 A Variti desenvolve proteção contra ataques de bots e DDoS e também realiza testes de estresse e carga. Na conferência HighLoad ++ 2018, conversamos sobre como proteger recursos de vários tipos de ataques. Em resumo: isole partes do sistema, use serviços em nuvem e CDN e atualize regularmente. Mas sem empresas especializadas, proteção você ainda não pode fazer :)
A Variti desenvolve proteção contra ataques de bots e DDoS e também realiza testes de estresse e carga. Na conferência HighLoad ++ 2018, conversamos sobre como proteger recursos de vários tipos de ataques. Em resumo: isole partes do sistema, use serviços em nuvem e CDN e atualize regularmente. Mas sem empresas especializadas, proteção você ainda não pode fazer :)Antes de ler o texto, você pode se familiarizar com pequenos resumos
no site da conferência .
E se você não gosta de ler ou apenas deseja assistir a um vídeo, a gravação do nosso relatório está abaixo do spoiler.
Muitas empresas já sabem como realizar testes de estresse, mas nem todas fazem testes de estresse. Alguns de nossos clientes pensam que seu site é invulnerável porque possui um sistema de carga alta e protege contra ataques. Mostramos que isso não é inteiramente verdade.
Obviamente, antes de realizar os testes, obtemos permissão do cliente, assinada e carimbada e, com nossa ajuda, não podemos fazer um ataque DDoS a ninguém. Os testes são realizados no horário escolhido pelo cliente, quando o atendimento de seus recursos é mínimo e os problemas de acesso não afetam os clientes. Além disso, como algo sempre pode dar errado durante o processo de teste, temos contato constante com o cliente. Isso permite não apenas relatar os resultados alcançados, mas também alterar algo durante o teste. No final do teste, sempre elaboramos um relatório no qual apontamos as falhas descobertas e fazemos recomendações para eliminar os pontos fracos do site.
Como trabalhamos
Durante o teste, emulamos uma botnet. Como trabalhamos com clientes que não estão localizados em nossas redes, para impedir que o teste termine no primeiro minuto devido ao acionamento de limites ou proteção, carregamos a carga não de um IP, mas de nossa própria sub-rede. Além disso, para criar uma carga significativa, temos nosso próprio servidor de teste bastante poderoso.
Postulados
Muito não é bom
Quanto menos carga pudermos levar o recurso à falha, melhor. Se você conseguir fazer com que o site pare de funcionar com uma solicitação por segundo, ou mesmo com uma solicitação por minuto, tudo bem. Porque, de acordo com a lei da maldade, usuários ou atacantes acidentalmente se enquadram nessa vulnerabilidade.
Falha parcial é melhor que falha completa
Sempre aconselhamos tornar os sistemas heterogêneos. Além disso, vale a pena separá-los no nível físico, e não apenas na conteinerização. No caso de separação física, mesmo que algo falhe no site, é provável que ele não pare de funcionar completamente, e os usuários ainda terão acesso a pelo menos parte da funcionalidade.
Arquitetura adequada é a base da sustentabilidade
A tolerância a falhas de um recurso e sua capacidade de suportar ataques e cargas devem ser estabelecidas no estágio de design, na verdade, no estágio de desenhar os primeiros diagramas de bloco em um notebook. Porque se erros fatais aparecerem, você poderá corrigi-los no futuro, mas é muito difícil.
Não apenas o código deve ser bom, mas também uma configuração
Muitas pessoas pensam que uma boa equipe de desenvolvimento é uma garantia de resiliência do serviço. Uma boa equipe de desenvolvimento é realmente necessária, mas também deve haver uma boa operação, bons DevOps. Ou seja, precisamos de especialistas que configurem corretamente o Linux e a rede, gravem corretamente as configurações no nginx, configurem limites e muito mais. Caso contrário, o recurso funcionará bem apenas no teste e, em algum momento da produção, tudo quebrará.
Diferenças entre estresse e teste de estresse
O teste de carga permite identificar os limites do sistema. O teste de estresse visa encontrar as fraquezas do sistema e é usado para quebrar esse sistema e ver como ele se comportará no processo de falha de certas partes. Ao mesmo tempo, a natureza da carga geralmente permanece desconhecida para o cliente até o início do teste de estresse.
Recursos distintos dos ataques L7
Geralmente, dividimos os tipos de carga em cargas nos níveis L7 e L3 e 4. L7 é uma carga no nível do aplicativo, na maioria das vezes é entendida apenas como HTTP, mas queremos dizer qualquer carga no nível do protocolo TCP.
Os ataques L7 têm certas características distintivas. Em primeiro lugar, eles vêm diretamente para o aplicativo, ou seja, é improvável que possam ser refletidos por meios de rede. Tais ataques usam lógica e, por isso, consomem CPU, memória, disco, banco de dados e outros recursos de maneira muito eficiente e com pouco tráfego.
Inundação HTTP
No caso de qualquer ataque, a carga é mais fácil de criar do que manipular, e no caso de L7 isso também é verdade. Nem sempre é fácil distinguir o tráfego de ataque do legítimo, e na maioria das vezes isso pode ser feito com frequência, mas se tudo for planejado corretamente, será impossível entender onde está o ataque e onde estão os pedidos legítimos dos logs.
Como primeiro exemplo, considere um ataque HTTP Flood. O gráfico mostra que geralmente esses ataques são muito poderosos, no exemplo abaixo, o número máximo de solicitações excedeu 600 mil por minuto.

O HTTP Flood é a maneira mais fácil de criar uma carga. Geralmente, é utilizado algum tipo de ferramenta de teste de carga, por exemplo, ApacheBench, e a solicitação e a finalidade são definidas. Com uma abordagem tão simples, é provável que ocorra o cache do servidor, mas é fácil contornar isso. Por exemplo, adicionando linhas aleatórias à consulta, o que força o servidor a fornecer constantemente uma página nova.
Além disso, não se esqueça do user-agent no processo de criação de uma carga. Muitos user-agents de ferramentas de teste populares são filtrados pelos administradores do sistema e, nesse caso, a carga pode simplesmente não atingir o back-end. Você pode melhorar significativamente o resultado inserindo um cabeçalho mais ou menos válido do navegador na solicitação.
Por toda a sua simplicidade, os ataques do HTTP Flood têm suas desvantagens. Em primeiro lugar, são necessárias grandes capacidades para criar uma carga. Em segundo lugar, esses ataques são muito fáceis de detectar, principalmente se vierem do mesmo endereço. Como resultado, as solicitações começam a ser filtradas imediatamente pelos administradores do sistema ou mesmo no nível do provedor.
O que procurar
Para reduzir o número de solicitações por segundo e ainda não perder eficiência, você precisa mostrar um pouco de imaginação e explorar o site. Portanto, você pode carregar não apenas o canal ou servidor, mas também partes individuais do aplicativo, por exemplo, bancos de dados ou sistemas de arquivos. Você também pode procurar lugares no site que fazem ótimos cálculos: calculadoras, páginas de seleção de produtos e muito mais. Finalmente, acontece frequentemente que existe um script php no site que gera uma página de várias centenas de milhares de linhas. Esse script também carrega muito o servidor e pode se tornar um alvo de ataque.
Onde procurar
Quando analisamos um recurso antes do teste, antes de tudo, é claro, olhamos para o próprio site. Estamos procurando por todos os tipos de campos de entrada, arquivos pesados - em geral, tudo o que possa criar problemas para um recurso e diminuir sua operação. Aqui, ferramentas de desenvolvimento comuns no Google Chrome e Firefox ajudam a mostrar o tempo de resposta da página.
Também analisamos subdomínios. Por exemplo, existe uma determinada loja online, abc.com, e ela tem um subdomínio admin.abc.com. Provavelmente, este é o painel de administração com autorização, mas se você colocar um carregamento nele, ele poderá criar problemas para o recurso principal.
O site pode ter um subdomínio api.abc.com. Provavelmente, este é um recurso para aplicativos móveis. O aplicativo pode ser encontrado na App Store ou no Google Play, colocar um ponto de acesso especial, dissecar a API e registrar contas de teste. O problema é que muitas vezes as pessoas pensam que tudo o que é protegido por autorização é imune a ataques de negação de serviço. Alegadamente, a autorização é o melhor CAPTCHA, mas não é. Fazer 10 a 20 contas de teste é simples e, ao criá-las, obtemos acesso a funcionalidades complexas e indisfarçadas.
Naturalmente, analisamos o histórico, no robots.txt e no WebArchive, ViewDNS, procuramos versões antigas do recurso. Às vezes acontece que os desenvolvedores lançaram, digamos, mail2.yandex.net, mas a versão antiga, mail.yandex.net, permaneceu. Esse mail.yandex.net não é mais suportado, os recursos de desenvolvimento não são alocados a ele, mas continua consumindo o banco de dados. Assim, usando a versão antiga, você pode usar efetivamente os recursos do back-end e tudo o que está por trás do layout. Obviamente, isso nem sempre acontece, mas ainda encontramos algo assim com bastante frequência.
Naturalmente, dissecamos todos os parâmetros de solicitação, estrutura de cookies. Você pode, por exemplo, inserir algum valor na matriz JSON dentro do cookie, criar mais aninhamentos e tornar o recurso excessivamente longo.
Carga de pesquisa
A primeira coisa que vem à mente ao pesquisar um site é carregar o banco de dados, já que quase todo mundo tem uma pesquisa e quase todo mundo a possui, infelizmente, está mal protegida. Por alguma razão, os desenvolvedores não prestam atenção suficiente à pesquisa. Mas há uma recomendação - não faça o mesmo tipo de solicitações, pois você pode encontrar armazenamento em cache, como é o caso da inundação HTTP.
Fazer consultas aleatórias no banco de dados também nem sempre é eficiente. É muito melhor criar uma lista de palavras-chave relevantes para a pesquisa. Se você voltar ao exemplo de uma loja on-line: digamos que o site vende pneus de carros e permite definir o raio dos pneus, o tipo de carro e outros parâmetros. Assim, combinações de palavras relevantes farão o banco de dados funcionar em condições muito mais complexas.
Além disso, vale a pena usar a paginação: é muito mais difícil para uma pesquisa retornar a penúltima página de um problema do que a primeira. Ou seja, com a ajuda da paginação, você pode diversificar um pouco a carga.
No exemplo abaixo, mostramos a carga na pesquisa. Pode-se observar que, a partir do primeiro segundo do teste, a uma velocidade de dez solicitações por segundo, o site caiu e não respondeu.
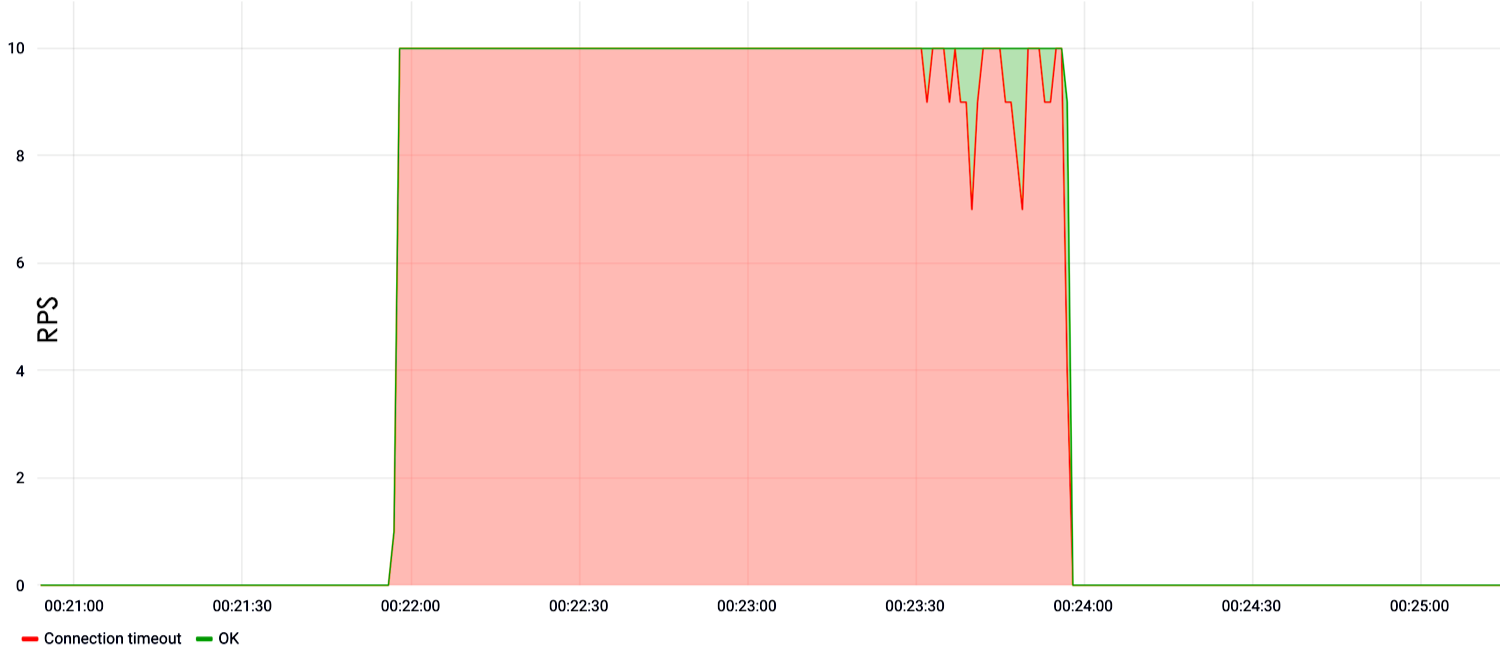
Se não houver pesquisa?
Se não houver pesquisa, isso não significa que o site não contenha outros campos de entrada vulneráveis. Este campo pode ser uma autorização. Agora, os desenvolvedores gostam de criar hashes complexos para proteger o banco de dados de login de ataques a tabelas arco-íris. Isso é bom, mas esses hashes consomem grandes recursos da CPU. Um grande fluxo de autorizações falsas leva a uma falha do processador e, como resultado, o site para de funcionar na saída.
A presença no site de todos os tipos de formulários para comentários e feedback é uma ocasião para enviar textos muito grandes para lá ou simplesmente criar uma inundação maciça. Às vezes, os sites aceitam anexos de arquivos, inclusive no formato gzip. Nesse caso, pegamos um arquivo de 1 TB, usando o gzip, compactamos para alguns bytes ou kilobytes e o enviamos para o site. Depois é descompactado e é obtido um efeito muito interessante.
API Rest
Gostaria de prestar um pouco de atenção a serviços populares como a API Rest. Proteger a API Rest é muito mais difícil do que um site comum. Para a API Rest, mesmo métodos triviais de proteção contra quebra de senha e outras atividades ilegítimas não funcionam.
A API Rest é muito fácil de quebrar porque acessa o banco de dados diretamente. Ao mesmo tempo, a falha de um serviço desse tipo acarreta consequências bastante sérias para os negócios. O fato é que a API Rest normalmente envolve não apenas o site principal, mas também o aplicativo móvel, alguns recursos internos de negócios. E se tudo isso cair, o efeito será muito mais forte do que no caso de falha de um site simples.
Carga de conteúdo pesado
Se nos oferecerem o teste de algum aplicativo comum de uma página, página inicial, site de cartão de visita, que não possui funcionalidade complexa, estamos procurando conteúdo pesado. Por exemplo, fotos grandes que o servidor fornece, arquivos binários, documentação em pdf - estamos tentando fazer tudo isso. Esses testes carregam bem o sistema de arquivos e entupem os canais e, portanto, são eficazes. Ou seja, mesmo que você não desligue o servidor, baixando um arquivo grande em baixa velocidade, você simplesmente obstruirá o canal do servidor de destino e ocorrerá uma negação de serviço.
Um exemplo desse teste mostra que, a uma velocidade de 30 RPS, o site parou de responder ou gerou 500 erros no servidor.

Não se esqueça de configurar servidores. Muitas vezes, você pode descobrir que uma pessoa comprou uma máquina virtual, instalou o Apache lá, configurou tudo por padrão, localizou um aplicativo php e, abaixo, você pode ver o resultado.

Aqui, a carga foi para a raiz e atingiu apenas 10 RPS. Esperamos 5 minutos e o servidor travou. No final, no entanto, não se sabe por que ele caiu, mas há uma suposição de que ele simplesmente estava cheio de memória e, portanto, parou de responder.
Baseado em ondas
Nos últimos dois anos, ataques de onda se tornaram bastante populares. Isso se deve ao fato de muitas organizações comprarem determinadas peças de hardware para proteção contra DDoS, que exigem uma certa quantidade de estatísticas para começar a filtrar ataques. Ou seja, eles não filtram o ataque nos primeiros 30 a 40 segundos, porque acumulam dados e aprendem. Assim, nesses 30 a 40 segundos, você pode iniciar tanto que o recurso permanecerá por um longo tempo até que todas as solicitações sejam processadas.
No caso do ataque, houve um intervalo de 10 minutos abaixo, após o qual uma nova parte modificada do ataque chegou.

Ou seja, a defesa treinada começou a filtrar, mas uma nova parte completamente diferente do ataque chegou e a defesa começou a treinar novamente. De fato, a filtragem para de funcionar, a proteção se torna ineficaz e o site fica inacessível.
Os ataques de onda são caracterizados por valores muito altos no pico, podendo atingir cem mil ou um milhão de solicitações por segundo, no caso de L7. Se falamos de L3 e 4, pode haver centenas de gigabits de tráfego ou, consequentemente, centenas de mpps, se você contar em pacotes.
O problema com esses ataques é a sincronização. Os ataques vêm de uma botnet e, para criar um pico único muito grande, é necessário um alto grau de sincronização. E essa coordenação nem sempre funciona: às vezes a saída é algum tipo de pico parabólico, que parece bastante patético.
Não HTTP unificado
Além do HTTP no nível L7, adoramos explorar outros protocolos. Como regra, um site comum, especialmente uma hospedagem comum, possui protocolos de correio e o MySQL se destaca. Os protocolos de correio são menos afetados que os bancos de dados, mas também podem ser carregados com bastante eficiência e obter uma CPU sobrecarregada no servidor na saída.
Com a ajuda da vulnerabilidade SSH 2016, tivemos bastante sucesso. Agora, essa vulnerabilidade foi corrigida para quase todos, mas isso não significa que o SSH não possa ser carregado. Você pode. Apenas uma grande quantidade de autorizações é atendida, o SSH consome quase toda a CPU no servidor e, em seguida, o site já é composto de uma ou duas solicitações por segundo.
Portanto, essas uma ou duas consultas de log não podem ser distinguidas de uma carga legítima.
As muitas conexões que abrimos nos servidores permanecem relevantes. Anteriormente, o Apache pecava, agora o nginx realmente pecava, pois geralmente é configurado por padrão. O número de conexões que o nginx pode manter aberto é limitado; portanto, abrimos esse número de conexões, a nova conexão nginx não aceita mais e o site não funciona na saída.
Nosso cluster de teste tem CPU suficiente para atacar o handshake SSL. Em princípio, como mostra a prática, as redes de bots às vezes também gostam disso. Por um lado, é claro que você não pode ficar sem o SSL, porque a emissão, a classificação e a segurança do Google. SSL, por outro lado, infelizmente tem um problema de CPU.
L3 e 4
Quando falamos sobre um ataque nos níveis L3 e 4, geralmente falamos sobre um ataque no nível do canal. Essa carga quase sempre é distinguível de legítima se não for um ataque de inundação SYN. O problema dos ataques de inundação SYN para recursos de segurança é grande. O valor máximo de L3 e 4 foi de 1,5-2 Tb / s. Esse tráfego é muito difícil de lidar, mesmo para grandes empresas, incluindo Oracle e Google.
SYN e SYN-ACK são os pacotes usados para estabelecer a conexão. Portanto, é difícil distinguir o SYN-flood de uma carga legítima: não está claro que seja o SYN, que veio estabelecer a conexão ou parte do flood.
Inundação UDP
Normalmente, os invasores não têm os recursos que temos, portanto a amplificação pode ser usada para organizar ataques. Ou seja, um invasor verifica a Internet e encontra servidores vulneráveis ou configurados incorretamente, que, por exemplo, em resposta a um pacote SYN, respondem com três SYN-ACKs. Ao fingir o endereço de origem do endereço do servidor de destino, você pode usar um pacote para aumentar a capacidade, digamos, três vezes, e redirecionar o tráfego para a vítima.

O problema das amplificações é a sua detecção complexa. A partir dos exemplos mais recentes, podemos citar o caso sensacional com o vulnerável memcached. Além disso, agora existem muitos dispositivos IoT, câmeras IP, que também são configurados principalmente por padrão e, por padrão, são configurados incorretamente; portanto, por meio desses dispositivos, os atacantes costumam fazer ataques.

Difícil SYN-flood
O SYN-flood é provavelmente a visão mais interessante de todos os ataques do ponto de vista do desenvolvedor. O problema é que geralmente os administradores de sistema usam bloqueio de IP para proteção. Além disso, o bloqueio de IP afeta não apenas os administradores de sistemas que operam de acordo com os scripts, mas, infelizmente, alguns sistemas de segurança comprados por muito dinheiro.
Esse método pode se transformar em uma catástrofe, porque se os invasores mudarem seus endereços IP, a empresa bloqueará sua própria sub-rede. Quando o Firewall bloqueia seu próprio cluster, as interações externas são interrompidas na saída e o recurso é interrompido.
E para conseguir bloquear sua própria rede é fácil. Se o escritório do cliente tiver uma rede Wi-Fi ou se a integridade dos recursos for medida usando vários monitoramento, pegamos o endereço IP desse sistema de monitoramento ou cliente Wi-Fi do escritório e o usamos como fonte. Na saída, o recurso parece estar disponível, mas os endereços IP de destino estão bloqueados. Portanto, a rede Wi-Fi da conferência HighLoad, onde é apresentado um novo produto da empresa, pode ser bloqueada, e isso implica em certos custos comerciais e econômicos.
Durante o teste, não podemos usar a amplificação através do memcached por alguns recursos externos, porque existem acordos para fornecer tráfego apenas para endereços IP permitidos. Assim, usamos a amplificação via SYN e SYN-ACK, quando o sistema responde com dois ou três SYN-ACKs para enviar um SYN, e a saída é multiplicada por duas a três vezes.
As ferramentas
Uma das principais ferramentas que usamos para a carga no nível L7 é o tanque Yandex. Em particular, um fantasma é usado como arma, além de vários scripts para gerar cartuchos e analisar os resultados.
Tcpdump é usado para analisar o tráfego de rede e o Nmap é usado para analisar o tráfego do servidor. Para criar uma carga no nível L3 e 4, o OpenSSL é usado e um pouco de sua própria mágica com a biblioteca DPDK. O DPDK é uma biblioteca da Intel que permite trabalhar com uma interface de rede, ignorando a pilha do Linux e, assim, aumentando a eficiência. Naturalmente, usamos o DPDK não apenas nos níveis L3 e 4, mas também no nível L7, porque permite criar um fluxo de carga muito alto, dentro de alguns milhões de solicitações por segundo de uma máquina.
Também usamos certos geradores de tráfego e ferramentas especiais que escrevemos para testes específicos. Se recordarmos a vulnerabilidade no SSH, com o conjunto acima, não será possível escapar. Se atacarmos o protocolo de email, utilizamos utilitários de email ou apenas escrevemos scripts neles.
Conclusões
Como resultado, gostaria de dizer:
- Além do teste de carga clássico, também é necessário realizar o teste de estresse. Temos um exemplo do mundo real em que um subempreiteiro parceiro conduzia apenas testes de carga. Ele mostrou que o recurso suporta a carga padrão. Mas, em seguida, apareceu uma carga anormal, os visitantes do site começaram a usar o recurso de maneira um pouco diferente e, na saída, o subcontratado estabeleceu. Portanto, vale a pena procurar vulnerabilidades, mesmo se você já estiver protegido contra ataques DDoS.
- É necessário isolar algumas partes do sistema de outras. , , . , - . - , , , , OAuth2.
- .
- CDN , .
- . L3&4 , , , . L7 , . , - , .
- . , SSH daemon, . , , .