Sugiro que você se familiarize com a transcrição do relatório de Alexander Sigachev da Inventos "O processo de desenvolvimento e teste com o Docker + Gitlab CI"
Aqueles que estão apenas começando a implementar o processo de desenvolvimento e teste com base no Docker + Gitlab CI geralmente fazem perguntas básicas. Por onde começar? Como organizar? Como testar?
Este relatório é útil para informar de maneira estruturada sobre o processo de desenvolvimento e teste usando o Docker e o Gitlab CI. 2017 próprio relatório. Penso que, a partir deste relatório, você pode desenhar o básico, metodologia, idéia, experiência de uso.
Quem se importa, por favor, debaixo do gato.
Meu nome é Alexander Sigachev. Eu trabalho na Inventos. Vou contar sobre minha experiência no uso do Docker e como estamos gradualmente implementando-o em projetos na empresa.
Tópico: Processo de desenvolvimento usando o Docker e o Gitlab CI.
Esta é a minha segunda conversa sobre o Docker. No momento do primeiro relatório, usamos o Docker apenas no desenvolvimento em máquinas de desenvolvimento. O número de funcionários que usaram o Docker foi de cerca de 2 a 3 pessoas. Gradualmente, a experiência foi conquistada e avançamos um pouco mais. Link para o nosso primeiro relatório .
O que haverá neste relatório? Compartilharemos nossa experiência sobre qual rake coletamos, que problemas resolvemos. Não era bonito em todos os lugares, mas era permitido seguir em frente.
Nosso lema é: encaixe tudo que nossas mãos alcançarem.
Que problemas resolvemos?
Quando uma empresa possui várias equipes, o programador é um recurso compartilhado. Há estágios em que um programador é retirado de um projeto e entregue por algum tempo a outro projeto.
Para que o programador se aprofunde rapidamente nele, ele precisa fazer o download do código-fonte do projeto e iniciar o ambiente o mais rápido possível, o que lhe permitirá avançar ainda mais na resolução das tarefas desse projeto.
Normalmente, se você começar do zero, a documentação no projeto não será suficiente. Somente os veteranos têm informações sobre como configurar. Os funcionários montam independentemente o local de trabalho em um a dois dias. Para acelerar isso, usamos o Docker.
O próximo motivo é a padronização das configurações no Desenvolvimento. Na minha experiência, os desenvolvedores sempre tomam a iniciativa. Em cada quinto caso, um domínio personalizado é inserido, por exemplo, vasya.dev. Perto está o vizinho Petya, cujo domínio é petya.dev. Eles estão desenvolvendo um site ou algum componente do sistema usando esse nome de domínio.
Quando o sistema cresce e esses nomes de domínio começam a cair na configuração, há um conflito de ambientes de Desenvolvimento e o caminho do site é reescrito.
O mesmo acontece com as configurações do banco de dados. Alguém não se preocupa com a segurança e trabalha com uma senha raiz vazia. Alguém no estágio de instalação do MySQL exigiu uma senha e a senha acabou sendo uma 123. Freqüentemente acontece que a configuração do banco de dados muda constantemente, dependendo da confirmação do desenvolvedor. Alguém corrigiu, alguém não corrigiu a configuração. Havia truques quando lançamos algum tipo de configuração de teste no .gitignore e cada desenvolvedor teve que instalar um banco de dados. Isso complicou o processo inicial. Entre outras coisas, você precisa se lembrar sobre o banco de dados. O banco de dados deve ser inicializado, uma senha deve ser registrada, um usuário deve ser registrado, uma placa deve ser criada e assim por diante.
Outro problema são as diferentes versões das bibliotecas. Muitas vezes acontece que um desenvolvedor trabalha com projetos diferentes. Existe um projeto Legacy iniciado há cinco anos (a partir de 2017 - nota. Ed.). No início, começamos com o MySQL 5.5. Também existem projetos modernos nos quais estamos tentando introduzir versões mais modernas do MySQL, por exemplo, 5.7 ou mais antigas (em 2017 - nota. Ed.)
Qualquer pessoa que trabalhe com o MySQL sabe que essas bibliotecas estão gerando dependências. É bastante problemático executar duas bases juntas. No mínimo, é problemático para clientes antigos se conectarem ao novo banco de dados. Por sua vez, isso causa vários problemas.
O próximo problema é quando o desenvolvedor trabalha na máquina local, ele usa recursos locais, arquivos locais, RAM local. Toda a interação no momento do desenvolvimento da solução para o problema é realizada no âmbito do fato de funcionar em uma máquina. Um exemplo é quando temos servidores back-end na Produção 3, e o desenvolvedor salva os arquivos no diretório raiz e, a partir daí, o nginx leva os arquivos para responder à solicitação. Quando esse código cai em Produção, acontece que o arquivo está presente em um dos três servidores.
Agora, a direção dos microsserviços está se desenvolvendo. Quando dividimos nossos aplicativos grandes em alguns componentes pequenos que interagem entre si. Isso permite selecionar a tecnologia para uma pilha de tarefas específica. Também permite compartilhar o trabalho e a área de responsabilidade entre os desenvolvedores.
Frondend-developer, desenvolvendo em JS, praticamente não afeta o Backend. O desenvolvedor de back-end, por sua vez, desenvolve, no nosso caso, Ruby on Rails e não interfere no Frondend. A interação é realizada usando a API.
Como bônus, com o Docker, pudemos utilizar recursos no teste. Cada projeto, devido à sua especificidade, exigiu determinadas configurações. Fisicamente, era necessário selecionar um servidor virtual e configurá-lo separadamente, ou compartilhar algum tipo de ambiente variável, e os projetos poderiam influenciar um ao outro, dependendo da versão das bibliotecas.

Ferramentas O que usamos?
- Diretamente o próprio Docker. Dockerfile descreve dependências de um aplicativo.
- O Docker-compose é um pacote que reúne alguns de nossos aplicativos Docker.
- GitLab que usamos para armazenar o código fonte.
- Usamos o GitLab-CI para integração de sistemas.

O relatório consiste em duas partes.
A primeira parte abordará como executar o Docker em máquinas de desenvolvimento.
A segunda parte abordará como interagir com o GitLab, como executamos testes e como implementamos o teste.
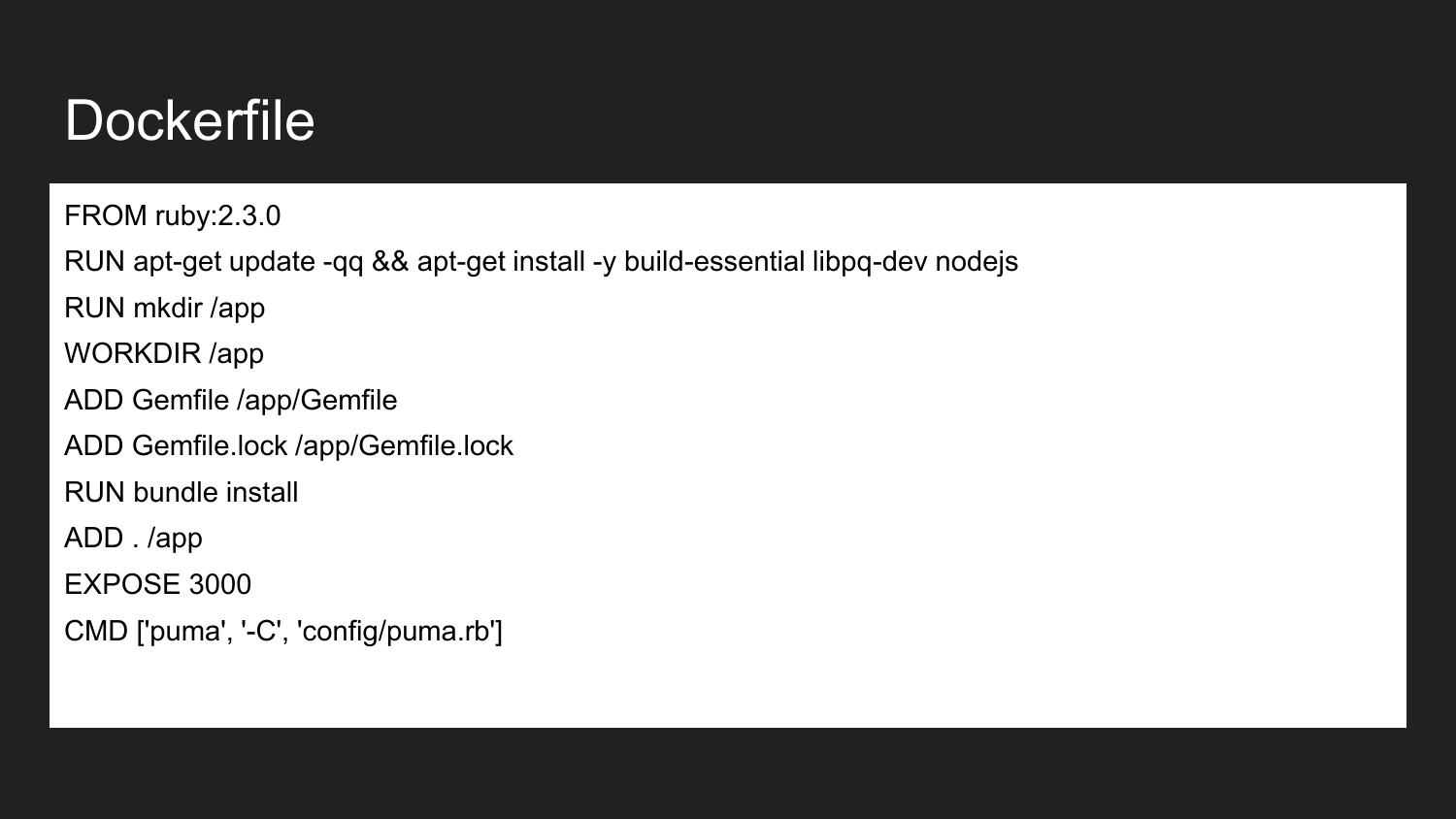
O Docker é uma tecnologia que permite (usando uma abordagem declarativa) descrever os componentes necessários. Este é um exemplo de um Dockerfile. Aqui anunciamos que estamos herdando da imagem oficial do Ruby Docker: 2.3.0. Ele contém o Ruby instalado versão 2.3. Instalamos as bibliotecas de construção necessárias e o NodeJS. Descrevemos que criamos o diretório /app . Atribua o diretório do aplicativo ao diretório de trabalho. Neste diretório, colocamos o Gemfile e Gemfile.lock mínimos necessários. Em seguida, criamos os projetos que instalam essa imagem de dependência. Indicamos que o contêiner estará pronto para escutar na porta externa 3000. O último comando é o comando que inicia diretamente nosso aplicativo. Se executarmos o comando start do projeto, o aplicativo tentará executar e iniciar o comando especificado.

Este é um exemplo mínimo de um arquivo de composição de encaixe. Nesse caso, mostramos que há uma conexão entre os dois contêineres. Isso é diretamente no serviço de banco de dados e no serviço da web. Na maioria dos casos, nossos aplicativos da web exigem algum tipo de banco de dados como back-end para armazenamento de dados. Como usamos o MySQL, o exemplo está no MySQL - mas nada nos impede de usar algum tipo de banco de dados de amigos (PostgreSQL, Redis).
Pegamos a imagem do MySQL 5.7.14 da fonte oficial com o hub Docker inalterado. A imagem responsável por nosso aplicativo da web que coletamos do diretório atual. Ele, durante o primeiro lançamento, coleta uma imagem para nós. Em seguida, lança o comando que executamos aqui. Se voltarmos, veremos que o comando de lançamento através do Puma foi definido. Puma é um serviço escrito em Ruby. No segundo caso, redefinimos. Este comando pode ser arbitrário, dependendo de nossas necessidades ou tarefas.
Também descrevemos o que você precisa para encaminhar a porta em nossa máquina host de 3000 para 3000 porta container. Isso é feito automaticamente usando o iptables e seu próprio mecanismo, diretamente incorporado ao Docker.
O desenvolvedor pode, como antes, aplicar a qualquer endereço IP disponível, por exemplo, 127.0.0.1 endereço IP local ou externo da máquina.
A última linha diz que o contêiner da web depende do contêiner db. Quando chamamos o lançamento do contêiner da web, o docker-compose iniciará o banco de dados para nós. Já no início do banco de dados (de fato, depois de iniciar o contêiner! Isso não garante a prontidão do banco de dados), lançaremos um aplicativo, nosso back-end.
Isso permite evitar erros quando o banco de dados não é gerado e salvar recursos quando paramos o contêiner do banco de dados, liberando os recursos para outros projetos.

O que nos dá o uso do banco de dados de dockerização no projeto. Todos os desenvolvedores corrigimos a versão do MySQL. Isso permite evitar alguns erros que podem ocorrer quando há uma divergência de versões, quando a sintaxe, a configuração e as configurações padrão são alteradas. Isso permite que você especifique um nome de host comum para o banco de dados, login e senha. Afastamo-nos dos nomes e conflitos do zoológico nos arquivos de configuração anteriores.
Podemos usar uma configuração mais ideal para o ambiente de desenvolvimento, que será diferente do padrão. O MySQL é configurado por padrão em máquinas fracas e seu desempenho imediato é muito baixo.

O Docker permite usar o interpretador Python, Ruby, NodeJS, PHP da versão desejada. Nós nos livramos da necessidade de usar algum tipo de gerenciador de versões. Anteriormente, Ruby usava o pacote rpm, que permitia alterar a versão dependendo do projeto. Isso também permite que o contêiner do Docker migre o código sem problemas e faça a versão juntamente com as dependências. Não temos problemas para entender a versão do intérprete e do código. Para atualizar a versão, abaixe o contêiner antigo e levante o novo contêiner. Se algo der errado, podemos abaixar o novo contêiner, elevar o contêiner antigo.
Após a montagem da imagem, os contêineres em Desenvolvimento e Produção serão os mesmos. Isto é especialmente verdade para grandes instalações.
 No Frontend, usamos JavaScipt e NodeJS.
No Frontend, usamos JavaScipt e NodeJS.
Agora temos o projeto mais recente no ReacJS. O desenvolvedor executou todo o contêiner e desenvolveu usando hot-reload.
Em seguida, a tarefa de montar o JavaScipt é iniciada e o código coletado na estática é fornecido através dos recursos de economia do nginx.
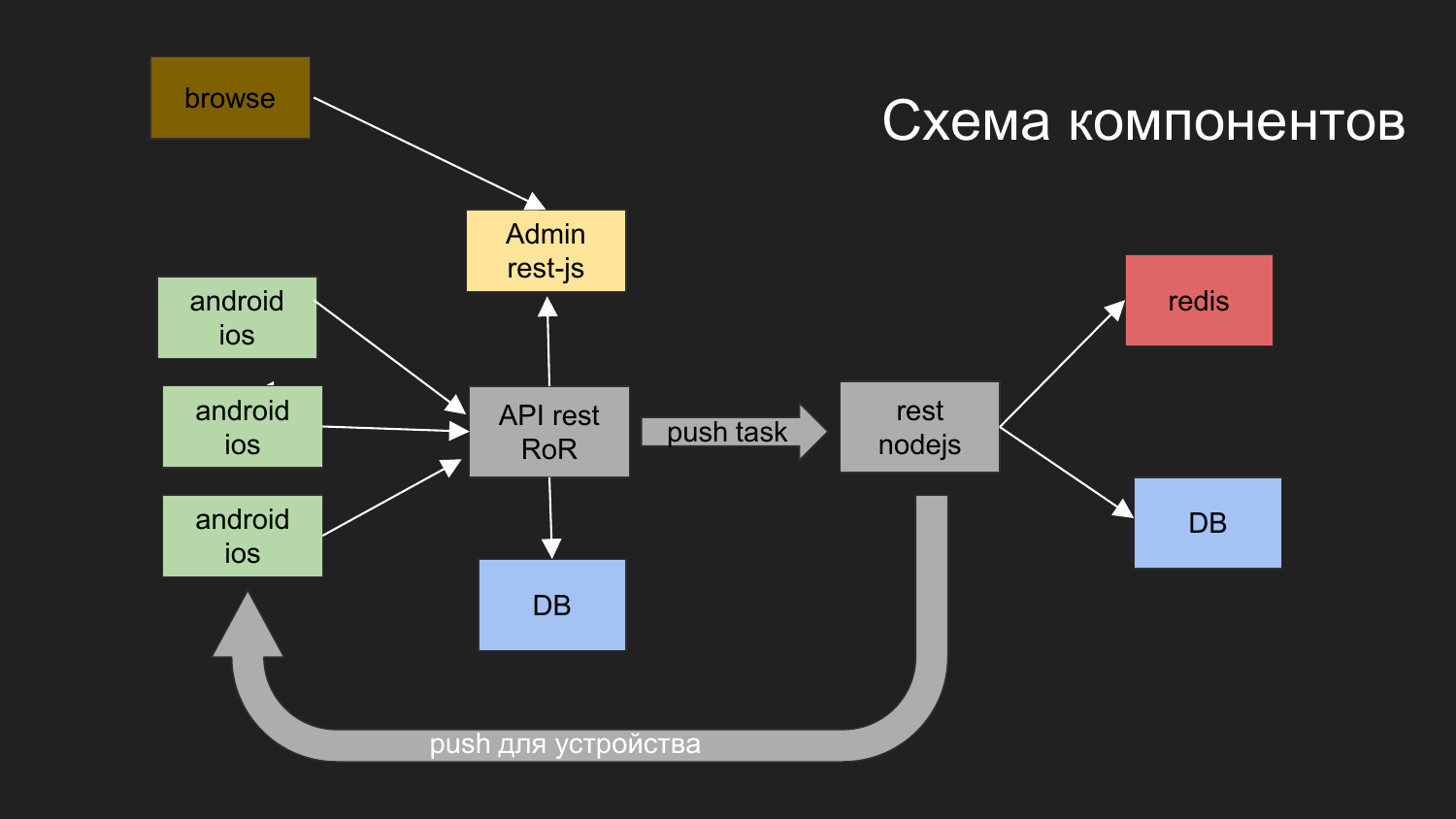
Aqui eu dei um diagrama do nosso último projeto.
Que tarefas você resolveu? Precisamos criar um sistema com o qual os dispositivos móveis interajam. Eles obtêm dados. Uma das opções é enviar notificações por push para este dispositivo.
O que fizemos para isso?
Dividimos em componentes de aplicativos como: a parte administrativa em JS, o back-end, que funciona através da interface REST no Ruby on Rails. O back-end interage com o banco de dados. O resultado gerado é fornecido ao cliente. O administrador com back-end e banco de dados interage via interface REST.
Também precisamos enviar notificações por push. Antes disso, tínhamos um projeto no qual era implementado um mecanismo responsável por entregar notificações às plataformas móveis.
Desenvolvemos esse esquema: o operador do navegador interage com o painel de administração, o painel de administração interage com o back-end, a tarefa é enviar notificações por push.
As notificações por push interagem com outro componente implementado no NodeJS.
As filas estão sendo criadas e o envio de notificações segue seu próprio mecanismo.
Dois bancos de dados são desenhados aqui. No momento, com a ajuda do Docker, usamos 2 bancos de dados independentes, que não estão de forma alguma conectados entre si. Além disso, eles têm uma rede virtual comum e os dados físicos são armazenados em diferentes diretórios na máquina do desenvolvedor.
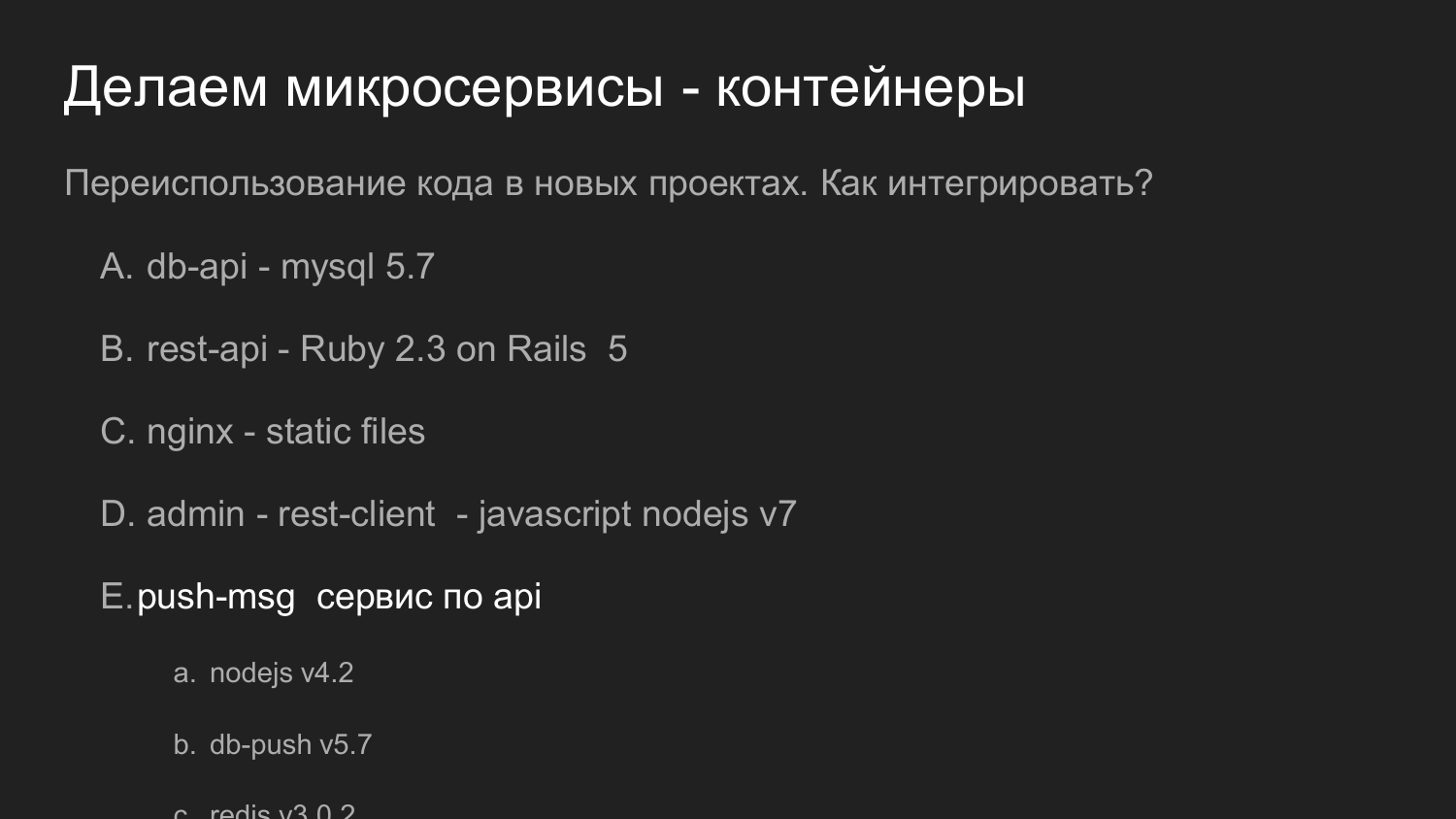
A mesma coisa, mas em números. Reutilizar código é importante aqui.
Se falamos anteriormente sobre a reutilização de código na forma de bibliotecas, neste exemplo, nosso serviço, que responde a notificações por push, é reutilizado como um servidor completo. Ele fornece uma API. E já com o nosso novo desenvolvimento interage com ele.
Naquela época, usamos a versão 4 do NodeJS. Agora (em 2017 - nota. Ed.) Nos desenvolvimentos recentes, usamos a versão 7 do NodeJS. Não há problema em novos componentes para atrair novas versões de bibliotecas.
Se necessário, você pode refatorar e atualizar a versão NodeJS do serviço de notificação por push.
E se podemos manter a compatibilidade da API, podemos substituí-la por outros projetos que foram usados anteriormente.

O que você precisa para adicionar o Docker? Adicione um Dockerfile ao nosso repositório que descreva as dependências necessárias. Neste exemplo, os componentes são divididos por lógica. Este é um conjunto mínimo de desenvolvedor de back-end.
Ao criar um novo projeto, crie um Dockerfile, descreva o ecossistema desejado (Python, Ruby, NodeJS). A janela de encaixe-compor descreve a dependência necessária - o banco de dados. Descrevemos que precisamos de um banco de dados dessa e de tal versão para armazenar os dados em algum lugar.
Usamos um terceiro contêiner separado com nginx para tornar estático. Você pode fazer upload de fotos. O back-end os coloca em um volume pré-preparado, que também é montado em um contêiner com nginx, que fornece estática.
Para armazenar a configuração nginx, mysql, adicionamos a pasta Docker, na qual armazenamos as configurações necessárias. Quando um desenvolvedor cria um repositório git clone em sua máquina, ele já prepara um projeto para o desenvolvimento local. Não se coloca a questão de qual porta ou quais configurações aplicar.

Além disso, temos vários componentes: admin, inform-API, push-Notifications.
Para executar tudo, criamos outro repositório chamado dockerized-app. Atualmente, usamos vários repositórios até cada componente. Eles diferem logicamente - no GitLab parece uma pasta e, na máquina do desenvolvedor, uma pasta para um projeto específico. Um nível abaixo são os componentes que serão combinados.
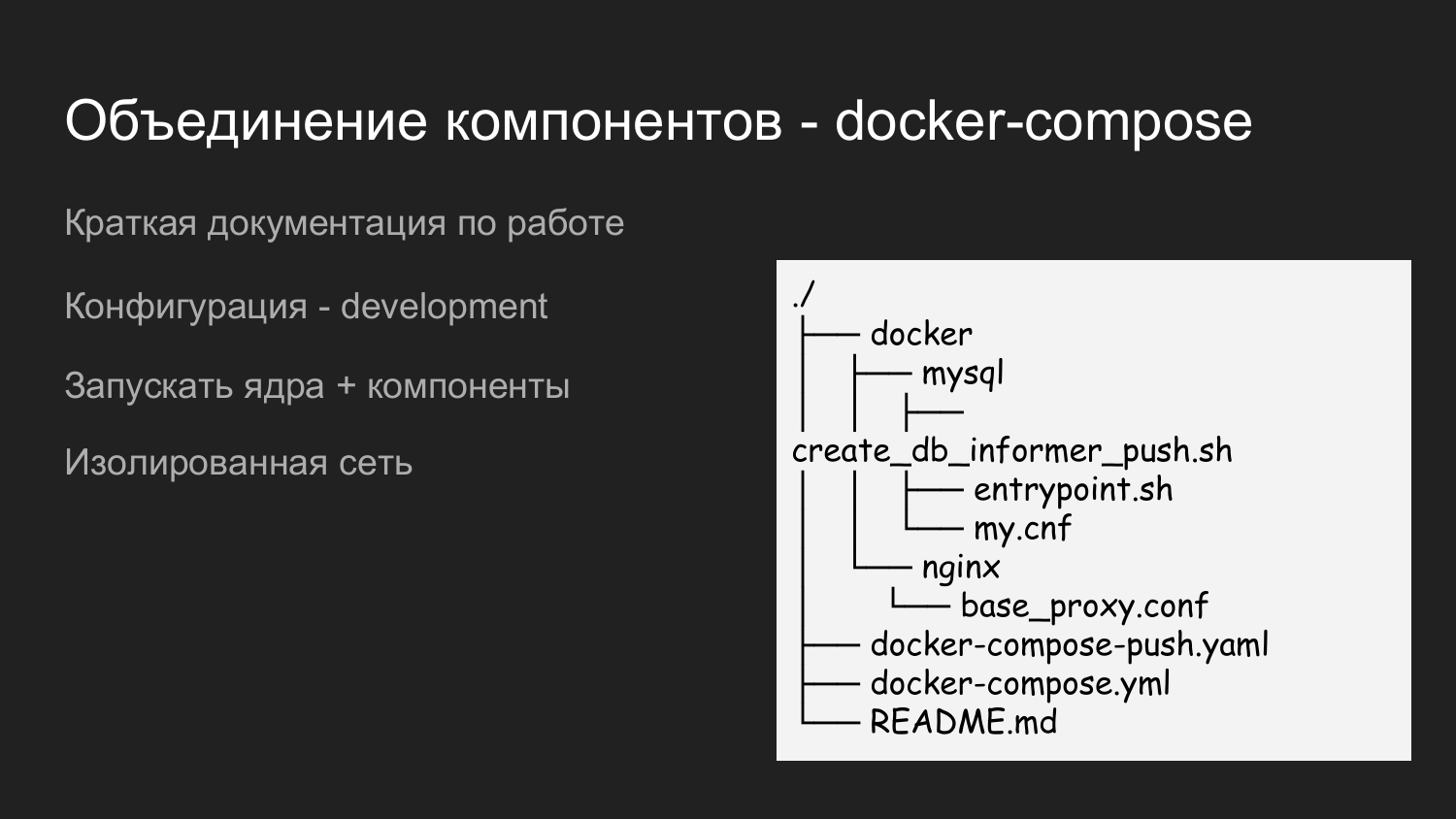
Este é um exemplo apenas do conteúdo do aplicativo dockerized. Também trazemos o catálogo do Docker aqui, no qual preenchemos as configurações necessárias para interações de todos os componentes. Existe o arquivo README.md, que descreve brevemente como iniciar um projeto.
Aqui usamos dois arquivos de composição de encaixe. Isso é feito para poder executar as etapas. Quando um desenvolvedor trabalha com o kernel, ele não precisa de notificações por push, ele apenas inicia o arquivo de docker-compose e, portanto, o recurso é salvo.
Se houver necessidade de integração com notificações por push, o docker-compose.yaml e o docker-compose-push.yaml serão iniciados.
Como o docker-compose.yaml e o docker-compose-push.yaml estão na pasta, uma única rede virtual é criada automaticamente.
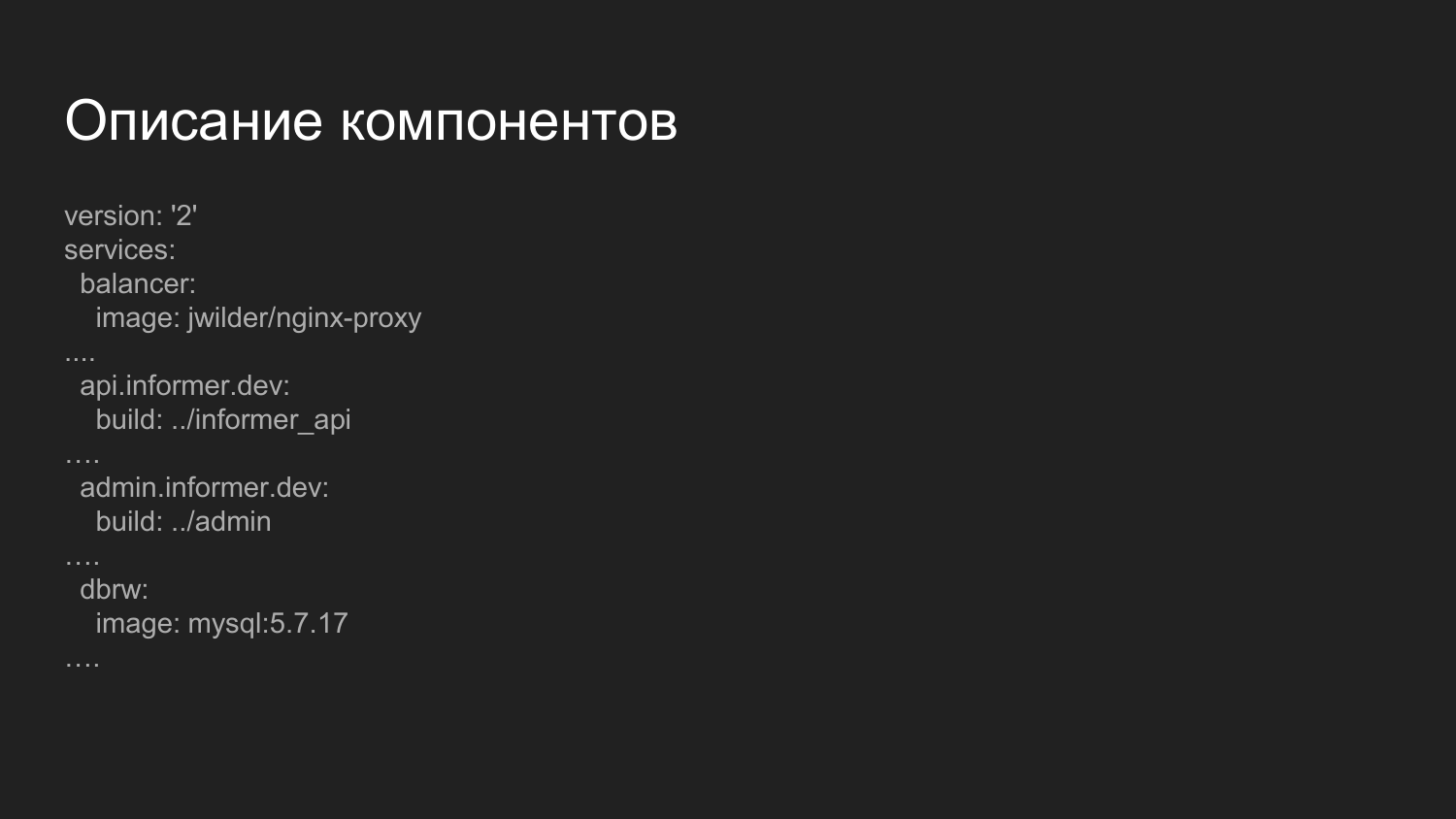
Descrição dos componentes. Este é um arquivo mais avançado que é responsável pela coleta de componentes. O que é notável aqui? Aqui apresentamos o componente balanceador.
Essa é uma imagem pronta do Docker na qual o nginx é iniciado e um aplicativo que escuta o soquete do Docker. Dinâmico, à medida que os contêineres são ativados e desativados, a configuração do nginx será gerada novamente. Distribuímos o manuseio de componentes por nomes de domínio de terceiro nível.
Para o ambiente de desenvolvimento, usamos o domínio .dev - api.informer.dev. Os aplicativos com o domínio .dev estão disponíveis na máquina do desenvolvedor local.
Em seguida, as configurações são transferidas para cada projeto e todos os projetos são lançados juntos ao mesmo tempo.
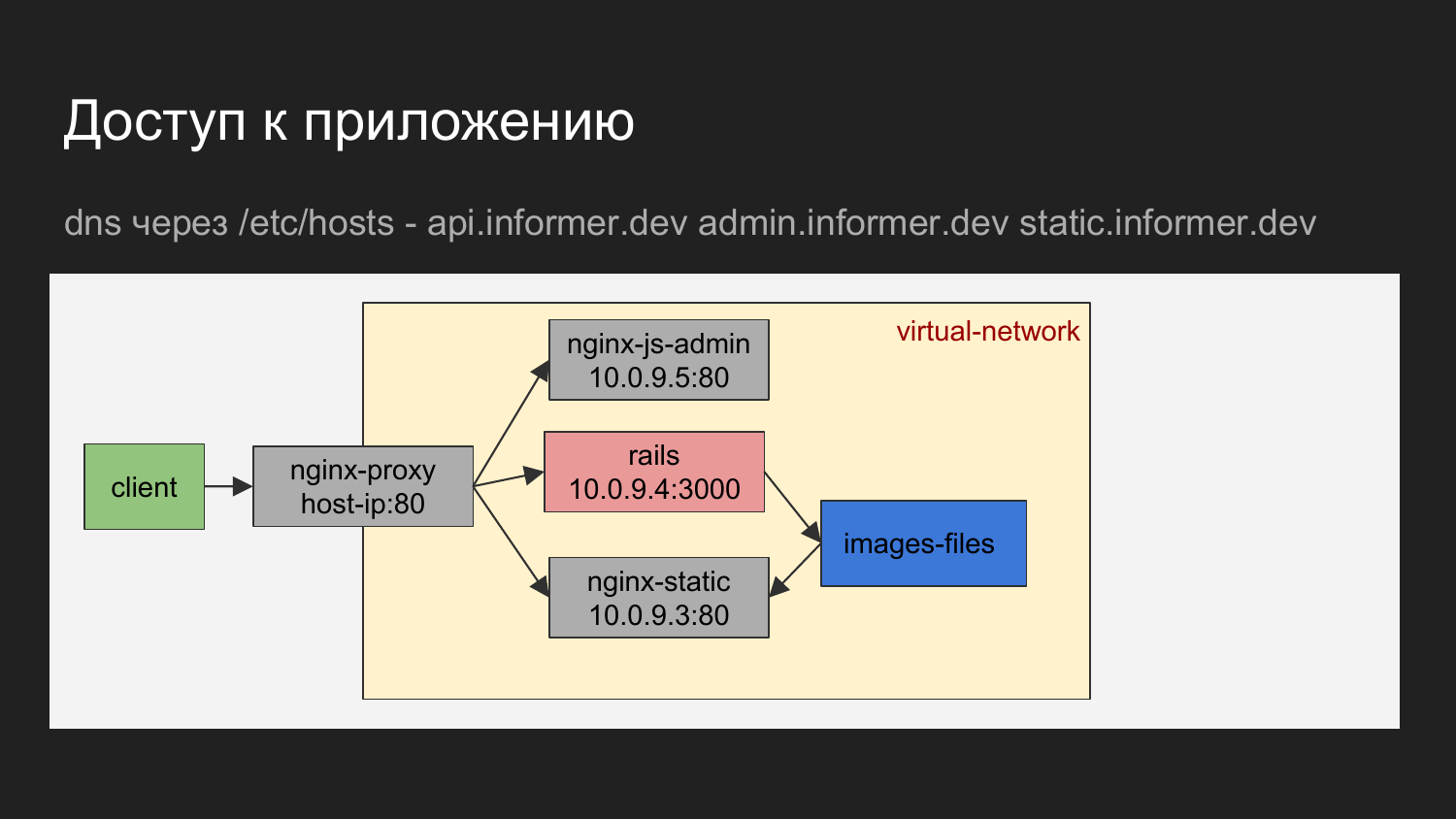
Se representado graficamente, o cliente é o nosso navegador ou alguma ferramenta com a qual realizamos solicitações para o balanceador.
O balanceador de nome de domínio determina qual contêiner acessar.
Pode ser o nginx, que fornece a área de administração do JS. Pode ser o nginx, que fornece a API ou os arquivos estáticos fornecidos ao nginx na forma de carregamento de imagens.
O diagrama mostra que os contêineres estão conectados por uma rede virtual e estão ocultos atrás do proxy.
Na máquina do desenvolvedor, você pode acessar o contêiner sabendo IP, mas basicamente não o usamos. A necessidade de tratamento direto praticamente não surge.

Que exemplo procurar para dockerize o aplicativo? Na minha opinião, um bom exemplo é a imagem oficial do docker para MySQL.
Isso é bastante complicado. Existem muitas versões. Mas sua funcionalidade permite que você cubra muitas necessidades que possam surgir no processo de desenvolvimento adicional. Se você gastar tempo e descobrir como tudo isso interage, acho que você não terá problemas na auto-implementação.
No hub.docker.com, geralmente existem links para o github.com, que fornecem dados brutos diretamente a partir dos quais você pode montar a imagem.
Mais adiante neste repositório está o script docker-endpoint.sh, responsável pela inicialização inicial e pelo processamento adicional do lançamento do aplicativo.
Também neste exemplo, há a possibilidade de configuração usando variáveis de ambiente. Ao definir a variável de ambiente ao iniciar um único contêiner ou via docker-compose, podemos dizer que precisamos definir uma senha vazia para docker on para root no MySQL ou o que desejar.
Existe uma opção para criar uma senha aleatória. Dizemos que precisamos de um usuário, precisamos definir uma senha para o usuário e precisamos criar um banco de dados.
Em nossos projetos, unificamos levemente o Dockerfile, responsável pela inicialização. Lá, corrigimos nossas necessidades para fazer apenas uma extensão dos direitos do usuário que o aplicativo usa. Isso permitiu no futuro simplesmente criar um banco de dados a partir do console do aplicativo. Os aplicativos Ruby têm um comando para criar, modificar e excluir bancos de dados.

Este é um exemplo de como uma versão específica do MySQL se parece no github.com. Você pode abrir o dockerfile e ver como a instalação está acontecendo lá.
script docker-endpoint.sh responsável pelo ponto de entrada. Durante a inicialização, algumas etapas de preparação são necessárias e todas essas ações são executadas apenas no script de inicialização.

Passamos para a segunda parte.
Para armazenar o código fonte, mudamos para o gitlab. Este é um sistema bastante poderoso que possui uma interface visual.
Um dos componentes do Gitlab é o Gitlab CI. Ele permite que você descreva os comandos de acompanhamento que serão usados posteriormente para organizar um sistema de entrega de código ou executar testes automáticos.
Relatório sobre o Gitlab CI 2 https://goo.gl/uohKjI - um relatório do clube Ruby Russia - bastante detalhado e talvez seja do seu interesse.

Agora vamos considerar o que é necessário para ativar o Gitlab CI. Para iniciar o Gitlab CI, basta colocar o arquivo .gitlab-ci.yml na raiz do projeto.
Aqui descrevemos que queremos executar uma sequência de estados, como teste, implantação.
Executamos scripts que chamam diretamente docker-componha a montagem de nosso aplicativo. Este é um exemplo de apenas um back-end.
Em seguida, dizemos que é necessário conduzir migrações para alterar o banco de dados e executar testes.
Se os scripts forem executados corretamente e não retornarem um código de erro, o sistema continuará para o segundo estágio da implantação.
A fase de implantação está atualmente implementada para preparação. Não organizamos uma reinicialização suave.
Nós extinguimos todos os contêineres à força e depois levantamos todos os contêineres, coletados no primeiro estágio durante o teste.
Estamos executando o ambiente variável atual de migração de banco de dados, que foi escrito pelos desenvolvedores.
Há uma observação que aplica isso apenas à ramificação principal.
Ao alterar outros ramos não é executado.
É possível organizar lançamentos em filiais.
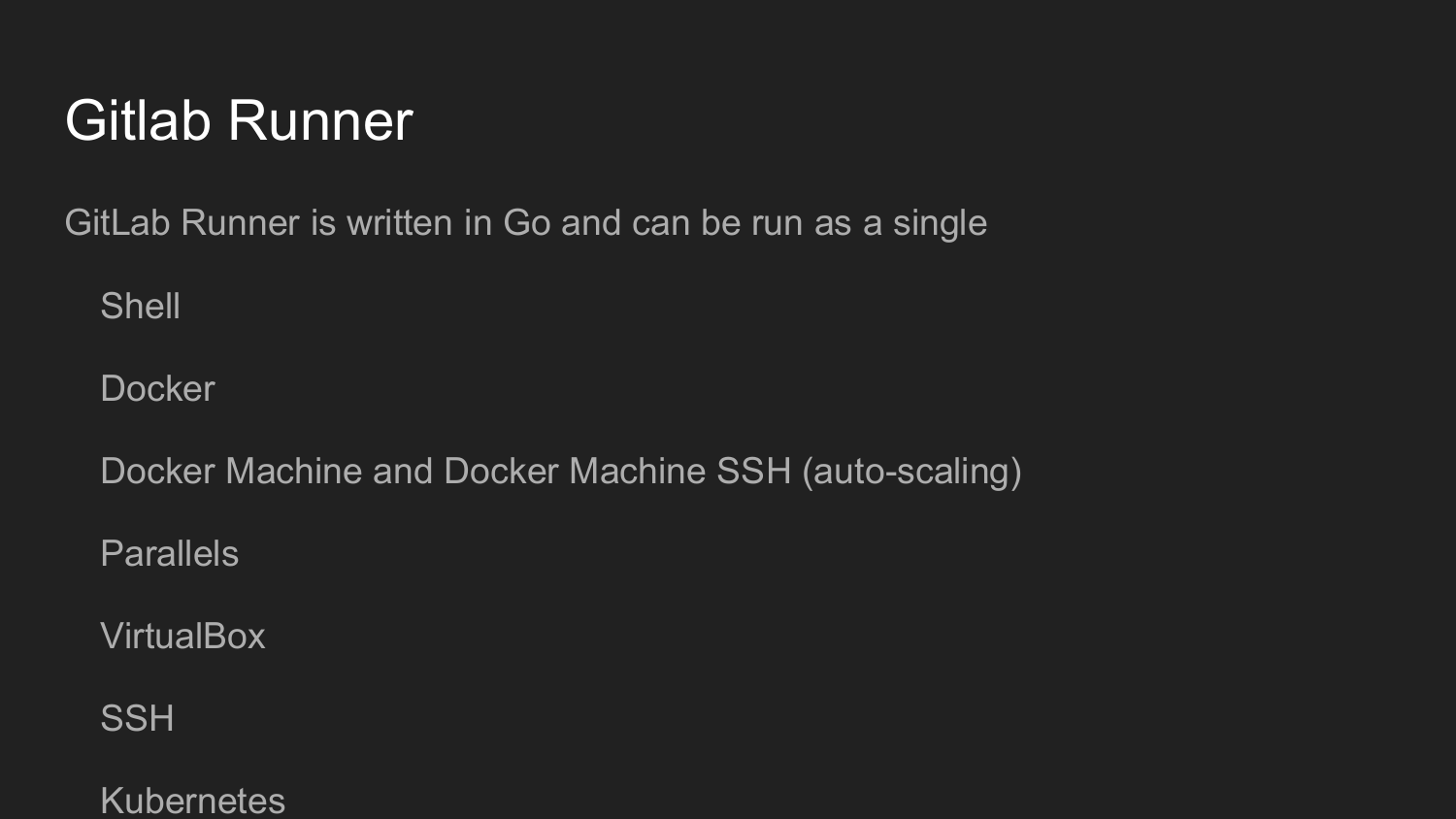
Para organizar ainda mais isso, precisamos instalar o Gitlab Runner.
Este utilitário está escrito em Golang. É um arquivo único, como é habitual no mundo Golang, que não requer nenhuma dependência.
Na inicialização, registramos o Gitlab Runner.
Nós obtemos a chave na interface da web do Gitlab.
Então chamamos o comando init na linha de comando.
Configurar o Gitlab Runner no modo de diálogo (Shell, Docker, VirtualBox, SSH)
O código no Gitlab Runner será executado a cada confirmação, dependendo da configuração .gitlab-ci.yml.
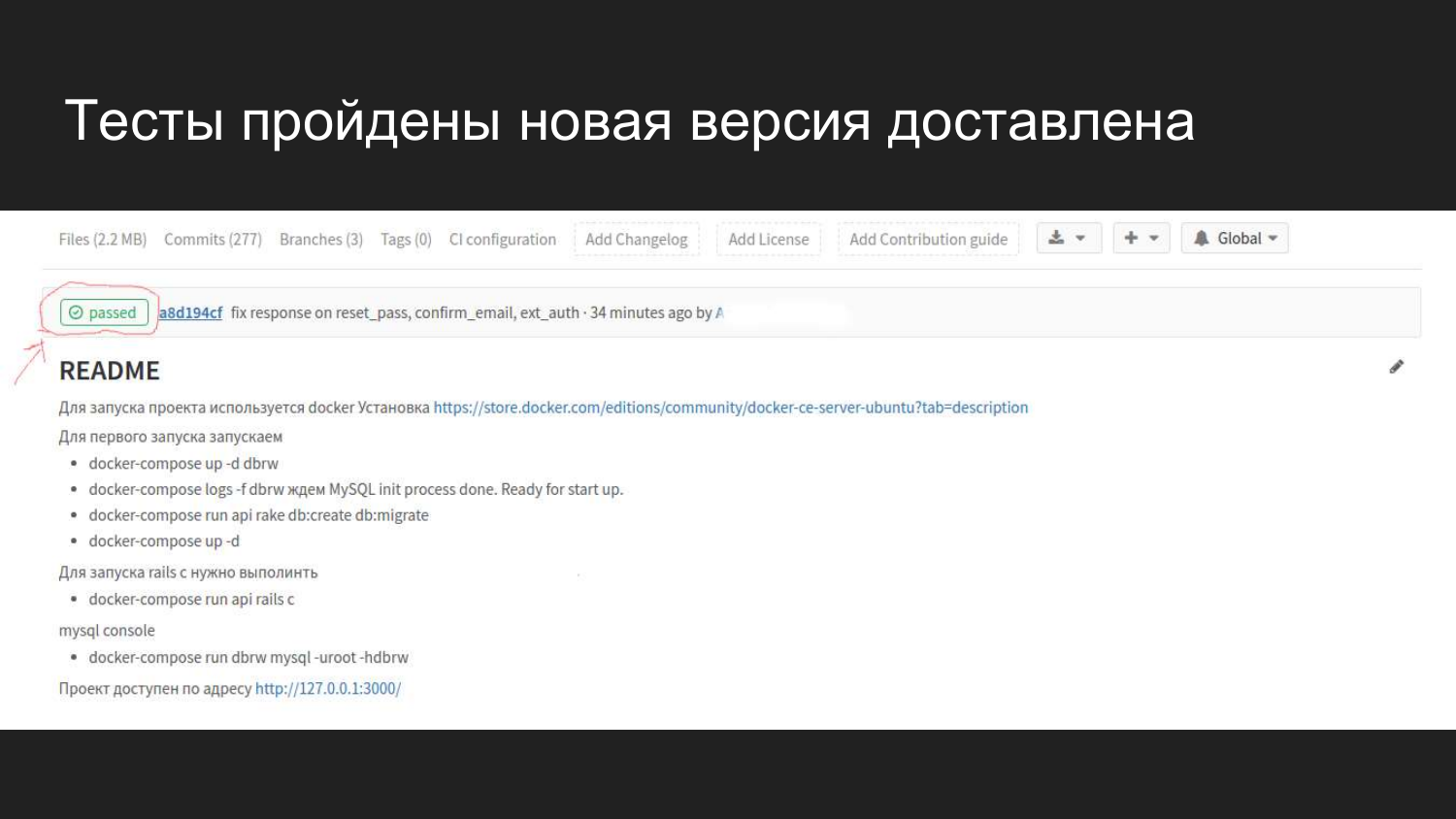
Como é visualmente visualizado no Gitlab em uma interface da web. Depois de conectar o IC do GItlab, aparece um sinalizador que mostra o estado atual da compilação.
Vimos que uma confirmação foi feita há 4 minutos, que passou em todos os testes e não causou problemas.
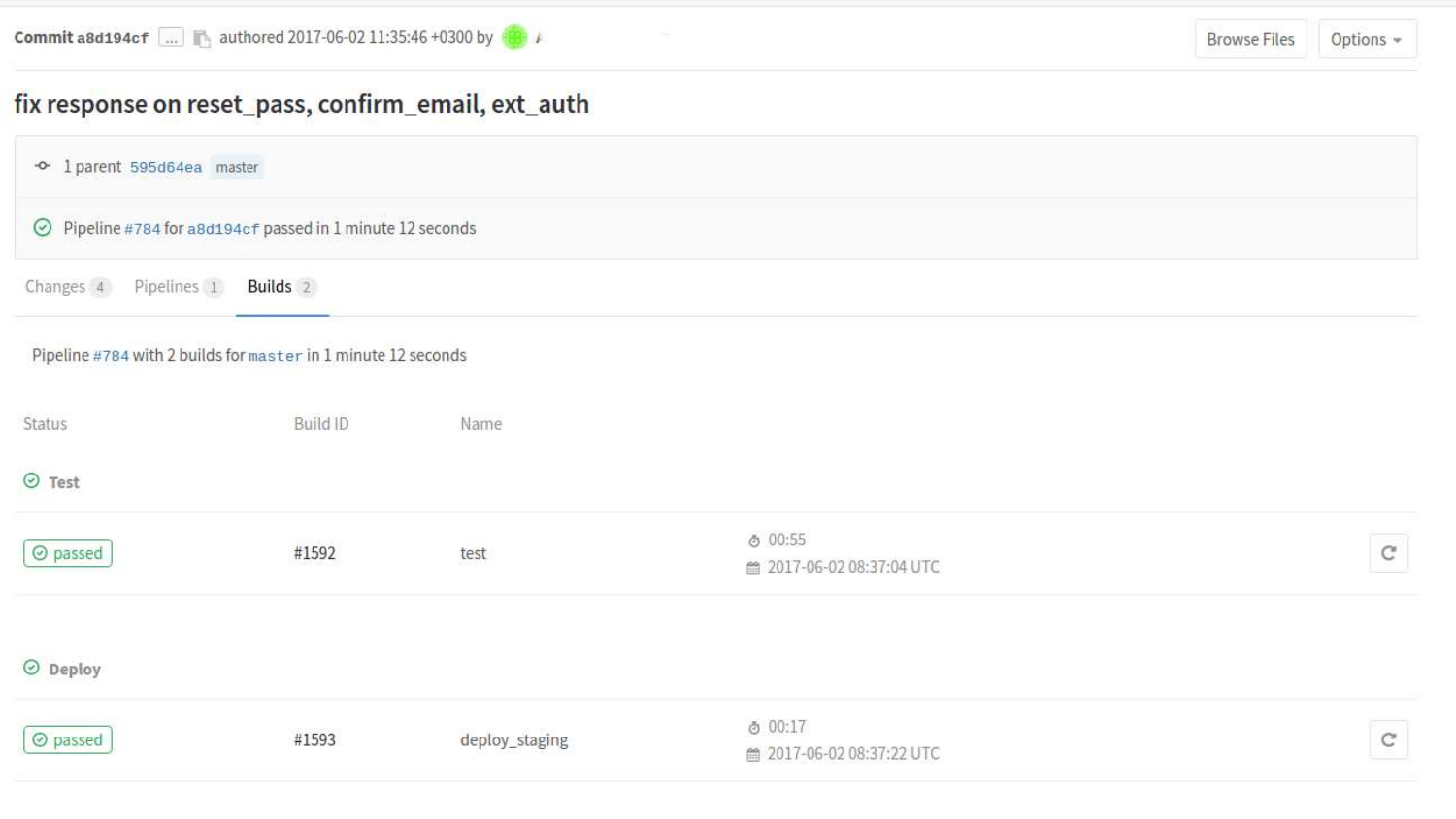
Podemos ver as construções com mais detalhes. Aqui vemos que dois estados já passaram. Testando o status e o status de implementação na preparação.
Se clicarmos em uma construção específica, haverá uma saída do console dos comandos que foram iniciados no processo de acordo com .gitlab-ci.yml.
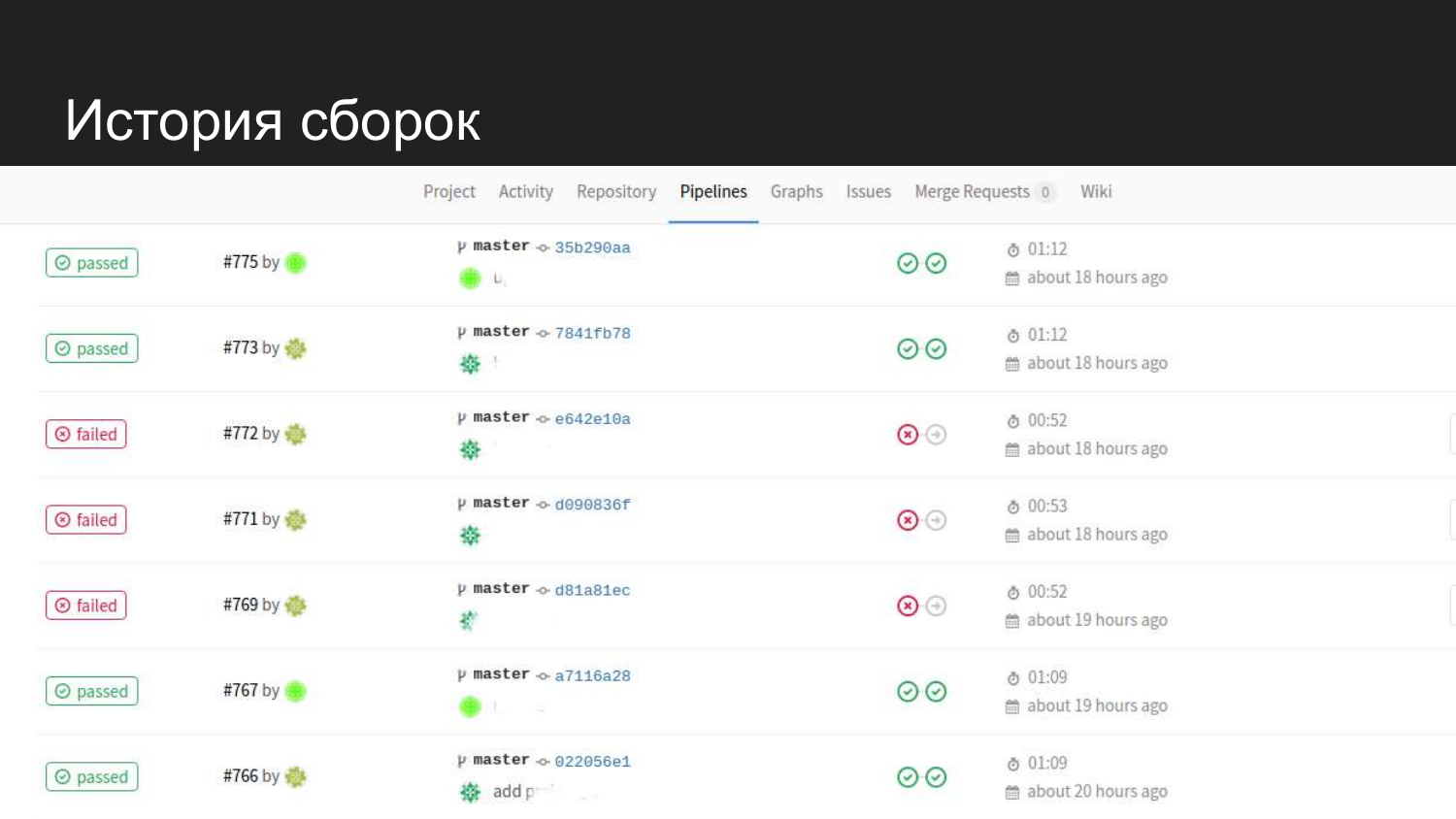
É assim que a história do nosso produto se parece. Vimos que houve tentativas bem-sucedidas. Quando os testes são enviados, ele não prossegue para a próxima etapa e o código para preparação não é atualizado.

Que tarefas resolvemos na preparação quando introduzimos o docker? , , , .
.
Docker-compose .
, Docker . Docker-compose .
, .
— staging .
production 80 443 , WEB.

? Gitlab Runner .
Gitlab Gitlab Runner, - , .
Gitlab Runner, .
nginx-proxy .
, . .
80 , .

? root. root root .
, root , root.
- , , , , .
? , .
, ?
ID (UID) ID (GID).
ID 1000.
Ubuntu. Ubuntu ID 1000.
?
Docker. , . , - , .
, .
.
Docker Docker Swarm, . - Docker Swarm.
. . . web-.
