer quais exemplos são anômalos:
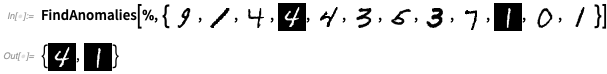
Introduzimos pela primeira vez nossa estrutura simbólica para construir, explorar e usar redes neurais em 2016, como parte da versão 11. E em todas as versões desde então, adicionamos todos os tipos de recursos de ponta. Em junho de 2018, apresentamos nosso
Repositório de Rede Neural para facilitar o acesso aos modelos de rede neural mais recentes da Wolfram Language - e já existem quase 100 modelos com curadoria de muitos tipos diferentes no repositório, com novos sendo adicionados o tempo todo.
Portanto, se você precisar da mais recente
rede neural "transformadora" BERT (que foi adicionada hoje!), Você pode obtê-la no
NetModel :

Você pode abrir isso e ver a rede envolvida (e, sim, atualizamos a exibição dos gráficos de rede para a versão 12.0):
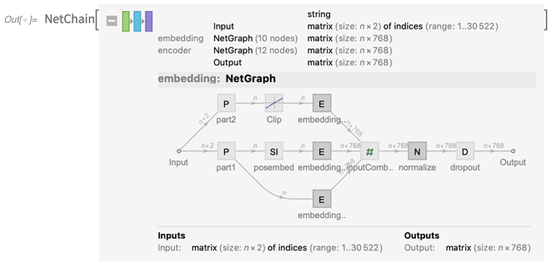
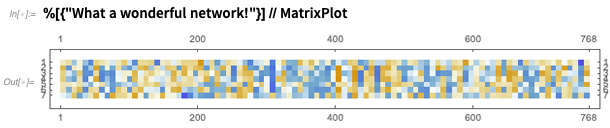
E você pode usar imediatamente a rede, aqui para produzir algum tipo de matriz de "recursos de significado":
Na versão 12.0, apresentamos vários novos tipos de camada - principalmente o
AttentionLayer , que permite configurar as mais recentes arquiteturas de "transformadores" - e aprimoramos nossos recursos de "programação funcional da rede neural", com coisas como
NetMapThreadOperator e sequência múltipla
NetFoldOperator . Além desses aprimoramentos "dentro da rede", a Versão 12.0 inclui todos os tipos de novos casos
NetEncoder e
NetDecoder , como
tokenização BPE para texto em centenas de idiomas, e a capacidade de incluir funções personalizadas para entrada e saída de dados. redes neurais.
Porém, alguns dos aprimoramentos mais importantes da versão 12.0 são mais infraestruturais.
O NetTrain agora oferece suporte
ao treinamento com várias GPUs , além de lidar com critérios aritméticos de precisão mista e critérios de parada antecipada flexíveis. Continuamos a usar a popular estrutura de rede neural de baixo nível
MXNet (da qual temos sido os
principais colaboradores ) - para que possamos tirar proveito das mais recentes otimizações de hardware. Existem
novas opções para ver o que está acontecendo durante o treinamento e também o
NetMeasurements que permite que você faça 33 tipos diferentes de medidas no desempenho de uma rede:

As redes neurais não são a única - ou sempre a melhor - maneira de fazer o aprendizado de máquina. Mas uma coisa nova na versão 12.0 é que agora podemos usar
redes com auto-normalização automaticamente no
Classify and
Predict , para que possam
tirar vantagem facilmente
das redes neurais quando isso faz sentido.
Introduzimos o
ImageIdentify , para identificar o que é uma imagem, na Versão 10.1. Na versão 12.0, conseguimos generalizar isso, para descobrir não apenas o que é uma imagem, mas também o que está em uma imagem. Assim, por exemplo, o
ImageCases nos mostrará casos de tipos conhecidos de objetos em uma imagem:

Para mais detalhes, o
ImageContents fornece um conjunto de dados sobre o que está em uma imagem:
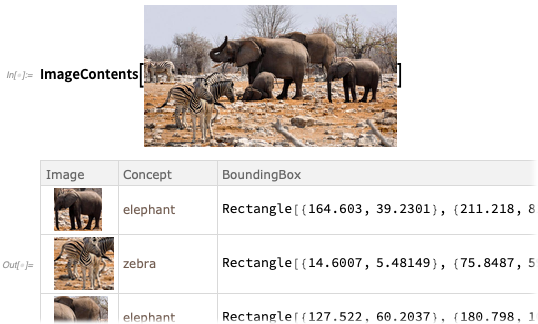
Você pode dizer ao
ImageCases para procurar um tipo específico de coisa:

E você também pode apenas testar para ver se uma imagem contém um tipo específico de coisa:

Em certo sentido, o
ImageCases é como uma versão generalizada do
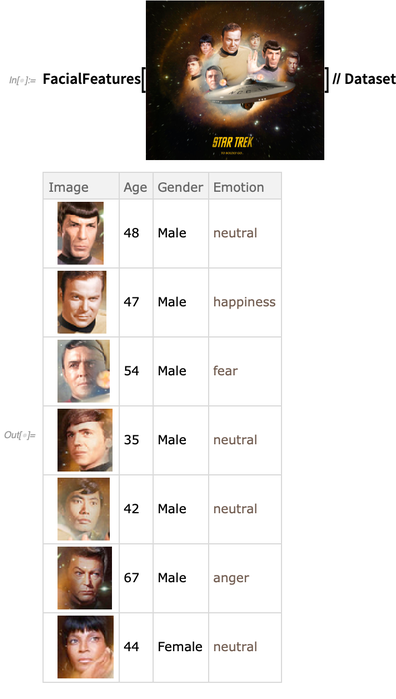
FindFaces , para encontrar rostos humanos em uma imagem. Algo novo na versão 12.0 é que o
FindFaces e o
FacialFeatures se tornaram
mais eficientes e robustos - com o
FindFaces agora baseado em redes neurais em vez de no processamento clássico de imagens, e a rede para o
FacialFeatures agora com 10 MB em vez de 500 MB:
Funções como o
ImageCases representam um processamento de imagem "novo estilo", de um tipo que não parecia concebível há apenas alguns anos atrás. Mas, embora essas funções permitam fazer todo tipo de coisas novas, ainda há muito valor em técnicas mais clássicas. Tivemos
um processamento de imagem clássico bastante completo na Wolfram Language por um longo tempo, mas continuamos a fazer melhorias incrementais.
Um exemplo na versão 12.0 é a estrutura
ImagePyramid , para executar o processamento de imagem em
várias escalas :

Existem várias novas funções na versão 12.0 relacionadas ao cálculo de cores. Uma ideia-chave é
ColorsNear , que representa uma vizinhança no espaço perceptivo de cores, aqui em torno da cor
Pink :
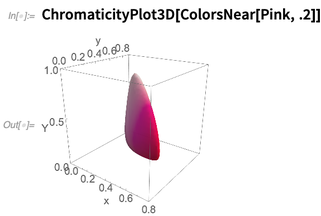
A noção de vizinhanças de cores pode ser usada, por exemplo, na nova função
ImageRecolor :

Enquanto estou sentado no meu computador escrevendo isso, vou dizer algo ao meu computador e
capturá-lo :
Aqui está um espectrograma do áudio que eu capturei:
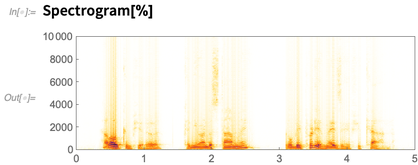
Até agora, poderíamos fazer isso na versão 11.3 (embora o
Spectrogram tenha ficado 10 vezes mais rápido no 12.0). Mas agora, aqui está algo novo:

Estamos falando de texto para texto! Estamos usando a tecnologia de rede neural de última geração, mas estou impressionado com o quão bem ele funciona. É bem simplificado, e somos perfeitamente capazes de lidar com peças muito longas de áudio, digamos, armazenadas em arquivos. E em um computador típico, a transcrição será executada aproximadamente à velocidade real em tempo real, de modo que uma hora de fala levará cerca de uma hora para ser transcrita.
No momento, consideramos o
reconhecimento de fala experimental e continuaremos aprimorando-o. Mas é interessante ver outra tarefa computacional importante se tornar uma única função na Wolfram Language.
Na versão 12.0, há outros aprimoramentos também.
O SpeechSynthesize suporta novos idiomas e novas vozes (conforme listado por
VoiceStyleData []).
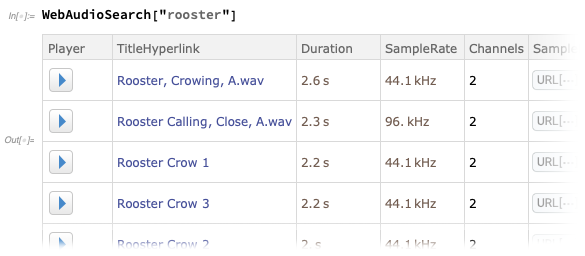
Agora
existe o WebAudioSearch -
análogo ao
WebImageSearch - que permite pesquisar áudio na web:
Você pode recuperar objetos de
áudio reais:
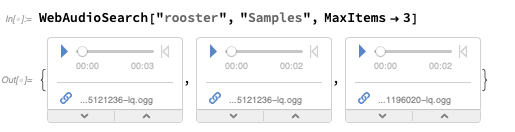
Então você pode fazer espectrogramas ou outras medições:

E então - novo na versão 12.0 - você pode usar o
AudioIdentify para tentar identificar a categoria de som (isso é um galo falante?):

Ainda consideramos o
AudioIdentify experimental. É um começo interessante, mas definitivamente, por exemplo, não funciona tão bem quanto o
ImageIdentify .
Uma função de áudio mais bem-sucedida é o
PitchRecognize , que tenta reconhecer a frequência dominante em um sinal de áudio (ele usa os métodos de rede "clássica" e neural). Ainda não consegue lidar com "acordes", mas funciona perfeitamente com "notas simples".
Quando se lida com áudio, muitas vezes se quer não apenas identificar o que está no áudio, mas anotá-lo. A versão 12.0 apresenta o início de uma
estrutura de áudio em larga escala. No momento, o
AudioAnnotate pode marcar onde há silêncio ou onde há algo alto. No futuro, adicionaremos identificação de alto-falante, limites de palavras e muito mais. E para acompanhar isso, também temos funções como
AudioAnnotationLookup , para selecionar partes de um objeto de áudio que foram anotadas de maneiras específicas.
Por trás de toda essa funcionalidade de áudio de alto nível, há toda uma infraestrutura de processamento de áudio de baixo nível. A versão 12.0 aprimora muito o
AudioBlockMap (para aplicar filtros aos sinais de áudio), além de introduzir funções como
ShortTimeFourier .
Um espectrograma pode ser visto um pouco como um análogo contínuo de uma partitura musical, em que os arremessos são plotados em função do tempo. Na versão 12.0 agora existe o
InverseSpectrogram - que vai de uma matriz de dados do espectrograma para o áudio. Desde a versão 2 em 1991, tivemos o
Play para gerar som a partir de uma função (como
Sin [100 t]). Agora, com o
espectro inverso , temos um caminho para passar de um "bitmap de frequência e tempo" para um som. (E, sim, existem questões complicadas sobre as melhores suposições para as fases quando se tem apenas informações de magnitude.)
Começando com o
Wolfram | Alpha , tivemos
recursos de compreensão da linguagem natural (NLU) excepcionalmente fortes por um longo tempo. E isso significa que, dada uma parte da linguagem natural, somos bons em entendê-la como Wolfram Language - e podemos calcular:
Mas e o processamento da linguagem natural (PNL) - onde estamos pegando passagens potencialmente longas da linguagem natural e não tentando entendê-las completamente, mas apenas localizando ou processando recursos específicos delas? Funções como
TextSentences ,
TextStructure ,
TextCases e
WordCounts nos forneceram recursos básicos nessa área por um tempo. Mas na versão 12.0 - utilizando o mais recente aprendizado de máquina, bem como nossos recursos de NLU e base de conhecimento de longa data - agora passamos a ter recursos de NLP muito fortes.
A peça central é a versão dramaticamente aprimorada do
TextCases . O objetivo básico do
TextCases é encontrar casos de diferentes tipos de conteúdo em um pedaço de texto. Um exemplo disso é a tarefa clássica da PNL de "reconhecimento de entidade" - com o
TextCases aqui, que procura quais nomes de países aparecem no
artigo da
Wikipedia sobre jaguatiricas :

Também poderíamos perguntar quais ilhas são mencionadas, mas agora não pediremos uma interpretação da Wolfram Language:
 O TextCases
O TextCases não é perfeito, mas funciona muito bem:

Ele também suporta vários tipos de conteúdo diferentes:

Você pode pedir para encontrar
pronomes, cláusulas ou
quantidades relativas reduzidas ,
endereços de email ou ocorrências de qualquer um dos 150 tipos de entidades (como
empresas, fábricas ou
filmes ). Você também pode pedir que escolha trechos de texto que sejam em particular idiomas
humanos ou de
computador , ou que sejam
sobre tópicos específicos (como
viagens ou
saúde ) ou que tenham
sentimentos positivos ou negativos . E você pode usar construções como
Contendo para solicitar combinações dessas coisas (como frases substantivas que contêm o nome de um rio):
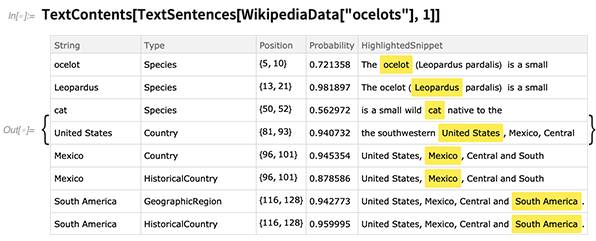
 TextContents
TextContents permite ver, por exemplo, detalhes de todas as entidades que foram detectadas em uma parte específica do texto:
E, sim, em princípio, é possível usar esses recursos por meio do
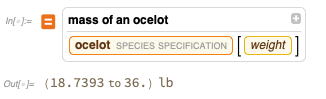
FindTextualAnswer para tentar responder a perguntas do texto - mas, em um caso como esse, os resultados podem ser bem estranhos:

Obviamente, você pode obter uma resposta real da nossa base de dados com curadoria incorporada:
A propósito, na Versão 12.0, adicionamos uma variedade de pequenas "funções de conveniência de linguagem natural", como
Sinônimos e
Antônimos :

Uma das novas áreas "surpreendentes" da Versão 12.0 é a química computacional. Temos dados sobre
produtos químicos conhecidos explícitos em nossa base de conhecimento há muito tempo. Mas na versão 12.0, podemos calcular com moléculas que são especificadas simplesmente como objetos simbólicos puros. Veja como podemos especificar o que acaba sendo uma molécula de água:

E aqui está como podemos fazer uma renderização em 3D:
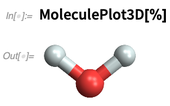
Podemos lidar com "produtos químicos conhecidos":

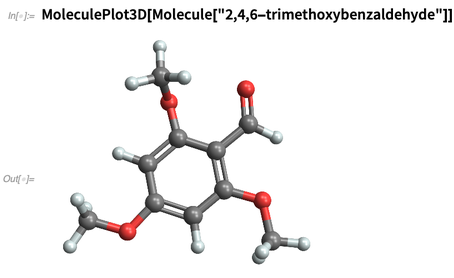
Podemos usar nomes arbitrários da
IUPAC :
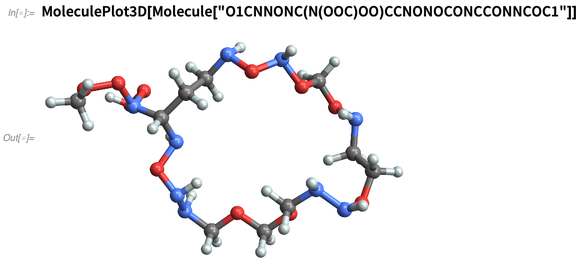
Ou nós "inventamos" produtos químicos, por exemplo, especificando-os por suas seqüências de caracteres
SMILES :
Mas não estamos apenas gerando fotos aqui. Também podemos calcular coisas da estrutura - como simetrias:
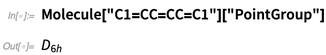
Dada uma molécula, podemos fazer coisas como destacar ligações carbono-oxigênio:
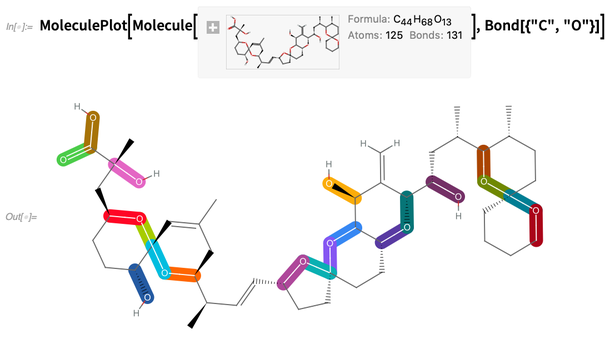
Ou destacar estruturas, digamos, especificadas por strings
SMARTS (aqui qualquer anel de 5 membros):
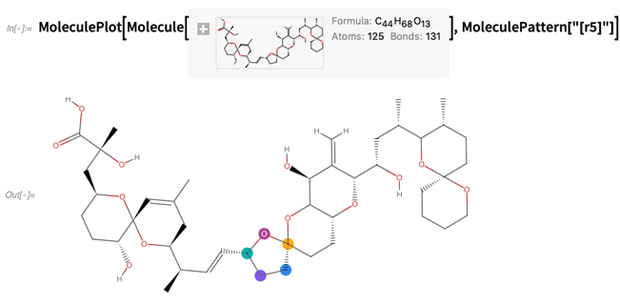
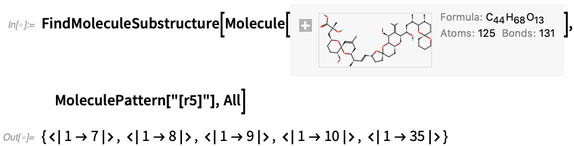
Você também pode pesquisar "padrões de moléculas"; os resultados são apresentados em termos de números de átomos:
Os recursos de química computacional que adicionamos na versão 12.0 são bastante gerais e bastante poderosos (com a ressalva de que até agora eles lidam apenas com moléculas orgânicas). No nível mais baixo, eles vêem as moléculas como gráficos rotulados com arestas correspondentes a ligações. Mas eles também conhecem a física e explicam corretamente valências atômicas e configurações de ligações. Escusado será dizer que existem muitos detalhes (sobre estereoquímica, simetria, aromaticidade, isótopos, etc.). Mas o resultado final é que a estrutura molecular e a computação molecular foram adicionadas com sucesso à lista de áreas integradas à Wolfram Language.
A Wolfram Language já possui fortes recursos para computação geográfica, mas a Versão 12.0 adiciona mais funções e aprimora algumas daquelas que já estavam lá.Por exemplo, agora existe o RandomGeoPosition , que gera um local aleatório ao longo do tempo. O One do poder de pensar a isso o BE O trivial, Mas é claro que do um tem que se preocupar com coordenadas de transformações e que o torna muito mais trivial é que um de PODE dizer do que os pontos de recolha somente dentro de uma determinada região, encontrada aqui no país de França: Um tema é de novos recursos geográficos na Versão 12.0 estão lidando não apenas com pontos e regiões geográficos, mas também com vetores geográficos. Aqui está o vetor de vento atual, por exemplo, na posição da Torre Eiffel, representada como um GeoVector, Com velocidade e direção (há também GeoVectorENU , o que dá a leste, norte e até componentes close up, como com o de um bem como com o GeoGridVector e GeoVectorXYZ ):
Um tema é de novos recursos geográficos na Versão 12.0 estão lidando não apenas com pontos e regiões geográficos, mas também com vetores geográficos. Aqui está o vetor de vento atual, por exemplo, na posição da Torre Eiffel, representada como um GeoVector, Com velocidade e direção (há também GeoVectorENU , o que dá a leste, norte e até componentes close up, como com o de um bem como com o GeoGridVector e GeoVectorXYZ ): Funções como GeoGraphics permitem visualizar vetores geográficos discretos. O GeoStreamPlot é o análogo geográfico do StreamPlot (ou ListStreamPlot ) - e mostra linhas de fluxo formadas a partir de vetores geográficos (aqui da WindDirectionData ): A
Funções como GeoGraphics permitem visualizar vetores geográficos discretos. O GeoStreamPlot é o análogo geográfico do StreamPlot (ou ListStreamPlot ) - e mostra linhas de fluxo formadas a partir de vetores geográficos (aqui da WindDirectionData ): A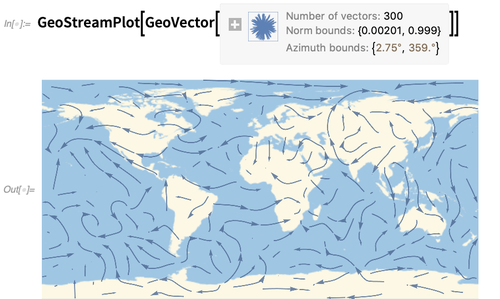 geodésia é uma área matematicamente sofisticada e nos orgulhamos de fazê-lo bem na Wolfram Language. Na versão 12.0, adicionamos algumas novas funções para preencher alguns detalhes. Por exemplo, agora temos funções como GeoGridUnitDistance e GeoGridUnitArea, que fornecem a distorção (basicamente, autovalores do jacobiano) associados a diferentes projeções geográficas em todas as posições da Terra (ou Lua, Marte, etc.).Uma direção de visualização que estamos desenvolvendo constantemente é o que poderíamos chamar de "meta-gráficos": a rotulagem e anotação de coisas gráficas. Introduzimos o Callout na versão 11.0; na versão 12.0, ela foi estendida a coisas como gráficos 3D:
geodésia é uma área matematicamente sofisticada e nos orgulhamos de fazê-lo bem na Wolfram Language. Na versão 12.0, adicionamos algumas novas funções para preencher alguns detalhes. Por exemplo, agora temos funções como GeoGridUnitDistance e GeoGridUnitArea, que fornecem a distorção (basicamente, autovalores do jacobiano) associados a diferentes projeções geográficas em todas as posições da Terra (ou Lua, Marte, etc.).Uma direção de visualização que estamos desenvolvendo constantemente é o que poderíamos chamar de "meta-gráficos": a rotulagem e anotação de coisas gráficas. Introduzimos o Callout na versão 11.0; na versão 12.0, ela foi estendida a coisas como gráficos 3D: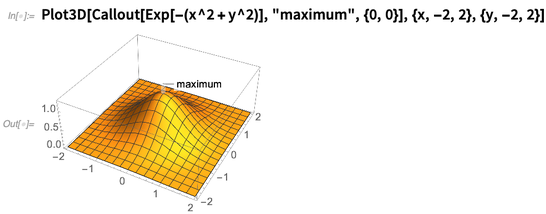 é muito bom descobrir onde rotular as coisas, mesmo quando elas ficam um pouco complexas:
é muito bom descobrir onde rotular as coisas, mesmo quando elas ficam um pouco complexas: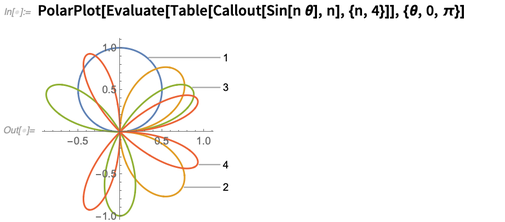 existem muitos detalhes importantes para fazer com que os gráficos realmente pareçam bons. Algo que foi aprimorado na Versão 12.0 é garantir que as colunas de gráficos se alinhem em seus quadros, independentemente do tamanho de seus rótulos de marca. Também adicionamos o LabelVisibility , que permite especificar as prioridades relativas com as quais os diferentes rótulos devem ficar visíveis.Outro novo recurso da Versão 12.0 é o layout de plotagem de vários painéis, onde diferentes conjuntos de dados são mostrados em painéis diferentes, mas os painéis compartilham eixos sempre que podem:
existem muitos detalhes importantes para fazer com que os gráficos realmente pareçam bons. Algo que foi aprimorado na Versão 12.0 é garantir que as colunas de gráficos se alinhem em seus quadros, independentemente do tamanho de seus rótulos de marca. Também adicionamos o LabelVisibility , que permite especificar as prioridades relativas com as quais os diferentes rótulos devem ficar visíveis.Outro novo recurso da Versão 12.0 é o layout de plotagem de vários painéis, onde diferentes conjuntos de dados são mostrados em painéis diferentes, mas os painéis compartilham eixos sempre que podem: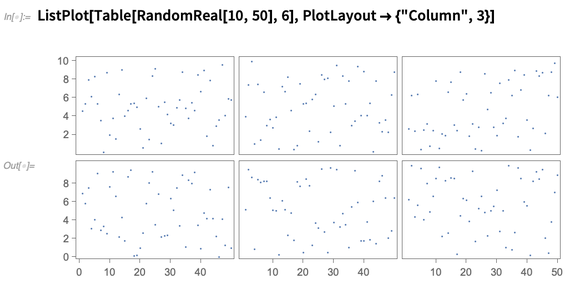
Apertando a integração da base de conhecimento
Nossa base de conhecimento com curadoria - que, por exemplo, alimenta o Wolfram | Alpha - é vasta e cresce continuamente. E com todas as versões da Wolfram Language, estamos progressivamente reforçando sua integração no núcleo da linguagem.Na versão 12.0, uma coisa que estamos fazendo é expor centenas de tipos de entidades diretamente no idioma: Antes da versão 12.0, as páginas Wolfram | Alpha Example serviam como proxy para documentar muitos tipos de entidades. Mas agora há documentação da Wolfram Language para todos eles:
Antes da versão 12.0, as páginas Wolfram | Alpha Example serviam como proxy para documentar muitos tipos de entidades. Mas agora há documentação da Wolfram Language para todos eles: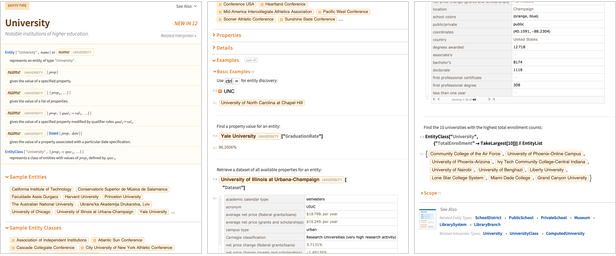 Ainda existem funções como SatelliteData , WeatherData e FinancialDataque lidam com tipos de entidade que rotineiramente precisam de seleção ou computação complexa. Porém, na versão 12.0, todo tipo de entidade pode ser acessado da mesma maneira, com entrada em linguagem natural ("controle + =") e entidades e propriedades "com caixa amarela":
Ainda existem funções como SatelliteData , WeatherData e FinancialDataque lidam com tipos de entidade que rotineiramente precisam de seleção ou computação complexa. Porém, na versão 12.0, todo tipo de entidade pode ser acessado da mesma maneira, com entrada em linguagem natural ("controle + =") e entidades e propriedades "com caixa amarela": A propósito, também é possível usar entidades implicitamente, como aqui pedindo os 5 elementos com os pontos de fusão mais altos conhecidos:
A propósito, também é possível usar entidades implicitamente, como aqui pedindo os 5 elementos com os pontos de fusão mais altos conhecidos: E pode-se usar Dated para obter uma série temporal de valores:
E pode-se usar Dated para obter uma série temporal de valores: Tornamos realmente conveniente trabalhar com dados incorporados à Base de Conhecimento Wolfram . Você tem entidades e é muito fácil perguntar sobre propriedades e assim por diante:
Tornamos realmente conveniente trabalhar com dados incorporados à Base de Conhecimento Wolfram . Você tem entidades e é muito fácil perguntar sobre propriedades e assim por diante: Mas e se você tiver seus próprios dados? Você pode configurá-lo para usá-lo tão facilmente quanto isso? Um novo recurso importante da Versão 11 foi a adição do EntityStore , na qual é possível definir os próprios tipos de entidade e especificar entidades, propriedades e valores.O Wolfram Data Repository contém vários exemplos de armazenamentos de entidades . Aqui está um:
Mas e se você tiver seus próprios dados? Você pode configurá-lo para usá-lo tão facilmente quanto isso? Um novo recurso importante da Versão 11 foi a adição do EntityStore , na qual é possível definir os próprios tipos de entidade e especificar entidades, propriedades e valores.O Wolfram Data Repository contém vários exemplos de armazenamentos de entidades . Aqui está um: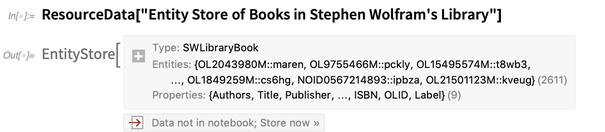 descreve um único tipo de entidade: um "SWLibraryBook" . Para poder usar entidades desse tipo, assim como as entidades internas , “registramos” o armazenamento de entidades:
descreve um único tipo de entidade: um "SWLibraryBook" . Para poder usar entidades desse tipo, assim como as entidades internas , “registramos” o armazenamento de entidades: Agora, podemos fazer coisas como solicitar 10 entidades aleatórias do tipo "SWLibraryBook" :
Agora, podemos fazer coisas como solicitar 10 entidades aleatórias do tipo "SWLibraryBook" : cada entidade no armazenamento de entidades tem uma variedade de propriedades. Aqui está um conjunto de dados dos valores das propriedades para uma entidade específica:
cada entidade no armazenamento de entidades tem uma variedade de propriedades. Aqui está um conjunto de dados dos valores das propriedades para uma entidade específica: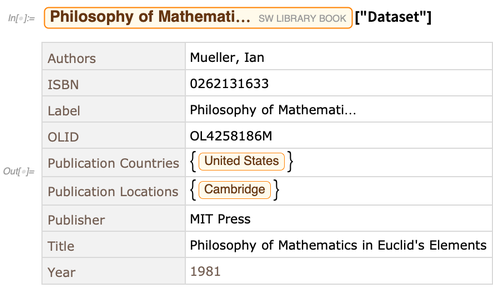 OK, mas com essa configuração, estamos basicamente lendo todo o conteúdo de um armazenamento de entidade na memória. Isso torna muito eficiente fazer qualquer operação que a Wolfram Language deseje. Mas não é uma boa solução escalável para grandes quantidades de dados - por exemplo, dados grandes demais para caber na memória.Mas o que é uma fonte típica de dados grandes? Muitas vezes, é um banco de dados, e geralmente um relacional que pode ser acessado usando SQL . Temos nosso pacote DatabaseLink para acesso de leitura e gravação de baixo nível aos bancos de dados SQL há mais de uma década. Porém, na Versão 12.0, estamos adicionando alguns dos principais recursos internos que permitem que bancos de dados relacionais externos sejam manipulados na Wolfram Language, assim como lojas de entidades ou partes internas da Wolfram Knowledgebase.Vamos começar com um exemplo de brinquedo. Aqui está uma representação simbólica de um pequeno banco de dados relacional que por acaso é armazenado em um arquivo:
OK, mas com essa configuração, estamos basicamente lendo todo o conteúdo de um armazenamento de entidade na memória. Isso torna muito eficiente fazer qualquer operação que a Wolfram Language deseje. Mas não é uma boa solução escalável para grandes quantidades de dados - por exemplo, dados grandes demais para caber na memória.Mas o que é uma fonte típica de dados grandes? Muitas vezes, é um banco de dados, e geralmente um relacional que pode ser acessado usando SQL . Temos nosso pacote DatabaseLink para acesso de leitura e gravação de baixo nível aos bancos de dados SQL há mais de uma década. Porém, na Versão 12.0, estamos adicionando alguns dos principais recursos internos que permitem que bancos de dados relacionais externos sejam manipulados na Wolfram Language, assim como lojas de entidades ou partes internas da Wolfram Knowledgebase.Vamos começar com um exemplo de brinquedo. Aqui está uma representação simbólica de um pequeno banco de dados relacional que por acaso é armazenado em um arquivo: Imediatamente obtemos uma caixa que resume o que há no banco de dados e nos diz que esse banco de dados possui 8 tabelas. Se abrirmos a caixa, poderemos começar a inspecionar a estrutura dessas tabelas:
Imediatamente obtemos uma caixa que resume o que há no banco de dados e nos diz que esse banco de dados possui 8 tabelas. Se abrirmos a caixa, poderemos começar a inspecionar a estrutura dessas tabelas: Podemos então configurar esse banco de dados relacional como um armazenamento de entidade no Wolfram Language. Parece muito com o armazenamento de entidade do livro da biblioteca acima, mas agora os dados reais não são extraídos para a memória; em vez disso, ele ainda está no banco de dados relacional externo e estamos apenas definindo um mapeamento ("semelhante ao ORM") para entidades na Wolfram Language:
Podemos então configurar esse banco de dados relacional como um armazenamento de entidade no Wolfram Language. Parece muito com o armazenamento de entidade do livro da biblioteca acima, mas agora os dados reais não são extraídos para a memória; em vez disso, ele ainda está no banco de dados relacional externo e estamos apenas definindo um mapeamento ("semelhante ao ORM") para entidades na Wolfram Language: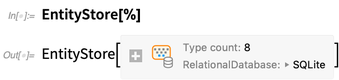 Agora podemos registrar esse armazenamento de entidades, que configura vários tipos de entidades que (pelo menos por padrão) são nomeados após os nomes das tabelas no banco de dados:
Agora podemos registrar esse armazenamento de entidades, que configura vários tipos de entidades que (pelo menos por padrão) são nomeados após os nomes das tabelas no banco de dados: E agora podemos fazer “cálculos de entidades” sobre eles, assim como nós. seria em entidades internas da Wolfram Knowledgebase. Cada entidade aqui corresponde a uma linha na tabela "funcionários" no banco de dados:
E agora podemos fazer “cálculos de entidades” sobre eles, assim como nós. seria em entidades internas da Wolfram Knowledgebase. Cada entidade aqui corresponde a uma linha na tabela "funcionários" no banco de dados: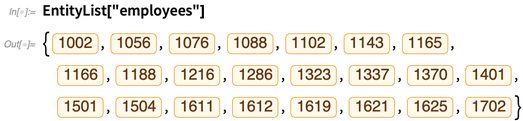 Para um determinado tipo de entidade, podemos perguntar quais propriedades ela possui. Essas “propriedades” correspondem às colunas da tabela no banco de dados subjacente:
Para um determinado tipo de entidade, podemos perguntar quais propriedades ela possui. Essas “propriedades” correspondem às colunas da tabela no banco de dados subjacente: Agora podemos solicitar o valor de uma propriedade específica de uma entidade específica:
Agora podemos solicitar o valor de uma propriedade específica de uma entidade específica: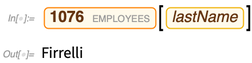 Também podemos selecionar entidades fornecendo critérios; aqui solicitamos entidades de "pagamentos" com os 4 maiores valores da propriedade "quantidade":
Também podemos selecionar entidades fornecendo critérios; aqui solicitamos entidades de "pagamentos" com os 4 maiores valores da propriedade "quantidade": Podemos igualmente pedir os valores desses maiores valores:
Podemos igualmente pedir os valores desses maiores valores: OK, mas é aqui que fica mais interessante: até agora, examinamos um pequeno banco de dados com backup de arquivos. Mas podemos fazer exatamente a mesma coisa com um banco de dados gigante hospedado em um servidor externo.Como exemplo, vamos nos conectar ao banco de dados OpenStreetMap PostgreSQL do tamanho de um terabyte que contém basicamente o mapa de ruas do mundo:
OK, mas é aqui que fica mais interessante: até agora, examinamos um pequeno banco de dados com backup de arquivos. Mas podemos fazer exatamente a mesma coisa com um banco de dados gigante hospedado em um servidor externo.Como exemplo, vamos nos conectar ao banco de dados OpenStreetMap PostgreSQL do tamanho de um terabyte que contém basicamente o mapa de ruas do mundo: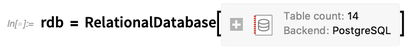 Como antes, vamos registrar as tabelas neste banco de dados como tipos de entidade. Como a maioria dos bancos de dados comuns, existem poucas falhas na estrutura, que são contornadas, mas geram avisos:
Como antes, vamos registrar as tabelas neste banco de dados como tipos de entidade. Como a maioria dos bancos de dados comuns, existem poucas falhas na estrutura, que são contornadas, mas geram avisos: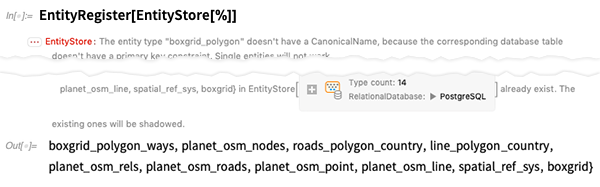 Mas agora podemos fazer perguntas sobre o banco de dados - como quantos pontos geográficos ou nós existem em todas as ruas do mundo (e, sim, é um grande número, e é por isso que o banco de dados é grande):
Mas agora podemos fazer perguntas sobre o banco de dados - como quantos pontos geográficos ou nós existem em todas as ruas do mundo (e, sim, é um grande número, e é por isso que o banco de dados é grande): aqui estamos solicitando os nomes dos objetos com as 10 maiores áreas (projetadas) da tabela planet_osm_polygon (101 GB) ( e, sim, leva menos de um segundo):
aqui estamos solicitando os nomes dos objetos com as 10 maiores áreas (projetadas) da tabela planet_osm_polygon (101 GB) ( e, sim, leva menos de um segundo): Então, como tudo isso funciona? Basicamente, o que está acontecendo é que nossa representação da Wolfram Language está sendo compilada em consultas SQL de baixo nível que são enviadas para serem executadas diretamente no servidor de banco de dados.Às vezes, você solicita resultados que são apenas valores finais (como, por exemplo, os "valores" acima). Mas em outros casos, você desejará algo intermediário - como uma coleção de entidades que foram selecionadas de uma maneira específica. E é claro que essa coleção pode ter um bilhão de entradas. Portanto, um recurso muito importante do que estamos apresentando na Versão 12.0 é que podemos representar e manipular essas coisas puramente simbolicamente, resolvendo-as para algo específico apenas no final.Voltando ao nosso banco de dados de brinquedos, aqui está um exemplo de como especificaríamos uma classe de entidades obtida agregando o limite de crédito total para todos os clientes com um determinado valor de país :
Então, como tudo isso funciona? Basicamente, o que está acontecendo é que nossa representação da Wolfram Language está sendo compilada em consultas SQL de baixo nível que são enviadas para serem executadas diretamente no servidor de banco de dados.Às vezes, você solicita resultados que são apenas valores finais (como, por exemplo, os "valores" acima). Mas em outros casos, você desejará algo intermediário - como uma coleção de entidades que foram selecionadas de uma maneira específica. E é claro que essa coleção pode ter um bilhão de entradas. Portanto, um recurso muito importante do que estamos apresentando na Versão 12.0 é que podemos representar e manipular essas coisas puramente simbolicamente, resolvendo-as para algo específico apenas no final.Voltando ao nosso banco de dados de brinquedos, aqui está um exemplo de como especificaríamos uma classe de entidades obtida agregando o limite de crédito total para todos os clientes com um determinado valor de país : No início, isso é apenas algo simbólico. Porém, se solicitarmos valores específicos, as consultas reais ao banco de dados serão feitas e obteremos resultados específicos:
No início, isso é apenas algo simbólico. Porém, se solicitarmos valores específicos, as consultas reais ao banco de dados serão feitas e obteremos resultados específicos: existe uma família de novas funções para configurar diferentes tipos de consultas. E as funções realmente funcionam não apenas para bancos de dados relacionais, mas também para armazenamentos de entidades e para a Base de Conhecimento Wolfram integrada. Assim, por exemplo, podemos pedir a massa atômica média para um determinado período na tabela periódica de elementos :
existe uma família de novas funções para configurar diferentes tipos de consultas. E as funções realmente funcionam não apenas para bancos de dados relacionais, mas também para armazenamentos de entidades e para a Base de Conhecimento Wolfram integrada. Assim, por exemplo, podemos pedir a massa atômica média para um determinado período na tabela periódica de elementos : Uma nova construção importante éEntityFunction . EntityFunction é como Function , exceto que suas variáveis representam entidades (ou classes de entidades) e descreve operações que podem ser executadas diretamente em bancos de dados externos. Aqui está um exemplo com dados internos, nos quais definimos uma classe de entidade "filtrada" na qual o critério de filtragem é uma função que testa os valores da população. O próprio FilteredEntityClass é representado apenas simbolicamente, mas o EntityList realmente executa a consulta e resolve uma lista explícita de entidades (aqui, não classificadas):
Uma nova construção importante éEntityFunction . EntityFunction é como Function , exceto que suas variáveis representam entidades (ou classes de entidades) e descreve operações que podem ser executadas diretamente em bancos de dados externos. Aqui está um exemplo com dados internos, nos quais definimos uma classe de entidade "filtrada" na qual o critério de filtragem é uma função que testa os valores da população. O próprio FilteredEntityClass é representado apenas simbolicamente, mas o EntityList realmente executa a consulta e resolve uma lista explícita de entidades (aqui, não classificadas):
 Além de EntityFunction , AggregatedEntityClass e SortedEntityClass , a Versão 12.0 inclui SampledEntityClass (para obter algumas entidades de uma classe), ExtendedEntityClass (para adicionar propriedades computadas) e CombinedEntityClass (para combinar propriedades de diferentes classes). Com essas primitivas, pode-se construir todas as operações padrão da " álgebra relacional ".Na programação de banco de dados padrão, normalmente se termina com uma selva inteira de "junções" e "chaves estrangeiras" e assim por diante. Nossa representação da Wolfram Language permite operar em um nível mais alto - onde basicamente as junções se tornam composição de funções e chaves estrangeiras são apenas tipos de entidade diferentes. (Se você deseja fazer associações explícitas, pode, por exemplo, usar CombinedEntityClass .)O que está acontecendo sob o capô é que todas essas construções da Wolfram Language estão sendo compiladas no SQL, ou, mais precisamente, o dialeto específico do SQL que é adequado para o banco de dados específico que você está usando (atualmente suportamos SQLite , MySQL , PostgreSQL e MS -SQL , com suporte para OracleSQL em breve). Quando fazemos a compilação, estamos verificando automaticamente os tipos, para garantir uma consulta significativa. Mesmo especificações bastante simples da Wolfram Language podem acabar se transformando em muitas linhas de SQL. Por exemplo,
Além de EntityFunction , AggregatedEntityClass e SortedEntityClass , a Versão 12.0 inclui SampledEntityClass (para obter algumas entidades de uma classe), ExtendedEntityClass (para adicionar propriedades computadas) e CombinedEntityClass (para combinar propriedades de diferentes classes). Com essas primitivas, pode-se construir todas as operações padrão da " álgebra relacional ".Na programação de banco de dados padrão, normalmente se termina com uma selva inteira de "junções" e "chaves estrangeiras" e assim por diante. Nossa representação da Wolfram Language permite operar em um nível mais alto - onde basicamente as junções se tornam composição de funções e chaves estrangeiras são apenas tipos de entidade diferentes. (Se você deseja fazer associações explícitas, pode, por exemplo, usar CombinedEntityClass .)O que está acontecendo sob o capô é que todas essas construções da Wolfram Language estão sendo compiladas no SQL, ou, mais precisamente, o dialeto específico do SQL que é adequado para o banco de dados específico que você está usando (atualmente suportamos SQLite , MySQL , PostgreSQL e MS -SQL , com suporte para OracleSQL em breve). Quando fazemos a compilação, estamos verificando automaticamente os tipos, para garantir uma consulta significativa. Mesmo especificações bastante simples da Wolfram Language podem acabar se transformando em muitas linhas de SQL. Por exemplo, produziria o seguinte SQL intermediário (aqui para consultar o banco de dados SQLite):
produziria o seguinte SQL intermediário (aqui para consultar o banco de dados SQLite): O sistema de integração de banco de dados que temos na versão 12.0 é bastante sofisticado - e estamos trabalhando nele há alguns anos. É um passo importante para permitir que a Wolfram Language lide diretamente com um novo nível de "grandeza" em big data - e permita que a Wolfram Language faça ciência de dados diretamente em conjuntos de dados do tamanho de terabytes e além. Como descobrir quais entidades semelhantes a ruas no mundo têm "Wolfram" em seu nome:
O sistema de integração de banco de dados que temos na versão 12.0 é bastante sofisticado - e estamos trabalhando nele há alguns anos. É um passo importante para permitir que a Wolfram Language lide diretamente com um novo nível de "grandeza" em big data - e permita que a Wolfram Language faça ciência de dados diretamente em conjuntos de dados do tamanho de terabytes e além. Como descobrir quais entidades semelhantes a ruas no mundo têm "Wolfram" em seu nome: Qual é a melhor maneira de representar o conhecimento sobre o mundo? É uma questão que tem sido debatida por filósofos (e outros) desde a antiguidade. Às vezes, as pessoas diziam que a lógica era a chave. Às vezes matemática. Às vezes, bancos de dados relacionais. Mas agora sabemos pelo menos uma base sólida (ou pelo menos, tenho certeza de que sabemos): tudo pode ser representado pela computação. Essa é uma idéia poderosa - e, em certo sentido, é isso que torna possível tudo o que fazemos com a Wolfram Language.Mas existem subconjuntos de computação geral que são úteis para representar pelo menos certos tipos de conhecimento? Um que usamos amplamente na Base de Conhecimento Wolframé a noção de entidades ("Nova York"), propriedades ("população") e seus valores ("8,6 milhões de pessoas"). É claro que esses triplos não representam todo o conhecimento do mundo ("qual será a posição de Marte amanhã?"). Mas eles são um começo decente quando se trata de certos tipos de conhecimento "estático" sobre coisas distintas.Então, como se pode formalizar esse tipo de representação do conhecimento? Uma resposta é através de bancos de dados gráficos. E na versão 12.0 - alinhada com muitos projetos de "web semântica" - oferecemos suporte a bancos de dados de gráficos usando RDF e consultas a eles usando SPARQL . No RDF, o objeto central é um IRI ("Internationalized Resource Identifier"), que pode representar uma entidade ou uma propriedade. Um " triplestore " consiste então em uma coleção de triplos ("sujeito", "predicado", "objeto"), com cada elemento em cada triplo sendo um IRI (ou um literal, como um número). Todo o objeto pode ser pensado como um banco de dados ou armazenamento de gráficos, ou, matematicamente, um hipergrafo. (É umhipergrafo porque o predicado "bordas" também pode ser vértices em outro lugar.)Você pode construir seu próprio RDFStore assim como você construir uma EntityStore -e na verdade, você pode consultar qualquer Wolfram Idioma EntityStore usando SPARQL como você consultar um RDFStore . E como a parte da entidade-propriedade da Wolfram Knowledgebase pode ser tratada como um armazenamento de entidade, você também pode consultar isso. Então, aqui, finalmente, é um exemplo. A lista país-cidade Entidade [" País "], Entidade [" Cidade "]} em vigor representa um armazenamento RDF. Então SPARQLSelecté um operador que atua nesta loja. O que ele faz é tentar encontrar um triplo que corresponda ao que você está solicitando, com um valor específico para a "variável SPARQL" x:
Qual é a melhor maneira de representar o conhecimento sobre o mundo? É uma questão que tem sido debatida por filósofos (e outros) desde a antiguidade. Às vezes, as pessoas diziam que a lógica era a chave. Às vezes matemática. Às vezes, bancos de dados relacionais. Mas agora sabemos pelo menos uma base sólida (ou pelo menos, tenho certeza de que sabemos): tudo pode ser representado pela computação. Essa é uma idéia poderosa - e, em certo sentido, é isso que torna possível tudo o que fazemos com a Wolfram Language.Mas existem subconjuntos de computação geral que são úteis para representar pelo menos certos tipos de conhecimento? Um que usamos amplamente na Base de Conhecimento Wolframé a noção de entidades ("Nova York"), propriedades ("população") e seus valores ("8,6 milhões de pessoas"). É claro que esses triplos não representam todo o conhecimento do mundo ("qual será a posição de Marte amanhã?"). Mas eles são um começo decente quando se trata de certos tipos de conhecimento "estático" sobre coisas distintas.Então, como se pode formalizar esse tipo de representação do conhecimento? Uma resposta é através de bancos de dados gráficos. E na versão 12.0 - alinhada com muitos projetos de "web semântica" - oferecemos suporte a bancos de dados de gráficos usando RDF e consultas a eles usando SPARQL . No RDF, o objeto central é um IRI ("Internationalized Resource Identifier"), que pode representar uma entidade ou uma propriedade. Um " triplestore " consiste então em uma coleção de triplos ("sujeito", "predicado", "objeto"), com cada elemento em cada triplo sendo um IRI (ou um literal, como um número). Todo o objeto pode ser pensado como um banco de dados ou armazenamento de gráficos, ou, matematicamente, um hipergrafo. (É umhipergrafo porque o predicado "bordas" também pode ser vértices em outro lugar.)Você pode construir seu próprio RDFStore assim como você construir uma EntityStore -e na verdade, você pode consultar qualquer Wolfram Idioma EntityStore usando SPARQL como você consultar um RDFStore . E como a parte da entidade-propriedade da Wolfram Knowledgebase pode ser tratada como um armazenamento de entidade, você também pode consultar isso. Então, aqui, finalmente, é um exemplo. A lista país-cidade Entidade [" País "], Entidade [" Cidade "]} em vigor representa um armazenamento RDF. Então SPARQLSelecté um operador que atua nesta loja. O que ele faz é tentar encontrar um triplo que corresponda ao que você está solicitando, com um valor específico para a "variável SPARQL" x: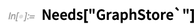
 Claro, também há uma maneira muito mais simples de fazer isso na linguagem Wolfram:
Claro, também há uma maneira muito mais simples de fazer isso na linguagem Wolfram: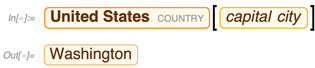 Mas com o SPARQL, você pode fazer coisas muito mais exóticas - como perguntar quais propriedades relacionam os EUA ao México:
Mas com o SPARQL, você pode fazer coisas muito mais exóticas - como perguntar quais propriedades relacionam os EUA ao México: ou se existe um caminho baseado na relação entre países vizinhos de Portugal para a Alemanha:
ou se existe um caminho baseado na relação entre países vizinhos de Portugal para a Alemanha: Em princípio, você pode simplesmente escrever uma consulta SPARQL como uma string (um pouco como você pode escrever uma string SQL). Mas o que fizemos na versão 12.0 é introduzir uma representação simbólica do SPARQL que permite o cálculo da própria representação, facilitando, por exemplo, a geração automática de consultas complexas ao SPARQL. (E é particularmente importante fazer isso porque, por si só, as consultas práticas do SPARQL têm o hábito de ficar extremamente longas e ponderadas.)OK, mas existem lojas de RDF na natureza? Tem sido uma esperança de longo prazo que uma grande parte da web seja, de alguma forma, marcada o suficiente para "se tornar semântica" e, na verdade, ser uma loja gigante de RDF. Seria ótimo se isso acontecesse, mas até agora definitivamente não aconteceu. Ainda assim, existem algumas lojas RDF públicas por aí, e também algumas lojas RDF nas organizações, e com nossos novos recursos na Versão 12.0, estamos em uma posição única para fazer coisas interessantes com elas.Uma forma incrivelmente comum de problema em aplicações industriais da matemática é: "Que configuração minimiza o custo (ou maximiza o retorno) se certas restrições precisam ser satisfeitas?" Mais de meio século atrás, o chamado algoritmo simplex foi inventado para resolver versões lineares desse tipo de problema, nas quais tanto a função objetivo (custo, recompensa) quanto as restrições são funções lineares das variáveis do problema. Na década de 1980, métodos muito mais eficientes ("ponto interior") foram inventados - e já os tínhamos para fazer " programação linear " na Wolfram Language por um longo tempo.Mas e os problemas não lineares? Bem, no caso geral, pode-se usar funções como NMinimize. E eles fazem um trabalho de ponta. Mas é um problema difícil. No entanto, há alguns anos, ficou claro que, mesmo entre os problemas de otimização não linear, existe uma classe dos chamados problemas de otimização convexa que podem ser resolvidos de maneira quase tão eficiente quanto os lineares. ("Convexo" significa que tanto o objetivo quanto as restrições envolvem apenas funções convexas - para que nada possa "mexer" quando alguém se aproxima de um extremo e não pode haver mínimos locais que não sejam mínimos globais.)Na versão 12.0 , agora temos implementações fortes para todas as várias classes padrão de otimização convexa. Aqui está um caso simples, envolvendo a minimização de uma forma quadrática com algumas restrições lineares:
Em princípio, você pode simplesmente escrever uma consulta SPARQL como uma string (um pouco como você pode escrever uma string SQL). Mas o que fizemos na versão 12.0 é introduzir uma representação simbólica do SPARQL que permite o cálculo da própria representação, facilitando, por exemplo, a geração automática de consultas complexas ao SPARQL. (E é particularmente importante fazer isso porque, por si só, as consultas práticas do SPARQL têm o hábito de ficar extremamente longas e ponderadas.)OK, mas existem lojas de RDF na natureza? Tem sido uma esperança de longo prazo que uma grande parte da web seja, de alguma forma, marcada o suficiente para "se tornar semântica" e, na verdade, ser uma loja gigante de RDF. Seria ótimo se isso acontecesse, mas até agora definitivamente não aconteceu. Ainda assim, existem algumas lojas RDF públicas por aí, e também algumas lojas RDF nas organizações, e com nossos novos recursos na Versão 12.0, estamos em uma posição única para fazer coisas interessantes com elas.Uma forma incrivelmente comum de problema em aplicações industriais da matemática é: "Que configuração minimiza o custo (ou maximiza o retorno) se certas restrições precisam ser satisfeitas?" Mais de meio século atrás, o chamado algoritmo simplex foi inventado para resolver versões lineares desse tipo de problema, nas quais tanto a função objetivo (custo, recompensa) quanto as restrições são funções lineares das variáveis do problema. Na década de 1980, métodos muito mais eficientes ("ponto interior") foram inventados - e já os tínhamos para fazer " programação linear " na Wolfram Language por um longo tempo.Mas e os problemas não lineares? Bem, no caso geral, pode-se usar funções como NMinimize. E eles fazem um trabalho de ponta. Mas é um problema difícil. No entanto, há alguns anos, ficou claro que, mesmo entre os problemas de otimização não linear, existe uma classe dos chamados problemas de otimização convexa que podem ser resolvidos de maneira quase tão eficiente quanto os lineares. ("Convexo" significa que tanto o objetivo quanto as restrições envolvem apenas funções convexas - para que nada possa "mexer" quando alguém se aproxima de um extremo e não pode haver mínimos locais que não sejam mínimos globais.)Na versão 12.0 , agora temos implementações fortes para todas as várias classes padrão de otimização convexa. Aqui está um caso simples, envolvendo a minimização de uma forma quadrática com algumas restrições lineares: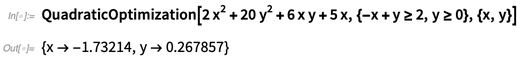 NMinimizejá poderia fazer esse problema específico na versão 11.3:
NMinimizejá poderia fazer esse problema específico na versão 11.3: Mas se alguém tivesse mais variáveis, o antigo NMinimize rapidamente se atolaria . Na versão 12.0, no entanto, a Otimização quadrática continuará funcionando bem, até mais de 100.000 variáveis com mais de 100.000 restrições (desde que sejam razoavelmente escassas).Na versão 12.0, temos funções de "otimização convexa bruta" como SemidefiniteOptimization (que lida com desigualdades de matriz linear) e ConicOptimization (que lida com desigualdades de vetores lineares). Mas funções como NMinimize e FindMinimumtambém reconhecerá automaticamente quando um problema pode ser resolvido com eficiência, sendo transformado em um formulário de otimização convexo.Como alguém configura problemas de otimização convexos? Os maiores envolvem restrições em vetores inteiros ou matrizes de variáveis. E na versão 12.0, agora temos funções como VectorGeavyEqual (entrada como ≥) que podem representá-las imediatamente.As equações diferenciais parciais são difíceis, e estamos trabalhando em maneiras mais e mais sofisticadas e gerais de lidar com elas há 30 anos. Introduzimos o NDSolve (para ODEs) pela primeira vez na versão 2, em 1991 . Tivemos nossos primeiros PDEs numéricos (1 + 1-dimensionais) em meados dos anos 90. Em 2003, introduzimos nossa poderosa estrutura modular para lidar com equações diferenciais numéricas. Mas em termos de PDEs, ainda estávamos basicamente lidando apenas com regiões retangulares simples. Para ir além do necessário, construímos todo o sistema de geometria computacional , que introduzimos na versão 10. E com isso, lançamos nosso primeiro solucionador de elementos finitos PDE . Na versão 11, generalizamos para problemas próprios .Agora, na versão 12, estamos introduzindo outra grande generalização: análise de elementos finitos não lineares. A análise de elementos finitos envolve a decomposição de regiões em pequenos triângulos discretos, tetraedros etc. - nas quais o PDE original pode ser aproximado por um grande número de equações acopladas. Quando o PDE original é linear, essas equações também serão lineares - e esse é o caso típico que as pessoas consideram quando falam sobre "análise de elementos finitos".Mas existem muitos PDEs de importância prática que não são lineares - e para enfrentá-los é necessário uma análise não linear de elementos finitos, que é o que temos agora na Versão 12.0.Como exemplo, eis o que é necessário para resolver o PDE desagradável não linear que descreve a altura de uma superfície mínima 2D (por exemplo, um filme de sabão idealizado), aqui sobre um espaço anular, com condições de contorno (Dirichlet) que o fazem se mover sinusoidalmente na bordas (como se o filme de sabão estivesse suspenso nos fios):
Mas se alguém tivesse mais variáveis, o antigo NMinimize rapidamente se atolaria . Na versão 12.0, no entanto, a Otimização quadrática continuará funcionando bem, até mais de 100.000 variáveis com mais de 100.000 restrições (desde que sejam razoavelmente escassas).Na versão 12.0, temos funções de "otimização convexa bruta" como SemidefiniteOptimization (que lida com desigualdades de matriz linear) e ConicOptimization (que lida com desigualdades de vetores lineares). Mas funções como NMinimize e FindMinimumtambém reconhecerá automaticamente quando um problema pode ser resolvido com eficiência, sendo transformado em um formulário de otimização convexo.Como alguém configura problemas de otimização convexos? Os maiores envolvem restrições em vetores inteiros ou matrizes de variáveis. E na versão 12.0, agora temos funções como VectorGeavyEqual (entrada como ≥) que podem representá-las imediatamente.As equações diferenciais parciais são difíceis, e estamos trabalhando em maneiras mais e mais sofisticadas e gerais de lidar com elas há 30 anos. Introduzimos o NDSolve (para ODEs) pela primeira vez na versão 2, em 1991 . Tivemos nossos primeiros PDEs numéricos (1 + 1-dimensionais) em meados dos anos 90. Em 2003, introduzimos nossa poderosa estrutura modular para lidar com equações diferenciais numéricas. Mas em termos de PDEs, ainda estávamos basicamente lidando apenas com regiões retangulares simples. Para ir além do necessário, construímos todo o sistema de geometria computacional , que introduzimos na versão 10. E com isso, lançamos nosso primeiro solucionador de elementos finitos PDE . Na versão 11, generalizamos para problemas próprios .Agora, na versão 12, estamos introduzindo outra grande generalização: análise de elementos finitos não lineares. A análise de elementos finitos envolve a decomposição de regiões em pequenos triângulos discretos, tetraedros etc. - nas quais o PDE original pode ser aproximado por um grande número de equações acopladas. Quando o PDE original é linear, essas equações também serão lineares - e esse é o caso típico que as pessoas consideram quando falam sobre "análise de elementos finitos".Mas existem muitos PDEs de importância prática que não são lineares - e para enfrentá-los é necessário uma análise não linear de elementos finitos, que é o que temos agora na Versão 12.0.Como exemplo, eis o que é necessário para resolver o PDE desagradável não linear que descreve a altura de uma superfície mínima 2D (por exemplo, um filme de sabão idealizado), aqui sobre um espaço anular, com condições de contorno (Dirichlet) que o fazem se mover sinusoidalmente na bordas (como se o filme de sabão estivesse suspenso nos fios):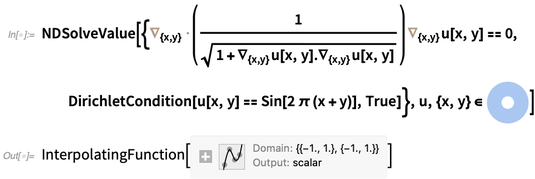 No meu computador, são necessários apenas um quarto de segundo para resolver essa equação e obter uma função de interpolação. Aqui está um gráfico da função de interpolação que representa a solução:
No meu computador, são necessários apenas um quarto de segundo para resolver essa equação e obter uma função de interpolação. Aqui está um gráfico da função de interpolação que representa a solução: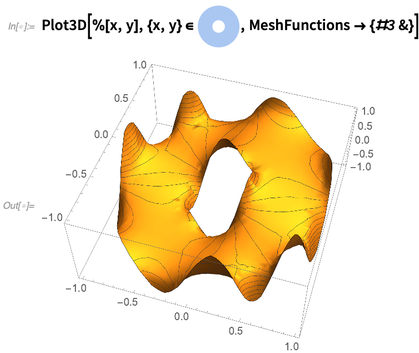 Dedicamos muita engenharia à otimização da execução dos programas da Wolfram Language ao longo dos anos. Já em 1989, começamos a compilar automaticamente cálculos numéricos de precisão de máquina simples com instruções para uma máquina virtual eficiente (e, por acaso, escrevi o código original para isso). Ao longo dos anos, estendemos os recursos desse compilador, mas ele sempre foi limitado a programas bastante simples.Na versão 12.0, estamos dando um grande passo adiante e lançamos a primeira versão de um novo compilador muito mais poderoso em que trabalhamos há vários anos. Esse compilador é capaz de lidar com uma gama muito mais ampla de programas (incluindo construções funcionais complexas e fluxos de controle elaborados) e também está compilando não em uma máquina virtual, mas diretamente no código de máquina nativo otimizado.Na versão 12.0, ainda consideramos o novo compilador experimental. Mas está avançando rapidamente e terá um efeito dramático na eficiência de muitas coisas na Wolfram Language. Na versão 12.0, estamos apenas expondo um "formulário de kit" do novo compilador, com funções de compilação específicas. Mas progressivamente faremos com que o compilador opere cada vez mais automaticamente - descobrindo com o aprendizado de máquina e outros métodos quando vale a pena dedicar algum tempo para fazer o nível de compilação.Em nível técnico, o novo compilador da Versão 12.0 é baseado no LLVM e funciona gerando código LLVM - vinculando na mesma biblioteca de tempo de execução de baixo nível que o próprio kernel da Wolfram Language usa e retornando ao kernel da Wolfram Language completo para funcionalidade que não está na biblioteca de tempo de execução.Aqui está a maneira básica de compilar uma função pura na versão atual do novo compilador:
Dedicamos muita engenharia à otimização da execução dos programas da Wolfram Language ao longo dos anos. Já em 1989, começamos a compilar automaticamente cálculos numéricos de precisão de máquina simples com instruções para uma máquina virtual eficiente (e, por acaso, escrevi o código original para isso). Ao longo dos anos, estendemos os recursos desse compilador, mas ele sempre foi limitado a programas bastante simples.Na versão 12.0, estamos dando um grande passo adiante e lançamos a primeira versão de um novo compilador muito mais poderoso em que trabalhamos há vários anos. Esse compilador é capaz de lidar com uma gama muito mais ampla de programas (incluindo construções funcionais complexas e fluxos de controle elaborados) e também está compilando não em uma máquina virtual, mas diretamente no código de máquina nativo otimizado.Na versão 12.0, ainda consideramos o novo compilador experimental. Mas está avançando rapidamente e terá um efeito dramático na eficiência de muitas coisas na Wolfram Language. Na versão 12.0, estamos apenas expondo um "formulário de kit" do novo compilador, com funções de compilação específicas. Mas progressivamente faremos com que o compilador opere cada vez mais automaticamente - descobrindo com o aprendizado de máquina e outros métodos quando vale a pena dedicar algum tempo para fazer o nível de compilação.Em nível técnico, o novo compilador da Versão 12.0 é baseado no LLVM e funciona gerando código LLVM - vinculando na mesma biblioteca de tempo de execução de baixo nível que o próprio kernel da Wolfram Language usa e retornando ao kernel da Wolfram Language completo para funcionalidade que não está na biblioteca de tempo de execução.Aqui está a maneira básica de compilar uma função pura na versão atual do novo compilador: A função de código compilado resultante funciona exatamente como a função original, embora mais rápida:
A função de código compilado resultante funciona exatamente como a função original, embora mais rápida: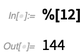 uma grande parte do que permite que o FunctionCompile produza uma função mais rápida é o que você está dizendo para fazer suposições sobre o tipo de argumento que obterá. Apoiamos muitos tipos básicos (como " Integer32 " e " Real64"). Mas quando você usa o FunctionCompile , está comprometendo-se com tipos de argumentos específicos, muito mais código simplificado pode ser produzido.Muita sofisticação do novo compilador está associada à dedução de quais tipos de dados serão gerados na execução (Existem muitos algoritmos teóricos e outros algoritmos envolvidos, e nem é preciso dizer, toda a metaprogramação para o compilador é feita com a Wolfram Language.)Aqui está um exemplo que envolve um pouco de inferência de tipo (o tipo de fib é deduzido como sendo “Inteiro64” -> “Inteiro64” : uma função inteira retornando um inteiro):
uma grande parte do que permite que o FunctionCompile produza uma função mais rápida é o que você está dizendo para fazer suposições sobre o tipo de argumento que obterá. Apoiamos muitos tipos básicos (como " Integer32 " e " Real64"). Mas quando você usa o FunctionCompile , está comprometendo-se com tipos de argumentos específicos, muito mais código simplificado pode ser produzido.Muita sofisticação do novo compilador está associada à dedução de quais tipos de dados serão gerados na execução (Existem muitos algoritmos teóricos e outros algoritmos envolvidos, e nem é preciso dizer, toda a metaprogramação para o compilador é feita com a Wolfram Language.)Aqui está um exemplo que envolve um pouco de inferência de tipo (o tipo de fib é deduzido como sendo “Inteiro64” -> “Inteiro64” : uma função inteira retornando um inteiro): No meu computador, o cf [25] roda cerca de 300 vezes mais rápido que a função não compilada. (Obviamente, a versão compilada falha quando sua saída não é mais do tipo " Integer64 ", mas a versão padrão da Wolfram Language continua funcionando perfeitamente.)O compilador já pode lidar com centenas de primitivas de programação da Wolfram Language, rastreando adequadamente quais tipos são produzido - e gerando código que implementa diretamente essas primitivas. Às vezes, no entanto, alguém desejará usar funções sofisticadas na Wolfram Language para as quais não faz sentido gerar seu próprio código compilado - e onde o que realmente queremos fazer é chamar o kernel da Wolfram Language para essas funções. . Na versão 12.0, o KernelFunction permite:
No meu computador, o cf [25] roda cerca de 300 vezes mais rápido que a função não compilada. (Obviamente, a versão compilada falha quando sua saída não é mais do tipo " Integer64 ", mas a versão padrão da Wolfram Language continua funcionando perfeitamente.)O compilador já pode lidar com centenas de primitivas de programação da Wolfram Language, rastreando adequadamente quais tipos são produzido - e gerando código que implementa diretamente essas primitivas. Às vezes, no entanto, alguém desejará usar funções sofisticadas na Wolfram Language para as quais não faz sentido gerar seu próprio código compilado - e onde o que realmente queremos fazer é chamar o kernel da Wolfram Language para essas funções. . Na versão 12.0, o KernelFunction permite: OK, mas digamos que alguém tenha uma função de código compilado. O que se pode fazer com isso? Bem, antes de tudo, é possível executá-lo dentro da Wolfram Language. Pode-se armazená-lo também e executá-lo mais tarde. Qualquer compilação específica é feita para uma arquitetura de processador específica (por exemplo, x86 de 64 bits). Mas CompiledCodeFunction mantém automaticamente informações suficientes para fazer compilação adicional para uma arquitetura diferente, se necessário.Mas, dada a CompiledCodeFunction , uma das novas possibilidades interessantes é que se pode gerar diretamente código que pode ser executado mesmo fora do ambiente da Wolfram Language. (Nosso antigo compilador tinha o CCodeGeneratepacote que forneceu recursos ligeiramente semelhantes em casos simples - embora, mesmo assim, dependa de uma cadeia de ferramentas elaborada de compiladores C etc.)Veja como é possível exportar código LLVM bruto (observe que coisas como otimização da recursão da cauda são feitas automaticamente automaticamente) e observe também a função simbólica opções do compilador no final):
OK, mas digamos que alguém tenha uma função de código compilado. O que se pode fazer com isso? Bem, antes de tudo, é possível executá-lo dentro da Wolfram Language. Pode-se armazená-lo também e executá-lo mais tarde. Qualquer compilação específica é feita para uma arquitetura de processador específica (por exemplo, x86 de 64 bits). Mas CompiledCodeFunction mantém automaticamente informações suficientes para fazer compilação adicional para uma arquitetura diferente, se necessário.Mas, dada a CompiledCodeFunction , uma das novas possibilidades interessantes é que se pode gerar diretamente código que pode ser executado mesmo fora do ambiente da Wolfram Language. (Nosso antigo compilador tinha o CCodeGeneratepacote que forneceu recursos ligeiramente semelhantes em casos simples - embora, mesmo assim, dependa de uma cadeia de ferramentas elaborada de compiladores C etc.)Veja como é possível exportar código LLVM bruto (observe que coisas como otimização da recursão da cauda são feitas automaticamente automaticamente) e observe também a função simbólica opções do compilador no final): Se alguém usa o FunctionCompileExportLibrary , obtém um arquivo de biblioteca - .dylib no Mac, .dll no Windows e .so no Linux. Pode-se usar isso na linguagem Wolfram fazendo LibraryFunctionLoad . Mas também se pode usá-lo em um programa externo.Uma das principais coisas que determina a generalidade do novo compilador é a riqueza do seu sistema de tipos. No momento, o compilador suporta 14 tipos atômicos (como " Boolean ", " Integer8 ", " Complex64 " etc.). Ele também suporta construtores de tipo como " PackedArray " - de modo que, por exemplo, TypeSpecifier [" PackedArray "] [ "Real64", 2] corresponde a uma matriz empacotada no nível 2 de reais de 64 bits.Na implementação interna da Wolfram Language (que, aliás, é principalmente em Wolfram Language), tivemos uma maneira otimizada de armazenar matrizes por um longo tempo. Na versão 12.0, estamos expondo-o como NumericArray . Diferente das construções comuns da Wolfram Language, você precisa informar ao NumericArray em detalhes como ele deve armazenar dados. Mas então ele funciona de uma maneira agradável e otimizada:
Se alguém usa o FunctionCompileExportLibrary , obtém um arquivo de biblioteca - .dylib no Mac, .dll no Windows e .so no Linux. Pode-se usar isso na linguagem Wolfram fazendo LibraryFunctionLoad . Mas também se pode usá-lo em um programa externo.Uma das principais coisas que determina a generalidade do novo compilador é a riqueza do seu sistema de tipos. No momento, o compilador suporta 14 tipos atômicos (como " Boolean ", " Integer8 ", " Complex64 " etc.). Ele também suporta construtores de tipo como " PackedArray " - de modo que, por exemplo, TypeSpecifier [" PackedArray "] [ "Real64", 2] corresponde a uma matriz empacotada no nível 2 de reais de 64 bits.Na implementação interna da Wolfram Language (que, aliás, é principalmente em Wolfram Language), tivemos uma maneira otimizada de armazenar matrizes por um longo tempo. Na versão 12.0, estamos expondo-o como NumericArray . Diferente das construções comuns da Wolfram Language, você precisa informar ao NumericArray em detalhes como ele deve armazenar dados. Mas então ele funciona de uma maneira agradável e otimizada: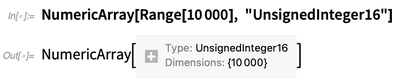

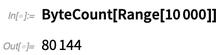 Na versão 11.2, apresentamos o ExternalEvaluate , que permite fazer cálculos em linguagens como Python e JavaScript a partir da Wolfram Language (em Python , “^” significa BitXor ):
Na versão 11.2, apresentamos o ExternalEvaluate , que permite fazer cálculos em linguagens como Python e JavaScript a partir da Wolfram Language (em Python , “^” significa BitXor ): Na versão 11.3, introduzimos células de idioma externas, para facilitar a inserção de programas em idiomas externos ou outras entradas diretamente em um notebook:
Na versão 11.3, introduzimos células de idioma externas, para facilitar a inserção de programas em idiomas externos ou outras entradas diretamente em um notebook: Na versão 12.0, estamos reforçando a integração. Por exemplo, dentro de uma string de linguagem externa, você pode usar <* ... *> para avaliar o código da Wolfram Language:
Na versão 12.0, estamos reforçando a integração. Por exemplo, dentro de uma string de linguagem externa, você pode usar <* ... *> para avaliar o código da Wolfram Language: Isso também funciona em células da linguagem externa:
Isso também funciona em células da linguagem externa: É claro que o Python não é a Wolfram Language; muitas coisas não funcionam:
É claro que o Python não é a Wolfram Language; muitas coisas não funcionam: Mas ExternalEvaluate pode pelo menos retornar muitos tipos de dados do Python, incluindo listas (como Lista ), dicionários (como Associação ), imagens (como Imagem ), datas (como DateObject ), matrizes NumPy (comoNumericArray ) e conjuntos de dados de pandas (como TimeSeries , DataSet , etc.). ( ExternalEvaluate também pode retornar ExternalObject, que é basicamente um identificador para um objeto que você pode enviar de volta para Python.)Você também pode usar diretamente funções externas (o ord ligeiramente bizarramente nomeado é basicamente o analógico Python do ToCharacterCode ):
Mas ExternalEvaluate pode pelo menos retornar muitos tipos de dados do Python, incluindo listas (como Lista ), dicionários (como Associação ), imagens (como Imagem ), datas (como DateObject ), matrizes NumPy (comoNumericArray ) e conjuntos de dados de pandas (como TimeSeries , DataSet , etc.). ( ExternalEvaluate também pode retornar ExternalObject, que é basicamente um identificador para um objeto que você pode enviar de volta para Python.)Você também pode usar diretamente funções externas (o ord ligeiramente bizarramente nomeado é basicamente o analógico Python do ToCharacterCode ): E aqui está uma função pura do Python, representada simbolicamente na Wolfram Language:
E aqui está uma função pura do Python, representada simbolicamente na Wolfram Language:

Chamando a linguagem Wolfram de Python e outros lugares
Como se deve acessar a Wolfram Language? Existem muitas maneiras. Pode-se usá-lo diretamente em um notebook. Pode-se chamar APIs que o executam na nuvem. Ou pode-se usar o WolframScript em um shell de linha de comando . O WolframScript pode ser executado em um Wolfram Engine local ou em um Wolfram Engine na nuvem . Permite fornecer código diretamente para executar: E permite que você faça coisas como definir funções, por exemplo, com código em um arquivo:
E permite que você faça coisas como definir funções, por exemplo, com código em um arquivo:
 Juntamente com o lançamento da versão 12.0, também estamos lançando nossa primeira nova nova biblioteca cliente da Wolfram Language - para Python. A idéia básica desta biblioteca é facilitar para os programas Python chamarem a Wolfram Language. (Vale ressaltar que, efetivamente, temos uma biblioteca de clientes em linguagem C há pelo menos 30 anos - através do que agora é chamado de WSTP .)A maneira como uma biblioteca de clientes em linguagem funciona é diferente para diferentes idiomas. Para Python - como uma linguagem interpretada (que na verdade foi historicamente informada pela Wolfram Language) - é particularmente simples. Depois de configurar a biblioteca, E iniciar uma sessão (localmente ou na nuvem), então você pode apenas avaliar o código Wolfram idioma e obter os resultados de volta em Python:
Juntamente com o lançamento da versão 12.0, também estamos lançando nossa primeira nova nova biblioteca cliente da Wolfram Language - para Python. A idéia básica desta biblioteca é facilitar para os programas Python chamarem a Wolfram Language. (Vale ressaltar que, efetivamente, temos uma biblioteca de clientes em linguagem C há pelo menos 30 anos - através do que agora é chamado de WSTP .)A maneira como uma biblioteca de clientes em linguagem funciona é diferente para diferentes idiomas. Para Python - como uma linguagem interpretada (que na verdade foi historicamente informada pela Wolfram Language) - é particularmente simples. Depois de configurar a biblioteca, E iniciar uma sessão (localmente ou na nuvem), então você pode apenas avaliar o código Wolfram idioma e obter os resultados de volta em Python: Você também pode acessar diretamente as funções Wolfram de idioma (como uma espécie de inverso de ExternalFunction ):
Você também pode acessar diretamente as funções Wolfram de idioma (como uma espécie de inverso de ExternalFunction ): E você pode interaja diretamente com coisas como estruturas de pandas, matrizes NumPy etc. De fato, você pode apenas tratar toda a linguagem Wolfram como uma biblioteca gigante que pode ser acessada a partir do Python. Ou, é claro, você pode simplesmente usar a agradável e integrada Wolfram Language diretamente, talvez criando APIs externas, se precisar delas.
E você pode interaja diretamente com coisas como estruturas de pandas, matrizes NumPy etc. De fato, você pode apenas tratar toda a linguagem Wolfram como uma biblioteca gigante que pode ser acessada a partir do Python. Ou, é claro, você pode simplesmente usar a agradável e integrada Wolfram Language diretamente, talvez criando APIs externas, se precisar delas.Mais para o Wolfram “Super Shell”
Uma característica do uso da Wolfram Language é que ela permite que você evite pensar nos detalhes do sistema do seu computador e em coisas como arquivos e processos. Mas, às vezes, alguém quer trabalhar no nível de sistemas. E para operações bastante simples, pode-se usar apenas uma GUI do sistema operacional. Mas e as coisas mais complicadas? No passado, eu normalmente me via usando o shell Unix . Mas há muito tempo, em vez disso, usei a Wolfram Language.Certamente é muito conveniente ter tudo em um notebook e foi ótimo poder usar programaticamente funções como FileNames (ls), FindList (grep), SystemProcessData (ps), RemoteRunProcess (ssh) eFileSystemScan . Mas na versão 12.0, estamos adicionando várias funções adicionais para suportar o uso da Wolfram Language como um "super shell".Há o RemoteFile para representar simbolicamente um arquivo remoto (com autenticação, se necessário) - que você pode usar imediatamente em funções como CopyFile . Há o FileConvert para converter diretamente arquivos entre diferentes formatos.E se você realmente quiser mergulhar fundo, veja como rastrear todos os pacotes nas portas 80 e 443 usados na leitura de wolfram.com :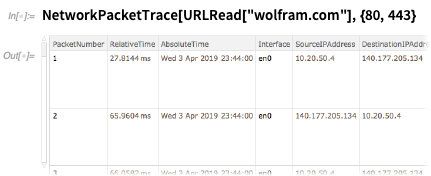
Fantoches em um navegador da web
Dentro da Wolfram Language, é fácil há muito tempo interagir com servidores da Web, usando funções como
URLExecute e
HTTPRequest , além de $
Cookies , etc. Mas na versão 12.0, estamos adicionando algo novo: a capacidade da Wolfram Language de
controlar um navegador da Web e fazê-lo programaticamente fazer o que queremos. A coisa mais imediata que podemos fazer é apenas obter uma imagem da aparência de um site em um navegador da web:

O resultado é uma imagem com a qual podemos calcular:
Para fazer algo mais detalhado, precisamos iniciar uma sessão do navegador (atualmente oferecemos suporte ao Firefox e Chrome):

Imediatamente uma janela em branco do navegador aparece em nossa tela. Agora podemos usar o WebExecute para abrir uma página da web:

Agora que abrimos a página, existem muitos comandos que podemos executar. Isso clica no primeiro hiperlink que contém o texto "Laboratório de programação":
Isso retorna o título da página que alcançamos:
Você pode digitar em campos, executar JavaScript e basicamente fazer programaticamente tudo o que você poderia fazer manualmente com um navegador da web. Desnecessário dizer que há anos que usamos uma versão dessa tecnologia em nossa empresa para testar todos os nossos vários sites e serviços da web. Mas agora, na versão 12.0, estamos disponibilizando uma versão simplificada.
Para todos os computadores de uso geral no mundo de hoje, há provavelmente 10 vezes mais
microcontroladores - executando cálculos específicos sem nenhum sistema operacional geral. Um microcontrolador pode custar alguns centavos a alguns dólares e, em algo como um carro de gama média, pode haver 30 deles.
Na versão 12.0, estamos introduzindo um
kit de microcontrolador para a Wolfram Language, que permite fornecer especificações simbólicas a partir das quais ele gera e implementa automaticamente o código para executar de forma autônoma nos microcontroladores. Na configuração típica, um microcontrolador está continuamente computando dados provenientes de sensores e, em tempo real, emitindo sinais para os atuadores. Os tipos mais comuns de computação são efetivamente os da teoria de controle e processamento de sinais.
Temos um amplo suporte para a
teoria do controle e o
processamento de sinais diretamente na Wolfram Language por um longo tempo. Mas agora o que é possível com o Kit de Microcontrolador é pegar o que está especificado no idioma e baixá-lo como código incorporado em um microcontrolador autônomo que pode ser
implantado em qualquer lugar (em dispositivos, IoT, dispositivos etc.).
Como exemplo, veja como se pode gerar uma representação simbólica de um filtro de processamento de sinal analógico:

Podemos usar esse filtro diretamente no Wolfram Language - digamos, usando o
RecurrenceFilter para aplicá-lo a um sinal de áudio. Também podemos fazer coisas como traçar sua resposta de frequência:
Para implantar o filtro em um microcontrolador, primeiro precisamos derivar dessa representação em tempo contínuo uma aproximação em tempo discreto que pode ser executada em um loop apertado (aqui, a cada 0,1 segundos) no microcontrolador:
Agora estamos prontos para usar o kit de microcontrolador para realmente implementá-lo em um microcontrolador. O kit suporta mais de cem tipos diferentes de microcontroladores. Veja como podemos implantar o filtro em um
Arduino Uno que conectamos a uma porta serial em nosso computador:

 Microcontrolador O EmbedCode
Microcontrolador O EmbedCode funciona gerando código-fonte apropriado do tipo C, compilando-o para a arquitetura de microcontrolador desejada e, em seguida, implantando-o no microcontrolador por meio do chamado programador. Aqui está o código-fonte real que foi gerado neste caso específico:
Então agora temos algo assim que executa nosso
filtro Butterworth , que podemos usar em qualquer lugar:
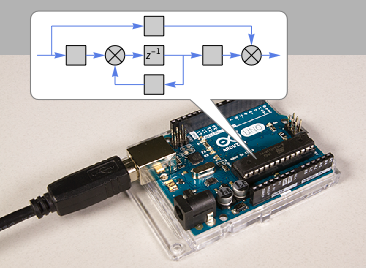
Se quisermos verificar o que está fazendo, sempre podemos conectá-lo novamente à Wolfram Language usando
DeviceOpen para abrir sua
porta serial e ler e escrever a partir dela.
Qual a relação entre a Wolfram Language e os videogames? Ao longo dos anos, a Wolfram Language tem sido usada nos bastidores em
muitos aspectos do desenvolvimento de jogos (simulação de estratégias, criação de geometrias, análise de resultados etc.). Mas há algum tempo estamos trabalhando em um vínculo mais próximo entre o Wolfram Language e o
ambiente de jogo Unity , e na Versão 12.0 estamos lançando uma primeira versão deste link.
O esquema básico é ter o Unity rodando ao lado da Wolfram Language e, em seguida, configurar a comunicação bidirecional, permitindo a troca de objetos e comandos. O encanamento sob o capô é bastante complexo, mas o resultado é uma boa fusão dos pontos fortes da Wolfram Language e Unity.
Isso configura o link e inicia um novo projeto no Unity:

Agora crie uma forma complexa:
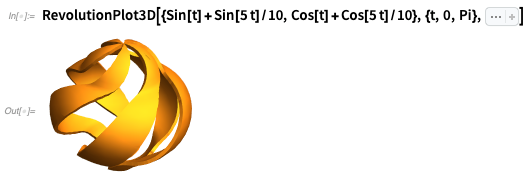
Depois, é necessário apenas um comando para colocar isso no jogo do Unity como um objeto chamado "
thingoid ":

Dentro da Wolfram Language, há uma representação simbólica do objeto, e o UnityLink agora oferece centenas de funções para manipular esses objetos, mantendo sempre versões na Unity e na Wolfram Language.
É muito poderoso que se possa pegar coisas da Wolfram Language e colocá-las imediatamente no Unity - sejam elas
geometria ,
imagens ,
áudio ,
terreno geográfico ,
estruturas moleculares ,
anatomia 3D ou qualquer outra coisa. Também é muito poderoso que essas coisas possam ser manipuladas no jogo Unity, seja através da física dos jogos ou pela ação do usuário. (Eventualmente, pode-se esperar ter uma funcionalidade semelhante a
Manipular , na qual os controles não são apenas controles deslizantes e outras coisas, mas peças complexas de jogo.)
Fizemos experimentos para colocar o conteúdo gerado pela Wolfram Language em realidade virtual desde o início dos anos 90. Mas, nos tempos modernos, o Unity se tornou um padrão de fato para configurar ambientes de VR / AR - e com o UnityLink agora é fácil colocar rotineiramente coisas da Wolfram Language em qualquer ambiente XR moderno.
Pode-se usar o Wolfram Language para preparar material para os jogos do Unity, mas em um jogo do Unity, o UnityLink também basicamente permite inserir o código do Wolfram Language que pode ser executado durante o jogo em uma máquina local ou por meio de uma API na
Wolfram Cloud . E, entre outras coisas, isso torna mais fácil colocar ganchos em um jogo para que o jogo possa enviar "telemetria" (digamos no
Wolfram Data Drop ) para análise na linguagem Wolfram. (Também é possível programar a execução do jogo - o que é, por exemplo, muito útil para testes de jogos.)
Escrever jogos é uma questão complexa. Mas o UnityLink fornece uma nova abordagem interessante que deve facilitar a criação de protótipos de todos os tipos de jogos e o aprendizado das idéias de desenvolvimento de jogos. Uma razão para isso é que ele efetivamente permite que um script seja jogado em um nível superior, usando construções simbólicas na Wolfram Language. Mas outro motivo é que ele permite que o processo de desenvolvimento seja realizado de forma incremental em um notebook, além de explicar e documentar todas as etapas do processo. Por exemplo, aqui está o que equivale a um
ensaio computacional que descreve o desenvolvimento de um "
jogo de piano ":

O UnityLink não é uma coisa simples: contém mais de 600 funções. Mas com essas funções é possível acessar praticamente todos os recursos do Unity e configurar praticamente qualquer jogo imaginável.
Para algo como o aprendizado por reforço, é essencial ter um ambiente externo manipulável durante o aprendizado de máquina. Bem, o
ServiceExecute permite ativar dispositivos reais (vire o robô para a esquerda) e obter dados de sensores (o robô caiu?) E o
DeviceExecute permite chamar APIs reais (qual é o efeito de postar esse tweet ou fazer essa troca?).
Mas, para muitos propósitos, o que se deseja é ter um ambiente externo simulado. E, de certa forma, apenas a pura Wolfram Language já faz isso, por exemplo, fornecendo acesso a um rico “universo computacional” cheio de programas e equações modificáveis (
autômatos celulares ,
equações diferenciais , ...). E, sim, as coisas nesse universo computacional podem ser informadas pelo mundo real - digamos, com as propriedades realistas dos
oceanos ,
produtos químicos ou
montanhas .
Mas e os ambientes mais parecidos com os que os humanos modernos geralmente aprendem - cheios de estruturas de engenharia construídas e assim por diante? Por conveniência, o
SystemModel dá acesso a muitos sistemas de engenharia realistas. E através do UnityLink, podemos esperar ter acesso a simulações ricas em jogos do mundo.
Mas como um primeiro passo, na versão 12.0, estamos configurando conexões para alguns jogos simples - em particular a partir do
"ginásio" do
OpenAI . A interface é como seria para interagir com o mundo real, com o jogo acessado como um "dispositivo" (após a instalação apropriada, às vezes, "dolorosa em código aberto"):

Podemos ler o estado do jogo:

E podemos mostrá-lo como uma imagem:
Com um pouco mais de esforço, podemos realizar 100 ações aleatórias no jogo (sempre verificando se não "morremos") e depois mostrar um gráfico de espaço dos estados observados do jogo:

Na versão 11.3, iniciamos
nossa primeira conexão com o blockchain . A versão 12.0 inclui muitos novos recursos e capacidades, talvez mais notadamente a capacidade de gravar em blockchains públicas, bem como ler a partir deles. (Também temos nosso próprio
Wolfram Blockchain para usuários do Wolfram Cloud.) No momento, estamos suportando blockchains
Bitcoin ,
Ethereum e
ARK , suas redes principais e testnets (e, sim, temos nossos próprios nós se conectando diretamente a essas blockchains).
Na versão 11.3, permitimos a
leitura bruta de transações de blockchains. Na versão 12.0, adicionamos uma camada de análise, para que, por exemplo, você possa solicitar um resumo dos tokens "CK" (AKA
CryptoKitties ) no blockchain
Ethereum :

É rápido olhar para todas as transações de token no histórico e criar uma nuvem de palavras de quão ativos diferentes tokens foram:

Mas e quanto a fazer nossa própria transação? Digamos que queremos usar um
caixa eletrônico Bitcoin (como o que, estranhamente,
existe em uma loja de bagels perto de mim ) para transferir dinheiro para um endereço Bitcoin. Bem, primeiro criamos nossas chaves criptográficas (e precisamos nos lembrar de nossa chave privada!):

Em seguida, precisamos pegar nossa chave pública e gerar um endereço Bitcoin a partir dela:

Faça um código QR a partir disso e você está pronto para ir ao caixa eletrônico:

Mas e se quisermos escrever para a blockchain nós mesmos? Aqui, usaremos a rede de teste Bitcoin (para não gastar dinheiro real). Isso mostra o resultado de uma transação que fizemos anteriormente - que inclui 0,0002 bitcoin (ou seja, 20.000 satoshi):

Agora podemos configurar uma transação que recebe essa saída e, por exemplo, envia 8000 satoshi para cada um dos dois endereços (que definimos exatamente como para a transação ATM):
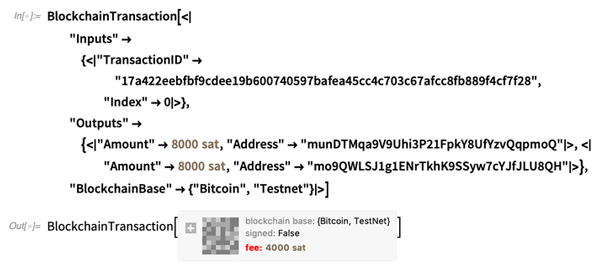
OK, agora temos um objeto de transação de blockchain - que ofereceria uma taxa (mostrada em vermelho porque é "dinheiro real" que você gastará) de toda a restante criptomoeda (aqui 4000 satoshi) para um minerador disposto a colocar o transação na blockchain. Mas antes que possamos enviar esta transação (e "gastar o dinheiro"), precisamos assiná-la com nossa chave privada:
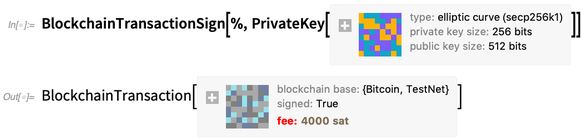
Finalmente, aplicamos o
BlockchainTransactionSubmit e
enviamos nossa transação para ser colocada no blockchain:

Aqui está o ID da transação:

Se perguntarmos imediatamente sobre essa transação, receberemos uma mensagem dizendo que não está no blockchain:

Mas depois de esperarmos alguns minutos, já está - e em breve se espalhará para todas as cópias da blockchain do Bitnetin testnet:
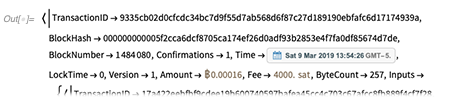
Se você estiver preparado para gastar dinheiro real, poderá usar exatamente as mesmas funções para fazer uma transação na rede principal. Você também pode fazer coisas como comprar CryptoKitties. Funções como
BlockchainContractValue podem ser usadas para qualquer contrato inteligente (por enquanto, apenas o Ethereum) e são configuradas para entender imediatamente coisas como os tokens
ERC-20 e
ERC-721 .
Lidar com cadeias de blocos envolve muita criptografia, algumas das quais são novas na versão 12.0 (principalmente, lidar com curvas elípticas). Mas na versão 12.0 também estamos estendendo nossas funções criptográficas que não são da blockchain. Por exemplo, agora temos funções para lidar diretamente com
assinaturas digitais . Isso cria uma assinatura digital usando a chave privada acima:


Agora qualquer um pode verificar a mensagem usando a chave pública correspondente:

Na versão 12.0, adicionamos vários novos tipos de hashes para a função
Hash , principalmente para suportar várias criptomoedas. Também adicionamos maneiras de gerar e verificar
chaves derivadas . Comece com qualquer senha e o
GenerateDerivedKey "inflará" para algo mais longo (para ser mais seguro, adicione "
salt "):

Aqui está uma versão da chave derivada, adequada para uso em vários esquemas de autenticação:

Conexão a feeds de dados financeiros
A
Wolfram Knowledgebase contém todos os tipos de
dados financeiros . Normalmente, há uma
entidade financeira (como uma ação), depois há uma propriedade (como o preço). Aqui está o histórico diário completo do preço das ações da Apple (é impressionante que pareça melhor em uma escala de log):
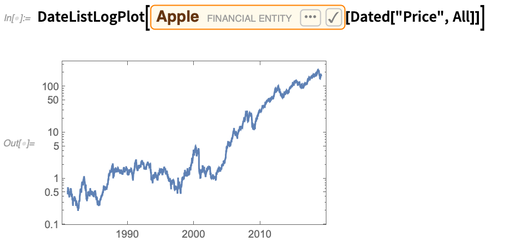
Mas enquanto os dados financeiros na Wolfram Knowledgebase, e disponíveis de maneira padrão no Wolfram Language, são atualizados continuamente, não é em tempo real (principalmente com atraso de 15 minutos) e não possui todos os detalhes que muitos traders financeiros usam. Para uso financeiro sério, no entanto, desenvolvemos a
Wolfram Finance Platform . E agora, na versão 12.0, ele tem acesso direto aos feeds de dados financeiros da Bloomberg e da Reuters.
A maneira como arquitetamos o Wolfram Language, a estrutura para as conexões da Bloomberg e da Reuters está sempre disponível no idioma - mas só é ativada se você tiver a Wolfram Finance Platform, bem como as assinaturas apropriadas da Bloomberg ou da Reuters. Mas, supondo que você os tenha, veja como se conectar ao serviço
Terminal Bloomberg :

Todos os instrumentos financeiros manipulados pelo Terminal Bloomberg agora estão disponíveis como entidades no idioma Wolfram:

Agora podemos solicitar propriedades dessa entidade:

Ao todo, existem mais de 60.000 propriedades acessíveis a partir do Terminal Bloomberg:

Aqui estão 5 exemplos aleatórios (sim, eles são bem detalhados; esses são os nomes da Bloomberg, não o nosso):

Apoiamos o serviço Terminal Bloomberg, o serviço
Bloomberg Data License e o serviço
Reuters Elektron . Uma coisa sofisticada que se pode fazer agora é configurar uma tarefa contínua para receber dados de forma assíncrona e chamar uma "
função de manipulador " toda vez que um novo conjunto de dados entra:
Atualizações de plataforma e engenharia de software
Eu falei sobre muitas novas funções e novas funcionalidades na Wolfram Language. Mas e a infraestrutura subjacente da Wolfram Language? Bem, estamos trabalhando duro nisso também. Por exemplo, entre a Versão 11.3 e a Versão 12.0, conseguimos corrigir quase 8000 erros relatados. Também tornamos muitas coisas mais rápidas e robustas. Em geral, estamos reforçando a engenharia de software do sistema, por exemplo, reduzindo o tamanho do download inicial em quase 10% (apesar de toda a funcionalidade adicionada). (Também fizemos coisas como melhorar a
pré-busca preditiva
dos elementos da base
de conhecimento da nuvem - portanto, quando você precisar de dados semelhantes, é mais provável que ele já esteja armazenado em cache no computador.)
É um recurso de longa data do cenário da computação que os sistemas operacionais estão sendo atualizados continuamente - e para aproveitar os recursos mais recentes, os aplicativos também precisam ser atualizados. Trabalhamos há vários anos em uma grande atualização da interface do notebook Mac - que finalmente está pronta na versão 12.0. Como parte da atualização, reescrevemos e reestruturamos grandes quantidades de código que foram desenvolvidas e polidas por mais de 20 anos, mas o resultado é que, na versão 12.0, tudo sobre nosso sistema no Mac é totalmente de 64 bits, e faz uso das mais recentes
APIs de cacau . Isso significa que o front end do notebook é significativamente mais rápido - e também pode ir além do limite de memória anterior de 2 GB.
Há também uma atualização de plataforma no Linux, onde agora a interface do notebook suporta totalmente o
Qt 5 , o que permite que todas as operações de renderização ocorram "sem cabeça", sem nenhum servidor X - simplificando bastante a implantação do
Wolfram Engine na nuvem. (A versão 12.0 ainda não possui suporte de alta resolução para o Windows, mas isso está chegando muito em breve.)
O desenvolvimento da
Wolfram Cloud é, de certa forma, separado do desenvolvimento das aplicações Wolfram Language e
Wolfram Desktop (embora, para compatibilidade interna, estamos lançando a versão 12.0 ao mesmo tempo nos dois ambientes). Mas no ano passado desde o lançamento da Versão 11.3, houve um progresso dramático na Wolfram Cloud.
Especialmente notáveis são os avanços nos notebooks na nuvem - suportando mais elementos de interface (incluindo alguns, como sites e vídeos incorporados, que ainda não estão disponíveis nos notebooks de mesa), bem como maior robustez e velocidade. (Fazer toda a interface do notebook funcionar em um navegador da Web não é uma tarefa fácil da engenharia de software, e na Versão 12.0 existem algumas estratégias bastante sofisticadas para coisas como manter caches consistentes de carregamento rápido, além de representações DOM simbólicas completas.)
Na versão 12.0, agora existe apenas um item de menu simples (Arquivo> Publicar na nuvem ...) para publicar qualquer bloco de anotações na nuvem. E uma vez publicado o caderno, qualquer pessoa no mundo pode interagir com ele - assim como fazer sua própria cópia para poder editá-lo.
É interessante ver
quão amplamente a nuvem entrou no que pode ser feito na Wolfram Language. Além de toda a integração perfeita da base de conhecimento em nuvem e a capacidade de alcançar coisas como blockchains, também existem conveniências como
Enviar para ... enviar qualquer notebook por email, usando a nuvem se não houver conexão direta com o servidor de email disponível.
E muito mais ...
Mesmo que essa tenha sido uma peça longa, não é nem perto de contar toda a história do que há de novo na versão 12.0. Juntamente com o restante de nossa equipe, estou trabalhando muito na versão 12.0 há um longo tempo - mas ainda é emocionante ver o quanto realmente há nela.
Mas o que é fundamental (e muito trabalho a ser alcançado!) É que tudo o que adicionamos foi cuidadosamente projetado para se encaixar de forma coerente com o que já existe. Desde a primeira versão, há mais de 30 anos, do que agora é a Wolfram Language, seguimos os mesmos princípios básicos - e isso faz parte do que nos permitiu crescer de maneira tão dramática o sistema, mantendo a compatibilidade a longo prazo.
É sempre difícil decidir exatamente o que priorizar o desenvolvimento para cada nova versão, mas estou muito satisfeito com as escolhas que fizemos para a Versão 12.0. Eu dei muitas palestras durante o ano passado e fiquei muito impressionado com a frequência com que consegui dizer sobre as coisas que surgem: “Bem, acontece que isso fará parte da versão 12.0! "
Pessoalmente, uso compilações preliminares internas da Versão 12.0 há quase um ano e cheguei a considerar muitos de seus novos recursos - e usá-los e apreciá-los bastante. Portanto, é um grande prazer que hoje tenhamos a versão final 12.0 - com todos esses novos recursos oficialmente, prontos para serem usados por qualquer pessoa e todos ...