No relatório do desenvolvedor sênior Sergey Murylyov, você pode aprender sobre o contêiner associativo multithread para a biblioteca padrão, que está sendo desenvolvida como parte do WG21. Sergey falou sobre os prós e contras de soluções populares para esse problema e o caminho escolhido pelos desenvolvedores.
- Você provavelmente já adivinhou a partir do título que o relatório de hoje será sobre como, na estrutura do Grupo de Trabalho 21, tornamos nosso contêiner semelhante ao std :: unordered_map, mas para um ambiente multithread.
Em muitas linguagens de programação - Java, C #, Python - isso já existe e é amplamente utilizado. Mas em nosso amado, mais rápido e produtivo C ++, isso não aconteceu. Mas consultamos e decidimos fazer uma coisa dessas.

Antes de adicionar algo ao padrão, você precisa pensar em como as pessoas o usarão. Em seguida, faça uma interface mais correta, que provavelmente será adotada pelo comitê - de preferência sem alterações. E para que, no final, não houvesse tal coisa que eles fizessem uma coisa, mas acabou outra.
A opção mais famosa e amplamente usada é o armazenamento em cache de grandes computadores pesados. Existe um serviço Memcached bastante conhecido que simplesmente armazena em cache as respostas do servidor da Web na memória. É claro que você pode fazer aproximadamente a mesma coisa no lado do seu aplicativo, se você tiver um contêiner associativo competitivo. Ambas as abordagens têm seus prós e contras. Mas se você não tiver esse recipiente, precisará fabricar sua própria bicicleta ou usar algum tipo de Memcached.
Outro caso de uso popular é a deduplicação de eventos. Acho que muitos nesta sala escrevem todos os tipos de sistemas distribuídos e sabem que filas frequentemente distribuídas são usadas para se comunicar entre componentes, como Apache Kafka e Amazon Kinesis. Eles se distinguem por esse recurso que podem enviar uma mensagem para um consumidor várias vezes. Isso é chamado pelo menos uma vez na entrega, o que significa uma garantia de entrega pelo menos uma vez: mais é possível, menos não é.
Considere isso em termos da vida real. Imagine que temos algum back-end de alguma sala de bate-papo ou rede social onde as mensagens ocorrem. Isso pode levar ao fato de que alguém escreveu uma mensagem e mais tarde recebeu uma notificação por push no celular várias vezes. É claro que se os usuários virem isso, eles não ficarão felizes com isso. Argumenta-se que esse problema pode ser resolvido com um maravilhoso recipiente multiencadeado.
O próximo caso menos usado é quando precisamos salvar algo em algum lugar do lado do servidor, alguns metadados para o usuário. Por exemplo, podemos economizar o tempo em que o usuário foi autenticado pela última vez, para entender quando na próxima vez em que ele deve ser solicitado a fornecer seu nome de usuário e senha.
A última opção neste slide é estatística. A partir de aplicativos da vida real, um exemplo de uso em uma máquina virtual do Facebook pode ser dado. Eles criaram uma máquina virtual inteira para otimizar o PHP e, em sua máquina virtual, tentam anotar os argumentos com os quais foram chamados em uma tabela de hash multiencadeada para todas as funções internas. E se eles tiverem um resultado no cache, eles tentarão entregá-lo imediatamente e não contar nada.

Adicionar algo grande e complicado ao padrão não é fácil nem rápido. Como regra, se algo grande é adicionado, ele passa pelas especificações técnicas. Atualmente, o padrão está mudando bastante para expandir o suporte a multithreading na biblioteca padrão. E, especificamente, a proposta P0260R3 sobre filas multithread está chegando lá agora. Essa proposta é sobre uma estrutura de dados muito semelhante a nós e nossas decisões de design são muito semelhantes em muitos aspectos.
Na verdade, um dos conceitos básicos de seu design é que sua interface é diferente da fila padrão std ::. Qual é o objetivo? Se você observar a fila padrão, para extrair um elemento dela, precisará executar duas operações. Você precisa executar uma operação frontal para contar e uma operação pop para excluir. Se trabalharmos sob condições de multithreading, poderemos ter algum tipo de operação na fila entre essas duas chamadas, e pode considerar que consideramos um elemento e excluímos outro, o que parece conceitualmente incorreto. Portanto, essas duas chamadas foram substituídas por uma e foram adicionadas mais algumas chamadas da categoria de tentativa de push e tentativa de pop. Mas a idéia geral é que um contêiner multithread não será o mesmo que uma interface normal.
As filas multithread também têm muitas implementações diferentes que resolvem várias tarefas diferentes. A tarefa mais comum é a de produtores e consumidores, quando temos alguns threads que produzem algumas tarefas e existem alguns threads que retiram tarefas da fila e as processam.
O segundo caso é quando precisamos apenas de algum tipo de fila sincronizada. No caso de fabricantes e consumidores, temos uma fila que é limitada à parte superior e inferior. Se tentarmos, relativamente falando, extrair de uma fila vazia, entraremos em um estado de espera. E o mesmo acontece aproximadamente se tentarmos adicionar algo que não se encaixa na fila de tamanho.
Também nesta proposta, é descrito que temos uma interface criada separadamente, que nos permite distinguir qual implementação temos dentro do bloqueio ou sem bloqueio. O fato de que aqui em toda parte da proposta está escrito sem bloqueios, na verdade, está escrito em livros como sem espera. Isso significa que nosso algoritmo funciona para um número fixo de operações. Bloquear livre significa um pouco diferente, mas esse não é o ponto.
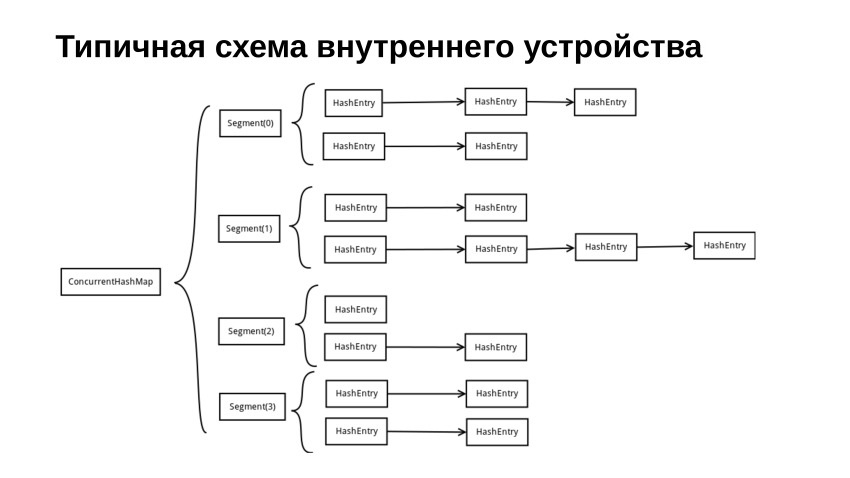
Vejamos um diagrama típico de como a implementação de nossa tabela de hash pode parecer se estiver bloqueada. Nós o dividimos em vários segmentos. Cada segmento, como regra, contém algum tipo de bloqueio, como Mutex, Spinlock ou algo ainda mais complicado. Além de Mutex ou Spinlock, ele também contém a tabela de hash usual, protegida por esse negócio.
Nesta figura, temos uma tabela de hash, feita nas listas. De fato, em nossa implementação de referência, escrevemos uma tabela de hash com endereçamento aberto por motivos de desempenho. As considerações de desempenho são basicamente as mesmas de por que o std :: vector é mais rápido que o std :: list porque o vetor, relativamente falando, é armazenado sequencialmente na memória. Quando o acompanhamos, temos acesso seqüencial, que é bem armazenado em cache. Se usarmos algum tipo de planilha, teremos todos os tipos de saltos entre diferentes seções da memória. E a coisa toda, em regra, termina com o fato de que perdemos produtividade.
No início, quando queremos encontrar algo nessa tabela de hash, pegamos o código de hash da chave. Você pode usar o módulo e fazer outra coisa com ele para obter o número do segmento e no segmento que estamos procurando, como em uma tabela de hash regular, mas ao mesmo tempo naturalmente fechamos o bloqueio.

As principais idéias do nosso design. Obviamente, também criamos uma interface que não corresponde a std :: unordered_map. A razão é essa. Por exemplo, no std :: unordered_map comum, temos algo maravilhoso como iteradores. Em primeiro lugar, nem todas as implementações podem suportá-las normalmente. E aqueles que podem suportar, como regra, são algum tipo de implementações sem bloqueio que exigem uma coleta de lixo ou algum tipo de ponteiro inteligente que limpe a memória por trás dela.
Além disso, existem vários outros tipos de operações que descartamos. De fato, iteradores, eles estão em muitos lugares. Por exemplo, eles estão em Java. Mas, por via de regra, curiosamente, eles não são sincronizados lá. E se você tentar fazer algo com eles a partir de diferentes threads, eles poderão facilmente entrar em um estado inválido, e você poderá obter uma exceção em Java. Se você escrever isso nas vantagens, provavelmente será um comportamento indefinido, o que é ainda pior. . E, a propósito, sobre o tema de comportamento indefinido: na minha opinião, camaradas do Facebook em sua biblioteca loucura, publicada em código aberto no GitHub, fizeram exatamente isso. Apenas copiei a interface com Java e obtive iteradores maravilhosos.
Também não temos uma reclamação de memória, ou seja, se adicionarmos algo ao contêiner e levarmos memória para ele, não o devolveremos, mesmo se excluirmos tudo. Outro pré-requisito para essa decisão é que tenhamos uma tabela de hash com endereçamento aberto. Ele funciona em uma estrutura de dados linear, que como vetor não devolve memória.
O próximo momento conceitual é que, sob nenhuma circunstância, daremos a alguém links externos e indicadores para objetos internos. Isso foi feito com precisão para evitar a necessidade de uma coleta de lixo e não aplicar indicadores inteligentes. É claro que, se armazenarmos objetos grandes o suficiente, armazená-los por valor interno será inútil. Mas, nesse caso, sempre podemos envolvê-los em algum tipo de ponteiro inteligente de nossa escolha. E, se quisermos, por exemplo, fazer algum tipo de sincronização nos valores, podemos envolvê-los em algum tipo de boost :: synchronized_value.
Vimos o fato de que, há algum tempo, a classe shared_ptr foi removida do método que retornou o número de links ativos para esse objeto. E chegamos à conclusão de que também precisamos jogar várias funções, a saber, tamanho, contagem, vazio, buckets_count, porque assim que retornamos esse valor da função, ele deixa de ser válido imediatamente, porque alguém pode mude o mesmo momento.
Em uma de nossas reuniões anteriores, eles nos pediram para adicionar um tipo de modo para que pudéssemos acessar nosso contêiner no modo de thread único, como um std :: unordered_map comum. Essa semântica nos permite distinguir claramente onde trabalhamos no modo multithread e onde não. E para evitar algumas situações desagradáveis quando as pessoas pegam um contêiner de vários segmentos, espere que tudo fique bem com elas, faça iteradores e, de repente, acontece que tudo está ruim.

Nesta reunião no Havaí, toda uma proposta foi escrita contra nós. :) Disseram-nos que essas coisas não têm lugar no padrão, porque existem muitas maneiras de criar seu contêiner associativo multithread.
Cada um tem seus prós e contras - e não está claro como usar o que obtemos no final das contas. Como regra, ele é usado quando você precisa de algum tipo de desempenho extremo. E parece que nossa solução in a box não é adequada, é necessário otimizar para cada caso específico.
O segundo ponto desta proposta foi que nossa interface não é compatível com o fato de o Facebook ter postado no GitHub a partir de sua biblioteca padrão.
De fato, não havia problemas particulares lá. Simplesmente havia uma pergunta da categoria "Eu não li, mas condeno". Eles apenas olharam - a interface é diferente, o que significa que não é compatível.
A ideia da proposta também era que tarefas semelhantes fossem resolvidas com a ajuda do chamado design baseado em políticas, quando for necessário criar um parâmetro de modelo adicional no qual você possa passar uma máscara de bit com quais recursos queremos ativar e quais desativar. De fato, isso parece um pouco selvagem e leva ao fato de termos cerca de 2 ^ n implementações, onde n é o número de recursos diferentes.

No código, é algo parecido com isto. Temos algum tipo de parâmetro e um número de constantes predefinidas que podem ser passadas para lá. Curiosamente, esta proposta foi rejeitada.

Porque, de fato, o comitê já assumiu a posição de que tais coisas deveriam ser quando a fila multiencadeada passou pelo SG1. Não houve sequer uma votação sobre esta questão. Mas duas perguntas foram colocadas à votação.
Primeiro. Muitas pessoas nos queriam do lado de nossa implementação de referência para dar suporte à leitura sem bloquear nenhum bloqueio. Para que tenhamos uma leitura completamente sem bloqueio. Realmente faz sentido: como regra, o caso de usuário mais popular é o cache. E é muito benéfico para nós ter uma leitura rápida.
Segundo momento. Todo mundo ouviu muito do amigo anterior que falou sobre o design baseado em políticas. Todo mundo teve uma ideia - mas o que, deixe-me falar sobre a minha ideia também! E todos votaram para ter um design baseado em políticas. Embora deva ser dito, toda essa história vem acontecendo há algum tempo, e os colegas da Intel, Arch Robinson e Anton Malakhov estavam fazendo isso antes de nós. E eles já tinham várias propostas sobre esse assunto. Eles apenas se ofereceram para adicionar uma implementação sem bloqueio, com base no algoritmo
SeepOrderedList . E eles também tinham um design baseado em políticas com a reclamação de memória.
E essa proposta não gostou do Grupo de Trabalho sobre Evolução da Biblioteca. Foi encerrado com a razão de que simplesmente teremos um aumento ilimitado no número de palavras no padrão. Será simplesmente impossível visualizar e implementar adequadamente o código.
Não temos comentários sobre as próprias idéias. Temos comentários, na maior parte, sobre a implementação de referência. E, claro, temos algumas idéias que podem ser introduzidas para torná-lo mais claro. Mas essencialmente, da próxima vez, iremos com a mesma proposta. Esperamos sinceramente que não tenhamos, como nos módulos, cinco chamadas com a mesma proposta. Acreditamos sinceramente em nós mesmos e que poderemos prosseguir para a próxima convocação, e que o Grupo de Trabalho sobre Evolução da Biblioteca, no entanto, insistirá em nossa opinião e não nos permitirá avançar com o design baseado em políticas. Porque nosso oponente não para. Ele decidiu provar a todos que era necessário. Mas como se costuma dizer, o tempo dirá. Eu tenho tudo, obrigado por sua atenção.