A primeira parte do artigo sobre o básico da PNL pode ser lida
aqui . Hoje, falaremos sobre uma das tarefas mais populares da PNL - NER (Entidade de Entidade Nomeada) - e analisaremos em detalhes a arquitetura das soluções para esse problema.
A tarefa do NER é destacar extensões de entidades no texto (span é um fragmento contínuo de texto). Suponha que exista um texto de notícias e queremos destacar as entidades nele (alguns conjuntos pré-fixados - por exemplo, pessoas, locais, organizações, datas e assim por diante). A tarefa do NER é entender que a parte do texto "
1º de janeiro de 1997 " é a data, "
Kofi Annan " é a pessoa e "
ONU " é a organização.
O que são entidades nomeadas? No primeiro cenário clássico, que foi formulado na conferência do
MUC-6 em 1995, são pessoas, locais e organizações. Desde então, vários pacotes disponíveis apareceram, cada um com seu próprio conjunto de entidades nomeadas. Normalmente, novos tipos de entidade são adicionados a pessoas, locais e organizações. Os mais comuns são numéricos (datas, valores monetários) e entidades diversas (de diversas - outras entidades nomeadas; um exemplo é o iPhone 6).
Por que você precisa resolver o problema do NER
É fácil entender que, mesmo que possamos identificar pessoas, locais e organizações no texto, é improvável que isso cause grande interesse entre os clientes. Embora alguma aplicação prática, é claro, tenha o problema no cenário clássico.
Um dos cenários em que uma solução para o problema na formulação clássica ainda pode ser necessária é a estruturação de dados não estruturados. Suponha que você tenha algum tipo de texto (ou um conjunto de textos) e os dados dele devem ser inseridos em um banco de dados (tabela). As entidades nomeadas clássicas podem corresponder às linhas de uma tabela ou servir como conteúdo de algumas células. Portanto, para preencher corretamente a tabela, você deve primeiro selecionar no texto os dados que inserirá nela (geralmente depois disso há outra etapa - identificar as entidades no texto, quando entendermos que a
ONU e
as Nações Unidas abrangem ”Consulte a mesma organização; no entanto, a tarefa de identificação ou vinculação de entidades é outra tarefa, e não falaremos sobre isso em detalhes neste post).
No entanto, existem várias razões pelas quais o NER é uma das tarefas mais populares da PNL.
Primeiro, extrair entidades nomeadas é um passo em direção à "compreensão" do texto. Isso pode ter valor independente e ajudar a resolver melhor outras tarefas da PNL.
Portanto, se soubermos onde as entidades estão destacadas no texto, podemos encontrar fragmentos do texto que são importantes para alguma tarefa. Por exemplo, podemos selecionar apenas os parágrafos em que são encontradas entidades de um determinado tipo e, em seguida, trabalhar apenas com elas.
Suponha que você receba uma carta, e seria bom fazer um trecho apenas daquela parte em que houver algo útil, e não apenas "
Olá, Ivan Petrovich ". Se você pode distinguir entidades nomeadas, pode tornar o snippet inteligente, mostrando a parte da carta onde estão as entidades de nosso interesse (e não apenas mostrando a primeira frase da carta, como costuma ser feito). Ou você pode simplesmente destacar no texto as partes necessárias da carta (ou, diretamente, as entidades que são importantes para nós) para a conveniência dos analistas.
Além disso, as entidades são colocações rígidas e confiáveis; sua seleção pode ser importante para muitas tarefas. Suponha que você tenha um nome para uma entidade nomeada e, seja o que for, provavelmente é contínuo, e todas as ações com ela precisam ser executadas como em um único bloco. Por exemplo, traduza o nome de uma entidade para o nome de uma entidade. Você deseja traduzir
"Pyaterochka Shop" para o francês em uma única peça e não dividir em vários fragmentos que não são relacionados um ao outro. A capacidade de detectar colocações também é útil para muitas outras tarefas - por exemplo, para análise sintática.
Sem resolver o problema do NER, é difícil imaginar a solução para muitos problemas da PNL, por exemplo, resolver o pronome anáfora ou criar sistemas de resposta a perguntas. O pronome anáfora nos permite entender a qual elemento do texto o pronome se refere. Por exemplo, vamos analisar o texto “
Galopante charmoso em um cavalo branco. A princesa correu para encontrá-lo e o beijou . " Se destacarmos a essência de Persona na palavra "Encantador", a máquina será muito mais fácil de entender que a princesa provavelmente não beijou o cavalo, mas o príncipe de Encanto.
Agora, damos um exemplo de como a alocação de entidades nomeadas pode ajudar na construção de sistemas de perguntas e respostas. Se você fizer a pergunta "
Quem desempenhou o papel de Darth Vader no filme" O Império Contra-Ataca " " em seu mecanismo de busca favorito "", com uma alta probabilidade de obter a resposta certa. Isso é feito apenas isolando as entidades nomeadas: selecionamos as entidades (filme, papel etc.), entendemos o que nos é pedido e, em seguida, procuramos a resposta no banco de dados.
Provavelmente a consideração mais importante devido à qual a tarefa NER é tão popular: a declaração do problema é muito flexível. Em outras palavras, ninguém nos obriga a destacar locais, pessoas e organizações. Podemos selecionar qualquer parte contínua do texto que precisarmos que seja um pouco diferente do restante do texto. Como resultado, você pode escolher seu próprio conjunto de entidades para uma tarefa prática específica vinda do cliente, marcar o corpo dos textos com esse conjunto e treinar o modelo. Esse cenário é onipresente e isso faz do NER uma das tarefas de PNL mais frequentemente executadas no setor.
Vou dar alguns exemplos de casos de clientes específicos, cuja solução eu participei.
Aqui está o primeiro: permita que você tenha um conjunto de faturas (transferências de dinheiro). Cada fatura possui uma descrição em texto, que contém as informações necessárias sobre a transferência (quem, quem, quando, o que e por que motivo foi enviado). Por exemplo, a empresa X transferiu US $ 10 para a empresa Y nessa e naquela data para tal e tal. O texto é bastante formal, mas escrito em linguagem viva. Os bancos treinaram pessoas especialmente treinadas que leem este texto e, em seguida, inserem as informações nele contidas em um banco de dados.
Podemos selecionar um conjunto de entidades que correspondem às colunas da tabela no banco de dados (nomes da empresa, quantidade de transferência, data, tipo de transferência etc.) e aprender como selecioná-las automaticamente. Depois disso, resta apenas inserir as entidades selecionadas na tabela, e as pessoas que leram anteriormente os textos e inseriram as informações no banco de dados poderão executar tarefas mais importantes e úteis.
O segundo caso de usuário é este: você precisa analisar cartas com pedidos de lojas on-line. Para fazer isso, você precisa saber o número do pedido (para que todas as letras relacionadas a esse pedido possam ser marcadas ou colocadas em uma pasta separada), além de outras informações úteis - o nome da loja, a lista de mercadorias encomendadas, o valor do cheque, etc. Tudo isso - números de pedidos, nomes de lojas etc. - podem ser considerados entidades nomeadas e também é fácil aprender a diferenciá-las usando os métodos que iremos analisar agora.
Se o NER é tão útil, por que não é usado em todos os lugares?
Por que a tarefa do NER nem sempre é resolvida e os clientes comerciais ainda estão dispostos a não pagar o menor dinheiro pela sua solução? Parece que tudo é simples: entender qual pedaço de texto destacar e destacá-lo.
Mas na vida tudo não é tão fácil, surgem várias dificuldades.
A complexidade clássica que nos impede de resolver uma variedade de problemas de PNL é todo tipo de ambiguidade na linguagem. Por exemplo, palavras polissemânticas e homônimos (veja exemplos na
parte 1 ). Existe um tipo separado de homonímia que está diretamente relacionado à tarefa NER - entidades completamente diferentes podem ser chamadas da mesma palavra. Por exemplo, vamos ter a palavra "
Washington ". O que é isso Pessoa, cidade, estado, nome da loja, nome do cachorro, objeto, alguma outra coisa? Para destacar esta seção do texto como uma entidade específica, é preciso levar muito em conta - o contexto local (sobre o que era o texto anterior), o contexto global (conhecimento sobre o mundo). Uma pessoa leva tudo isso em consideração, mas não é fácil ensinar uma máquina a fazer isso.
A segunda dificuldade é técnica, mas não a subestime. Não importa como você defina a essência, provavelmente haverá alguns casos limitados e difíceis - quando você precisar realçar a essência, quando não precisar o que incluir no período da entidade e o que não, etc. (é claro, se a nossa essência for não algo levemente variável, como um e-mail; no entanto, você geralmente pode distinguir essas entidades triviais por métodos triviais - escreva uma expressão regular e não pense em nenhum tipo de aprendizado de máquina).
Suponha, por exemplo, que desejemos destacar os nomes das lojas.
No texto “A
loja de detectores de metais profissionais dá as boas-vindas a você ”, quase certamente queremos incluir a palavra “loja” em nossa essência - isso é claramente parte do nome.
Outro exemplo é "
Você é recebido pela Volkhonka Prestige, sua loja de marca favorita a preços acessíveis ". Provavelmente, a palavra "loja" não deve ser incluída na anotação - isso claramente não faz parte do nome, mas simplesmente sua descrição. Além disso, se você incluir essa palavra no nome, também deverá incluir as palavras “- sua favorita” e isso talvez eu não queira fazer.
O terceiro exemplo:
"A loja de animais de estimação de Nemo escreve para você "
. Não está claro se a "loja de animais" faz parte do nome ou não. Neste exemplo, parece que qualquer escolha será adequada. No entanto, é importante que precisamos fazer essa escolha e corrigi-la nas instruções dos marcadores, para que em todos os textos esses exemplos sejam marcados igualmente (se isso não for feito, o aprendizado de máquina inevitavelmente começará a cometer erros devido a contradições na marcação).
Existem muitos exemplos limítrofes e, se queremos que a marcação seja consistente, todos eles precisam ser incluídos nas instruções dos marcadores. Mesmo que os exemplos sejam simples, eles precisam ser levados em consideração e calculados, e isso tornará a instrução maior e mais complicada.
Bem, quanto mais complicadas forem as instruções, você precisará de marcadores mais qualificados. Uma coisa é quando o escriba precisa determinar se a letra é o texto da ordem ou não (embora haja sutilezas e casos de fronteira aqui), e outra coisa quando o escriba precisa ler as instruções de 50 páginas, encontrar entidades específicas, entender o que incluir em anotação e o que não.
Os marcadores qualificados são caros e geralmente não funcionam muito rapidamente. Você gastará o dinheiro com certeza, mas não é um fato que você obtenha a marcação perfeita, porque se as instruções forem complexas, mesmo uma pessoa qualificada pode cometer um erro e entender algo errado. Para combater isso, várias marcações do mesmo texto por pessoas diferentes são usadas, o que aumenta ainda mais o preço da marcação e o tempo para o qual é preparado. Evitar esse processo ou até mesmo reduzi-lo seriamente não funcionará: para aprender, você precisa ter um conjunto de treinamento de alta qualidade e tamanhos razoáveis.
Essas são as duas principais razões pelas quais o NER ainda não conquistou o mundo e por que as macieiras ainda não crescem em Marte.
Como entender se o problema do NER foi resolvido de maneira qualitativa
Vou falar um pouco sobre as métricas que as pessoas usam para avaliar a qualidade de sua solução para o problema de NER e sobre casos padrão.
A principal métrica para a nossa tarefa é uma f-medida rigorosa. Explique o que é isso.
Vamos fazer uma marcação de teste (o resultado do trabalho do nosso sistema) e um padrão (marcação correta dos mesmos textos). Então, podemos contar duas métricas - precisão e integridade. Precisão é a fração de verdadeiras entidades positivas (ou seja, entidades selecionadas por nós no texto, que também estão presentes no padrão), em relação a todas as entidades selecionadas pelo nosso sistema. E integridade é a fração de verdadeiras entidades positivas em relação a todas as entidades presentes no padrão. Um exemplo de um classificador muito preciso, mas incompleto, é um classificador que seleciona um objeto correto no texto e nada mais. Um exemplo de um classificador muito completo, mas geralmente impreciso, é um classificador que seleciona uma entidade em qualquer segmento do texto (assim, além de todas as entidades padrão, nosso classificador aloca uma quantidade enorme de lixo).
A medida F é a média harmônica de precisão e integridade, uma métrica padrão.
Conforme descrito na seção anterior, a criação de marcação é cara. Portanto, não há muitos edifícios acessíveis com uma marcação.
Existe alguma variedade para o idioma inglês - há conferências populares nas quais as pessoas competem na solução do problema NER (e a marcação é criada para as competições). Exemplos de tais conferências nas quais seus corpos com entidades nomeadas foram criadas são MUC, TAC, CoNLL. Todos esses casos consistem quase exclusivamente em textos de notícias.
O corpo principal no qual a qualidade da solução do problema NER é avaliada é o caso CoNLL 2003 (aqui está um
link para o caso em si , aqui está
um artigo sobre ele ). Existem aproximadamente 300 mil tokens e até 10 mil entidades. Agora, os sistemas SOTA (estado da arte - ou seja, os melhores resultados no momento) mostram neste caso uma f-medida da ordem de 0,93.
Para o idioma russo, tudo é muito pior. Existe um órgão público (
FactRuEval 2016 , aqui está
um artigo , aqui está
um artigo sobre Habré ), e é muito pequeno - existem apenas 50 mil fichas. Nesse caso, o caso é bastante específico. Em particular, a essência bastante controversa do LocOrg (localização em um contexto organizacional) destaca-se no caso, que é confundido com organizações e locais, como resultado do qual a qualidade da seleção deste último é mais baixa do que poderia ser.
Como resolver o problema do NER
Redução do problema NER ao problema de classificação
Apesar do fato de as entidades serem geralmente detalhadas, a tarefa NER geralmente se resume ao problema de classificação no nível do token, ou seja, cada token pertence a uma das várias classes possíveis. Existem várias maneiras padrão de fazer isso, mas a mais comum é chamada de esquema BIOES. O esquema é adicionar algum prefixo ao rótulo da entidade (por exemplo, PER para pessoas ou ORG para organizações), o que indica a posição do token no período da entidade. Mais detalhes:
B - desde o início da palavra - o primeiro token no período da entidade, que consiste em mais de 1 palavra.
Eu - pelas palavras de dentro - é isso que está no meio.
E - a partir da palavra que termina, este é o último token da entidade, que consiste em mais de 1 elemento.
S é solteiro. Nós adicionamos esse prefixo se a entidade consistir em uma palavra.
Assim, adicionamos um dos quatro prefixos possíveis a cada tipo de entidade. Se o token não pertencer a nenhuma entidade, será marcado com um rótulo especial, geralmente rotulado como OUT ou O.
Nós damos um exemplo. Vamos ter o texto "
Karl Friedrich Jerome von Munchausen nasceu em Bodenwerder ". Aqui existe uma entidade detalhada - a pessoa "Karl Friedrich Jerome von Münhausen" e uma de uma palavra - a localização "Bodenwerder".
Assim, BIOES é uma maneira de mapear projeções de intervalos ou anotações para o nível do token.
É claro que, com essa marcação, podemos estabelecer de forma inequívoca os limites de todas as anotações de entidade. De fato, sobre cada token, sabemos se é verdade que uma entidade começa com esse token ou termina nele, o que significa se deve terminar a anotação da entidade em um determinado token ou expandi-lo para os próximos tokens.
A grande maioria dos pesquisadores usa esse método (ou suas variações com menos rótulos - BIOE ou BIO), mas possui várias desvantagens significativas. A principal é que o esquema não permite trabalhar com entidades aninhadas ou cruzadas. Por exemplo, a essência da "
Universidade Estadual de Moscou com o nome de M.V. Lomonosov ”é uma organização. Mas o próprio Lomonosov é uma pessoa, e também seria bom perguntar na marcação. Usando o método de marcação descrito acima, nunca podemos transmitir esses dois fatos ao mesmo tempo (porque só podemos fazer uma marca em um token). Consequentemente, o token “Lomonosov” pode ser parte da anotação da organização ou parte da anotação da pessoa, mas nunca as duas ao mesmo tempo.
Outro exemplo de entidades incorporadas: "
Departamento de Lógica Matemática e Teoria dos Algoritmos da Faculdade de Mecânica e Matemática da Universidade Estadual de Moscou ". Aqui, idealmente, eu gostaria de distinguir três organizações aninhadas, mas o método de marcação acima permite selecionar 3 entidades separadas ou uma entidade que anote todo o fragmento.
Além da maneira padrão de reduzir a tarefa à classificação no nível do token, também há um formato de dados padrão no qual é conveniente armazenar a marcação para a tarefa NER (assim como para muitas outras tarefas da PNL). Este formato é chamado
CoNLL-U .
A idéia principal do formato é a seguinte: armazenamos os dados na forma de uma tabela, em que uma linha corresponde a um token e as colunas correspondem a um tipo específico de atributos de token (incluindo a própria palavra, a forma da palavra). Em um sentido restrito, o formato CoNLL-U define quais tipos de recursos (ou seja, colunas) são incluídos na tabela - um total de 10 tipos de recursos para cada token. Mas os pesquisadores geralmente consideram o formato de forma mais ampla e incluem os tipos de recursos necessários para uma tarefa e método específicos para resolvê-lo.
Abaixo está um exemplo de dados em um formato semelhante ao CoNLL-U, onde são considerados 6 tipos de atributos: número da sentença atual no texto, forma da palavra (ou seja, a palavra em si), lema (forma da palavra inicial), lema (forma da palavra inicial), tag POS (parte do discurso), morfológica características da palavra e, finalmente, o rótulo da entidade alocada nesse token.

Como você resolveu o problema do NER antes?
A rigor, o problema pode ser resolvido sem o aprendizado de máquina - com a ajuda de sistemas baseados em regras (na versão mais simples - com a ajuda de expressões regulares). Isso parece desatualizado e ineficaz, no entanto, você precisa entender se sua área de assunto é limitada e claramente definida e se a entidade, por si só, não possui muita variabilidade, o problema do NER é resolvido usando métodos baseados em regras com bastante rapidez e eficiência.
, (, ), , .
, ( ), . .
, 2000- SOTA . , .
, — . . . , ( ), 1, 0.
, (POS-), ( — , , ), (. . ), (, ), .
, , :
- “ , ”,
- “ ”,
- “ ”,
- “ ” ( , , “iPhone”).
, , - , — .
, – . , , , – , , , – , , , – . , (“” , “” — ), . , , , — ( , NER 2 — ).
, NER, ,
Nadeau and Sekine (2007), A survey of Named Entity Recognition and Classification . , , , ( - , , , HMM, , , , ), .
(summarized pattern ). NLP. , 2018
(word shape) .
NER ?
NLP almost from scratch
NER
2011 .
SOTA- CoNLL 2003. , . ML , .
NER , , NLP . , , , , . , NER ( , NLP).
, .
, :
- «» (window based approach),
- (sentence based approach).
– , – , .. , .
: , “
The cat sat on the mat ”.
K (, , , , . .). (, , 1 ). Vamos

— , i- j- .
, sentence based approach , , — , . i i-core, core — , ( , , ).
—
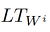
, Lookup Table ( “” ). ,
— , 1, – 0.
em
, . .
( i 1 K) – , .
word2vec ( , word2vec, ) , , word2vec ( ).
, ,
em
.
, sentence based approach (window based ). , (. . “The cat sat on the mat” 6 ). , , , — core.
: 3-5. , , ( ). m f, m — , (. . ), f — .
, — max pooling (. . ), f. , , , core, (max pooling , , ). “ ” , , core.
- ( — HardTanh), softmax d, d — .
, , — ( ), softmax — , core.
CharCNN-BLSTM-CRF
CharCNN-BLSTM-CRF, , SOTA 2016-2018 ( 2018 , NLP ; ). NER
Lample et al (2016) Ma & Hovy (2016) .
, NLP,
.
- . . – , – , — : , . . - .
. , , . — . Lookup- , , .
, .
, . — , , ( , ).
CharCNN ( , CharRNN). , - . - (, 20) — . , — , .
, , , , — ( ). - , .
2 .
– ( CharCNN). , sentence based approach .
, (, 3), . max pooling, 1 . .
– (BLSTM BiGRU; ,
). RNN.
, - . - .
BLSTM BiGRU. i- , RNN. ( RNN), ( RNN). - .
NLP, NLP.
, , NER. - , . .
– softmax d, d — . ( ).
, — . BiRNN, , . , I-PER B-PER I-PER.
— CRF (conditional random fields). , (
), , CRF , .
, CharCNN-BLSTM-CRF, SOTA NER 2018 .
. CharCNN f- 1%, CRF — 1-1.5%, ( multi-task learning,
Wu et al (2018) ). BiRNN — , , ,
.
, NER. , , .
,
NLP Advanced Research Group