Já nos familiarizamos com o
mecanismo de indexação do PostgreSQL e a interface dos métodos de acesso e discutimos
índices de hash ,
árvores B e também os índices
GiST e
SP-GiST . E este artigo apresentará o índice GIN.
Gin
"Gin? .. Gin é, ao que parece, uma bebida tão americana? .."
"Eu não sou um drinque, oh, garoto curioso!" novamente o velho se acendeu, novamente percebeu a si mesmo e novamente se pegou na mão. "Eu não sou uma bebida, mas um espírito poderoso e destemido, e não existe tal mágica no mundo que eu não seria capaz de fazer".- Lazar Lagin, "Velho Khottabych".
Gin significa Índice Invertido Generalizado e deve ser considerado um gênio, não uma bebida.-
READMEConceito geral
GIN é o Índice Invertido Generalizado abreviado. Este é o chamado
índice invertido . Ele manipula tipos de dados cujos valores não são atômicos, mas consistem em elementos. Vamos chamar esses tipos de compostos. E esses não são os valores que são indexados, mas elementos individuais; cada elemento faz referência aos valores em que ocorre.
Uma boa analogia a esse método é o índice no final de um livro, que para cada termo fornece uma lista de páginas em que esse termo ocorre. O método de acesso deve garantir a pesquisa rápida de elementos indexados, assim como o índice de um livro. Portanto, esses elementos são armazenados como uma
árvore B familiar (uma implementação diferente e mais simples é usada para isso, mas não importa nesse caso). Um conjunto ordenado de referências a linhas da tabela que contêm valores compostos com o elemento é vinculado a cada elemento. A ordem não é essencial para a recuperação de dados (a ordem de classificação dos TIDs não significa muito), mas importante para a estrutura interna do índice.
Os elementos nunca são excluídos do índice GIN. Considera-se que os valores que contêm elementos podem desaparecer, surgir ou variar, mas o conjunto de elementos dos quais são compostos é mais ou menos estável. Essa solução simplifica significativamente os algoritmos para o trabalho simultâneo de vários processos com o índice.
Se a lista de TIDs for muito pequena, poderá caber na mesma página que o elemento (e é chamada de "lista de lançamentos"). Mas se a lista for grande, é necessária uma estrutura de dados mais eficiente, e já estamos cientes disso - é a árvore B novamente. Essa árvore está localizada em páginas de dados separadas (e é chamada "a árvore de lançamento").
Portanto, o índice GIN consiste na árvore B de elementos, e as árvores B ou listas planas de TIDs estão vinculadas às linhas das folhas dessa árvore B.
Assim como os índices GiST e SP-GiST, discutidos anteriormente, o GIN fornece ao desenvolvedor de aplicativos a interface para oferecer suporte a várias operações sobre tipos de dados compostos.
Pesquisa de texto completo
A principal área de aplicação do método GIN é acelerar a pesquisa de texto completo, o que é, portanto, razoável para ser usado como exemplo em uma discussão mais detalhada desse índice.
O artigo relacionado ao GiST já forneceu uma pequena introdução à pesquisa de texto completo, então vamos direto ao ponto sem repetições. É claro que os valores compostos, neste caso, são
documentos e os elementos desses documentos são
lexemas .
Vamos considerar o exemplo do artigo relacionado ao GiST:
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc); postgres=# create index on ts using gin(doc_tsv);
Uma estrutura possível desse índice é mostrada na figura:
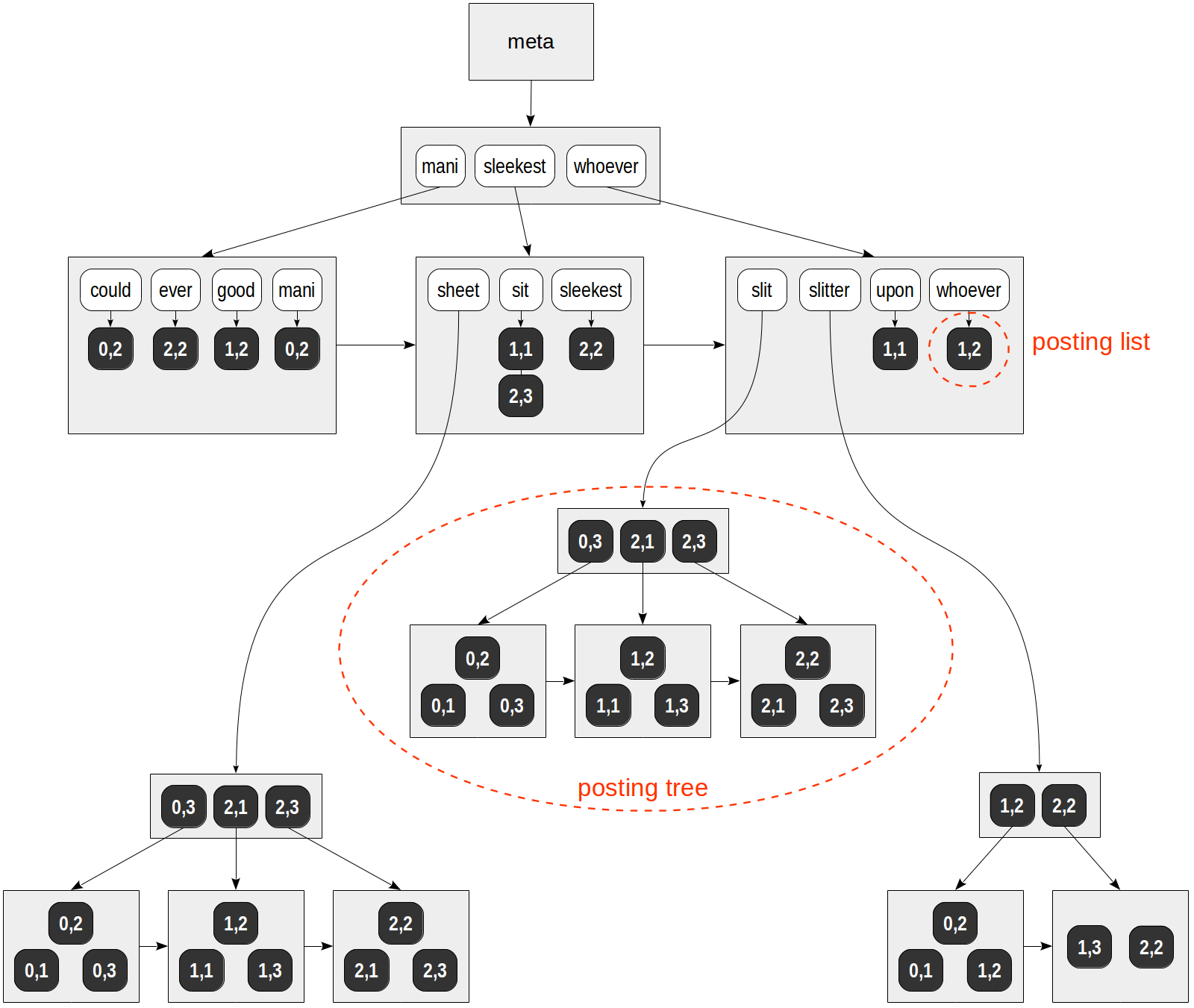
Diferentemente de todas as figuras anteriores, as referências às linhas da tabela (TIDs) são indicadas com valores numéricos em um fundo escuro (o número da página e a posição na página), e não com as setas.
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
Neste exemplo especulativo, a lista de TIDs se encaixa em páginas regulares para todos os lexemas, exceto "folha", "fenda" e "talhadeira". Esses lexemes ocorreram em muitos documentos e as listas de TIDs foram colocadas em árvores B individuais.
A propósito, como podemos descobrir quantos documentos contêm um léxico? Para uma tabela pequena, uma técnica “direta”, mostrada abaixo, funcionará, mas aprenderemos mais o que fazer com as maiores.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count ----------+------- sheet | 9 slit | 8 slitter | 5 sit | 2 upon | 1 mani | 1 whoever | 1 sleekest | 1 good | 1 could | 1 ever | 1 (11 rows)
Observe também que, diferentemente de uma árvore B comum, as páginas do índice GIN são conectadas por uma lista unidirecional, e não bidirecional. Isso é suficiente, pois uma travessia de árvore é feita apenas de uma maneira.
Exemplo de uma Consulta
Como a seguinte consulta será executada para o nosso exemplo?
postgres=# explain(costs off) select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) (4 rows)
Os lexemes individuais (chaves de pesquisa) são extraídos da consulta primeiro: "mani" e "slitter". Isso é feito por uma função API especializada que leva em conta o tipo de dados e a estratégia determinados pela classe de operador
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'tsvector_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- @@(tsvector,tsquery) | 1 matching search query @@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility) (2 rows)
Na árvore B dos lexemas, encontramos as duas chaves e examinamos as listas prontas de IDs. Temos:
para "mani" - (0,2).
para "talhadeira" - (0,1), (0,2), (1,2), (1,3), (2,2).
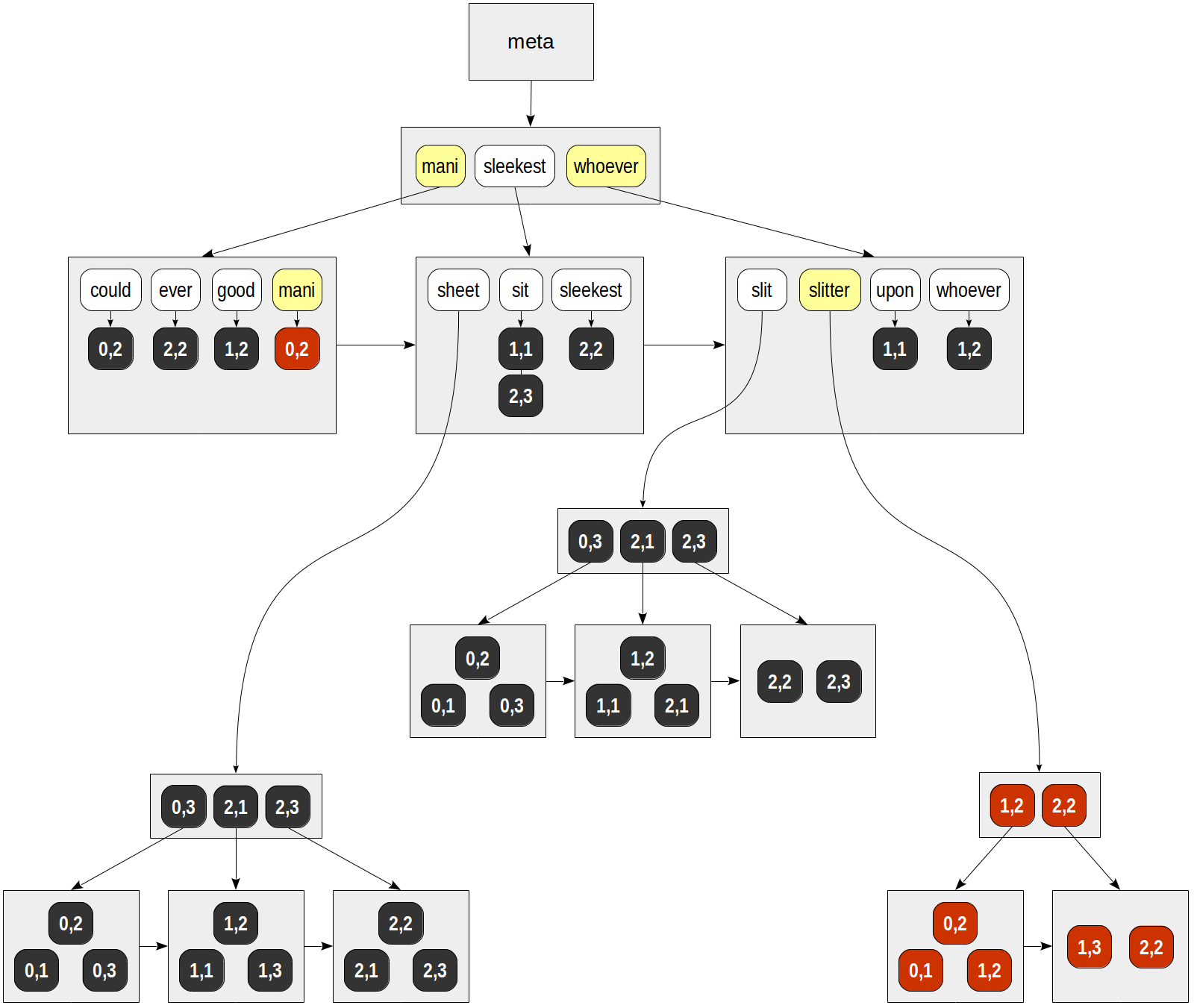
Finalmente, para cada TID encontrado, é chamada uma função de consistência da API, que deve determinar quais linhas encontradas correspondem à consulta de pesquisa. Como os lexemes em nossa consulta são unidos por Boolean "e", a única linha retornada é (0,2):
| | | consistency | | | function TID | mani | slitter | slit & slitter -------+------+---------+---------------- (0,1) | f | T | f (0,2) | T | T | T (1,2) | f | T | f (1,3) | f | T | f (2,2) | f | T | f
E o resultado é:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc --------------------------------------------- How many sheets could a sheet slitter slit? (1 row)
Se compararmos essa abordagem com a já discutida no GiST, a vantagem do GIN para a pesquisa de texto completo parece evidente. Mas há mais nisso do que aparenta.
O problema de uma atualização lenta
O problema é que a inserção ou atualização de dados no índice GIN é bem lenta. Cada documento geralmente contém muitos lexemes a serem indexados. Portanto, quando apenas um documento é adicionado ou atualizado, precisamos atualizar massivamente a árvore de índices.
Por outro lado, se vários documentos forem atualizados simultaneamente, alguns de seus lexemas podem ser os mesmos e a quantidade total de trabalho será menor do que na atualização de documentos um por um.
O índice GIN possui um parâmetro de armazenamento "fastupdate", que podemos especificar durante a criação e atualização do índice posteriormente:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
Com esse parâmetro ativado, as atualizações serão acumuladas em uma lista não ordenada separada (em páginas conectadas individuais). Quando essa lista fica grande o suficiente ou durante a aspiração, todas as atualizações acumuladas são feitas instantaneamente no índice. A lista a considerar "suficientemente grande" é determinada pelo parâmetro de configuração "gin_pending_list_limit" ou pelo parâmetro de armazenamento com o mesmo nome do índice.
Mas essa abordagem tem desvantagens: primeiro, a pesquisa é mais lenta (uma vez que a lista não ordenada precisa ser examinada além da árvore) e, segundo, uma próxima atualização pode levar inesperadamente muito tempo se a lista não ordenada for excedida.
Pesquisa de uma correspondência parcial
Podemos usar correspondência parcial na pesquisa de texto completo. Por exemplo, considere a seguinte consulta:
gin=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc -------------------------------------------------------- Can a sheet slitter slit sheets? How many sheets could a sheet slitter slit? I slit a sheet, a sheet I slit. Upon a slitted sheet I sit. Whoever slit the sheets is a good sheet slitter. I am a sheet slitter. I slit sheets. I am the sleekest sheet slitter that ever slit sheets. She slits the sheet she sits on. (9 rows)
Esta consulta encontrará documentos que contêm lexemas começando com "fenda". Neste exemplo, esses lexemes são "fenda" e "talhadeira".
Uma consulta certamente funcionará de qualquer maneira, mesmo sem índices, mas o GIN também permite acelerar a seguinte pesquisa:
postgres=# explain (costs off) select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN ------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) (4 rows)
Aqui todos os lexemes com o prefixo especificado na consulta de pesquisa são procurados na árvore e unidos por booleano "ou".
Lexemes frequentes e pouco frequentes
Para observar como a indexação funciona com dados ao vivo, vamos pegar o arquivo de e-mail "pgsql-hackers", que já usamos ao discutir o GiST.
Esta versão do arquivo contém 356125 mensagens com a data de envio, assunto, autor e texto.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
Vamos considerar um léxico que ocorre em muitos documentos. A consulta que usa "unnest" não funcionará em um tamanho de dados tão grande, e a técnica correta é usar a função "ts_stat", que fornece as informações sobre lexemes, o número de documentos em que eles ocorreram e o número total de ocorrências.
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') order by ndoc desc limit 3;
word | ndoc -------+-------- re | 322141 wrote | 231174 use | 176917 (3 rows)
Vamos escolher "escreveu".
E usaremos uma palavra que não é frequente no e-mail dos desenvolvedores, como "tatuagem":
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc --------+------ tattoo | 2 (1 row)
Existem documentos onde esses dois lexemes ocorrem? Parece que existem:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row)
Surge uma pergunta sobre como executar esta consulta. Se obtivermos listas de TIDs para ambos os lexemas, como descrito acima, a pesquisa será evidentemente ineficiente: teremos que passar por mais de 200 mil valores, restando apenas um deles. Felizmente, usando as estatísticas do planejador, o algoritmo entende que o léxico "escrito" ocorre com frequência, enquanto "tatoo" ocorre com pouca frequência. Portanto, é realizada a pesquisa do lexeme infreqüente e os dois documentos recuperados são verificados quanto à ocorrência de lexeme "gravado". E isso fica claro na consulta, que é realizada rapidamente:
fts=# \timing on fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row) Time: 0,959 ms
A pesquisa de "escreveu" sozinha leva significativamente mais tempo:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count -------- 231174 (1 row) Time: 2875,543 ms (00:02,876)
Essa otimização certamente funciona não apenas para dois lexemas, mas também em casos mais complexos.
Limitando o resultado da consulta
Um recurso do método de acesso GIN é que o resultado é sempre retornado como um bitmap: esse método não pode retornar o resultado TID por TID. É por isso que todos os planos de consulta neste artigo usam verificação de bitmap.
Portanto, a limitação do resultado da varredura de índice usando a cláusula LIMIT não é muito eficiente. Preste atenção ao custo previsto da operação (campo "custo" do nó "Limite"):
fts=# explain (costs off) select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN ----------------------------------------------------------------------------------------- Limit (cost=1283.61..1285.13 rows=1) -> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207) Recheck Cond: (tsv @@ to_tsquery('wrote'::text)) -> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207) Index Cond: (tsv @@ to_tsquery('wrote'::text)) (5 rows)
O custo é estimado em 1285.13, um pouco maior que o custo da construção de todo o bitmap 1249.30 (campo "cost" do nó Bitmap Index Scan).
Portanto, o índice possui uma capacidade especial para limitar o número de resultados. O valor do limite é especificado no parâmetro de configuração "gin_fuzzy_search_limit" e é igual a zero por padrão (nenhuma limitação ocorre). Mas podemos definir o valor limite:
fts=# set gin_fuzzy_search_limit = 1000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 5746 (1 row)
fts=# set gin_fuzzy_search_limit = 10000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 14726 (1 row)
Como podemos ver, o número de linhas retornadas pela consulta difere para diferentes valores de parâmetros (se o acesso ao índice for usado). A limitação não é estrita: mais linhas do que as especificadas podem ser retornadas, o que justifica parte "difusa" do nome do parâmetro.
Representação compacta
Entre os demais, os índices GIN são bons, graças à sua compacidade. Primeiro, se um mesmo lexeme ocorrer em vários documentos (e esse geralmente é o caso), ele será armazenado no índice apenas uma vez. Segundo, os TIDs são armazenados no índice de maneira ordenada, e isso nos permite usar uma compactação simples: cada próximo TID da lista é realmente armazenado como sua diferença em relação ao anterior; esse geralmente é um número pequeno, que requer muito menos bits que um TID completo de seis bytes.
Para ter uma idéia do tamanho, vamos construir uma árvore B a partir do texto das mensagens. Mas uma comparação justa certamente não vai acontecer:
- O GIN é criado com um tipo de dados diferente ("tsvector" em vez de "texto"), que é menor,
- ao mesmo tempo, o tamanho das mensagens para a árvore B deve ser reduzido para aproximadamente dois kilobytes.
No entanto, continuamos:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
Também criaremos o índice GiST:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
O tamanho dos índices no "vácuo cheio":
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin, pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist, pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree --------+--------+-------- 179 MB | 125 MB | 546 MB (1 row)
Devido à compactação da representação, podemos tentar usar o índice GIN durante a migração do Oracle como um substituto para índices de bitmap (sem entrar em detalhes, forneço
uma referência à postagem de Lewis para mentes inquisitivas). Como regra, índices de bitmap são usados para campos com poucos valores exclusivos, o que também é excelente para o GIN. E, como mostrado
no primeiro artigo , o PostgreSQL pode criar um bitmap com base em qualquer índice, incluindo GIN, em tempo real.
GiST ou GIN?
Para muitos tipos de dados, as classes de operadores estão disponíveis para GiST e GIN, o que levanta uma questão sobre qual índice usar. Talvez já possamos tirar algumas conclusões.
Como regra, o GIN supera o GiST em precisão e velocidade de pesquisa. Se os dados não forem atualizados com frequência e a pesquisa rápida for necessária, provavelmente o GIN será uma opção.
Por outro lado, se os dados forem atualizados intensivamente, os custos indiretos da atualização do GIN podem parecer muito grandes. Nesse caso, teremos que comparar as duas opções e escolher aquela cujas características são mais equilibradas.
Matrizes
Outro exemplo de uso do GIN é a indexação de matrizes. Nesse caso, os elementos da matriz entram no índice, o que permite acelerar várias operações nas matrizes:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- &&(anyarray,anyarray) | 1 intersection @>(anyarray,anyarray) | 2 contains array <@(anyarray,anyarray) | 3 contained in array =(anyarray,anyarray) | 4 equality (4 rows)
Nosso
banco de dados de demonstração possui visualização de "rotas" com informações sobre voos. Entre o restante, essa exibição contém a coluna "days_of_week" - uma matriz de dias da semana em que os voos ocorrem. Por exemplo, um voo de Vnukovo para Gelendzhik sai às terças, quintas e domingos:
demo=# select departure_airport_name, arrival_airport_name, days_of_week from routes where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week ------------------------+----------------------+-------------- Vnukovo | Gelendzhik | {2,4,7} (1 row)
Para criar o índice, vamos "materializar" a visualização em uma tabela:
demo=# create table routes_t as select * from routes; demo=# create index on routes_t using gin(days_of_week);
Agora podemos usar o índice para conhecer todos os voos que partem às terças, quintas e domingos:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (4 rows)
Parece que existem seis deles:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week -----------+------------------------+----------------------+-------------- PG0005 | Domodedovo | Pskov | {2,4,7} PG0049 | Vnukovo | Gelendzhik | {2,4,7} PG0113 | Naryan-Mar | Domodedovo | {2,4,7} PG0249 | Domodedovo | Gelendzhik | {2,4,7} PG0449 | Stavropol | Vnukovo | {2,4,7} PG0540 | Barnaul | Vnukovo | {2,4,7} (6 rows)
Como essa consulta é realizada? Exatamente da mesma maneira descrita acima:
- Da matriz {2,4,7}, que desempenha o papel da consulta de pesquisa aqui, elementos (palavras-chave de pesquisa) são extraídos. Evidentemente, esses são os valores de "2", "4" e "7".
- Na árvore de elementos, as chaves extraídas são encontradas e, para cada um deles, a lista de TIDs é selecionada.
- De todos os TIDs encontrados, a função de consistência seleciona aqueles que correspondem ao operador na consulta. Para o operador
= , apenas os TIDs correspondem ao que ocorreu nas três listas (em outras palavras, a matriz inicial deve conter todos os elementos). Mas isso não é suficiente: também é necessário que a matriz não contenha outros valores e não podemos verificar essa condição com o índice. Portanto, nesse caso, o método de acesso solicita que o mecanismo de indexação verifique novamente todos os TIDs retornados com a tabela.
Curiosamente, existem estratégias (por exemplo, "contidas na matriz") que não podem verificar nada e precisam verificar novamente todos os TIDs encontrados na tabela.
Mas o que fazer se precisarmos conhecer os voos que partem de Moscou às terças, quintas e domingos? O índice não suporta a condição adicional, que entra na coluna "Filtro".
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) Filter: (departure_city = 'Moscow'::text) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (5 rows)
Aqui está OK (o índice seleciona apenas seis linhas de qualquer maneira), mas nos casos em que a condição adicional aumenta a capacidade seletiva, é desejável ter esse suporte. No entanto, não podemos apenas criar o índice:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin" HINT: You must specify an operator class for the index or define a default operator class for the data type.
Mas a extensão "
btree_gin " ajudará, o que adiciona classes de operadores GIN que simulam o trabalho de uma árvore B comum.
demo=# create extension btree_gin; demo=# create index on routes_t using gin(days_of_week,departure_city); demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) -> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) (4 rows)
Jsonb
Mais um exemplo de um tipo de dados composto que possui suporte GIN interno é JSON. Para trabalhar com valores JSON, vários operadores e funções são definidos no momento, alguns dos quais podem ser acelerados usando índices:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname in ('jsonb_ops','jsonb_path_ops') and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str ----------------+------------------+----- jsonb_ops | ?(jsonb,text) | 9 top-level key exists jsonb_ops | ?|(jsonb,text[]) | 10 some top-level key exists jsonb_ops | ?&(jsonb,text[]) | 11 all top-level keys exist jsonb_ops | @>(jsonb,jsonb) | 7 JSON value is at top level jsonb_path_ops | @>(jsonb,jsonb) | 7 (5 rows)
Como podemos ver, duas classes de operadores estão disponíveis: "jsonb_ops" e "jsonb_path_ops".
A primeira classe de operador "jsonb_ops" é usada por padrão. Todas as chaves, valores e elementos da matriz chegam ao índice como elementos do documento JSON inicial. Um atributo é adicionado a cada um desses elementos, o que indica se esse elemento é uma chave (isso é necessário para estratégias "existentes", que distinguem entre chaves e valores).
Por exemplo, vamos representar algumas linhas de "rotas" como JSON da seguinte maneira:
demo=# create table routes_jsonb as select to_jsonb(t) route from ( select departure_airport_name, arrival_airport_name, days_of_week from routes order by flight_no limit 4 ) t; demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty -------+------------------------------------------------- (0,1) | { + | "days_of_week": [ + | 1 + | ], + | "arrival_airport_name": "Surgut", + | "departure_airport_name": "Ust-Ilimsk" + | } (0,2) | { + | "days_of_week": [ + | 2 + | ], + | "arrival_airport_name": "Ust-Ilimsk", + | "departure_airport_name": "Surgut" + | } (0,3) | { + | "days_of_week": [ + | 1, + | 4 + | ], + | "arrival_airport_name": "Sochi", + | "departure_airport_name": "Ivanovo-Yuzhnyi"+ | } (0,4) | { + | "days_of_week": [ + | 2, + | 5 + | ], + | "arrival_airport_name": "Ivanovo-Yuzhnyi", + | "departure_airport_name": "Sochi" + | } (4 rows)
demo=# create index on routes_jsonb using gin(route);
O índice pode ter a seguinte aparência:
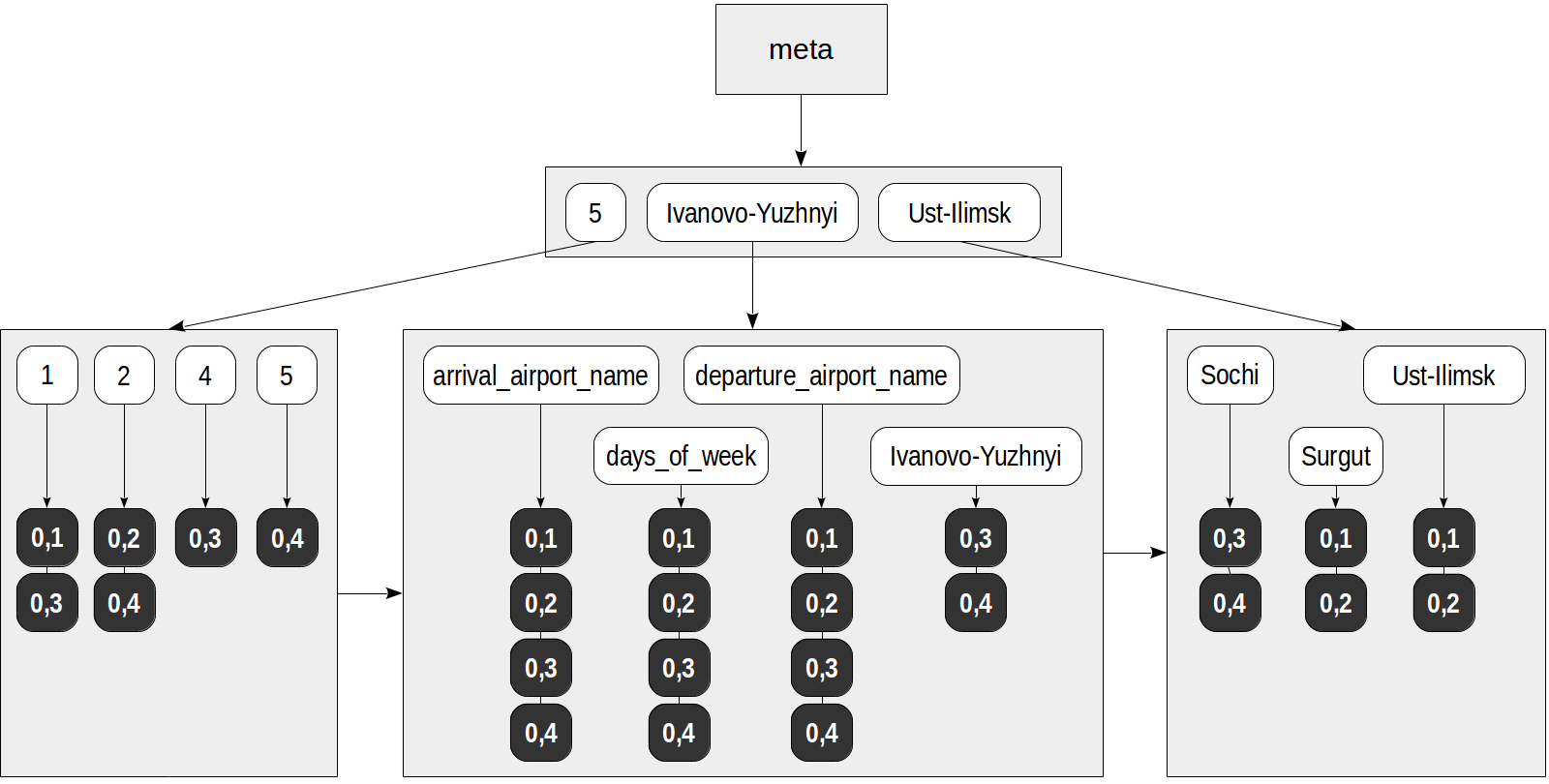
Agora, uma consulta como esta, por exemplo, pode ser realizada usando o índice:
demo=# explain (costs off) select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
QUERY PLAN --------------------------------------------------------------- Bitmap Heap Scan on routes_jsonb Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb) -> Bitmap Index Scan on routes_jsonb_route_idx Index Cond: (route @> '{"days_of_week": [5]}'::jsonb) (4 rows)
Começando com a raiz do documento JSON, o operador
@> verifica se a rota especificada (
"days_of_week": [5] ) ocorre. Aqui a consulta retornará uma linha:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty ------------------------------------------------ { + "days_of_week": [ + 2, + 5 + ], + "arrival_airport_name": "Ivanovo-Yuzhnyi",+ "departure_airport_name": "Sochi" + } (1 row)
A consulta é realizada da seguinte maneira:
- Na consulta de pesquisa (
"days_of_week": [5] ) os elementos (chaves de pesquisa) são extraídos: "days_of_week" e "5".
- Na árvore de elementos, as chaves extraídas são encontradas e, para cada um deles, a lista de TIDs é selecionada: para "5" - (0,4) e para "dias_de_semana" - (0,1), (0,2 ), (0,3), (0,4).
- De todos os TIDs encontrados, a função de consistência seleciona aqueles que correspondem ao operador na consulta. Para o operador
@> , os documentos que não contêm todos os elementos da consulta de pesquisa não serão suficientes, portanto, apenas (0,4) será deixado. Mas ainda precisamos verificar novamente o TID deixado com a tabela, pois não está claro no índice em que ordem os elementos encontrados ocorrem no documento JSON.
Para descobrir mais detalhes de outros operadores, você pode ler
a documentação .
Além das operações convencionais para lidar com JSON, a extensão "jsquery" está disponível há muito tempo, que define uma linguagem de consulta com recursos mais avançados (e certamente com suporte aos índices GIN). Além disso, em 2016, foi emitido um novo padrão SQL, que define seu próprio conjunto de operações e a linguagem de consulta "caminho SQL / JSON". Uma implementação deste padrão já foi realizada e acreditamos que ele aparecerá no PostgreSQL 11.
O patch do caminho SQL / JSON foi finalmente confirmado no PostgreSQL 12, enquanto outras partes ainda estão a caminho. Esperamos ver o recurso totalmente implementado no PostgreSQL 13.
Internals
Podemos examinar o índice GIN usando a extensão "
pageinspect ".
fts=# create extension pageinspect;
As informações da página meta mostram estatísticas gerais:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+----------- pending_head | 4294967295 pending_tail | 4294967295 tail_free_size | 0 n_pending_pages | 0 n_pending_tuples | 0 n_total_pages | 22968 n_entry_pages | 13751 n_data_pages | 9216 n_entries | 1423598 version | 2
A estrutura da página fornece uma área especial onde os métodos de acesso armazenam suas informações; essa área é "opaca" para programas comuns, como o vácuo. A função "Gin_page_opaque_info" mostra esses dados para o GIN. Por exemplo, podemos conhecer o conjunto de páginas de índice:
fts=# select flags, count(*) from generate_series(1,22967) as g(id),
flags | count ------------------------+------- {meta} | 1 meta page {} | 133 internal page of element B-tree {leaf} | 13618 leaf page of element B-tree {data} | 1497 internal page of TID B-tree {data,leaf,compressed} | 7719 leaf page of TID B-tree (5 rows)
A função "Gin_leafpage_items" fornece informações sobre os TIDs armazenados nas páginas {data, leaf, compactado}:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]--------------------------------------------------------------------- first_tid | (239,44) nbytes | 248 tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",... -[ RECORD 2 ]--------------------------------------------------------------------- first_tid | (247,40) nbytes | 248 tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",... ...
Observe aqui que as páginas da árvore dos TIDs contêm, na verdade, pequenas listas compactadas de ponteiros para linhas da tabela, em vez de ponteiros individuais.
Propriedades
Vamos examinar as propriedades do método de acesso GIN (consultas
já foram fornecidas ).
amname | name | pg_indexam_has_property --------+---------------+------------------------- gin | can_order | f gin | can_unique | f gin | can_multi_col | t gin | can_exclude | f
Curiosamente, o GIN suporta a criação de índices com várias colunas. No entanto, diferentemente de uma árvore B comum, em vez de chaves compostas, um índice de várias colunas ainda armazenará elementos individuais e o número da coluna será indicado para cada elemento.
As seguintes propriedades da camada de índice estão disponíveis:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Observe que o retorno de resultados TID por TID (varredura de índice) não é suportado; somente a verificação de bitmap é possível.
A verificação reversa também não é suportada: esse recurso é essencial apenas para a verificação de índice, mas não para a verificação de bitmap.
E a seguir estão as propriedades da camada de coluna:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Nada está disponível aqui: sem classificação (o que é claro), sem uso do índice como cobertura (uma vez que o documento em si não está armazenado no índice), sem manipulação de NULLs (pois não faz sentido para elementos do tipo composto) .
Outros tipos de dados
Estão disponíveis mais algumas extensões que adicionam suporte ao GIN para alguns tipos de dados.
- " pg_trgm " nos permite determinar a "semelhança" das palavras, comparando quantas seqüências iguais de três letras (trigramas) estão disponíveis. Duas classes de operadores são adicionadas, "gist_trgm_ops" e "gin_trgm_ops", que suportam vários operadores, incluindo a comparação por meio de LIKE e expressões regulares. Podemos usar essa extensão juntamente com a pesquisa de texto completo para sugerir opções de palavras para corrigir erros de digitação.
- " hstore " implementa armazenamento "key-value". Para esse tipo de dados, estão disponíveis classes de operadores para vários métodos de acesso, incluindo GIN. No entanto, com a introdução do tipo de dados "jsonb", não há motivos especiais para usar o "hstore".
- " intarray " estende a funcionalidade de matrizes inteiras. O suporte ao índice inclui GiST, bem como GIN (classe de operador "gin__int_ops").
E essas duas extensões já foram mencionadas acima:
- " btree_gin " adiciona suporte GIN a tipos de dados regulares para que eles sejam usados em um índice de várias colunas junto com tipos compostos.
- " jsquery " define um idioma para consulta JSON e uma classe de operador para suporte ao índice desse idioma. Esta extensão não está incluída em uma entrega padrão do PostgreSQL.
Continue lendo .