Olá pessoal. A biblioteca de redes neurais é descrita no meu último
artigo . Aqui eu decidi mostrar como você pode usar a rede treinada do TF (Tensorflow) em sua decisão e se vale a pena.
Sob o corte, uma comparação com a implementação original do TF, um aplicativo de demonstração para reconhecer fotos, bem ... conclusões. Quem se importa, por favor.
Você pode descobrir como o ResNet funciona, por exemplo,
aqui .
Aqui está a estrutura da rede em números:
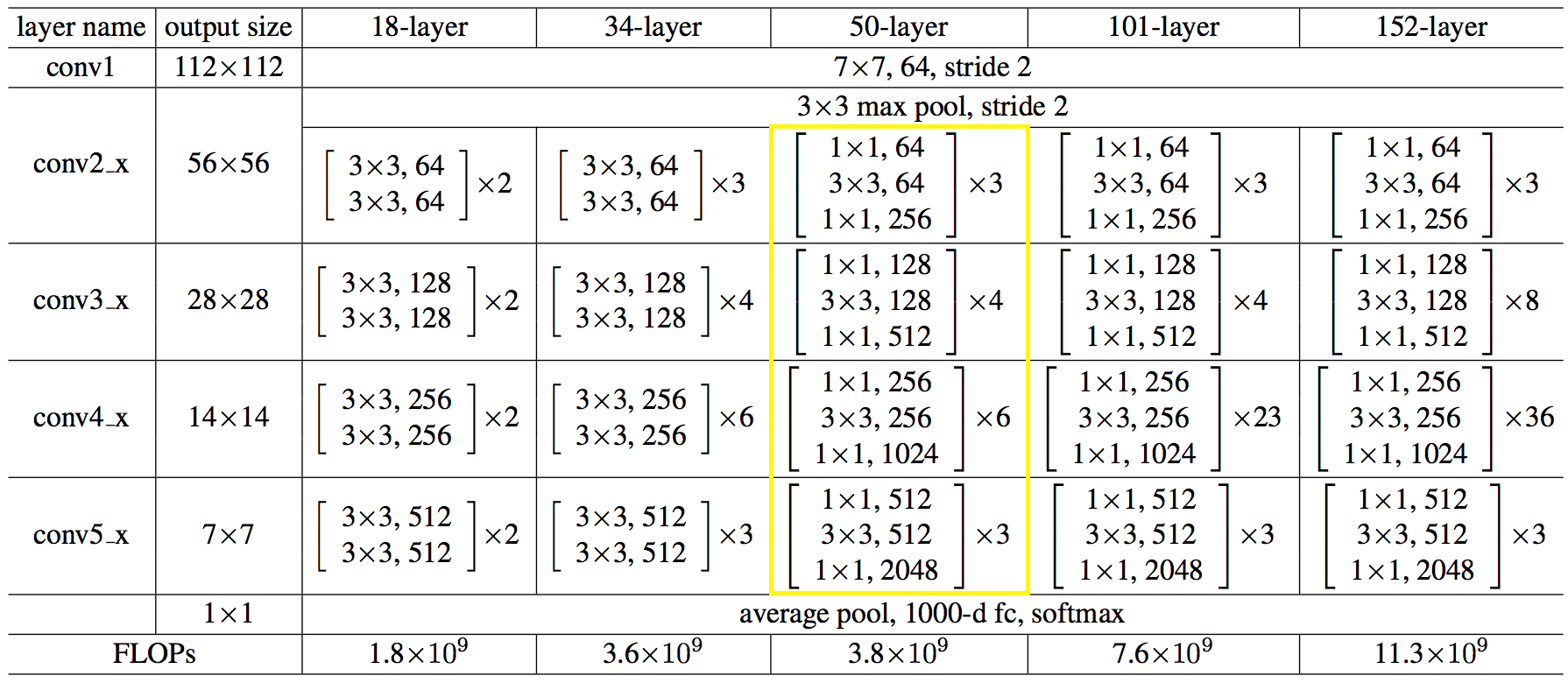
O código acabou não sendo mais simples e nem mais complicado que o python.
Código C ++ para criar uma rede:auto net = sn::Net(); net.addNode("In", sn::Input(), "conv1") .addNode("conv1", sn::Convolution(64, 7, 3, 2, sn::batchNormType::beforeActive, sn::active::none, mode), "pool1_pad") .addNode("pool1_pad", sn::Pooling(3, 2, sn::poolType::max, mode), "res2a_branch1 res2a_branch2a"); convBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, 1, "res2a_branch", "res2b_branch2a res2b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, "res2b_branch", "res2c_branch2a res2c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256}, 3, "res2c_branch", "res3a_branch1 res3a_branch2a", mode); convBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, 2, "res3a_branch", "res3b_branch2a res3b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3b_branch", "res3c_branch2a res3c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3c_branch", "res3d_branch2a res3d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3d_branch", "res4a_branch1 res4a_branch2a", mode); convBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, 2, "res4a_branch", "res4b_branch2a res4b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4b_branch", "res4c_branch2a res4c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4c_branch", "res4d_branch2a res4d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4d_branch", "res4e_branch2a res4e_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4e_branch", "res4f_branch2a res4f_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4f_branch", "res5a_branch1 res5a_branch2a", mode); convBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, 2, "res5a_branch", "res5b_branch2a res5b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5b_branch", "res5c_branch2a res5c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5c_branch", "avg_pool", mode); net.addNode("avg_pool", sn::Pooling(7, 7, sn::poolType::avg, mode), "fc1000") .addNode("fc1000", sn::FullyConnected(1000, sn::active::none, mode), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
→ O código completo está disponível
aquiVocê pode facilitar, carregar a arquitetura de rede e os pesos dos arquivos,
assim: string archPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Struct.json", weightPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Weights.dat"; std::ifstream ifs; ifs.open(archPath, std::ifstream::in); if (!ifs.good()){ cout << "error open file : " + archPath << endl; system("pause"); return false; } ifs.seekg(0, ifs.end); size_t length = ifs.tellg(); ifs.seekg(0, ifs.beg); string jnArch; jnArch.resize(length); ifs.read((char*)jnArch.data(), length);
Fez um pedido de interesse. Você pode baixar
aqui . O volume é grande devido aos pesos da rede. As fontes estão lá, você pode usar como exemplo.
O aplicativo foi criado apenas para o artigo, não será suportado e, portanto, não foi incluído no repositório do projeto.

Agora, o que aconteceu em comparação com o TF.
Indicações após uma execução de 100 imagens, em média. Máquina: i5-2400, GF1050, Win7, MSVC12.
Os valores dos resultados do reconhecimento correspondem ao terceiro caractere.
→
Código de testeDe fato, tudo é deplorável, é claro.
Para a CPU, decidi não usar o MKL-DNN, pensei em terminar: redistribui a memória para leitura sequencial, carregava os registros de vetor ao máximo. Talvez fosse necessário levar à multiplicação de matrizes e / ou alguns outros hacks. Descansado aqui, no começo era pior, seria mais correto usar o MKL da mesma forma.
Na GPU, é gasto tempo copiando a memória da / para a memória da placa de vídeo e nem todas as operações são executadas na GPU.
Que conclusões podem ser tiradas de toda essa confusão:
- não para se exibir, mas para usar soluções comprovadas conhecidas, elas já vêm à mente mais ou menos. Ele se sentou no mxnet uma vez e trabalhou com o uso nativo, mais sobre isso abaixo;
- Não tente usar a interface C nativa das estruturas ML. E use-os na linguagem em que os desenvolvedores se concentraram, ou seja, python.
Uma maneira fácil de usar a funcionalidade ML do seu idioma é fazer um processo de serviço em python e enviar fotos para ele no soquete, você obtém uma divisão de responsabilidade e a ausência de código pesado.
Talvez tudo. O artigo foi curto, mas acho que as conclusões são valiosas e se aplicam não apenas ao ML.
Obrigada
PS:
se alguém tiver vontade e força para tentar alcançar o TF, seja
bem-vindo !)
PS2:
abaixou as mãos cedo. Ele fez uma pausa para fumar, tomou novamente e tudo deu certo.
Para a CPU, converter para multiplicação de matrizes ajudou, como eu pensava.
Para a GPU, selecionei todas as operações em uma biblioteca separada, de modo que, sem copiar para a CPU e vice-versa, o único ponto negativo dessa abordagem era que eu tinha que reescrever (duplicar) todos os operadores, embora algumas coisas coincidissem, mas eu não os conectei.
Em geral, veja como agora:
Ou seja, pelo menos a inferência foi ainda mais rápida do que no TF.
O código de teste não foi alterado.