A história do VKontakte está na Wikipedia, foi contada pelo próprio Pavel. Parece que todo mundo já a conhece. Pavel
falou sobre o interior, a arquitetura e o design do site no HighLoad ++
em 2010 . Muitos servidores vazaram desde então; portanto, atualizaremos as informações: dissecamos, extraímos o interior, pesamos - examinamos o dispositivo VK de um ponto de vista técnico.
 Alexey Akulovich
Alexey Akulovich (
AterCattus ) é desenvolvedor de back-end da equipe VKontakte. A transcrição deste relatório é uma resposta coletiva a perguntas freqüentes sobre o funcionamento da plataforma, infraestrutura, servidores e a interação entre eles, mas não sobre desenvolvimento, principalmente
sobre hardware . Separadamente - sobre bancos de dados e o que a VK possui em seu lugar, sobre a coleta de logs e o monitoramento de todo o projeto como um todo. Detalhes sob o corte.
Por mais de quatro anos, venho realizando todos os tipos de tarefas relacionadas ao back-end.
- Download, armazenamento, processamento, distribuição de mídia: vídeo, transmissão ao vivo, áudio, fotos, documentos.
- Infraestrutura, plataforma, monitoramento de desenvolvedor, logs, caches regionais, CDN, protocolo RPC proprietário.
- Integração com serviços externos: envio por correio, análise de links externos, feed RSS.
- Ajude os colegas em várias questões, para obter as respostas nas quais você precisa mergulhar em um código desconhecido.
Durante esse período, participei de muitos componentes do site. Eu quero compartilhar essa experiência.
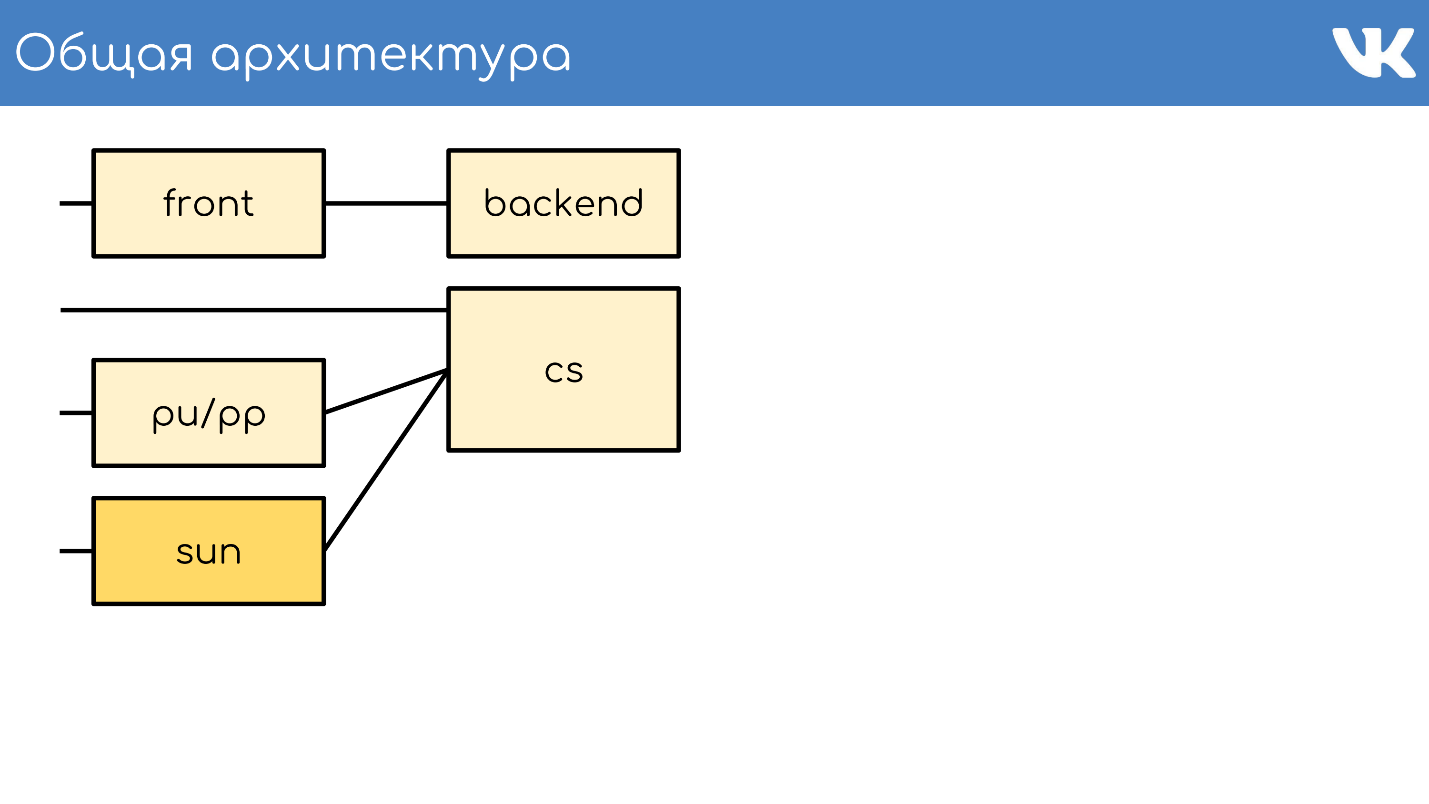
Arquitetura geral
Tudo, como sempre, começa com um servidor ou um grupo de servidores que aceitam solicitações.
Servidor frontal
O servidor frontal aceita solicitações por HTTPS, RTMP e WSS.
HTTPS são solicitações para as versões web principal e móvel do site: vk.com e m.vk.com e outros clientes oficiais e não oficiais da nossa API: clientes móveis, mensageiros instantâneos. Temos uma recepção de tráfego
RTMP para transmissões ao vivo com servidores frontais separados e conexões
WSS para a API de Streaming.
Para HTTPS e WSS, o
nginx é instalado nos servidores. Para transmissões RTMP, recentemente mudamos para nossa própria solução
kive , mas ela está além do escopo do relatório. Para tolerância a falhas, esses servidores anunciam endereços IP comuns e agem como grupos para que, no caso de um problema em um dos servidores, as solicitações do usuário não sejam perdidas. Para HTTPS e WSS, esses mesmos servidores criptografam o tráfego para fazer parte da carga da CPU.
Além disso, não falaremos sobre WSS e RTMP, mas apenas sobre solicitações HTTPS padrão, que geralmente são associadas a um projeto da web.
Backend
Atrás da frente, geralmente estão os servidores back-end. Eles lidam com solicitações que o servidor frontal recebe dos clientes.
Esses são
servidores kPHP executando o daemon HTTP porque o HTTPS já está descriptografado. O kPHP é um servidor que funciona de acordo com o
modelo prefork : inicia o processo mestre, vários processos filhos, passa soquetes de escuta para eles e eles processam seus pedidos. Ao mesmo tempo, os processos não são reiniciados entre cada solicitação do usuário, mas simplesmente redefinem seu estado para o estado inicial de valor zero - solicitação por solicitação, em vez de reiniciar.
Compartilhamento de carga
Todos os nossos back-end não são um grande conjunto de máquinas que podem lidar com qualquer solicitação. Nós os
dividimos em grupos separados : geral, móvel, API, vídeo, teste ... O problema em um grupo separado de máquinas não afetará todos os outros. Em caso de problemas com o vídeo, o usuário que está ouvindo música nem conhece os problemas. Qual backend para o qual enviar a solicitação é resolvido pelo nginx na frente da configuração.
Coleta e reequilíbrio de métricas
Para entender quantos carros você precisa em cada grupo,
não confiamos no QPS . Os back-end são diferentes, eles têm solicitações diferentes, cada solicitação tem uma complexidade de cálculo QPS diferente. Portanto, usamos o
conceito de carga no servidor como um todo - na CPU e no perf .
Temos milhares desses servidores. O grupo kPHP está sendo executado em cada servidor físico para utilizar todos os kernels (porque o kPHP é de thread único).
Servidor de conteúdo
O CS ou o Content Server é armazenamento . O CS é um servidor que armazena arquivos e também processa arquivos enviados, todos os tipos de tarefas em segundo plano síncronas que o principal front-end da Web representa para ele.
Temos dezenas de milhares de servidores físicos que armazenam arquivos. Os usuários adoram fazer upload de arquivos, e nós gostamos de armazenar e compartilhá-los. Alguns desses servidores são fechados por servidores pu / pp especiais.
pu / pp
Se você abriu a guia de rede no VK, viu pu / pp.

O que é pu / pp? Se fecharmos um servidor após o outro, há duas opções para carregar e baixar um arquivo em um servidor que foi fechado:
diretamente por meio de
http://cs100500.userapi.com/path ou
por um servidor intermediário -
http://pu.vk.com/c100500/path .
Pu é o nome histórico para upload de fotos e pp é proxy de fotos . Ou seja, um servidor para enviar fotos e outro - para dar. Agora, não apenas as fotos são carregadas, mas o nome foi preservado.
Esses servidores
encerram as sessões HTTPS para remover a carga do processador do armazenamento. Além disso, como os arquivos do usuário são processados nesses servidores, as informações menos confidenciais são armazenadas nessas máquinas, melhor. Por exemplo, chaves de criptografia HTTPS.
Como as máquinas são fechadas por outras máquinas, podemos dar ao luxo de não lhes dar IPs externos “brancos” e de IPs
“cinzas” . Assim, economizamos no pool de IP e garantimos a proteção das máquinas contra o acesso externo - simplesmente não há IP para acessá-lo.
Tolerância a falhas através de IP compartilhado . Em termos de tolerância a falhas, o esquema funciona da mesma maneira - vários servidores físicos têm um IP físico comum, e o pedaço de ferro à sua frente escolhe para onde enviar a solicitação. Mais tarde vou falar sobre outras opções.
O ponto controverso é que, nesse caso, o
cliente mantém menos conexões . Se houver o mesmo IP em várias máquinas - com o mesmo host: pu.vk.com ou pp.vk.com, o navegador do cliente terá um limite no número de solicitações simultâneas para um host. Mas durante o onipresente HTTP / 2, acredito que esse não seja mais o caso.
O menos óbvio do esquema é que você precisa
bombear todo o tráfego que vai para o armazenamento por outro servidor. Como bombeamos o tráfego pelos carros, ainda não podemos bombear o tráfego pesado da mesma maneira, por exemplo, vídeo. Transferimos diretamente - uma conexão direta separada para repositórios individuais especificamente para vídeo. Nós transmitimos conteúdo mais leve através de um proxy.
Não faz muito tempo, temos uma versão aprimorada do proxy. Agora vou dizer como eles diferem dos comuns e por que isso é necessário.
Sol
Em setembro de 2017, a Oracle, que havia comprado a Sun,
demitiu um grande número de funcionários da Sun. Podemos dizer que, neste momento, a empresa deixou de existir. Escolhendo um nome para o novo sistema, nossos administradores decidiram prestar homenagem e respeito a essa empresa e nomearam o novo sistema Sun. Entre nós, chamamos simplesmente de "luz do sol".
Pp teve alguns problemas.
Um IP por grupo é um cache ineficiente . Vários servidores físicos têm um endereço IP comum e não há como controlar em qual servidor a solicitação chegará. Portanto, se diferentes usuários buscarem o mesmo arquivo, se houver um cache nesses servidores, o arquivo será instalado no cache de cada servidor. Este é um esquema muito ineficiente, mas nada pode ser feito.
Como resultado,
não podemos compartilhar conteúdo , porque não podemos selecionar um servidor específico para este grupo - eles têm um IP comum. Além disso, por alguns motivos internos,
não tivemos a oportunidade de colocar esses servidores nas regiões . Eles ficaram apenas em São Petersburgo.
Com os sóis, mudamos o sistema de seleção. Agora temos o
roteamento anycast :
roteamento dinâmico, anycast, daemon de autoverificação. Cada servidor tem seu próprio IP individual, mas ao mesmo tempo uma sub-rede comum. Tudo é configurado de tal maneira que, no caso de perda de um servidor, o tráfego é espalhado automaticamente para outros servidores do mesmo grupo. Agora é possível selecionar um servidor específico,
não há armazenamento em cache excessivo e a confiabilidade não é afetada.
Suporte de peso . Agora, podemos dar ao luxo de colocar carros de diferentes capacidades, conforme necessário, e também em caso de problemas temporários, alterar os pesos dos “sóis” que trabalham para reduzir a carga sobre eles, para que “descansem” e trabalhem novamente.
Fragmento por ID do conteúdo . O engraçado do sharding é que geralmente compartilhamos o conteúdo, para que usuários diferentes sigam o mesmo arquivo pelo mesmo "sol" para que eles tenham um cache comum.
Lançamos recentemente o aplicativo Clover. Este é um teste de transmissão ao vivo on-line, onde o apresentador faz perguntas e os usuários respondem em tempo real, escolhendo as opções. O aplicativo tem um bate-papo onde os usuários podem inundar.
Mais de 100 mil pessoas podem se conectar simultaneamente à transmissão. Todos eles escrevem mensagens enviadas a todos os participantes, junto com a mensagem e outro avatar. Se 100 mil pessoas procuram um avatar em um "sol", às vezes ele pode rolar sobre uma nuvem.
Para suportar explosões de solicitações do mesmo arquivo, é para algum tipo de conteúdo que incluímos um esquema burro que espalha arquivos por todos os "sóis" disponíveis na região.
Sol por dentro
Proxy reverso para nginx, cache em discos rápidos RAM ou Optane / NVMe. Exemplo:
http://sun4-2.userapi.com/c100500/path - link para o "sol", que está na quarta região, o segundo grupo de servidores. Ele fecha o arquivo de caminho, que fica fisicamente no servidor 100500.
Cache
Adicionamos mais um nó ao nosso esquema arquitetural - o ambiente de armazenamento em cache.

Abaixo está o layout dos
caches regionais , existem cerca de 20 deles. Estes são os locais em que exatamente os caches e "sóis" estão localizados, os quais podem armazenar em cache o tráfego por si mesmos.

Isso é cache de conteúdo multimídia, os dados do usuário não são armazenados aqui - apenas música, vídeo, fotos.
Para determinar a região do usuário,
coletamos os prefixos de rede BGP anunciados nas regiões . No caso de fallback, ainda temos a análise da base geográfica, se não conseguirmos encontrar o IP por prefixos.
Com base no IP do usuário, determinamos a região . No código, podemos observar uma ou mais regiões do usuário - aqueles pontos nos quais ele é geograficamente mais próximo.
Como isso funciona?
Consideramos a popularidade dos arquivos por região . Há um número de cache regional em que o usuário está localizado e um identificador de arquivo - pegamos esse par e incrementamos a classificação de cada download.
Ao mesmo tempo, demônios - serviços nas regiões - ocasionalmente acessam a API e dizem: "Eu tenho esse e esse cache, me dê uma lista dos arquivos mais populares da minha região que ainda não tenho". A API fornece vários arquivos classificados por classificação, o daemon os distribui, os leva para as regiões e os arquivos a partir daí. Essa é uma diferença fundamental entre pu / pp e Sun dos caches: eles fornecem o arquivo imediatamente, mesmo que o arquivo não exista no cache, e o cache primeiro bombeia o arquivo para si próprio e, em seguida, começa a distribuí-lo.
Ao mesmo tempo,
aproximamos o conteúdo dos usuários e diminuímos a carga da rede. Por exemplo, somente do cache de Moscou distribuímos mais de 1 Tbit / s durante o horário de pico.
Mas há problemas - os
servidores de cache não são de borracha . Para conteúdo super popular, às vezes não há rede suficiente em um servidor separado. Temos servidores de cache de 40 a 50 Gbit / s, mas há conteúdo que obstrui completamente esse canal. Estamos nos esforçando para realizar o armazenamento de mais de uma cópia de arquivos populares na região. Espero que possamos perceber isso até o final do ano.
Examinamos a arquitetura geral.
- Servidores frontais que aceitam solicitações.
- Back-end que manipulam solicitações.
- Cofres fechados por dois tipos de proxies.
- Caches regionais.
O que está faltando nesse esquema? Obviamente, os bancos de dados nos quais armazenamos dados.
Bancos de dados ou mecanismos
Nós os chamamos não de bancos de dados, mas de mecanismos de motores, porque, no sentido geralmente aceito, praticamente não temos bancos de dados.
 Esta é uma medida necessária
Esta é uma medida necessária . Isso aconteceu porque, em 2008-2009, quando o VK teve um crescimento explosivo em popularidade, o projeto funcionou totalmente no MySQL e Memcache, e houve problemas. O MySQL gostava de cair e arruinar arquivos, após o que não aumentou, e o Memcache gradualmente diminuiu o desempenho e teve que ser reiniciado.
Acontece que no projeto que estava ganhando popularidade havia um armazenamento persistente que corrompeu os dados e um cache que diminuiu a velocidade. Em tais condições, é difícil desenvolver um projeto em crescimento. Decidiu-se tentar reescrever as coisas críticas nas quais o projeto repousava em suas próprias motos.
A solução foi bem sucedida . A capacidade de fazer isso era, como era uma necessidade urgente, porque outros métodos de dimensionamento não existiam naquele momento. Não havia um monte de bases, o NoSQL ainda não existia, havia apenas MySQL, Memcache, PostrgreSQL - e isso é tudo.
Operação universal . O desenvolvimento foi liderado por nossa equipe de desenvolvedores C, e tudo foi feito da mesma maneira. Independentemente do mecanismo, em todos os lugares havia aproximadamente o mesmo formato dos arquivos gravados no disco, os mesmos parâmetros de inicialização, os sinais eram processados da mesma forma e se comportavam da mesma maneira em caso de situações e problemas de borda. Com o crescimento dos mecanismos, é conveniente para os administradores operar o sistema - não há zoológico que precise ser mantido e aprender a operar novamente cada nova base de terceiros, o que possibilitou aumentar seu número de maneira rápida e conveniente.
Tipos de motores
A equipe escreveu alguns mecanismos. Aqui estão apenas alguns deles: amigo, dicas, imagem, ipdb, cartas, listas, logs, memcached, meowdb, notícias, nostradamus, foto, listas de reprodução, pmemcached, sandbox, pesquisa, armazenamento, curtidas, tarefas, ...
Para cada tarefa que requer uma estrutura de dados específica ou processa solicitações atípicas, a equipe C escreve um novo mecanismo. Porque não
Temos um mecanismo
memcached separado, que é semelhante ao habitual, mas com muitos pães e que não diminui a velocidade. Não ClickHouse, mas também funciona. Há
pmemcached separadamente - é um
memcached persistente que pode armazenar dados também no disco e mais do que entra na RAM para não perder dados ao reiniciar. Existem vários mecanismos para tarefas individuais: filas, listas, conjuntos - tudo o que é exigido pelo nosso projeto.
Clusters
Do ponto de vista do código, não há necessidade de imaginar mecanismos ou bancos de dados como certos processos, entidades ou instâncias. O código funciona especificamente com clusters, com grupos de mecanismos -
um tipo por cluster . Digamos que exista um cluster armazenado em cache - é apenas um grupo de máquinas.
O código não precisa saber a localização física, tamanho e número de servidores. Ele vai para o cluster por algum identificador.
Para que isso funcione, você precisa adicionar outra entidade, localizada entre o código e os mecanismos -
proxy .
Proxy RPC
Proxy - um
barramento de conexão , que roda quase todo o site. Ao mesmo tempo,
não temos descoberta de serviço - em vez disso, há uma configuração desse proxy, que sabe a localização de todos os clusters e todos os shards deste cluster. Isso é feito pelos administradores.
Os programadores geralmente não se importam com quanto, onde e quanto custa - eles apenas acessam o cluster. Isso nos permite muito. Após o recebimento da solicitação, o proxy a redireciona, sabendo onde - determina isso.

Ao mesmo tempo, o proxy é um ponto de proteção contra falhas no serviço. Se algum mecanismo diminuir a velocidade ou travar, o proxy entenderá isso e responderá adequadamente ao lado do cliente. Isso permite remover o tempo limite - o código não espera o mecanismo responder, mas entende que ele não funciona e você precisa se comportar de maneira diferente. O código deve estar preparado para o fato de que os bancos de dados nem sempre funcionam.
Implementações específicas
Às vezes, ainda queremos ter algum tipo de solução personalizada como mecanismo. Ao mesmo tempo, foi decidido não usar nosso rpc-proxy pronto, criado especificamente para nossos mecanismos, mas criar um proxy separado para a tarefa.
Para o MySQL, que ainda temos em alguns lugares, usamos db-proxy e para ClickHouse -
Kittenhouse .
Isso funciona globalmente assim. Há um servidor, o kPHP, Go, Python em execução - em geral, qualquer código que possa seguir o nosso protocolo RPC. O código vai localmente para o proxy RPC - em cada servidor onde há código, seu próprio proxy local é iniciado. Mediante solicitação, o proxy entende para onde ir.
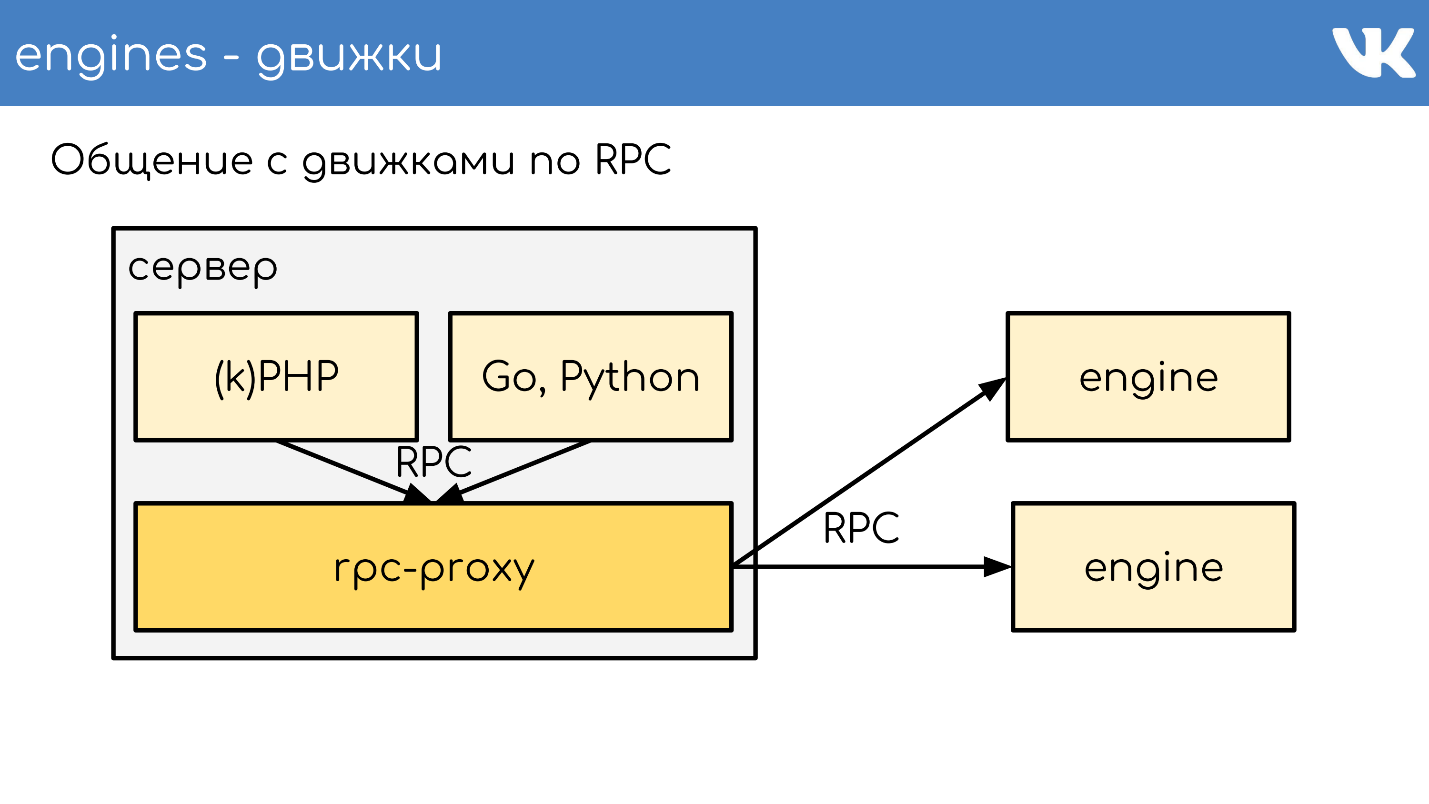
Se um mecanismo deseja ir para outro, mesmo que seja um vizinho, ele passa por um proxy, porque o vizinho pode estar em um data center diferente. O mecanismo não deve estar vinculado a saber a localização de algo que não seja ele próprio - nós temos esta solução padrão. Mas é claro que há exceções :)
Um exemplo de um esquema TL segundo o qual todos os mecanismos funcionam.
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long;
Este é um protocolo binário, cujo análogo mais próximo é o
protobuf. O esquema descreve antecipadamente campos opcionais, tipos complexos - extensões de escalares internos e consultas. Tudo funciona de acordo com este protocolo.
RPC sobre TL sobre TCP / UDP ... UDP?
Temos um protocolo RPC para consultar o mecanismo, que é executado sobre o esquema TL. Tudo isso funciona em cima da conexão TCP / UDP. TCP - está claro por que muitas vezes nos perguntam sobre o UDP.
O UDP ajuda a
evitar o problema de um grande número de conexões entre servidores . Se houver um proxy RPC em cada servidor e, em geral, ele for para qualquer mecanismo, você receberá dezenas de milhares de conexões TCP com o servidor. Há uma carga, mas é inútil. No caso do UDP, isso não é um problema.
Nenhum aperto de mão TCP redundante . Esse é um problema típico: quando um novo mecanismo ou um novo servidor é ativado, muitas conexões TCP são estabelecidas ao mesmo tempo. Para pequenas solicitações leves, por exemplo, carga útil UDP, toda a comunicação entre o código e o mecanismo é de
dois pacotes UDP: um voa em uma direção e o outro voa na outra. Uma viagem de ida e volta - e o código recebeu uma resposta do mecanismo sem um aperto de mão.
Sim, tudo funciona apenas
com uma porcentagem muito pequena de perda de pacotes . O protocolo tem suporte para retransmitências, tempos limite, mas se perdermos muito, obtemos praticamente o TCP, o que não é lucrativo. Nos oceanos, não dirija UDP.
Temos milhares desses servidores e o mesmo esquema existe: um pacote de mecanismos é colocado em cada servidor físico. Basicamente, eles são de rosca única para trabalhar o mais rápido possível sem bloquear e são fragmentados como soluções de rosca única. Ao mesmo tempo, não temos nada mais confiável que esses mecanismos e muita atenção é dada ao armazenamento persistente de dados.
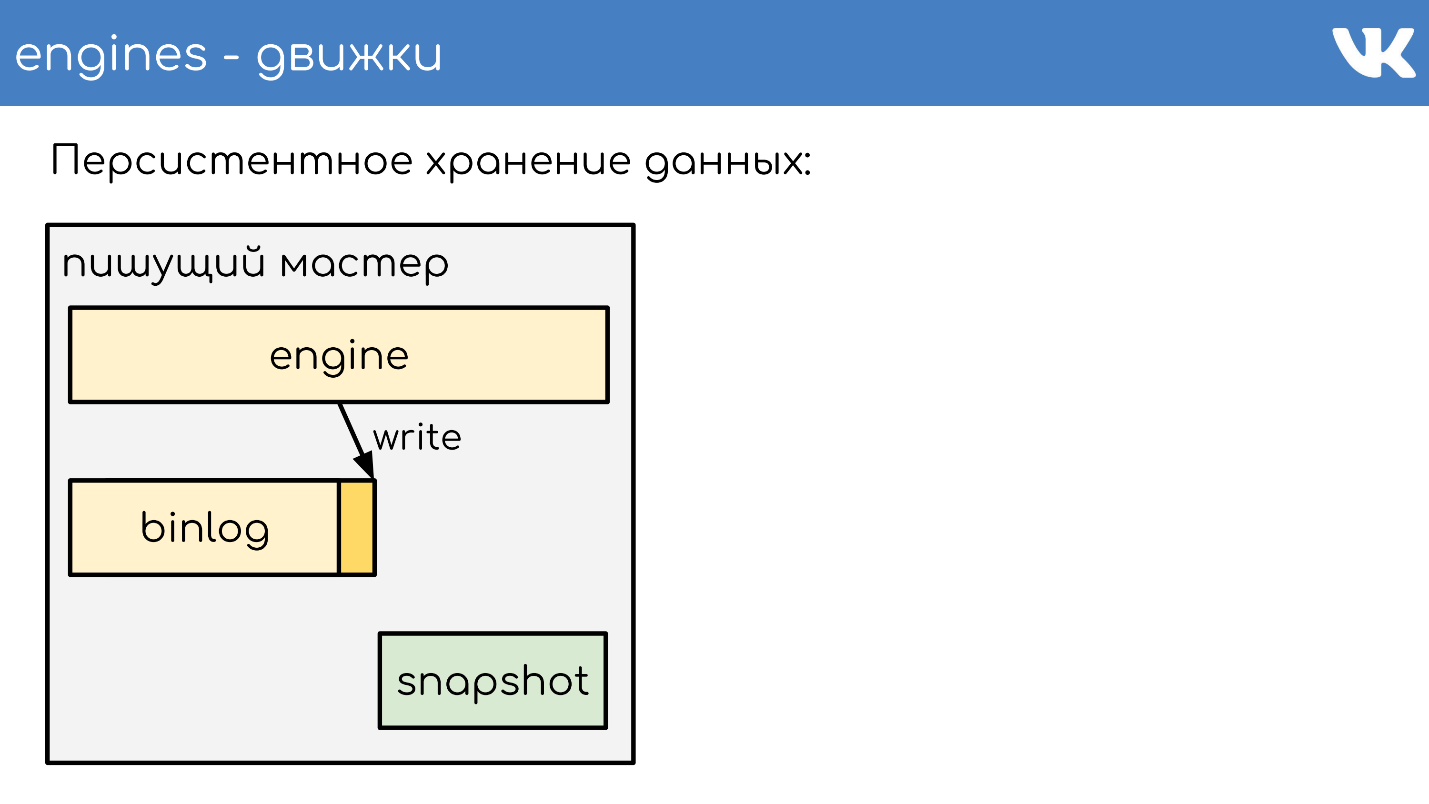
Armazenamento de dados persistente
Os motores escrevem binlogs . Um binlog é um arquivo no final do qual um evento é adicionado para alterar um estado ou dados. Em diferentes soluções, isso é chamado de maneira diferente: log binário,
WAL ,
AOF , mas o princípio é um.
Para que o mecanismo não releia todo o binlog durante uma reinicialização durante muitos anos, os mecanismos gravam
instantâneos - o status atual . Se necessário, eles primeiro lêem e depois lêem no binlog. Todos os binlogs são gravados no mesmo formato binário - de acordo com o esquema TL, para que os administradores possam administrá-los igualmente com suas ferramentas. Não há necessidade de capturas instantâneas. Existe um cabeçalho geral que indica cujo instantâneo é o int, a mágica do mecanismo e qual corpo não é importante para ninguém. Esse é o problema do mecanismo que registrou o instantâneo.
Descreverei brevemente o princípio do trabalho. Há um servidor no qual o mecanismo está sendo executado. Ele abre um novo binlog vazio para gravação, escreve um evento de mudança nele.

Em algum momento, ele decide tirar uma foto instantânea ou recebe um sinal. O servidor cria um novo arquivo, grava completamente seu estado nele, anexa o tamanho atual do log de bin - compensado no final do arquivo e continua a escrever mais. Um novo binlog não é criado.
Em algum momento, quando o mecanismo reiniciar, haverá um binlog e um instantâneo no disco. O mecanismo lê em instantâneo completo, eleva seu estado em um determinado ponto.

Subtrai a posição que estava no momento em que o instantâneo foi criado e o tamanho do binlog.
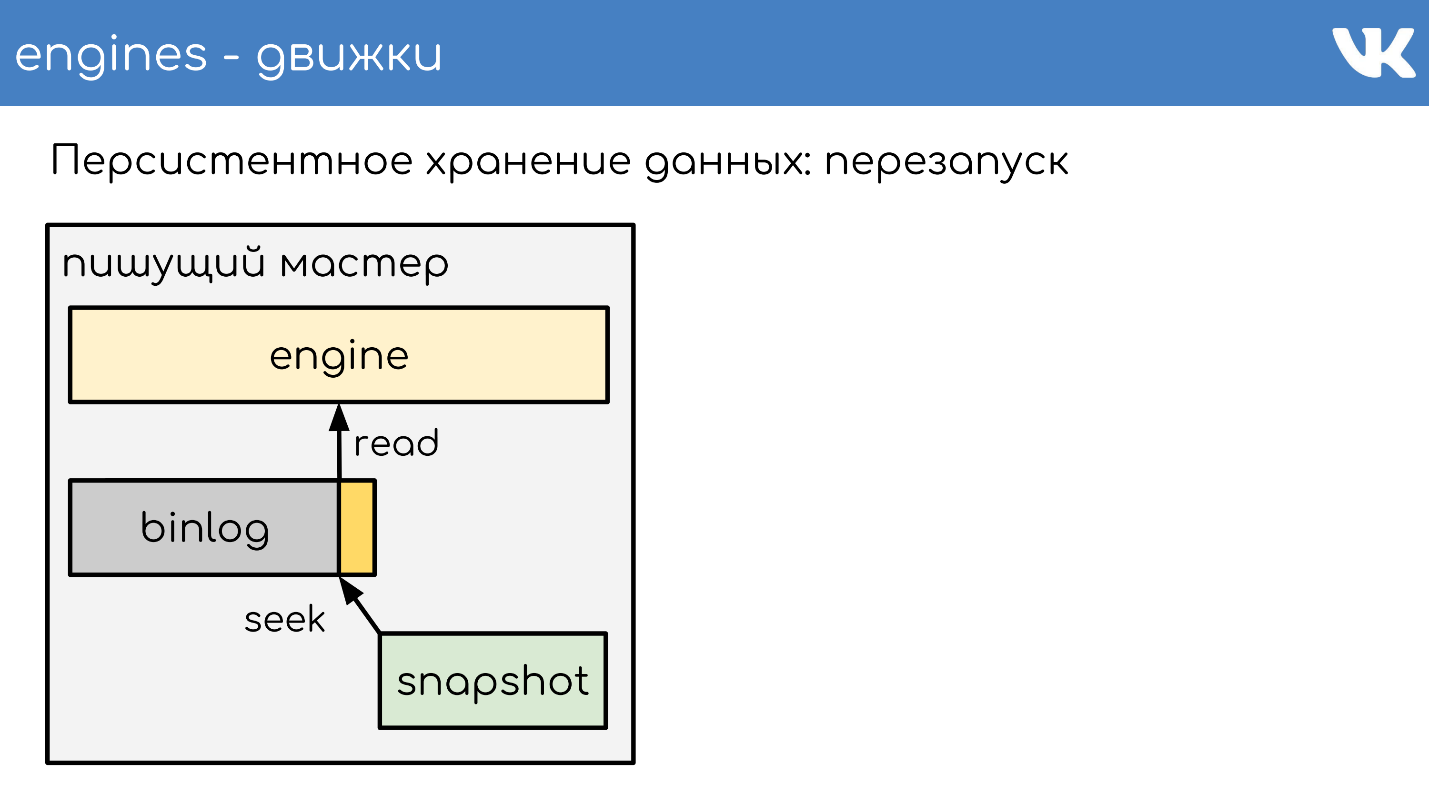
Lê o final do binlog para obter o estado atual e continua a gravar outros eventos. Este é um esquema simples, todos os nossos mecanismos trabalham nele.
Replicação de dados
Como resultado, a replicação de dados é
baseada em instruções - não estamos escrevendo nenhuma alteração de página no binlog, mas
solicitando alterações . Muito parecido com o que vem pela rede, apenas um pouco mudou.
O mesmo esquema é usado não apenas para replicação, mas também
para criar backups . Temos um mecanismo - um mestre de escrita que escreve em um binlog. Em qualquer outro local em que os administradores configurem, a cópia desse binlog aumenta e é tudo - temos um backup.

Se você precisar de uma
réplica de leitura para reduzir a carga de leitura na CPU, o mecanismo de leitura apenas aumentará, que lê o final do binlog e executa esses comandos localmente.
O atraso aqui é muito pequeno e há uma oportunidade de descobrir quanto a réplica está por trás do mestre.
Compartilhamento de dados no proxy RPC
Como o sharding funciona? Como o proxy entende para qual shard de cluster enviar? O código não diz: "Enviar para 15 shard!" - não, ele faz um proxy.
O esquema mais simples é firstint , o primeiro número na solicitação.
get(photo100_500) => 100 % N.Este é um exemplo para um protocolo de texto em memcached simples, mas é claro que as solicitações são complexas e estruturadas. O exemplo pega o primeiro número na consulta e o restante da divisão pelo tamanho do cluster.
Isso é útil quando queremos ter a localidade dos dados de uma entidade. Digamos que 100 seja um ID de usuário ou grupo e queremos que todos os dados de uma entidade estejam no mesmo fragmento para consultas complexas.
Se não nos importamos como as solicitações são espalhadas pelo cluster, há outra opção: fazer o
hash de todo o fragmento .
hash(photo100_500) => 3539886280 % NTambém obtemos o hash, o restante da divisão e o número do shard.
Ambas as opções funcionam apenas se estivermos preparados para o fato de que, quando aumentarmos o tamanho do cluster, o dividiremos ou o aumentaremos várias vezes. Por exemplo, tivemos 16 shards, estamos perdendo, queremos mais - você pode obter 32 com segurança sem tempo de inatividade. Se queremos construir várias vezes, haverá um tempo de inatividade, porque não será possível esmagar tudo com cuidado, sem perdas. Essas opções são úteis, mas nem sempre.
Se precisarmos adicionar ou remover um número arbitrário de servidores,
um hash consistente no anel à la Ketama será usado . Mas, ao mesmo tempo, perdemos completamente a localidade dos dados, precisamos fazer uma solicitação de mesclagem para o cluster para que cada parte retorne sua pequena resposta e já combine as respostas ao proxy.
Existem consultas superespecíficas. : RPC-proxy , , . , , , . proxy.

. —
memcache .
ring-buffer: prefix.idx = line— , , — . 0 1. memcache — . .
,
Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
ClickHouse
, .

, RPC RPC-proxy, , . ClickHouse, :
- - ClickHouse;
- RPC-proxy, ClickHouse, - , , RPC.
— ClickHouse.
ClickHouse,
KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse
reverse proxy , , . .

RPC- , , nginx. KittenHouse UDP.

, UDP- . RPC , UDP. .
Monitoramento
: , , . :
.
Netdata ,
Graphite Carbon . ClickHouse, Whisper, . ClickHouse,
Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
statlogsCountEvent ( 'stat_name', $key1, $key2, …) statlogsUniqueCount ( 'stat_name', $uid, $key1, $key2, …) statlogsValuetEvent ( 'stat_name', $value, $key1, $key2, …) $stats = statlogsStatData($params)
, , — , Wathdogs.
, 600 1 .
, . — , . , .
,
memcache , .
stats-daemon .
logs-collectors , , .

logs-collectors.
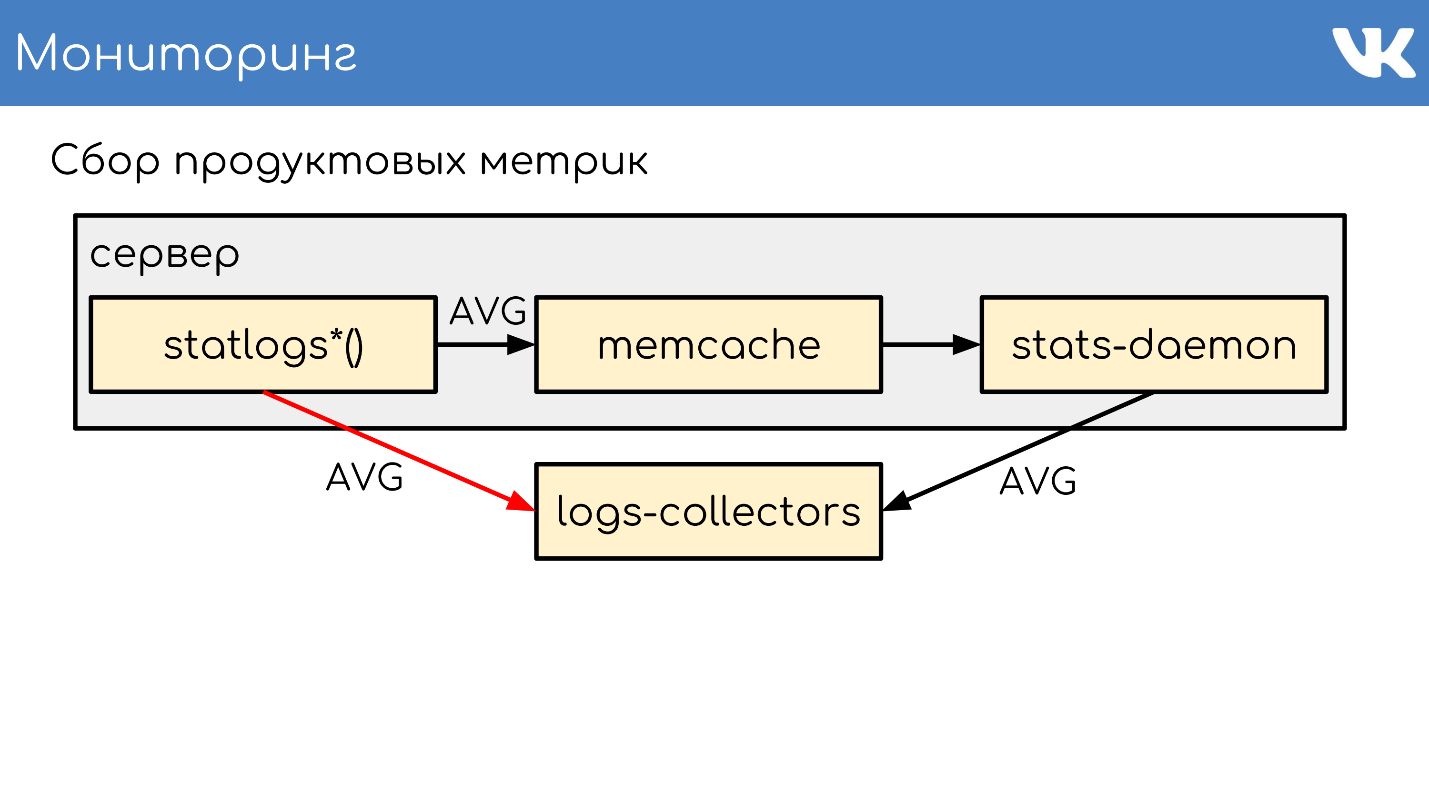
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors
meowDB — , .
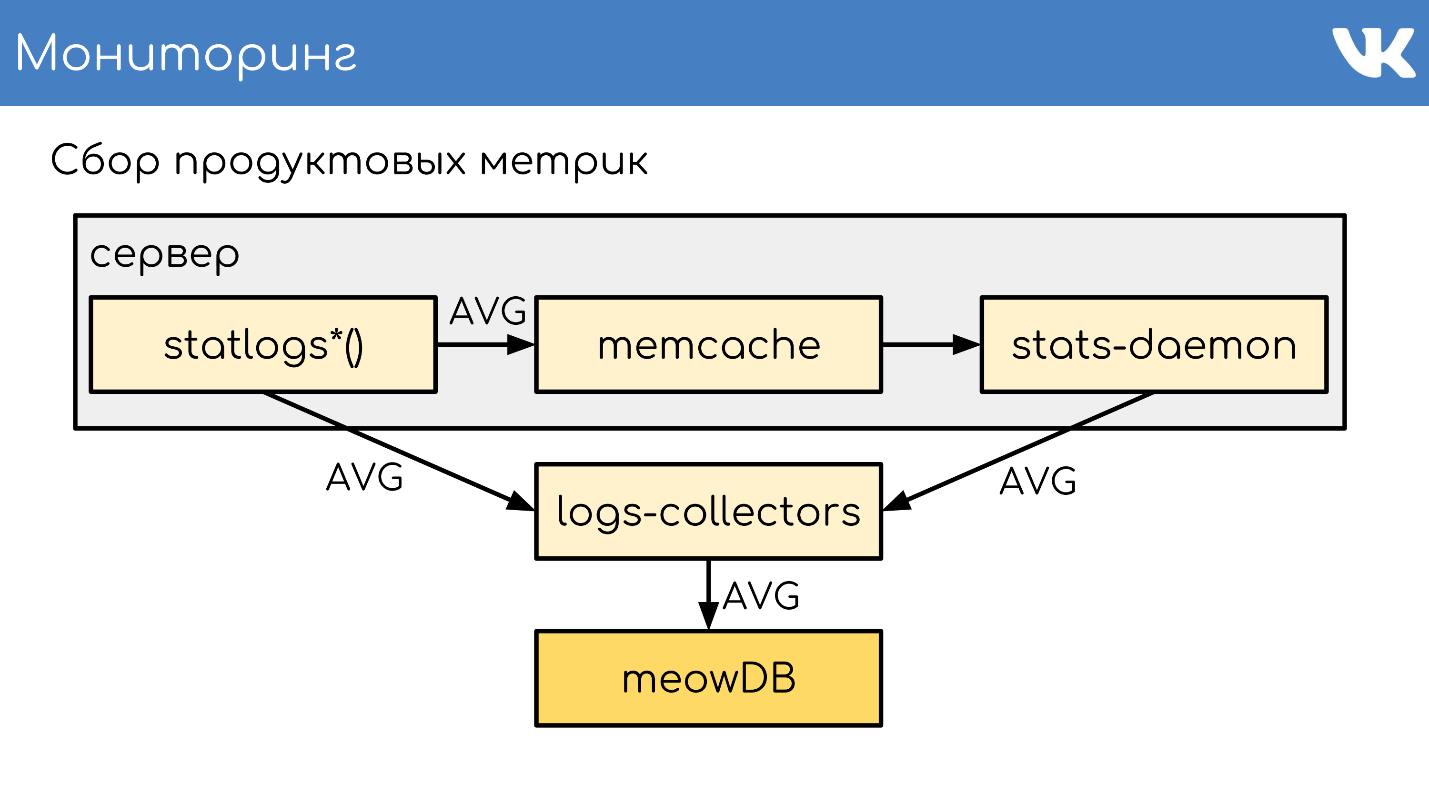
«-SQL» .

2018 , -, ClickHouse. ClickHouse — ?

, KittenHouse.
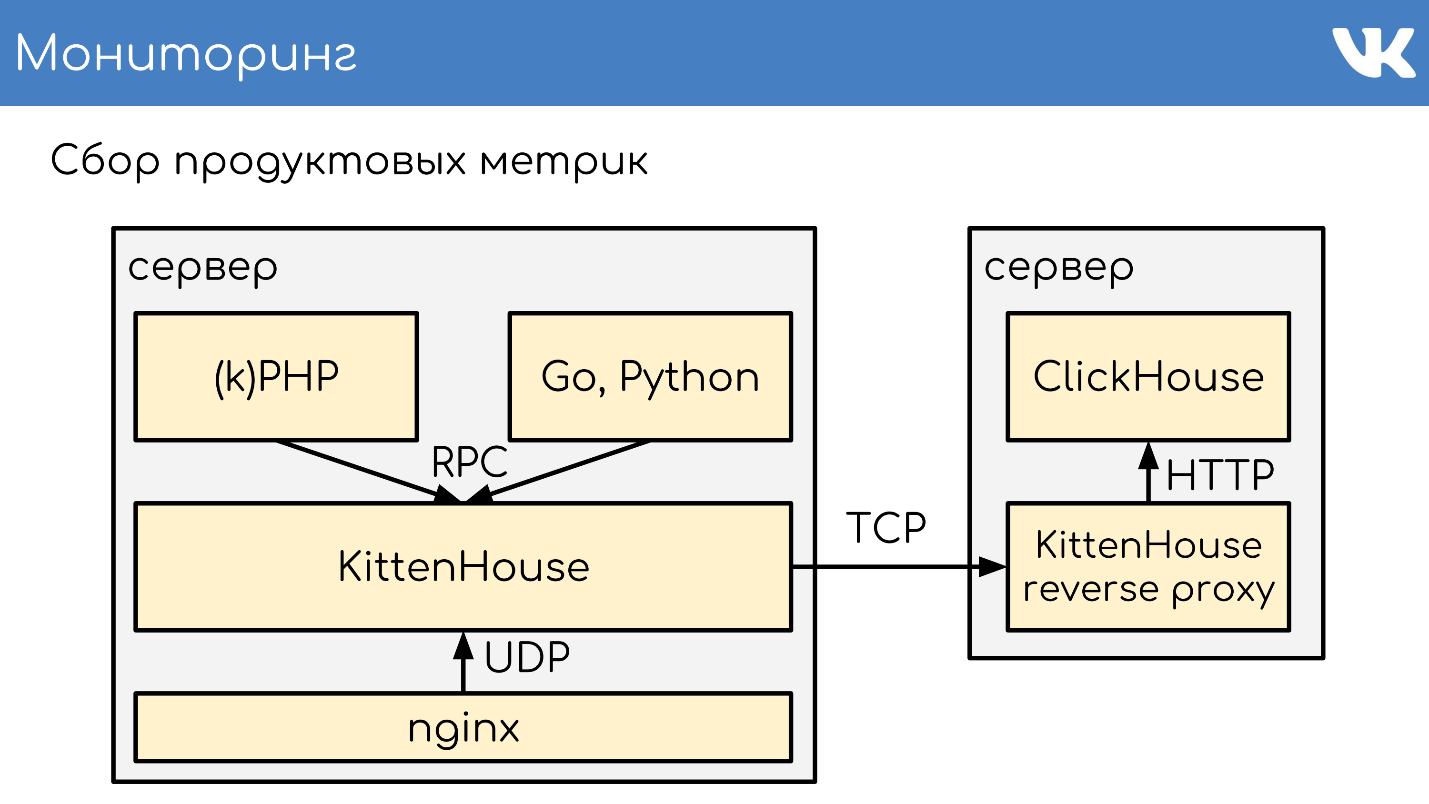 «*House»
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
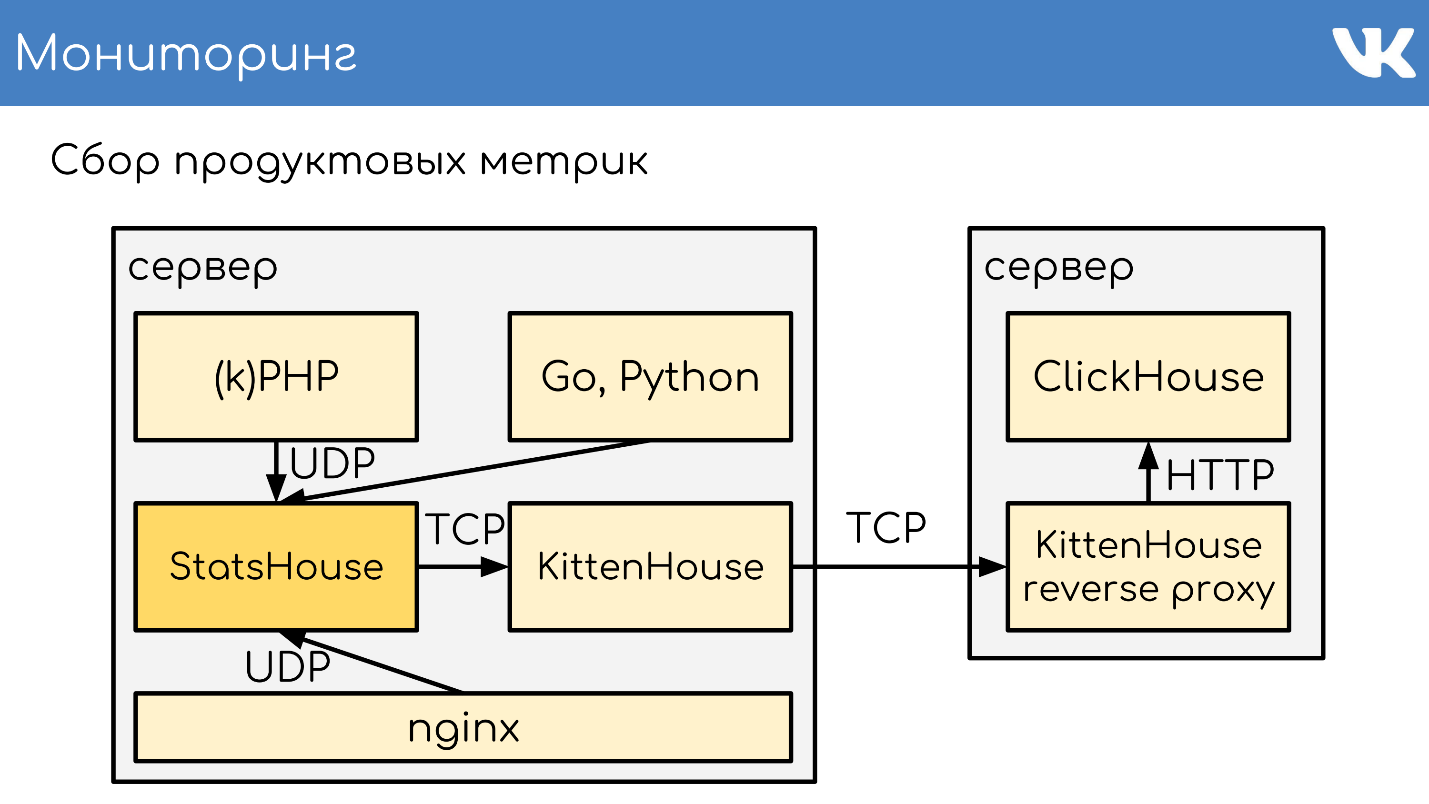
memcache, stats-daemon logs-collectors .

memcache, stats-daemon logs-collectors .
- , StatsHouse.
- StatsHouse KittenHouse UDP-, SQL-inserts, .
- KittenHouse ClickHouse.
- , StatsHouse — ClickHouse SQL.
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , .
, .
PHP.
git :
GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . ,
gossip replication , , — , . . ,
. .
kPHP
git .
HTTP- , diff — . —
binlog copyfast . , .
. copyfast' , binlog , gossip replication , -, .
graceful .
, , :
- git master branch;
- .deb ;
- binlog copyfast;
- ;
- .dep;
- dpkg -i ;
- graceful .
,
.deb ,
dpkg -i . kPHP , — dpkg? . — .
:, PHP Russia 17 PHP-. , , ( PHP!) — , PHP, .