Continuando o tópico dos concursos de aprendizado de máquina no Habré, queremos apresentar aos leitores mais duas plataformas. Eles certamente não são tão grandes quanto os kaggle, mas definitivamente merecem atenção.

Pessoalmente, não gosto muito de kaggle por vários motivos:
- primeiro, as competições duram vários meses e é necessário muito esforço para participação ativa;
- segundo, kernels públicos (soluções públicas). Os adeptos do kaggle os aconselham a ficarem calmos com os monges tibetanos, mas, na realidade, é uma pena que o que você passou por um mês ou dois repentinamente acabe sendo colocado em uma bandeja para todos.
Felizmente, as competições de aprendizado de máquina são realizadas em outras plataformas e algumas dessas competições serão discutidas.
| IDAO | SNA Hackathon 2019 |
|---|
Língua oficial: inglês,
organizadores: Yandex, Sberbank, HSE | Língua oficial: russo,
organizadores: Mail.ru Group |
Rodada Online: 15 de janeiro a 11 de fevereiro de 2019;
Final no local: 4-6 de abril de 2019 | online - de 7 de fevereiro a 15 de março;
offline - de 30 de março a 1º de abril. |
A partir de um determinado conjunto de dados de uma partícula em um grande colisor de hádrons (na trajetória, momento e outros parâmetros físicos bastante complexos), determine se é ou não um múon
A partir dessa declaração, foram distinguidas 2 tarefas:
- em um você apenas tinha que enviar sua previsão,
- e no outro - o código e o modelo completos para previsão, e restrições bastante estritas foram impostas ao tempo de execução e uso de memória | Para a competição SNA Hackathon, foram coletados logs para mostrar o conteúdo de grupos abertos nos feeds de notícias dos usuários de fevereiro a março de 2018. O conjunto de testes ocultou a última semana e meia de março. Cada entrada no log contém informações sobre o que foi mostrado a quem e também sobre como o usuário reagiu a esse conteúdo: coloque uma "classe", comentada, ignorada ou oculta do feed.
A essência das tarefas do SNA Hackathon é organizar para cada usuário da rede social Odnoklassniki sua fita, elevando o mais alto possível os posts que receberão a “classe”.
No estágio online, a tarefa foi dividida em 3 partes:
1. para classificar as postagens com uma variedade de motivos de colaboração
2. classifique os posts pelas imagens contidas neles
3. classificar os posts de acordo com o texto neles contido |
| Uma métrica personalizada complexa, algo como ROC-AUC | ROC-AUC médio por usuários |
Prêmios para a primeira etapa - camisetas para N lugares, passagem para a segunda etapa, onde hospedagem e refeições foram pagas durante a competição
A segunda etapa - ??? (Por alguma razão, eu não estava presente na cerimônia de premiação e não conseguia descobrir o que acabei com os prêmios). Laptops prometidos a todos os membros da equipe vencedora | Prêmios para a primeira etapa - camisetas para os 100 melhores participantes, passagem para a segunda etapa, onde pagaram a viagem a Moscou, acomodação e refeições durante a competição. Além disso, no final do primeiro estágio, os prêmios foram anunciados como os melhores em três tarefas no estágio 1: todos venceram na placa de vídeo RTX 2080 TI!
A segunda etapa é a equipe 1, as equipes tinham de 2 a 5 pessoas, prêmios:
1º lugar - 300.000 rublos
2º lugar - 200 000 rublos
3º lugar - 100.000 rublos
prêmio do júri - 100 000 rublos |
| O grupo oficial no telegrama, ~ 190 participantes, comunicação em inglês, tive que esperar vários dias para responder perguntas | O grupo oficial no telegrama, ~ 1500 participantes, uma discussão ativa de tarefas entre participantes e organizadores |
| Os organizadores forneceram duas soluções básicas, simples e avançadas. Um simples exigia menos de 16 GB de RAM, enquanto um avançado de 16 não era adequado. Ao mesmo tempo, avançando um pouco à frente, os participantes não conseguiram exceder significativamente a solução avançada. Não houve dificuldades no lançamento dessas soluções. Note-se que no exemplo avançado houve um comentário com uma dica de onde começar a melhorar a solução. | Soluções primitivas básicas foram fornecidas para cada uma das tarefas, facilmente ultrapassadas pelos participantes. Nos primeiros dias do concurso, os participantes enfrentaram várias dificuldades: primeiro, os dados foram fornecidos no formato Apache Parquet, e nem todas as combinações de Python e o pacote parquet funcionaram sem erros. A segunda dificuldade foi extrair imagens da nuvem de correio, no momento não há uma maneira fácil de baixar uma grande quantidade de dados por vez. Como resultado, esses problemas atrasaram os participantes por alguns dias. |
IDAO. Primeira etapa
A tarefa era classificar as partículas de múon / não-múon de acordo com suas características. Uma característica fundamental dessa tarefa foi a presença de uma coluna de peso nos dados de treinamento, que os próprios organizadores interpretaram como confiança na resposta para essa linha. O problema era que algumas linhas continham pesos negativos.
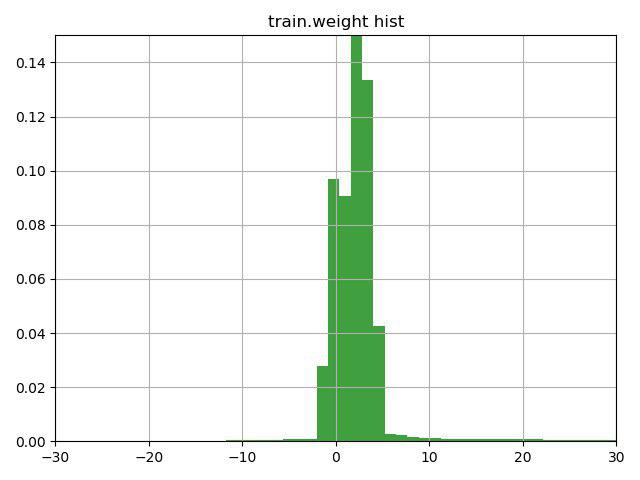
Depois de pensar por alguns minutos na linha com uma dica (a dica chamou a atenção para esse recurso da coluna de peso) e construir esse gráfico, decidimos verificar três opções:
1) inverta a meta para linhas com peso negativo (e peso, respectivamente)
2) mude os pesos para o valor mínimo, para que eles comecem com 0
3) não use pesos para linhas
A terceira opção acabou sendo a pior, mas as duas primeiras melhoraram o resultado, a melhor foi a opção número 1, que imediatamente nos levou ao atual segundo lugar na primeira tarefa e à primeira na segunda.

Nosso próximo passo foi examinar os dados em busca de valores ausentes. Os organizadores nos deram dados já penteados, onde havia alguns valores ausentes, e eles foram substituídos por -9999.
Encontramos valores ausentes nas colunas MatchedHit_ {X, Y, Z} [N] e MatchedHit_D {X, Y, Z} [N] e somente quando N = 2 ou 3. Como entendemos, algumas partículas não voaram pelos quatro detectores e parou na placa 3 ou 4. Os dados também continham colunas Lextra_ {X, Y} [N], que aparentemente descrevem a mesma coisa que MatchedHit_ {X, Y, Z} [N], mas usando algum tipo de extrapolação. Essas suposições limitadas sugeriram que, em vez de valores ausentes no MatchedHit_ {X, Y, Z} [N], você pode substituir Lextra_ {X, Y} [N] (apenas as coordenadas X e Y). MatchedHit_Z [N] foi bem preenchido com uma mediana. Essas manipulações nos permitiram ir para um local intermediário para ambas as tarefas.

Dado que para a vitória na primeira etapa eles não deram nada, poderíamos parar com isso, mas continuamos, desenhamos algumas belas imagens e criamos novos recursos.

Por exemplo, descobrimos que, se construirmos os pontos de interseção das partículas a partir de cada uma das quatro placas dos detectores, podemos ver que os pontos em cada uma das placas são agrupados em 5 retângulos com uma proporção de 4 a 5 e o centro em (0,0) o primeiro retângulo não tem pontos.
| Nº da placa / dimensões do retângulo | 1 | 2 | 3 | 4 | 5 |
|---|
| Placa 1 | 500 x 625 | 1000x1250 | 2000x2500 | 4000x5000 | 8000x10000 |
| Placa 2 | 520x650 | 1040x1300 | 2080x2600 | 4160x5200 | 8320x10400 |
| Placa 3 | 560x700 | 1120x1400 | 2240x2800 | 4480x5600 | 8960x11200 |
| Placa 4 | 600x750 | 1200x1500 | 2400x3000 | 4800x6000 | 9600x12000 |
Depois de determinar esses tamanhos, adicionamos para cada partícula 4 novos recursos categóricos - o número do retângulo no qual ele cruza cada placa.
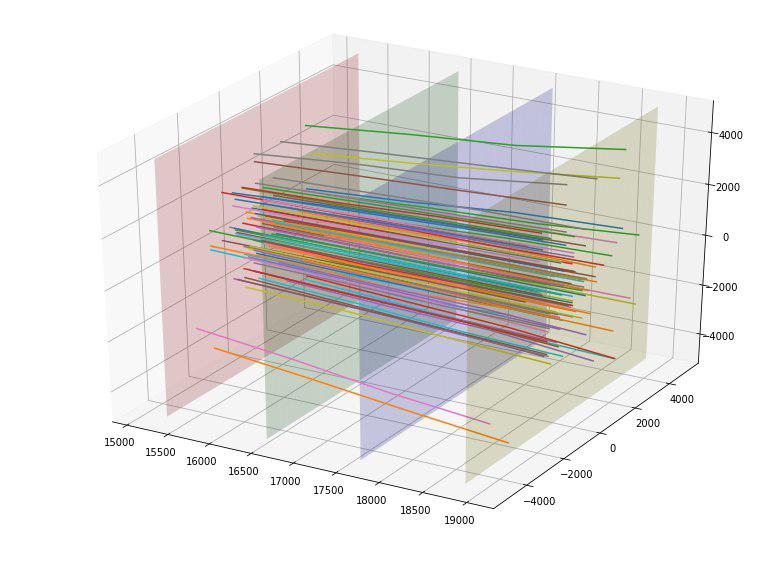
Também percebemos que as partículas pareciam se espalhar para longe do centro e surgiu a idéia de avaliar de alguma forma a “qualidade” dessa dispersão. Idealmente, provavelmente, alguém poderia inventar algum tipo de parábola "ideal", dependendo do ponto de entrada e estimar o desvio, mas nos limitamos à linha "ideal". Ao construir essas linhas ideais para cada ponto de entrada, conseguimos calcular o desvio do quadrado médio da trajetória de cada partícula dessa linha. Como o desvio médio para a meta = 1 foi 152 e para a meta = 0 resultou em 390, classificamos provisoriamente esse recurso como bom. De fato, esse recurso atingiu imediatamente o topo dos mais úteis.
Ficamos encantados e adicionamos o desvio de todos os 4 pontos de interseção para cada partícula da linha ideal como quatro recursos adicionais (e eles também funcionaram bem).
Os links para artigos científicos sobre o tema da competição, dados pelos organizadores, sugerem que estamos longe dos primeiros a resolver esse problema e, talvez, haja algum software especializado. Após descobrir o repositório no github onde os métodos IsMuonSimple, IsMuon, IsMuonLoose foram implementados, nós os transferimos para nós mesmos com pequenas modificações. Os métodos em si eram muito simples: por exemplo, se a energia é menor que um limite, então este não é um múon, caso contrário, um múon. Obviamente, esses sinais simples não poderiam aumentar o uso do aumento de gradiente; portanto, adicionamos outro sinal "distância" ao limite. Esses recursos também melhoraram um pouco. Talvez, tendo analisado os métodos existentes mais detalhadamente, seja possível encontrar métodos mais fortes e adicioná-los aos atributos.
No final do concurso, criamos uma solução “rápida” para a segunda tarefa, como resultado, ela diferiu da linha de base nos seguintes pontos:
- Nas linhas com peso negativo, o destino foi invertido
- Preenchido os valores ausentes em MatchedHit_ {X, Y, Z} [N]
- Profundidade reduzida para 7
- Taxa de aprendizado reduzida para 0,1 (foi de 0,19)
Como resultado, tentamos mais recursos (não particularmente bem-sucedidos), selecionamos os parâmetros e treinamos catboost, lightgbm e xgboost, tentamos diferentes combinações de previsões e vencemos com confiança a segunda tarefa antes de abrir o privat e estivemos entre os líderes na primeira.
Depois que o privat foi aberto, estávamos no 10º lugar em 1 tarefa e 3 na segunda. Todos os líderes estavam confusos, e a velocidade no privat era maior do que no quadro de distribuição. Parece que os dados foram pouco estratificados (ou, por exemplo, não havia linhas com pesos negativos no privado) e isso foi um pouco frustrante.
SNA Hackathon 2019 - Textos. Primeira etapa
A tarefa era classificar as postagens do usuário na rede social Odnoklassniki de acordo com o texto nelas, além do texto, havia mais algumas características da postagem (idioma, proprietário, data e hora da criação, data e hora da exibição).
Como abordagens clássicas para trabalhar com texto, eu destacaria duas opções:
- Mapeando cada palavra no espaço vetorial n-dimensional, de modo que palavras semelhantes tenham vetores semelhantes (mais detalhes podem ser encontrados em nosso artigo ), localize a palavra do meio para o texto ou use mecanismos que levem em consideração a posição relativa das palavras (CNN, LSTM / GRU) .
- Usando modelos que podem trabalhar imediatamente com frases inteiras. Por exemplo, Bert. Em teoria, essa abordagem deve funcionar melhor.
Como essa foi minha primeira experiência com textos, seria errado ensinar alguém, então eu vou me ensinar. Estas são as dicas que eu daria a mim mesmo no início do concurso:
- Antes de correr para aprender algo, observe os dados! Além dos textos em si, havia várias colunas nos dados e muito mais poderia ser extraído delas do que eu. O mais simples é significar a codificação de destino para parte das colunas.
- Não aprenda com todos os dados! Havia muitos dados (aproximadamente 17 milhões de linhas) e era completamente opcional usar todos eles para testar hipóteses. O treinamento e o pré-processamento eram muito lentos, e eu claramente teria tempo para testar hipóteses mais interessantes.
- < Conselho controverso > Não há necessidade de procurar um modelo matador. Eu lidei com Elmo e Bert por um longo tempo, esperando que eles me levassem imediatamente a um lugar alto e, como resultado, eu usei casamentos pré-treinados do FastText para o idioma russo. Com o Elmo, não foi possível obter uma velocidade melhor, mas com o Bert não consegui descobrir.
- < Conselho controverso > Não procure um recurso matador. Observando os dados, notei que na região de 1% dos textos não contêm, de fato, o texto! Mas havia links para alguns recursos, e escrevi um analisador simples que abriu o site e extraiu o nome e a descrição. Parece uma boa ideia, mas então me empolguei, decidi analisar todos os links de todos os textos e, novamente, perdi muito tempo. Tudo isso não deu uma melhora significativa no resultado final (embora eu tenha descoberto com o stemming, por exemplo).
- Os recursos clássicos funcionam. O Google, por exemplo, "recursos de texto alternativos", lê e adiciona tudo. O TF-IDF deu uma melhoria, características estatísticas, como o comprimento do texto, a palavra, a quantidade de pontuação também.
- Se houver colunas DateTime, você deverá analisá-las em vários recursos separados (horas, dias da semana etc.). Quais recursos a serem destacados devem ser analisados com gráficos / algumas métricas. Aqui, eu fiz tudo certo com um palpite e selecionei os recursos necessários, mas uma análise normal não faria mal (por exemplo, como fizemos na final).
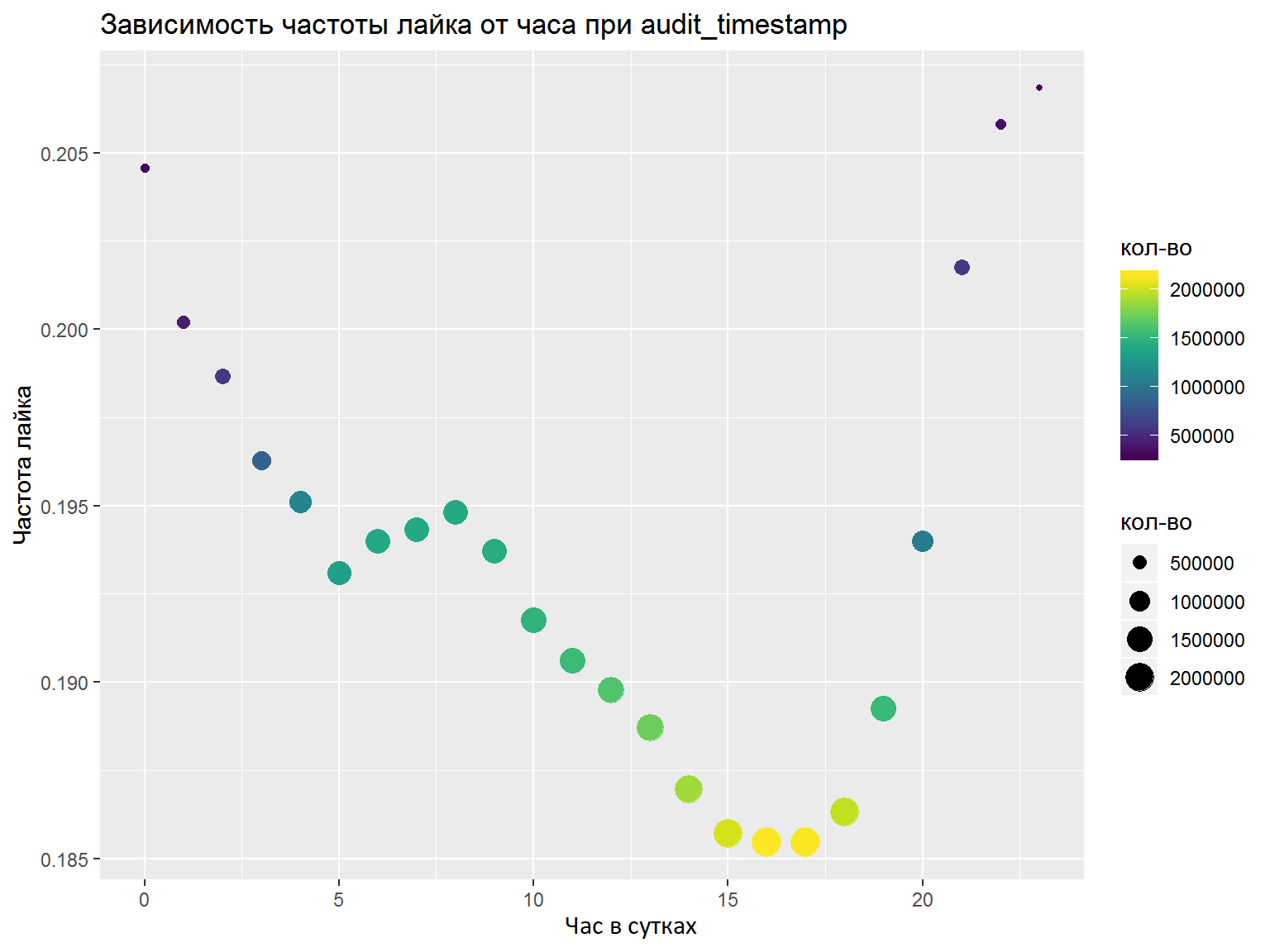
Como resultado da competição, treinei um modelo de keras com convolução de acordo com as palavras, e outro baseado em LSTM e GRU. Lá e lá foram utilizados casamentos FastText pré-treinados para o idioma russo (tentei vários outros casamentos, mas esses funcionaram melhor). Tendo calculado a média das previsões, consegui o 7º lugar final de 76 participantes.
Já após a primeira etapa, um artigo foi publicado por Nikolai Anokhin , que ficou em segundo lugar (ele participou da competição), e sua decisão foi repetida até a próxima etapa, mas ele foi além devido ao mecanismo de atenção ao valor da chave de consulta.
Segunda etapa OK & IDAO
As segundas etapas das competições foram realizadas quase seguidas, então decidi considerá-las juntas.
Primeiro, com a equipe recém-adquirida, acabei no impressionante escritório do Mail.ru, onde nossa tarefa era combinar os modelos das três faixas da primeira etapa - texto, fotos e colaboração. Um pouco mais de 2 dias foram alocados para isso, o que acabou sendo muito pequeno. De fato, só pudemos repetir nossos resultados da primeira etapa, sem receber nenhum ganho da associação. Como resultado, ocupamos o 5º lugar, mas o modelo de texto não pôde ser usado. Observando as decisões de outros participantes, parece que valeu a pena tentar agrupar os textos e adicioná-los ao modelo de colaboração. Um efeito colateral desse estágio foram as novas impressões, conhecidos e a comunicação com os participantes e organizadores legais, bem como a grave falta de sono, que pode ter afetado o resultado do estágio final do IDAO.
A tarefa na fase presencial da final do IDAO 2019 era prever o tempo de espera de um pedido para os motoristas de táxi Yandex no aeroporto. No estágio 2, foram alocadas 3 tarefas = 3 aeroportos. Para cada aeroporto, são fornecidos dados por minuto sobre o número de pedidos de táxi por seis meses. E no mês seguinte e os dados de pedidos por minuto das últimas duas semanas foram dados como dados de teste. Não houve tempo suficiente (1,5 dias), a tarefa era bastante específica, apenas uma pessoa veio da equipe para o concurso - e, como resultado, o local triste estava mais próximo do fim. Das idéias interessantes, houve tentativas de usar dados externos: previsão do tempo, engarrafamentos e estatísticas sobre pedidos de táxi Yandex. Embora os organizadores não tenham dito quais eram os aeroportos, muitos participantes sugeriram que eram Sheremetyevo, Domodedovo e Vnukovo. Embora essa suposição tenha sido refutada após a competição, recursos, por exemplo, dos dados meteorológicos de Moscou melhoraram o resultado na validação e na tabela de classificação.
Conclusão
- Concursos de ML são legais e interessantes! Há um pedido de habilidades em análise de dados e em modelos e técnicas astutos, e apenas o bom senso é bem-vindo.
- O ML já é uma enorme camada de conhecimento que parece crescer exponencialmente. Estabeleci o objetivo de conhecer diferentes áreas (sinais, figuras, tabelas, texto) e já percebi o quanto aprender. Por exemplo, após essas competições, decidi estudar: algoritmos de agrupamento, técnicas avançadas para trabalhar com bibliotecas de aumento de gradiente (em particular, trabalhar com CatBoost na GPU), redes de cápsulas e o mecanismo de atenção ao valor da chave da consulta.
- Nem um único bando! Existem muitos outros concursos em que pelo menos é mais fácil conseguir uma camiseta e há mais chances de outros prêmios.
- Chat! No campo de aprendizado de máquina e análise de dados, já existe uma grande comunidade, existem grupos temáticos em telegrama, folga e pessoas sérias do Mail.ru, Yandex e outras empresas respondem a perguntas e ajudam iniciantes e continuam sua jornada nesse campo de conhecimento.
- Aconselho a todos que estão imbuídos do parágrafo anterior a visitar o datafest - uma grande conferência gratuita em Moscou, que será realizada de 10 a 11 de maio.