
Ao longo dos anos, a Netcracker foi um fornecedor de produtos para operadoras de telecomunicações e, ao mesmo tempo, atua como um integrador de toda a gama de softwares de operadoras. Neste trabalho, surge inevitavelmente a tarefa de sincronizar e coordenar um grande número de versões de produtos e soluções, em diferentes combinações, de diferentes desenvolvedores e com diferentes funcionalidades. Muitos operadores evitam deliberadamente a dependência de um fornecedor, criando um zoológico de produtos de diferentes fornecedores, para que, em um cenário bastante complexo, até duas dúzias de sistemas e processos diferentes possam ser envolvidos.
Para deixar claro o que se trata, imagine que uma vez por semana você precise implementar um processo usando um conjunto de ferramentas e tecnologias diferentes: procedimentos PL / SQL, scripts bash, scripts Perl, iniciando aplicativos individuais e acessando processos daemon. Tudo isso se deve à heterogeneidade do cenário de TI do operador. Ao mesmo tempo, para cada procedimento, haverá seus próprios parâmetros de inicialização, controle de saída e um conjunto de possíveis erros que afetam a execução subsequente do script. Cada um desses lançamentos se torna uma tarefa séria, exigindo várias horas ou dias de trabalho de engenheiros de TI altamente qualificados - seu treinamento pode levar até três anos antes de serem liberados para um operador de telecomunicações produtivo com dezenas de milhões de usuários.
É claro que essas tarefas precisam ser automatizadas. Portanto, decidimos tirar o melhor proveito da BPMN Orchestra, planejador de processos, sistema de monitoramento e enriquecer esse conjunto com a capacidade de analisar logs e erros. Obviamente, os melhores representantes de seu tipo foram considerados para cada tipo de sistema. Mas não foram encontradas essências correspondentes para as especificidades da indústria. Portanto - faça você mesmo.
Brevemente sobre o que estamos fazendo: procedimentos heterogêneos são agrupados em "tarefas" com um conjunto típico de interfaces e propriedades; uma certa sequência de tarefas forma um "processo" (por exemplo, um processo de cobrança de cobranças por serviços de comunicação). Além disso, de acordo com um cronograma ou manualmente, cada processo inicia sua sequência de procedimentos com os parâmetros necessários, monitora a execução, avalia os resultados das tarefas aninhadas e toma uma decisão sobre a escolha dos cenários. O relacionamento entre as tarefas dentro do processo é baseado na lógica padrão do BPMN, enquanto no servidor de gerenciamento definimos a capacidade de interromper manualmente o processo, pausá-lo, sair do cenário atual salvando os dados que já foram processados. O gerenciamento de processos é implementado através de uma interface da Web com monitoramento em tempo real, com avaliação de anomalias, monitoramento de SLAs específicos para cada processo.
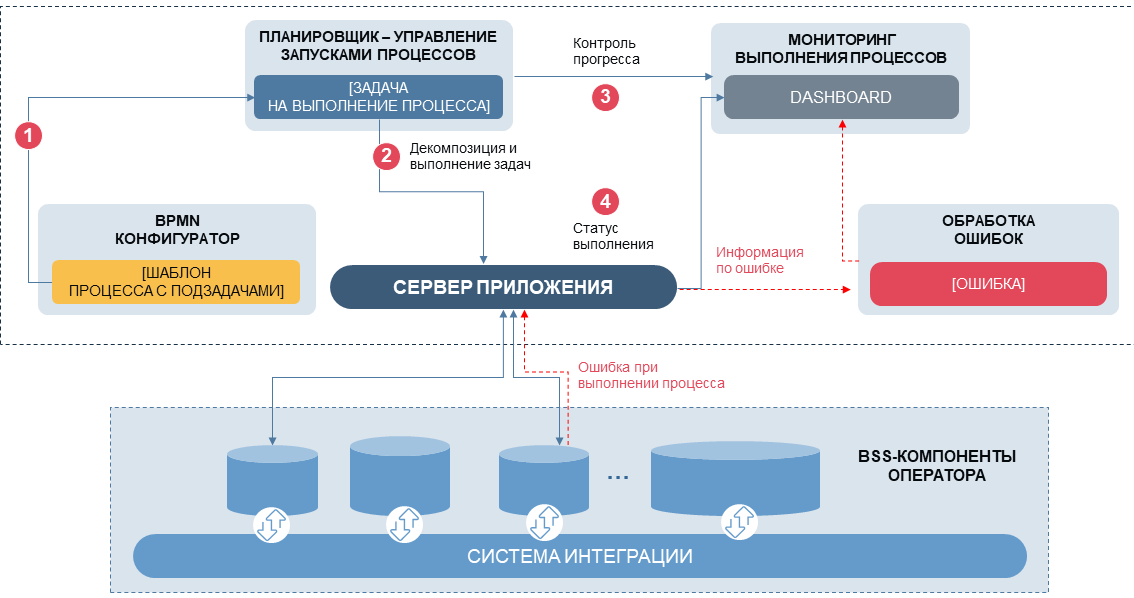
Agora, nosso "gerenciador de processos" pode funcionar de modo semi-automático, mas praticamente não reduz a carga dos engenheiros de TI - quando dois ou mais sistemas complexos interagem, a variabilidade de anomalias nos processos aumenta muitas vezes e os principais esforços são dedicados ao tratamento de erros. Portanto, na próxima etapa, tivemos que tomar uma decisão:
- Como queremos automatizar o tratamento de erros?
- Como corrigir cenários com base na análise de anomalias?
- Em geral, quanto uma pessoa deve intervir na operação desse sistema, em quais volumes e em quais locais?
Observo mais uma vez que tudo isso precisa ser feito em tempo real na produtividade do sistema de missão crítica que atende dezenas e centenas de milhares de transações por segundo. E aqui tivemos que resolver o problema de localização e solução de problemas (a chamada solução de problemas) nas condições:
- atualizações periódicas nos processos
- base transportadora em desenvolvimento
- mudanças no conjunto de serviços de telecomunicações
Sim, e outra condição importante que devemos cumprir é não prejudicar. Ou falando o idioma dos documentos oficiais - para reduzir tempo e custos de mão-de-obra na operação de sistemas de TI de um provedor de telecomunicações.
Surgiu a questão - em que proporção o tratamento automático de erros e a participação de especialistas nessa solução de problemas devem ser misturados. Em seguida, vamos falar sobre as opções.
AI
Como vivemos na era do hype eterno, decidimos fazer do desenvolvimento uma base de inteligência artificial - para que esse intelecto reconheça erros e anomalias, preveja falhas e as corrija imediatamente. Grandes empresas e pequenas startups já estão criando essas e até implementando soluções semelhantes. O principal escopo de sua aplicação: operações para construção, manutenção e suporte da infraestrutura de TI. Isso se chama AIOps - Operações de Inteligência Aritificial (para TI), e o termo mais popular é NoOps, ou seja, operações de TI totalmente automatizadas.
Aprender o sistema não será fácil, porque o conjunto de dados históricos é limitado, é caro fazer uma cópia exata do produto e os exemplos de ensino (aprendizado ativo) são muito longos e, no nosso caso, imprecisos. Você pode tentar o método de agregação de autoinicialização - para simular um conjunto finito de cenários para casos conhecidos e suspeitos e criar uma árvore de decisão com base nela, por exemplo, Árvore de Classificação e Regressão, mas esse também é um método bastante caro. Mas se fizermos tudo isso, faremos com que o programa pense por nós e economize muitos recursos úteis (que, traduzidos de gerenciais para humanos, significam "demitir os administradores de sistema mais irritantes").
Contras:
- Devido à complexidade dos sistemas e sua interação, é praticamente impossível criar e treinar uma certa versão "em caixa" dessa solução para todas as situações possíveis. Para cada novo projeto, este será o seu próprio “curso de treinamento” separado, com o reconhecimento de erros específicos, anomalias e maneiras apropriadas de resolvê-los.
- Não projetamos uma solução em massa, mas uma interna, para um número limitado de implementações (porque existem muito poucos operadores dessa escala no mundo). Pode ser fácil, de forma que seja mais econômico oferecer a nossos clientes a terceirização "humana" apropriada para resolver esses problemas.
- Talvez nossos clientes tenham mais chances de suportar os custos de novos engenheiros altamente qualificados do que correr o risco de transferir o suporte ao produto para a inteligência artificial. Para dizer o mínimo, isso pode levantar algumas preocupações.
Não me cérebros AI
Como a intervenção humana não pode ser dispensada, seguimos o caminho antiquado. Lembre-se, uma vez que pensamos que "uma máquina deve funcionar e uma pessoa deve pensar"? Nós reformulamos isso: "o programa deve resolver problemas conhecidos e o engenheiro deve resolver incógnitas".
Criamos um sistema algorítmico organizado no conceito de aprendizado reforçado, mas com lógica clara. O treinamento do sistema ocorre em um volume limitado e controlado, as regras são armazenadas de forma transparente, podem ser editadas, expandidas, especificadas, desabilitadas, etc. Esse desenvolvimento não é muito mais complicado do que a simples "semi-automação". Um engenheiro qualificado ainda é necessário para a operação, mas seus recursos são usados apenas para identificar e resolver novos problemas. Se aderirmos firmemente ao princípio "uma pessoa não deve resolver problemas conhecidos", podemos assumir que, após algum tempo, o suprimento de problemas desconhecidos começará a secar, e a funcionalidade do sistema desenvolvido abordará a IA para esse campo de aplicação específico.
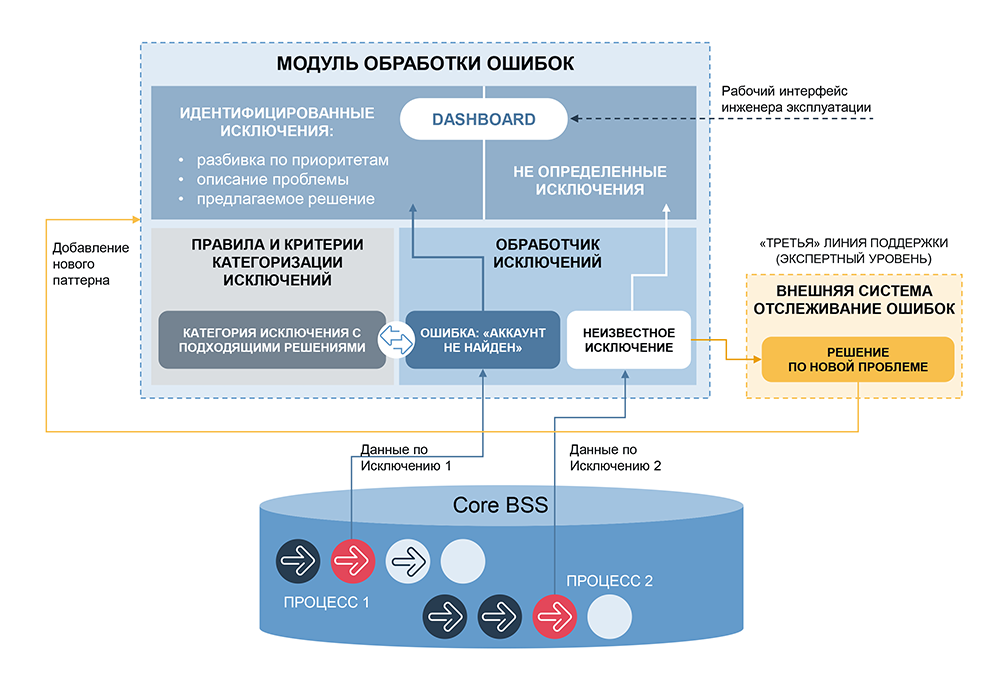
A parte mais importante desse sistema é a categorização e re-identificação de anomalias. Nossa empresa já possui um sistema semelhante - Order Tracker, que é usado para monitorar os processos de negócios de uma operadora móvel que gerencia pedidos. O Order Tracker analisa centenas de eventos por segundo, identifica anomalias em linhas separadas e em combinações de eventos, permite ao usuário agrupá-los, definir valores máximos e mínimos, determinar erros de diferentes níveis de gravidade e propor ações para resolver problemas. O sistema está em funcionamento há muito tempo, muitos rakes já foram concluídos com êxito, por isso o consideramos uma ferramenta de categorização.
Agora era necessário automatizar a solução dos problemas. Diferentemente do gerenciamento de pedidos, onde a intervenção do operador é frequentemente necessária (por exemplo, quando você precisa envolver o departamento financeiro, o atendimento ao cliente etc.), temos a capacidade de resolver automaticamente uma parte significativa dos incidentes e existe uma ferramenta pronta para projetar essas soluções - scripts a partir de blocos prontos, que pode ser complementada, com lógica expandida, inclui verificações adicionais e se associa a cada categoria reconhecida de erros.
O que poderia dar errado?
Isso é tudo!
O sistema de monitoramento de pedidos geralmente não requer tomada de decisão e correção em tempo real, e qualquer anomalia afeta um número limitado de clientes, de uma a várias centenas. Estamos tentando introduzir o tratamento automático de erros em processos que afetam centenas de milhares e milhões de assinantes e exigem uma solução em tempo real ou dentro de algumas horas. Esse é um risco enorme para qualquer operador com quem trabalhamos e, portanto, para nós, para nossa reputação.
Tivemos que aumentar significativamente a flexibilidade dos scripts, implementar um sistema de controle de versão, adicionar a entidade "instância de script", ou seja, para cada script agora você pode criar muitas subclasses com certas combinações de parâmetros, limites, verificações adicionais, etc. Eu tive que aumentar a flexibilidade de muitas tarefas, introduzindo verificações adicionais dos parâmetros de entrada e saída.
Outra direção de desenvolvimento é aumentar a granularidade das categorias de eventos analisados e criar meta-categorias, ou seja, combinações de diferentes eventos definidos pelo categorizador. Adicionamos uma estimativa da sequência de anomalias e a coincidência de diferentes anomalias no tempo. O sistema tornou-se cada vez mais complicado, mas ainda mantinha uma lógica clara - para qualquer par "categoria de anomalias - cenário selecionado", os relacionamentos causais ainda são preservados.
Para muitas combinações, já obtivemos resultados confiáveis e os lançamos de maneira produtiva. Os erros, cuja busca e correção demoravam horas, agora são resolvidos no modo automático. Para outros tipos de anomalias, ainda continuamos testando: em algum lugar nos dados de teste, em algum lugar no modo de verificação manual e confirmação do cenário selecionado.
E então acabou ...
Recentemente, percebemos que obtivemos um resultado desses trabalhos que não esperávamos no início - uma ferramenta altamente eficaz para a engenharia reversa de soluções de outras pessoas, incluindo aquelas para as quais não temos o apoio de desenvolvedores nem documentação clara. Inadvertidamente, foi realizada a chamada “descoberta de processos de negócios”. Aprendemos na prática a analisar a lógica dos aplicativos, a identificar erros internos e problemas de integração com outros sistemas. Agora não podemos apenas orquestrar os aplicativos de outras pessoas - podemos desenvolver correções para eles, melhorar a integração e o mais valioso é oferecer nossos produtos para substituir o legado existente.
No próximo estágio, queremos tentar implementar nossa solução na forma de um produto abrangente para testes de integração, que detectará automaticamente erros e anomalias, aprenderá rapidamente, fornecerá ferramentas para correção sintomática e para pesquisar e analisar problemas na lógica da aplicação. Essa solução terá menos eficiência do que os modernos AIOps e NoOps, enquanto preservamos a lógica de decisão transparente e gerenciável. Portanto, se em alguns anos você encontrar uma solução do Netcracker no mercado, lembre-se - tudo começou com scripts bash ...