Antecedentes
Nos últimos dois anos, participei de um grande número de entrevistas. Em cada uma delas, perguntei aos recorrentes sobre o princípio da responsabilidade exclusiva (adiante designado SRP). E a maioria das pessoas não sabe nada sobre o princípio. E mesmo daqueles que sabiam ler a definição, quase ninguém sabia dizer como eles usam esse princípio em seu trabalho. Eles não podiam dizer como o SRP afeta o código que eles escrevem ou a revisão de código dos colegas. Alguns deles também tiveram a idéia errada de que o SRP, como todo o SOLID, é relevante apenas para a programação orientada a objetos. Além disso, muitas vezes as pessoas não conseguiam identificar casos óbvios de violação desse princípio, simplesmente porque o código foi escrito no estilo recomendado pela estrutura conhecida.
Redux é um excelente exemplo de uma estrutura cuja diretriz viola o SRP.
Assuntos SRP
Quero começar com o valor desse princípio, com os benefícios que ele traz. E também quero observar que o princípio se aplica não apenas ao POO, mas também à programação procedural, funcional e até declarativa. O HTML, como representante deste último, pode e deve ser decomposto, especialmente agora quando é controlado por estruturas de interface do usuário, como React ou Angular. Além disso, o princípio se aplica a outras áreas de engenharia. E não apenas a engenharia, havia uma expressão em assuntos militares: “dividir e conquistar”, que em geral é a personificação do mesmo princípio. A complexidade mata, divide-a em partes e você ganha.
Em relação a outras áreas de engenharia, aqui, no hub, havia um artigo interessante sobre como as aeronaves desenvolvidas falharam nos motores, não mudaram para reverter ao comando do piloto. O problema era que eles interpretaram mal o estado do chassi. Em vez de confiar nos sistemas que controlam o chassi, o controlador do motor lê diretamente os sensores, interruptores de limite etc. localizados no chassi. Também foi mencionado no artigo que o motor deve passar por uma certificação longa antes mesmo de ser colocado em um protótipo de aeronave. E a violação do SRP nesse caso claramente levou ao fato de que, ao alterar o design do chassi, o código no controlador do motor precisava ser modificado e certificado novamente. Pior ainda, uma violação desse princípio quase valia o avião e a vida do piloto. Felizmente, nossa programação diária não ameaça essas conseqüências; no entanto, você ainda não deve negligenciar os princípios de escrever um bom código. E aqui está o porquê:
- A decomposição do código reduz sua complexidade. Por exemplo, se resolver um problema exigir que você escreva código com uma complexidade ciclomática de quatro, o método responsável por resolver dois desses problemas ao mesmo tempo exigirá código com complexidade 16. Se for dividido em dois métodos, a complexidade total será 8. Claro, isso nem sempre é se resume à quantia em relação ao trabalho, mas a tendência será aproximadamente a mesma.
- O teste de unidade do código decomposto é simplificado e mais eficiente.
- O código decomposto cria menos resistência à mudança. Ao fazer alterações, é menos provável que cometa um erro.
- O código está ficando melhor estruturado. Procurar algo no código organizado em arquivos e pastas é muito mais fácil do que em um grande calçado.
- A separação do código padrão da lógica de negócios leva ao fato de que a geração de código pode ser aplicada em um projeto.
E todos esses sinais andam juntos, são sinais do mesmo código. Você não precisa escolher entre, por exemplo, código bem testado e código bem estruturado.
Definições existentes não funcionam
Uma das definições é: "deve haver apenas um motivo para alterar o código (classe ou função)". O problema com esta definição é que ela entra em conflito com o princípio de abertura / fechamento, o segundo do grupo de princípios do SOLID. Sua definição: "o código deve estar aberto para extensão e fechado para mudança". Uma razão para a mudança versus proibição total da mudança. Se revelarmos mais detalhadamente o que se entende aqui, verifica-se que não há conflito entre os princípios, mas há definitivamente um conflito entre definições difusas.
A segunda definição mais direta é: "o código deve ter apenas uma responsabilidade". O problema com esta definição é que é da natureza humana generalizar tudo.
Por exemplo, existe uma fazenda que cultiva galinhas e, nesse momento, a fazenda tem apenas uma responsabilidade. E então a decisão é tomada para criar patos lá também. Instintivamente, chamaremos isso de avicultura, em vez de admitir que agora existem duas responsabilidades. Adicione ovelhas lá, e agora é uma fazenda de animais. Então, queremos cultivar tomates ou cogumelos lá e criar o seguinte nome ainda mais generalizado. O mesmo se aplica à "única razão" para a mudança. Essa razão pode ser tão generalizada quanto a imaginação é suficiente.
Outro exemplo é a classe de gerente de estação espacial. Ele não faz mais nada, ele apenas gerencia a estação espacial. Como você gosta desta classe com uma responsabilidade?
E, como mencionei o Redux quando o candidato a emprego está familiarizado com essa tecnologia, também faço a pergunta: um redutor de SRP típico viola?
O redutor, lembro-me, inclui a instrução switch, e acontece que cresce para dezenas ou mesmo centenas de casos. E a única responsabilidade do redutor é gerenciar as transições de estado do seu aplicativo. Isto é, literalmente, alguns candidatos responderam. E nenhuma dica poderia tirar essa opinião do chão.
No total, se algum tipo de código parece satisfazer o princípio SRP, mas ao mesmo tempo cheira desagradável - saiba por que isso acontece. Porque a definição de "código deve ter uma responsabilidade" simplesmente não funciona.
Definição mais apropriada
Por tentativa e erro, eu tive uma definição melhor:
A responsabilidade do código não deve ser muito grandeSim, agora você precisa "medir" a responsabilidade de uma classe ou função. E se for muito grande, você precisará dividir essa grande responsabilidade em várias responsabilidades menores. Voltando ao exemplo da fazenda, mesmo a responsabilidade de criar galinhas pode ser muito grande e faz sentido separar, de alguma forma, frangos de corte de galinhas poedeiras, por exemplo.
Mas como medir, como determinar que a responsabilidade desse código é muito grande?
Infelizmente, não tenho métodos matematicamente precisos, apenas empíricos. E, acima de tudo, isso vem com a experiência: os desenvolvedores iniciantes não conseguem decompor o código, os mais avançados são melhores em possuí-lo, embora nem sempre possam descrever por que o fazem e como isso se aplica a teorias como o SRP.
- Complexidade ciclomática métrica. Infelizmente, existem maneiras de mascarar essa métrica, mas se você a coletar, é possível que ela mostre os locais mais vulneráveis em seu aplicativo.
- O tamanho das funções e classes. Uma função de 800 linhas não precisa ser lida para entender que algo está errado com ela.
- Muitas importações. Depois que abri um arquivo no projeto de uma equipe vizinha e vi uma tela inteira de importações, pressionei a página para baixo e, novamente, havia apenas importações na tela. Somente após a segunda impressão, vi o início do código. Você pode dizer que todos os IDEs modernos podem ocultar importações sob o "sinal de mais", mas eu digo que um bom código não precisa ocultar os "cheiros". Além disso, eu precisava reutilizar um pequeno pedaço de código e removi-o deste arquivo para outro, e um quarto ou até um terço das importações foram movidas para trás desse pedaço. Este código claramente não pertence a esse local.
- Testes unitários. Se você ainda tiver dificuldade em determinar a quantidade de responsabilidade, force-se a escrever testes. Se você precisar escrever duas dúzias de testes com o objetivo principal de uma função, sem contar casos limítrofes, etc., será necessária a decomposição.
- O mesmo se aplica a muitas etapas preparatórias no início do teste e verificações no final. A propósito, na Internet, você encontra a afirmação utópica de que os chamados Deve haver apenas uma afirmação no teste. Acredito que qualquer idéia arbitrariamente boa, sendo levada ao absoluto, pode se tornar absurdamente impraticável.
- A lógica de negócios não deve depender diretamente de ferramentas externas. O driver Oracle, rotas Express, é desejável separar tudo isso da lógica de negócios e / ou se esconder atrás das interfaces.
Alguns pontos:
Obviamente, como eu já mencionei, há um outro lado da moeda, e 800 métodos em uma linha podem não ser melhores que um método em 800 linhas, deve haver um equilíbrio em tudo.
A segunda - não abordo a questão de onde colocar esse ou aquele código de acordo com sua responsabilidade. Por exemplo, às vezes os desenvolvedores também têm dificuldades em extrair muita lógica para a camada DAL.
Terceiro, não proponho limites rígidos específicos como "não mais que 50 linhas por função". Essa abordagem envolve apenas uma direção para o desenvolvimento de desenvolvedores e talvez equipes. Ele trabalha para mim, ele deve ganhar dinheiro para os outros.
E a última coisa, se você passar pelo TDD, isso certamente fará com que você decomponha o código muito antes de escrever esses 20 testes com 20 asserções cada.
Separando a lógica de negócios do código padrão
Falando sobre as regras do bom código, você não pode prescindir de exemplos. O primeiro exemplo é sobre a separação do código padrão.
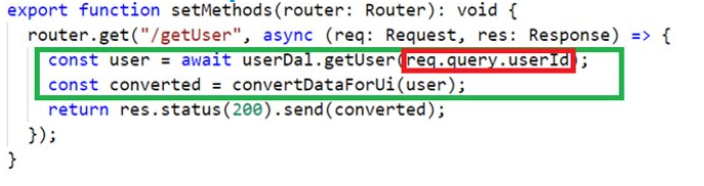
Este exemplo demonstra como o código de back-end geralmente é escrito. As pessoas geralmente escrevem lógica inextricavelmente com o código que indica parâmetros para o servidor Web Express, como URL, método de solicitação etc.
O marcador verde que eu denotei a própria lógica de negócios e o marcador vermelho indicam a incorporação externa do código que interage com os parâmetros da consulta (string de consulta).
Eu sempre compartilho essas duas responsabilidades desta maneira:

Neste exemplo, toda a interação com o Express está em um arquivo separado.
À primeira vista, pode parecer que o segundo exemplo não trouxe melhorias, havia 2 arquivos em vez de um, apareceram linhas adicionais que não existiam antes - o nome da classe e a assinatura do método. E então o que essa separação de código fornece? Primeiro, o "ponto de entrada do aplicativo" não é mais o Express. Agora, esta é uma função normal de Typecript. Ou uma função javascript, seja C #, que escreve WebAPI sobre o quê.
Isso, por sua vez, permite executar várias ações que não estão disponíveis no primeiro exemplo. Por exemplo, você pode escrever testes de comportamento sem precisar gerar o Express, sem usar solicitações http dentro do teste. E mesmo que não seja necessário molhar, substitua o objeto Roteador pelo seu objeto "teste", agora o código do aplicativo pode ser simplesmente chamado diretamente a partir do teste.
Outro recurso interessante fornecido por essa decomposição é que agora você pode escrever um gerador de código que irá analisar o userApiService e usá-lo para gerar código que conecta esse serviço ao Express. Nas minhas publicações futuras, pretendo indicar o seguinte: a geração de código não economizará tempo no processo de escrita do código. Os custos do gerador de código não serão compensados pelo fato de que agora você não precisa copiar este padrão. A geração de código será recompensada pelo fato de o código que ele produzir não precisar de suporte, o que economizará tempo e, mais importante, os nervos dos desenvolvedores a longo prazo.
Dividir e conquistar
Esse método de escrever código existe há muito tempo, eu mesmo não o inventei. Acabei de concluir que é muito conveniente quando se escreve lógica de negócios. E, para isso, criei outro exemplo fictício, mostrando como você pode escrever rápida e facilmente código que é imediatamente bem decomposto e também auto-documentado por métodos de nomeação.
Digamos que você obtenha uma tarefa de um analista de negócios para fazer um método que envie um relatório de funcionário para uma companhia de seguros. Para fazer isso:
- Os dados devem ser retirados do banco de dados
- Converter para o formato desejado
- Envie o relatório resultante
Esses requisitos nem sempre são escritos explicitamente; algumas vezes, essa sequência pode ser implícita ou esclarecida a partir de uma conversa com o analista. No processo de implementação do método, não se apresse em abrir conexões com o banco de dados ou rede; tente traduzir esse algoritmo simples no código "como está". Algo assim:
async function sendEmployeeReportToProvider(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await networkService.sendReport(formatted); }
Com essa abordagem, acaba sendo um código bastante simples, fácil de ler e testar, embora eu acredite que esse código seja trivial e não precise de teste. E era responsabilidade desse método não enviar um relatório, sua responsabilidade era dividir essa tarefa complexa em três subtarefas.
Em seguida, retornamos aos requisitos e descobrimos que o relatório deve consistir em uma seção salarial e uma seção com horas trabalhadas.
function prepareEmployeeReport(reportData){ const salarySection = prepareSalarySection(reportData); const workHoursSection = prepareWorkHoursSection(reportData); return { salarySection, workHoursSection }; }
E assim por diante, continuamos a dividir a tarefa até a implementação de pequenos métodos próximos a triviais.
Interação com o princípio de abertura / fechamento
No começo do artigo, eu disse que as definições dos princípios do SRP e do Aberto-Fechado se contradizem. O primeiro diz que deve haver um motivo para a alteração, o segundo diz que o código deve estar fechado para a alteração. E os próprios princípios, não apenas não se contradizem, pelo contrário, eles trabalham em sinergia entre si. Todos os 5 princípios do SOLID têm como objetivo um bom objetivo - informar ao desenvolvedor qual código é "ruim" e como alterá-lo para que se torne "bom". A ironia - acabei de substituir 5 responsabilidades por mais uma.
Portanto, além do exemplo anterior com o envio do relatório para a companhia de seguros, imagine que um analista de negócios chegue até nós e diga que agora precisamos adicionar uma segunda funcionalidade ao projeto. O mesmo relatório deve ser impresso.
Imagine que existe um desenvolvedor que acredita que o SRP "não se trata de decomposição".
Portanto, esse princípio não lhe indicava a necessidade de decomposição e ele realizou toda a primeira tarefa em uma função. Depois que a tarefa chegou, ele combina as duas responsabilidades em uma, porque eles têm muito em comum e generalizam seu nome. Agora, essa responsabilidade é chamada de "relatório de serviço". A implementação disso se parece com isso:
async function serveEmployeeReportToProvider(reportId, serveMethod){ switch(serveMethod) { case sendToProvider: case print: default: throw; } }
Lembra algum código do seu projeto? Como eu disse, ambas as definições diretas de SRP não funcionam. Eles não transmitem informações ao desenvolvedor que esse código não pode ser gravado. E qual código pode ser escrito. Ainda havia apenas um motivo para o desenvolvedor alterar esse código. Ele simplesmente chamou novamente o motivo anterior, adicionou switch e está calmo. E aqui o princípio do princípio de abrir e fechar aparece, o que diz diretamente que era impossível modificar um arquivo existente. Era necessário escrever código para que, ao adicionar nova funcionalidade, fosse necessário adicionar um novo arquivo e não editar um existente. Ou seja, esse código é ruim do ponto de vista de dois princípios ao mesmo tempo. E se o primeiro não ajudou a vê-lo, o segundo deve ajudar.
E como o método de dividir e conquistar resolve o mesmo problema:
async function printEmployeeReport(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await printService.printReport(formatted); }
Adicione uma nova função. Às vezes os chamo de "função de script" porque eles não carregam implementações, eles determinam a sequência de chamar partes decompostas de nossa responsabilidade. Obviamente, as duas primeiras linhas, as duas primeiras responsabilidades decompostas coincidem com as duas primeiras da função implementada anteriormente. Assim como as duas primeiras etapas de duas tarefas descritas por um analista de negócios coincidem.
Assim, para adicionar nova funcionalidade ao projeto, adicionamos um novo método de script e um novo printService. Arquivos antigos não foram alterados. Ou seja, esse método de escrever código é bom do ponto de vista de dois princípios. E SRP e Abrir-Fechar
Alternativa
Eu também queria mencionar uma maneira alternativa e competitiva de obter um código bem decomposto que se parece com isso - primeiro escrevemos o código "na testa" e depois refatoramos usando várias técnicas, por exemplo, de acordo com o livro de Fowler "Refatoração". Esses métodos me lembraram a abordagem matemática do jogo de xadrez, onde você não entende exatamente o que está fazendo em termos de estratégia, apenas calcula o "peso" da sua posição e tenta maximizá-lo fazendo movimentos. Não gostei dessa abordagem por um pequeno motivo: nomear métodos e variáveis já é difícil e, quando não têm valor comercial, torna-se impossível. Por exemplo, se essas técnicas sugerem que você precisa selecionar 6 linhas idênticas daqui e dali, destacando-as, como chamar esse método? someSixIdenticalLines ()?
Quero fazer uma reserva - não acho que esse método seja ruim, simplesmente não consegui aprender como usá-lo.
Total
Seguindo o princípio, você pode encontrar benefícios.
A definição de "deve haver uma responsabilidade" não funciona.
Existe uma definição melhor e várias características indiretas, as chamadas o código cheira sinalizando a necessidade de se decompor.
A abordagem de “dividir e conquistar” permite que você escreva imediatamente um código bem estruturado e auto-documentado.