Continuamos a falar sobre os projetos da primavera hackathon DevDays, da qual participaram os alunos do programa de mestrado
"Engenharia de Software / Engenharia de Software" .

A propósito, queremos convidar os leitores a se juntarem ao
grupo VK da magistratura . Nele publicaremos as últimas notícias sobre recrutamento e estudo. O vídeo do dia aberto também pode ser encontrado no grupo. Lembramos: o evento será realizado no dia 29 de abril, com detalhes
no site .
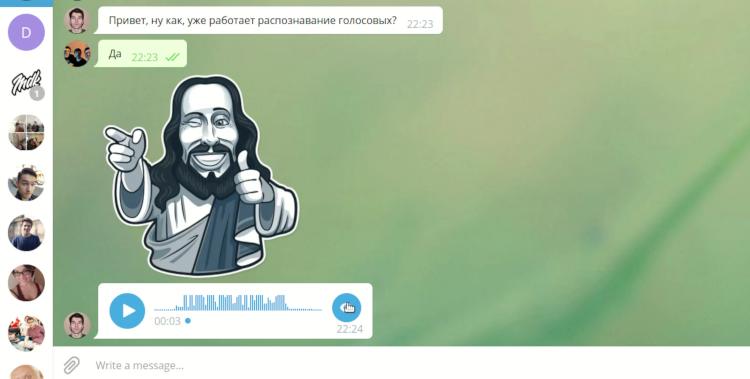
Analisador de Mensagens de Voz do Telegram Desktop
 O autor da ideia
O autor da ideiaKhoroshev Artyom
Composição da equipeKhoroshev Artem - gerente de projetos / desenvolvedor / QA
Eliseev Anton - Analista de Negócios / Especialista em Marketing
Kuklina Maria - UI designer / desenvolvedor
Bakhvalov Pavel - UI designer / desenvolvedor / QA
Do nosso ponto de vista, o Telegram é um mensageiro moderno e conveniente, e sua versão para PC é popular e de código aberto, por isso é possível modificá-lo. O cliente oferece uma funcionalidade bastante rica. Além das mensagens de texto padrão, ele contém chamadas de voz, mensagens de vídeo e mensagens de voz. E é este último que às vezes incomoda seu destinatário. Geralmente, não há como ouvir uma mensagem de voz em um computador ou laptop. Ruído ambiente, falta de fones de ouvido podem interferir ou você não deseja que o conteúdo da mensagem seja ouvido por ninguém. Esses problemas quase nunca ocorrem se você usar telegramas em seu smartphone, porque você pode trazê-lo ao ouvido, ao contrário de um laptop ou PC. Tentamos resolver esse problema.
O objetivo do nosso projeto no DevDays era adicionar a capacidade de converter mensagens de voz recebidas em texto no cliente de desktop Telegram (a seguir, Telegram Desktop).
Todos os análogos no momento são bots para os quais você pode enviar uma mensagem de áudio e, em troca, receber um texto. Isso não é muito conveniente para nós: encaminhar uma mensagem para um bot não é muito conveniente, eu gostaria de ter uma funcionalidade nativa. Além disso, qualquer bot é um terceiro que atua como intermediário entre a API de reconhecimento de fala e o usuário, e isso é pelo menos inseguro.
Como observado anteriormente, o telegrama-desktop tem duas vantagens de peso: leveza e velocidade. E isso não é coincidência, porque está completamente escrito em C ++. E como decidimos adicionar novas funcionalidades diretamente ao cliente, tivemos que desenvolvê-las em C ++.

Havia 4 pessoas em nossa equipe. Inicialmente, dois estavam procurando uma biblioteca adequada para reconhecimento de fala, uma pessoa estudou o código-fonte do Telegram-desktop e outra estava implantando a construção do projeto
Telegram Desktop . Mais tarde, todos estavam ocupados com correções da interface do usuário e depuração.
Parecia que a implementação da funcionalidade pretendida não seria difícil, mas, como sempre, surgiram dificuldades.
A solução para o problema consistiu em duas subtarefas independentes: selecionar os meios apropriados para reconhecimento de fala e implementar a interface do usuário para novas funcionalidades.
Ao escolher uma biblioteca para reconhecimento de voz, tivemos que abandonar imediatamente todas as APIs offline, porque os modelos de idioma ocupam muito espaço. Mas este é apenas um idioma. Ficou claro que você precisaria usar a API online. Mais tarde, constatou-se que os serviços de reconhecimento de fala de gigantes como Google, Yandex e Microsoft não são gratuitos e teremos que nos contentar com um período de teste. Como resultado, o Google Speech-To-Text foi escolhido, pois permite que você obtenha um token para usar o serviço, que durará um ano inteiro.
O segundo problema que encontramos está associado a algumas das desvantagens do C ++ - o zoológico de várias bibliotecas na ausência de um repositório centralizado. Aconteceu que o Telegram Desktop depende de muitas outras bibliotecas de versões específicas. O repositório oficial possui
instruções para a construção do projeto. E também um grande número de questões abertas sobre problemas de construção, por exemplo,
uma e
duas vezes . Todos os problemas acabaram devido ao fato de o script de compilação ter sido escrito para o Ubuntu 14.04, e para construir um telegrama com sucesso no Ubuntu 18.04, tive que fazer alterações.
O próprio Telegram Desktop levará um bom tempo: em um laptop com um Intel Core i5-7200U, o conjunto completo (sinalizador -j 4) com todas as dependências leva cerca de três horas. Destas, são necessárias cerca de 30 minutos para vincular o próprio cliente (mais tarde, na configuração de Depuração, a vinculação leva cerca de 10 minutos), mas a etapa de vinculação deve ser repetida todas as vezes após as alterações.
Apesar dos problemas, conseguimos implementar nossa ideia e atualizar o
script de compilação para o Ubuntu 18.04. A demonstração do trabalho pode ser vista
aqui . Também aplicamos várias animações. Um botão apareceu perto de todas as mensagens de voz, permitindo que você traduza a mensagem em texto. Quando você clica com o botão direito do mouse, pode opcionalmente especificar o idioma que será usado para tradução. O cliente está disponível para download
através do link .
Repositório.Em nossa opinião, obtivemos uma boa funcionalidade de Prova de conceito que seria conveniente para muitos usuários. Esperamos vê-lo em versões futuras do Telegram Desktop.
Suporte expandido a idiomas naturais no IntelliJ IDEA
 O autor da ideia
O autor da ideiaTanques Vladislav
Composição da equipeTanques Vladislav (líder da equipe, trabalhando com o LanguageTool e o IntelliJ IDEA)
Sokolov Nikita (trabalhando com o LanguageTool e criando UI)
Hvorov Alexander (trabalhando com o LanguageTool e otimizando o desempenho)
Sadovnikov Alexander (suporte para analisar linguagens e códigos de marcação)
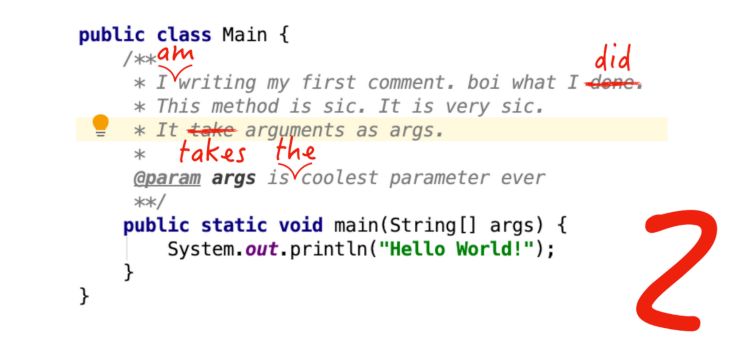
Desenvolvemos um plug-in para o IntelliJ IDEA que verifica vários textos (comentários e documentação, linhas literais no código, texto formatado em Markdown ou marcação XML) quanto à fidelidade gramatical, ortográfica e estilística (em inglês, isso é chamado de revisão).
A idéia do projeto era expandir a verificação ortográfica padrão do IntelliJ IDEA para a escala Grammarly, para criar uma espécie de gramática dentro do IDE.
Você pode ver o que aconteceu
clicando no link .
Bem, abaixo, falaremos mais sobre as capacidades do plugin, bem como sobre as dificuldades que surgiram durante a sua criação.
MotivaçãoExistem muitos produtos projetados para escrever textos em idiomas naturais, mas a documentação e os comentários sobre o código são escritos com mais frequência em ambientes de desenvolvimento. Ao mesmo tempo, os IDEs fazem um excelente trabalho para encontrar erros na escrita de código, mas são pouco adaptados para textos em idiomas naturais. Por isso, é muito fácil cometer erros de gramática, pontuação ou estilo, e o ambiente de desenvolvimento não os aponta. É mais crítico cometer um erro ao escrever a interface do usuário, pois isso afetará não apenas a compreensibilidade do código, mas também os próprios usuários do aplicativo desenvolvido.
Um dos ambientes de desenvolvimento mais populares e desenvolvidos é o IntelliJ IDEA, bem como os IDEs baseados na plataforma IntelliJ. A plataforma IntelliJ já possui um corretor ortográfico integrado, mas não salva nem mesmo os erros gramaticais mais simples. Decidimos integrar um dos sistemas populares de análise de linguagem natural no IntelliJ IDEA.
Implementação
Não nos propusemos a tarefa de criar nosso próprio sistema de verificação de textos, por isso aproveitamos a solução existente. A opção mais adequada foi o
LanguageTool . A licença nos permitiu usá-la livremente para nossos propósitos: é gratuita, escrita em Java e definida em código aberto. Além disso, ele suporta 25 idiomas e vem sendo desenvolvido há mais de quinze anos. Apesar de sua abertura, o LanguageTool é um concorrente sério das soluções de verificação de texto paga, e o fato de poder trabalhar localmente é literalmente o seu principal recurso.
O código do plug-in está no
repositório no GitHub . Todo o projeto foi escrito em Kotlin com uma pequena adição de Java para a interface do usuário. Durante o hackathon, conseguiu implementar suporte para Markdown, JavaDoc, HTML e texto sem formatação. Após o hackathon, uma grande atualização adicionou suporte para XML, literais de strings em Java, Kotlin e Python, além de verificação ortográfica.
DificuldadesMuito rapidamente, percebemos que, se alimentarmos todo o texto toda vez para a verificação do LanguageTool, a interface do IDEA permanecerá com textos mais ou menos sérios, pois a inspeção em si bloqueia o fluxo da interface do usuário. O problema foi resolvido através da verificação do `ProgressManager.checkCancelled` - essa função gera uma exceção se o IDEA considerar que a inspeção deve ser interrompida.
Isso eliminou completamente os travamentos, mas é impossível usá-lo: o texto foi processado por muito tempo. Além disso, no nosso caso, na maioria das vezes uma parte muito pequena do texto muda e eu quero, de alguma forma, armazenar em cache os resultados. Foi o que fizemos. Para não checar tudo o tempo todo, deterministicamente dividimos o texto em pedaços e verificamos apenas os que foram alterados. Como os textos podem ser grandes e não desejarem carregar o cache, armazenamos não os textos em si, mas seus hashes. Isso permitiu que o plug-in funcionasse sem problemas, mesmo em arquivos grandes.
O LanguageTool suporta mais de 25 idiomas, mas dificilmente um usuário precisa de todos. Eu queria dar a oportunidade de baixar bibliotecas para um idioma específico, mediante solicitação (se marcada por uma marca na interface do usuário). Nós até o implementamos, mas ficou muito complicado e não confiável. Em particular, tivemos que carregar o LanguageTool com um novo conjunto de idiomas como um carregador de classes separado e, em seguida, inicializá-lo cuidadosamente. Ao mesmo tempo, todas as bibliotecas estavam no repositório .m2 do usuário e, a cada início, tínhamos que verificar sua integridade. No final, decidimos que, se os usuários tivessem problemas com o tamanho do plug-in, forneceríamos um plug-in separado para vários dos idiomas mais populares.
Após hackathonO hackathon terminou, mas o trabalho no plug-in continuou com uma composição mais restrita. Eu queria dar suporte a linhas, comentários e até construções de linguagem, como nomes de variáveis e classes. Atualmente, isso é suportado apenas para Java, Kotlin e Python, mas esperamos que esta lista aumente. Corrigimos muitos bugs pequenos e nos tornamos mais compatíveis com o corretor ortográfico embutido Idea. Além disso, o suporte a XML e a verificação ortográfica apareceram. Tudo isso pode ser encontrado na segunda versão que publicamos recentemente.
O que vem a seguir?Esse plug-in pode ser útil não apenas para desenvolvedores, mas também para escritores técnicos (geralmente trabalhando, por exemplo, com XML no IDE). Todos os dias eles precisam trabalhar com a linguagem natural, sem ter um assistente na forma de dicas do editor sobre possíveis erros. Nosso plugin fornece essas dicas e o faz com um alto grau de precisão.
Planejamos desenvolver o plugin adicionando novos idiomas e explorando a abordagem geral para organizar a validação de texto. Em um futuro próximo, a implementação de perfis de estilo (conjuntos de regras que definem o guia de estilo do texto, por exemplo, "não escreva, por exemplo, mas escreva a forma completa"), expanda o dicionário e melhore a interface do usuário (em particular, queremos dar ao usuário a capacidade de não apenas ignorar a palavra, mas adicionar ele no dicionário, indicando parte do discurso).