
Desde 2008, nossa empresa atua principalmente no gerenciamento de infraestrutura e no suporte técnico contínuo a projetos web: temos mais de 400 clientes, o que representa cerca de 15% do comércio eletrônico na Rússia. Consequentemente, uma arquitetura muito diversificada é suportada. Se algo cair, devemos corrigi-lo em 15 minutos. Mas, para entender que ocorreu um acidente, você precisa monitorar o projeto e responder a incidentes. Como fazer isso?
Acredito que a organização do sistema de monitoramento correto esteja com problemas. Se não houve problemas, meu discurso consistiu em uma tese: "Instale o Prometheus + Grafana e os plugins 1, 2, 3." Infelizmente, isso não funciona agora. E o principal problema é que todos continuam acreditando em algo que existia em 2008, em termos de componentes de software.
Em relação à organização do sistema de monitoramento, arrisco-me a dizer que ... projetos com monitoramento competente não existem. E a situação é tão ruim se algo cair, corre o risco de passar despercebido - todos têm certeza de que "tudo está sendo monitorado".
Talvez tudo esteja sendo monitorado. Mas como
Todos nos deparamos com uma história semelhante à seguinte: um certo devop, um certo administrador está trabalhando, uma equipe de desenvolvimento chega a eles e diz: "nós conseguimos, agora é monitorado". Qual monitor? Como isso funciona?
Ok Monitoramos a maneira antiquada. Mas já está mudando e acontece que você monitorou o serviço A, que se tornou o serviço B, que interage com o serviço C. Mas a equipe de desenvolvimento diz para você: “Instale o software, ele deve monitorar tudo!”
Então o que mudou? - Tudo mudou!
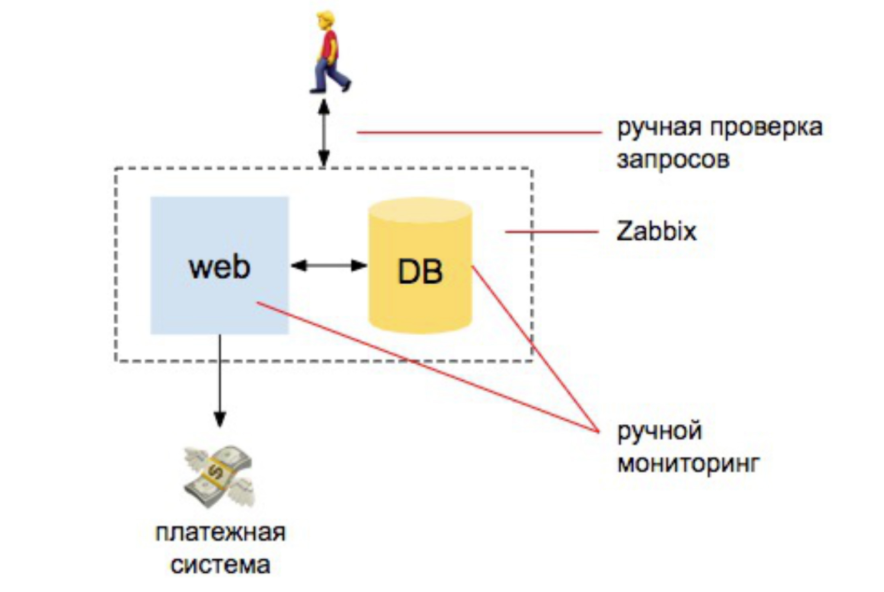
2008 ano. Está tudo bem
Existem alguns desenvolvedores, um servidor, um servidor de banco de dados. A partir daqui tudo vai. Temos alguns infa, colocamos zabbix, Nagios, cactos. E então definimos alertas claros na CPU, na operação dos discos, no local dos discos. Também fazemos algumas verificações manuais de que o site responde a pedidos que chegam ao banco de dados. E é isso - estamos mais ou menos protegidos.
Se compararmos a quantidade de trabalho que o administrador executou para garantir o monitoramento, foi 98% automático: a pessoa que está monitorando deve entender como instalar o Zabbix, como configurá-lo e configurar alertas. E 2% - para verificações externas: que o site responda e solicite ao banco de dados a chegada de novos pedidos.
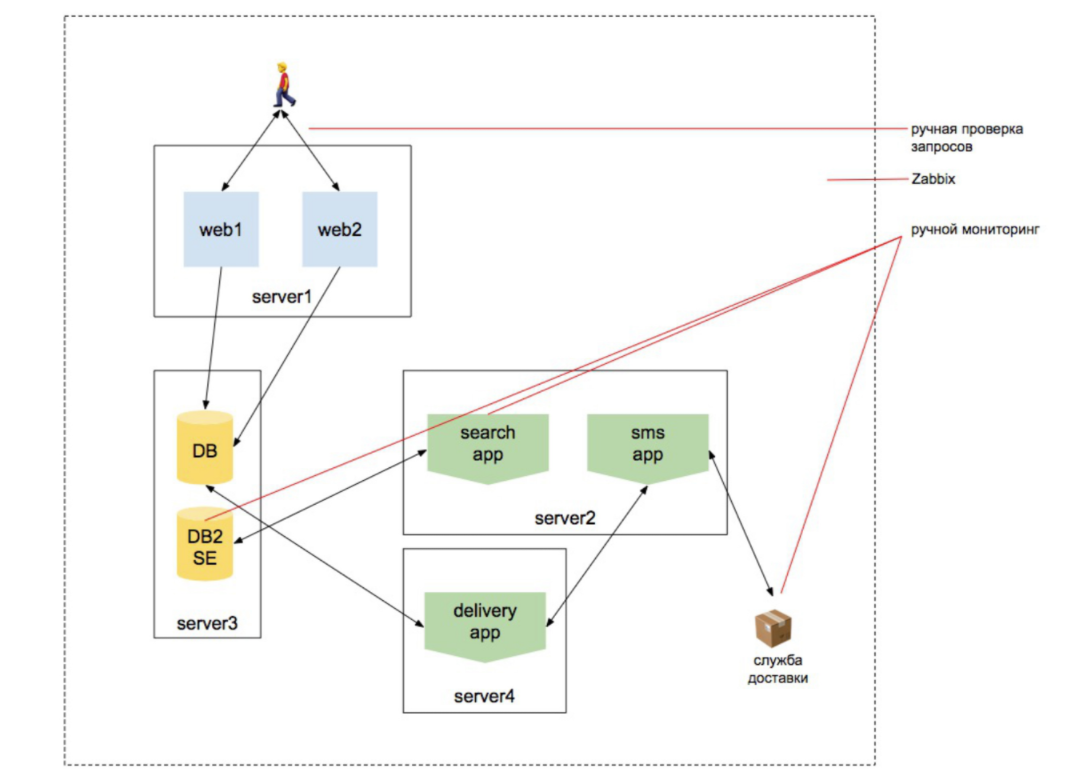
Ano de 2010. A carga está crescendo
Começamos a dimensionar a web, adicionar um mecanismo de pesquisa. Queremos ter certeza de que o catálogo de produtos contém todos os produtos. E essa pesquisa de produto funciona. Que o banco de dados funciona, que pedidos estão sendo feitos, que o site está respondendo externamente e está respondendo a partir de dois servidores e que o usuário não é expulso do site enquanto está reequilibrando para outro servidor, etc. Existem mais entidades.
Além disso, a entidade associada à infraestrutura continua sendo a maior na cabeça do gerente. Ainda está na minha cabeça que a pessoa que está monitorando é a pessoa que instalará o zabbix e poderá configurá-lo.
Mas, ao mesmo tempo, existem trabalhos sobre a realização de verificações externas, sobre a criação de um conjunto de scripts para consultar o indexador de pesquisa, um conjunto de scripts para verificar se a pesquisa é alterada durante o processo de indexação, um conjunto de scripts que verifica se as mercadorias são transferidas para o serviço de entrega etc. etc.

Nota: eu escrevi um "conjunto de scripts" 3 vezes. Ou seja, a pessoa responsável pelo monitoramento não é mais a única que instala o zabbix. Essa é a pessoa que começa a codificar. Mas nada mudou na cabeça da equipe ainda.
Mas o mundo está mudando, se tornando cada vez mais complicado. Uma camada de virtualização, vários novos sistemas são adicionados. Eles começam a interagir um com o outro. Quem disse que "cheira a microsserviços?" Mas cada serviço ainda parece individualmente um site. Podemos nos voltar para ele e entender que ele fornece as informações necessárias e trabalha por si só. E se você é um administrador que está constantemente envolvido em um projeto que está em desenvolvimento por 5-7-10 anos, você tem esse conhecimento acumulado: um novo nível aparece - você percebeu, outro nível aparece - você percebeu ...
Mas raramente alguém acompanha o projeto há 10 anos.
Resumo de Monitoramento Man
Suponha que você tenha chegado a uma nova startup que pontuou imediatamente 20 desenvolvedores, escreveu 15 microsserviços e você é o administrador informado: “Crie um CI / CD. Por favor " Você criou um CI / CD e, de repente, ouve: "É difícil trabalhar com a produção no" cubo "sem entender como o aplicativo funcionará nele. Faça-nos uma caixa de areia no mesmo "cubo".
Você faz uma caixa de areia neste cubo. Eles imediatamente dizem: "Queremos um banco de dados de estágio, que é atualizado diariamente a partir da produção, para entender que ele funciona no banco de dados, mas ao mesmo tempo não estragar o banco de dados da produção".
Você vive em tudo isso. Faltam duas semanas para o lançamento, eles dizem para você: "Agora tudo seria monitorado ..." Isso é monitorar a infraestrutura de cluster, monitorar a arquitetura de microsserviços, monitorar o trabalho com serviços externos ...
E os colegas tiram um esquema tão familiar e dizem: “Então aqui está tudo claro! Instale um programa que monitore tudo. ” Sim: plugins Prometheus + Grafana +.
E eles acrescentam ao mesmo tempo: "Você tem duas semanas, verifique se tudo é confiável".
No monte de projetos que vemos, uma pessoa é alocada para monitoramento. Imagine que queremos contratar uma pessoa por 2 semanas para monitorar e escreveremos um currículo para ele. Que habilidades essa pessoa deve possuir - considerando tudo o que dissemos antes?
- Ele deve entender o monitoramento e as especificidades do trabalho da infraestrutura de ferro.
- Ele deve entender as especificidades do monitoramento do Kubernetes (e todo mundo quer um "cubo", porque você pode ignorar tudo, ocultar, porque o administrador descobrirá isso) - por si só, sua infraestrutura e entender como monitorar aplicativos internos.
- Ele deve entender que os serviços se comunicam de maneiras especiais e conhecer as especificidades da interação dos serviços entre si. É bastante realista ver um projeto em que alguns dos serviços se comunicam de forma síncrona, porque não há outra maneira. Por exemplo, o back-end continua no REST, no gRPC para o serviço de catálogo, recebe uma lista de mercadorias e retorna. Você não pode esperar aqui. E com outros serviços, funciona de forma assíncrona. Transfira o pedido para o serviço de entrega, envie uma carta, etc.
Você provavelmente já navegou de tudo isso? E o administrador, que precisa monitorar isso, nadou ainda mais. - Ele deve ser capaz de planejar e planejar corretamente - à medida que o trabalho se torna cada vez mais.
- Portanto, ele deve criar uma estratégia a partir do serviço criado para entender como monitorá-lo especificamente. Ele precisa entender a arquitetura do projeto e seu desenvolvimento + entender as tecnologias usadas no desenvolvimento.
Lembremos de um caso absolutamente normal: parte dos serviços em php, parte dos serviços em Go, parte dos serviços em JS. De alguma forma eles trabalham entre si. É daí que vem o termo “microsserviço”: existem tantos sistemas separados que os desenvolvedores não conseguem entender o projeto como um todo. Uma parte da equipe cria serviços em JS que funcionam por conta própria e não sabem como o restante do sistema funciona. A outra parte escreve serviços em Python e não entra no modo como outros serviços funcionam, eles são isolados em seu campo. Terceiro - escreve serviços em php ou outra coisa.
Todas essas 20 pessoas estão divididas em 15 serviços, e apenas um administrador deve entender tudo isso. Pare com isso! nós apenas dividimos o sistema em 15 microsserviços, porque 20 pessoas não conseguem entender o sistema inteiro.
Mas precisa ser monitorado de alguma forma ...
Qual é o resultado? Como resultado, há uma pessoa que inclui tudo o que toda uma equipe de desenvolvedores não pode entender e, no entanto, ele também deve conhecer e ser capaz do que indicamos acima - infraestrutura de ferro, infraestrutura de Kubernetes etc.
O que posso dizer ... Houston, temos problemas.
Monitorar um projeto de software moderno é um projeto de software em si
Por uma falsa crença de que monitorar é um software, temos fé em milagres. Mas milagres, infelizmente, não acontecem. Você não pode instalar o zabbix e esperar que tudo funcione. Não faz sentido colocar Grafana e espero que tudo dê certo. A maior parte do tempo será gasta na organização de verificações sobre a operação dos serviços e sua interação entre si, verificações de como os sistemas externos funcionam. De fato, 90% do tempo será gasto não na escrita de scripts, mas no desenvolvimento de software. E deve ser uma equipe que entenda o trabalho do projeto.
Se nesta situação uma pessoa for lançada para monitoramento, ocorrerá um problema. O que está acontecendo em todo lugar.
Por exemplo, existem vários serviços que se comunicam através do Kafka. Chegou um pedido, enviamos uma mensagem sobre o pedido para Kafka. Existe um serviço que escuta informações sobre o pedido e realiza o transporte de mercadorias. Há um serviço que escuta informações sobre o pedido e envia uma carta ao usuário. E ainda há muitos serviços, e começamos a ficar confusos.
E se você ainda o der ao administrador e aos desenvolvedores em um estágio em que resta pouco tempo antes do lançamento, uma pessoa precisará entender todo esse protocolo. I.e. um projeto dessa escala leva um tempo considerável, e isso deve ser incorporado ao desenvolvimento do sistema.
Mas muitas vezes, especialmente na gravação, nas startups, vemos como o monitoramento é adiado até mais tarde. “Agora faremos a Prova de Conceito, começaremos com ela, deixaremos cair - estamos prontos para o sacrifício. E então vamos monitorar tudo. ” Quando (ou se) o projeto começa a ganhar dinheiro, a empresa deseja reduzir ainda mais recursos - porque começou a funcionar, então você precisa ir mais longe! E você está no ponto em que, no começo, precisa monitorar tudo o que é anterior, o que leva não 1% do tempo, mas muito mais. A propósito, os desenvolvedores precisarão de monitoramento e é mais fácil colocá-los em novos recursos. Como resultado, novos recursos são gravados, tudo é encerrado e você fica em um beco sem saída.
Então, como você monitora um projeto desde o início e se você tem um projeto que precisa monitorar, mas não sabe por onde começar?
Primeiro, você precisa planejar.
Digressão lírica: muitas vezes começa com o monitoramento da infraestrutura. Por exemplo, temos o Kubernetes. Para começar, colocamos Prometheus na Grafana, colocamos os plugins sob o monitoramento do "cubo". Não apenas os desenvolvedores, mas também os administradores têm uma prática infeliz: "Instalaremos este plug-in, e o plug-in provavelmente sabe como fazer isso". As pessoas gostam de começar com ações simples e compreensíveis, em vez de importantes. E a infraestrutura de monitoramento é fácil.Primeiro, decida o que e como deseja monitorar e depois pegue o instrumento, porque outras pessoas não podem pensar em você. Sim, e deveriam? Outras pessoas pensaram consigo mesmas sobre o sistema universal - ou nem pensaram quando esse plugin foi escrito. E o fato de este plugin ter 5 mil usuários não significa que traga algum benefício. Talvez você se torne o 5001 simplesmente porque já havia 5.000 pessoas lá antes.
Se você começou a monitorar a infraestrutura e o back-end do seu aplicativo parou de responder, todos os usuários perderão contato com o aplicativo móvel. Um erro vai desaparecer. Eles vão até você e dizem: "O aplicativo não funciona, o que você está fazendo aqui?" "Estamos monitorando." - "Como você monitora se não vê que o aplicativo não está funcionando?!"
- Eu acredito que é necessário iniciar o monitoramento a partir do ponto de entrada do usuário. Se o usuário não perceber que o aplicativo está funcionando - isso é tudo, é uma falha. E o sistema de monitoramento deve alertar sobre isso em primeiro lugar.
- E só então podemos monitorar a infraestrutura. Ou faça-o em paralelo. A infraestrutura é mais simples - aqui finalmente podemos instalar o zabbix.
- E agora você precisa ir às raízes do aplicativo para entender onde isso não funciona.
Meu pensamento principal é que o monitoramento seja paralelo ao processo de desenvolvimento. Se você destacar a equipe de monitoramento para outras tarefas (criação de um CI / CD, caixas de proteção, reorganização da infraestrutura), o monitoramento começará a ficar lento e você nunca poderá acompanhar o desenvolvimento (ou mais cedo ou mais tarde precisará ser interrompido).
Tudo por níveis
É assim que vejo a organização do sistema de monitoramento.
1) Nível de Aplicação:
- monitorar a lógica de negócios do aplicativo;
- monitoramento de métricas de saúde dos serviços;
- monitoramento de integração.
2) Nível de infraestrutura:
- monitorar o nível de orquestração;
- software de sistema de monitoramento;
- monitorando o nível de "ferro".
3) Mais uma vez, o nível de aplicação - mas como um produto de engenharia:
- coletando e monitorando logs de aplicativos;
- APM
- rastreamento.
4) Alerta:
- organização de um sistema de alerta;
- organização de um sistema de observação;
- organização de uma "base de conhecimento" e processamento de incidentes no fluxo de trabalho.
Importante : chegamos ao alerta não depois, mas imediatamente! Não é necessário começar a monitorar e "de alguma forma mais tarde" pensar em quem receberá alertas. Afinal, qual é a tarefa de monitoramento: entender onde algo não está funcionando no sistema e informar as pessoas certas. Se isso for deixado até o fim, as pessoas certas descobrirão que algo está errado, apenas chamando "nada funciona para nós".
Camada de aplicação - Monitorando a lógica de negócios
Aqui estamos falando sobre verificar o fato de que o aplicativo funciona para o usuário.
Este nível deve ser feito na fase de design. Por exemplo, temos um Prometheus condicional: ele rastreia para o servidor envolvido em verificações, obtém o ponto final e o ponto final vai e verifica a API.
Quando solicitado a monitorar a página principal para garantir que o site esteja funcionando, os programadores fornecem uma caneta que pode ser puxada toda vez que você precisa garantir que a API funcione. E os programadores neste momento ainda pegam e escrevem / api / test / helloworld
A única maneira de garantir que tudo funcione? Não!
- Criar tais verificações é essencialmente uma tarefa dos desenvolvedores. Os testes de unidade devem ser escritos por programadores que escrevem código. Porque se você mesclar isso ao administrador "Cara, aqui está uma lista de protocolos de API para todas as 25 funções, monitore tudo!" - nada vai funcionar.
- Se você imprimir “olá mundo”, ninguém nunca saberá que a API deve e realmente funciona. Cada alteração na API deve levar a uma alteração nas verificações.
- Se você já tiver esse desastre, pare os recursos e selecione os desenvolvedores que farão essas verificações ou se reconciliarão com as perdas, se reconciliarão se nada for verificado e cairá.
Dicas técnicas:
- Certifique-se de organizar um servidor externo para organizar as inspeções - você deve ter certeza de que seu projeto está acessível ao mundo externo.
- Organize a validação em todo o protocolo da API, não apenas nos pontos de extremidade individuais.
- Crie um ponto final prometheus com os resultados do teste.
Nível do aplicativo - Monitoramento de métricas de integridade
Agora estamos falando de métricas externas de saúde de serviços.
Decidimos monitorar todas as "canetas" do aplicativo usando verificações externas que chamamos de um sistema de monitoramento externo. Mas essas são precisamente as "canetas" que o usuário "vê". Queremos ter certeza de que os próprios serviços funcionam para nós. Aqui está uma história melhor: o K8s tem verificações de saúde para que pelo menos o cubo garanta que o serviço funcione. Mas metade dos cheques que vi são da mesma estampa “olá mundo”. I.e. aqui ele puxa uma vez após a implantação, respondeu que está tudo bem - e é isso. E o serviço, se descansar em sua própria API, possui um grande número de pontos de entrada para a mesma API, que também precisa ser monitorada, porque queremos saber que funciona. E já estamos monitorando isso lá dentro.
Como implementá-lo tecnicamente corretamente: cada serviço define um ponto final sobre seu desempenho atual e, nos gráficos da Grafana (ou qualquer outro aplicativo), vemos o status de todos os serviços.
- Cada alteração na API deve levar a uma alteração nas verificações.
- Crie um novo serviço imediatamente com métricas de integridade.
- O administrador pode procurar os desenvolvedores e perguntar "adicione-me alguns recursos para que eu entenda tudo e adicione informações sobre isso ao meu sistema de monitoramento". Mas os desenvolvedores geralmente respondem: "Não adicionaremos nada duas semanas antes do lançamento".
Informe os gerentes de desenvolvimento de que haverá tais perdas; informe também os chefes dos gerentes de desenvolvimento. Porque quando tudo cai, alguém ainda liga e exige o monitoramento do "serviço em constante queda" (c) - A propósito, selecione desenvolvedores para escrever plugins para o Grafana - isso será uma boa ajuda para os administradores.
Camada de Aplicação - Monitoramento de Integração
O monitoramento da integração se concentra no monitoramento da comunicação entre sistemas críticos para os negócios.
Por exemplo, existem 15 serviços que se comunicam. Estes não são mais sites individuais. I.e. não podemos executar o serviço por conta própria, obter / helloworld e entender que o serviço está funcionando. Como o serviço da web para fazer um pedido deve enviar informações sobre o pedido ao barramento - o serviço do armazém deve receber essa mensagem do barramento e trabalhar com ele ainda mais. E o serviço de distribuição de email deve lidar com isso de alguma forma, etc.
Portanto, não podemos entender, cutucando cada serviço individual, que tudo isso funciona. Porque nós temos um certo barramento através do qual tudo se comunica e interage.
Portanto, esse estágio deve indicar o estágio de serviços de teste para interagir com outros serviços. Após monitorar um intermediário de mensagens, você não pode organizar o monitoramento da comunicação. Se houver um serviço que emita dados e um serviço que os receba, ao monitorar um broker, veremos apenas os dados que voam de um lado para o outro. Mesmo que de alguma forma tenhamos conseguido monitorar a interação desses dados - que algum produtor publica os dados, alguém os lê, esse fluxo continua indo para Kafka - ainda não nos fornecerá informações se um serviço enviar uma mensagem em uma versão, mas outro serviço não esperava essa versão e a ignorou. Não descobriremos isso, porque os serviços nos dirão que tudo funciona.
Como eu recomendo fazer:
- Para comunicação síncrona: o terminal executa solicitações de serviços relacionados. I.e. pegamos esse endpoint, puxamos o script dentro do serviço, que vai para todos os pontos e diz: "Eu posso puxar para lá e puxar para lá, eu posso puxar ..."
- Para comunicação assíncrona: mensagens recebidas - o terminal verifica o barramento quanto a mensagens de teste e exibe o status do processamento.
- Para comunicação assíncrona: mensagens enviadas - o terminal envia mensagens de teste ao barramento.
Como costuma acontecer: temos um serviço que lança dados no barramento. Chegamos a este serviço e pedimos que você fale sobre a integridade da integração. E se o serviço precisar vender alguma mensagem em outro local (WebApp), produzirá essa mensagem de teste. E se extrairmos o serviço do lado do OrderProcessing, ele publicará primeiro algo que pode ser independente e, se houver alguma coisa dependente, ele lerá um conjunto de mensagens de teste do barramento, entenderá que pode processá-las, denunciá-las e , se necessário, poste-os mais e, sobre isso, ele diz - está tudo bem, estou vivo.
Muitas vezes ouvimos a pergunta "como podemos testar isso em dados de combate?" Por exemplo, estamos falando do mesmo serviço de pedidos. O pedido envia mensagens para o armazém onde as mercadorias são baixadas: não podemos testar isso nos dados de combate, porque "minhas mercadorias serão baixadas!" Saída: no estágio inicial, planeje todo esse teste. Você tem testes de unidade que zombam. Portanto, faça isso em um nível mais profundo, onde você terá um canal de comunicação que não prejudicará os negócios.
Nível de infraestrutura
Monitoramento de infraestrutura é o que há muito tempo é considerado monitoramento em si.
- O monitoramento da infraestrutura pode e deve ser iniciado como um processo separado.
- Você não deve começar monitorando a infraestrutura em um projeto em funcionamento, mesmo se realmente quiser. Isso é uma ferida para todos os devops. "Primeiro monitoro o cluster, monitoro a infraestrutura" - ou seja, Primeiro, ele monitora o que está abaixo, mas não entra no aplicativo. Porque o aplicativo é uma coisa incompreensível para a devopa. Eles vazaram para ele, e ele não entende como isso funciona. E ele entende a infraestrutura e começa com ela. Mas não - você sempre precisa monitorar o aplicativo primeiro.
- . , , - . on-call, , « ». .
-
:
- ELK. . - , .
- APM. APM (NewRelic, BlackFire, Datadog). , - , .
- Tracing. , . , tracing — . – ! . Jaeger/Zipkin
- : . Grafana. PagerDuty. (, …). ,
- : ( , ). Oncall : , , , — ( — , : , ). , — (« — »), .
- « » workflow : , , . , — ; .
, :
- — Prometheus + Grafana;
- — ELK;
- APM Tracing — Jaeger (Zipkin).
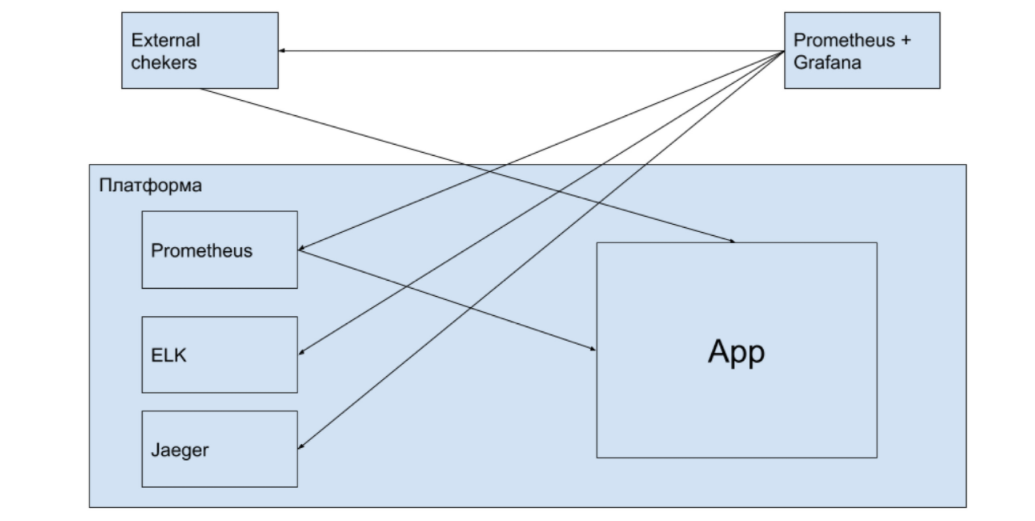
. , , , . , . , , , — .
, :
Prometheus Kubernetes — ?! , ? , , — , .
. . , Promtheus, , , . ? , , .
Conclusões
- — , . 98% — . , , , --.
- : 30% , .
- , , - , — . , — .
- ( ) — .
- , , « » — , .
Saint Highload++.UPD ( ):
1. , , , «, , , ». , : DevOps , — , , , .
2. Não estou tentando sugerir, eles dizem, "tudo está ruim em todos os lugares, mas podemos monitorá-lo - venha para o ITSumma". Não, se o projeto for lançado, o monitoramento não poderá ser realizado por uma empresa terceirizada. Obviamente, também temos objetivos de negócios, e o que realmente estamos pensando em fazer é introduzir consultoria para apoiar o projeto no processo de seu desenvolvimento, a fim de transmitir como é correto, do lado do desenvolvimento, realizar a parte de monitoramento.Se você está interessado em minhas idéias e pensamentos, e assim por diante, pode
ler o canal :-)