Olá. Meu nome é Ibadov Ilkin, sou estudante da Universidade Federal de Ural.
Neste artigo, quero falar sobre minha experiência com a solução automatizada para o captcha do Google - "reCAPTCHA". Gostaria de avisar o leitor antecipadamente que, no momento da redação do artigo, o protótipo não funciona da maneira mais eficiente possível do título; no entanto, o resultado demonstra que a abordagem implementada é capaz de resolver o problema.
Provavelmente, todos em sua vida se depararam com um captcha: digite texto de uma imagem, resolva uma expressão simples ou uma equação complicada, escolha carros, hidrantes, travessias de pedestres ... É necessário proteger recursos de sistemas automatizados e desempenha um papel importante na segurança: o captcha protege contra ataques DDoS , registros e lançamentos automáticos, analisando, evitam a seleção de spam e senha para contas.
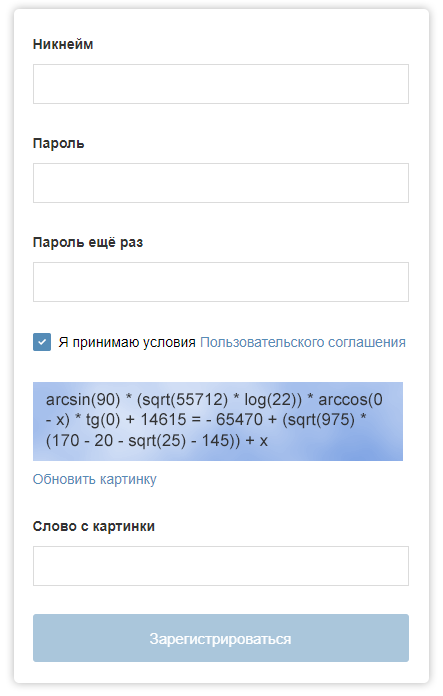 O formulário de inscrição no "Habré" pode ser com esse captcha.
O formulário de inscrição no "Habré" pode ser com esse captcha.Com o desenvolvimento de tecnologias de aprendizado de máquina, o desempenho do captcha pode estar em risco. Neste artigo, descrevo os principais pontos de um programa que podem resolver o problema de selecionar manualmente imagens no Google reCAPTCHA (felizmente, nem sempre até o momento).
Para passar pelo captcha, é necessário resolver problemas como: determinação da classe captcha necessária, detecção e classificação de objetos, detecção de células captcha, simulação de atividades humanas na resolução de captcha (movimento do cursor, clique).
Para procurar objetos em uma imagem, são usadas redes neurais treinadas que podem ser baixadas em um computador e reconhecem objetos em imagens ou vídeos. Mas para resolver o captcha, apenas detectar objetos não é suficiente: você precisa determinar a posição das células e descobrir quais células deseja selecionar (ou não selecionar as células). Para isso, são utilizadas ferramentas de visão computacional: neste trabalho, esta é a famosa
biblioteca OpenCV .
Para encontrar objetos na imagem, primeiro é necessário a própria imagem. Recebo uma captura de tela de uma parte da tela usando o módulo
PyAutoGUI com dimensões suficientes para detectar objetos. No restante da tela, mostro janelas para depuração e monitoramento de processos de programas.
Detecção de Objetos
Detecção e classificação de objetos é o que a rede neural faz. A biblioteca que nos permite trabalhar com redes neurais é chamada "
Tensorflow " (desenvolvido pelo Google). Hoje,
existem muitos modelos treinados diferentes para sua escolha
em dados diferentes , o que significa que todos eles podem retornar um resultado de detecção diferente: alguns modelos detectam melhor objetos e outros piores.
Neste artigo, estou usando o modelo ssd_mobilenet_v1_coco. O modelo selecionado foi treinado no conjunto de dados
COCO , que destaca 90 classes diferentes (de pessoas e carros a escovas de dentes e pentes). Agora, existem outros modelos treinados nos mesmos dados, mas com parâmetros diferentes. Além disso, este modelo possui parâmetros ideais de desempenho e precisão, o que é importante para um computador de mesa. A fonte diz que o tempo de processamento para um quadro de 300 x 300 pixels é de 30 milissegundos. No "Nvidia GeForce GTX TITAN X".
O resultado da rede neural é um conjunto de matrizes:
- com uma lista de classes de objetos detectados (seus identificadores);
- com uma lista de classificações de objetos detectados (em porcentagem);
- com uma lista de coordenadas dos objetos detectados ("caixas").
Os índices dos elementos nessas matrizes correspondem um ao outro, ou seja: o terceiro elemento na matriz de classes de objetos corresponde ao terceiro elemento na matriz de "caixas" dos objetos detectados e o terceiro elemento na matriz de classificações de objetos.
 O modelo selecionado permite detectar objetos de 90 classes em tempo real.
O modelo selecionado permite detectar objetos de 90 classes em tempo real.Detecção de células
O “OpenCV” nos oferece a capacidade de operar com entidades chamadas “
circuitos ”: elas podem ser detectadas apenas pela função “findContours ()” da biblioteca “OpenCV”. É necessário enviar uma imagem binária para a entrada dessa função, que pode ser obtida
pela função de transformação de limite :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
Depois de definir os valores extremos dos parâmetros da função de transformação de limiar, também nos livramos de vários tipos de ruído. Além disso, para minimizar a quantidade de pequenos elementos e ruídos desnecessários,
transformações morfológicas podem ser aplicadas: funções de erosão (compressão) e acumulação (expansão). Essas funções também fazem parte do OpenCV. Após as transformações, são selecionados os contornos cujo número de vértices é quatro (tendo realizado anteriormente a função de
aproximação nos contornos).
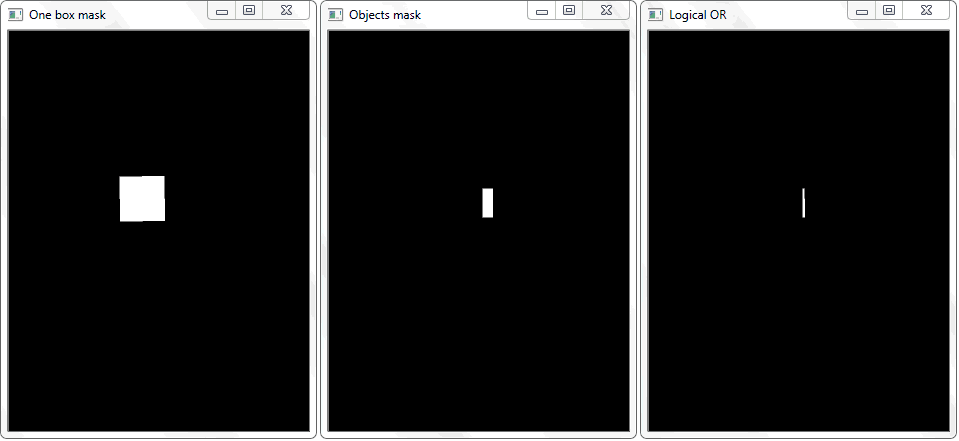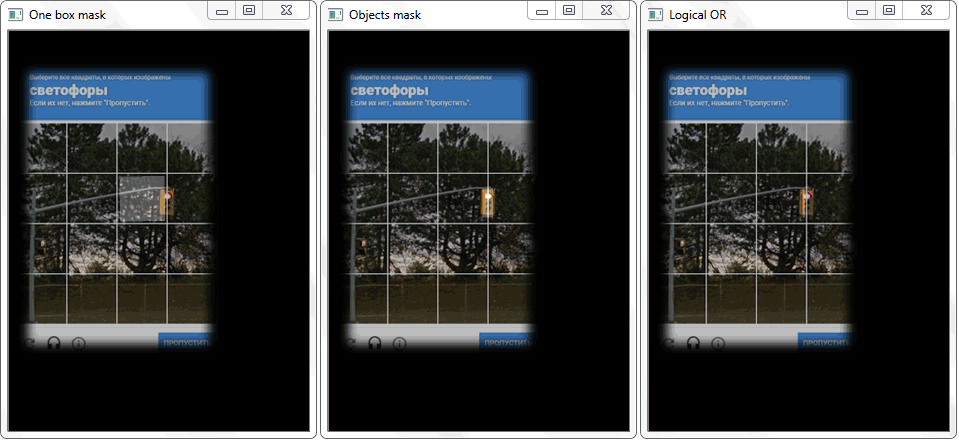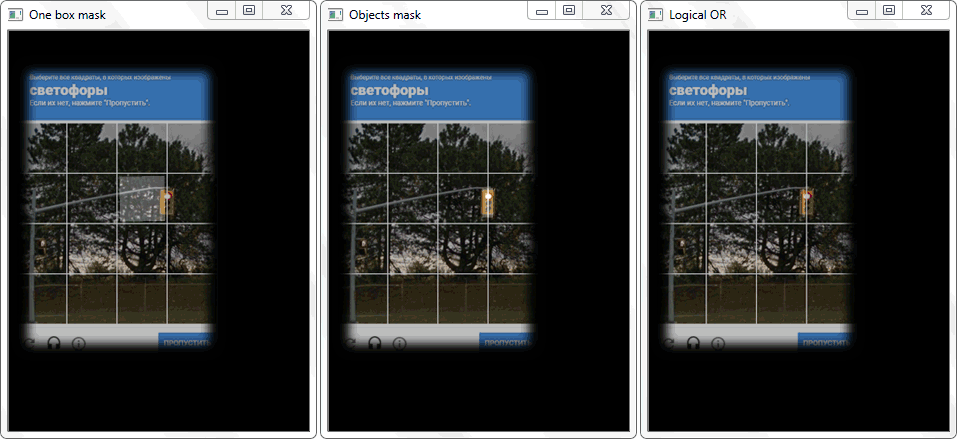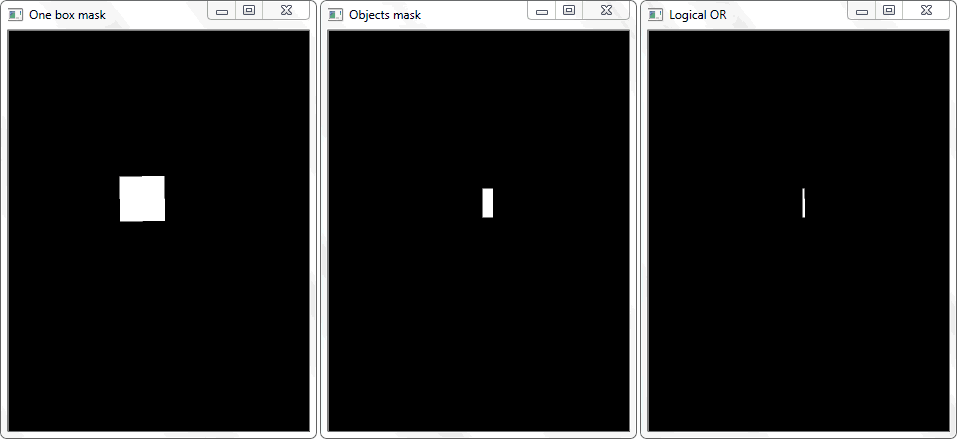
 Na primeira janela, o resultado da transformação do limite. O segundo é um exemplo de transformação morfológica. Na terceira janela, as células e a tampa do captcha já estão selecionadas: destacadas em cores programaticamente.
Na primeira janela, o resultado da transformação do limite. O segundo é um exemplo de transformação morfológica. Na terceira janela, as células e a tampa do captcha já estão selecionadas: destacadas em cores programaticamente.Depois de todas as transformações, os contornos que não são células ainda caem na matriz final com células. Para filtrar ruídos desnecessários, seleciono de acordo com os valores do comprimento (perímetro) e da área dos contornos.
Foi experimentalmente revelado que os valores dos circuitos de interesse estão na faixa de 360 a 900 unidades. Este valor é selecionado na tela com uma diagonal de 15,6 polegadas e uma resolução de 1366 x 768 pixels. Além disso, os valores indicados dos contornos podem ser calculados dependendo do tamanho da tela do usuário, mas não existe esse link no protótipo que está sendo criado.
A principal vantagem da abordagem escolhida para detectar células é que não nos importamos com a aparência da grade e quantas células serão exibidas na página captcha: 8, 9 ou 16.
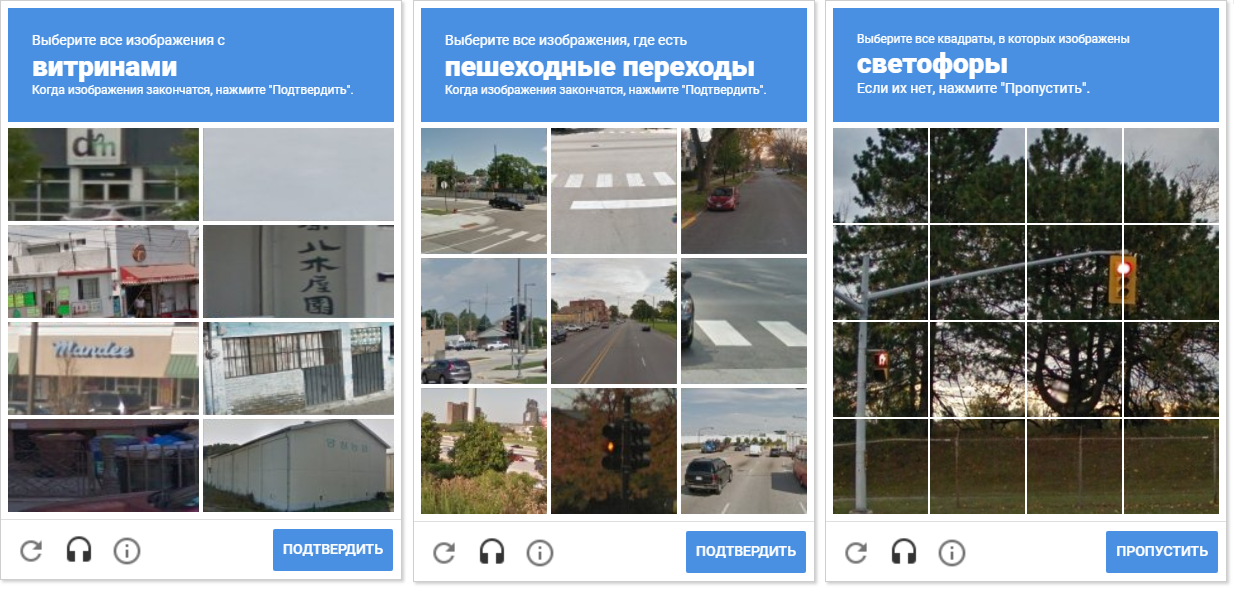 A imagem mostra uma variedade de redes captcha. Observe que a distância entre as células é diferente. Separar as células umas das outras permite compressão morfológica.
A imagem mostra uma variedade de redes captcha. Observe que a distância entre as células é diferente. Separar as células umas das outras permite compressão morfológica.Uma vantagem adicional de detectar contornos é que o OpenCV nos permite detectar seus centros (precisamos deles para determinar as coordenadas de movimento e o clique do mouse).
Selecionando células para selecionar
Tendo uma matriz com contornos limpos de células CAPTCHA sem circuitos de ruído desnecessários, podemos percorrer cada célula CAPTCHA ("circuito" na terminologia "OpenCV") e verificar se ele se cruza com a "caixa" detectada do objeto recebido da rede neural.
Para estabelecer esse fato, foi utilizada a transferência da “caixa” detectada para um circuito semelhante às células. Mas essa abordagem acabou errada, porque o caso em que o objeto está localizado dentro da célula não é considerado um cruzamento. Naturalmente, essas células não se destacaram no captcha.
O problema foi resolvido redesenhando o contorno de cada célula (com preenchimento branco) em uma folha preta. De maneira semelhante, foi obtida uma imagem binária de um quadro com um objeto. Surge a questão - como agora estabelecer o fato da interseção da célula com a estrutura sombreada do objeto? Em cada iteração de uma matriz com células, uma operação de disjunção (lógica ou) é realizada em duas imagens binárias. Como resultado, obtemos uma nova imagem binária na qual as áreas cruzadas serão destacadas. Ou seja, se houver essas áreas, a célula e a estrutura do objeto se cruzam. Programaticamente, essa verificação pode ser feita usando o método “
.any () ”: retornará “True” se a matriz tiver pelo menos um elemento igual a um ou “False” se não houver unidades.
 A função "any ()" para a imagem "OR lógica" nesse caso retornará true e, assim, estabelecerá o fato da interseção da célula com a área do quadro do objeto detectado.
A função "any ()" para a imagem "OR lógica" nesse caso retornará true e, assim, estabelecerá o fato da interseção da célula com a área do quadro do objeto detectado.Gerência
O controle do cursor no “Python” fica disponível graças ao módulo “win32api” (no entanto, mais tarde, verificou-se que o “PyAutoGUI” já importado para o projeto também sabe como fazer isso). Pressionar e soltar o botão esquerdo do mouse, bem como mover o cursor para as coordenadas desejadas, é realizado pelas funções correspondentes do módulo win32api. Porém, no protótipo, eles foram agrupados em funções definidas pelo usuário para fornecer observação visual do movimento do cursor. Isso afeta negativamente o desempenho e foi implementado apenas para demonstração.
Durante o processo de desenvolvimento, surgiu a ideia de escolher células em uma ordem aleatória. É possível que isso não faça sentido prático (por razões óbvias, o Google não nos fornece comentários e descrições dos mecanismos da operação captcha), mas mover o cursor pelas células de uma maneira caótica parece mais divertido.
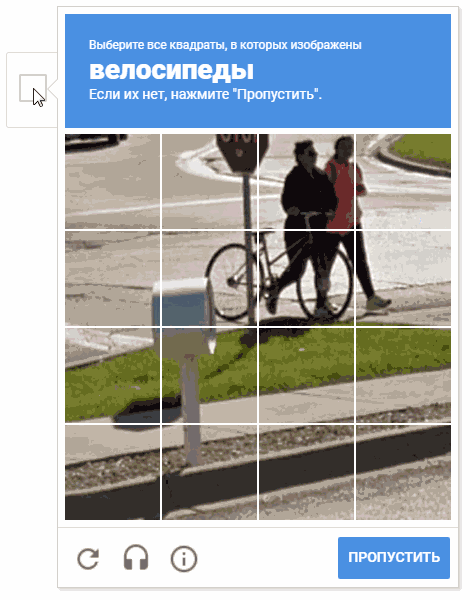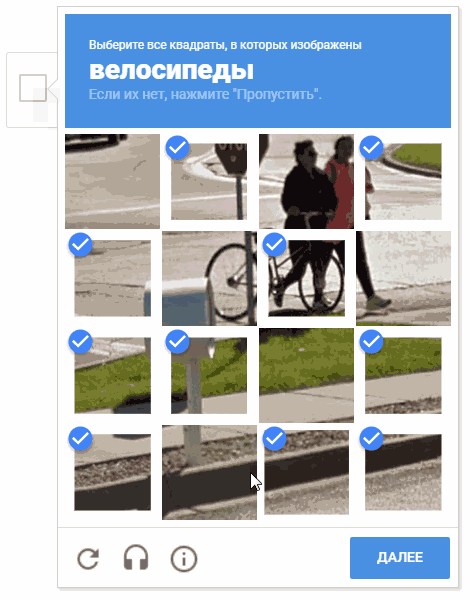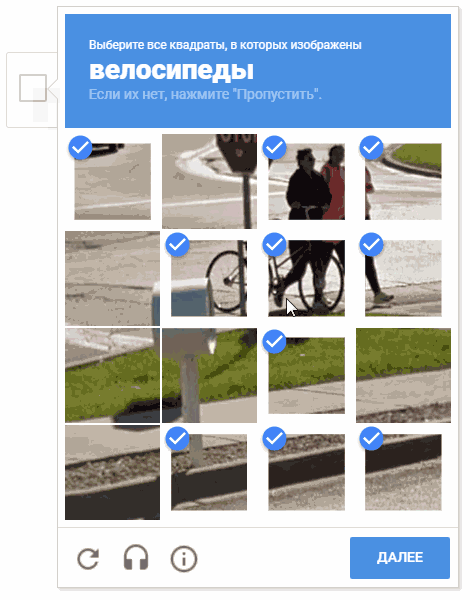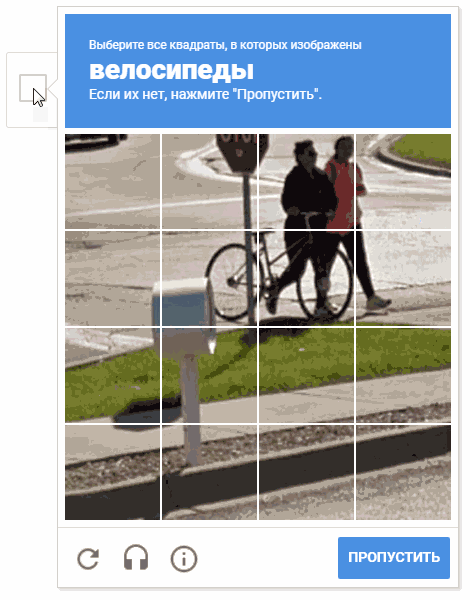 Na animação, o resultado é "random.shuffle (boxesForSelect)".
Na animação, o resultado é "random.shuffle (boxesForSelect)".Reconhecimento de texto
Para combinar todos os desenvolvimentos disponíveis em um único todo, é necessário mais um link: uma unidade de reconhecimento para a classe exigida no captcha. Já sabemos como reconhecer e distinguir objetos diferentes na imagem, podemos clicar em células captcha arbitrárias, mas não sabemos em quais células clicar. Uma das maneiras de resolver esse problema é reconhecer o texto do cabeçalho captcha. Primeiro, tentei implementar o reconhecimento de texto usando a ferramenta de reconhecimento óptico de caracteres "
Tesseract-OCR ".
Nas versões mais recentes, é possível instalar pacotes de idiomas diretamente na janela do instalador (anteriormente isso era feito manualmente). Após instalar e importar o Tesseract-OCR no meu projeto, tentei reconhecer o texto do cabeçalho captcha.
O resultado, infelizmente, não me impressionou. Decidi que o texto no cabeçalho era destacado em negrito e mesclado por um motivo, então tentei aplicar várias transformações à imagem: operações de binarização, estreitamento, expansão, desfoque, distorção e redimensionamento. Infelizmente, isso não deu um bom resultado: nos melhores casos, apenas uma parte das cartas da classe foi determinada e, quando o resultado foi satisfatório, apliquei as mesmas transformações, mas para outras letras maiúsculas (com texto diferente), e o resultado acabou sendo ruim novamente.
 O reconhecimento dos limites de Tesseract-OCR geralmente leva a resultados insatisfatórios.
O reconhecimento dos limites de Tesseract-OCR geralmente leva a resultados insatisfatórios.É impossível dizer inequivocamente que o “Tesseract-OCR” não reconhece bem o texto, não é assim: a ferramenta lida com outras imagens (sem captcha caps) muito melhor.
Decidi usar um serviço de terceiros que oferecia uma API para trabalhar com ele de graça (é necessário registrar e receber uma chave para um endereço de email). O serviço tem um limite de 500 reconhecimentos por dia, mas durante todo o período de desenvolvimento não encontrei nenhum problema com limitações. Pelo contrário: enviei a imagem original do cabeçalho para o serviço (sem aplicar absolutamente nenhuma transformação) e o resultado me impressionou agradavelmente.
As palavras do serviço foram retornadas praticamente sem erros (geralmente mesmo as escritas em letras pequenas). Além disso, eles retornaram em um formato muito conveniente - interrompido pela linha com caracteres de quebra de linha. Em todas as imagens, eu estava interessado apenas na segunda linha, então eu a acessei diretamente. Isso não podia deixar de se alegrar, pois esse formato me libertou da necessidade de preparar uma linha: não precisei cortar o começo ou o fim de todo o texto, fazer “recortes”, substituições, trabalhar com expressões regulares e realizar outras operações na linha, com o objetivo de destacar uma palavra (e às vezes duas!) - um bom bônus!
text = serviceResponse['ParsedResults'][0]['ParsedText']
Um serviço que reconheceu o texto quase nunca cometeu um erro com o nome da classe, mas ainda assim decidi deixar parte do nome da classe para um possível erro. Isso é opcional, mas notei que “Tesseract-OCR” em alguns casos reconheceu incorretamente o final de uma palavra começando do meio. Além disso, essa abordagem elimina o erro de aplicativo no caso de um nome de classe longo ou de duas palavras (nesse caso, o serviço retornará não 3, mas 4 linhas, e não consigo encontrar o nome completo da classe na segunda linha).
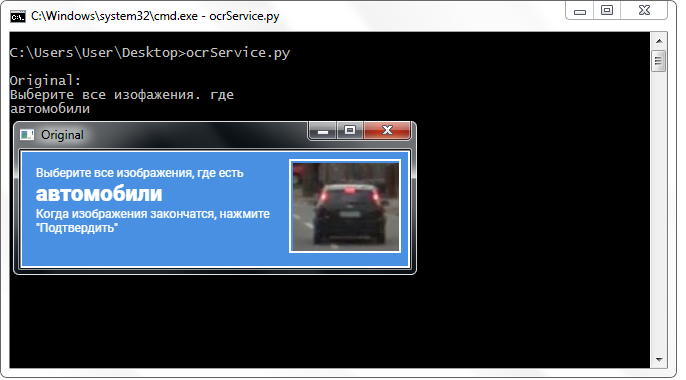 Um serviço de terceiros reconhece bem o nome da classe sem nenhuma transformação na imagem.
Um serviço de terceiros reconhece bem o nome da classe sem nenhuma transformação na imagem.Fusão
Obter texto do cabeçalho não é suficiente. Ele precisa ser comparado com os identificadores das classes de modelo disponíveis, porque na matriz de classes a rede neural retorna exatamente o identificador de classe, e não o nome, como pode parecer. Ao treinar o modelo, como regra geral, é criado um arquivo no qual os nomes de classe e seus identificadores são comparados (também conhecido como "mapa de etiquetas"). Decidi facilitar e especificar manualmente os identificadores de classe, já que o captcha ainda exige aulas em russo (a propósito, isso pode ser alterado):
if "" in query:
Tudo o que foi descrito acima é reproduzido no ciclo principal do programa: os quadros do objeto, a célula, suas interseções são determinados, o cursor se move e clica. Quando um cabeçalho é detectado, o reconhecimento de texto é realizado. Se a rede neural não puder detectar a classe necessária, um deslocamento arbitrário da imagem será realizado até 5 vezes (ou seja, a entrada da rede neural será alterada) e, se a detecção ainda não ocorrer, o botão "Ignorar / Confirmar" é clicado (sua posição é detectada da mesma forma detectar células e tampas).
Se você costuma resolver o captcha, poderá observar a imagem quando a célula selecionada desaparecer e uma nova aparecer lenta e lentamente em seu lugar. Como o protótipo está programado para ir instantaneamente para a página seguinte após selecionar todas as células, decidi fazer 3 segundos para excluir o clique no botão "Avançar" sem detectar objetos na célula que aparecia lentamente.
O artigo não estaria completo se não contivesse uma descrição da coisa mais importante - uma marca de seleção para passar com êxito o captcha. Decidi que uma simples
comparação de modelos poderia fazer isso. Vale ressaltar que a correspondência de padrões está longe de ser a melhor maneira de detectar objetos. Por exemplo, eu tive que definir a sensibilidade de detecção como "0,01" para que a função parasse de ver tiques em tudo, mas vi quando realmente existe um tiquetaque. Da mesma forma, atuei com uma caixa de seleção vazia que atende ao usuário e a partir da qual o captcha inicia (não houve problemas com a sensibilidade).
Resultado
O resultado de todas as ações descritas foi uma aplicação, cujo desempenho eu testei na "
Torradeira ":
Vale a pena reconhecer que o vídeo não foi gravado na primeira tentativa, pois muitas vezes eu me deparava com a necessidade de escolher classes que não estão no modelo (por exemplo, travessias de pedestres, escadas ou vitrines).
O "Google reCAPTCHA" retorna um determinado valor ao site, mostrando como "Você é um robô", e os administradores do site, por sua vez, podem definir um limite para a transmissão desse valor. É possível que um limite de captcha relativamente baixo tenha sido definido no Toaster. Isso explica a passagem bastante fácil do captcha pelo programa, apesar de ter sido enganado duas vezes, sem ver o semáforo da primeira página e o hidrante da quarta página do captcha.
Além da Torradeira, foram realizadas experiências na
página de demonstração oficial do
reCAPTCHA . Como resultado, percebeu-se que, após várias detecções errôneas (e não detecções), obter um captcha se torna extremamente difícil, mesmo para uma pessoa: são necessárias novas classes (como tratores e palmeiras), células sem objetos aparecem nas amostras (cores quase monótonas) e o número de páginas aumenta dramaticamente. para passar.
Isso foi especialmente notável quando decidi tentar clicar em células aleatórias em caso de não detecção de objetos (devido à sua ausência no modelo). Portanto, podemos dizer com certeza que cliques aleatórios não levarão a uma solução para o problema. Para se livrar desse "bloqueio" do examinador, reconectamos a conexão à Internet e limpamos os dados do navegador, porque ficou impossível passar em um teste - era quase infinito!
 Se você duvida de sua humanidade, esse resultado é possível.
Se você duvida de sua humanidade, esse resultado é possível.Desenvolvimento
Se o artigo e o aplicativo despertarem interesse do leitor, terei prazer em continuar sua implementação, testes e a descrição adicional de uma forma mais detalhada.
Trata-se de encontrar classes que não fazem parte da rede atual, isso melhorará bastante a eficiência do aplicativo. No momento, há uma necessidade urgente de reconhecer pelo menos classes como: passagens para pedestres, vitrines e chaminés - eu vou lhe dizer como treinar novamente o modelo. Durante o desenvolvimento, fiz uma pequena lista das classes mais comuns:
- travessias de pedestres;
- hidrantes;
- montras
- chaminés;
- carros;
- Ônibus
- semáforos;
- bicicletas
- meios de transporte;
- escadas
- sinais.
É possível melhorar a qualidade da detecção de objetos usando vários modelos ao mesmo tempo: isso pode prejudicar o desempenho, mas aumentar a precisão.
Outra maneira de melhorar a qualidade da detecção de objetos é alterar a entrada de imagem para a rede neural: no vídeo, você pode ver que, quando os objetos não são detectados, faço uma troca arbitrária de imagens várias vezes (com 10 pixels na horizontal e na vertical), e muitas vezes essa operação permite ver objetos que eram anteriormente não foram detectados.
Um aumento na imagem de um quadrado pequeno para um quadrado grande (até 300 x 300 pixels) também leva à detecção de objetos não detectados.
 Nenhum objeto foi encontrado à esquerda: quadrado original com 100 pixels de lado. À direita, um barramento é detectado: um quadrado ampliado até 300 x 300 pixels.
Nenhum objeto foi encontrado à esquerda: quadrado original com 100 pixels de lado. À direita, um barramento é detectado: um quadrado ampliado até 300 x 300 pixels.Outra transformação interessante é a remoção da grade branca sobre a imagem usando as ferramentas OpenCV: é possível que o hidrante não tenha sido detectado no vídeo por esse motivo (essa classe está presente na rede neural).
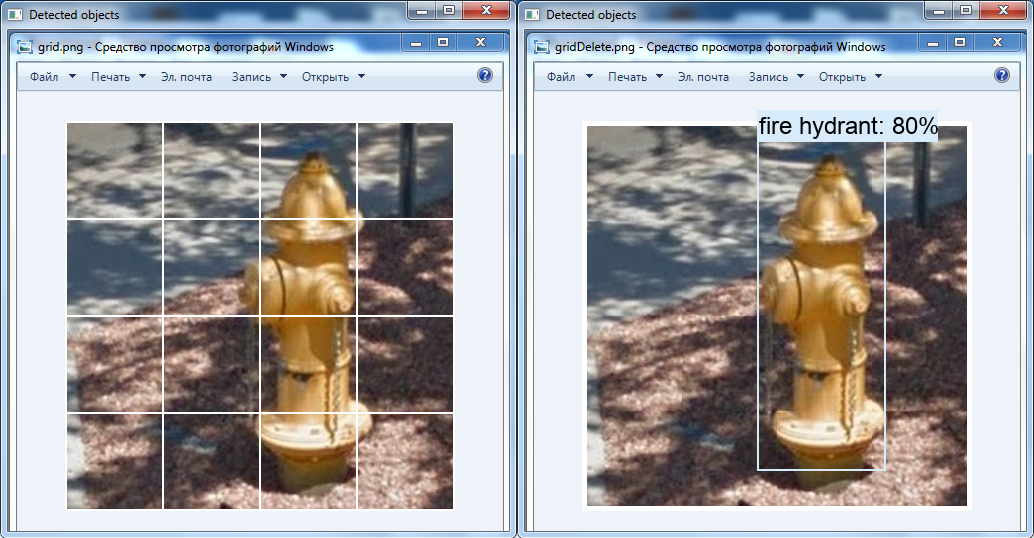 À esquerda, a imagem original, e à direita, a imagem que foi alterada no editor de gráficos: a grade é excluída, as células são movidas uma para a outra.
À esquerda, a imagem original, e à direita, a imagem que foi alterada no editor de gráficos: a grade é excluída, as células são movidas uma para a outra.Sumário
Com este artigo, eu queria dizer que o captcha provavelmente não é a melhor proteção contra bots, e é bem possível que, em um futuro próximo, haja necessidade de novos meios de proteção contra sistemas automatizados.
O protótipo desenvolvido, mesmo estando em estado incompleto, demonstra que, com as classes necessárias no modelo de rede neural e aplicando transformações sobre imagens, é possível obter a automação de um processo que não deve ser automatizado.
Além disso, gostaria de chamar a atenção do Google para o fato de que, além do método para contornar o captcha descrito neste artigo, também há
outra maneira pela qual uma amostra de áudio é
transcrita . Na minha opinião, agora é necessário tomar medidas relacionadas à melhoria da qualidade de produtos e algoritmos de software contra robôs.
Pelo conteúdo e pela essência do material, pode parecer que eu não gosto do Google e, em particular, do reCAPTCHA, mas isso está longe de ser o caso e, se houver uma próxima implementação, vou lhe dizer por quê.
Desenvolvido e demonstrado com o objetivo de melhorar a educação e melhorar os métodos destinados a garantir a segurança da informação
Obrigado pela atenção.