Se você usar o banco de dados de séries temporais (timeseries db,
wiki ) como o repositório principal de um site com estatísticas, em vez de resolver o problema, poderá sentir muita dor de cabeça. Estou trabalhando em um projeto em que esse banco de dados é usado e, algumas vezes, o InfluxDB, que será discutido, apresentou surpresas inesperadas em geral.
Isenção de responsabilidade : Esses problemas são para o InfluxDB 1.7.4.
Por que séries temporais?
O projeto é rastrear transações em várias cadeias de blocos e exibir estatísticas. Especificamente, analisamos a emissão e queima de moedas estáveis (
wiki ). Com base nessas transações, você precisa criar gráficos e mostrar tabelas dinâmicas.
Ao analisar as transações, surgiu a idéia: usar o banco de dados de séries temporais do InfluxDB como armazenamento principal. As transações são pontos no tempo e se encaixam bem no modelo de série temporal.
Além disso, as funções de agregação pareciam muito convenientes - elas são ideais para processar gráficos por um longo período. O usuário precisa de um gráfico para o ano e o banco de dados contém um conjunto de dados com um período de cinco minutos. Não faz sentido enviar-lhe cem mil pontos - exceto pelo processamento longo, eles não caberão na tela. Você pode escrever sua própria implementação para aumentar o período ou usar as funções de agregação criadas no Influx. Com a ajuda deles, você pode agrupar dados por dia e enviar os 365 pontos desejados.
Foi um pouco embaraçoso que geralmente esses bancos de dados sejam usados para coletar métricas. Servidores de monitoramento, dispositivos iot, todos dos quais milhões de pontos da forma "fluem": [<time> - <valor métrico>]. Mas se o banco de dados funciona bem com um grande fluxo de dados, por que uma pequena quantidade causa problemas? Com isso em mente, eles levaram o InfluxDB para trabalhar.
O que mais é conveniente no InfluxDB
Além das funções de agregação mencionadas, há outra grande coisa -
consultas contínuas (
doc ). Este é um planejador embutido no banco de dados que pode processar dados em um planejamento. Por exemplo, você pode agrupar todos os registros de um dia a cada 24 horas, calcular a média e escrever um novo ponto em outra tabela sem escrever suas próprias bicicletas.
Também há
políticas de retenção (
doc ) - configurando a exclusão de dados após um período. É útil quando, por exemplo, você precisa armazenar a carga na CPU por uma semana com medições uma vez por segundo, mas a uma distância de alguns meses essa precisão não é necessária. Nessa situação, você pode fazer o seguinte:
- crie uma consulta contínua para agregar dados em outra tabela;
- Para a primeira tabela, defina uma política para excluir métricas anteriores à semana.
E o Influx reduzirá independentemente o tamanho dos dados e excluirá desnecessariamente.
Sobre dados armazenados
Poucos dados são armazenados: cerca de 70 mil transações e outro milhão de pontos com informações de mercado. Adicionando novas entradas - não mais que 3000 pontos por dia. Também existem métricas no site, mas existem poucos dados e, pela política de retenção, eles são armazenados por não mais que um mês.
Os problemas
Durante o desenvolvimento e os testes subsequentes do serviço, surgiram problemas cada vez mais críticos durante a operação do InfluxDB.
1. Exclusão de dados
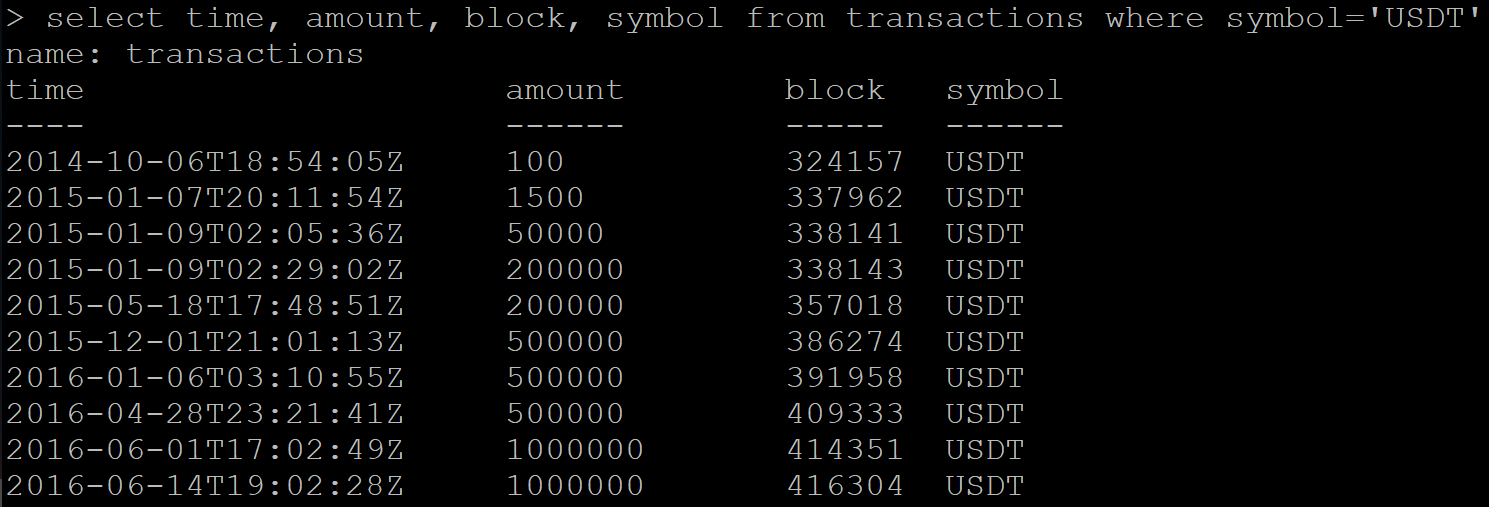
Há uma série de dados com transações:
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'
Resultado:
Eu envio um comando para excluir dados:
DELETE FROM transactions WHERE symbol='USDT'
Em seguida, solicito o recebimento de dados já excluídos. E o Influx, em vez de uma resposta vazia, retorna parte dos dados que devem ser excluídos.
Eu tento excluir a tabela inteira:
DROP MEASUREMENT transactions
Verifico a exclusão da tabela:
SHOW MEASUREMENTS
Não assisto à tabela na lista, mas uma nova solicitação de dados ainda retorna o mesmo conjunto de transações.
O problema me ocorreu apenas uma vez, pois o caso de exclusão é um caso isolado. Mas esse comportamento do banco de dados claramente não se enquadra na estrutura do trabalho "correto". Mais tarde, no github, encontrei um
ticket aberto há quase um ano sobre esse tópico.
Como resultado, a remoção e a restauração subsequente de todo o banco de dados ajudaram.
2. Números de ponto flutuante
Cálculos matemáticos usando as funções internas do InfluxDB fornecem erros de precisão. Não que fosse algo incomum, mas desagradável.
No meu caso, os dados têm um componente financeiro e eu gostaria de processá-los com alta precisão. Por esse motivo, os planos de abandonar consultas contínuas.
3. As consultas contínuas não podem ser adaptadas a diferentes fusos horários
O serviço possui uma tabela com estatísticas diárias sobre transações. Para cada dia, você precisa agrupar todas as transações para esse dia. Mas o dia para cada usuário começará em um horário diferente, portanto, o conjunto de transações é diferente. O UTC possui
37 opções de turno para as quais você precisa agregar dados.
Ao agrupar por hora no InfluxDB, você também pode especificar um turno, por exemplo, para a hora de Moscou (UTC + 3):
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)
Mas o resultado da consulta estará incorreto. Por alguma razão, os dados agrupados por dia começarão em 1677 (o InfluxDB suporta oficialmente o período deste ano):
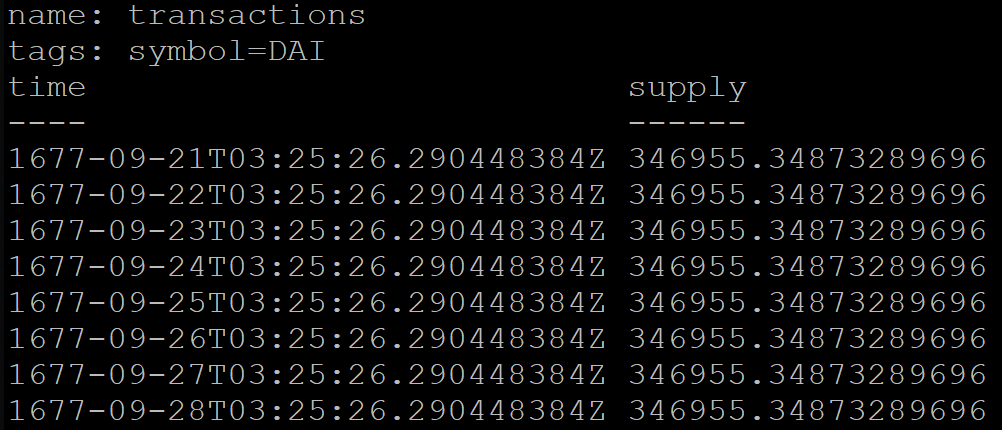
Para contornar esse problema, o serviço foi temporariamente transferido para o UTC + 0.
4. Desempenho
Existem muitos benchmarks na Internet com comparações do InfluxDB e outros bancos de dados. No primeiro contato, eles pareciam materiais de marketing, mas agora acho que há alguma verdade neles.
Vou lhe contar o meu caso.
O serviço fornece um método de API que retorna estatísticas para o último dia. Durante os cálculos, o método consulta o banco de dados três vezes com as seguintes consultas:
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1
SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1
SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESC
Explicação
- Na primeira consulta, obtemos os últimos pontos para cada moeda com dados de mercado. Oito pontos por oito moedas no meu caso.
- A segunda solicitação recebe um o ponto mais novo.
- O terceiro solicita uma lista de transações para o último dia, pode haver várias centenas.
Esclarecemos que, no InfluxDB, um índice é criado automaticamente por tags e por tempo, o que acelera as consultas. Na primeira consulta, o
símbolo é a tag.
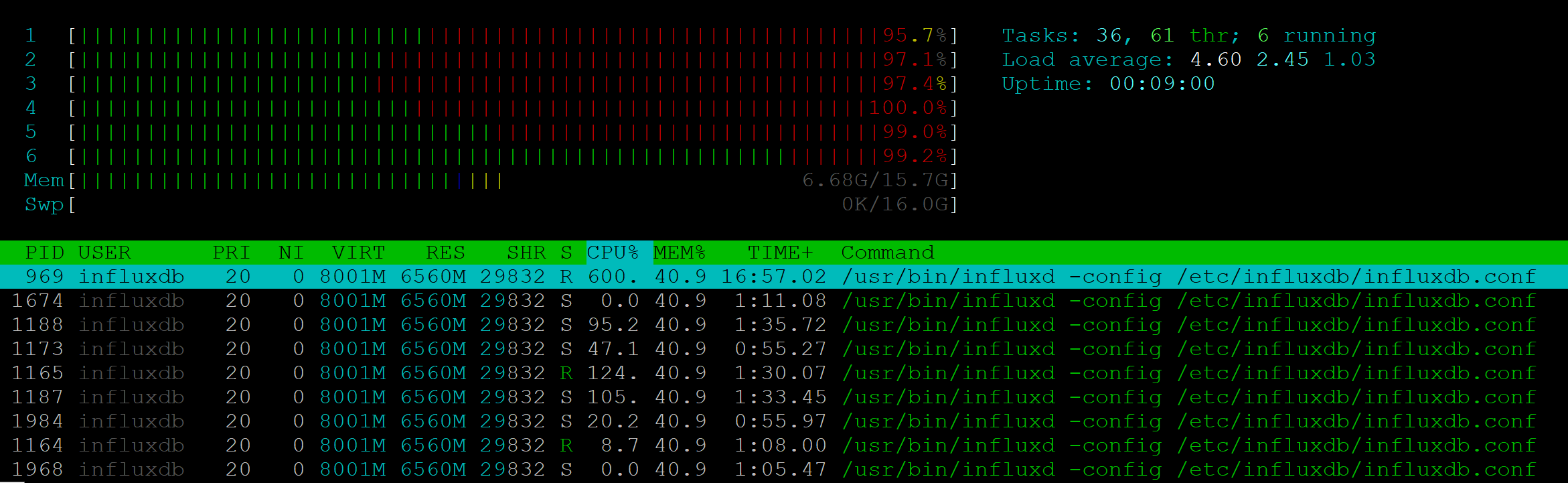
Fiz um teste de estresse para esse método API. Para 25 RPS, o servidor mostrou uma carga completa de seis CPUs:
Ao mesmo tempo, o processo NodeJs não forneceu nenhuma carga.
A velocidade de execução já foi reduzida em 7 a 10 RPS: se um cliente puder receber uma resposta em 200 ms, 10 clientes deverão esperar um segundo. 25 RPS - a fronteira com a qual a estabilidade sofreu, foram devolvidos 500 erros aos clientes.
Com esse desempenho, é impossível usar o Influx em nosso projeto. Além disso: em um projeto em que você precisa demonstrar o monitoramento para muitos clientes, problemas semelhantes podem aparecer e o servidor de métricas será sobrecarregado.
Conclusão
A conclusão mais importante da experiência obtida é que você não pode levar uma tecnologia desconhecida para o projeto sem análise suficiente. Uma simples triagem de tickets abertos no github pode fornecer informações para não levar o InfluxDB como o principal data warehouse.
O InfluxDB deveria ter sido bem adequado para as tarefas do meu projeto, mas, como a prática demonstrou, esse banco de dados não atende às necessidades e atrapalha muito.
Você já pode encontrar a versão 2.0.0-beta no repositório do projeto, espera-se que na segunda versão haja melhorias significativas. Enquanto isso, vou estudar a documentação do TimescaleDB.