Olá, sou Sergey Elantsev, estou desenvolvendo um
balanceador de carga de rede no Yandex.Cloud. Anteriormente, liderei o desenvolvimento do balanceador L7 do portal Yandex - meus colegas brincam que, não importa o que eu faça, eu tenho um balanceador. Vou dizer aos leitores da Habr como gerenciar a carga na plataforma de nuvem, como vemos a ferramenta ideal para alcançar esse objetivo e como estamos caminhando para a construção dessa ferramenta.
Primeiro, apresentamos alguns termos:
- VIP (IP virtual) - endereço IP do balanceador
- Servidor, back-end, instância - uma máquina virtual com um aplicativo em execução
- RIP (IP Real) - endereço IP do servidor
- Healthcheck - verificação de disponibilidade do servidor
- Zona de disponibilidade, AZ - infraestrutura isolada no data center
- Região - a união de diferentes AZ
Os balanceadores de carga resolvem três tarefas principais: realizam o próprio balanceamento, melhoram a tolerância a falhas do serviço e simplificam seu dimensionamento. A tolerância a falhas é garantida pelo controle automático de tráfego: o balanceador monitora o estado do aplicativo e exclui instâncias do balanceamento que falham no teste de disponibilidade. O dimensionamento é garantido pela distribuição uniforme da carga entre instâncias, bem como pela atualização da lista de instâncias em tempo real. Se o balanceamento não for suficientemente uniforme, algumas das instâncias receberão uma carga que excede o limite de capacidade de trabalho e o serviço se tornará menos confiável.
O balanceador de carga geralmente é classificado por nível de protocolo no modelo OSI em que é executado. O Cloud Balancer opera no nível TCP, que corresponde ao quarto nível, L4.
Vamos passar para uma revisão da arquitetura do balanceador de nuvem. Aumentaremos gradualmente o nível de detalhe. Dividimos os componentes do balanceador em três classes. A classe do plano de configuração é responsável pela interação do usuário e armazena o estado de destino do sistema. O plano de controle armazena o estado atual do sistema e gerencia os sistemas da classe de plano de dados, que são diretamente responsáveis pela entrega de tráfego dos clientes para suas instâncias.
Plano de dados
O tráfego cai em dispositivos caros chamados roteadores de borda. Para aumentar a tolerância a falhas, vários desses dispositivos funcionam simultaneamente em um data center. Em seguida, o tráfego vai para os balanceadores, que anunciam qualquer endereço IP de broadcast para todos os AZs via BGP para clientes.
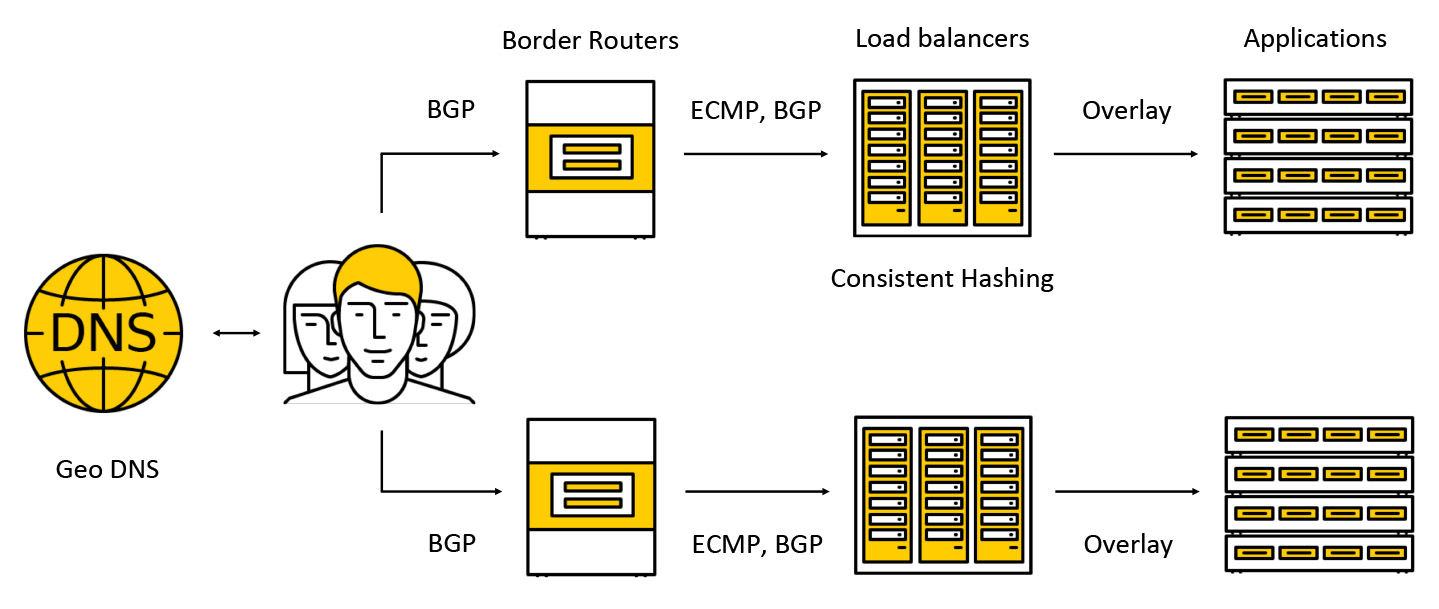
O tráfego é transmitido via ECMP - essa é uma estratégia de roteamento segundo a qual pode haver várias rotas igualmente boas para o destino (no nosso caso, o destino será o endereço IP de destino) e os pacotes podem ser enviados para qualquer um deles. Também apoiamos o trabalho em várias zonas de acesso, de acordo com o seguinte esquema: anunciamos o endereço em cada uma das zonas, o tráfego cai no mais próximo e já não vai além dele. Mais adiante, postaremos mais detalhadamente o que acontece com o tráfego.
Plano de configuração
O componente principal do plano de configuração é a API através da qual as operações básicas com balanceadores são executadas: criando, excluindo, alterando a composição de instâncias, obtendo resultados de verificações de saúde, etc. Por um lado, essa é uma API REST e, por outro, costumamos usar a estrutura na nuvem gRPC, portanto, “convertemos” o REST em gRPC e, em seguida, usamos apenas gRPC. Qualquer solicitação leva à criação de uma série de tarefas idempotentes assíncronas que são executadas em um pool compartilhado de trabalhadores do Yandex.Cloud. As tarefas são gravadas de forma que possam ser suspensas a qualquer momento e depois reiniciadas. Isso fornece operações de escalabilidade, repetibilidade e registro.

Como resultado, a tarefa da API fará uma solicitação ao controlador de serviço do balancer, escrito em Go. Ele pode adicionar e remover balanceadores, alterar a composição de back-end e configurações.
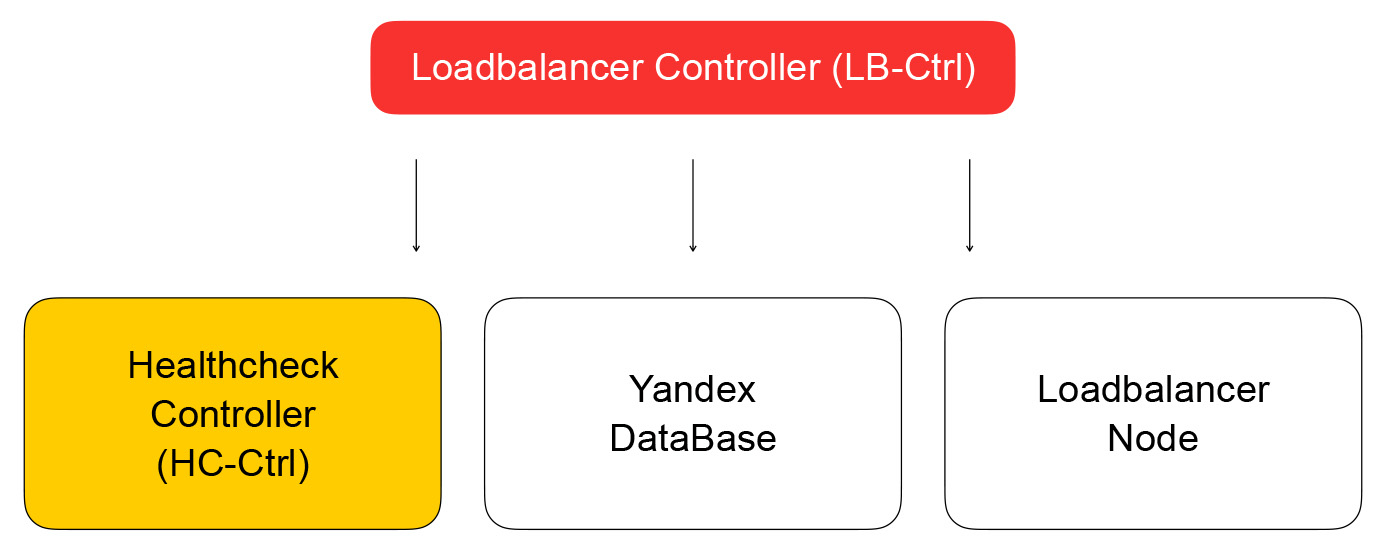
O serviço armazena seu estado no Yandex Database - um banco de dados gerenciado distribuído que você poderá usar em breve também. No Yandex.Cloud, como já
dissemos , o conceito de comida para cães opera: se nós próprios usamos nossos serviços, nossos clientes também terão prazer em usá-los. O Yandex Database é um exemplo da implementação desse conceito. Armazenamos todos os nossos dados no YDB e não precisamos pensar em manter e dimensionar o banco de dados: esses problemas são resolvidos para nós, usamos o banco de dados como um serviço.
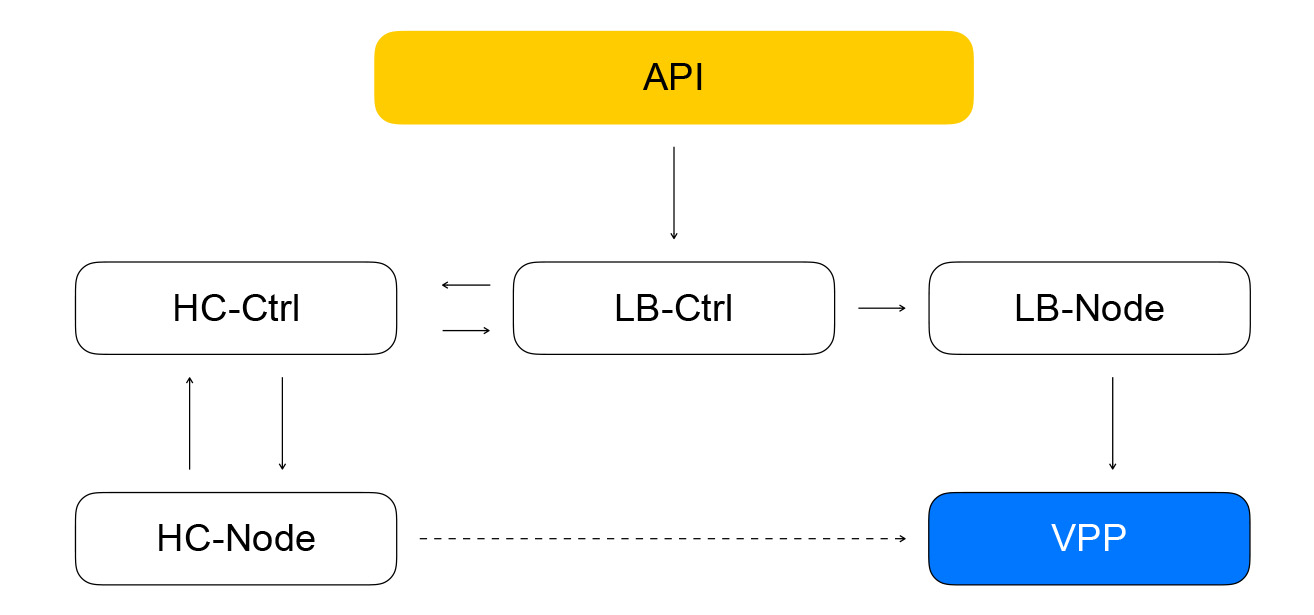
Retornamos ao controlador do balanceador. Sua tarefa é salvar informações sobre o balanceador, enviar a tarefa de verificar a prontidão da máquina virtual para o controlador de verificação de saúde.
Controlador Healthcheck
Ele recebe solicitações para alterar as regras de inspeção, as salva no YDB, distribui tarefas para verificar os nós e agrega os resultados, que são salvos no banco de dados e enviados ao controlador do loadbalancer. Ele, por sua vez, envia uma solicitação para alterar a composição do cluster no plano de dados para loadbalancer-node, que discutirei abaixo.

Vamos falar mais sobre verificações de saúde. Eles podem ser divididos em várias classes. As auditorias têm diferentes critérios de sucesso. As verificações de TCP precisam estabelecer com êxito uma conexão em um tempo fixo. As verificações de HTTP requerem uma conexão bem-sucedida e uma resposta com um código de status 200.
Além disso, as verificações diferem na classe de ação - elas são ativas e passivas. As verificações passivas simplesmente monitoram o que acontece com o tráfego sem tomar nenhuma ação especial. Isso não funciona muito bem no L4, porque depende da lógica dos protocolos de nível superior: no L4 não há informações sobre quanto tempo a operação levou e se a conexão foi boa ou ruim. As verificações ativas exigem que o balanceador envie solicitações para cada instância do servidor.
A maioria dos balanceadores de carga realiza verificações de animação por conta própria. Nós da Cloud decidimos separar essas partes do sistema para aumentar a escalabilidade. Essa abordagem nos permitirá aumentar o número de balanceadores, mantendo o número de solicitações de verificação de integridade para o serviço. As verificações são executadas por nós de verificação de integridade separados, que são usados para fragmentar e replicar destinos de teste. É impossível fazer verificações de um host, pois isso pode falhar. Então não obteremos o estado das instâncias que ele verificou. Realizamos verificações em qualquer instância a partir de pelo menos três nós de verificação de integridade. Os alvos das verificações dividimos entre nós usando algoritmos de hash consistentes.

A separação entre balanceamento e verificação de saúde pode levar a problemas. Se o nó de verificação de integridade fizer solicitações para a instância, ignorando o balanceador (que atualmente não atende tráfego), surge uma situação estranha: o recurso parece estar vivo, mas o tráfego não o alcançará. Resolvemos esse problema da seguinte maneira: garantimos o tráfego de verificação de saúde através de balanceadores. Em outras palavras, o esquema de mover pacotes com tráfego de clientes e de verificações de saúde difere minimamente: em ambos os casos, os pacotes irão para os balanceadores, que os entregarão aos recursos de destino.
A diferença é que os clientes fazem solicitações de VIPs e as verificações de saúde se referem a cada RIP individual. Aqui surge um problema interessante: damos aos nossos usuários a oportunidade de criar recursos em redes IP cinzas. Imagine que existem dois proprietários de nuvens diferentes que ocultaram seus serviços para balanceadores. Cada um deles possui recursos na sub-rede 10.0.0.1/24, além disso, com os mesmos endereços. Você precisa ser capaz de diferenciá-los de alguma forma, e aqui você precisa mergulhar no dispositivo da rede virtual Yandex.Cloud. Para mais detalhes, assista ao
vídeo do evento sobre: nuvem , é importante para nós agora que a rede possui várias camadas e possui túneis que podem ser distinguidos pelo ID da sub-rede.
Os nós Healthcheck acessam balanceadores usando os chamados endereços quase IPv6. Um quase-endereço é um endereço IPv6 no qual o endereço IPv4 e o ID da sub-rede do usuário estão protegidos. O tráfego cai no balanceador, extrai dele o endereço IPv4, substitui o IPv6 pelo IPv4 e envia o pacote para a rede do usuário.
O tráfego reverso segue o mesmo caminho: o balanceador vê que o destino é uma rede cinza dos verificadores de saúde e converte IPv4 em IPv6.
VPP - o coração do plano de dados
O balanceador é implementado na tecnologia de Vector Packet Processing (VPP) - uma estrutura da Cisco para processamento de pacotes de tráfego de rede. No nosso caso, a estrutura é executada no topo da biblioteca de gerenciamento de espaço do usuário dos dispositivos de rede - Data Plane Development Kit (DPDK). Isso fornece alto desempenho de processamento de pacotes: há muito menos interrupções no kernel, não há alternância de contexto entre o espaço do kernel e o espaço do usuário.
O VPP vai ainda mais longe e reduz ainda mais o desempenho do sistema, combinando pacotes em lotes. O aumento da produtividade se deve ao uso agressivo de caches dos processadores modernos. Ambos os caches de dados são usados (pacotes são processados por "vetores", os dados são próximos uns dos outros) e caches de instruções: no VPP, o processamento de pacotes segue um gráfico, nos nós em que existem funções que executam uma tarefa.
Por exemplo, o processamento de pacotes IP no VPP ocorre na seguinte ordem: primeiro, os cabeçalhos dos pacotes são analisados no nó de análise e, em seguida, são enviados ao nó que encaminha os pacotes ainda mais, de acordo com as tabelas de roteamento.
Um pouco de hardcore. Os autores do VPP não comprometem o uso de caches de processador; portanto, um código de processamento de vetor de pacote típico contém uma vetorização manual: existe um ciclo de processamento no qual a situação como "temos quatro pacotes na fila" é processada e, em seguida, a mesma para dois, então - por um. Geralmente, são usadas instruções de pré-busca que carregam dados nos caches para acelerar o acesso a eles nas iterações a seguir.
n_left_from = frame->n_vectors; while (n_left_from > 0) { vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
Portanto, as verificações de saúde estão transferindo o IPv6 para o VPP, que os transforma em IPv4. Isso é feito pelo nó do gráfico, que chamamos de NAT algorítmico. Para tráfego reverso (e conversão de IPv6 para IPv4), existe o mesmo nó do NAT algorítmico.
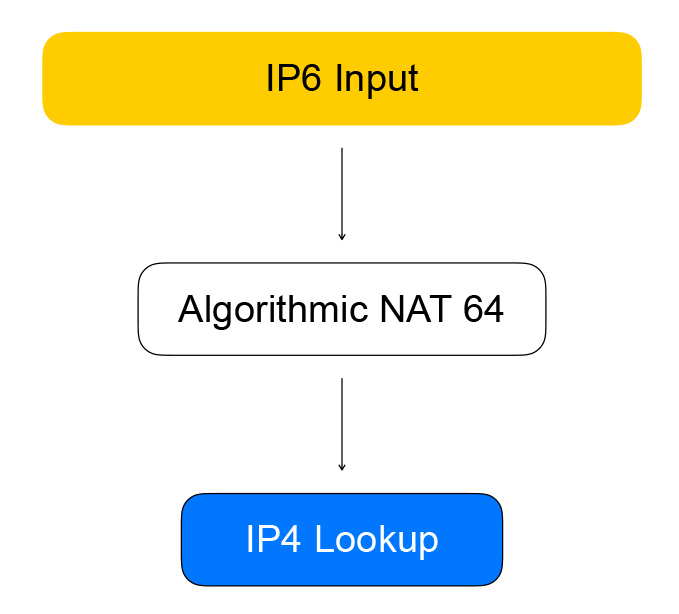
O tráfego direto dos clientes do balanceador passa pelos nós do gráfico, que realizam o próprio balanceamento.

O primeiro nó são sessões persistentes. Ele armazena um hash de
cinco tuplas para sessões estabelecidas. A tupla 5 inclui o endereço e a porta do cliente a partir do qual as informações são transmitidas, o endereço e as portas dos recursos disponíveis para receber tráfego, bem como o protocolo de rede.
O hash de cinco tuplas nos ajuda a executar menos computação no nó de hash consistente subsequente e também a lidar melhor com a alteração na lista de recursos atrás do balanceador. Quando um pacote chega ao balanceador para o qual não há sessão, ele é enviado para o nó de hash consistente. É aqui que o balanceamento ocorre usando hash consistente: selecionamos um recurso na lista de recursos "ativos" disponíveis. Em seguida, os pacotes são enviados para o nó NAT, que na verdade substitui o endereço de destino e recalcula as somas de verificação. Como você pode ver, seguimos as regras do VPP - semelhantes aos similares, agrupamos cálculos semelhantes para aumentar a eficiência dos caches do processador.
Hashing Consistente
Por que o escolhemos e o que é isso tudo? Para começar, considere a tarefa anterior - selecionando um recurso da lista.
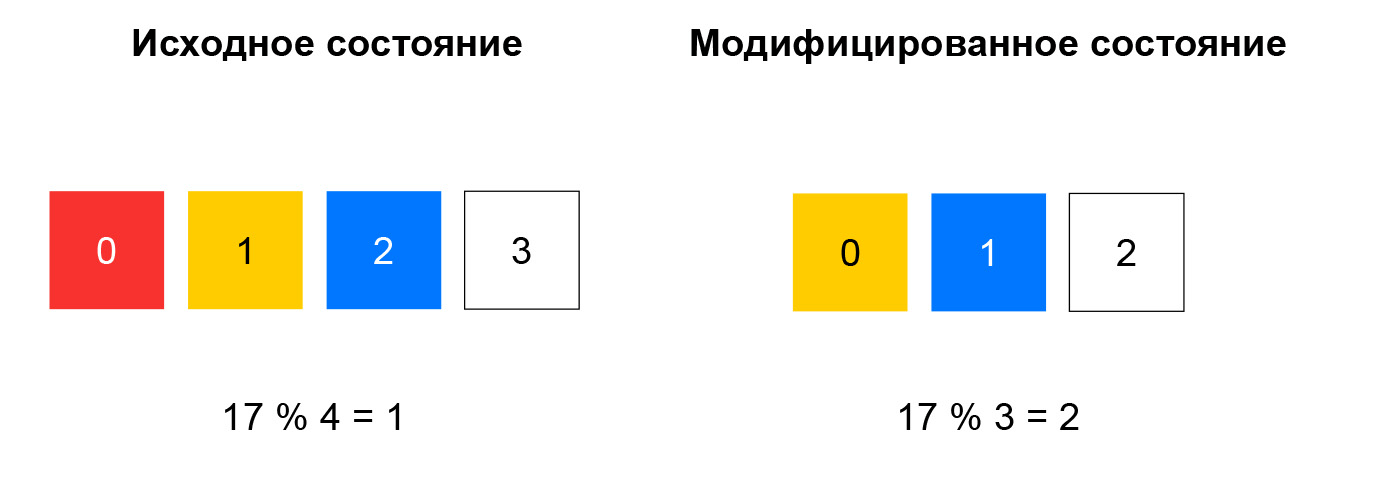
Com o hash não consistente, o hash do pacote recebido é calculado e o recurso é selecionado na lista pelo restante da divisão desse hash pelo número de recursos. Enquanto a lista permanecer inalterada, esse esquema funcionará bem: sempre enviamos pacotes com as mesmas cinco tuplas para a mesma instância. Se, por exemplo, algum recurso parar de responder às verificações de saúde, uma parte significativa dos hashes mudará a opção. As conexões TCP serão interrompidas no cliente: um pacote que foi anteriormente para a instância A pode começar a cair para a instância B, que não está familiarizada com a sessão para esse pacote.
O hash consistente resolve o problema descrito. A maneira mais fácil de explicar esse conceito é a seguinte: imagine que você tenha um anel no qual distribui recursos por hash (por exemplo, por IP: porta). A escolha de um recurso é a rotação da roda por um ângulo, que é determinado pelo hash do pacote.
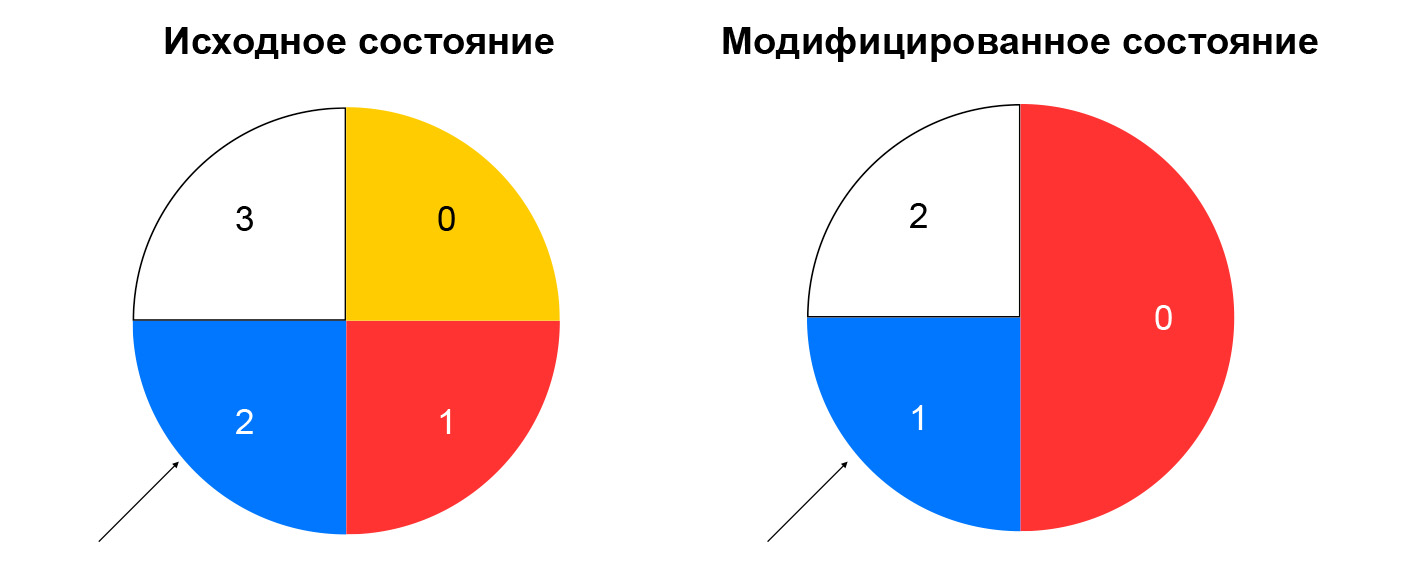
Isso minimiza a redistribuição do tráfego ao alterar a composição dos recursos. A exclusão de um recurso afetará apenas a parte do anel de hash consistente em que o recurso especificado foi localizado. A adição de um recurso também altera a distribuição, mas temos um nó de sessões persistentes que nos permite não mudar as sessões já estabelecidas para novos recursos.
Examinamos o que acontece com o tráfego direto entre o balanceador e os recursos. Agora vamos lidar com o tráfego reverso. Ele segue o mesmo padrão do tráfego de verificação - por meio de NAT algorítmico, ou seja, por NAT 44 reverso para tráfego de clientes e por NAT 46 para verificações de integridade. Aderimos ao nosso próprio esquema: unificamos o tráfego de verificações de saúde e o tráfego real do usuário.
Montagem do nó do balanceador de carga e componentes
A composição de balanceadores e recursos no VPP é relatada pelo serviço local - loadbalancer-node. Ele assina o fluxo de eventos do loadbalancer-controller, é capaz de criar a diferença entre o estado atual do VPP e o estado de destino recebido do controlador. Temos um sistema fechado: os eventos da API chegam ao controlador do balanceador, que define as tarefas do controlador de verificação de integridade para verificar a "vitalidade" dos recursos. Isso, por sua vez, define tarefas no nó de verificação de integridade e agrega os resultados, após o que os envia de volta ao controlador do balanceador. O nó loadbalancer assina eventos do controlador e altera o estado do VPP. Nesse sistema, cada serviço sabe apenas o que precisa sobre os serviços vizinhos. O número de conexões é limitado e temos a oportunidade de explorar e dimensionar independentemente os vários segmentos.
Que perguntas foram evitadas
Todos os nossos serviços no plano de controle estão escritos em Go e possuem bons recursos de dimensionamento e confiabilidade. O Go tem muitas bibliotecas de código aberto para criar sistemas distribuídos. Utilizamos ativamente o GRPC, todos os componentes contêm uma implementação de código aberto da descoberta de serviços - nossos serviços monitoram o desempenho um do outro, podem mudar sua composição dinamicamente e o associamos ao balanceamento de GRPC. Para métricas, também usamos uma solução de código aberto. No plano de dados, obtivemos um desempenho decente e uma grande reserva de recursos: tornou-se muito difícil montar um suporte no qual se pudesse descansar no desempenho do VPP, e não em uma placa de rede de ferro.
Problemas e Soluções
O que não funcionou muito bem? No Go, o gerenciamento de memória é automático, mas ocorrem vazamentos de memória. A maneira mais fácil de lidar com eles é lançar goroutines e não se esqueça de completá-las. Conclusão: monitore o consumo de memória dos programas Go. Muitas vezes, um bom indicador é a quantidade de goroutina. Há uma vantagem nesta história: no Go, é fácil obter dados em tempo de execução - no consumo de memória, no número de goroutines lançadas e em muitos outros parâmetros.
Além disso, o Go pode não ser a melhor opção para testes funcionais. Eles são bastante detalhados, e a abordagem padrão "execute tudo no pacote de IC" não é muito adequada para eles. O fato é que os testes funcionais são mais exigentes em recursos, com eles há tempos limites reais. Por esse motivo, os testes podem falhar porque a CPU está ocupada com os testes de unidade. Conclusão: se possível, realize testes "pesados" separadamente dos testes de unidade.
A arquitetura de eventos de microsserviço é mais complicada do que um monólito: pegar logs em dezenas de máquinas diferentes não é muito conveniente. Conclusão: se você estiver executando microsserviços, pense imediatamente sobre o rastreamento.
Nossos planos
Iniciaremos o balanceador interno, IPv6-balancer, adicionaremos suporte aos scripts do Kubernetes, continuaremos a fragmentar nossos serviços (agora apenas o nó de verificação de saúde e o healthcheck-ctrl estão sombreados), adicionaremos novas verificações de integridade e também implementaremos a agregação de verificação inteligente. Estamos considerando a possibilidade de tornar nossos serviços ainda mais independentes - para que eles não se comuniquem diretamente, mas usando uma fila de mensagens. O serviço
Yandex Message Queue compatível com SQS apareceu recentemente na nuvem.
Recentemente, o Yandex Load Balancer foi lançado publicamente. Estude a
documentação do serviço, gerencie os balanceadores de maneira conveniente para você e aumente a tolerância a falhas de seus projetos!