Hola! continuamos uma série de publicações dedicadas ao lançamento do curso
"Desenvolvedor da Web em Python" e agora estamos compartilhando com você a tradução de outro artigo interessante.
No Zendesk, usamos o Python para criar produtos de aprendizado de máquina. Em aplicativos de aprendizado de máquina, um dos problemas mais comuns que encontramos são vazamentos e picos de memória. O código Python geralmente é executado em contêineres usando estruturas de processamento distribuído, como
Hadoop ,
Spark e
AWS Batch . Cada contêiner recebe uma quantidade fixa de memória. Assim que a execução do código exceder o limite de memória especificado, o contêiner deixará de funcionar devido a erros que ocorrem devido à falta de memória.

Você pode resolver rapidamente o problema alocando ainda mais memória. No entanto, isso pode levar ao desperdício de recursos e afetar a estabilidade dos aplicativos devido a explosões imprevisíveis de memória. As causas de um vazamento de memória podem ser
as seguintes :
- Armazenamento longo de objetos grandes que não são excluídos;
- Links de loopback no código;
- Bibliotecas Base C / extensões que levam ao vazamento de memória;
É uma boa prática criar um perfil do uso da memória com aplicativos para entender melhor a eficiência do espaço de código e dos pacotes usados.
Este artigo discute os seguintes aspectos:
- Criação de perfil de uso de memória do aplicativo ao longo do tempo;
- Como verificar o uso de memória em uma parte específica do programa;
- Dicas para erros de depuração causados por problemas de memória.
Perfil de memória ao longo do tempoVocê pode dar uma olhada no uso de memória variável durante a execução de um programa Python usando o pacote
memory-profiler .
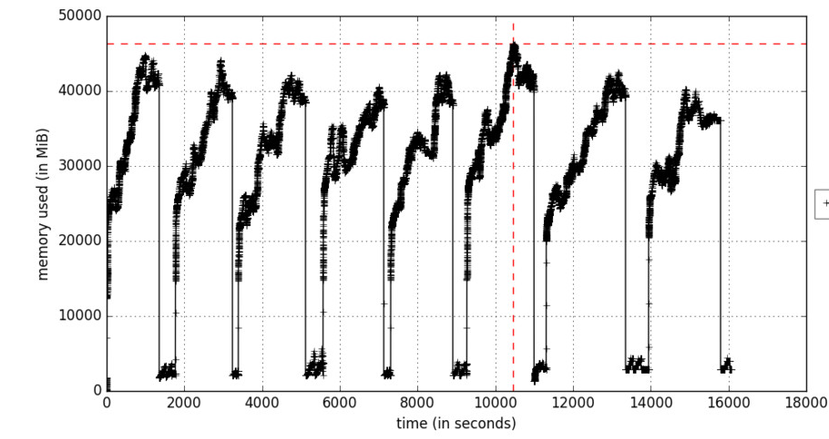 Figura A. Perfil de memória em função do tempo
Figura A. Perfil de memória em função do tempoA
opção include-children permitirá o uso da memória por qualquer processo filho gerado pelos processos pai. A Figura A reflete o processo de aprendizado iterativo, que faz com que a memória aumente os ciclos nos momentos em que os pacotes de dados de treinamento são processados. Os objetos são excluídos durante a coleta de lixo.
Se o uso da memória estiver aumentando constantemente, isso será considerado uma ameaça potencial de vazamento de memória.
Aqui está um código de exemplo que reflete isso:
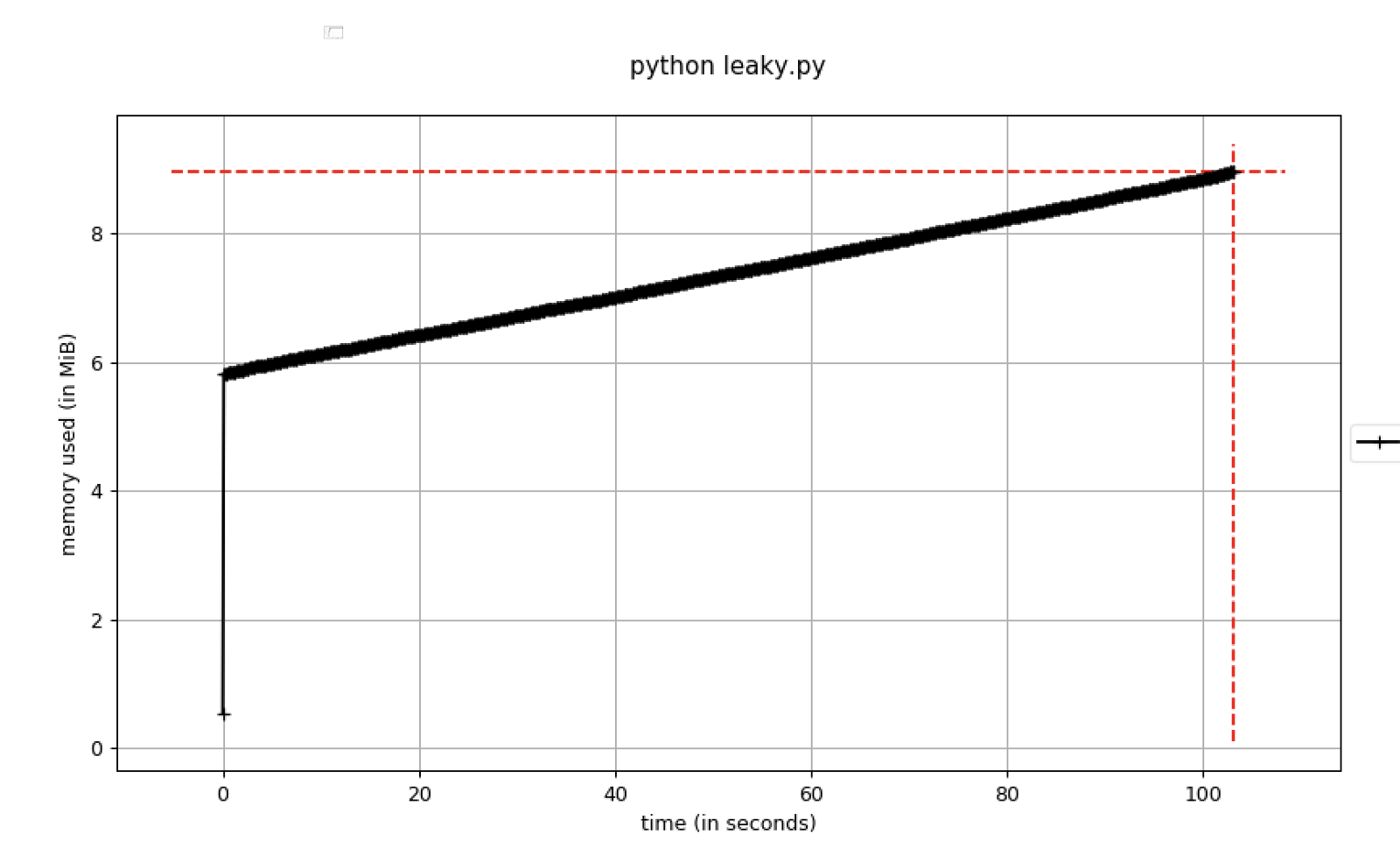 Figura B. Uso da memória aumentando ao longo do tempo
Figura B. Uso da memória aumentando ao longo do tempoVocê deve definir pontos de interrupção no depurador assim que o uso da memória exceder um determinado limite. Para fazer isso, você pode usar o
parâmetro pdb-mmem , que é conveniente durante a solução de problemas.
Despejo de memória em um momento específicoÉ útil estimar o número pré-esperado de objetos grandes no programa e se eles devem ser duplicados e / ou convertidos para vários formatos.
Para uma análise mais aprofundada dos objetos na memória, você pode criar um heap de despejo em determinadas linhas do programa usando o
muppy .
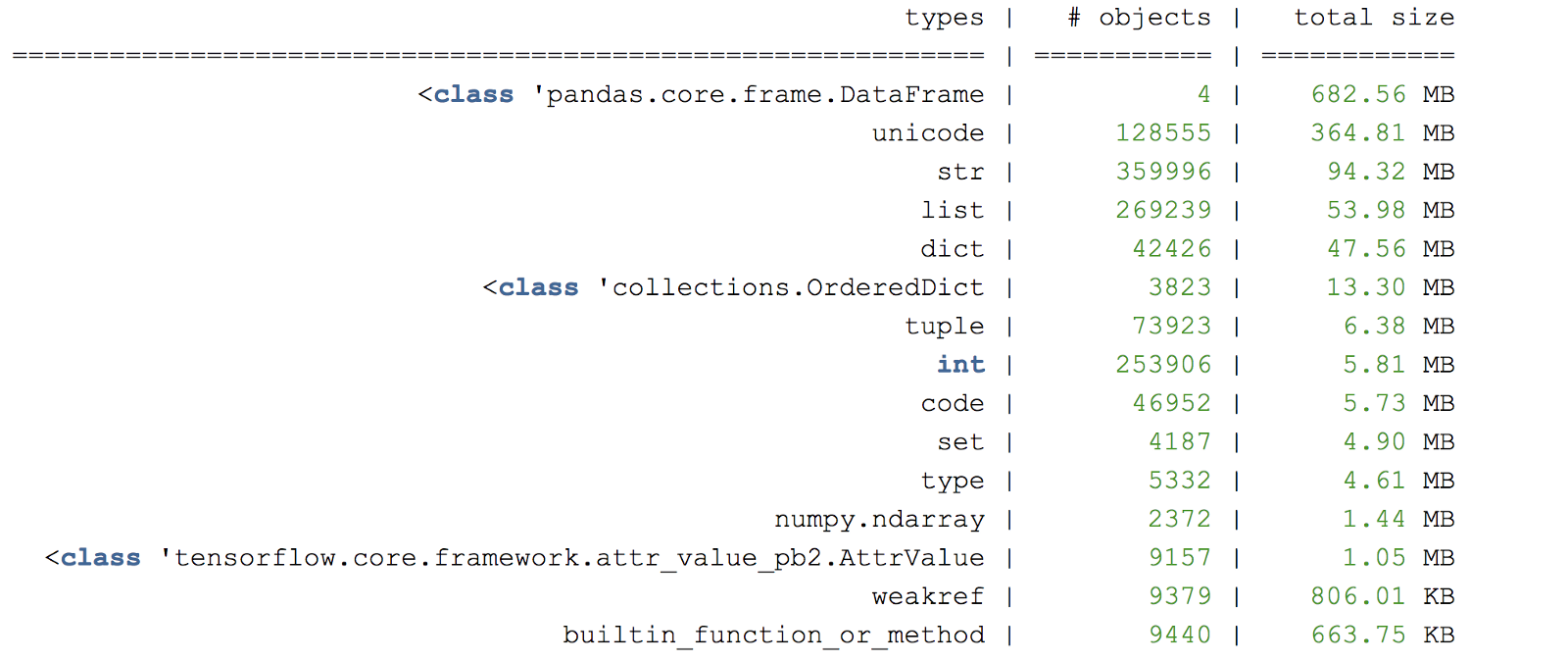 Figura C. Amostra dump heap dump
Figura C. Amostra dump heap dumpOutra biblioteca útil de criação de perfil de memória é o
objgraph , que permite gerar gráficos para verificar a origem dos objetos.
Ponteiros úteisUma abordagem útil é criar um pequeno "caso de teste" que execute o código apropriado que causa um vazamento de memória. Considere usar um subconjunto de dados selecionados aleatoriamente se a entrada completa demorar muito tempo para processar.
Execute tarefas com alta carga de memória em um processo separadoPython não necessariamente libera memória imediatamente para o sistema operacional. Para garantir que a memória tenha sido liberada, você deve iniciar um processo separado após executar um pedaço de código. Você pode aprender mais sobre o coletor de lixo em Python
aqui .
O depurador pode adicionar referências a objetos.Se você usar um depurador de ponto de interrupção, como
pdb , todos os objetos criados que são referenciados manualmente pelo depurador permanecerão na memória. Isso pode criar uma falsa sensação de vazamento de memória, porque os objetos não são excluídos em tempo hábil.
Cuidado com os pacotes que podem causar vazamento de memória.Algumas bibliotecas no Python podem causar um vazamento, por exemplo, o
pandas possui vários problemas conhecidos de
vazamento de memória .
Tenha uma boa caçada por vazamentos!
Links úteis:docs.python.org/3/c-api/memory.htmldocs.python.org/3/library/debug.htmlEscreva nos comentários se este artigo foi útil para você. E para quem quiser saber mais sobre o curso, convidamos você a
abrir o dia , que será realizado em 22 de abril.