No processo de transição de um aplicativo monolítico para uma arquitetura de microsserviço, enfrentamos novos problemas.
Em um aplicativo monolítico, geralmente é bastante simples determinar em qual parte do sistema ocorreu um erro. Provavelmente, o problema está no código do próprio monólito ou no banco de dados. Mas quando começamos a procurar um problema na arquitetura de microsserviços, nem tudo é tão óbvio. Você precisa encontrar todo o caminho que a solicitação percorreu do começo ao fim, para selecioná-lo em centenas de microsserviços. Além disso, muitos deles também têm seus próprios repositórios, o que também pode causar erros lógicos, além de problemas com desempenho e tolerância a falhas.

Durante muito tempo, eu estava procurando por uma ferramenta que ajudasse a lidar com esses problemas (escrevi sobre ela em Habré: 1 , 2 ), mas, no final, criei minha própria solução de código aberto. No artigo, falo sobre os benefícios da abordagem de malha de serviço e compartilho uma nova ferramenta para sua implementação.
O rastreamento distribuído é uma solução comum para o problema de encontrar erros em sistemas distribuídos. Mas e se o sistema ainda não implementou essa abordagem para coletar informações sobre interações de rede ou, pior ainda, na parte do sistema que já funciona corretamente e na parte que não funciona, uma vez que não é adicionado aos serviços antigos? Para determinar a causa raiz exata do problema, você deve ter uma imagem completa do que está acontecendo no sistema. É especialmente importante entender quais microsserviços estão envolvidos nos principais caminhos críticos dos negócios.
Aqui, uma abordagem de malha de serviço pode vir em nosso auxílio, que lidará com todo o mecanismo para coletar informações de rede em um nível inferior ao que os próprios serviços fazem. Essa abordagem nos permite interceptar todo o tráfego e analisá-lo em tempo real. Além disso, os aplicativos a respeito nem deveriam saber de nada.
Abordagem de malha de serviço
A idéia principal da abordagem de malha de serviço é adicionar outra camada de infraestrutura na rede, o que nos permitirá fazer qualquer coisa com a interação entre serviços. A maioria das implementações funciona da seguinte maneira: um contêiner lateral adicional com um proxy transparente é adicionado a cada microsserviço, através do qual todo o tráfego de serviço de entrada e saída é passado. E é neste local que podemos fazer o balanceamento do cliente, aplicar políticas de segurança, introduzir restrições no número de solicitações e coletar informações importantes sobre a interação dos serviços na produção.
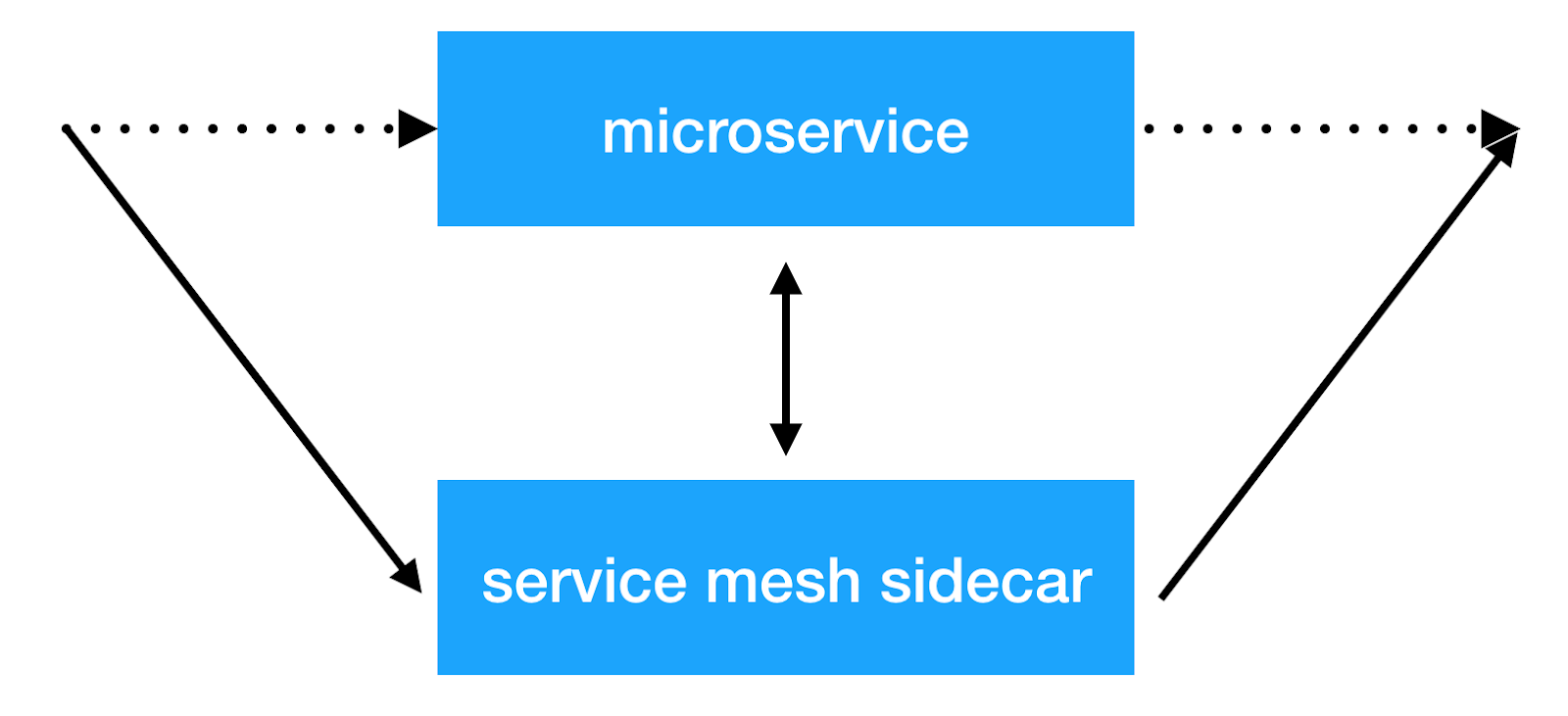
Soluções
Já existem várias implementações dessa abordagem: Istio e linkerd2 . Eles fornecem muitos recursos prontos para uso. Mas, ao mesmo tempo, uma grande sobrecarga chega a recursos. Além disso, quanto maior o cluster em que esse sistema funciona, mais recursos serão necessários para manter a nova infraestrutura. No Avito, operamos clusters kubernetes com milhares de instâncias de serviço (e seu número continua crescendo rapidamente). Na implementação atual, o Istio consome ~ 300Mb de RAM por instância de serviço. Devido ao grande número de recursos, o balanceamento transparente também afeta o tempo total de resposta dos serviços (até 10 ms).
Como resultado, analisamos exatamente quais recursos precisávamos no momento e decidimos que a principal razão pela qual começamos a implementar essas soluções era a capacidade de coletar informações de rastreamento de todo o sistema de forma transparente. Também queríamos ter controle sobre a interação dos serviços e fazer várias manipulações com os cabeçalhos transferidos entre os serviços.
No final, chegamos à nossa decisão: Netramesh .
Netramesh
O Netramesh é uma solução de malha de serviço leve com escalabilidade infinita, independentemente do número de serviços no sistema.
Os principais objetivos da nova solução foram uma pequena sobrecarga de recursos e alto desempenho. Dentre os principais recursos, imediatamente desejamos poder enviar transparentemente intervalos de rastreamento para o nosso sistema Jaeger.
Hoje, a maioria das soluções em nuvem é implementada no Golang. E, é claro, existem razões para isso. Escrever aplicativos de rede Golang que funcionam de forma assíncrona com E / S e escalonam para kernels conforme necessário é conveniente e bastante simples. E, o que também é muito importante, o desempenho é suficiente para resolver esse problema. Portanto, também escolhemos Golang.
Desempenho
Concentramos nossos esforços em obter o máximo desempenho. Para uma solução implantada ao lado de cada instância do serviço, é necessário um pequeno consumo de RAM e tempo do processador. E, é claro, o atraso na resposta também deve ser pequeno.
Vamos ver quais são os resultados.
RAM
O Netramesh consome ~ 10 Mb sem tráfego e 50 Mb no máximo, com uma carga de até 10.000 RPS por instância.
O proxy enviado do Istio sempre consome ~ 300Mb em nossos clusters com milhares de instâncias. Isso não permite dimensioná-lo para todo o cluster.
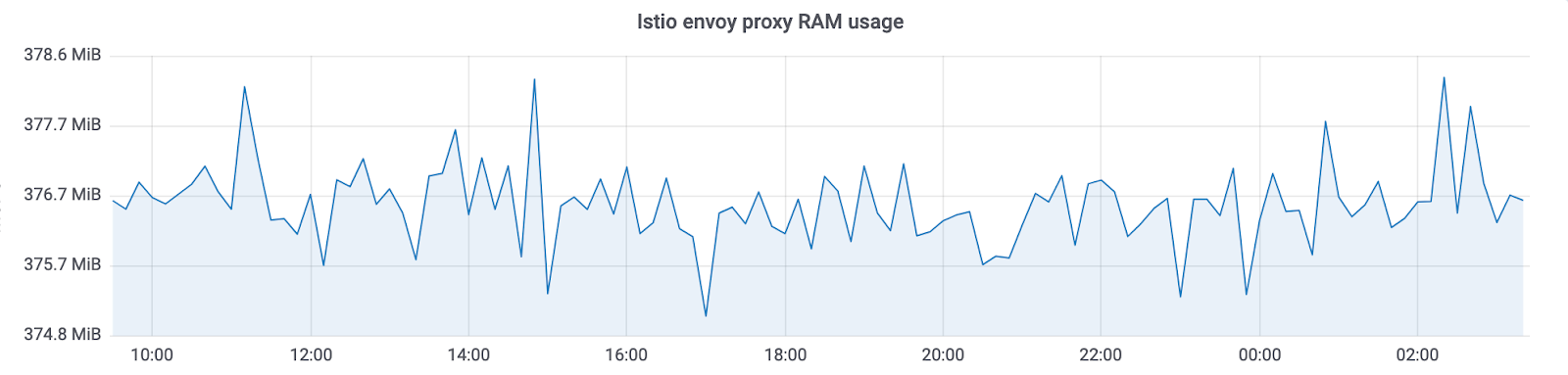

Com o Netramesh, obtivemos ~ 10 vezes menos consumo de memória.
CPU
O uso da CPU é relativamente igual sob carga. Depende do número de solicitações por unidade de tempo para o side-car. Valores em 3000 solicitações por segundo no pico:


Há outro ponto importante: Netramesh - uma solução sem um plano de controle e sem carga não consome tempo da CPU. Com o Istio, os sidecar sempre atualizam os terminais de serviço. Como resultado, podemos ver uma imagem sem carga:

Usamos HTTP / 1 para nos comunicarmos entre serviços. O aumento no tempo de resposta para o Istio quando o proxy através do enviado era de 5 a 10 ms, o que é bastante para serviços prontos para responder em um milissegundo. Com o Netramesh, esse tempo diminuiu para 0,5-2ms.
Escalabilidade
Uma pequena quantidade de recursos gastos por cada proxy possibilita colocá-lo ao lado de cada serviço. O Netramesh foi criado intencionalmente sem um componente do plano de controle para simplesmente manter a leveza de cada carro lateral. Geralmente, em soluções de malha de serviço, o plano de controle distribui informações de descoberta de serviço para cada carro lateral. Junto com ele, há informações sobre tempos limite, configurações de balanceamento. Tudo isso permite que você faça muitas coisas úteis, mas, infelizmente, aumenta de tamanho lateralmente.
Descoberta de serviço

O Netramesh não adiciona nenhum mecanismo adicional para descoberta de serviço. Todo o tráfego é proxy de forma transparente através do carro lateral netra.
O Netramesh suporta o protocolo de aplicativo HTTP / 1. Uma lista configurável de portas é usada para determiná-lo. Normalmente, existem várias portas em um sistema que se comunicam por HTTP. Por exemplo, usamos 80, 8890, 8080 para interagir com serviços e solicitações externas.Neste caso, eles podem ser configurados usando a NETRA_HTTP_PORTS ambiente NETRA_HTTP_PORTS .
Se você usar o Kubernetes como uma orquestra e seu mecanismo de entidades de Serviço para interação intracluster entre serviços, o mecanismo permanecerá exatamente o mesmo. Primeiro, o microsserviço obtém o endereço IP do serviço usando o kube-dns e abre uma nova conexão a ele. Essa conexão é estabelecida primeiro com o netra-sidecar local, e todos os pacotes TCP chegam inicialmente no netra. Em seguida, o netra-sidecar estabelece uma conexão com o destino original. O NAT no IP do pod no nó permanece exatamente o mesmo que sem o netra.
Rastreamento distribuído e rolagem de contexto
O Netramesh fornece a funcionalidade necessária para enviar intervalos de rastreamento sobre interações HTTP. O Netra-sidecar analisa o protocolo HTTP, mede os atrasos na solicitação, recupera as informações necessárias dos cabeçalhos HTTP. Por fim, obtemos todos os rastreamentos em um único sistema Jaeger. Para o ajuste fino , você também pode usar as variáveis de ambiente fornecidas pela biblioteca oficial do jaeger go .


Mas há um problema. Até que os serviços gerem e encaminhem um cabeçalho uber especial, não veremos os intervalos de rastreamento conectados no sistema. E é isso que precisamos para encontrar rapidamente a causa dos problemas. Aqui o Netramesh tem uma solução novamente. Os proxies leem os cabeçalhos HTTP e, se não tiverem um ID de rastreamento uber, gere-o. O Netramesh também armazena informações sobre solicitações de entrada e saída no sidecar e as compara, enriquecendo os cabeçalhos necessários das solicitações de saída. Tudo o que precisa ser feito nos serviços é lançar apenas um cabeçalho X-Request-Id , que pode ser configurado usando a NETRA_HTTP_REQUEST_ID_HEADER_NAME ambiente NETRA_HTTP_REQUEST_ID_HEADER_NAME . Para controlar o tamanho do contexto no Netramesh, você pode definir as seguintes variáveis de ambiente: NETRA_TRACING_CONTEXT_EXPIRATION_MILLISECONDS (o tempo durante o qual o contexto será armazenado) e NETRA_TRACING_CONTEXT_CLEANUP_INTERVAL (periodicidade da limpeza de contexto).
Também é possível combinar vários caminhos no seu sistema, marcando-os com um marcador de sessão especial. O Netra permite definir HTTP_HEADER_TAG_MAP para transformar cabeçalhos HTTP em tags de extensão de rastreio apropriadas. Isso pode ser especialmente útil para testes. Depois de passar no teste funcional, você pode ver qual parte do sistema foi afetada pela filtragem pela chave da sessão correspondente.
Determinando a origem da solicitação
Para determinar de onde veio a solicitação, você pode usar a função para adicionar automaticamente um cabeçalho a uma fonte. Usando a NETRA_HTTP_X_SOURCE_HEADER_NAME ambiente NETRA_HTTP_X_SOURCE_HEADER_NAME você pode especificar o nome do cabeçalho que será definido automaticamente. Usando NETRA_HTTP_X_SOURCE_VALUE você pode definir o valor no qual o cabeçalho X-Source será definido para todas as solicitações de saída.
Isso permite que você uniformemente em toda a rede faça a distribuição desse cabeçalho útil. Então você já pode usá-lo em serviços e adicioná-lo a logs e métricas.
Tráfego Netramesh e roteamento interno
O Netramesh consiste em dois componentes principais. O primeiro, netra-init, define regras de rede para interceptar tráfego. Ele usa regras de redirecionamento do iptables para interceptar todo ou parte do tráfego no side-car, que é o segundo componente principal do Netramesh. Você pode configurar as portas que deseja interceptar para as sessões TCP de entrada e saída: INBOUND_INTERCEPT_PORTS, OUTBOUND_INTERCEPT_PORTS .
A ferramenta também possui um recurso interessante - roteamento probabilístico. Se você usar o Netramesh exclusivamente para coletar extensões de rastreamento, em um ambiente de produção, poderá economizar recursos e ativar o roteamento probabilístico usando as variáveis NETRA_INBOUND_PROBABILITY e NETRA_OUTBOUND_PROBABILITY (de 0 a 1). O valor padrão é 1 (todo o tráfego é interceptado).
Após uma interceptação bem-sucedida, o netra sidecar aceita uma nova conexão e usa a opção de soquete SO_ORIGINAL_DST para obter o destino original. O Netra então abre uma nova conexão com o endereço IP original e estabelece uma comunicação TCP bidirecional entre as partes, ouvindo todo o tráfego que passa. Se a porta for definida como HTTP, o Netra tentará analisá-la e encaminhá-la. Se a análise HTTP não for bem-sucedida, o Netra fará fallback no TCP e nos bytes de proxy transparentemente.
Construindo um gráfico de dependência
Depois de receber muitas informações de rastreamento em Jaeger, quero obter um gráfico completo das interações no sistema. Mas se o seu sistema estiver suficientemente carregado e bilhões de extensões de rastreamento se acumularem por dia, tornar sua agregação uma tarefa não tão simples. Existe uma maneira oficial de fazer isso: dependências de centelha . No entanto, levará horas para criar o gráfico completo e forçar o download de todo o conjunto de dados do Jaeger nas últimas 24 horas.
Se você usar o Elasticsearch para armazenar intervalos de rastreamento, poderá usar um utilitário simples no Golang que criará o mesmo gráfico em minutos usando os recursos e os recursos do Elasticsearch.
Como usar o Netramesh
O Netra pode ser simplesmente adicionado a qualquer serviço que esteja executando qualquer orquestrador. Você pode ver um exemplo aqui .
No momento, a Netra não tem a capacidade de implantar side-car automaticamente nos serviços, mas há planos de implementação.
Future Netramesh
O principal objetivo do Netramesh é alcançar custos mínimos de recursos e alto desempenho, oferecendo as principais oportunidades de observabilidade e controle da interação entre serviços.
No futuro, o Netramesh receberá suporte para protocolos em nível de aplicativo que não sejam HTTP. Em um futuro próximo, haverá a possibilidade de roteamento L7.
Use o Netramesh se encontrar problemas semelhantes e escreva-nos perguntas e sugestões.