Introdução aos sistemas operacionais
Olá Habr! Quero chamar sua atenção para uma série de artigos - traduções de uma literatura interessante em minha opinião - OSTEP. Este artigo discute profundamente o trabalho de sistemas operacionais semelhantes a unix, ou seja, trabalha com processos, vários agendadores, memória e outros componentes similares que compõem o sistema operacional moderno. O original de todos os materiais que você pode ver
aqui . Observe que a tradução foi feita de maneira não profissional (muito livremente), mas espero ter mantido o significado geral.
O trabalho de laboratório sobre este assunto pode ser encontrado aqui:
Outras partes:
E você pode olhar para o meu canal no
telegrama =)
Introdução ao Agendador
A essência do problema: como desenvolver uma política de planejamento
Como as estruturas de políticas básicas do planejador devem ser desenvolvidas? Quais devem ser as principais premissas? Quais métricas são importantes? Quais técnicas básicas foram usadas na computação inicial?Pressupostos da carga de trabalho
Antes de discutir possíveis políticas, faremos algumas digressões simplificadoras sobre os processos em execução no sistema, que são coletivamente chamados de
carga de trabalho . Ao definir uma carga de trabalho como uma parte crítica da criação de políticas e quanto mais você souber sobre a carga de trabalho, melhor a política que você pode escrever.
Fazemos as seguintes suposições sobre os processos em execução no sistema, às vezes também chamados de
tarefas (tarefas). Quase todas essas suposições não são realistas, mas necessárias para o desenvolvimento do pensamento.
- Cada tarefa executa a mesma quantidade de tempo,
- Todas as tarefas são definidas ao mesmo tempo,
- A tarefa em questão até sua conclusão,
- Todas as tarefas usam apenas a CPU,
- O tempo de execução de cada tarefa é conhecido.
Métricas do agendador
Além de algumas suposições sobre a carga, ainda é necessária alguma ferramenta para comparar várias políticas de planejamento: métricas do planejador. Uma métrica é apenas uma medida de algo. Há várias métricas que podem ser usadas para comparar planejadores.
Por exemplo, usaremos uma métrica chamada tempo de resposta. O tempo de resposta de uma tarefa é definido como a diferença entre o tempo necessário para concluir a tarefa e o tempo em que a tarefa entra no sistema.
Tturnaround = Conclusão - TarrivalComo assumimos que todas as tarefas chegaram ao mesmo tempo, Ta = 0 e, portanto, Tt = Tc. Esse valor mudará naturalmente quando alterarmos as premissas acima.
Outra métrica é a
justiça (justiça, honestidade). Produtividade e honestidade são frequentemente características opostas no planejamento. Por exemplo, um planejador pode otimizar o desempenho, mas com o custo de aguardar a execução de outras tarefas, reduzindo a integridade.
PRIMEIRO EM PRIMEIRO OUT (FIFO)
O algoritmo mais básico que podemos implementar é chamado FIFO ou
primeiro a chegar (entrar), primeiro a ser servido (sair) . Esse algoritmo tem várias vantagens: é muito simples de implementar e se encaixa em todas as nossas suposições, fazendo o trabalho muito bem.
Considere um exemplo simples. Suponha que 3 tarefas foram definidas ao mesmo tempo. Mas suponha que a tarefa A tenha chegado um pouco mais cedo do que todos os outros, portanto ela estará na lista de execução antes das outras, assim como B em relação a C. Suponha que cada uma delas leve 10 segundos para ser concluída. Qual será o tempo médio para concluir essas tarefas?
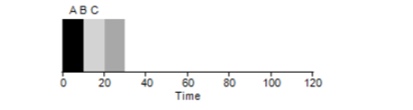
Contando os valores - 10 + 20 + 30 e dividindo por 3, obtemos o tempo médio de execução do programa igual a 20 segundos.
Agora vamos tentar mudar nossas suposições. Em particular, suposição 1 e, portanto, não assumiremos mais que cada tarefa leva a mesma quantidade de tempo. Como o FIFO se mostrará desta vez?
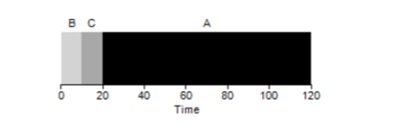
Como se vê, diferentes tempos de execução das tarefas têm um impacto extremamente negativo na produtividade do algoritmo FIFO. Suponha que a tarefa A será executada por 100 segundos, enquanto B e C ainda serão 10 cada.

Como pode ser visto na figura, o tempo médio para o sistema é (100 + 110 + 120) / 3 = 110. Esse efeito é chamado de
efeito comboio , quando alguns consumidores de curto prazo de um recurso estarão alinhados após um consumidor pesado. Parece uma linha de supermercado quando um cliente com um carrinho cheio está na sua frente. A melhor solução para o problema é tentar trocar o caixa ou relaxar e respirar profundamente.
Primeiro trabalho mais curto
É possível resolver de alguma forma uma situação semelhante com processos pesados? Claro. Outro tipo de agendamento é chamado
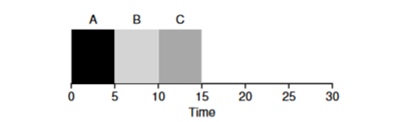
Shortest Job First (SJF). Seu algoritmo também é bastante primitivo - como o nome indica, as tarefas mais curtas serão iniciadas uma após a outra.
Neste exemplo, o resultado do início dos mesmos processos será uma melhoria no tempo médio de resposta dos programas e será
50 em vez de 110 , o que é quase duas vezes melhor.
Assim, para a suposição de que todas as tarefas chegam ao mesmo tempo, o algoritmo SJF parece ser o algoritmo mais ideal. No entanto, nossas suposições ainda não parecem realistas. Desta vez, alteramos a suposição 2 e, desta vez, imaginamos que as tarefas podem permanecer a qualquer momento, e não todas ao mesmo tempo. A que problemas isso pode levar?

Imagine que a tarefa A (100s) chegue primeiro e comece a ser executada. No momento t = 10, as tarefas B, C chegam, cada uma levando 10 segundos. Portanto, o tempo médio de execução é (100+ (110-10) + (120-10)) \ 3 = 103. O que o planejador poderia fazer para melhorar a situação?
Menor tempo até a conclusão primeiro (STCF)
Para melhorar a situação, omitimos a suposição 3 de que o programa está em funcionamento até a conclusão. Além disso, precisaremos de suporte de hardware e, como você deve ter adivinhado, usaremos um
timer para interromper uma tarefa de trabalho e
alternar contextos . Assim, o planejador pode fazer algo no momento em que as tarefas B e C chegam - interromper a execução da tarefa A e colocar as tarefas B e C em processamento e, após a conclusão, continuar o processo A. Esse planejador é chamado
STCF ou
Primeiro Trabalho Preemptivo .
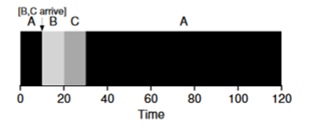
O resultado deste planejador será este resultado: ((120-0) + (20-10) + (30-10)) / 3 = 50. Assim, esse agendador se torna ainda mais ideal para nossas tarefas.
Tempo de resposta da métrica
Portanto, se soubermos o tempo de execução das tarefas e se essas tarefas usam apenas a CPU, o STCF será a melhor solução. E uma vez nos primeiros dias, esses algoritmos funcionavam muito bem. No entanto, agora o usuário passa a maior parte do tempo no terminal e espera interação produtiva e interativa. Então nasceu uma nova métrica -
tempo de resposta (resposta).
O tempo de resposta é calculado da seguinte maneira:
Tresponse = Tfirstrun - TarrivalAssim, para o exemplo anterior, o tempo de resposta será o seguinte: A = 0, B = 0, B = 10 (abg = 3,33).
E acontece que o algoritmo STCF não é tão bom em uma situação em que três tarefas chegam ao mesmo tempo - ele terá que esperar até que as pequenas tarefas sejam completamente concluídas. Portanto, o algoritmo é bom para a métrica de tempo de resposta, mas ruim para a métrica de interatividade. Imagine sentado no terminal, na tentativa de digitar caracteres no editor, você teria que esperar mais de 10 segundos, porque alguma outra tarefa é ocupada pelo processador. Isso não é muito agradável.
Portanto, estamos diante de outro problema - como podemos criar um agendador sensível ao tempo de resposta?
Pisco de peito vermelho redondo
Para resolver esse problema, o algoritmo
Round Robin (RR) foi desenvolvido. A idéia básica é bastante simples: em vez de iniciar tarefas até a conclusão, iniciaremos a tarefa por um determinado período de tempo (chamado quantum de tempo) e, em seguida, mudaremos para outra tarefa da fila. O algoritmo repete seu trabalho até que todas as tarefas sejam concluídas. Nesse caso, o tempo de execução do programa deve ser múltiplo do tempo após o qual o timer interrompe o processo. Por exemplo, se o cronômetro interromper o processo a cada x = 10ms, o tamanho da janela de execução do processo deve ser um múltiplo de 10 e ser 10,20 ou x * 10.
Vejamos um exemplo: as tarefas do ABV chegam simultaneamente ao sistema e cada uma delas deseja trabalhar por 5 segundos. O algoritmo SJF concluirá cada tarefa até o fim antes de iniciar outra. Por outro lado, o algoritmo RR com a janela de inicialização = 1s executará as tarefas da seguinte maneira (Fig. 4.3):
(SJF novamente (ruim para o tempo de resposta)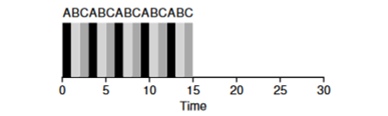 (Round Robin (bom para tempo de resposta)
(Round Robin (bom para tempo de resposta)O tempo médio de resposta para o algoritmo é RR (0 + 1 + 2) / 3 = 1, enquanto para SJF (0 + 5 + 10) / 3 = 5.
É lógico supor que a janela de tempo é um parâmetro muito importante para RR, quanto menor, maior o tempo de resposta. No entanto, você não pode torná-lo muito pequeno, porque o tempo para mudar de contexto também desempenhará um papel no desempenho geral. Portanto, o tempo da janela de execução é definido pelo arquiteto do SO e depende das tarefas planejadas para serem executadas nele. Mudar o contexto não é a única operação de serviço que gasta tempo - o programa em execução opera com muito mais, por exemplo, vários caches, e cada vez é necessário salvar e restaurar esse ambiente, o que também pode levar muito tempo.
O RR é um ótimo planejador se for apenas uma métrica de tempo de resposta. Mas como a métrica do tempo de resposta da tarefa se comportará com esse algoritmo? Considere o exemplo acima, quando o tempo de operação A, B, C = 5s e chegar ao mesmo tempo. A tarefa A terminará em 13, B em 14, C em 15s e o tempo médio de resposta será de 14s. Portanto, o RR é o pior algoritmo para métricas de rotatividade.
De maneira mais geral, qualquer algoritmo como o RR é honesto, divide o tempo gasto na CPU igualmente entre todos os processos. E assim, essas métricas conflitam constantemente entre si.
Assim, temos vários algoritmos opostos e, ao mesmo tempo, várias suposições permanecem - que o tempo da tarefa é conhecido e que a tarefa usa apenas a CPU.
Misturando com E / S
Primeiro, removemos a suposição 4 de que o processo usa apenas a CPU, é claro que não é assim, e os processos podem se voltar para outros equipamentos.
No momento em que um processo solicita uma operação de E / S, o processo entra em um estado bloqueado, aguardando a conclusão da E / S. Se a E / S for enviada para o disco rígido, essa operação poderá demorar vários ms ou mais e o processador ficará inativo nesse momento. No momento, o agendador pode assumir o controle do processador por qualquer outro processo. A próxima decisão que o planejador terá que tomar é quando o processo concluir sua E / S. Quando isso acontece, ocorre uma interrupção e o sistema operacional coloca o processo de chamada de E / S no estado pronto.
Considere um exemplo de várias tarefas. Cada um deles precisa de 50ms de tempo do processador. No entanto, o primeiro acessará a E / S a cada 10ms (que também será executado por 10ms). E o processo B simplesmente usa um processador de 50ms sem E / S.
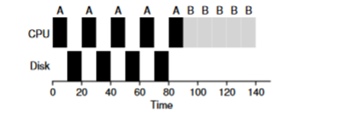
Neste exemplo, usaremos o planejador STCF. Como o agendador se comporta se você executa um processo como A nele? Ele procederá da seguinte maneira - primeiro processe totalmente A e depois o processo B.

A abordagem tradicional para resolver esse problema é interpretar cada subtarefa de 10 ms do processo A como uma tarefa separada. Assim, ao iniciar com o algoritmo STJF, a escolha entre uma tarefa de 50 ms e uma tarefa de 10 ms é óbvia. Em seguida, quando a subtarefa A for concluída, o processo B e a E / S serão iniciados. Após a conclusão da E / S, será habitual iniciar o processo A de 10 ms novamente em vez do processo B. Portanto, é possível realizar sobreposição quando a CPU for usada por outro processo enquanto o primeiro estiver aguardando a E / S. E, como resultado, o sistema é melhor utilizado - no momento em que processos interativos aguardam E / S, outros processos podem ser executados no processador.
Oracle não é mais
Agora vamos tentar nos livrar da suposição de que a hora da tarefa é conhecida. Essa é geralmente a pior e mais irrealista suposição de toda a lista. De fato, em sistemas operacionais padrão comuns, o sistema operacional em si geralmente sabe muito pouco sobre o tempo necessário para concluir as tarefas, então como você pode criar um agendador sem saber quanto tempo a tarefa levará? Talvez possamos usar alguns dos princípios do RR para resolver esse problema?
Sumário
Examinamos as idéias básicas do planejamento de tarefas e revisamos duas famílias de planejadores. O primeiro inicia a tarefa mais curta no início e, portanto, aumenta o tempo de resposta, o segundo é dividido entre todas as tarefas igualmente, aumentando o tempo de resposta. Ambos os algoritmos são ruins, enquanto outros da família são bons. Também vimos como o uso paralelo da CPU e da E / S pode melhorar o desempenho, mas não resolvemos o problema com a clarividência do sistema operacional. E na próxima lição, consideraremos um planejador que olha para o passado próximo e tenta prever o futuro. E isso é chamado de fila de feedback de vários níveis.