
Todo mundo percebe de maneira única os textos, independentemente de essa pessoa ler notícias na Internet ou romances clássicos mundialmente conhecidos. Isso também se aplica a uma variedade de algoritmos e técnicas de aprendizado de máquina, que compreendem textos de uma maneira mais matemática, ou seja, usando espaço vetorial de alta dimensão.
Este artigo é dedicado à visualização de incorporações de palavras do Word2Vec de alta dimensão usando t-SNE. A visualização pode ser útil para entender como o Word2Vec funciona e como interpretar relações entre vetores capturados em seus textos antes de usá-los em redes neurais ou em outros algoritmos de aprendizado de máquina. Como dados de treinamento, usaremos artigos do Google Notícias e obras literárias clássicas de Leo Tolstoy, o escritor russo considerado um dos maiores autores de todos os tempos.
Analisamos a breve visão geral do algoritmo t-SNE, depois passamos para o cálculo de incorporação de palavras usando o Word2Vec e, finalmente, prosseguimos para a visualização de vetores de palavras com t-SNE no espaço 2D e 3D. Escreveremos nossos scripts em Python usando o Jupyter Notebook.
Incorporação estocástica de vizinhos distribuídos em T
O T-SNE é um algoritmo de aprendizado de máquina para visualização de dados, baseado em uma técnica de redução de linearidade não linear. A idéia básica do t-SNE é reduzir o espaço dimensional, mantendo a distância pareada entre os pontos. Em outras palavras, o algoritmo mapeia dados multidimensionais para duas ou mais dimensões, onde pontos que inicialmente estavam distantes um do outro também estão localizados longe, e pontos próximos também são convertidos em pontos próximos. Pode-se dizer que o t-SNE procura uma nova representação de dados onde as relações de vizinhança são preservadas. A descrição detalhada de toda a lógica do t-SNE pode ser encontrada no artigo original [1].
O modelo Word2Vec
Para começar, devemos obter representações vetoriais de palavras. Para esse fim, selecionei o Word2vec [2], ou seja, um modelo preditivo computacionalmente eficiente para aprender a incorporação de palavras multidimensionais a partir de dados textuais brutos. O conceito principal do Word2Vec é localizar palavras, que compartilham contextos comuns no corpus de treinamento, em estreita proximidade no espaço vetorial em comparação com outros.
Como dados de entrada para visualização, usaremos artigos do Google Notícias e alguns romances de Leo Tolstoy. Vetores pré-treinados, treinados em parte do conjunto de dados do Google Notícias (cerca de 100 bilhões de palavras), foram publicados pelo Google na
página oficial , portanto, vamos usá-lo.
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Além do modelo pré-treinado, treinaremos outro modelo nos romances de Tolstoi usando a biblioteca Gensim [3]. O Word2Vec usa sentenças como dados de entrada e produz vetores de palavras como saída. Primeiro, é necessário fazer o download do Punkt Sentença Tokenizer pré-treinado, que divide um texto em uma lista de frases, considerando palavras de abreviação, colocações e palavras, o que provavelmente indica o início ou o fim das frases. Por padrão, o pacote de dados NLTK não inclui um tokenizador Punkt pré-treinado para russo; portanto, usaremos modelos de terceiros em
github.com/mhq/train_punkt .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
No estágio de treinamento do Word2Vec, foram utilizados os seguintes hiperparâmetros:
- A dimensionalidade do vetor de recurso é 200.
- A distância máxima entre as palavras analisadas em uma frase é 5.
- Ignora todas as palavras com a frequência total menor que 5 por corpus.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualizando incorporações de palavras usando t-SNE
O T-SNE é bastante útil caso seja necessário visualizar a semelhança entre objetos que estão localizados no espaço multidimensional. Com um grande conjunto de dados, está se tornando cada vez mais desafiador fazer um gráfico t-SNE fácil de ler, por isso é prática comum visualizar grupos das palavras mais semelhantes.
Vamos selecionar algumas palavras do vocabulário do modelo pré-treinado do Google Notícias e preparar vetores de palavras para visualização.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
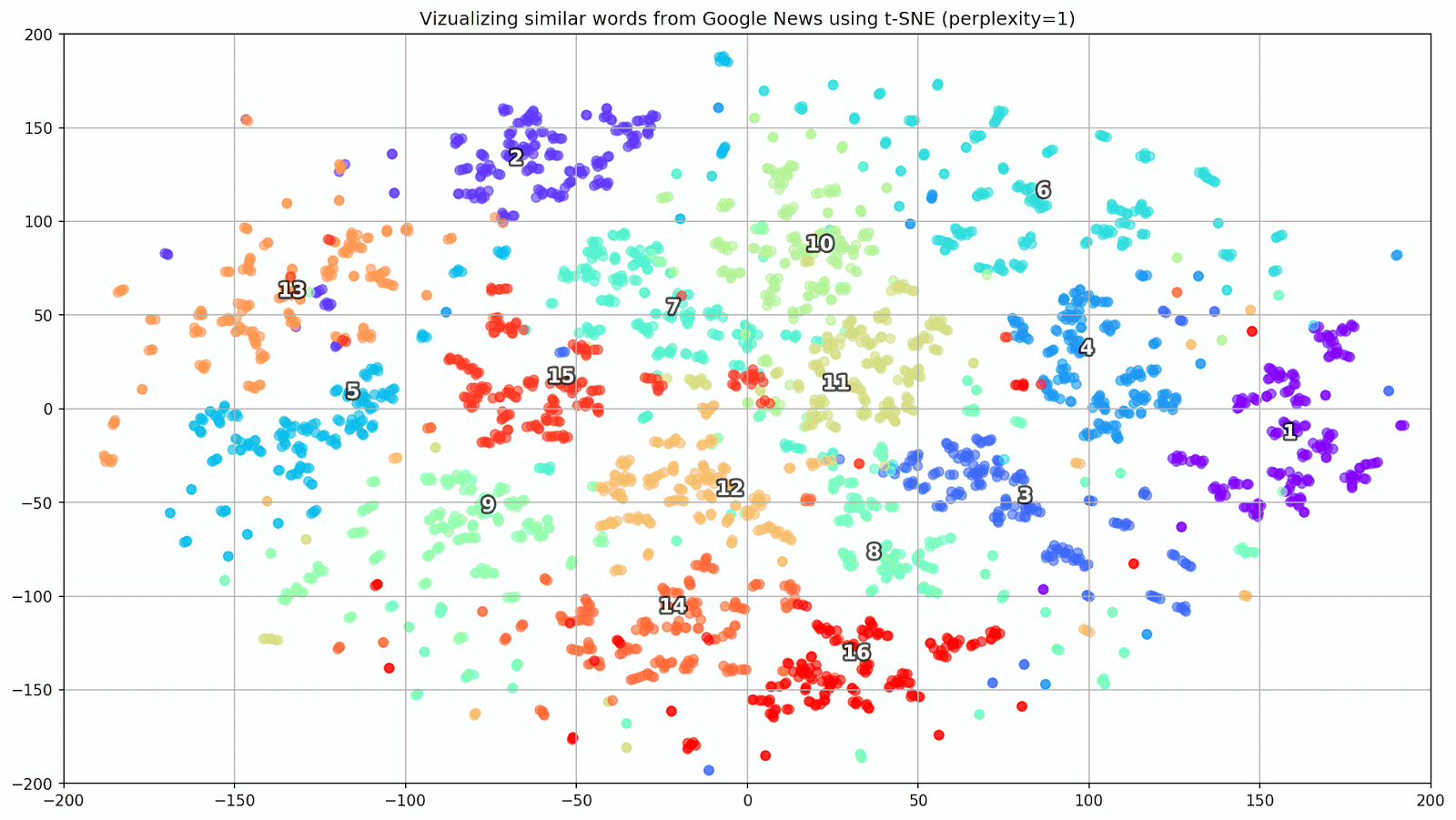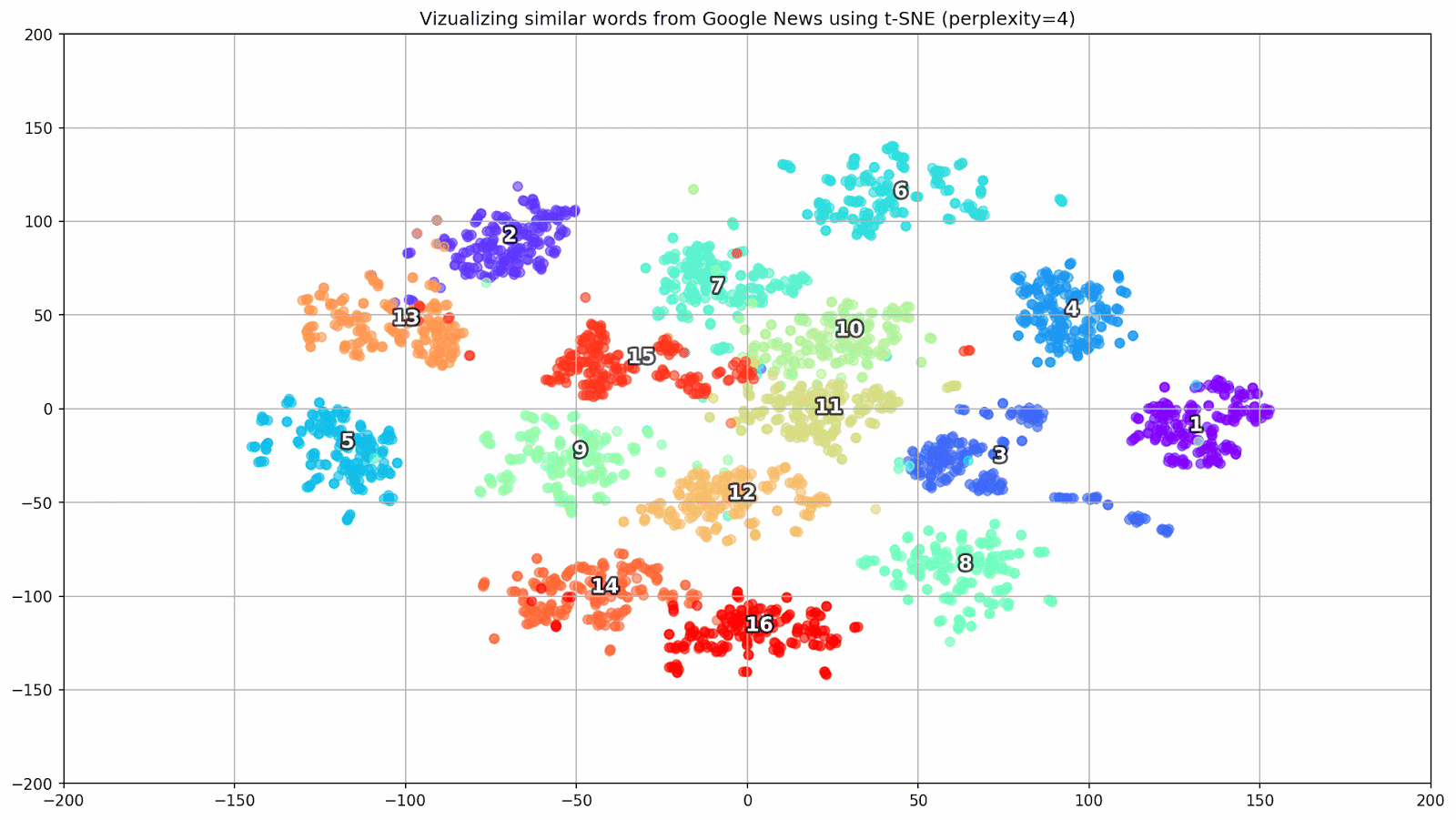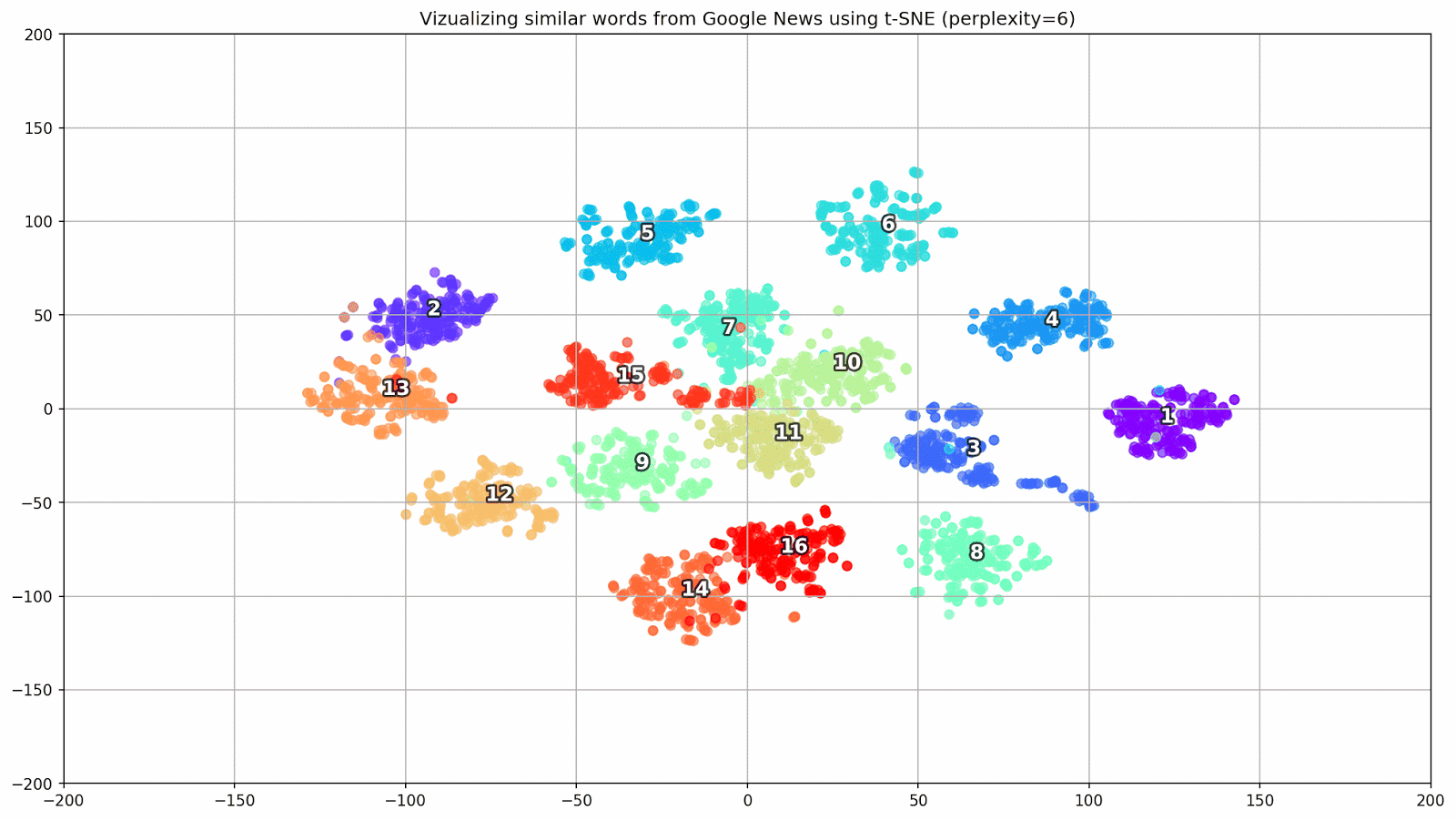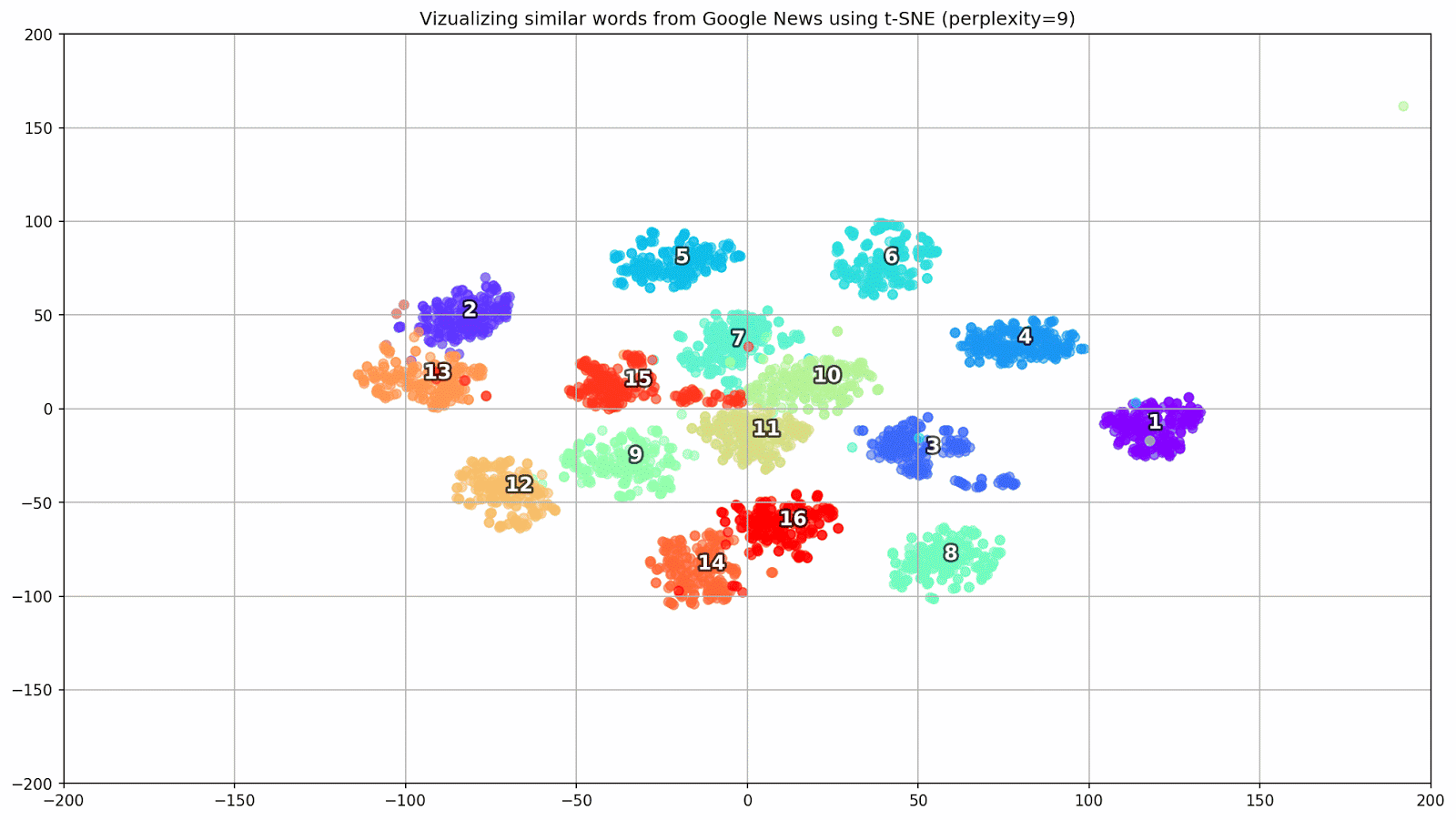 Fig. 1. O efeito de vários valores de perplexidade na forma dos conjuntos de palavras.
Fig. 1. O efeito de vários valores de perplexidade na forma dos conjuntos de palavras.Em seguida, prosseguimos para a parte fascinante deste artigo, a configuração do t-SNE. Nesta seção, devemos prestar atenção aos seguintes hiperparâmetros.
- O número de componentes , ou seja, a dimensão do espaço de saída.
- O valor da perplexidade , que no contexto do t-SNE, pode ser visto como uma medida suave do número efetivo de vizinhos. Está relacionado ao número de vizinhos mais próximos empregados em muitos outros alunos múltiplos (veja a figura acima). De acordo com [1], é recomendável selecionar um valor entre 5 e 50.
- O tipo de inicialização inicial para incorporação.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Deve-se mencionar que o t-SNE tem uma função objetiva não convexa, que é minimizada usando uma otimização de descida gradiente com iniciação aleatória, para que execuções diferentes produzam resultados ligeiramente diferentes.
Abaixo, você encontra um script para criar um gráfico de dispersão 2D usando o Matplotlib, uma das bibliotecas mais populares para visualização de dados no Python.
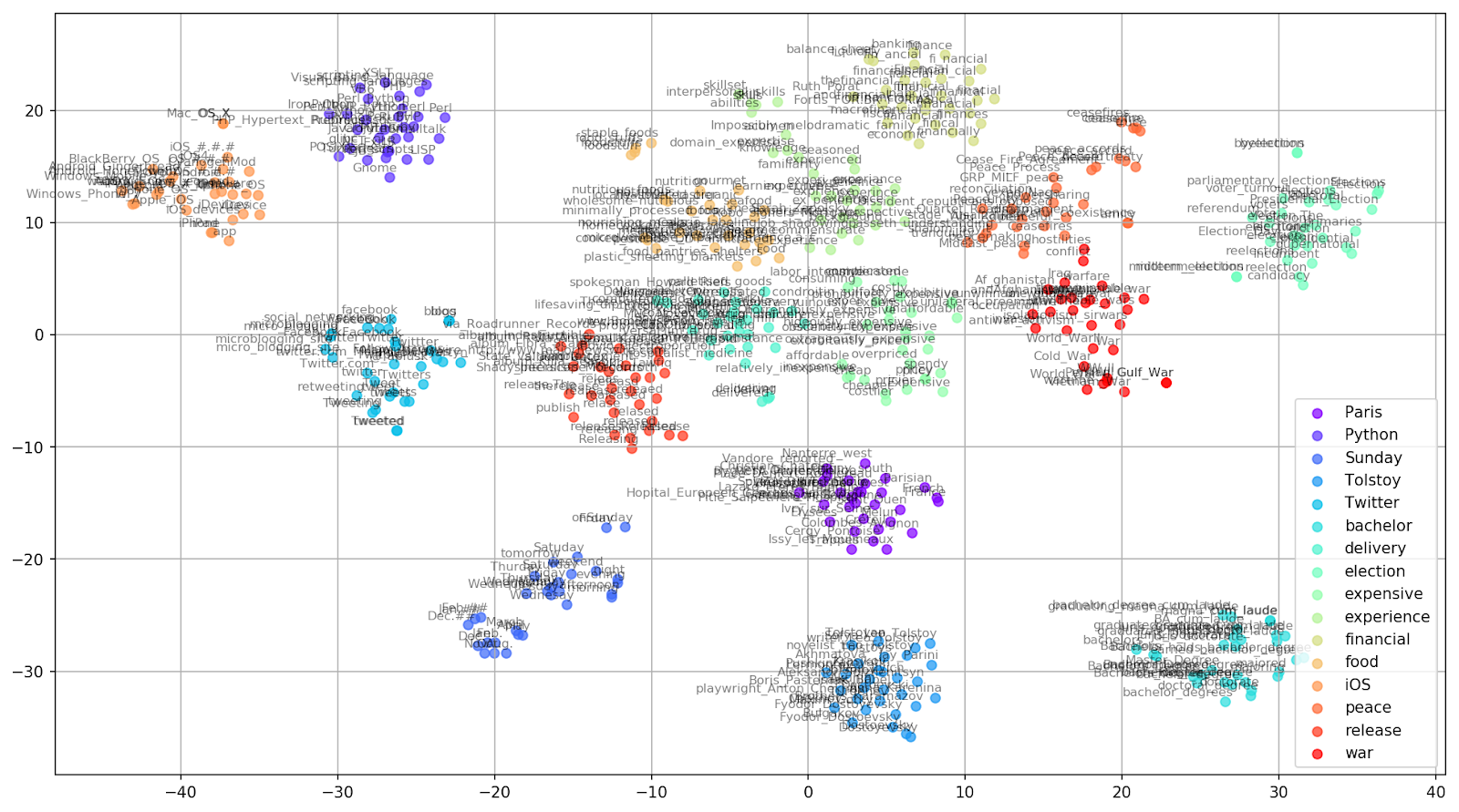 Fig. 2. Clusters de palavras semelhantes do Google Notícias (preplexidade = 15).
Fig. 2. Clusters de palavras semelhantes do Google Notícias (preplexidade = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
Em alguns casos, pode ser útil plotar todos os vetores de palavras de uma só vez para ver a figura inteira. Vamos agora analisar Anna Karenina, um romance épico de paixão, intriga, tragédia e redenção.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
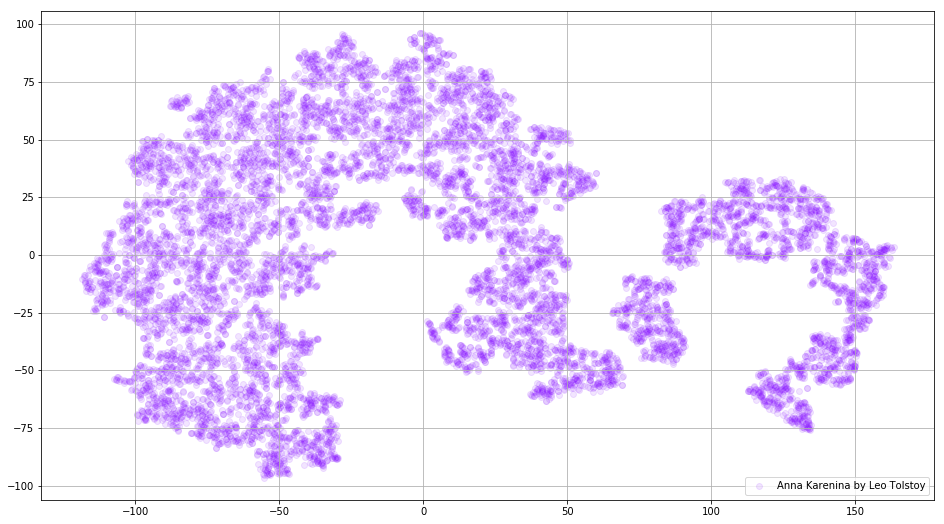
 Fig. 3. Visualização do modelo Word2Vec treinado em Anna Karenina.
Fig. 3. Visualização do modelo Word2Vec treinado em Anna Karenina.A imagem inteira pode ser ainda mais informativa se mapearmos as incorporações iniciais no espaço 3D. Neste momento, vamos dar uma olhada em Guerra e paz, uma das novelas vitais da literatura mundial e uma das maiores realizações literárias de Tolstoi.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
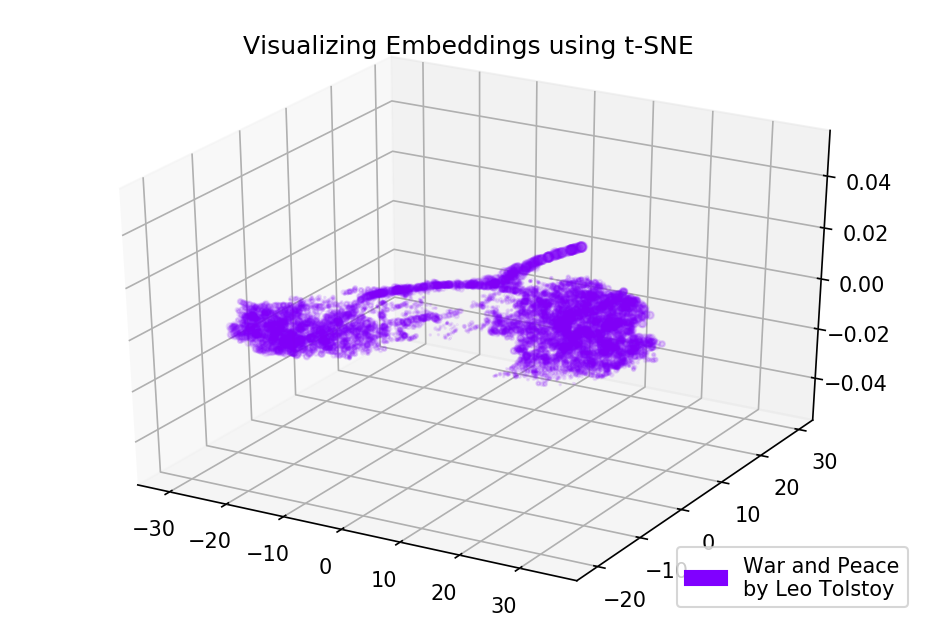 Fig. 4. Visualização do modelo Word2Vec treinado em Guerra e Paz.
Fig. 4. Visualização do modelo Word2Vec treinado em Guerra e Paz.Os resultados
É assim que os textos se parecem com as perspectivas para Word2Vec e t-SNE. Traçamos um gráfico bastante informativo para palavras semelhantes do Google Notícias e dois diagramas para os romances de Tolstoi. Além disso, mais uma coisa, GIFs! Os GIFs são impressionantes, mas plotar GIFs é quase o mesmo que plotar gráficos regulares. Decidi não mencioná-las no artigo, mas você pode encontrar o código para a geração de animações nas fontes.
O código fonte está disponível no
Github .
O artigo foi publicado originalmente na
Towards Data Science .
Referências
- L. Maate e G. Hinton, "Visualizando dados usando t-SNE", Journal of Machine Learning Research, vol. 9, pp. 2579-2605, 2008.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado e J. Dean, "Representações distribuídas de palavras e frases e sua composicionalidade", Avanços em sistemas de processamento de informações neurais, pp. 3111-3119, 2013.
- R. Rehurek e P. Sojka, “Estrutura de Software para Modelagem de Tópicos com Grandes Corpora”, Anais do Workshop LREC 2010 sobre Novos Desafios para Estruturas de PNL, 2010.