Olá Habr! Apresento a você a tradução do artigo
“Envoy threading model” de Matt Klein.
Este artigo me pareceu interessante o suficiente e, como o Envoy é mais frequentemente usado como parte do "istio" ou simplesmente como "kubernetes" do controlador de entrada ", portanto, a maioria das pessoas não tem a mesma interação direta com ele, como por exemplo nas instalações típicas do Nginx ou Haproxy. No entanto, se algo quebrar, seria bom entender como funciona por dentro. Tentei traduzir o máximo de texto possível para o russo, incluindo palavras especiais, para quem é doloroso de ver isso, deixei os originais entre parênteses. Bem-vindo ao gato.
A documentação técnica de baixo nível na base de código do Envoy é atualmente bastante escassa. Para corrigir isso, pretendo fazer uma série de artigos de blog sobre os vários subsistemas da Envoy. Como este é o primeiro artigo, informe-me o que pensa e o que pode interessar nos artigos a seguir.
Uma das perguntas técnicas mais comuns que recebo sobre o Envoy é uma solicitação de uma descrição de baixo nível do modelo de encadeamento usado. Nesta postagem, descreverei como o Envoy mapeia conexões com threads, bem como uma descrição do sistema Thread Local Storage, que é usado internamente para tornar o código mais paralelo e de alto desempenho.
Visão geral do encadeamento
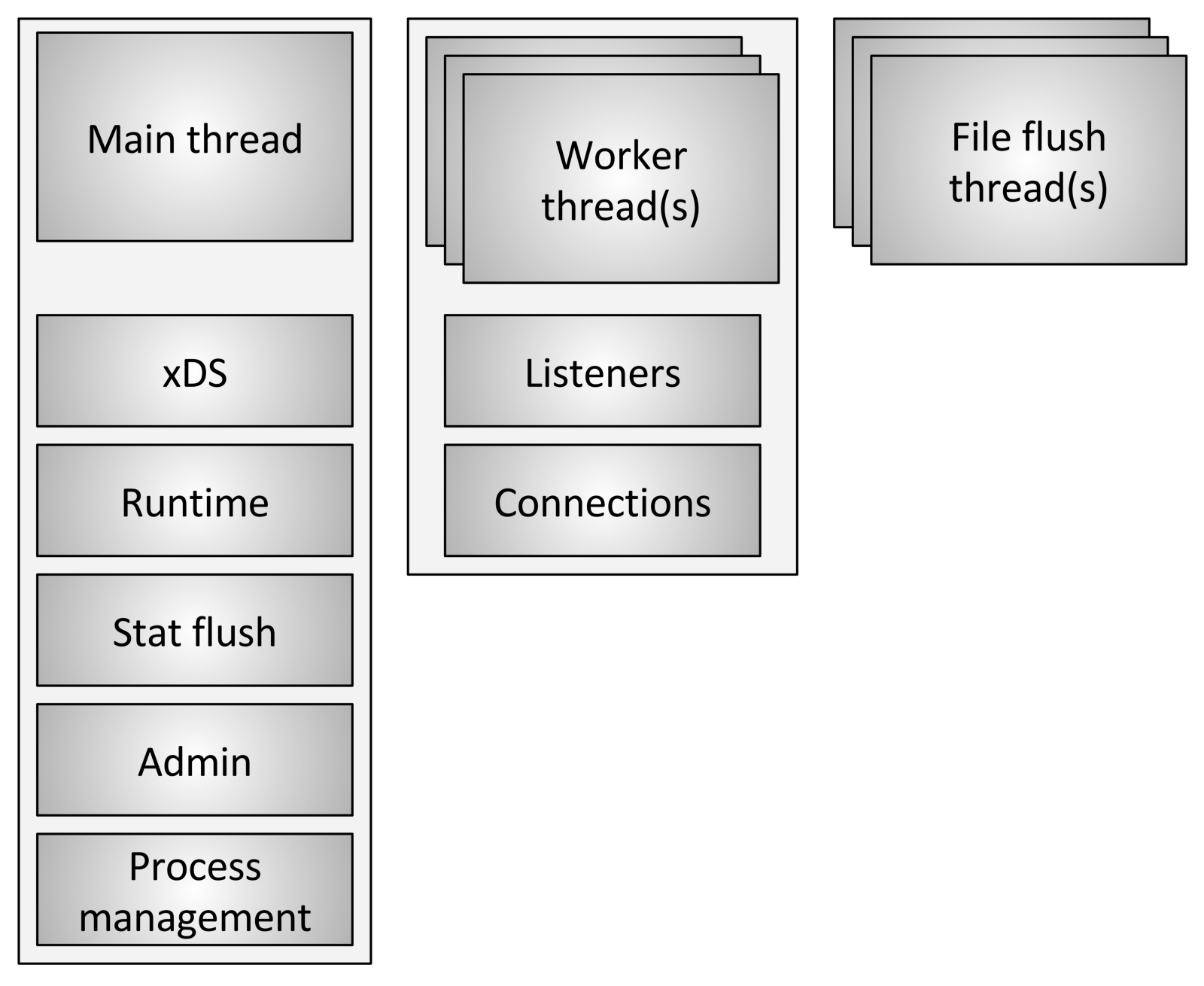 O Enviado usa três tipos diferentes de fluxos:
O Enviado usa três tipos diferentes de fluxos:- Principal: Esse encadeamento controla o início e o fim do processo, todo o processamento da API XDS (xDiscovery Service), incluindo DNS, verificação de integridade, cluster geral e gerenciamento de serviços (tempo de execução), redefinição de estatísticas, administração e gerenciamento geral processos - sinais do Linux, reinicialização a quente, etc. Tudo o que acontece nesse encadeamento é assíncrono e sem bloqueio. Em geral, o encadeamento principal coordena todos os processos críticos de funcionalidade, que não exigem um grande número de CPUs para serem concluídos. Isso permite que a maior parte do código de controle seja gravada como se fosse de thread único.
- Worker: Por padrão, o Envoy cria um thread de trabalho para cada segmento de hardware no sistema, que pode ser controlado usando a opção
--concurrency . Cada encadeamento de trabalhador inicia um loop de eventos "sem bloqueio", responsável por ouvir cada ouvinte, no momento da escrita (29 de julho de 2017), não há fragmentação do ouvinte, recebendo novos conexões, criando uma instância da pilha de filtros para conectar e processando todas as operações de E / S durante a vida útil da conexão. Novamente, isso permite que a maior parte do código de processamento de conexão seja gravada como se fosse de thread único. - Lavador de arquivos: cada arquivo que o Envoy grava, principalmente acessa logs, atualmente possui um fluxo de bloqueio independente. Isso se deve ao fato de que a gravação em arquivos armazenados em cache pelo sistema de arquivos, mesmo ao usar
O_NONBLOCK , às vezes pode ser bloqueada (suspiro). Quando os threads de trabalho precisam gravar em um arquivo, os dados são realmente movidos para um buffer na memória, onde eventualmente são liberados pelo fluxo de liberação do arquivo . Essa é uma área do código em que tecnicamente todos os threads de trabalho podem bloquear o mesmo bloqueio enquanto tentam preencher o buffer de memória.
Manipulação de conexão
Como discutido brevemente acima, todos os threads de trabalho ouvem todos os ouvintes sem nenhuma segmentação. Assim, o kernel é usado para enviar corretamente os soquetes recebidos para threads de trabalho. Os núcleos modernos geralmente são muito bons nisso, eles usam recursos como aumentar a prioridade de entrada / saída (E / S) para tentar preencher o encadeamento com trabalho, antes de começar a usar outros encadeamentos que também escutam no mesmo soquete e também não usam bloqueio circular (Spinlock) para lidar com cada solicitação.
Depois que uma conexão é aceita em um encadeamento de trabalho, ela nunca sai desse encadeamento. Todo o processamento adicional da conexão é totalmente processado no encadeamento de trabalho, incluindo qualquer comportamento de encaminhamento.
Isso tem várias consequências importantes:- Todos os conjuntos de conexões no Envoy estão em um fluxo de trabalho. Portanto, embora os conjuntos de conexões HTTP / 2 estabeleçam apenas uma conexão para cada host upstream por vez, se houver quatro threads de trabalho, haverá quatro conexões HTTP / 2 para o host upstream em um estado estável.
- O motivo pelo qual o Envoy funciona dessa maneira é porque, armazenando tudo em um fluxo de trabalho, quase todo o código pode ser gravado sem bloqueio e como se fosse de thread único. Esse design facilita a escrita de muito código e é incrivelmente bem dimensionado para um número quase ilimitado de fluxos de trabalho.
- No entanto, uma das principais conclusões é que, do ponto de vista do pool de memória e da eficiência da conexão, é realmente muito importante configurar o parâmetro
--concurrency . Ter mais threads de trabalho do que o necessário levará à perda de memória, criando mais conexões inativas e diminuindo a velocidade de entrada no pool de conexões. Na Lyft, nossos contêineres de side-car enviados trabalham com simultaneidade muito baixa, portanto o desempenho é aproximadamente equivalente aos serviços aos quais eles se encontram. Executamos o Envoy como um proxy de borda (borda) somente com simultaneidade máxima.
O que significa não-bloqueio?
Até o momento, o termo "sem bloqueio" foi usado várias vezes para discutir como os threads principal e de trabalho funcionam. Todo o código é escrito, desde que nada seja bloqueado. No entanto, isso não é inteiramente verdade (o que não é totalmente verdade?).
O enviado usa vários bloqueios de processo demorados:- Como já mencionado, ao gravar logs de acesso, todos os threads de trabalho obtêm o mesmo bloqueio antes de preencher o buffer de log na memória. O tempo de espera do bloqueio deve ser muito baixo, mas é possível que esse bloqueio seja desafiado com alta simultaneidade e alta taxa de transferência.
- O Enviado usa um sistema muito sofisticado para processar estatísticas locais no fluxo. Este será o tópico de uma postagem separada. No entanto, mencionarei brevemente que, como parte do processamento local das estatísticas de fluxo, às vezes é necessário obter um bloqueio para o "armazenamento de estatísticas" central. Esse bloqueio nunca deve ser necessário.
- O thread principal periodicamente precisa de coordenação com todos os fluxos de trabalho. Isso é feito “publicando” do thread principal nos threads de trabalho e, às vezes, dos threads de trabalho de volta ao thread principal. Para enviar, o bloqueio é necessário para que a mensagem publicada possa ser enfileirada para entrega subsequente. Esses bloqueios nunca devem ser submetidos a uma concorrência séria, mas ainda podem ser tecnicamente bloqueados.
- Quando o Envoy grava um log no fluxo de erros do sistema (erro padrão), ele recebe um bloqueio em todo o processo. No geral, o registro local da Envoy é considerado terrível em termos de desempenho, portanto não há muita atenção para melhorá-lo.
- Existem vários outros bloqueios aleatórios, mas nenhum deles é crítico para o desempenho e nunca deve ser contestado.
Encadear armazenamento local
Devido à maneira como o Envoy separa as responsabilidades do encadeamento principal das tarefas do fluxo de trabalho, é necessário que o processamento complexo possa ser executado no encadeamento principal e, em seguida, fornecido a cada fluxo de trabalho com um alto grau de simultaneidade. Esta seção descreve o sistema TLS (Envoy Thread Local Storage) em um nível alto. Na próxima seção, descreverei como é usado para gerenciar o cluster.

Como já descrito, o encadeamento principal processa quase todas as funções de gerenciamento e a funcionalidade do plano de controle no processo do Envoy. O plano de controle está um pouco sobrecarregado aqui, mas se você o observar no próprio processo Envoy e compará-lo com o encaminhamento que os threads de trabalho executam, isso parece apropriado. Como regra geral, o processo principal do encadeamento realiza algum trabalho e, em seguida, ele precisa atualizar cada encadeamento de trabalho de acordo com o resultado deste trabalho,
enquanto o encadeamento de trabalho não precisa definir um bloqueio em todos os acessos .
O sistema Envoy TLS (Thread local storage) funciona da seguinte maneira:- O código em execução no encadeamento principal pode alocar um slot TLS para todo o processo. Embora isso seja abstraído, na prática é um índice em um vetor que fornece acesso a O (1).
- O fluxo principal pode definir dados arbitrários em seu slot. Quando isso é feito, os dados são publicados em cada fluxo de trabalho como um evento de loop de eventos regular.
- Os encadeamentos de trabalho podem ler do slot TLS e recuperar qualquer dado de encadeamento local disponível lá.
Embora este seja um paradigma muito simples e incrivelmente poderoso, é muito semelhante ao conceito de bloqueio de RCU (Read-Copy-Update). Em essência, os fluxos de trabalho nunca veem alterações de dados nos slots TLS em tempo de execução. A mudança ocorre apenas durante o período de descanso entre eventos de trabalho.
O enviado usa isso de duas maneiras diferentes:- Ao armazenar vários dados em cada fluxo de trabalho, o acesso a esses dados é realizado sem nenhum bloqueio.
- Armazenando um ponteiro global para dados globais no modo somente leitura em cada encadeamento de trabalho. Assim, cada encadeamento de trabalho possui um contador de referência de dados, que não pode ser reduzido durante a execução do trabalho. Somente quando todos os funcionários se acalmarem e enviarem novos dados compartilhados, os dados antigos serão destruídos. É idêntico ao RCU.
Thread de atualização de cluster
Nesta seção, descreverei como o TLS (Thread Local Storage) é usado para gerenciar um cluster. O gerenciamento de cluster inclui processamento de API xDS e / ou DNS, bem como verificação de integridade.
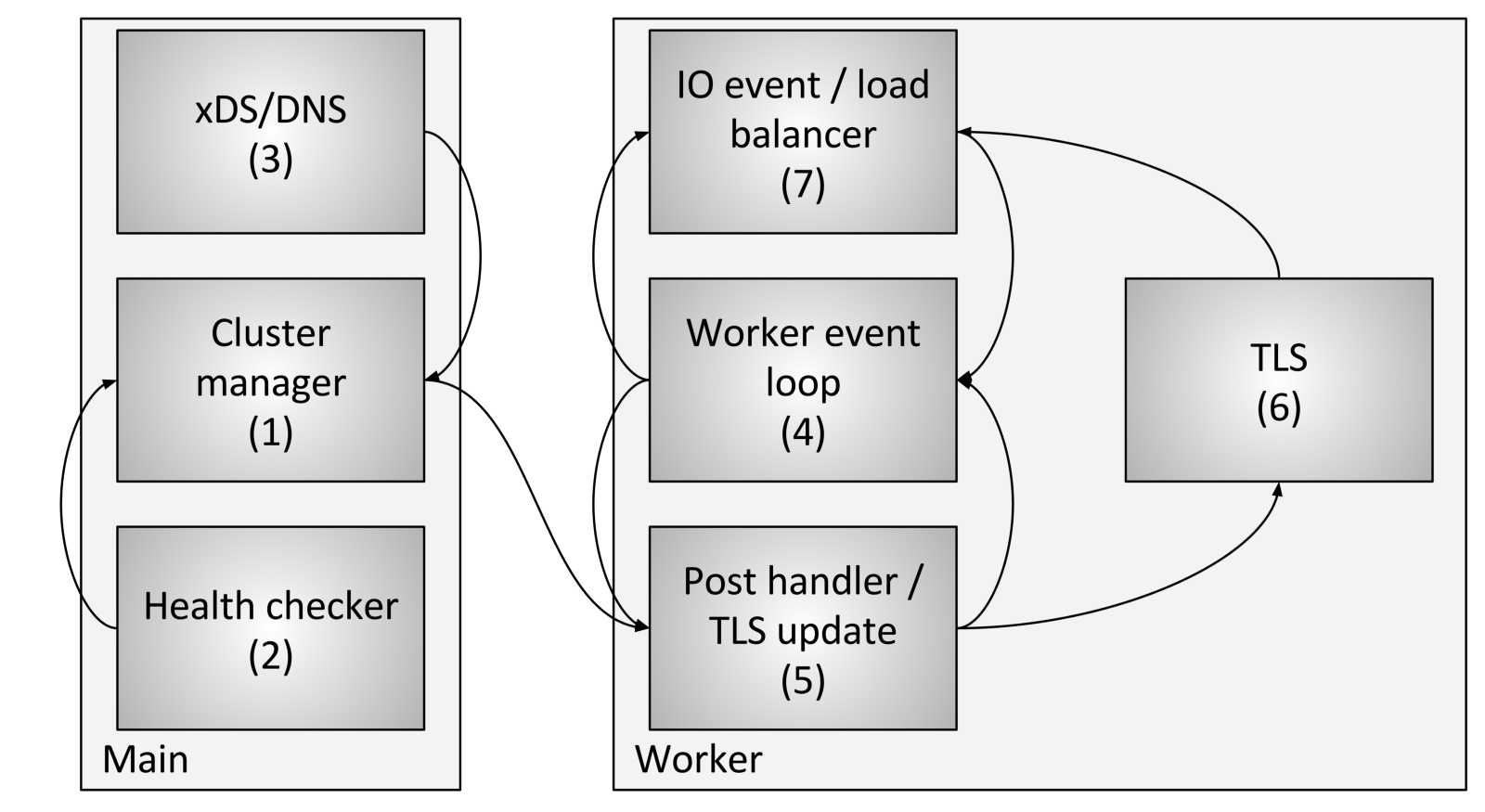 O gerenciamento de fluxo de cluster inclui os seguintes componentes e etapas:
O gerenciamento de fluxo de cluster inclui os seguintes componentes e etapas:- O Cluster Manager é um componente do Envoy que gerencia todos os upstream de cluster conhecido, APIs CDS (Serviço de Descoberta de Cluster), SDS (Serviço de Descoberta Secreta) e EDS (Serviço de Descoberta de Endpoint), DNS e verificações externas ativas saúde (verificação de saúde). Ele é responsável por criar uma representação “consistente” de cada cluster upstream que inclui os hosts descobertos, bem como o status de integridade.
- O verificador de integridade executa uma verificação de integridade ativa e relata as alterações no estado de integridade para o gerenciador de cluster.
- CDS (Serviço de Descoberta de Cluster) / SDS (Serviço de Descoberta Secreta) / EDS (Serviço de Descoberta de Endpoint) / DNS são executados para determinar a associação ao cluster. A mudança de estado é retornada ao gerenciador de cluster.
- Cada fluxo de trabalho executa constantemente um loop de eventos.
- Quando o gerenciador de cluster determina que o estado do cluster foi alterado, ele cria um novo instantâneo de cluster somente leitura e o envia para cada encadeamento de trabalho.
- Durante o próximo período inativo, o fluxo de trabalho atualizará o instantâneo no slot TLS dedicado.
- Durante um evento de E / S que o host deve determinar para o balanceamento de carga, o balanceador de carga solicitará um slot TLS (Thread local storage) para obter informações do host. Nenhum bloqueio é necessário para isso. Observe também que o TLS também pode disparar eventos durante a atualização, para que os balanceadores de carga e outros componentes possam recontar caches, estruturas de dados etc. Isso está além do escopo desta postagem, mas é usado em vários lugares do código.
Usando o procedimento acima, o Envoy pode processar cada solicitação sem nenhum bloqueio (além dos descritos anteriormente). Além da complexidade do próprio código TLS, a maior parte do código não precisa entender como o multithreading funciona e pode ser gravado no modo de thread único. Isso facilita a gravação da maior parte do código, além do desempenho superior.
Outros subsistemas que fazem uso do TLS
TLS (Thread local storage) e RCU (Read Copy Update) são amplamente utilizados no Envoy.
Exemplos de uso:- O mecanismo de alteração da funcionalidade durante a execução: A lista atual de funcionalidades ativadas é calculada no encadeamento principal. Cada fluxo de trabalho é fornecido com um instantâneo somente leitura usando a semântica de RCU.
- Substituindo tabelas de rotas : para tabelas de rotas fornecidas pelo RDS (Route Discovery Service), as tabelas de rotas são criadas no encadeamento principal. Um instantâneo somente leitura será fornecido posteriormente para cada fluxo de trabalho usando a semântica de RCU (Read Copy Update). Isso torna a modificação de tabelas de rotas atomicamente eficiente.
- Armazenamento em cache do cabeçalho HTTP: o cálculo do cabeçalho HTTP para cada solicitação (ao executar ~ 25K + RPS por núcleo) é bastante caro. O enviado calcula centralmente o cabeçalho aproximadamente a cada meio segundo e o fornece a todos os funcionários por meio de TLS e RCU.
Existem outros casos, mas os exemplos anteriores devem fornecer uma boa compreensão do uso do TLS.
Armadilhas conhecidas de desempenho
Embora o Envoy funcione muito bem no geral, existem algumas áreas conhecidas que precisam de atenção quando usadas com simultaneidade e largura de banda muito altas:
- Como já descrito neste artigo, atualmente todos os threads de trabalho estão bloqueados quando gravados no buffer de memória do log de acesso. Com alta simultaneidade e alta taxa de transferência, será necessário empacotar logs de acesso para cada fluxo de trabalho devido a entrega não ordenada ao gravar no arquivo final. Como alternativa, você pode criar um log de acesso separado para cada fluxo de trabalho.
- Embora as estatísticas sejam muito otimizadas, com simultaneidade e taxa de transferência muito altas, é provável que exista concorrência atômica nas estatísticas individuais. A solução para esse problema é contadores por um fluxo de trabalho com redefinição periódica dos contadores centrais. Isso será discutido em um post subsequente.
- A arquitetura existente não funcionará bem se o Envoy for implantado em um cenário em que existem muito poucas conexões que exijam recursos significativos de processamento. Não há garantia de que as comunicações serão distribuídas igualmente entre os fluxos de trabalho. Isso pode ser resolvido equilibrando as conexões de trabalho, nas quais a capacidade de trocar conexões entre fluxos de trabalho será realizada.
Conclusão
O modelo de encadeamento Envoy foi projetado para fornecer facilidade de programação e simultaneidade massiva devido ao uso potencialmente desperdiçador de memória e conexões, se não estiverem configuradas corretamente. Esse modelo permite que ele funcione muito bem com um número muito alto de threads e taxa de transferência.
Como mencionei brevemente no Twitter, um design também pode ser executado em cima de uma pilha de rede totalmente funcional no modo de usuário, como o DPDK (Data Plane Development Kit), que pode fazer com que servidores regulares processem milhões de solicitações por segundo com processamento L7 completo. Será muito interessante ver o que será construído nos próximos anos.
Um último comentário rápido: muitas vezes me perguntam por que escolhemos o C ++ para o Envoy. A razão, como antes, é que ainda é a única linguagem de nível industrial amplamente falada na qual construir a arquitetura descrita neste post. Definitivamente, o C ++ não é adequado para todos ou para muitos projetos, mas, em certos casos de uso, ainda é a única ferramenta para fazer o trabalho (para fazer o trabalho).
Links para código
Links para arquivos com interfaces e implementações de cabeçalho discutidos neste post: