Após o
comitê de 2019-03 , ocorreu o congelamento de recursos. Temos uma coluna quase tradicional aqui:
já escrevemos sobre o congelamento do ano passado. Agora, os resultados de 2019: qual dos novos será incluído no PostgreSQL 12. Nesta parte da revisão dedicada ao JSONPath, são usados exemplos e fragmentos do relatório "Postgres 12 in Etudes", que Oleg Bartunov leu no
Saint Highload ++ em São Petersburgo, no dia 9 de abril deste ano.
Jsonpath
Tudo relacionado ao JSON (B) é relevante, na demanda mundial, na Rússia, e esta é uma das áreas mais importantes de desenvolvimento do Postgres Professional. O tipo jsonb, funções e operadores para trabalhar com JSON / JSONB apareceram no PostgreSQL versão 9.4, eles foram criados por uma equipe liderada por Oleg Bartunov.
O padrão SQL / 2016 prevê trabalhar com JSON: JSONPath é mencionado lá - um conjunto de ferramentas de endereçamento de dados dentro do JSON; JSONTABLE - meio de converter JSON em tabelas regulares; Uma grande família de funções e operadores. Apesar de o JSON no Postgres ter sido suportado por um longo tempo, em 2017 Oleg Bartunov e seus colegas começaram a trabalhar no suporte ao padrão. Cumprir com o padrão é sempre bom. De tudo o que é descrito no padrão, apenas um, mas o patch mais importante, é o JSONPath na versão 12, portanto, falaremos sobre isso em primeiro lugar.
Nos tempos antigos, as pessoas usavam JSON, armazenando-o em campos de texto. Na 9.3, um tipo de dados especial para JSON apareceu, mas a funcionalidade associada a ele não era rica e as solicitações com esse tipo funcionaram lentamente devido ao tempo gasto na análise da representação de texto de JSON. Isso interrompeu muitos usuários em potencial do Postgres que preferiram os bancos de dados NoSQL. A produtividade do Postgres aumentou em 9,4 quando, graças a O. Bartunov, A. Korotkov e F. Sigaev, o Postgres introduziu uma versão binária do JSON - o tipo jsonb.
O jsonb não precisa ser analisado todas as vezes, portanto, trabalhar com ele é muito mais rápido. Das novas funções e operadores que surgiram ao mesmo tempo, alguns funcionam apenas com um novo tipo binário, como o importante operador de ocorrência
@> , que verifica se um elemento ou matriz está incluído em um determinado JSONB:
SELECT '[1, 2, 3]'::jsonb @> '[1, 3]'::jsonb;
dá TRUE, já que a matriz do lado direito entra na matriz da esquerda. Mas
SELECT '[1, 2, [1, 3]]'::jsonb @> '[1, 3]'::jsonb;
dará FALSE, já que o nível de aninhamento é diferente, ele deve ser definido explicitamente. O operador de existência é introduzido para o tipo jsonb
? (um ponto de interrogação) que verifica se uma sequência é uma chave de objeto ou um elemento de uma matriz no nível superior dos valores JSONB, além de mais dois operadores semelhantes (detalhes
aqui ). Eles são suportados por índices GIN com duas classes de operadores GIN. O operador
-> (seta) permite "navegar" pelo JSONB, ele retorna um valor por chave ou, se for uma matriz, por índice. Existem
vários outros operadores para se mover. Mas não há como organizar filtros que funcionem de maneira semelhante a WHERE. Foi uma inovação: graças ao jsonb, o Postgres começou a crescer em popularidade como um RDBMS com recursos NoSQL.
Em 2014, A. Korotkov, O. Bartunov e F. Sigaev desenvolveram a extensão jsquery, que foi incluída como resultado no Postgres Pro Standard 9.5 (e em versões posteriores do Standard e Enterprise). Ele fornece recursos adicionais muito amplos para trabalhar com o json (b). Essa extensão define a linguagem de consulta para extrair dados de json (b) e índices para acelerar essas consultas. Essa funcionalidade era exigida pelos usuários, eles não estavam prontos para aguardar o padrão e a inclusão de novos recursos na versão vanilla. O valor prático também é evidenciado pelo fato de o desenvolvimento ter sido patrocinado pela Wargaming.net. A extensão implementa um tipo especial - jsquery.
Uma consulta nesse idioma é compacta e se parece, por exemplo, com esta:
SELECT '{"apt":[{"no": 1, "rooms":2}, {"no": 2, "rooms":3}, {"no": 3, "rooms":2}]}'::jsonb @@ 'apt.#.rooms=3'::jsquery;
Estamos perguntando aqui se existem "três rublos" no prédio. O tipo jsquery deve ser especificado porque o operador @@ agora também está no tipo jsonb. A descrição está
aqui e a apresentação com muitos exemplos está
aqui .
Total: o Postgres já tinha tudo para trabalhar com JSON e, em seguida, o padrão SQL: 2016 apareceu. Aconteceu que sua semântica não é tão diferente da nossa na extensão jsquery. É possível que os autores do padrão tenham olhado para jsquery, inventando o JSONPath. Nossa equipe teve que implementar um pouco diferente do que já tínhamos e, é claro, muitas coisas novas também.
Mais de um ano atrás, no commitfest de março, os frutos de nossos esforços de programação foram oferecidos à comunidade na forma de 3 grandes patches com suporte para o padrão
SQL: 2016 :
SQL / JSON: JSONPath;
SQL / JSON: funções;
SQL / JSON: JSON_TABLE.
Mas desenvolver um patch não é o negócio todo, promovê-los também não é fácil, especialmente se os patches forem grandes e afetarem muitos módulos. Muitas iterações de revisão de revisão são necessárias, o patch deve ser promovido, como as empresas comerciais, investindo muitos recursos (horas-homem). O arquiteto-chefe do Postgres Professional, Alexander Korotkov, assumiu a responsabilidade (já que agora tem o status de committer) e garantiu a adoção do patch JSONPath - o principal nesta série de patches. O segundo e o terceiro estão agora no status de Revisão de necessidades. O JSONPath focado permite que você trabalhe com a estrutura JSON (B) e é flexível o suficiente para destacar seus fragmentos. Dos 15 pontos prescritos no padrão, 14 são implementados, e isso é mais do que no Oracle, MySQL e MS SQL.
A notação JSONPath difere das instruções do Postgres por trabalhar com a notação JSON e JSQuery. A hierarquia é indicada por pontos:
$ .abc (na notação do postgres 11, eu precisaria escrever 'a' -> 'b' -> 'c');
$ - o contexto atual do elemento - de fato, a expressão com $ define a região json (b) que deve ser processada, incluindo a região do filtro, o restante não está disponível para trabalho;
@ - o contexto atual na expressão de filtro - itera sobre os caminhos disponíveis na expressão com $;
[*] - uma matriz;
* - curinga, na expressão com $ ou @ significa qualquer valor do segmento de caminho, mas levando em consideração a hierarquia;
** - como parte da expressão com $ ou @ pode significar qualquer valor do segmento de caminho sem levar em conta a hierarquia - é conveniente usá-lo se você não souber o nível de aninhamento de elementos;
operador "?" permite organizar um filtro semelhante a WHERE:
$ .abc? (@ .x> 10);
$ .abcxtype (), bem como tamanho (), duplo (), teto (), piso (), abs (), datetime (), keyvalue () são métodos.
Uma consulta com a função jsonb_path_query (sobre as funções abaixo) pode ter esta aparência:
SELECT jsonb_path_query_array('[1,2,3,4,5]', '$[*] ? (@ > 3)'); jsonb_path_query_array
Embora um patch especial com funções não seja confirmado, o patch JSONPath já possui funções-chave para trabalhar com JSON (B):
jsonb_path_exists('{"a": 1}', '$.a') true ( "?") jsonb_path_exists('{"a": 1}', '$.b') false jsonb_path_match('{"a": 1}', '$.a == 1') true ( "@>") jsonb_path_match('{"a": 1}', '$.a >= 2') false jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') 3, 4, 5 jsonb_path_query('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') 0 jsonb_path_query_array('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') [3, 4, 5] jsonb_path_query_array('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') [] jsonb_path_query_first('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 2)') 3 jsonb_path_query_first('{"a": [1,2,3,4,5]}', '$.a[*] ? (@ > 5)') NULL
Observe que a igualdade nas expressões JSONPath é um único "=", enquanto no jsquery é o dobro: "==".
Para ilustrações mais elegantes, geraremos JSONB em uma placa de casa com uma coluna:
CREATE TABLE house(js jsonb); INSERT INTO house VALUES ('{ "address": { "city":"Moscow", "street": "Ulyanova, 7A" }, "lift": false, "floor": [ { "level": 1, "apt": [ {"no": 1, "area": 40, "rooms": 1}, {"no": 2, "area": 80, "rooms": 3}, {"no": 3, "area": 50, "rooms": 2} ] }, { "level": 2, "apt": [ {"no": 4, "area": 100, "rooms": 3}, {"no": 5, "area": 60, "rooms": 2} ] } ] }');
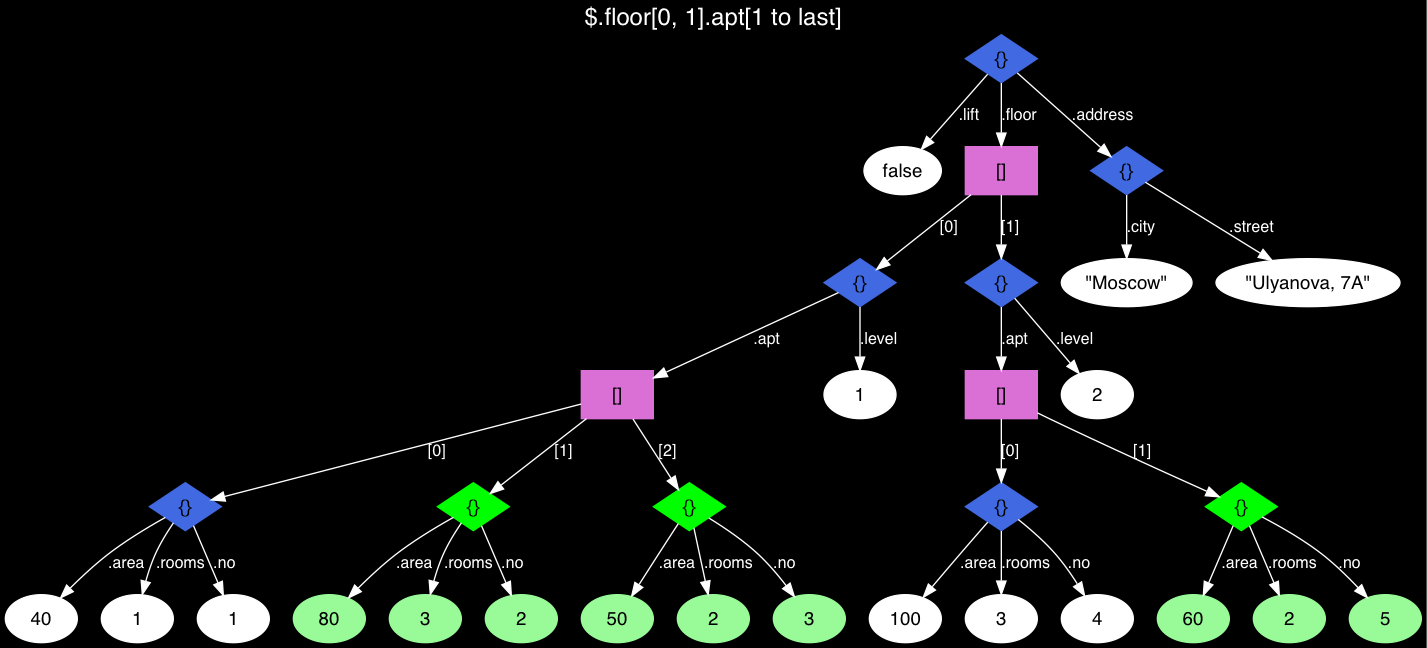 Fig. 1 Árvore JSON de habitação com apartamentos de folhas alocados.
Fig. 1 Árvore JSON de habitação com apartamentos de folhas alocados.Esse é um JSON estranho: ele tem uma hierarquia confusa, mas é tirada da vida e, na vida, muitas vezes é necessário trabalhar com o que é e não com o que deveria ser. Munidos dos recursos da nova versão, encontraremos apartamentos no 1º e 2º andares, mas não o primeiro na lista de apartamentos (na árvore, eles são destacados em verde):
SELECT jsonb_path_query_array(js, '$.floor[0, 1].apt[1 to last]') FROM house;
No PostgreSQL 11, você deve perguntar o seguinte:
SELECT jsonb_agg(apt) FROM ( SELECT apt->generate_series(1, jsonb_array_length(apt) - 1) FROM ( SELECT js->'floor'->unnest(array[0, 1])->'apt' FROM house ) apts(apt) ) apts(apt);
Agora, uma pergunta muito simples: existem linhas contendo (em qualquer lugar) o valor "Moscow"? Realmente simples:
SELECT jsonb_path_exists(js, '$.** ? (@ == "Moscow")') FROM house;
Na versão 11, você teria que escrever um script enorme:
WITH RECURSIVE t(value) AS ( SELECT * FROM house UNION ALL ( SELECT COALESCE(kv.value, e.value) AS value FROM t LEFT JOIN LATERAL jsonb_each ( CASE WHEN jsonb_typeof(t.value) = 'object' THEN t.value ELSE NULL END ) kv ON true LEFT JOIN LATERAL jsonb_array_elements ( CASE WHEN jsonb_typeof(t.value) = 'array' THEN t.value ELSE NULL END ) e ON true WHERE kv.value IS NOT NULL OR e.value IS NOT NULL ) ) SELECT EXISTS (SELECT 1 FROM t WHERE value = '"Moscow"');
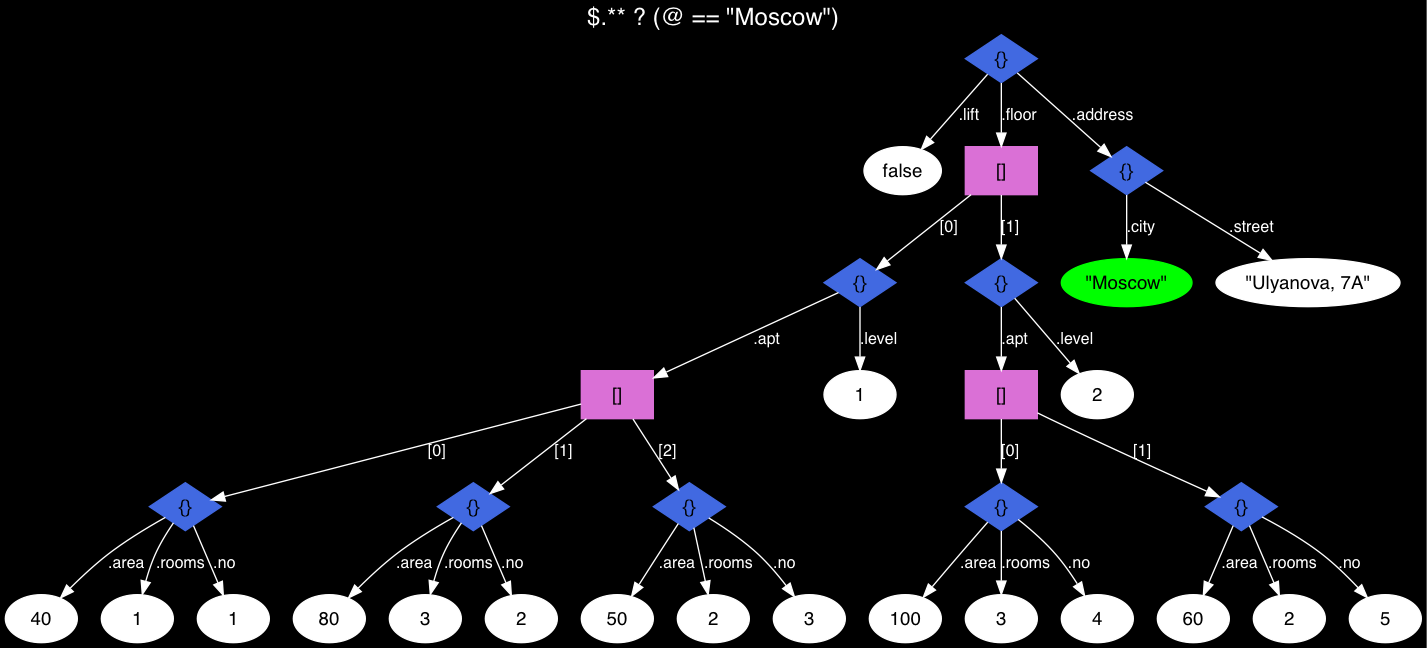 Fig. 2 Árvore da habitação JSON, Moscou foi encontrada!
Fig. 2 Árvore da habitação JSON, Moscou foi encontrada!Estamos à procura de qualquer apartamento em qualquer andar com uma área de 40 a 90 m²:
select jsonb_path_query(js, '$.floor[*].apt[*] ? (@.area > 40 && @.area < 90)') FROM house; jsonb_path_query ----------------------------------- {"no": 2, "area": 80, "rooms": 3} {"no": 3, "area": 50, "rooms": 2} {"no": 5, "area": 60, "rooms": 2} (3 rows)
Estamos à procura de apartamentos com quartos após o dia 3, usando o nosso alojamento jason:
SELECT jsonb_path_query(js, '$.floor.apt.no ? (@>3)') FROM house; jsonb_path_query
E aqui está como o jsonb_path_query_first funciona:
SELECT jsonb_path_query_first(js, '$.floor.apt.no ? (@>3)') FROM house; jsonb_path_query_first
Vemos que apenas o primeiro valor é selecionado que satisfaz a condição do filtro.
O operador booleano JSONPath para JSONB @@ é chamado de operador correspondente. Ele calcula o predicado JSONPath chamando a função jsonb_path_match_opr.
Outro operador booleano é @? - este é um teste de existência, responde à pergunta se a expressão JSONPath retornará objetos SQL / JSON, chama a função jsonb_path_exists_opr:
'[1,2,3]' @@ '$[*] == 3' true; '[1,2,3]' @? '$[*] @? (@ == 3)' - true
O mesmo resultado pode ser alcançado usando operadores diferentes:
js @? '$.a' js @@ 'exists($.a)' js @@ '$.a == 1' js @? '$ ? ($.a == 1)'
A beleza dos operadores booleanos JSONPath é que eles são suportados, acelerados pelos índices GIN. jsonb_ops e jsonb_path_ops são as classes de operadores correspondentes. No exemplo, desabilitamos o SEQSCAN, já que temos uma microtable, em tabelas grandes o próprio otimizador selecionará o Índice de bitmap:
SET ENABLE_SEQSCAN TO OFF; CREATE INDEX ON house USING gin (js); EXPLAIN (COSTS OFF) SELECT * FROM house WHERE js @? '$.floor[*].apt[*] ? (@.rooms == 3)'; QUERY PLAN
Todas as funções do formato jsonb_path_xxx () têm a mesma assinatura:
jsonb_path_xxx( js jsonb, jsp jsonpath, vars jsonb DEFAULT '{}', silent boolean DEFAULT false )
vars é um objeto JSONB para transmitir variáveis JSONPath:
SELECT jsonb_path_query_array('[1,2,3,4,5]', '$[*] ? (@ > $x)', vars => '{"x": 2}'); jsonb_path_query_array
É difícil ficar sem vars quando fazemos uma junção envolvendo um campo do tipo jsonb em uma das tabelas. Digamos que fazemos um aplicativo que procure apartamentos adequados para os funcionários daquela casa que anotaram seus requisitos para a área mínima do questionário:
CREATE TABLE demands(name text, position text, demand int); INSERT INTO demands VALUES ('','', 85), ('',' ', 45); SELECT jsonb_path_query(js, '$.floor[*].apt[*] ? (@.area >= $min)', vars => jsonb_build_object('min', demands.demand)) FROM house, demands WHERE name = ''; -[ RECORD 1 ]
Lucky Pasha pode escolher entre 4 apartamentos. Mas vale a pena alterar 1 letra na solicitação - de "P" para "C", e não haverá escolha! Apenas 1 apartamento servirá.
Mais uma palavra-chave permanece: silencioso é um sinalizador que suprime o tratamento de erros; eles estão na consciência do programador.
SELECT jsonb_path_query('[]', 'strict $.a'); ERROR: SQL/JSON member not found DETAIL: jsonpath member accessor can only be applied to an object
O erro Mas isso não será um erro:
SELECT jsonb_path_query('[]', 'strict $.a', silent => true); jsonb_path_query
A propósito, sobre erros: de acordo com o padrão, erros aritméticos nas expressões não emitem mensagens de erro, eles estão na consciência do programador:
SELECT jsonb_path_query('[1,0,2]', '$[*] ? (1/ @ >= 1)'); jsonb_path_query
Ao calcular a expressão no filtro, os valores da matriz são pesquisados, dentre os quais há 0, mas dividir por 0 não gera um erro.
As funções funcionarão de maneira diferente, dependendo do modo selecionado: Estrito ou Relaxado (na tradução “não estrito” ou até “solto”, é selecionado por padrão). Suponha que estamos procurando uma chave no modo Lax no JSON, onde obviamente não é:
SELECT jsonb '{"a":1}' @? 'lax $.b ? (@ > 1)'; ?column?
Agora no modo estrito:
SELECT jsonb '{"a":1}' @? 'strict $.b ? (@ > 1)'; ?column?
Ou seja, onde, no modo liberal, recebemos FALSE, com rigor obtemos NULL.
No modo relaxado, uma matriz com uma hierarquia complexa [1,2, [3,4,5]] sempre se expande para [1,2,3,4,5]:
SELECT jsonb '[1,2,[3,4,5]]' @? 'lax $[*] ? (@ == 5)'; ?column?
No modo Rigoroso, o número “5” não será encontrado, pois não está na parte inferior da hierarquia. Para encontrá-lo, você precisa modificar a consulta, substituindo "@" por "@ [*]":
SELECT jsonb '[1,2,[3,4,5]]' @? 'strict $[*] ? (@[*] == 5)'; ?column?
No PostgreSQL 12, JSONPath é um tipo de dados. O padrão não diz nada sobre a necessidade de um novo tipo, é uma propriedade de implementação. Com o novo tipo, obtemos um trabalho completo com jsonpath com a ajuda de operadores e índices que aceleram seu trabalho, que já existe para o JSONB. Caso contrário, o JSONPath teria que ser integrado no nível do código do executor e do otimizador.
Você pode ler sobre a sintaxe SQL / JSON, por exemplo,
aqui .
A postagem do blog de Oleg Bartunov é sobre
conformidade com o padrão SQL / JSON-2016 para PostgreSQL, Oracle, SQL Server e MySQL.
Aqui está uma
apresentação sobre SQL / JSON.
E aqui está uma
introdução ao SQL / JSON.