Bem, já sabemos tudo o que você precisa para programar o UDB. Mas uma coisa é saber e outra é poder. Portanto, hoje discutiremos onde e como obter inspiração para melhorar nossas próprias habilidades, onde ganhar experiência. Como pode ser visto na
tradução da documentação , há um conhecimento seco que nem sempre está vinculado à prática real (chamei a atenção para isso em uma nota bastante longa, até a última tradução até o momento). Na verdade, as estatísticas das visualizações de artigos mostram que cada vez menos pessoas leem traduções. Havia até uma proposta de interromper esse ciclo, por desinteressante, mas apenas duas partes permaneciam; portanto, no final, foi simplesmente decidido reduzir o ritmo de sua preparação. Em geral, a documentação para o controlador é uma coisa necessária, mas não auto-suficiente. Onde mais para obter inspiração?

Antes de tudo, posso recomendar o excelente documento
AN82156 Designing PSoC Creator Components com Datapaths UDB . Nele você encontrará soluções típicas, além de vários projetos padrão. Além disso, no início do documento, o desenvolvimento é realizado usando o UDB Editor e, no final, usando a Datapath Config Tool, ou seja, o documento abrange todos os aspectos do desenvolvimento. Infelizmente, porém, considerando o preço de um único chip PSoC, eu diria que, se ele puder resolver os problemas descritos neste documento, o controlador será superestimado. PWMs e portas seriais padrão podem ser feitas sem PSoC. Felizmente, a gama de tarefas PSoC é muito maior. Portanto, depois de terminar de ler AN82156, começamos a procurar outras fontes de inspiração.
A próxima fonte útil são os exemplos que acompanham o PSoC Creator. Eu já os referi em uma nota a uma das partes da tradução da documentação da empresa (você pode ver
aqui ). Eles são armazenados aproximadamente aqui (o disco pode ser diferente):
E: \ Arquivos de programas (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ psoc \ content \ CyComponentLibrary.
Você deve procurar arquivos * .v, ou seja, textos verilog ou * .vhd, pois a sintaxe da linguagem VHDL exige um pouco mais a ser descrita e, nessa linguagem, às vezes você pode encontrar nuances interessantes escondidas dos olhos do programador da Verilog. O problema é que esses não são exemplos, mas soluções prontas. Isso é maravilhoso, eles são perfeitamente depurados, mas nós, programadores simples, temos objetivos diferentes com os programadores Cypress. Nossa tarefa é fazer algo auxiliar em um curto espaço de tempo, após o que começamos a usá-lo em nossos projetos, que serão gastos a maior parte do tempo. Idealmente, deve resolver as tarefas que nos foram atribuídas hoje e, se amanhã quisermos inserir o mesmo código em outro projeto, onde tudo será um pouco diferente, amanhã terminaremos nessa situação. Para os desenvolvedores do Cypress, o componente é o produto final, para que possam passar a maior parte do tempo nele. E eles devem prover tudo-tudo-tudo. Então, quando assisti esses textos, fiquei triste. Eles são muito complexos para alguém que acaba de começar a procurar onde se inspirar para seus primeiros desenvolvimentos. Mas, como referências, esses textos são bastante adequados. Existem muitos designs valiosos que são necessários ao criar suas próprias coisas.
Também há cantos muito interessantes. Por exemplo, existem agora, no estilo do "óleo de manteiga", modelos para modelagem (há muito tempo, um professor severo me desencorajou de traduzir a simulação de qualquer outra maneira que não seja "modelagem"). Eles podem ser encontrados no catálogo.
E: \ Arquivos de programas (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim.
O diretório mais interessante para o programador no Verilogue é:
E: \ Arquivos de programas (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim \ presynth \ vlg.
A descrição dos componentes na documentação é boa. Mas modelos comportamentais para todos os componentes padrão são descritos aqui. Às vezes, isso é melhor do que a documentação (escrita em um idioma pesado, além de alguns detalhes essenciais serem omitidos). Quando o comportamento deste ou daquele componente não é claro, vale a pena iniciar tentativas de entendê-lo com precisão, visualizando arquivos deste diretório. No começo, tentei pesquisar no Google, mas muitas vezes encontrava nos fóruns encontrados apenas argumentos e detalhes específicos. Aqui estão precisamente os detalhes.
No entanto, o livro de referência é maravilhoso, mas onde procurar um livro didático, o que aprender? Honestamente, não há nada de especial. Não há muitos bons exemplos prontos para o UDB Editor. Eu tive muita sorte de que, quando de repente decidi jogar LEDs RGB, me deparei com um belo exemplo no UDB Editor (escrevi sobre isso em um
artigo que iniciou todo o ciclo). Mas se você trabalha muito com um mecanismo de pesquisa, ainda haverá exemplos para a Ferramenta de configuração do Datapath, e foi por isso que criei o
artigo anterior para que todos entendessem como usar essa ferramenta. E uma página maravilhosa na qual muitos exemplos são coletados está localizada
aqui .
Nesta página, desenvolvimentos feitos por desenvolvedores de terceiros, mas verificados pelo Cypress. Ou seja, exatamente o que precisamos: também somos desenvolvedores de terceiros, mas queremos aprender com algo que é precisamente verificado. Vejamos um exemplo em que encontrei esta página - uma calculadora de hardware com raiz quadrada. Os usuários finais o incluem no caminho de processamento do sinal, jogando um componente no circuito. Neste exemplo, treinaremos para analisar um código semelhante e todos poderão começar a nadar independentemente. Portanto, o exemplo necessário pode ser baixado do
link .
Nós examinamos isso. Existem exemplos (que todos considerarão independentemente) e bibliotecas localizadas no diretório \ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib.
Para cada tipo (número inteiro ou ponto fixo) e para cada bit, há uma solução. Isso deve ser observado. A versatilidade é boa ao desenvolver no UDB Editor, mas ao desenvolver usando a Datapath Edit Tool, como você pode ver, as pessoas são atormentadas assim. Não se assuste se você não puder fazer isso universalmente (mas se funcionar melhor).
No nível superior (circuito), não vou parar, estamos estudando não trabalhando com PSoC, mas trabalhando com UDB. Vejamos uma opção de média complexidade - 16 bits, mas inteiro. Está localizado no diretório CJCU_B_Isqrt16_v1_0.
A primeira coisa a fazer é expandir o gráfico de transição do firmware. Sem ele, nem adivinharemos que tipo de algoritmo de raiz quadrada foi aplicado, já que o Google oferece uma escolha de vários algoritmos fundamentalmente diferentes.
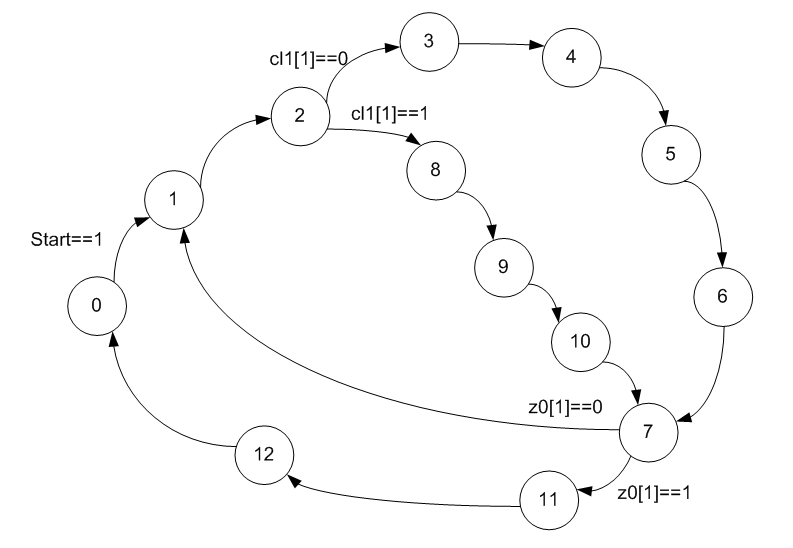
Até agora, nada está claro, mas é previsível. Precisa adicionar mais informações. Nós olhamos para a codificação de estado. É impressionante que eles não estejam codificados no código binário incremental usual.

Já mencionei essa abordagem em meus artigos, mas nunca consegui usá-la em exemplos específicos. Deixe-me lembrá-lo de que a configuração dinâmica da RAM ALU possui apenas três entradas de endereço. Ou seja, a ALU pode executar uma das oito operações. Se o autômato tiver mais estados, a regra "cada estado tem sua própria operação" se torna impossível. Portanto, são selecionados estados nos quais as operações da ALU são idênticas, elas têm três bits fornecidos ao endereço RAM da configuração dinâmica (geralmente de ordem baixa), são codificadas da mesma maneira e as demais de maneiras diferentes. Como adicionar esse paciência já é um problema do desenvolvedor. Os desenvolvedores do código estudado dobraram exatamente como mostrado acima.
Adicione essas informações ao gráfico, além de colorir os estados que executam a mesma função na ALU em cores semelhantes.
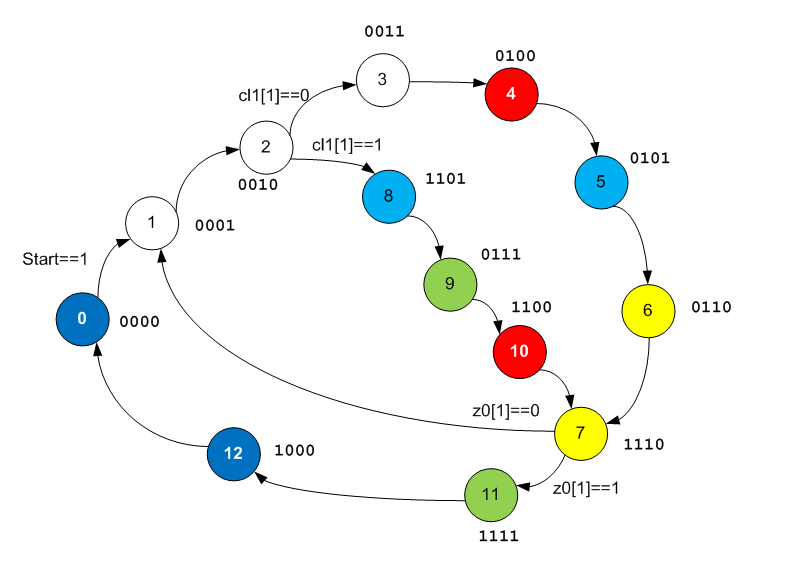
Nenhum padrão foi manifestado ainda, mas continuamos a abrir o gráfico. Abrimos a Ferramenta de Edição do Datapath e já estudamos a lógica nela.
Observe que temos dois blocos do Datapath conectados em uma cadeia. Quando fazemos algo próprio, também podemos precisar disso (a Ferramenta de edição do Datapath pode criar blocos já vinculados em uma cadeia, portanto, isso não é assustador):
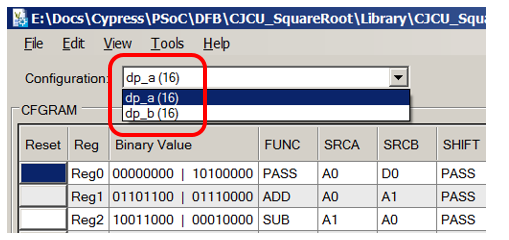
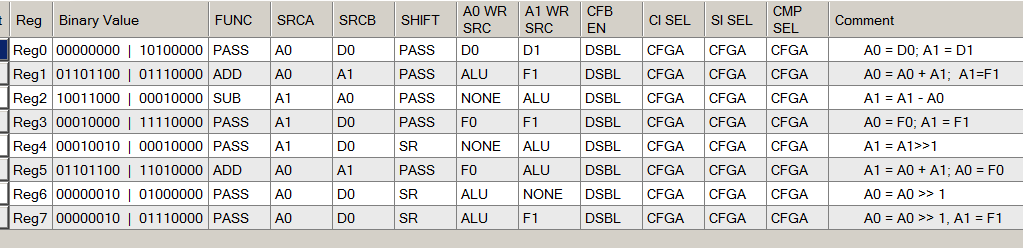
Ao ler (e preencher) o gráfico correspondente à ALU, sempre abrimos um documento com a seguinte figura:

É verdade que os desenvolvedores deste exemplo cuidaram de nós e preencheram os campos de comentários. Agora podemos usá-los para entender o que está configurado. Ao mesmo tempo, observamos por nós mesmos que escrever comentários é sempre útil tanto para quem acompanhará o código quanto para nós, quando em seis meses esqueceremos tudo sobre ele.
Observamos o código X000 correspondente aos estados 0 e 12:

A partir do comentário, já está claro o que está acontecendo lá (o conteúdo do registro D0 é copiado para o registro A0 e o conteúdo do D1 é copiado para o registro A1. Sabendo disso, treinamos nossa intuição para o futuro e encontramos uma entrada semelhante nos campos de configurações:

Lá vemos que a ULA opera no modo
PASS , o registro de turnos também é
PASS , para que nenhuma outra ação seja realmente executada.
Ao longo do caminho, examinamos o texto em Verilog e vemos onde o valor dos registros D0 e D1 é igual:

Se desejado, o mesmo pode ser visto na Ferramenta de configuração do Datapath, escolhendo Exibir-> Valores iniciais do registro:
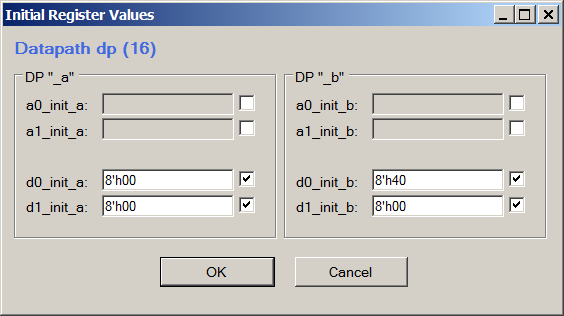
Para visualização, é mais conveniente analisar diretamente o código Verilog, criar sua própria versão - trabalhar no editor para não manter a sintaxe em mente.
Da mesma forma, analisamos (primeiro, espiando nos comentários) todas as outras funções da ALU:
Refazemos o gráfico de transição do autômato levando em consideração novos conhecimentos:

Algo já está aparecendo, mas até agora não posso confiar com confiança em nenhum dos algoritmos encontrados pelo Google neste gráfico. Em vez disso, sobre alguns, você pode dizer com segurança que não são eles, mas mesmo para os críveis, ainda não posso dar uma resposta confiante de que são eles. Confunde o uso ativo dos registradores FIFO F0 e F1. Geralmente no arquivo
\ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib \ CJCU_Isqrt_v1_0 \ API \ CJCU_Isqrt.c
pode-se ver que F1 é usado para passar o argumento e retornar o resultado:

Mesmo texto:void `$INSTANCE_NAME`_ComputeIsqrtAsync(uint`$regWidth` square) { /* Set up FIFOs, start the computation. */ CY_SET_REG`$dpWidth`(`$INSTANCE_NAME`_F1, square); CY_SET_REG8(`$INSTANCE_NAME`_CTL, 0x01); } … uint`$resultWidth` `$INSTANCE_NAME`_ReadIsqrtAsync() { /* Read back result. */ return CY_GET_REG`$dpWidth`(`$INSTANCE_NAME`_F1); }
Mas um argumento e um resultado. E por que existem tantas chamadas para o FIFO no decorrer do trabalho? E o que o FIFO0 tem a ver com isso? Corte-me em pedaços, mas parece que os autores aproveitaram o modo encontrado nas traduções da documentação. Quando, em vez de um FIFO de pleno direito, esse bloco agia como um único registro. Suponha que os autores decidam expandir o conjunto de registros. Nesse caso, a metodologia deles será útil para nós em nosso trabalho prático, vamos estudar os detalhes. De fato, a documentação fala sobre diferentes abordagens para trabalhar com o FIFO. Você pode - então, você pode - então, mas você pode - mais ou menos. E sem detalhes. Novamente, temos a chance de aprender sobre as melhores práticas internacionais. O que os autores fazem com o FIFO?
Primeiro, estas são as atribuições de sinal:
wire f0_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_4); wire f1_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_3 || state == B_SQRT_STATE_9 || state == B_SQRT_STATE_11); wire fifo_dyn = (state == B_SQRT_STATE_0 || state == B_SQRT_STATE_12);
Em segundo lugar, aqui está uma conexão com o Datapath:
/* input */ .f0_load(f0_load), /* input */ .f1_load(f1_load), /* input */ .d0_load(1'b0), /* input */ .d1_load(fifo_dyn),
Pela descrição do controlador, não está particularmente claro o que tudo isso significa. Mas, no Application Note, descobri que essa configuração é responsável por tudo:

A propósito, precisamente por causa dessa configuração, esse bloco não pode ser descrito usando o Editor UDB. Quando esses bits de controle estão no estado
ON , o FIFO pode trabalhar em diferentes fontes e receptores. Se
Dx_LOAD é igual a um, então
Fx troca com o barramento do sistema, se zero, com o registro selecionado aqui:

Acontece que F0 sempre troca com os registradores A0 e F1 nos estados 12 e 0 - com o barramento do sistema (para carregar o resultado e carregar o argumento), nos outros estados - com A1.
Além disso, a partir do código Verilog, descobrimos que em F0 os dados serão carregados nos estados 1 e 4 e em F1 - nos estados 1, 3, 9, 11.
Adicione o conhecimento adquirido ao gráfico. Para evitar confusão durante a sequência de operações, também era hora de substituir a marca de atribuição “a la UDB Editor” pelas setas Verilog, para enfatizar que a fonte é o valor do sinal que possuía antes de entrar no bloco.

Do ponto de vista da análise do algoritmo, tudo já está claro. Diante de nós está uma modificação de um algoritmo desse tipo:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 30; // The second-to-top bit is set: use 1u << 14 for uint16_t type; use 1uL<<30 for uint32_t type // "one" starts at the highest power of four <= than the argument. while (one > op) { one >>= 2; } while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Somente em relação ao nosso sistema será mais parecido com isto:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 14; // The second-to-top bit is set while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Os estados 4 e 10 codificam explicitamente a sequência:
res >>= 1;
para diferentes ramos.
A linha é:
one >>= 2;
é explicitamente codificado por um par de estados 6 e 7 ou por um par de estados 9 e 7. Por agora, quero exclamar: "Bem, os inventores são os mesmos autores!", mas logo ficará claro por que há tanta dificuldade com dois ramos (no código C há um ramo e solução alternativa).
O estado 2 codifica uma ramificação condicional. O estado 7 codifica uma instrução de loop. A operação de comparação na etapa 2 é muito cara. Em geral, na maioria das etapas, o registro A0 contém a variável Mas na etapa 1, a variável one é descarregada em F0 e, em vez disso, o valor de
res + one é carregado, na etapa 2 a subtração é executada para fins de comparação e nas etapas 3 e 8, o valor de
um é restaurado. Por que, na etapa 4, A0 é copiado para F0 novamente, eu não entendi. Talvez isso seja algum tipo de rudimento.
Resta descobrir quem é
res e quem é
op . Sabemos que a condição compara op e res + um. No estado 1, A0 (
um ) e A1 são adicionados. Portanto, A1 é
res . Acontece que no estado 11 A1 também é
res , e é ele quem entra em F1, que é alimentado com a saída da função. F1 no estado 1 é claramente
op . Proponho introduzir a diferenciação de cores das
calças das variáveis. Denotamos
res como vermelho,
op como verde e
um como marrom (não muito contrastado, mas as outras cores são ainda menos contrastadas).
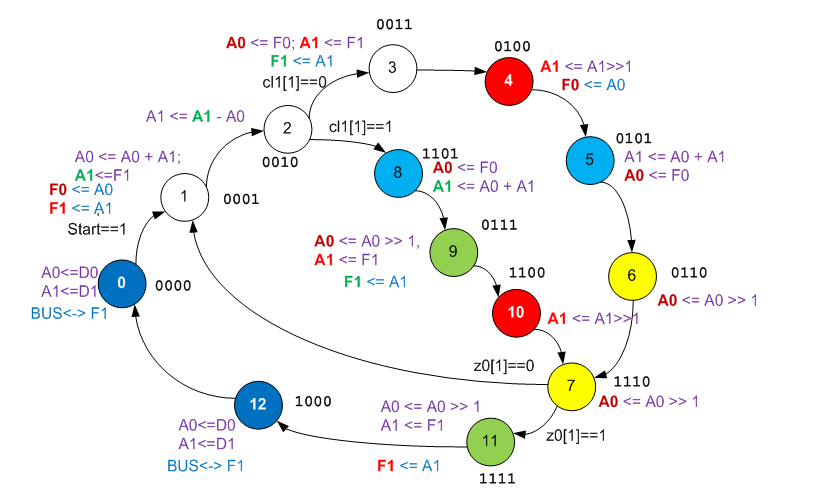
Na verdade, toda a verdade é revelada. Vemos como A1 famosa muda temporariamente de F1 para comparação e cálculos, como a mesma diferença é usada tanto para comparação (na verdade, gerando o bit C), quanto para participar da fórmula. Vimos até por que o espaço vazio (desvio) no algoritmo C é codificado por uma ramificação longa do gráfico de transição do autômato (nessa ramificação, os registros são trocados idênticos aos da troca que ocorre no ramo de código principal). Nós vemos tudo.
A única pergunta que nunca deixa de me atormentar é como os autores mudaram o FIFO para o modo de byte único? A documentação diz que, para isso, é necessário aumentar os bits CLR no registro do Controle Auxiliar em uma unidade, mas não vejo que a API tenha esses registros. Talvez alguém entenda isso e escreva nos comentários.
Bem, e desenvolver algo próprio - na ordem inversa, usando as habilidades adquiridas.
Conclusão
Para desenvolver as habilidades de desenvolver “firmware” baseado em UDB, é útil não apenas ler a documentação, mas também inspirar-se nos projetos de outras pessoas. O código que acompanha o PSoC Creator pode ser útil como referência, e os modelos comportamentais incluídos no compilador ajudarão você a entender melhor o significado da documentação. O artigo também fornece um link para um conjunto de exemplos de fabricantes de terceiros e mostra o processo de análise de um desses exemplos.
Sobre isso, o ciclo de artigos de direitos autorais sobre o trabalho com o UDB pode ser considerado concluído. Ficaria feliz se ele ajudasse alguém a obter conhecimento útil na prática. Existem algumas traduções de documentação adiante, mas as estatísticas mostram que quase ninguém as lê. Eles são planejados de maneira limpa, para não deixar o tópico em poucas palavras.