Às vezes, ao desenvolver um produto de alta carga, surge uma situação em que é necessário processar não o maior número possível de solicitações, mas limitar o número de solicitações por unidade de tempo. No nosso caso, esse é o número de notificações por push enviadas aos usuários finais. Leia mais sobre algoritmos de limitação de taxa, seus prós e contras - sob o corte.
Primeiro, um pouco sobre nós. Pushwoosh é um serviço b2b para comunicação entre nossos clientes e seus usuários. Fornecemos às empresas soluções abrangentes para comunicação com os usuários por meio de notificações push, email e outros canais de comunicação. Além de realmente enviar mensagens, oferecemos ferramentas para segmentar o público, coletar e processar estatísticas e muito mais. Para fazer isso, criamos um produto de alta carga na junção de muitas tecnologias, das quais apenas uma pequena parte é PHP, Golang, PostgreSQL, MongoDB, Apache Kafka. Muitas de nossas soluções são exclusivas, por exemplo, notificações de alta velocidade. Processamos mais de 2 bilhões de solicitações de API por dia, temos mais de 3 bilhões de dispositivos em nosso banco de dados e, durante todo o tempo, enviamos mais de 500 bilhões de notificações para esses dispositivos.
E aqui chegamos a uma situação em que as notificações precisam ser entregues a milhões de dispositivos não o mais rápido possível (como na já mencionada alta velocidade), mas limitando artificialmente a velocidade, para que os servidores de nossos clientes aos quais os usuários acessam quando abrem a notificação não caiam no mesmo tempo carga.
Aqui, vários algoritmos de limitação de taxa vêm em nosso auxílio, o que nos permite limitar o número de solicitações por unidade de tempo. Como regra, isso é usado, por exemplo, ao projetar uma API, pois dessa maneira podemos proteger o sistema contra excesso acidental ou malicioso de solicitações, resultando em um atraso ou negação de serviço para outros clientes. Se a limitação de taxa for implementada, todos os clientes serão limitados a um número fixo de solicitações por unidade de tempo. Além disso, a limitação de taxa pode ser usada ao acessar partes do sistema associadas a dados confidenciais; Portanto, se um invasor obtiver acesso a eles, não poderá acessar rapidamente todos os dados.
Existem muitas maneiras diferentes de implementar o limite de taxa. Neste artigo, consideraremos os prós e os contras de vários algoritmos, bem como os problemas que podem surgir ao dimensionar essas soluções.
Algoritmos de limite de velocidade de processamento de solicitações
Balde com vazamento (balde com vazamento)
O Leaky Bucket é um algoritmo que fornece a abordagem mais simples e intuitiva para limitar a velocidade de processamento usando uma fila, que pode ser representada como um "bucket" contendo solicitações. Quando uma solicitação é recebida, ela é adicionada ao final da fila. Em intervalos regulares, o primeiro elemento da fila é processado. Isso também é conhecido como fila FIFO . Se a fila estiver cheia, solicitações adicionais serão descartadas (ou "vazadas").

A vantagem desse algoritmo é que ele suaviza as explosões e processa solicitações aproximadamente na mesma velocidade, é fácil de implementar em um único servidor ou balanceador de carga, é eficiente no uso de memória, pois o tamanho da fila para cada usuário é limitado.
No entanto, com um aumento acentuado no tráfego, a fila pode ser preenchida com solicitações antigas e privar o sistema da capacidade de processar solicitações mais recentes. Ele também não garante que os pedidos sejam processados em um horário fixo. Além disso, se você carregar balanceadores para fornecer tolerância a falhas ou aumentar a taxa de transferência, deverá implementar uma política de coordenação e garantir restrições globais entre eles.
Há uma variação desse algoritmo - bucket de token ("bucket com tokens" ou "algoritmo de cesta de marcadores").
Em tal implementação, os tokens são adicionados ao "bucket" a uma velocidade constante e, ao processar a solicitação, o token do "bucket" é excluído; se não houver tokens suficientes, a solicitação será descartada. Você pode simplesmente usar o registro de data e hora como tokens.
Existem variações usando vários "baldes", enquanto o tamanho e a taxa de recebimento de tokens neles podem ser diferentes para "baldes" individuais. Se não houver tokens suficientes no primeiro "bucket" para processar a solicitação, sua presença no segundo etc. será verificada, mas a prioridade do processamento da solicitação será reduzida (como regra, isso é usado no design de interfaces de rede quando, por exemplo, você pode alterar o valor do campo Pacote processado por DSCP ).
A principal diferença da implementação do Leaky Bucket é que os tokens podem acumular quando o sistema está ocioso e as explosões podem ocorrer mais tarde, enquanto as solicitações serão processadas (já que existem tokens suficientes), enquanto o Leaky Bucket é garantido para suavizar a carga mesmo em caso de inatividade.
Janela fixa
Esse algoritmo usa uma janela de n segundos para rastrear solicitações. Normalmente, valores como 60 segundos (minutos) ou 3600 segundos (hora) são usados. Cada solicitação recebida aumenta o contador dessa janela. Se o contador exceder um determinado valor limite, a solicitação será descartada. Normalmente, a janela é determinada pelo limite inferior do intervalo de tempo atual, ou seja, quando a janela tem 60 segundos de largura, a solicitação que chega às 12:00:03 vai para a janela 12:00:00.
A vantagem desse algoritmo é que ele fornece o processamento de solicitações mais recentes, sem depender do processamento de solicitações antigas. No entanto, uma única explosão de tráfego perto da borda da janela pode dobrar o número de solicitações processadas, pois permite solicitações para a janela atual e a próxima janela por um curto período de tempo. Além disso, se muitos usuários estiverem aguardando a redefinição do contador de janelas, por exemplo, no final da hora, eles poderão provocar um aumento na carga neste momento, devido ao fato de acessar a API ao mesmo tempo.
Log deslizante
Esse algoritmo envolve o rastreamento de registros de data e hora de cada solicitação do usuário. Esses registros são armazenados, por exemplo, em um conjunto ou tabela de hash e classificados por hora; registros fora do intervalo monitorado são descartados. Quando chega uma nova solicitação, calculamos o número de registros para determinar a frequência das solicitações. Se a solicitação estiver fora da quantidade permitida, ela será descartada.
A vantagem desse algoritmo é que ele não está sujeito a problemas que surgem nas bordas da janela fixa , ou seja, o limite de velocidade será rigorosamente observado. Além disso, como as solicitações de cada cliente são monitoradas individualmente, não há crescimento de carga de pico em determinados pontos, o que é outro problema do algoritmo anterior.
No entanto, o armazenamento de informações sobre cada solicitação pode ser caro, além disso, cada solicitação exige o cálculo do número de solicitações anteriores, potencialmente em todo o cluster, como resultado da qual essa abordagem não é escalável para lidar com grandes explosões de tráfego e ataques de negação de serviço.
Janela de correr
Essa é uma abordagem híbrida que combina o baixo custo de processamento de uma janela fixa e o manuseio avançado de situações de fronteira Sliding Log . Como na janela fixa simples, rastreamos o contador de cada janela e, em seguida, levamos em conta o valor ponderado da frequência de solicitação da janela anterior com base no carimbo de data / hora atual para suavizar as explosões de tráfego. Por exemplo, se 25% do tempo da janela atual já passou, consideramos 75% das solicitações da janela anterior. A quantidade relativamente pequena de dados necessários para rastrear cada chave nos permite dimensionar e trabalhar em um grande cluster.
Esse algoritmo permite escalar a limitação da taxa, mantendo um bom desempenho. Além disso, é uma maneira compreensível de transmitir aos clientes informações sobre como limitar o número de solicitações e também evita os problemas que surgem ao implementar outros algoritmos de limitação de taxa.
Limitação de taxas em sistemas distribuídos
Políticas de sincronização
Se você deseja definir a limitação da taxa global ao acessar um cluster que consiste em vários nós, é necessário implementar uma política de restrição. Se cada nó rastreasse apenas sua própria restrição, o usuário poderia ignorá-lo simplesmente enviando solicitações para nós diferentes. De fato, quanto maior o número de nós, maior a probabilidade de o usuário exceder o limite global.
A maneira mais fácil de definir limites é configurar uma "sessão permanente" no balanceador para que o usuário seja direcionado para o mesmo nó. As desvantagens desse método são a falta de tolerância a falhas e problemas de dimensionamento quando os nós do cluster estão sobrecarregados.
A melhor solução, que permite regras mais flexíveis para o balanceamento de carga, é usar um data warehouse centralizado (de sua escolha). Ele pode armazenar contadores do número de solicitações para cada janela e usuário. Os principais problemas dessa abordagem são o aumento do tempo de resposta devido a solicitações de armazenamento e condições de corrida.
Condições da corrida
Um dos maiores problemas com um data warehouse centralizado é a possibilidade de condições de corrida ao competir. Isso acontece quando você usa a abordagem natural de obter e definir, na qual extrai o contador atual, incrementa-o e envia o valor resultante de volta para a loja. O problema com esse modelo é que, durante o tempo necessário para concluir o ciclo completo dessas operações (isto é, ler, incrementar e gravar), outras solicitações podem ser recebidas, em cada uma das quais o contador será armazenado com um valor (inferior) inválido. Isso permite que o usuário envie mais solicitações do que o algoritmo de limitação de taxa fornece.
Uma maneira de evitar esse problema é definir um bloqueio em torno da chave em questão, impedindo o acesso a ler ou gravar outros processos no contador. No entanto, isso pode rapidamente se tornar um gargalo de desempenho e não aumenta muito, especialmente ao usar servidores remotos, como Redis, como um armazenamento de dados adicional.
Uma abordagem muito melhor é o set-then-get, que depende de operadores atômicos, o que permite incrementar e verificar rapidamente o contador sem interferir nas operações atômicas.
Otimização de desempenho
Outra desvantagem do uso de um data warehouse centralizado é o aumento do tempo de resposta devido ao atraso na verificação dos contadores usados para implementar a limitação de taxa (tempo de ida e volta ou "atraso de ida e volta "). Infelizmente, mesmo a verificação de armazenamento rápido, como o Redis, resultará em atrasos adicionais de alguns milissegundos por solicitação.
Para definir a restrição com um atraso mínimo, é necessário realizar verificações na memória local. Isso pode ser feito relaxando as condições para verificar a velocidade e, eventualmente, usando um modelo consistente.
Por exemplo, cada nó pode criar um ciclo de sincronização de dados no qual será sincronizado com o repositório. Cada nó transmite periodicamente o valor do contador para cada usuário e a janela que afetou, para o armazenamento, que atualizará os valores atomicamente. Em seguida, o nó pode receber novos valores e atualizar dados na memória local. Esse ciclo permitirá que todos os nós do cluster estejam atualizados.
O período durante o qual os nós são sincronizados deve ser personalizável. Intervalos de sincronização mais curtos levarão a menos discrepância de dados quando a carga for distribuída igualmente entre vários nós do cluster (por exemplo, no caso em que o balanceador determine os nós de acordo com o princípio "round-robin"), enquanto intervalos mais longos criarão menos carga de leitura / gravação para o armazenamento e reduza o custo em cada nó para receber dados sincronizados.
Comparação de algoritmos de limitação de taxa
Especificamente, no nosso caso, não devemos rejeitar solicitações de clientes para a API, mas com base nos dados, pelo contrário, não os criamos; no entanto, não temos o direito de "perder" solicitações. Para fazer isso, ao enviar uma notificação, usamos o parâmetro send_rate, que indica o número máximo de notificações que enviaremos por segundo ao enviar.
Portanto, temos um certo Trabalhador executando o trabalho no tempo alocado (no meu exemplo, lendo de um arquivo), que recebe a interface RateLimitingInterface como uma entrada, informando se é possível executar uma solicitação em um determinado momento e por quanto tempo ela será executada.
interface RateLimitingInterface { public function __construct(int $rate); public function canDoWork(float $currentTime): bool; }
Todos os exemplos de código podem ser encontrados no GitHub aqui .
Explicarei imediatamente por que você precisa transferir um intervalo de tempo para o Worker. O fato é que é muito caro executar um daemon separado para processar o envio de uma mensagem com um limite de velocidade; portanto, send_rate é realmente usado como o parâmetro "número de notificações por unidade de tempo", que é de 0,01 a 1 segundo, dependendo da carga.
De fato, processamos até 100 solicitações diferentes com send_rate por segundo, alocando 1 / N segundos para processar cada quantum de tempo, em que N é o número de pushs processados por esse daemon. O parâmetro mais interessante para nós durante o processamento é se o send_rate será respeitado (pequenos erros são permitidos em uma direção ou outra) e a carga em nosso hardware (o número mínimo de acessos a armazenamentos, CPU e consumo de memória).
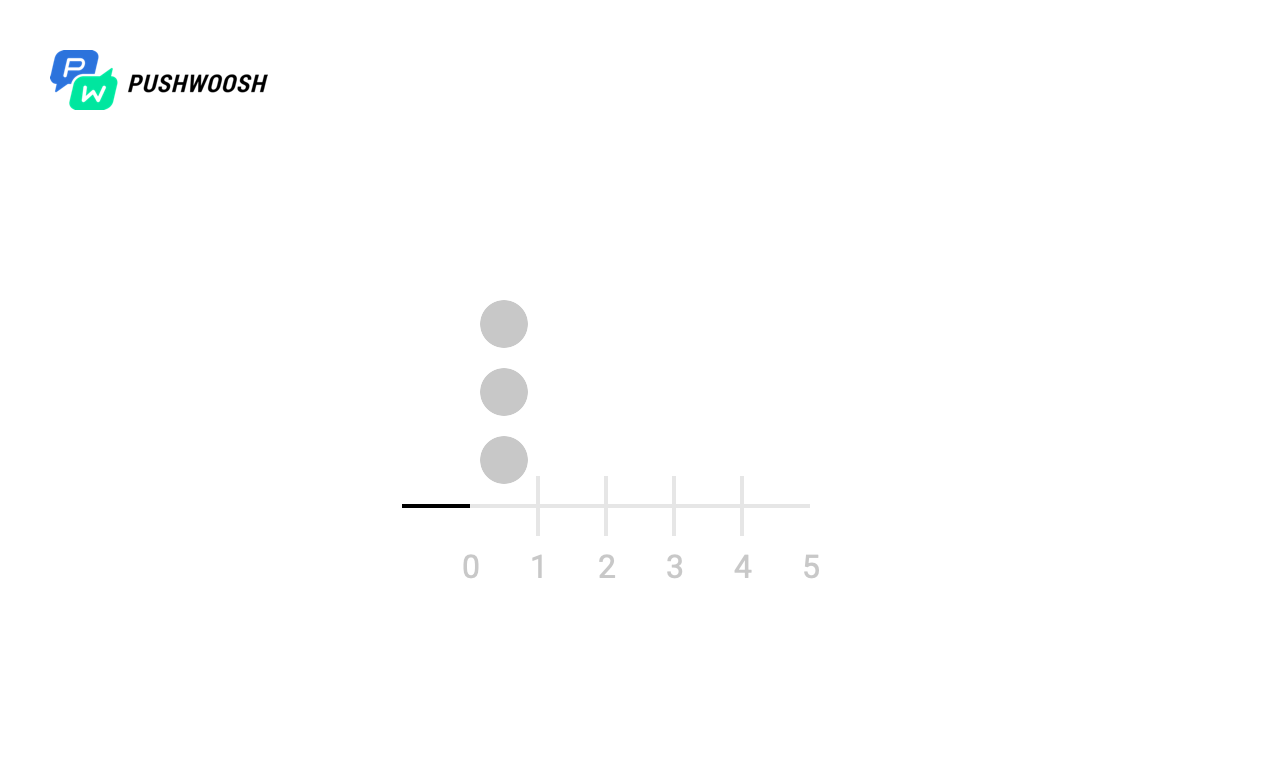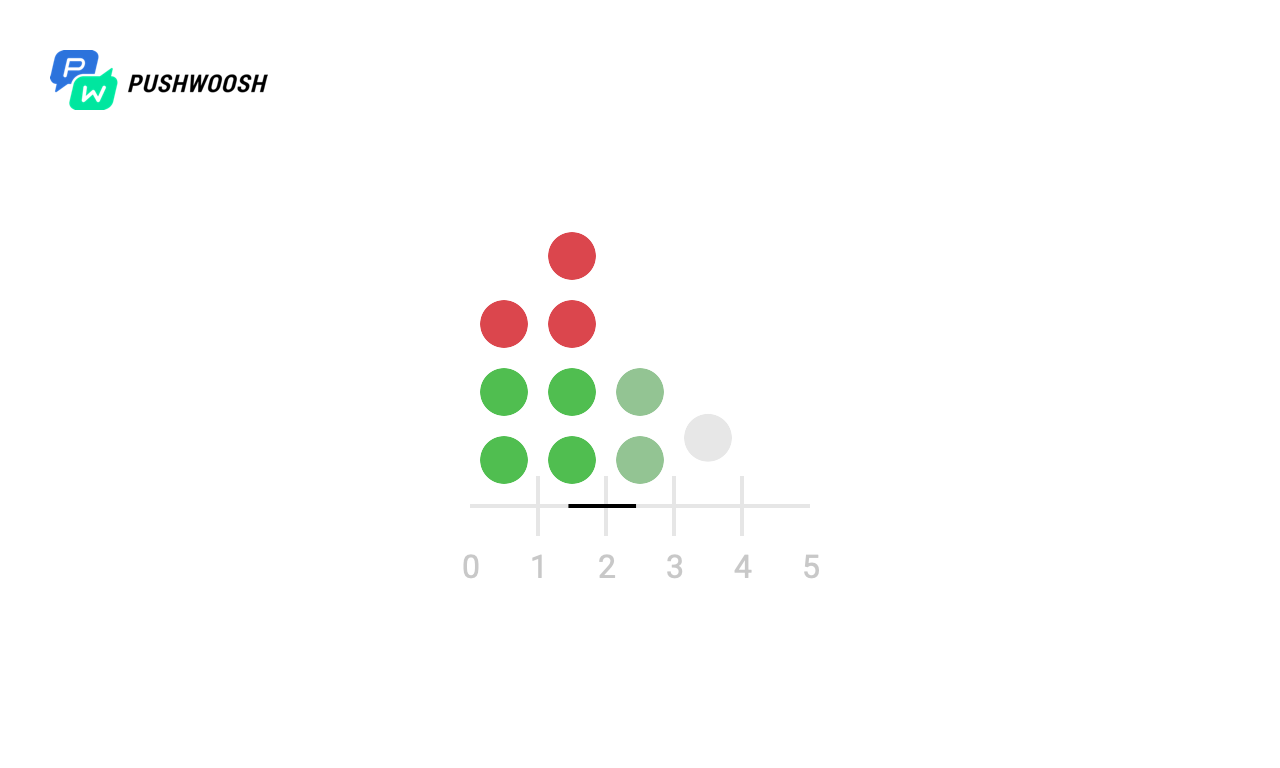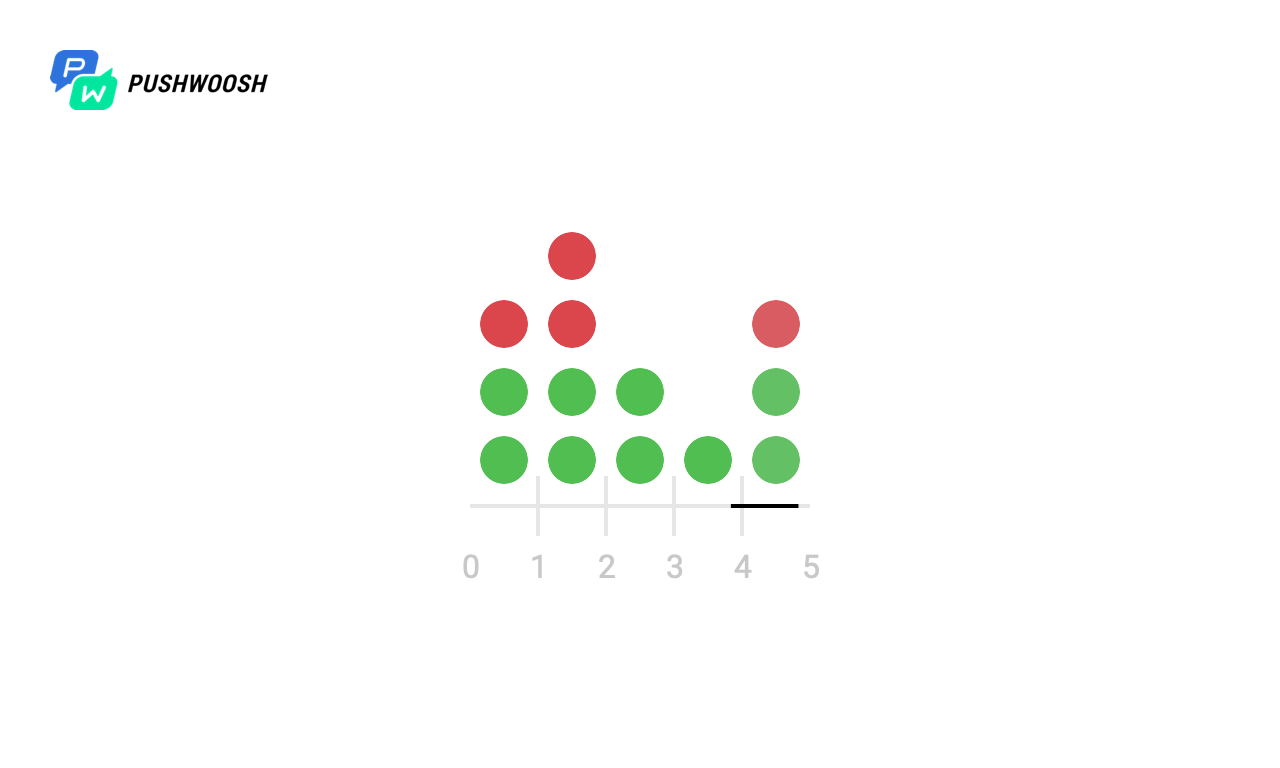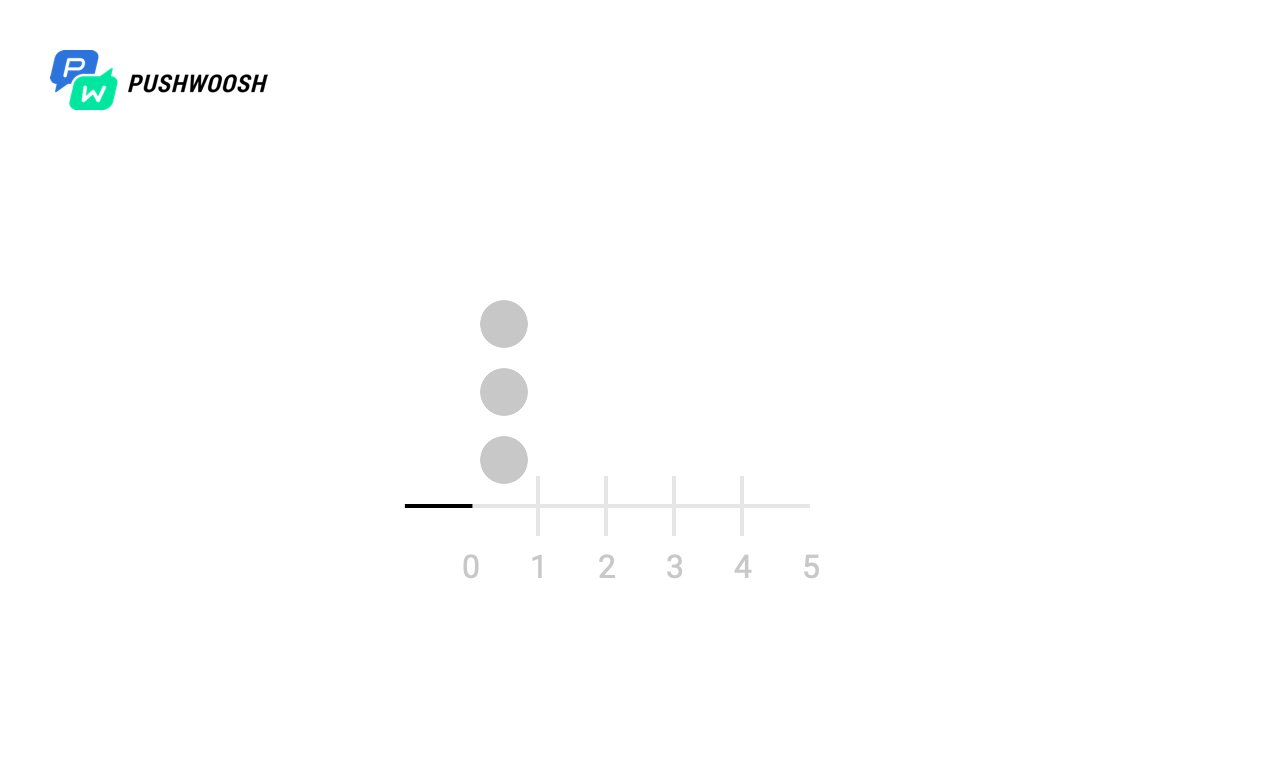
Para começar, vamos descobrir em que momentos o Worker realmente funciona. Para simplificar, este exemplo processou um arquivo de 10.000 linhas com send_rate = 1000 (ou seja, lemos 1000 linhas por segundo no arquivo).
Nas capturas de tela, os marcadores marcam os momentos e o número de chamadas de fgets para todos os algoritmos. Na realidade, isso pode ser um apelo a um banco de dados, a um recurso de terceiros ou a qualquer outra consulta, cujo número queremos limitar por unidade de tempo.
Na escala X - o tempo desde o início do processamento, de 0 a 10 segundos, cada segundo é dividido em décimos, portanto, o cronograma é de 0 a 100).
Vimos que, apesar de todos os algoritmos lidarem com a observância de send_rate (para isso, eles são destinados), a Janela Fixa e o Log Deslizante "distribuem" toda a carga quase simultaneamente, o que não nos serve muito, enquanto o Token Bucket e Sliding O Windows o distribui uniformemente por unidade de tempo (com exceção do pico de carga no momento do início, devido à falta de dados sobre a carga em momentos anteriores).
Como, na realidade, o código geralmente não funciona com o sistema de arquivos local, mas com um armazenamento de terceiros, a resposta pode ser adiada, pode haver problemas de rede e muitos outros problemas, tentaremos verificar como esse algoritmo se comportará quando as solicitações demorarem algum tempo não era. Por exemplo, após 4 e 6 segundos.
Aqui, pode parecer que a Janela Fixa não funcionou corretamente e processou duas vezes mais do que as solicitações esperadas no primeiro e de 7 a 8 segundos, mas na verdade não é assim, pois o tempo é contado a partir do momento do lançamento no gráfico e o algoritmo usa o timestamp atual do unix .
Em geral, nada mudou fundamentalmente, mas vemos que o Token Bucket suaviza a carga mais suavemente e nunca excede o limite de taxa especificado, mas o Log Deslizante em caso de inatividade pode exceder o valor permitido.
Conclusão
Examinamos todos os algoritmos básicos para implementar a limitação de taxa, cada um com seus prós e contras e é adequado para várias tarefas. Esperamos que, depois de ler este artigo, você escolha o algoritmo mais adequado para resolver seu problema.