
Em 8 de abril, na conferência
Saint HighLoad ++ 2019 , no âmbito da seção DevOps and Operations, foi elaborado um relatório intitulado “Expandindo e complementando Kubernetes”, criado por três funcionários da Flant. Nele, falamos sobre inúmeras situações nas quais queríamos expandir e complementar os recursos do Kubernetes, mas para os quais não encontramos uma solução pronta e simples. As soluções necessárias apareceram na forma de projetos de código aberto, e esta apresentação também é dedicada a eles.
Por tradição, temos o prazer de apresentar um
vídeo com um relatório (50 minutos, muito mais informativo que o artigo) e o aperto principal em forma de texto. Vamos lá!
K8s Kernel e Complementos
A Kubernetes está transformando uma abordagem industrial e administrativa estabelecida há muito tempo:
- Graças a suas abstrações , não operamos mais com conceitos como configurar uma configuração ou executar um comando (Chef, Ansible ...), mas usamos agrupamentos de contêineres, serviços, etc.
- Podemos preparar aplicativos sem pensar nas nuances da plataforma específica em que será lançada: bare metal, a nuvem de um dos fornecedores, etc.
- Com os K8s, as melhores práticas para organizar a infraestrutura tornaram-se mais acessíveis do que nunca: dimensionamento, autocorreção, tolerância a falhas etc.
No entanto, é claro, tudo não é tão tranquilo: com o Kubernetes surgiram seus próprios - novos - desafios.
O Kubernetes
não é uma combinação que resolve todos os problemas de todos os usuários.
O núcleo do Kubernetes é responsável apenas pelo conjunto de funções mínimas necessárias presentes em
cada cluster:
No núcleo do Kubernetes, é definido um conjunto básico de primitivas - para agrupar contêineres, gerenciar tráfego e assim por diante. Falamos sobre eles em mais detalhes em um
relatório de 2 anos atrás .
Por outro lado, o K8s oferece grandes oportunidades para expandir as funções disponíveis, o que ajuda a fechar as necessidades de outros usuários específicos. Os administradores de cluster são responsáveis pelas adições ao Kubernetes, que devem instalar e configurar tudo o necessário para que o cluster "tome a forma necessária" [para resolver seus problemas específicos]. Que tipo de acréscimos são esses? Vejamos alguns exemplos.
Exemplos de adições
Após a instalação do Kubernetes, podemos nos surpreender que a rede, tão necessária para a interação dos pods dentro do nó e entre nós, não funcione por si só. O núcleo do Kubernetes não garante as conexões necessárias - em vez disso, define uma
interface de rede (
CNI ) para complementos de terceiros. Precisamos instalar uma dessas adições, que será responsável pela configuração da rede.

Um exemplo próximo são as soluções de armazenamento de dados (disco local, dispositivo de bloco de rede, Ceph ...). Inicialmente, eles estavam no kernel, mas com o advento do
CSI, a situação muda para uma similar já descrita: no Kubernetes, a interface e sua implementação, em módulos de terceiros.
Entre outros exemplos:
- Controladores de ingresso (para uma revisão, consulte nosso artigo recente ) .
- gerente de certificação :

- Os operadores são uma classe inteira de complementos (que incluem o gerente de certificação mencionado), eles definem o (s) primitivo (s) e o (s) controlador (es). A lógica de seu trabalho é limitada apenas por nossa imaginação e nos permite transformar componentes de infraestrutura prontos (por exemplo, DBMS) em primitivos, que são muito mais fáceis de trabalhar (do que com um conjunto de contêineres e suas configurações). Um grande número de operadores foi gravado - embora muitos deles ainda não estejam prontos para produção, isso é apenas uma questão de tempo:
- Métricas é outra ilustração de como o Kubernetes separou a interface (API de métricas) da implementação (complementos de terceiros, como o adaptador Prometheus, o agente de cluster do Datadog ...).
- Para monitoramento e estatísticas , onde, na prática, não são necessários apenas Prometheus e Grafana , mas também métricas de estado de cubo, exportador de nó etc.
E essa não é uma lista completa de complementos ... Por exemplo, na empresa Flant hoje instalamos
29 complementos para cada cluster Kubernetes (todos eles criam 249 objetos Kubernetes no total). Simplificando, não vemos a vida de um cluster sem acréscimos.
Automação
Os operadores são projetados para automatizar as operações rotineiras que enfrentamos diariamente. Aqui estão exemplos de vida que seriam ótimos para escrever um operador:
- Há um registro privado (ou seja, que exige login) com imagens para o aplicativo. Supõe-se que cada pod esteja vinculado a um segredo especial que permita a autenticação no registro. Nossa tarefa é garantir que esse segredo seja encontrado no espaço para nome, para que os pods possam baixar imagens. Pode haver muitos aplicativos (cada um dos quais precisa de um segredo), e é útil atualizar regularmente os próprios segredos, para que a opção de descobrir os segredos com as mãos desapareça. Aqui o operador vem ao resgate: criamos um controlador que aguardará o espaço para nome aparecer e adicionamos um segredo ao espaço para nome para este evento.
- Suponha que, por padrão, o acesso dos pods à Internet seja proibido. Mas às vezes pode ser necessário: é lógico que o mecanismo de permissão de acesso funcione simplesmente sem exigir habilidades específicas, por exemplo, pela presença de um determinado rótulo no espaço para nome. Como o operador nos ajudará aqui? É criado um controlador que espera que o rótulo apareça no espaço para nome e adicione a política apropriada para acessar a Internet.
- Uma situação semelhante: precisamos adicionar uma certa mancha ao nó se ele tiver um rótulo semelhante (com algum tipo de prefixo). Ações com o operador são óbvias ...
Em qualquer cluster, é necessário resolver tarefas de rotina e fazer isso
corretamente - usando operadores.
Resumindo todas as histórias descritas, chegamos à conclusão de que,
para um trabalho confortável no Kubernetes, é necessário : a)
instalar complementos , b)
desenvolver operadores (para resolver tarefas diárias de administração).
Como escrever uma declaração para Kubernetes?
Em geral, o esquema é simples:
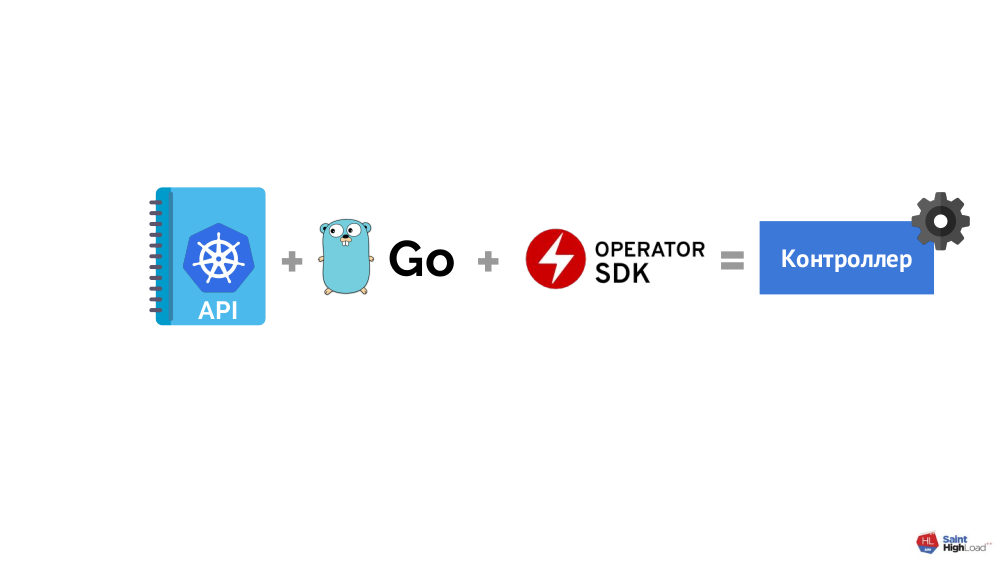
... mas acontece que:
- A API do Kubernetes é uma coisa não trivial que requer muito tempo para dominar;
- a programação também não é para todos (o Go é escolhido como o idioma preferido porque existe uma estrutura especial para ele - SDK do Operador );
- com a estrutura como tal, uma situação semelhante.
Conclusão:
para escrever um controlador (operador), você precisa
gastar recursos significativos para estudar o material. Isso seria justificado para os "grandes" operadores - digamos, para o MySQL DBMS. Mas se recordarmos os exemplos descritos acima (revelando segredos, acesso de pods à Internet ...), que também queremos fazer corretamente, entenderemos que os esforços gastos compensarão o resultado agora necessário:

Em geral, surge um dilema: gaste muitos recursos e encontre a ferramenta certa para escrever declarações ou agir "da maneira antiga" (mas rapidamente). Para resolvê-lo - para encontrar um compromisso entre esses extremos - criamos nosso próprio projeto:
operador de shell (veja também seu recente anúncio no hub) .
Operador Shell
Como ele trabalha? No cluster, há um pod no qual o Go-binário com operador de shell se encontra. Um conjunto de
ganchos é armazenado próximo a ele
(para obter mais detalhes sobre eles, veja abaixo) . O próprio operador de shell se inscreve em determinados
eventos na API Kubernetes, nos quais lança os ganchos correspondentes.
Como o operador de shell entende quais ganchos acionar em quais eventos? Essas informações são passadas ao operador do shell pelos próprios ganchos e elas tornam muito simples.
Um gancho é um script Bash ou qualquer outro arquivo executável que suporte um único argumento
--config e retorna JSON em resposta a ele. O último determina quais objetos o interessam e quais eventos (para esses objetos) devem ser reagidos:

Ilustrarei a implementação do operador de shell de um de nossos exemplos - revelando segredos para acessar um registro privado com imagens de aplicativos. Consiste em duas etapas.
Prática: 1. Escrevendo um gancho
A primeira etapa do processo é processar
--config , indicando que estamos interessados no espaço para nome e, especificamente - no momento de sua criação:
[[ $1 == "--config" ]] ; then cat << EOF { "onKubernetesEvent": [ { "kind": "namespace", "event": ["add"] } ] } EOF …
Como será a lógica? Muito simples também:
… else createdNamespace=$(jq -r '.[0].resourceName' $BINDING_CONTEXT_PATH) kubectl create -n ${createdNamespace} -f - << EOF Kind: Secret ... EOF fi
A primeira etapa é descobrir qual namespace foi criado e a segunda etapa é criar um segredo para esse namespace através do
kubectl .
Prática: 2. Montagem de uma imagem
Resta transferir o gancho criado para o operador de shell - como fazer isso? O próprio operador de shell é fornecido como uma imagem do Docker, portanto, nossa tarefa é adicionar um gancho a um diretório especial nesta imagem:
FROM flant/shell-operator:v1.0.0-beta.1 ADD my-handler.sh /hooks
Resta coletá-lo e pressionar:
$ docker build -t registry.example.com/my-operator:v1 . $ docker push registry.example.com/my-operator:v1
O toque final é incorporar a imagem em um cluster. Para fazer isso, escreva
Deployment :
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: my-operator spec: template: spec: containers: - name: my-operator image: registry.example.com/my-operator:v1 # 1 serviceAccountName: my-operator # 2
Nele, você precisa prestar atenção a dois pontos:
- Indicação de imagem recém-criada;
- este é um componente do sistema que (no mínimo) precisa de direitos para se inscrever em eventos no Kubernetes e revelar segredos por espaço para nome, por isso criamos uma ServiceAccount (e um conjunto de regras) para o gancho.
O resultado - resolvemos nosso problema de maneira
nativa do Kubernetes, criando um operador para revelar segredos.
Outros recursos do operador de shell
Para limitar os objetos do tipo de sua escolha com os quais o gancho funcionará,
você pode filtrá-los filtrando por rótulos específicos (ou usando
matchExpressions ):
"onKubernetesEvent": [ { "selector": { "matchLabels": { "foo": "bar", }, "matchExpressions": [ { "key": "allow", "operation": "In", "values": ["wan", "warehouse"], }, ], } … } ]
É fornecido um
mecanismo de deduplicação , que - usando um filtro jq - permite converter JSONs grandes de objetos em objetos pequenos, onde permanecem apenas esses parâmetros que queremos monitorar a mudança.
Quando o gancho é chamado, o operador de shell passa
dados sobre o objeto , que podem ser usados para qualquer necessidade.
Os eventos em que os ganchos são acionados não se limitam aos eventos do Kubernetes: o operador shell fornece suporte para
chamar ganchos por tempo (semelhante ao crontab no agendador tradicional), bem como um evento
onStartup especial. Todos esses eventos podem ser combinados e atribuídos ao mesmo gancho.
E mais dois recursos do operador de shell:
- Funciona de forma assíncrona . Desde o evento Kubernetes (por exemplo, a criação de um objeto), outros eventos (por exemplo, a remoção do mesmo objeto) podem ocorrer no cluster, e isso deve ser levado em consideração em ganchos. Se o gancho falhar, por padrão, ele será chamado novamente até a conclusão bem-sucedida (esse comportamento pode ser alterado).
- Ele exporta métricas para o Prometheus, com as quais você pode entender se o operador de shell está funcionando, descobrir o número de erros para cada gancho e o tamanho atual da fila.
Para resumir esta parte do relatório:

Instalação de Complementos
Para um trabalho confortável com o Kubernetes, também foi mencionada a necessidade de instalar complementos. Vou falar sobre isso no exemplo da maneira como nossa empresa é como estamos fazendo isso agora.
Começamos a trabalhar com o Kubernetes com vários clusters, a única adição ao Ingress. Era necessário colocá-lo em cada cluster de maneira diferente e fizemos várias configurações de YAML para diferentes ambientes: bare metal, AWS ...
Havia mais clusters - mais configurações. Além disso, aprimoramos essas configurações elas mesmas, como resultado das quais elas se tornaram bastante heterogêneas:
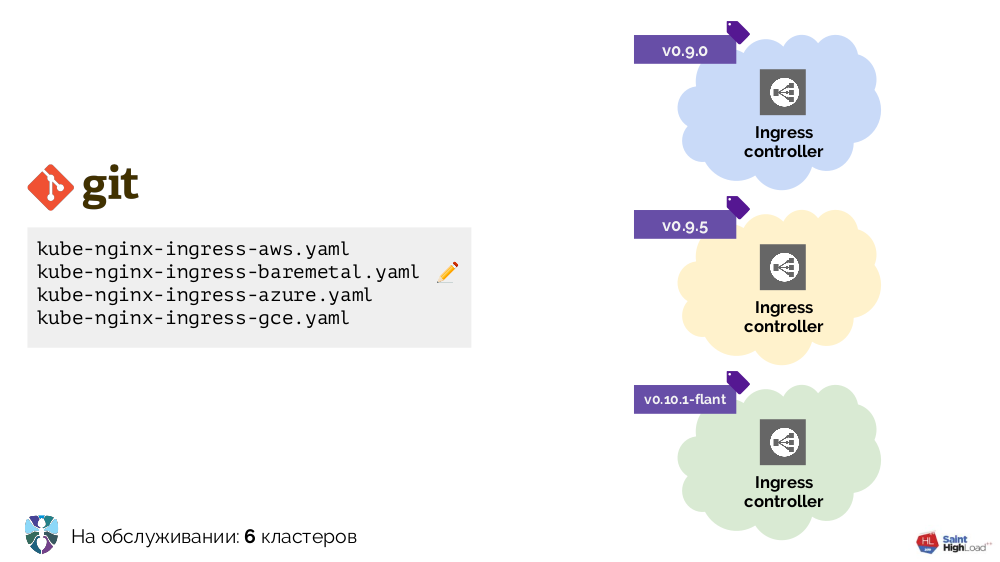
Para colocar tudo em ordem, começamos com um script (
install-ingress.sh ), que levou o tipo de cluster a ser implementado como argumento, gerou a configuração YAML desejada e a implementou no Kubernetes.
Em resumo, nosso caminho adicional e os argumentos relacionados a ele foram os seguintes:
- para trabalhar com configurações YAML, é necessário um mecanismo de modelo (nos primeiros estágios, é um simples sed);
- com o aumento do número de clusters, surgiu a necessidade de atualizações automáticas (a solução mais antiga é colocar um script no Git, atualizá-lo pelo cron e executá-lo);
- um script semelhante foi necessário para o Prometheus (
install-prometheus.sh ), no entanto, é digno de nota o fato de exigir muito mais dados de entrada, além de seu armazenamento (no bom sentido, centralizado e no cluster), e alguns dados (senhas) podem ser gerados automaticamente :

- o risco de incluir algo errado em um número crescente de clusters estava em constante crescimento; portanto, percebemos que os instaladores (ou seja, dois scripts: para Ingress e Prometheus) precisavam da configuração do estágio (várias ramificações no Git, vários cron para atualizá-las nas correspondentes: clusters estáveis ou de teste);
- tornou-se difícil trabalhar com o
kubectl apply , porque não é declarativo e pode apenas criar objetos, mas não tomar decisões sobre seu status / excluí-los; - faltavam algumas funções que não realizamos naquele momento:
- controle total sobre o resultado de atualizações de cluster,
- determinação automática de alguns parâmetros (entrada para scripts de instalação) com base em dados que podem ser obtidos no cluster (descoberta),
- seu desenvolvimento lógico na forma de descoberta contínua.
Percebemos toda essa experiência acumulada no âmbito de nosso outro projeto -
operador addon .
Operador adicional
É baseado no operador de shell já mencionado. Todo o sistema é o seguinte:
Aos ganchos do operador shell são adicionados:
- valores de armazenamento
- Gráfico do leme
- o componente que monitora o repositório de valores e - em caso de alterações - solicita ao Helm que volte a rolar o gráfico.

Assim, podemos responder a um evento no Kubernetes, iniciar um gancho e, a partir dele, fazer alterações no repositório, após o qual o gráfico será recarregado. No esquema resultante, selecionamos um conjunto de ganchos e um gráfico em um componente, que chamamos de
módulo :
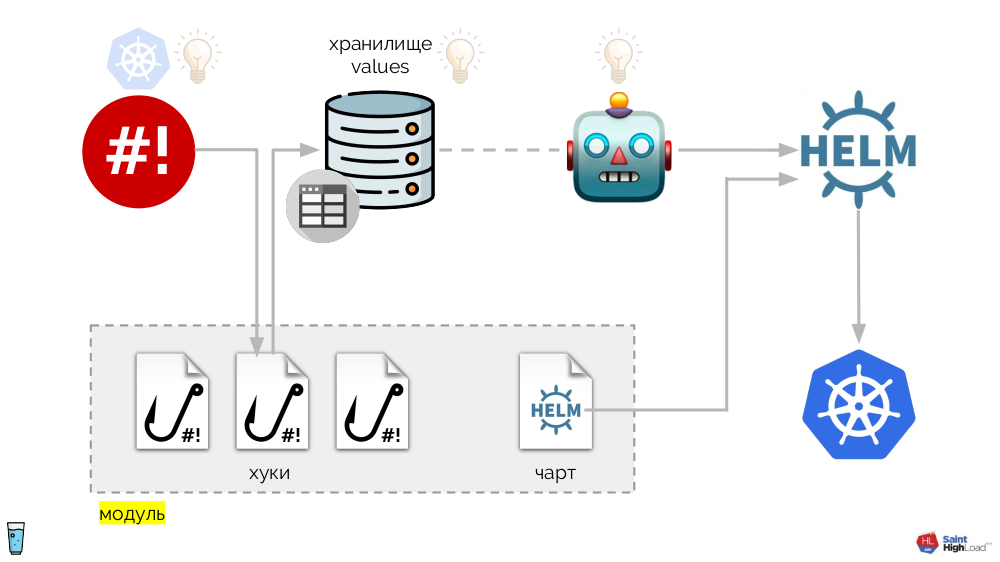
Pode haver muitos módulos e, a eles, adicionamos ganchos globais, um armazenamento de valores globais e um componente que monitora esse armazenamento global.
Agora que algo está acontecendo no Kubernetes, podemos responder a isso com um gancho global e mudar algo no repositório global. Essa alteração será notada e causará reversão de todos os módulos no cluster:
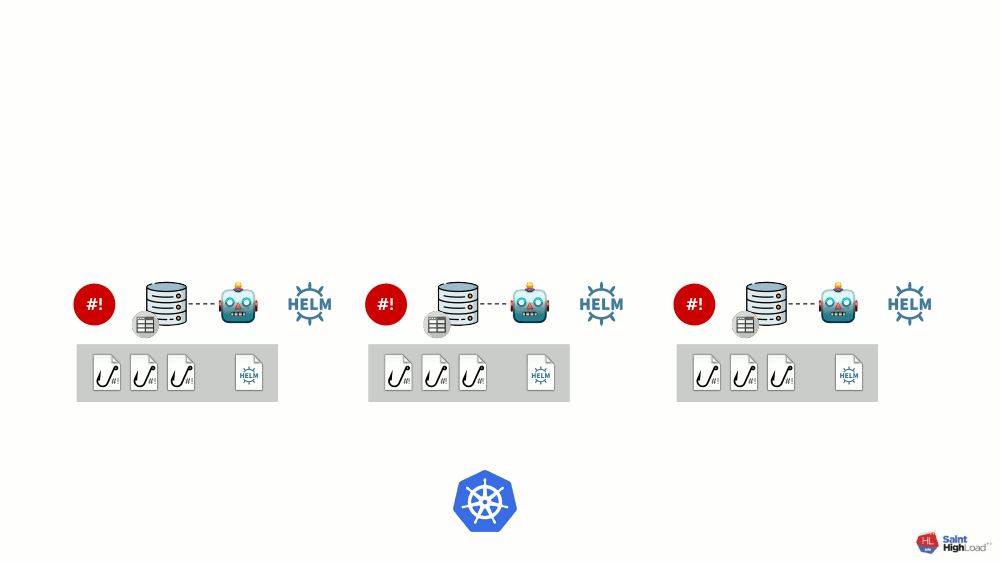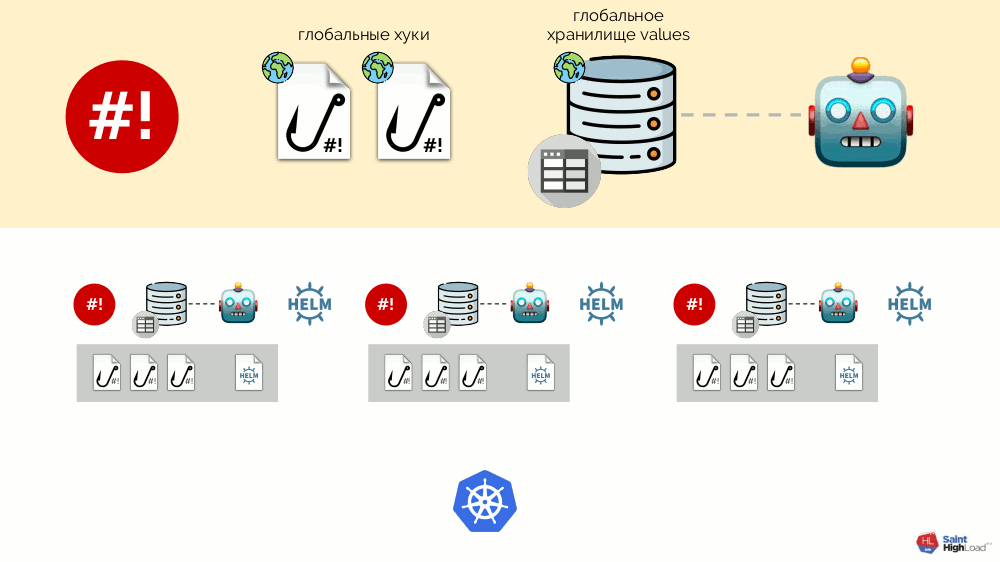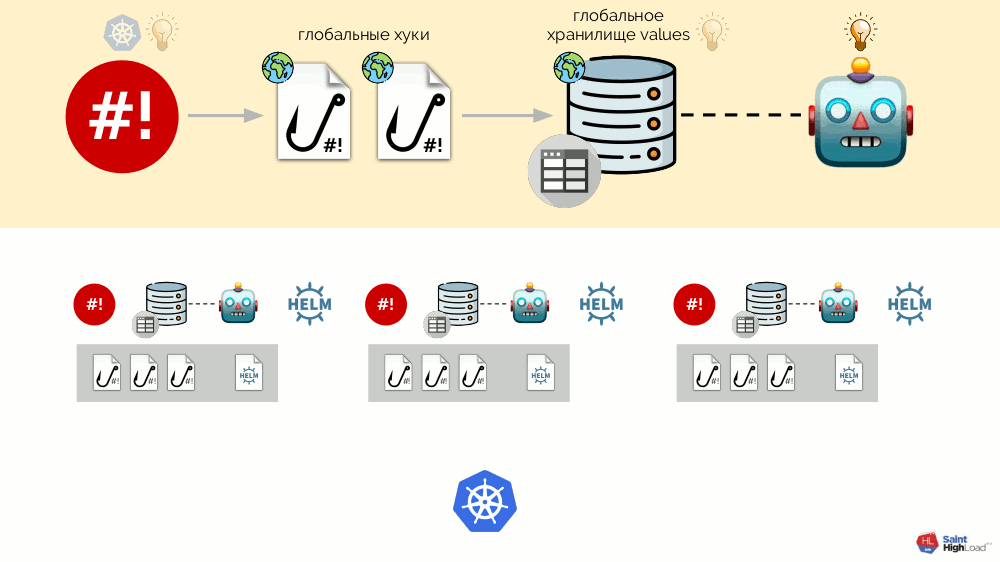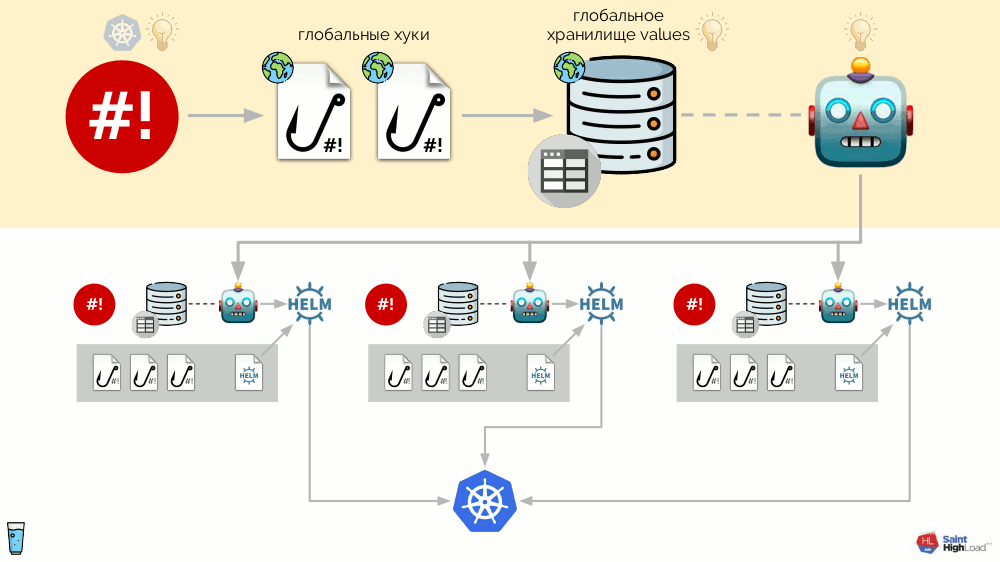
Esse esquema atende a todos os requisitos para a instalação de complementos anunciados acima:
- Helm é responsável pela padronização e declaratividade.
- O problema de atualização automática foi resolvido com a ajuda de um gancho global que acessa o registro de acordo com o cronograma e, se houver uma nova imagem do sistema, o relançará (ou seja, “ele mesmo”).
- O armazenamento das configurações no cluster é implementado usando o ConfigMap , no qual os dados primários dos armazenamentos são registrados (na inicialização, eles são carregados nos armazenamentos).
- Os problemas de geração de senha, descoberta e descoberta contínua são resolvidos usando ganchos.
- A preparação é obtida graças às tags que o Docker suporta imediatamente.
- O resultado é monitorado usando métricas pelas quais podemos entender o status.
Todo esse sistema é implementado como um único binário em movimento, chamado de operador de complemento. Graças a isso, o esquema parece mais simples:

O componente principal neste diagrama é um conjunto de módulos
(acinzentado abaixo) . Agora podemos escrever um módulo com um pouco de esforço para o complemento desejado e ter certeza de que ele será instalado em cada cluster, será atualizado e responderá aos eventos necessários no cluster.
Flant usa
addon-operator em mais de 70 clusters Kubernetes. O status atual é
a versão alfa . Agora estamos preparando a documentação para o lançamento da versão beta, mas, por enquanto
, há exemplos disponíveis no repositório, com base nos quais você pode criar seu complemento.
Onde obter os módulos addon-operator eles mesmos? A publicação de nossa biblioteca é a próxima etapa para nós, planejamos fazê-lo no verão.
Vídeos e slides
Vídeo da apresentação (~ 50 minutos):
Apresentação do relatório:
PS
Outros relatórios em nosso blog:
Você também pode estar interessado nas seguintes publicações: