
Oi Quero falar em linguagem clara sobre a mecânica do surgimento de roubo dentro de máquinas virtuais e sobre alguns artefatos não óbvios que conseguimos descobrir durante sua pesquisa, nos quais tive que mergulhar como técnico da plataforma de nuvem
Mail.ru Cloud Solutions . A plataforma é executada no KVM.
Tempo de roubo de CPU é o tempo durante o qual a máquina virtual não recebe recursos do processador para sua execução. Esse tempo é considerado apenas em sistemas operacionais convidados em ambientes de virtualização. As razões pelas quais esses recursos muito alocados vão, como na vida, são muito vagas. Mas decidimos descobrir e até montar uma série de experimentos. Não que agora saibamos tudo sobre roubar, mas contaremos uma coisa interessante agora.
1. O que é roubar
Portanto, roubar é uma métrica que indica falta de tempo do processador para processos dentro de uma máquina virtual. Conforme descrito
no patch do kVM do KVM , roubo é o tempo durante o qual o hypervisor executa outros processos no sistema operacional host, embora tenha colocado na fila o processo da máquina virtual para execução. Ou seja, roubar é considerado como a diferença entre o tempo em que o processo está pronto para executar e o tempo em que o processador recebe o tempo do processo.
O kernel recebe o roubo de métrica do hipervisor. Ao mesmo tempo, o hipervisor não especifica exatamente quais outros processos ele executa, simplesmente "enquanto estou ocupado, não posso lhe dar tempo". No KVM, o suporte à contagem de roubo foi adicionado aos
patches . Existem dois pontos principais aqui:
- A máquina virtual aprende sobre roubar do hipervisor. Ou seja, do ponto de vista de perdas, para processos na própria máquina virtual, é uma medida indireta que pode estar sujeita a várias distorções.
- O hipervisor não compartilha informações com a máquina virtual sobre o que está fazendo com outras pessoas - o principal é que ele não dedica tempo a elas. Por esse motivo, a própria máquina virtual não pode detectar distorções no índice de roubo, o que pode ser estimado pela natureza dos processos concorrentes.
2. O que afeta roubar
2.1 Roubo de cálculo
De fato, o roubo é considerado aproximadamente o mesmo que o tempo normal de utilização da CPU. Não há muita informação sobre como o descarte é considerado. Provavelmente porque a maioria considera essa questão óbvia. Mas também existem armadilhas aqui. Para
se familiarizar com esse processo, você pode ler o
artigo de Brendann Gregg : você aprenderá sobre
várias nuances no cálculo de utilização e sobre situações em que esse cálculo será incorreto pelos seguintes motivos:
- Superaquecimento do processador, durante o qual os ciclos do relógio são ignorados.
- Ligue / desligue o turbo boost, como resultado da alteração da frequência do clock do processador.
- Uma alteração na duração de um quantum de tempo que ocorre ao usar tecnologias de economia de energia do processador, como o SpeedStep.
- O problema de calcular a média: uma estimativa de utilização dentro de um minuto a 80% pode ocultar uma explosão de curto prazo em 100%.
- O bloqueio cíclico (bloqueio de rotação) leva ao fato de o processador ser descartado, mas o processo do usuário não vê progresso em sua execução. Como resultado, a utilização estimada do processador pelo processo será de cem por cento, embora o processo não consuma fisicamente o tempo do processador.
Não encontrei um artigo descrevendo um cálculo semelhante para roubar (se você souber, compartilhe nos comentários). Mas, a julgar pela fonte, o mecanismo de cálculo é o mesmo que para o descarte. É apenas que outro contador é adicionado ao kernel, diretamente para o processo KVM (processo de máquina virtual), que conta o tempo que o processo KVM fica no estado de espera do tempo do processador. O contador obtém informações sobre o processador de suas especificações e procura verificar se todos os seus ticks foram utilizados pelo processo virtual. Se isso é tudo, acreditamos que o processador estava envolvido apenas no processo da máquina virtual. Caso contrário, informamos que o processador estava fazendo outra coisa, o roubo apareceu.
O processo de contagem de roubo está sujeito aos mesmos problemas da contagem regular de reciclagem. Para não dizer que esses problemas aparecem com frequência, mas parecem desanimadores.
2.2 Tipos de virtualização no KVM
De um modo geral, existem três tipos de virtualização, e todos eles são suportados pelo KVM. O tipo de virtualização pode determinar o mecanismo pelo qual o roubo ocorre.
Difusão Nesse caso, a operação do sistema operacional da máquina virtual com os dispositivos físicos do hypervisor ocorre aproximadamente da seguinte maneira:
- O sistema operacional convidado envia um comando para seu dispositivo convidado.
- O driver de dispositivo convidado aceita o comando, gera uma solicitação para o BIOS do dispositivo e o envia ao hipervisor.
- O processo do hypervisor converte um comando em um comando para um dispositivo físico, tornando-o, entre outros, mais seguro.
- O driver de dispositivo físico aceita o comando modificado e o envia para o próprio dispositivo físico.
- Os resultados da execução do comando retornam pelo mesmo caminho.
A vantagem da tradução é que ela permite emular qualquer dispositivo e não requer preparação especial do kernel do sistema operacional. Mas você tem que pagar por isso, antes de tudo, com rapidez.
Virtualização de hardware . Nesse caso, o dispositivo no nível do hardware entende os comandos do sistema operacional. Esta é a maneira mais rápida e melhor. Infelizmente, porém, ele não é suportado por todos os dispositivos físicos, hipervisores e sistemas operacionais convidados. Atualmente, os principais dispositivos que suportam a virtualização de hardware são processadores.
Paravirtualização (paravirtualização) . A versão mais comum da virtualização de dispositivos no KVM e geralmente o modo de virtualização mais comum para sistemas operacionais convidados. Sua peculiaridade é que trabalha com alguns subsistemas do hypervisor (por exemplo, com uma rede ou pilha de discos) ou a alocação de páginas de memória ocorre usando a API do hypervisor, sem converter comandos de baixo nível. A desvantagem desse método de virtualização é a necessidade de modificar o kernel do sistema operacional convidado para que ele possa interagir com o hipervisor usando essa API. Mas geralmente isso é resolvido com a instalação de drivers especiais no sistema operacional convidado. No KVM, essa API é chamada de
API virtio .
Com a paravirtualização, em comparação com a tradução, o caminho para o dispositivo físico é reduzido significativamente enviando comandos diretamente da máquina virtual para o processo do hypervisor do host. Isso permite acelerar a execução de todas as instruções dentro da máquina virtual. No KVM, a API virtio é responsável por isso, que funciona apenas para determinados dispositivos, como um adaptador de rede ou disco. É por isso que os drivers virtio são colocados dentro de máquinas virtuais.
O outro lado dessa aceleração é que nem todos os processos executados dentro de uma máquina virtual permanecem dentro dela. Isso cria alguns efeitos especiais que podem levar ao roubo de aparências. Eu recomendo iniciar um estudo detalhado desse problema com
uma API para E / S virtual: virtio .
2.3 Fair Sheduling
A virtualização em um hipervisor é, de fato, um processo comum que obedece às leis de sheduling (alocação de recursos entre processos) no kernel do Linux; portanto, consideraremos mais detalhadamente.
O Linux usa o chamado CFS, Completely Fair Scheduler, que se tornou o despachante padrão desde o kernel 2.6.23. Para entender esse algoritmo, você pode ler a Arquitetura ou as Fontes do Kernel do Linux. A essência do CFS é a distribuição do tempo do processador entre os processos, dependendo da duração de sua execução. Quanto mais tempo o processador exigir, menos esse tempo receberá. Isso garante a execução "honesta" de todos os processos - para que um processo não ocupe constantemente todos os processadores e outros processos também possam ser executados.
Às vezes, esse paradigma leva a artefatos interessantes. Os usuários de longa data do Linux provavelmente se lembrarão do desbotamento de um editor de texto de desktop comum enquanto executam aplicativos exigentes do tipo compilador. Isso aconteceu porque tarefas de aplicativos de área de trabalho que não consomem muitos recursos competem com tarefas que consomem recursos ativamente, como um compilador. O CFS considera isso desonesto, portanto periodicamente interrompe o editor de texto e permite que o processador processe as tarefas do compilador. Isso foi corrigido usando o mecanismo
sched_autogroup , mas muitos outros recursos da distribuição do tempo da CPU entre tarefas permaneceram. Na verdade, essa história não é sobre como as coisas estão ruins no CFS, mas uma tentativa de chamar a atenção para o fato de que uma distribuição “honesta” do tempo do processador não é a tarefa mais trivial.
Outro ponto importante no sheduler é a preempção. Isso é necessário para conduzir o processo de risonho do processador e permitir que outras pessoas funcionem. O processo de exílio é chamado de alternância de contexto, alternância de contexto do processador. Nesse caso, todo o contexto da tarefa é salvo: o estado da pilha, registradores, etc., após o qual o processo espera e outro substitui. Essa é uma operação cara para o sistema operacional e raramente é usada, mas, na verdade, não há nada de errado com ela. A mudança frequente de contexto pode indicar um problema no sistema operacional, mas geralmente continua continuamente e não indica nada em particular.
Uma história tão longa é necessária para explicar um fato: quanto mais recursos de processador um honesto sheduler do Linux tentar consumir, mais rápido será interrompido para que outros processos funcionem também. Se isso está correto ou não, é um problema complexo, resolvido de maneira diferente sob diferentes cargas. No Windows, até recentemente, o sheduler estava focado no processamento prioritário de aplicativos de desktop, por causa dos quais os processos em segundo plano podiam travar. A Sun Solaris tinha cinco classes diferentes de shedulers. Quando eles começaram a virtualização, adicionaram o sexto
agendador de compartilhamento justo , porque os cinco anteriores trabalhavam inadequadamente com a virtualização do Solaris Zones. Eu recomendo iniciar um estudo detalhado desse problema com livros como
Solaris Internals: Solaris 10 e OpenSolaris Kernel Architecture ou
Entendendo o kernel do Linux .
2.4 Como monitorar o roubo?
O monitoramento de roubo dentro de uma máquina virtual, como qualquer outra métrica do processador, é simples: você pode usar qualquer meio de remover as métricas do processador. O principal é que a máquina virtual está no Linux. Por alguma razão, o Windows não fornece essas informações aos seus usuários. :(
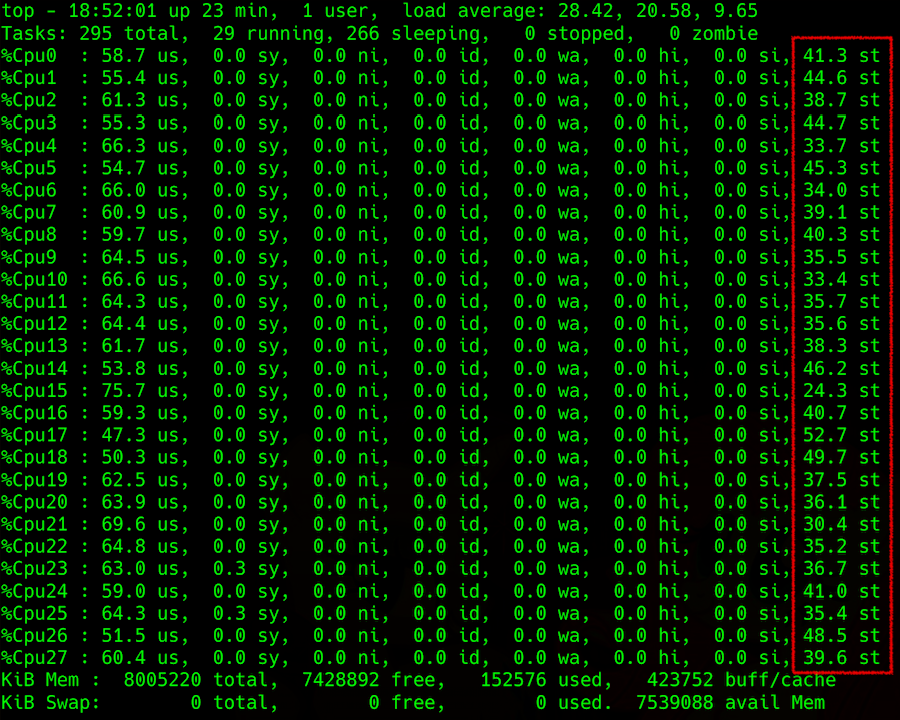 A saída do comando top: detalhes da carga do processador, na coluna da direita - steal
A saída do comando top: detalhes da carga do processador, na coluna da direita - stealA dificuldade surge ao tentar obter essas informações do hipervisor. Você pode tentar prever o roubo na máquina host, por exemplo, pelo parâmetro Load Average (LA) - o valor médio do número de processos aguardando na fila para execução. A metodologia para calcular esse parâmetro não é simples, mas, em geral, se LA, normalizada pelo número de threads do processador, for maior que 1, isso indica que o servidor Linux está um pouco sobrecarregado.
Quais são todos esses processos aguardando? A resposta óbvia é o processador. Mas a resposta não está totalmente correta, porque às vezes o processador é gratuito e LA é transferida. Lembre-se de
como o NFS cai e como LA cresce . Pode ser aproximadamente o mesmo com um disco e com outros dispositivos de entrada / saída. Mas, na verdade, os processos podem esperar o fim de qualquer bloqueio, tanto físico, associado a um dispositivo de E / S, quanto lógico, como um mutex. Isso também inclui bloqueios no nível do hardware (a mesma resposta do disco) ou lógica (as chamadas primitivas de bloqueio, que incluem várias entidades, adaptabilidade e rotação mutex, semáforos, variáveis de condição, bloqueios rw, bloqueios ipc ...).
Outra característica do LA é que ele é considerado como o valor médio para o sistema operacional. Por exemplo, 100 processos competem por um arquivo e, em seguida, LA = 50. Um valor tão grande, ao que parece, sugere que o sistema operacional é ruim. Mas para outro código torto, este pode ser um estado normal, apesar de ser ruim apenas para ele, e outros processos no sistema operacional não sofrerem.
Devido a essa média (e não menos de um minuto), determinar algo pelo indicador de AL não é a tarefa mais grata, com resultados muito incertos em casos específicos. Se você tentar descobrir, descobrirá que apenas os casos mais simples são descritos nos artigos da Wikipedia e em outros recursos disponíveis, sem uma explicação profunda do processo. Eu mando todos os interessados, novamente,
aqui, para Brendann Gregg - mais nos links. Para quem a preguiça em inglês é uma
tradução de seu popular artigo sobre LA .
3. efeitos especiais
Agora vamos nos debruçar nos principais casos de roubo que encontramos. Vou lhe contar como eles seguem o que foi dito acima e como eles se relacionam com os indicadores no hipervisor.
Reciclagem . O mais simples e mais frequente: o hipervisor é reutilizado. De fato, existem muitas máquinas virtuais em execução, um grande consumo de processador dentro delas, muita concorrência, a utilização de LA é superior a 1 (normalizada pelos encadeamentos do processador). Dentro de todos os virtualoks, tudo diminui. O roubo transmitido a partir do hipervisor também está crescendo, é necessário redistribuir a carga ou desligar alguém. Em geral, tudo é lógico e compreensível.
Paravirtualização versus instâncias únicas . Há uma única máquina virtual no hipervisor, que consome uma pequena parte dela, mas fornece uma grande carga na entrada / saída, por exemplo, em um disco. E de algum lugar, um pequeno roubo aparece, até 10% (como mostrado por várias experiências).
O caso é interessante. O roubo aparece aqui apenas por causa dos bloqueios no nível dos drivers paravirtualizados. Uma interrupção é criada dentro da máquina virtual, processada pelo driver e vai para o hipervisor. Devido ao processamento de interrupção no hypervisor da máquina virtual, parece uma solicitação enviada, está pronta para execução e aguardando o processador, mas eles não concedem tempo ao processador. Virtualka acha que desta vez foi roubado.
Isso acontece quando o buffer é enviado, ele vai para o espaço do kernel do hypervisor e começamos a esperar por ele. Embora, do ponto de vista do virtualka, ele deva retornar imediatamente. Portanto, de acordo com o algoritmo de cálculo de roubo, esse tempo é considerado roubado. Provavelmente, nessa situação, pode haver outros mecanismos (por exemplo, processamento de outras chamadas do sistema), mas eles não devem ser muito diferentes.
Sheduler contra virtualoks muito carregados . Quando uma máquina virtual sofre mais roubos do que outras, ela é conectada precisamente ao sheduler. Quanto mais forte o processo carregar o processador, mais cedo o sheduler o expulsará, para que os outros também possam trabalhar. Se a máquina virtual consome um pouco, ela quase não vê roubo: seu processo honestamente ficou parado e aguardou, é necessário dar mais tempo a ele. Se a máquina virtual produz a carga máxima em todos os seus núcleos, ela geralmente é expulsa do processador e tenta não dar muito tempo.
Pior ainda, quando os processos dentro da máquina virtual tentam obter mais processador, porque eles não conseguem lidar com o processamento de dados. Em seguida, o sistema operacional no hipervisor, devido à otimização honesta, fornecerá cada vez menos tempo ao processador. Esse processo ocorre como uma avalanche e o roubo salta para o céu, embora outras máquinas virtuais quase não notem. E quanto mais núcleos, pior a máquina caiu sob a distribuição. Em resumo, as máquinas virtuais pesadamente carregadas e com muitos núcleos sofrem mais.
Baixa LA, mas há um roubo . Se LA for de cerca de 0,7 (ou seja, o hipervisor parece estar sobrecarregado), mas o roubo é observado em máquinas virtuais individuais:
- A opção descrita acima com paravirtualização. Uma máquina virtual pode receber métricas que apontam para roubar, embora tudo esteja bem com o hipervisor. De acordo com os resultados de nossas experiências, essa opção de roubo não excede 10% e não deve ter um impacto significativo no desempenho do aplicativo dentro da máquina virtual.
- O parâmetro LA é considerado incorretamente. Mais precisamente, a cada momento em particular é considerado verdadeiro, mas, em média por um minuto, acaba sendo subestimado. Por exemplo, se uma máquina virtual consome todos os seus processadores por exatamente meio minuto por terço do hypervisor, então LA por minuto será de 0,15 no hypervisor; quatro dessas máquinas virtuais trabalhando simultaneamente fornecerão 0,6. E o fato de que por meio minuto em cada um deles houve um roubo de 25% em Los Angeles, não pode mais ser retirado.
- Mais uma vez, por causa do comerciante que decidiu que alguém estava comendo demais e deixou este esperar. Enquanto isso, estou mudando o contexto, processando interrupções e fazendo outras coisas importantes no sistema. Como resultado, algumas máquinas virtuais não apresentam problemas, enquanto outras experimentam uma grave degradação do desempenho.
4. Outras distorções
Há mais um milhão de razões para distorcer o retorno honesto do tempo do processador na máquina virtual. Por exemplo, hypertreading e NUMA adicionam complexidade aos cálculos. Eles confundem completamente a escolha do kernel para executar o processo, porque o sheduler usa coeficientes - pesos, que ao trocar de contexto tornam o cálculo ainda mais difícil.
Existem distorções devido a tecnologias como o turbo boost ou, inversamente, o modo de economia de energia, que ao calcular a utilização pode aumentar ou diminuir artificialmente a frequência ou mesmo o tempo no servidor. A ativação do turbo boost reduz o desempenho de um segmento do processador devido ao aumento do desempenho de outro. Nesse momento, as informações sobre a frequência atual do processador não são transmitidas para a máquina virtual e ela acredita que alguém está gastando seu tempo (por exemplo, ela solicitou 2 GHz, mas recebeu metade disso).
Em geral, pode haver muitas causas de distorção. Em um sistema específico, você pode encontrar outra coisa. É melhor começar com os livros aos quais forneci os links acima e obter estatísticas do hypervisor com utilitários como perf, sysdig, systemtap, dos quais existem
dezenas .
5. Conclusões
- Uma certa quantidade de roubo pode ocorrer devido à paravirtualização e pode ser considerada normal. Na Internet, eles escrevem que esse valor pode ser de 5 a 10%. Depende dos aplicativos dentro da máquina virtual e do tipo de carga que ela coloca em seus dispositivos físicos. É importante prestar atenção em como os aplicativos nas máquinas virtuais se sentem.
- A proporção da carga no hipervisor e o roubo dentro da máquina virtual nem sempre é interconectada de maneira inequívoca, ambas as estimativas de roubo podem ser errôneas em situações específicas com cargas diferentes.
- O Agendador não gosta de processos que exigem muito. Ele tenta dar menos para quem pede mais. Grandes máquinas virtuais são más.
- Um pequeno roubo pode ser a norma sem paravirtualização (levando em consideração a carga dentro da máquina virtual, os recursos de carga dos vizinhos, a distribuição de carga entre threads e outros fatores).
- Se você deseja descobrir roubo em um sistema específico, é necessário pesquisar várias opções, coletar métricas, analisá-las cuidadosamente e pensar em como distribuir uniformemente a carga. Desvios são possíveis em qualquer caso, que deve ser confirmado experimentalmente ou visualizado no depurador do kernel.