Recentemente, no grupo de reconhecimento ABBYY, estamos usando cada vez mais redes neurais em várias tarefas. Muito bem, eles se provaram principalmente para tipos complexos de escrita. Em posts anteriores, falamos sobre como usamos as redes neurais para reconhecer scripts em japonês, chinês e coreano.
 Publique sobre o reconhecimento de caracteres japoneses e chineses Post de reconhecimento de caracteres coreanos
Publique sobre o reconhecimento de caracteres japoneses e chineses Post de reconhecimento de caracteres coreanosNos dois casos, usamos redes neurais para substituir completamente o método de classificação por um único símbolo. Todas as abordagens incluíam muitas redes diferentes e algumas das tarefas incluíram a necessidade de trabalhar adequadamente em imagens que não são símbolos. O modelo nessas situações deve de alguma forma sinalizar que não somos um símbolo. Hoje, falaremos apenas sobre por que isso pode ser necessário em princípio e sobre abordagens que podem ser usadas para alcançar o efeito desejado.
Motivação
Qual é o problema? Por que trabalhar em imagens que não são caracteres separados? Parece que você pode dividir um fragmento de uma string em caracteres, classificá-los todos e coletar o resultado disso, como, por exemplo, na figura abaixo.
Sim, especificamente neste caso, isso realmente pode ser feito. Mas, infelizmente, o mundo real é muito mais complicado e, na prática, ao reconhecer, você precisa lidar com distorções geométricas, borrões, manchas de café e outras dificuldades.
Como resultado, você frequentemente precisa trabalhar com esses fragmentos:
Eu acho que é óbvio para todos qual é o problema. De acordo com essa imagem de um fragmento, não é tão simples dividi-lo inequivocamente em símbolos separados para reconhecê-los individualmente. Temos que apresentar um conjunto de hipóteses sobre onde estão os limites entre os personagens e onde estão os próprios personagens. Para isso, usamos o chamado gráfico de divisão linear (GLD). Na figura acima, este gráfico é mostrado na parte inferior: os segmentos verdes são os arcos da GLD construída, ou seja, as hipóteses sobre onde os símbolos individuais estão localizados.
Assim, algumas das imagens para as quais o módulo de reconhecimento de caracteres individuais é iniciado não são, de fato, caracteres individuais, mas erros de segmentação. E esse mesmo módulo deve sinalizar que na frente dele, provavelmente, não é um símbolo, retornando baixa confiança para todas as opções de reconhecimento. E se isso não acontecer, no final, a opção errada para segmentar esse fragmento por símbolos pode ser escolhida, o que aumentará bastante o número de erros de divisão linear.
Além dos erros de segmentação, o modelo também deve ser resistente a lixo a priori da página. Por exemplo, aqui essas imagens também podem ser enviadas para reconhecer um único caractere:
Se você simplesmente classificar essas imagens em caracteres separados, os resultados da classificação cairão nos resultados do reconhecimento. Além disso, de fato, essas imagens são simplesmente artefatos do algoritmo de binarização, nada deve corresponder a elas no resultado final. Portanto, também para eles, você precisa ser capaz de retornar uma baixa confiança na classificação.
Todas as imagens semelhantes: erros de segmentação, lixo a priori, etc. a seguir seremos chamados exemplos negativos. Imagens de símbolos reais serão chamadas de exemplos positivos.
O problema da abordagem da rede neural
Agora vamos lembrar como uma rede neural normal funciona para reconhecer caracteres individuais. Geralmente, esse é um tipo de camada convolucional e totalmente conectada, com a ajuda da qual é formado o vetor de probabilidades de pertencer a cada classe em particular a partir da imagem de entrada.
Além disso, o número de classes coincide com o tamanho do alfabeto. Durante o treinamento da rede neural, imagens de símbolos reais são exibidas e ensinadas a retornar uma alta probabilidade para a classe correta de símbolos.
E o que acontecerá se uma rede neural for alimentada com erros de segmentação e lixo a priori? De fato, puramente teoricamente, tudo pode acontecer, porque a rede não viu essas imagens no processo de aprendizado. Para algumas imagens, pode ter sorte e a rede retornará uma baixa probabilidade para todas as classes. Mas em alguns casos, a rede pode começar a procurar no lixo na entrada os contornos familiares de um determinado símbolo, por exemplo, o símbolo "A" e reconhecê-lo com uma probabilidade de 0,99.
Na prática, quando trabalhamos, por exemplo, em um modelo de rede neural para escrita japonesa e chinesa, o uso da probabilidade bruta da saída da rede levou ao aparecimento de um grande número de erros de segmentação. E, apesar do modelo simbólico funcionar muito bem com base em imagens, não foi possível integrá-lo ao algoritmo de reconhecimento total.
Alguém pode perguntar: por que exatamente com redes neurais esse problema surge? Por que os classificadores de atributos não funcionaram da mesma maneira, porque também estudaram com base em imagens, o que significa que não houve exemplos negativos no processo de aprendizagem?
A diferença fundamental, na minha opinião, está em como exatamente os sinais se distinguem das imagens de símbolos. No caso do classificador usual, a própria pessoa prescreve como extraí-los, guiada por algum conhecimento do seu dispositivo. No caso de uma rede neural, a extração de recursos também é uma parte treinada do modelo: eles são configurados para que seja possível distinguir da melhor maneira os caracteres de diferentes classes. E, na prática, verifica-se que as características descritas por uma pessoa são mais resistentes a imagens que não são símbolos: é menos provável que sejam iguais às imagens de símbolos reais, o que significa que um valor menor de confiança pode ser retornado a elas.
Aprimorando a estabilidade do modelo com perda central
Porque o problema, de acordo com nossas suspeitas, era como a rede neural seleciona sinais, decidimos tentar melhorar essa parte em particular, ou seja, aprender a destacar alguns sinais "bons". No aprendizado profundo, há uma seção separada dedicada a esse tópico, chamada de "Aprendizado de Representação". Decidimos tentar várias abordagens bem-sucedidas nessa área. A maioria das soluções foi proposta para o treinamento de representações em problemas de reconhecimento facial.
A abordagem descrita no artigo “
Uma abordagem discriminatória de aprendizado de recursos para o reconhecimento facial profundo ” parecia bastante boa. A principal idéia dos autores: adicionar um termo adicional à função de perda, o que reduzirá a distância euclidiana no espaço de feição entre elementos da mesma classe.
Para vários valores do peso desse termo na função de perda geral, é possível obter várias imagens nos espaços de atributo:
Esta figura mostra a distribuição dos elementos de uma amostra de teste em um espaço de atributo bidimensional. O problema de classificar números manuscritos é considerado (amostra MNIST).
Uma das propriedades importantes declaradas pelos autores: um aumento na capacidade de generalização das características obtidas para pessoas que não estavam no conjunto de treinamento. Os rostos de algumas pessoas ainda estavam localizados nas proximidades, e os rostos de pessoas diferentes estavam distantes.
Decidimos verificar se uma propriedade semelhante para a seleção de caracteres é preservada. Nesse caso, eles foram guiados pela seguinte lógica: se no espaço de feição todos os elementos da mesma classe forem agrupados de maneira compacta perto de um ponto, é menos provável que sinais de exemplos negativos sejam localizados perto do mesmo ponto. Portanto, como principal critério de filtragem, usamos a distância euclidiana ao centro estatístico de uma classe em particular.
Para testar a hipótese, realizamos o seguinte experimento: treinamos modelos para reconhecer um pequeno subconjunto de caracteres japoneses de alfabetos silábicos (o chamado kana). Além da amostra de treinamento, também examinamos 3 bases artificiais de exemplos negativos:
- Pares - um conjunto de pares de caracteres europeus
- Cortes - fragmentos de linhas japonesas cortadas em espaços, não caracteres
- Não kana - outros caracteres do alfabeto japonês que não estão relacionados ao subconjunto considerado
Queríamos comparar a abordagem clássica com a função de perda de entropia cruzada e a abordagem com a perda de centro na capacidade de filtrar exemplos negativos. Os critérios de filtragem para exemplos negativos foram diferentes. No caso de perda de entropia cruzada, usamos a resposta de rede da última camada e, no caso de perda de centro, usamos a distância euclidiana ao centro estatístico da classe no espaço de atributo. Nos dois casos, escolhemos o limite das estatísticas correspondentes, no qual não mais de 3% dos exemplos positivos da amostra de teste são eliminados e analisamos a proporção de exemplos negativos de cada banco de dados que é eliminado nesse limite.

Como você pode ver, a abordagem Center Loss realmente faz um trabalho melhor ao filtrar exemplos negativos. Além disso, em ambos os casos, não tivemos imagens de exemplos negativos no processo de aprendizagem. Isso é realmente muito bom, porque, no caso geral, obter uma base representativa de todos os exemplos negativos no problema de OCR não é uma tarefa fácil.
Aplicamos essa abordagem ao problema de reconhecer caracteres japoneses (no segundo nível de um modelo de dois níveis), e o resultado nos agradou: o número de erros de divisão linear foi reduzido significativamente. Embora os erros persistissem, eles já podiam ser classificados por tipos específicos: pares de números ou hieróglifos com um símbolo de pontuação presa. Para esses erros, já era possível formar uma base sintética de exemplos negativos e usá-la no processo de aprendizado. Sobre como isso pode ser feito, e será discutido mais adiante.
Usando a base de exemplos negativos no treinamento
Se você tem alguns exemplos negativos, é tolice não usá-lo no processo de aprendizagem. Mas vamos pensar em como isso pode ser feito.
Primeiro, considere o esquema mais simples: agrupamos todos os exemplos negativos em uma classe separada e adicionamos outro neurônio à camada de saída correspondente a essa classe. Agora, na saída, temos uma distribuição de probabilidade para a classe
N + 1 . E ensinamos a isso a perda entre entropia usual.
O critério de que o exemplo é negativo pode ser considerado o valor da nova resposta de rede correspondente. Mas, às vezes, caracteres reais de qualidade não muito alta podem ser classificados como exemplos negativos. É possível tornar a transição entre exemplos positivos e negativos mais suave?
Na verdade, você pode tentar não aumentar o número total de saídas, mas simplesmente fazer com que o modelo, ao aprender, retorne respostas baixas para todas as classes ao aplicar exemplos negativos à entrada. Para fazer isso, não podemos adicionar explicitamente a saída
N + 1 ao modelo, mas simplesmente adicionar o valor de
–max das respostas de todas as outras classes ao elemento
N + 1 . Então, ao aplicar exemplos negativos à entrada, a rede tentará fazer o máximo possível, o que significa que a resposta máxima tentará fazer o mínimo possível.
Exatamente esse esquema foi aplicado no primeiro nível de um modelo de dois níveis para os japoneses em combinação com a abordagem de perda central no segundo nível. Assim, alguns dos exemplos negativos foram filtrados no primeiro nível e outros no segundo. Em conjunto, já conseguimos obter uma solução pronta para ser incorporada no algoritmo de reconhecimento geral.
Em geral, pode-se perguntar: como usar a base de exemplos negativos na abordagem com Center Loss? Acontece que, de alguma forma, precisamos adiar os exemplos negativos que estão localizados próximos aos centros estatísticos das classes no espaço de atributo. Como colocar essa lógica na função de perda?
Vamos
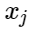
- sinais de exemplos negativos, e
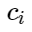
- centros de aulas. Em seguida, podemos considerar a seguinte adição para a função de perda:
Aqui
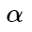
- uma certa lacuna permitida entre o centro e os exemplos negativos, dentro dos quais uma penalidade é aplicada a exemplos negativos.
A combinação do Center Loss com o aditivo descrito acima, aplicamos com sucesso, por exemplo, alguns classificadores individuais na tarefa de reconhecer caracteres coreanos.
Conclusões
Em geral, todas as abordagens para filtrar os chamados "exemplos negativos" descritos acima podem ser aplicadas a qualquer problema de classificação quando você tem uma classe implicitamente altamente desequilibrada em relação ao restante, sem uma boa base de representantes, que, no entanto, precisa ser considerada de alguma forma . O OCR é apenas uma tarefa específica na qual esse problema é mais agudo.
Naturalmente, todos esses problemas surgem apenas ao usar redes neurais como modelo principal para o reconhecimento de caracteres individuais. Ao usar o reconhecimento de linha de ponta a ponta como um modelo separado, esse problema não ocorre.
Grupo de Novas Tecnologias OCR