Olá Habr!
Lembramos que, após o livro sobre
Kafka , lançamos um trabalho igualmente interessante na biblioteca da
API Kafka Streams .

Até agora, a comunidade está apenas compreendendo os limites dessa ferramenta poderosa. Portanto, um artigo foi publicado recentemente, com a tradução que queremos apresentar a você. Por experiência própria, o autor conta como criar um data warehouse distribuído a partir do Kafka Streams. Boa leitura!
A biblioteca Apache
Kafka Streams em todo o mundo é usada na empresa para processamento de streaming distribuído sobre o Apache Kafka. Um dos aspectos subestimados dessa estrutura é que ela permite armazenar um estado local com base no processamento de streaming.
Neste artigo, mostrarei como nossa empresa utilizou com sucesso essa oportunidade para desenvolver um produto para a segurança de aplicativos em nuvem. Usando o Kafka Streams, criamos microsserviços de serviço compartilhado, cada um dos quais serve como fonte tolerante a falhas e altamente acessível de informações confiáveis sobre o estado dos objetos no sistema. Para nós, este é um passo à frente, tanto em termos de confiabilidade quanto de facilidade de suporte.
Se você estiver interessado em uma abordagem alternativa que permita usar um único banco de dados central para suportar o estado formal de seus objetos - leia, será interessante ...
Por que pensamos que era hora de mudar nossas abordagens para trabalhar com o estado compartilhadoPrecisávamos manter o estado de vários objetos com base nos relatórios do agente (por exemplo: o site foi atacado)? Antes de mudar para o Kafka Streams, geralmente dependíamos de um único banco de dados central (+ API de serviço) para gerenciar nosso estado. Essa abordagem tem suas desvantagens: em
situações com muitos dados, o suporte à consistência e sincronização se transforma em um verdadeiro desafio. O banco de dados pode se tornar um gargalo, ou pode estar em
uma condição de corrida e sofrer imprevisibilidade.
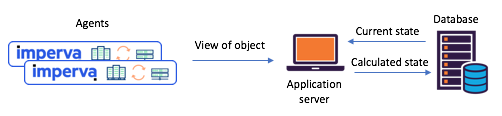 Figura 1: Um cenário típico de estado dividido encontrado antes da transição para
Figura 1: Um cenário típico de estado dividido encontrado antes da transição para
Kafka e Kafka Streams: os agentes comunicam seus envios via API, o status atualizado é calculado através de um banco de dados centralConheça o Kafka Streams - Agora é fácil criar microsserviços de estado compartilhadosCerca de um ano atrás, decidimos revisar completamente nossos cenários de estado compartilhado para lidar com esses problemas. Decidimos imediatamente experimentar o Kafka Streams - sabemos como é escalável, altamente acessível e tolerante a falhas, quão rica é a sua funcionalidade de streaming (transformações, incluindo as stateful). Exatamente o que precisávamos, sem mencionar o quão maduro e confiável era o sistema de mensagens em Kafka.
Cada um dos microsserviços que preservam o estado que criamos foi construído com base na instância do Kafka Streams com uma topologia bastante simples. Consistia em 1) uma fonte 2) um processador com um armazenamento permanente de chaves e valores 3) dreno:
 Figura 2: A topologia padrão de nossas instâncias de streaming para microsserviços com estado. Observe que também há um repositório que contém metadados de planejamento.
Figura 2: A topologia padrão de nossas instâncias de streaming para microsserviços com estado. Observe que também há um repositório que contém metadados de planejamento.Com essa nova abordagem, os agentes compõem mensagens entregues ao tópico original e os consumidores - digamos, um serviço de notificação por email - aceitam o estado compartilhado calculado através do estoque (tópico de saída).
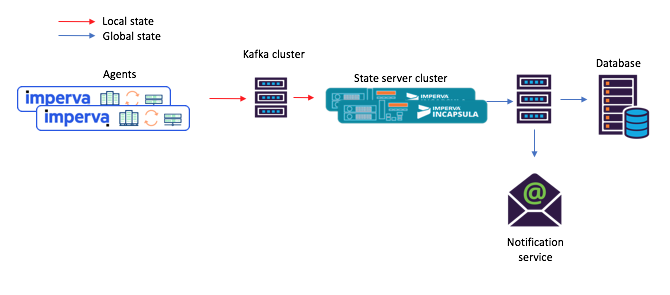 Figura 3: um novo exemplo de fluxo de tarefas para um cenário com microsserviços compartilhados: 1) o agente gera uma mensagem chegando no tópico Kafka original; 2) um microsserviço com um estado compartilhado (usando o Kafka Streams) processa e grava o estado calculado no tópico final do Kafka; após o qual 3) os consumidores aceitam o novo estadoEi, este repositório embutido de chaves e valores é realmente muito útil!
Figura 3: um novo exemplo de fluxo de tarefas para um cenário com microsserviços compartilhados: 1) o agente gera uma mensagem chegando no tópico Kafka original; 2) um microsserviço com um estado compartilhado (usando o Kafka Streams) processa e grava o estado calculado no tópico final do Kafka; após o qual 3) os consumidores aceitam o novo estadoEi, este repositório embutido de chaves e valores é realmente muito útil!Como mencionado acima, nossa topologia de estado compartilhado contém um armazenamento de chaves e valores. Encontramos várias opções para seu uso, e duas delas são descritas abaixo.
Opção 1: usando o keystore e o armazenamento de valores para cálculosNosso primeiro repositório de chaves e valores continha dados auxiliares necessários para os cálculos. Por exemplo, em alguns casos, o estado compartilhado foi determinado com base no princípio do “voto majoritário”. No repositório, foi possível manter todos os relatórios mais recentes do agente sobre o estado de um determinado objeto. Em seguida, recebendo um novo relatório de um agente, poderíamos salvá-lo, extrair relatórios de todos os outros agentes sobre o estado do mesmo objeto do repositório e repetir o cálculo.
A Figura 4 abaixo mostra como abrimos o acesso ao armazenamento de chave e valor ao método de processamento do processador, para que pudéssemos processar a nova mensagem.
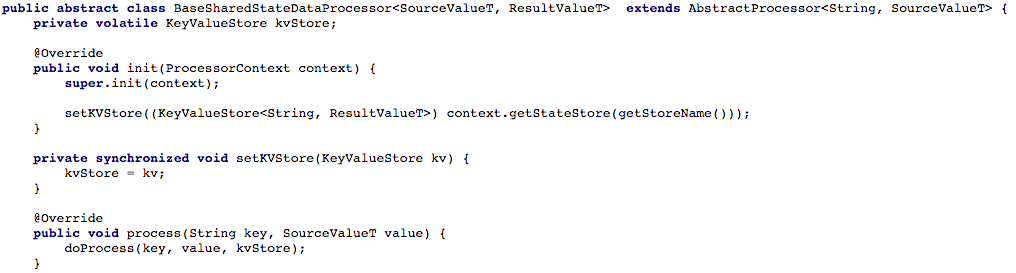 Figura 4: abrimos o acesso ao armazenamento de chaves e valores para o método de processamento do processador (depois disso, em cada script que trabalha com um estado compartilhado, você deve implementar o método
Figura 4: abrimos o acesso ao armazenamento de chaves e valores para o método de processamento do processador (depois disso, em cada script que trabalha com um estado compartilhado, você deve implementar o método doProcess )Opção # 2: criando uma API CRUD sobre o Kafka StreamsDepois de ajustar nosso fluxo básico de tarefas, começamos a tentar escrever uma API RESTful CRUD para nossos microsserviços de serviço compartilhado. Queríamos poder extrair o estado de alguns ou de todos os objetos, além de definir ou excluir o estado do objeto (isso é útil com o suporte do lado do servidor).
Para dar suporte a todas as APIs Get State, sempre que precisávamos recalcular o estado durante o processamento, colocá-lo no repositório interno de chaves e valores por um longo tempo. Nesse caso, torna-se bastante simples implementar essa API usando uma única instância do Kafka Streams, conforme mostrado na listagem abaixo:
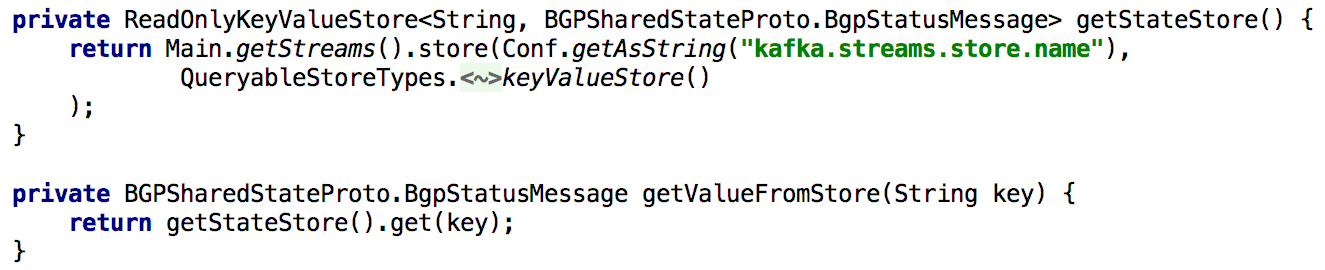 Figura 5: usando o armazenamento interno de chaves e valores para obter o estado pré-calculado de um objeto
Figura 5: usando o armazenamento interno de chaves e valores para obter o estado pré-calculado de um objetoA atualização do estado de um objeto por meio da API também é fácil de implementar. Em princípio, para isso, você só precisa criar um produtor Kafka e, com a ajuda dele, registrar um novo estado. Isso garante que todas as mensagens geradas por meio da API sejam processadas da mesma maneira que recebidas de outros produtores (por exemplo, agentes).
 Figura 6: Você pode definir o estado de um objeto usando o Kafka produtorUma pequena complicação: Kafka tem muitas partições.
Figura 6: Você pode definir o estado de um objeto usando o Kafka produtorUma pequena complicação: Kafka tem muitas partições.Em seguida, queríamos distribuir a carga de processamento e melhorar a disponibilidade, fornecendo um cluster de microsserviço de serviço compartilhado para cada cenário. A configuração foi feita da maneira mais simples possível: depois de configurarmos todas as instâncias para que funcionassem com o mesmo ID de aplicativo (e com os mesmos servidores de inicialização), quase tudo o mais era feito automaticamente. Também definimos que cada tópico de origem consistirá em várias partições, para que cada instância possa receber um subconjunto de tais partições.
Mencionarei também que é normal fazer uma cópia de backup do armazenamento de estado, para que, por exemplo, em caso de recuperação após uma falha, transfira essa cópia para outra instância. Para cada armazenamento de estado no Kafka Streams, um tópico replicado é criado com um log de alterações (no qual as atualizações locais são rastreadas). Assim, Kafka constantemente protege a loja do estado. Portanto, no caso de uma falha de uma ou outra instância do Kafka Streams, o armazenamento de estado pode ser restaurado rapidamente em outra instância, para onde as partições correspondentes irão. Nossos testes mostraram que isso pode ser feito em segundos, mesmo se houver milhões de registros no repositório.
Passando de um microsserviço de serviço compartilhado para um cluster de microsserviços, torna-se menos trivial implementar a API Get State. Na nova situação, o repositório de estados de cada microsserviço contém apenas parte da imagem geral (aqueles objetos cujas chaves foram mapeadas para uma partição específica). Tivemos que determinar em qual instância o estado do objeto que precisávamos estava contido e fizemos isso com base nos metadados do fluxo, conforme mostrado abaixo:
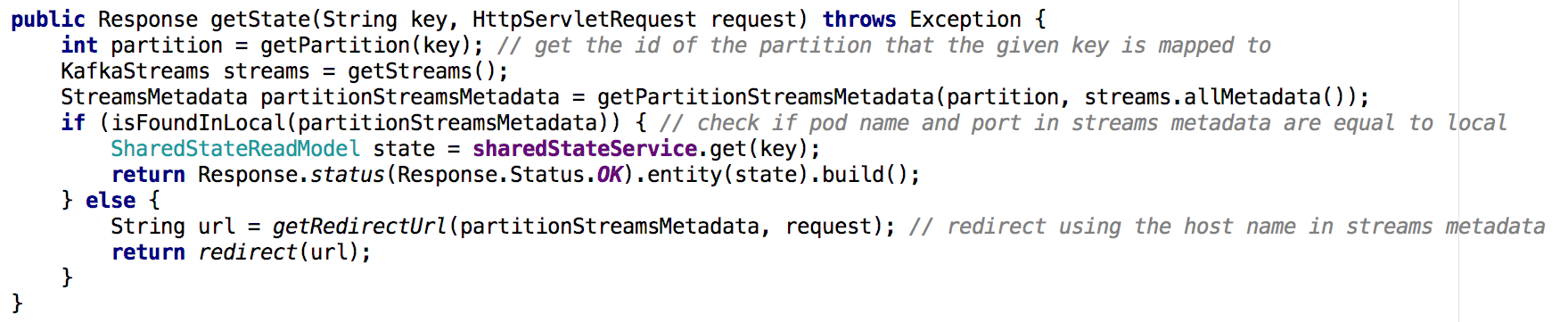 Figura 7: usando os metadados do fluxo, determinamos a partir de qual instância solicitar o estado do objeto desejado; uma abordagem semelhante foi usada com a API GET ALLPrincipais conclusões
Figura 7: usando os metadados do fluxo, determinamos a partir de qual instância solicitar o estado do objeto desejado; uma abordagem semelhante foi usada com a API GET ALLPrincipais conclusõesAs lojas do estado em Kafka Streams podem, de fato, servir como um banco de dados distribuído,
- replicado continuamente em kafka
- No topo desse sistema, é facilmente criada a API CRUD
- Processar várias partições é um pouco mais complicado
- Também é possível adicionar um ou mais armazenamentos de estado à topologia de fluxo para armazenar dados auxiliares. Esta opção pode ser usada para:
- Armazenamento de dados a longo prazo necessário para cálculos no processamento de streaming
- Armazenamento de dados a longo prazo que pode ser útil na próxima vez em que a instância do fluxo for inicializada
- muito mais ...
Graças a essas e outras vantagens, o Kafka Streams é excelente para oferecer suporte ao status global em um sistema distribuído como o nosso. O Kafka Streams provou ser muito confiável na produção (desde o momento de sua implantação, praticamente não perdemos mensagens) e temos certeza de que isso não se limita às suas capacidades!