Como trabalhar efetivamente com json no R?
É uma continuação de publicações anteriores .
Declaração do problema
Como regra, a principal fonte de dados no formato json é a API REST. O uso do json, além da independência da plataforma e da conveniência da percepção humana dos dados, permite trocar sistemas de dados não estruturados com uma estrutura de árvore complexa.
Nas tarefas de construção de uma API, isso é muito conveniente. É fácil garantir a versão dos protocolos de comunicação, é fácil fornecer a flexibilidade da troca de informações. Ao mesmo tempo, a complexidade da estrutura de dados (os níveis de aninhamento podem ser 5, 6, 10 ou até mais) não é assustadora, pois escrever um analisador flexível para um único registro que leva em conta tudo e tudo não é tão difícil.
As tarefas de processamento de dados também incluem a obtenção de dados de fontes externas, incluindo no formato json. O R possui um bom conjunto de pacotes, em particular o jsonlite , projetado para converter o json em objetos R ( list ou data.frame , se a estrutura dos dados permitir).
No entanto, na prática, duas classes de problemas geralmente surgem quando o uso do jsonlite e similares se tornam extremamente ineficientes. As tarefas são mais ou menos assim:
- processar uma grande quantidade de dados (unidade de medida - gigabytes) obtidos durante a operação de vários sistemas de informação;
- combinando um grande número de respostas estruturadas em variáveis recebidas durante um pacote de solicitações de API REST parametrizadas em uma representação retangular uniforme (
data.frame ).
Um exemplo de uma estrutura semelhante nas ilustrações:
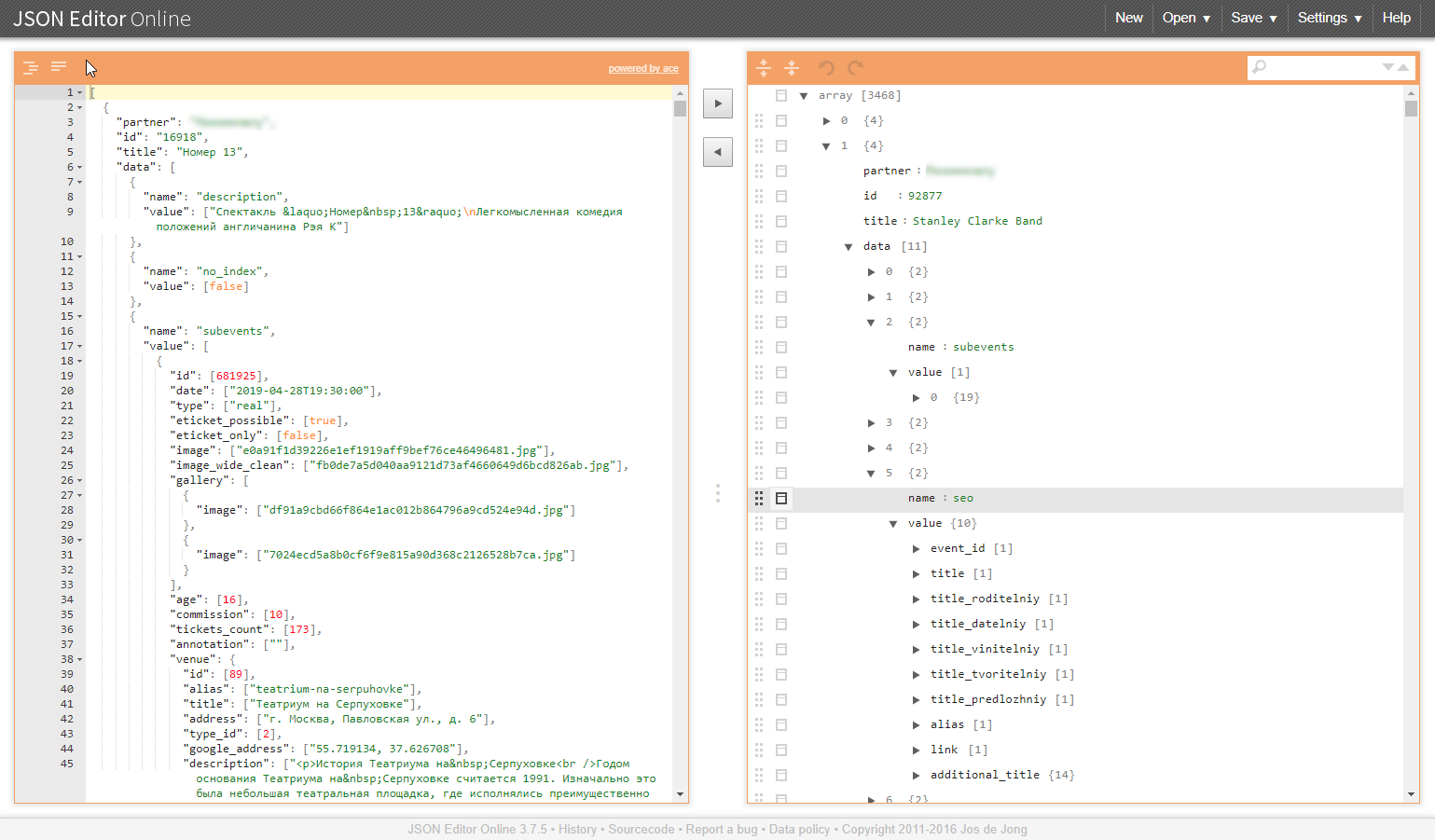
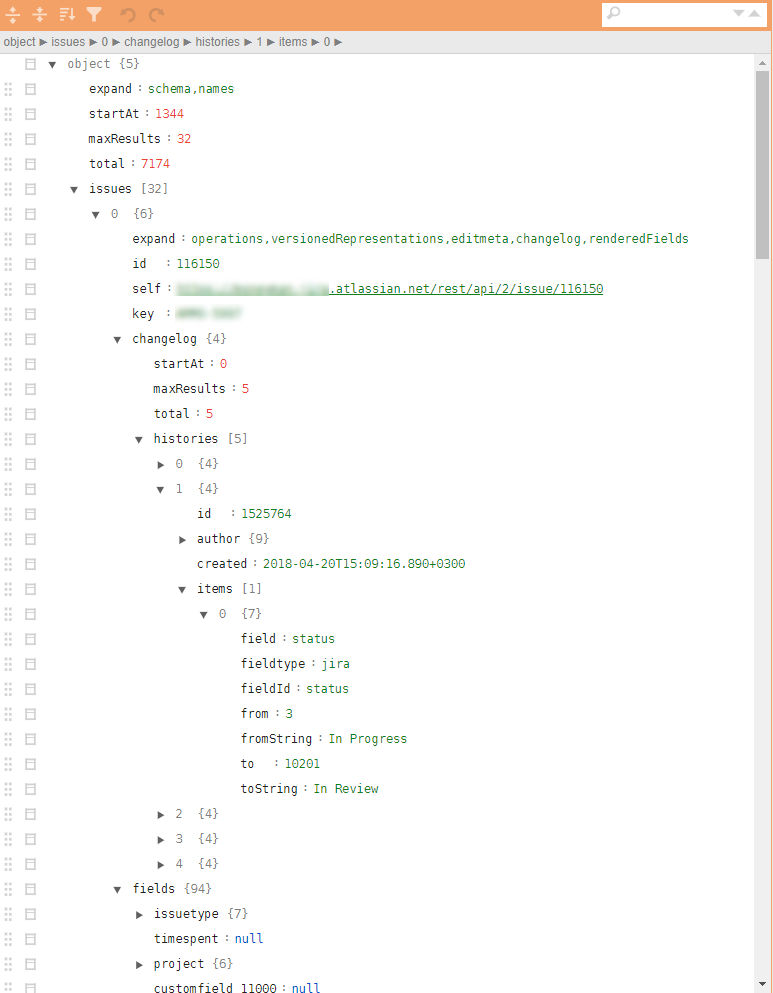
Por que essas classes de tarefas são problemáticas?
Grande quantidade de dados
Como regra, o descarregamento de sistemas de informação no formato json é um bloco de dados indivisível. Para analisá-lo corretamente, você precisa ler tudo e repassar todo o volume.
Problemas induzidos:
- é necessária uma quantidade correspondente de RAM e recursos de computação;
- a velocidade de análise depende fortemente da qualidade das bibliotecas usadas e, mesmo que haja recursos suficientes, o tempo de conversão pode ser de dezenas ou mesmo centenas de minutos;
- no caso de uma falha na análise, nenhum resultado é obtido na saída e não há razão para esperar que tudo sempre corra bem;
- Será muito bem-sucedido se os dados analisados puderem ser convertidos em
data.frame .
Mesclando estruturas de árvore
Tarefas semelhantes surgem, por exemplo, quando é necessário coletar os diretórios exigidos pelo processo de negócios para trabalhar com um pacote de solicitações por meio da API. Além disso, os diretórios implicam a unificação e a prontidão para incorporação no pipeline analítico e possível upload para o banco de dados. E isso novamente torna necessário transformar esses dados de resumo em data.frame .
Problemas induzidos:
- as estruturas das árvores em si não se transformarão em planas. Os analisadores json transformam os dados de entrada em um conjunto de listas aninhadas, que precisam ser implantadas manualmente por um longo período de tempo e de forma dolorosa;
- a liberdade nos atributos dos dados de saída (os ausentes podem não ser exibidos) leva ao aparecimento de objetos
NULL relevantes nas listas, mas não podem "caber" no data.frame , o que complica o pós-processamento e o processo básico de mesclar folhas de linhas individuais em data.frame (não importa rbindlist , bind_rows , 'map_dfr' ou rbind ).
JQ - saída
Em situações particularmente difíceis, o uso de abordagens muito convenientes do pacote jsonlite "converter tudo em objetos R" pelas razões acima mencionadas causa um mau funcionamento sério. Bem, se você conseguir chegar ao final do processamento. Pior, se no meio você tiver que abrir os braços e desistir.
Uma alternativa a essa abordagem é usar o pré-processador json, que opera diretamente nos dados json. Biblioteca jqr e wrapper jqr . A prática mostra que não é apenas usado pouco, mas poucos ouviram falar dele e em vão.
Benefícios da biblioteca jq .
- a biblioteca pode ser usada em R, em Python e na linha de comando;
- todas as transformações são executadas no nível json, sem transformação em representações de objetos R / Python;
- o processamento pode ser dividido em operações atômicas e usar o princípio de correntes (tubo);
- os ciclos de processamento de vetores de objetos estão ocultos no analisador, a sintaxe da iteração é simplificada ao máximo;
- a capacidade de executar todos os procedimentos de unificação da estrutura json, implantação e seleção dos elementos necessários para criar um formato json que é convertido em lote para
data.frame usando jsonlite ; - redução múltipla do código R responsável pelo processamento de dados json;
- enorme velocidade de processamento, dependendo do volume e da complexidade da estrutura de dados, o ganho pode ser de 1 a 3 ordens de magnitude;
- muito menos requisitos de RAM.
O código de processamento é compactado para caber na tela e pode ser algo como isto:
cont <- httr::content(r3, as = "text", encoding = "UTF-8") m <- cont %>% # jqr::jq('del(.[].movie.rating, .[].movie.genres, .[].movie.trailers)') %>% jqr::jq('del(.[].movie.countries, .[].movie.images)') %>% # jqr::jq('del(.[].schedules[].hall, .[].schedules[].language, .[].schedules[].subtitle)') %>% # jqr::jq('del(.[].cinema.location, .[].cinema.photo, .[].cinema.phones)') %>% jqr::jq('del(.[].cinema.goodies, .[].cinema.subway_stations)') # m2 <- m %>% jqr::jq('[.[] | {date, movie, schedule: .schedules[], cinema}]') df <- fromJSON(m2) %>% as_tibble()
jq é muito elegante e rápido! Para aqueles a quem é relevante: faça o download, configure, entenda. Aceleramos o processamento, simplificamos a vida para nós e nossos colegas.
Post anterior - “Como começar a aplicar o R no Enterprise. Um exemplo de uma abordagem prática . ”