
Tecnologias e modelos para o nosso futuro sistema de visão computacional foram criados e aprimorados gradualmente em vários projetos de nossa empresa - no Mail, Cloud e Search. Amadurecido como um bom queijo ou conhaque. Depois que percebemos que nossas redes neurais mostravam excelentes resultados de reconhecimento e decidimos reuni-las em um único produto b2b - Vision - que agora usamos a nós mesmos e nos oferecemos para usá-lo.
Hoje, nossa tecnologia de visão computacional na plataforma Mail.Ru Cloud Solutions funciona com sucesso e resolve problemas práticos muito complexos. É baseado em várias redes neurais treinadas em nossos conjuntos de dados e especializadas na solução de problemas aplicados. Todos os serviços estão girando em nossas capacidades de servidor. Você pode integrar a API pública do Vision em seus aplicativos, através dos quais todos os recursos do serviço estão disponíveis. A API é rápida - graças às GPUs do servidor, o tempo médio de resposta em nossa rede é de 100 ms.
Por baixo do corte, há uma história detalhada e muitos exemplos de Visão.
Como exemplo de um serviço no qual nós mesmos usamos as tecnologias de reconhecimento de rosto acima mencionadas, podemos citar
Eventos . Um de seus componentes é o suporte para fotos Vision, que instalamos em várias conferências. Se você for a um estande de fotos, tirar uma foto com a câmera embutida e digitar seu e-mail, o sistema encontrará imediatamente entre o conjunto de fotos aquelas das quais os fotógrafos regulares da conferência o capturaram e, se desejar, enviará as fotos encontradas por e-mail. E não se trata de fotos em etapas - a Vision reconhece você mesmo em segundo plano na multidão de visitantes. Obviamente, eles não são reconhecidos pela própria foto, são apenas tablets em belas montanhas-russas que simplesmente fotografam convidados em suas câmeras embutidas e transmitem informações aos servidores, onde toda a magia do reconhecimento ocorre. E observamos repetidamente como é surpreendente a eficácia da tecnologia, mesmo entre os especialistas em reconhecimento de imagens. Abaixo falaremos sobre alguns exemplos.
1. Nosso modelo de reconhecimento facial
1.1 Rede neural e velocidade de processamento
Para reconhecimento, usamos uma modificação do modelo de rede neural ResNet 101. O pool médio no final é substituído por uma camada totalmente conectada, semelhante à maneira como foi feita no ArcFace. No entanto, o tamanho das representações vetoriais é 128, não 512. Nosso conjunto de treinamento contém cerca de 10 milhões de fotos de 273.593 pessoas.
O modelo funciona muito rápido, graças a uma arquitetura de configuração do servidor cuidadosamente selecionada e à computação da GPU. São necessários 100 ms para obter uma resposta da API em nossas redes internas - isso inclui detecção de rosto (detecção de rosto na foto), reconhecimento e retorno do PersonID na resposta da API. Com grandes volumes de dados recebidos - fotos e vídeos - levará muito mais tempo para transferir dados para o serviço e receber uma resposta.
1.2 Estimativa da eficiência do modelo
Mas determinar a eficiência das redes neurais é uma tarefa muito mista. A qualidade do trabalho deles depende de quais conjuntos de dados os modelos foram treinados e se foram otimizados para trabalhar com dados específicos.
Começamos a avaliar a precisão do nosso modelo com o popular teste de verificação LFW, mas é muito pequeno e simples. Depois de atingir 99,8% de precisão, não é mais útil. Existe uma boa competição para avaliar os modelos de reconhecimento - o Megaface alcançou gradualmente 82% do ranking 1. O teste do Megaface consiste em um milhão de fotos - distratores - e o modelo deve ser capaz de distinguir vários milhares de fotos de celebridades do conjunto de dados Facescrub dos distratores. No entanto, após termos eliminado o teste de erros do Megaface, descobrimos que na versão limpa atingimos uma precisão de 98% no ranking 1 (fotos de celebridades geralmente são bastante específicas). Portanto, eles criaram um teste de identificação separado, semelhante ao Megaface, mas com fotos de pessoas "comuns". Melhorou ainda mais a precisão do reconhecimento em seus conjuntos de dados e foi muito além. Além disso, usamos o teste de qualidade de agrupamento, que consiste em vários milhares de fotografias; Simula a marcação de rostos na nuvem do usuário. Nesse caso, clusters são grupos de indivíduos semelhantes, um grupo para cada pessoa reconhecível. Verificamos a qualidade do trabalho em grupos reais (verdadeiro).
Obviamente, qualquer modelo possui erros de reconhecimento. Porém, essas situações geralmente são resolvidas ajustando os limites para condições específicas (para todas as conferências usamos os mesmos limites e, por exemplo, para ACSs, precisamos aumentar significativamente os limites para que haja menos falsos positivos). A grande maioria dos participantes da conferência foi reconhecida por nossos estandes de fotos Vision corretamente. Às vezes, alguém olhava para a visualização cortada e dizia: "Seu sistema estava errado, não sou eu". Em seguida, abrimos a fotografia inteira e constatamos que esse visitante realmente estava na fotografia, mas eles não a tiraram, mas outra pessoa, apenas um homem apareceu acidentalmente em segundo plano na zona de desfoque. Além disso, a rede neural geralmente reconhece corretamente mesmo quando uma parte do rosto não está visível, ou uma pessoa está de perfil, ou mesmo semifacial. O sistema pode reconhecer uma pessoa, mesmo que ela caia no campo da distorção óptica, por exemplo, ao fotografar com uma lente grande angular.
1.3 Testando exemplos em situações difíceis
Abaixo estão exemplos da operação de nossa rede neural. Na entrada, as fotos são enviadas, as quais ela deve marcar usando o PersonID - um identificador exclusivo para a pessoa. Se duas ou mais imagens tiverem o mesmo identificador, de acordo com os modelos, essas fotos mostrarão uma pessoa.
Imediatamente, observamos que durante o teste, temos acesso a vários parâmetros e limites de modelos que podemos configurar para alcançar um resultado específico. A API pública é otimizada para máxima precisão em casos comuns.
Vamos começar com o mais simples, com reconhecimento de rosto.

Bem, isso foi fácil demais. Nós complicamos a tarefa, adicionamos barba e alguns anos.

Alguém dirá que isso não foi muito difícil, porque em ambos os casos a face é visível na sua totalidade, o algoritmo possui muitas informações sobre a face. Ok, coloque Tom Hardy de perfil. Essa tarefa é muito mais complicada e investimos muito em sua solução bem-sucedida, mantendo um baixo nível de erros: selecionamos uma amostra de treinamento, pensamos na arquitetura da rede neural, aprimoramos as funções de perda e melhoramos o processamento preliminar de fotos.
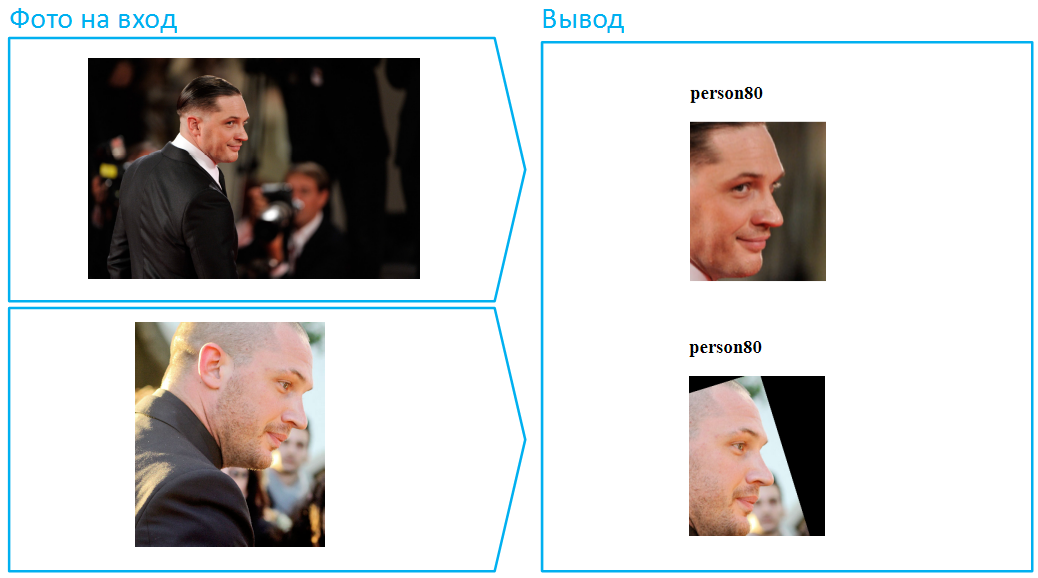
Vamos colocar um chapéu nele:

A propósito, este é um exemplo de uma situação particularmente difícil, já que o rosto é muito coberto aqui, e na imagem inferior também há uma sombra profunda que esconde os olhos. Na vida real, as pessoas muitas vezes mudam de aparência com a ajuda de óculos escuros. Faça o mesmo com o Tom.

Bem, vamos tentar enviar fotos de diferentes idades, e desta vez colocaremos experiência em outro ator. Vamos dar um exemplo muito mais complexo quando as alterações relacionadas à idade são especialmente pronunciadas. A situação não é exagerada, acontece o tempo todo quando você precisa comparar uma fotografia no seu passaporte com a cara do portador. Afinal, a primeira foto fica presa no passaporte quando o proprietário tem 20 anos e 45 pessoas podem mudar:

Você acha que o principal especial em missões impossíveis não mudou muito com a idade? Eu acho que mesmo poucas pessoas combinariam as fotos superior e inferior, o garoto mudou muito ao longo dos anos.

As redes neurais enfrentam mudanças na aparência com muito mais frequência. Por exemplo, às vezes as mulheres podem mudar bastante sua imagem com a ajuda de cosméticos:

Agora vamos complicar ainda mais a tarefa: cubra diferentes partes do rosto em fotos diferentes. Nesses casos, o algoritmo não pode comparar as amostras inteiras. No entanto, o Vision lida bem com essas situações.
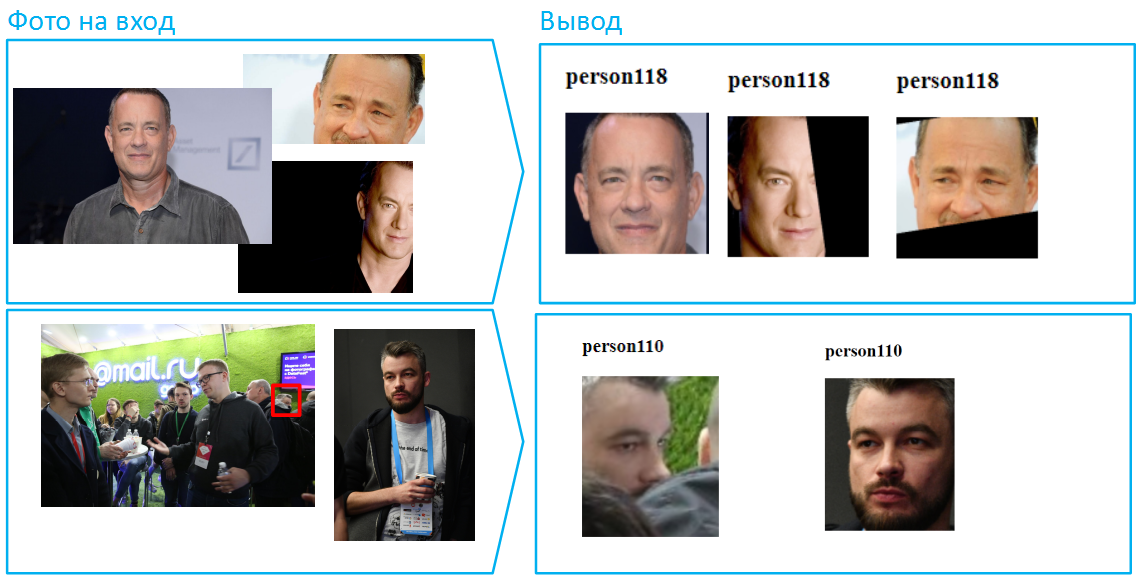
A propósito, existem muitos rostos nas fotografias, por exemplo, mais de 100 pessoas podem se encaixar em uma imagem comum do salão. Essa é uma situação difícil para redes neurais, pois muitos rostos podem ser iluminados de maneira diferente, alguém fora da zona de nitidez. No entanto, se a foto foi tirada com resolução e qualidade suficientes (pelo menos 75 pixels por quadrado cobrindo o rosto), o Vision poderá identificá-la e reconhecê-la.

A peculiaridade de relatar fotografias e imagens de câmeras de vigilância é que as pessoas geralmente ficam embaçadas porque estavam fora do campo de nitidez ou se moviam naquele momento:

Além disso, a intensidade da iluminação pode variar bastante de imagem para imagem. Isso também costuma se transformar em um obstáculo; muitos algoritmos têm grande dificuldade em processar corretamente imagens muito escuras e muito claras, sem mencionar a comparação exata. Deixe-me lembrá-lo que, para alcançar esse resultado, você precisa definir limites de uma certa maneira, essa possibilidade ainda não está disponível ao público. Para todos os clientes, usamos a mesma rede neural, com limites adequados para as tarefas mais práticas.

Recentemente, lançamos uma nova versão do modelo que reconhece rostos asiáticos com alta precisão. Anteriormente, esse era um grande problema, que era chamado de "racismo de aprendizado de máquina" (ou "redes neurais"). As redes neurais européias e americanas reconheceram bem os rostos europeus, e as coisas foram muito piores com os mongolóides e os negróides. Provavelmente na mesma China, a situação era exatamente o oposto. É tudo sobre conjuntos de dados de treinamento que refletem os tipos dominantes de pessoas em um país específico. No entanto, a situação está mudando, hoje esse problema está longe de ser tão agudo. A visão não tem dificuldades com representantes de diferentes raças.

O reconhecimento de faces é apenas uma das muitas aplicações de nossa tecnologia; o Vision pode ser ensinado a reconhecer qualquer coisa. Por exemplo, números de carros, inclusive em condições difíceis para algoritmos: em ângulos agudos, números sujos e difíceis de ler.

2. Casos de uso prático
2.1 Controle de acesso físico: quando dois passam no mesmo passe
Com a ajuda da Vision, é possível implementar sistemas de contabilidade para a chegada e saída de funcionários. Um sistema tradicional baseado em passes eletrônicos tem desvantagens óbvias, por exemplo, você pode passar por dois emblemas juntos. Se o sistema de controle de acesso (ACS) for complementado pelo Vision, ele registrará honestamente quem veio e foi quando.
2.2 Rastreamento de tempo
Esse caso de uso do Vision está intimamente relacionado ao anterior. Se complementarmos o sistema de controle de acesso com nosso serviço de reconhecimento de rosto, ele poderá não apenas observar violações do controle de acesso, mas também registrar a permanência real dos funcionários no edifício ou nas instalações. Em outras palavras, a Vision ajudará a considerar honestamente quem e quanto veio trabalhar e deixou com ela, e quem até pulou, mesmo que seus colegas o cobrissem na frente de seus superiores.
2.3 Análise de vídeo: rastreamento e segurança de pessoas
Ao rastrear pessoas que usam o Vision, você pode avaliar com precisão a perviedade real de áreas comerciais, estações de trem, cruzamentos, ruas e muitos outros locais públicos. Nosso rastreamento também pode ser de grande ajuda para controlar o acesso, por exemplo, a um armazém ou outras instalações importantes do escritório. E, é claro, rastrear pessoas e rostos ajuda a resolver problemas de segurança. Pegou alguém roubando da sua loja? Adicione-o ao PersonID, que retornou o Vision, na lista negra do seu software de análise de vídeo, e na próxima vez em que o sistema alertar imediatamente a segurança se esse tipo aparecer novamente.
2.4 No comércio
Varejo e várias empresas de serviços estão interessadas no reconhecimento de filas. Usando o Vision, você pode reconhecer que essa não é uma multidão aleatória de pessoas, mas uma fila e determinar sua duração. E então o sistema informa as pessoas responsáveis sobre a fila para entender a situação: esse é um fluxo de visitantes e é preciso chamar funcionários adicionais ou alguém está invadindo suas responsabilidades profissionais.
Outra tarefa interessante é a separação dos funcionários da empresa no salão e dos visitantes. Normalmente, o sistema aprende a separar objetos em certas roupas (código de vestimenta) ou com alguma característica distintiva (lenço de assinatura, crachá no peito etc.). Isso ajuda a avaliar com mais precisão a presença (para que os funcionários sozinhos não “encerrem” as estatísticas das pessoas no salão).
Usando o reconhecimento facial, você pode avaliar seu público-alvo: qual é a lealdade dos visitantes, ou seja, quantas pessoas retornam à sua instituição e com que frequência. Calcule quantos visitantes únicos chegam até você em um mês. Para otimizar os custos de atração e retenção, você pode descobrir e alterar a participação, dependendo do dia da semana e até da hora do dia.
Os franqueadores e as empresas de rede podem solicitar uma avaliação da qualidade da marca de vários pontos de venda a partir de fotografias: a presença de logotipos, letreiros, pôsteres, banners e assim por diante.
2.5 No transporte
Outro exemplo de segurança através da análise de vídeo é a identificação de itens deixados nos aeroportos ou nas estações de trem. A visão pode ser treinada para reconhecer objetos de centenas de classes: móveis, bolsas, malas, guarda-chuvas, vários tipos de roupas, garrafas e assim por diante. Se o seu sistema de análise de vídeo detectar um objeto sem dono e o reconhecer usando o Vision, ele enviará um sinal ao serviço de segurança. Uma tarefa semelhante está relacionada à detecção automática de situações fora do padrão em locais públicos: alguém ficou doente, alguém fumou no lugar errado, ou a pessoa caiu nos trilhos, e assim por diante - todos esses padrões do sistema de análise de vídeo podem reconhecer através da API Vision.
2.6 Workflow
Outra aplicação interessante do Vision que estamos desenvolvendo atualmente é o reconhecimento de documentos e sua análise automática em bancos de dados. Em vez de dirigir manualmente (ou pior ainda, entrar) séries, números, datas de emissão, números de contas, dados bancários, datas e locais de nascimento e muitos outros dados formalizados, você pode digitalizar documentos e enviá-los automaticamente por um canal seguro através da API na nuvem, onde o sistema estará em movimento, esses documentos serão reconhecidos, analisados e retornarão uma resposta com os dados no formato desejado para entrada automática no banco de dados. Hoje, a Vision já sabe como classificar documentos (inclusive em PDF) - distingue passaportes, SNILS, TIN, certidões de nascimento, certidões de casamento e outros.
Obviamente, em todas essas situações a rede neural não é capaz de lidar imediatamente. Em cada caso, um novo modelo é criado para um cliente específico, muitos fatores, nuances e requisitos são levados em consideração, conjuntos de dados são selecionados, configurações de teste de treinamento são iteradas.
3. Esquema de trabalho da API
O "portão de entrada" do Vision para os usuários é a API REST. Na entrada, ele pode tirar fotos, arquivos de vídeo e transmissões de câmeras de rede (fluxos RTSP).
Para usar o Vision, você precisa se
registrar no Mail.ru Cloud Solutions e obter tokens de acesso (client_id + client_secret). A autenticação do usuário é realizada usando o protocolo OAuth. Os dados de origem nos corpos das solicitações POST são enviados para a API. E, em resposta, o cliente recebe o resultado do reconhecimento da API no formato JSON, e a resposta é estruturada: contém informações sobre os objetos encontrados e suas coordenadas.

Exemplo de resposta{ "status":200, "body":{ "objects":[ { "status":0, "name":"file_0" }, { "status":0, "name":"file_2", "persons":[ { "tag":"person9" "coord":[149,60,234,181], "confidence":0.9999, "awesomeness":0.45 }, { "tag":"person10" "coord":[159,70,224,171], "confidence":0.9998, "awesomeness":0.32 } ] } { "status":0, "name":"file_3", "persons":[ { "tag":"person11", "coord":[157,60,232,111], "aliases":["person12", "person13"] "confidence":0.9998, "awesomeness":0.32 } ] }, { "status":0, "name":"file_4", "persons":[ { "tag":"undefined" "coord":[147,50,222,121], "confidence":0.9997, "awesomeness":0.26 } ] } ], "aliases_changed":false }, "htmlencoded":false, "last_modified":0 }
A resposta tem um parâmetro interessante de grandiosidade - essa é a “frieza” condicional do rosto na foto, com ele selecionamos a melhor foto de rosto da sequência. Nós treinamos a rede neural para prever a probabilidade de que a imagem seja como nas redes sociais. Quanto melhor a imagem e mais suave o rosto, maior a grandiosidade.
A API Vision usa um conceito como espaço. Esta é uma ferramenta para criar diferentes conjuntos de faces. Exemplos de espaços são listas em preto e branco, listas de visitantes, funcionários, clientes etc. Para cada token no Vision, você pode criar até 10 espaços, em cada espaço pode haver até 50 mil PersonID, ou seja, até 500 mil para um token . Além disso, o número de tokens por conta não é limitado.
Hoje, a API suporta os seguintes métodos de detecção e reconhecimento:
- Reconhecer / Definir - definição e reconhecimento de rostos. Atribui automaticamente um PersonID a cada face exclusiva, retorna o PersonID e as coordenadas das faces encontradas.
- Excluir - exclua um PersonID específico do banco de dados de pessoas.
- Truncar - limpa todo o espaço do PersonID, útil se tiver sido usado como teste e você precisar redefinir a base para produção.
- Detectar - definição de objetos, cenas, matrículas, atrações, filas, etc. Retorna a classe de objetos encontrados e suas coordenadas
- Detectar documentos - detecta tipos específicos de documentos da Federação Russa (distingue passaporte, snls, pousada etc.).
Além disso, em breve concluiremos o trabalho nos métodos de OCR, determinando sexo, idade e emoções, além de resolver tarefas de merchandising, ou seja, controlar automaticamente a exibição de mercadorias nas lojas. Você pode encontrar a documentação completa da API aqui:
https://mcs.mail.ru/help/vision-api4. Conclusão
Agora, através da API pública, você pode acessar o reconhecimento facial em fotos e vídeos, ele suporta a definição de vários objetos, números de carros, atrações, documentos e cenas inteiras. Cenários de aplicação - Mar. Venha, teste nosso serviço, defina as tarefas mais complicadas para ele. As primeiras 5.000 transações são gratuitas. Pode ser o "ingrediente que falta" para seus projetos.
O acesso à API pode ser obtido instantaneamente ao se registrar e conectar-se ao
Vision . Todos os usuários do Habra - um código promocional para transações adicionais. Escreva em um endereço de e-mail pessoal no qual a conta foi registrada!